 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fashion Image Retrieval with Capsule Networks
Aug 26, 2019

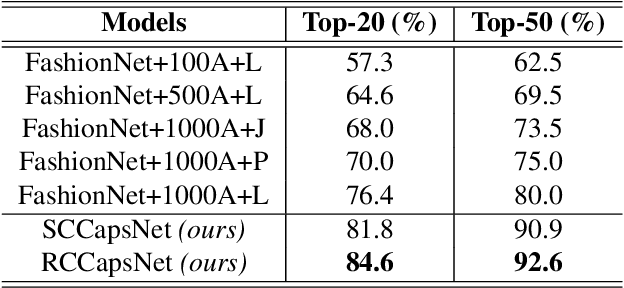
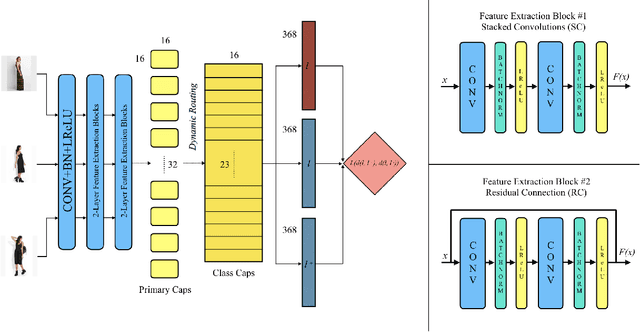

In this study, we investigate in-shop clothing retrieval performance of densely-connected Capsule Networks with dynamic routing. To achieve this, we propose Triplet-based design of Capsule Network architecture with two different feature extraction methods. In our design, Stacked-convolutional (SC) and Residual-connected (RC) blocks are used to form the input of capsule layers. Experimental results show that both of our designs outperform all variants of the baseline study, namely FashionNet, without relying on the landmark information. Moreover, when compared to the SOTA architectures on clothing retrieval, our proposed Triplet Capsule Networks achieve comparable recall rates only with half of parameters used in the SOTA architectures.
Iterative Reconstruction for Low-Dose CT using Deep Gradient Priors of Generative Model
Sep 27, 2020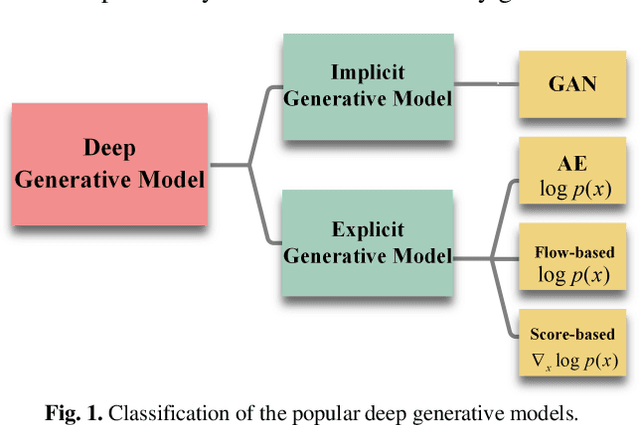
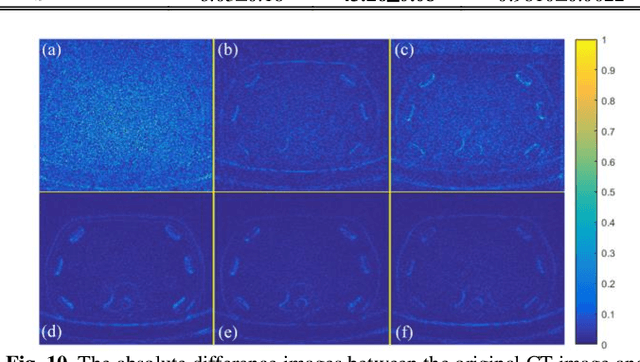
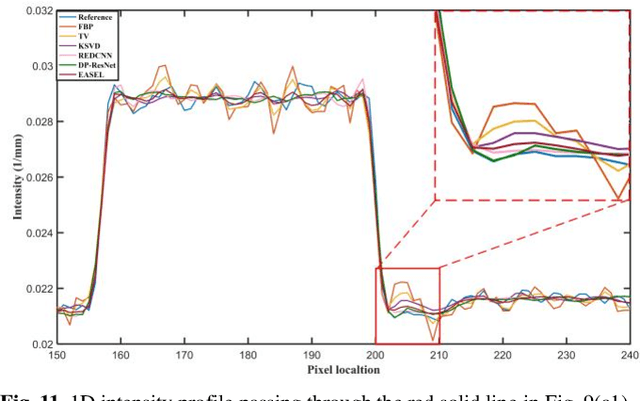
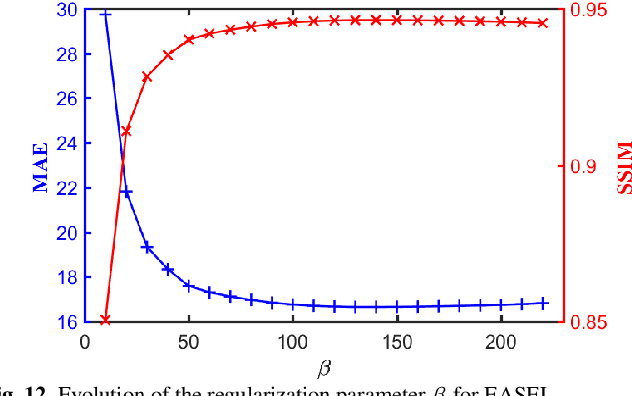
Dose reduction in computed tomography (CT) is essential for decreasing radiation risk in clinical applications. Iterative reconstruction is one of the most promising ways to compensate for the increased noise due to reduction of photon flux. Rather than most existing prior-driven algorithms that benefit from manually designed prior functions or supervised learning schemes, in this work we integrate the data-consistency as a conditional term into the iterative generative model for low-dose CT. At first, a score-based generative network is used for unsupervised distribution learning and the gradient of generative density prior is learned from normal-dose images. Then, the annealing Langevin dynamics is employed to update the trained priors with conditional scheme, i.e., the distance between the reconstructed image and the manifold is minimized along with data fidelity during reconstruction. Experimental comparisons demonstrated the noise reduction and detail preservation abilities of the proposed method.
Hierarchical pixel clustering for image segmentation
Jan 23, 2014

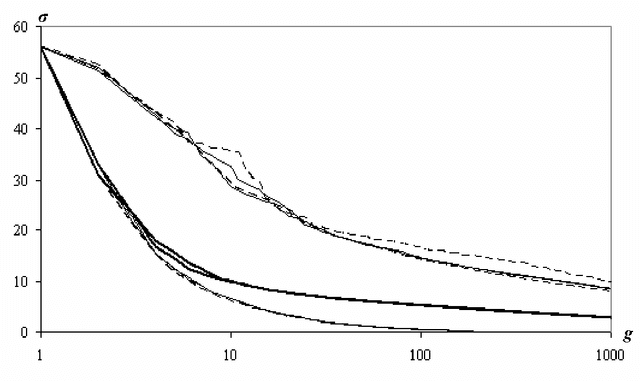
In the paper a piecewise constant image approximations of sequential number of pixel clusters or segments are treated. A majorizing of optimal approximation sequence by hierarchical sequence of image approximations is studied. Transition from pixel clustering to image segmentation by reducing of segment numbers in clusters is provided. Algorithms are proved by elementary formulas.
* 5 pages, 3 figures, 4 formulas, submitted to the 12 International Conference on Pattern Recognition and Information Processing May 28-30, 2014, Minsk, Belarus
Meta3D: Single-View 3D Object Reconstruction from Shape Priors in Memory
Mar 08, 2020
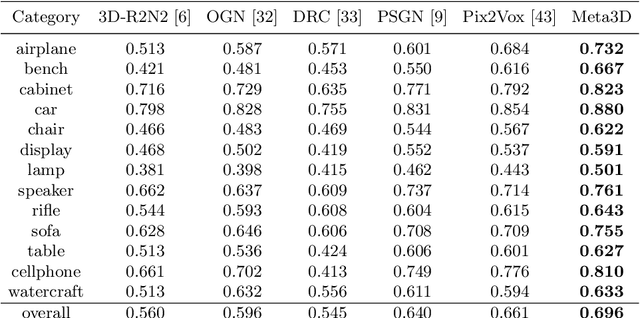
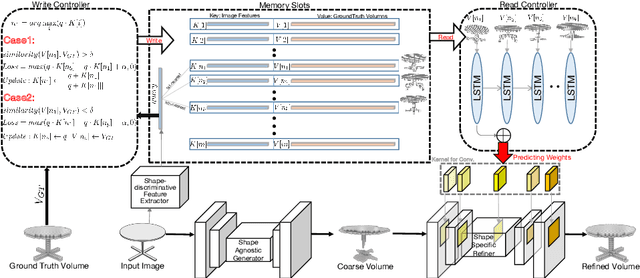
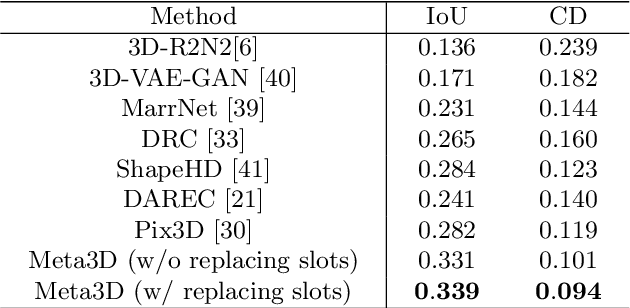
3D shape reconstruction from a single-view RGB image is an ill-posed problem due to the invisible parts of the object to be reconstructed. Most of the existing methods rely on large-scale data to obtain shape priors through tuning parameters of reconstruction models. These methods might not be able to deal with the cases with heavy object occlusions and noisy background since prior information can not be retained completely or applied efficiently. In this paper, we are the first to develop a memory-based meta-learning framework for single-view 3D reconstruction. A write controller is designed to extract shape-discriminative features from images and store image features and their corresponding volumes into external memory. A read controller is proposed to sequentially encode shape priors related to the input image and predict a shape-specific refiner. Experimental results demonstrate that our Meta3D outperforms state-of-the-art methods with a large margin through retaining shape priors explicitly, especially for the extremely difficult cases.
Enhancing Generalized Zero-Shot Learning via Adversarial Visual-Semantic Interaction
Jul 15, 2020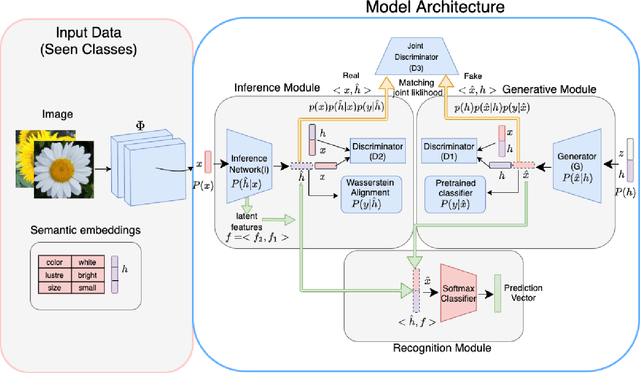
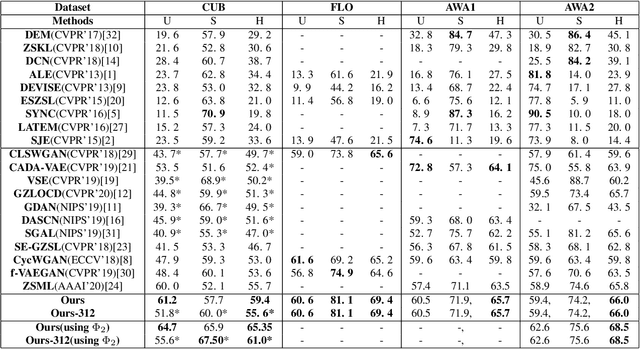
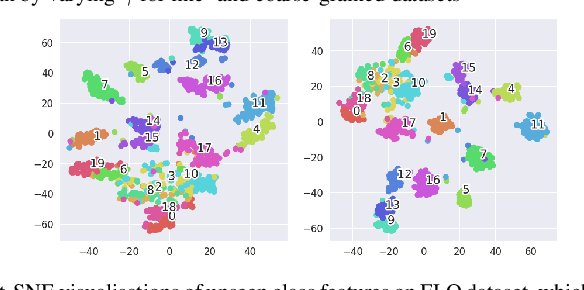

The performance of generative zero-shot methods mainly depends on the quality of generated features and how well the model facilitates knowledge transfer between visual and semantic domains. The quality of generated features is a direct consequence of the ability of the model to capture the several modes of the underlying data distribution. To address these issues, we propose a new two-level joint maximization idea to augment the generative network with an inference network during training which helps our model capture the several modes of the data and generate features that better represent the underlying data distribution. This provides strong cross-modal interaction for effective transfer of knowledge between visual and semantic domains. Furthermore, existing methods train the zero-shot classifier either on generate synthetic image features or latent embeddings produced by leveraging representation learning. In this work, we unify these paradigms into a single model which in addition to synthesizing image features, also utilizes the representation learning capabilities of the inference network to provide discriminative features for the final zero-shot recognition task. We evaluate our approach on four benchmark datasets i.e. CUB, FLO, AWA1 and AWA2 against several state-of-the-art methods, and show its performance. We also perform ablation studies to analyze and understand our method more carefully for the Generalized Zero-shot Learning task.
Motion-Based Generator Model: Unsupervised Disentanglement of Appearance, Trackable and Intrackable Motions in Dynamic Patterns
Nov 26, 2019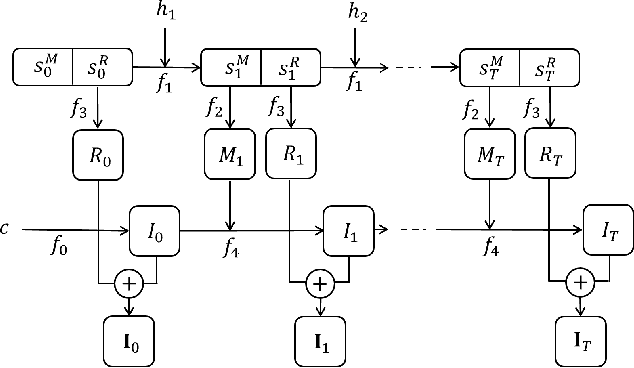

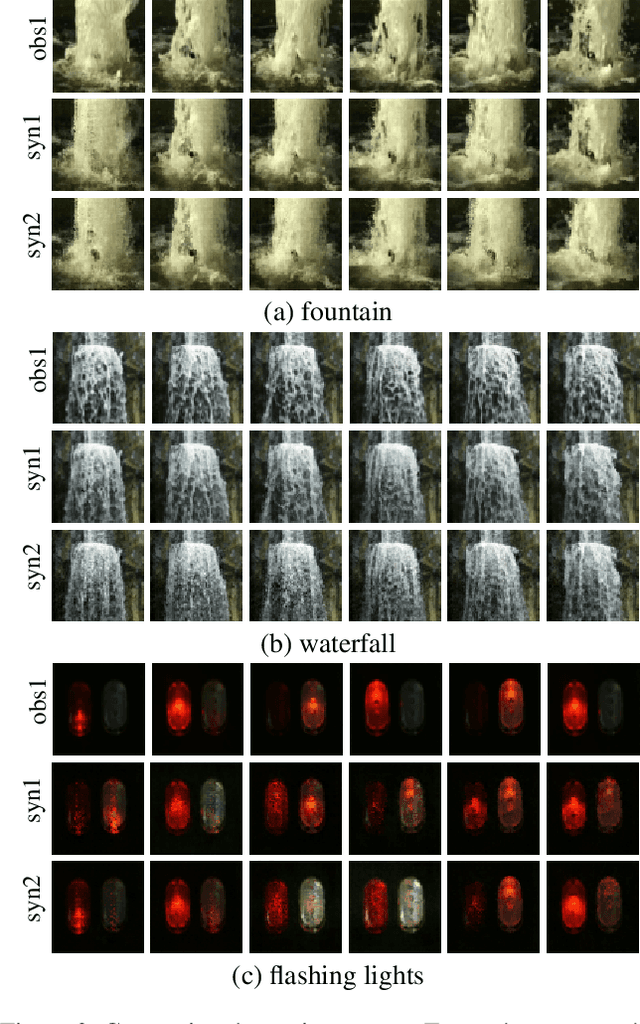
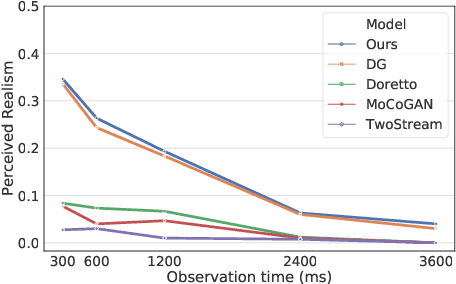
Dynamic patterns are characterized by complex spatial and motion patterns. Understanding dynamic patterns requires a disentangled representational model that separates the factorial components. A commonly used model for dynamic patterns is the state space model, where the state evolves over time according to a transition model and the state generates the observed image frames according to an emission model. To model the motions explicitly, it is natural for the model to be based on the motions or the displacement fields of the pixels. Thus in the emission model, we let the hidden state generate the displacement field, which warps the trackable component in the previous image frame to generate the next frame while adding a simultaneously emitted residual image to account for the change that cannot be explained by the deformation. The warping of the previous image is about the trackable part of the change of image frame, while the residual image is about the intrackable part of the image. We use a maximum likelihood algorithm to learn the model that iterates between inferring latent noise vectors that drive the transition model and updating the parameters given the inferred latent vectors. Meanwhile we adopt a regularization term to penalize the norms of the residual images to encourage the model to explain the change of image frames by trackable motion. Unlike existing methods on dynamic patterns, we learn our model in unsupervised setting without ground truth displacement fields. In addition, our model defines a notion of intrackability by the separation of warped component and residual component in each image frame. We show that our method can synthesize realistic dynamic pattern, and disentangling appearance, trackable and intrackable motions. The learned models are useful for motion transfer, and it is natural to adopt it to define and measure intrackability of a dynamic pattern.
Learning Normalized Inputs for Iterative Estimation in Medical Image Segmentation
Feb 16, 2017
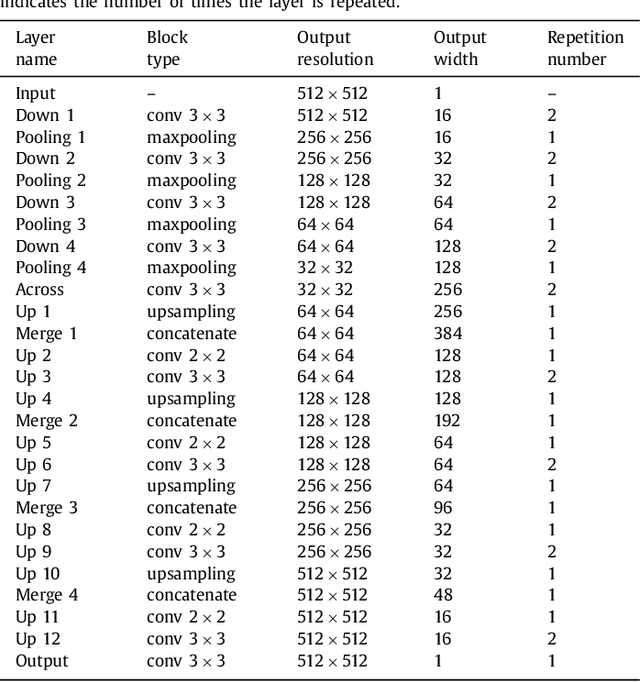
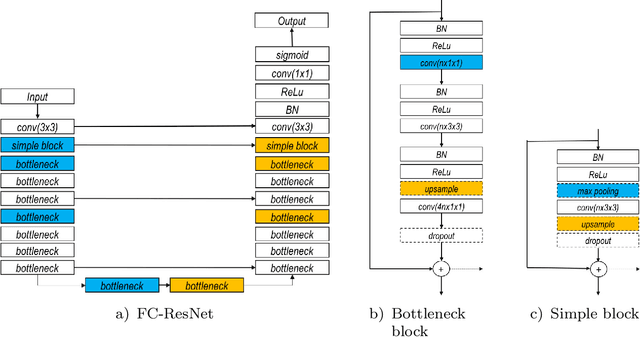
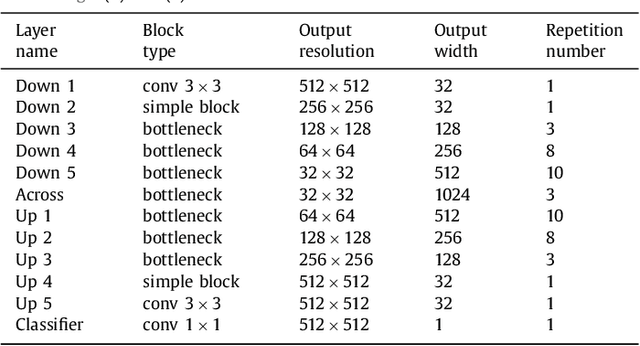
In this paper, we introduce a simple, yet powerful pipeline for medical image segmentation that combines Fully Convolutional Networks (FCNs) with Fully Convolutional Residual Networks (FC-ResNets). We propose and examine a design that takes particular advantage of recent advances in the understanding of both Convolutional Neural Networks as well as ResNets. Our approach focuses upon the importance of a trainable pre-processing when using FC-ResNets and we show that a low-capacity FCN model can serve as a pre-processor to normalize medical input data. In our image segmentation pipeline, we use FCNs to obtain normalized images, which are then iteratively refined by means of a FC-ResNet to generate a segmentation prediction. As in other fully convolutional approaches, our pipeline can be used off-the-shelf on different image modalities. We show that using this pipeline, we exhibit state-of-the-art performance on the challenging Electron Microscopy benchmark, when compared to other 2D methods. We improve segmentation results on CT images of liver lesions, when contrasting with standard FCN methods. Moreover, when applying our 2D pipeline on a challenging 3D MRI prostate segmentation challenge we reach results that are competitive even when compared to 3D methods. The obtained results illustrate the strong potential and versatility of the pipeline by achieving highly accurate results on multi-modality images from different anatomical regions and organs.
Off-Policy Self-Critical Training for Transformer in Visual Paragraph Generation
Jun 21, 2020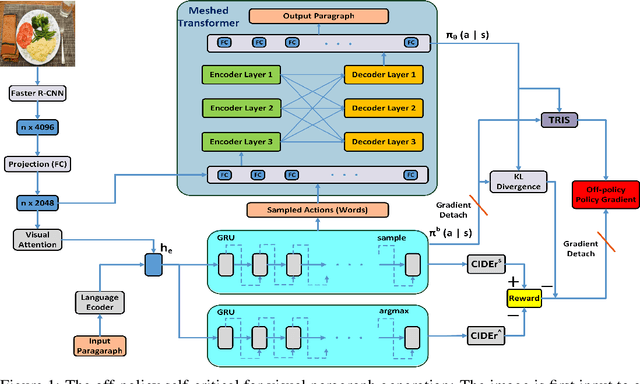
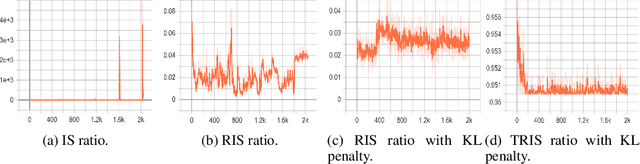


Recently, several approaches have been proposed to solve language generation problems. Transformer is currently state-of-the-art seq-to-seq model in language generation. Reinforcement Learning (RL) is useful in solving exposure bias and the optimisation on non-differentiable metrics in seq-to-seq language learning. However, Transformer is hard to combine with RL as the costly computing resource is required for sampling. We tackle this problem by proposing an off-policy RL learning algorithm where a behaviour policy represented by GRUs performs the sampling. We reduce the high variance of importance sampling (IS) by applying the truncated relative importance sampling (TRIS) technique and Kullback-Leibler (KL)-control concept. TRIS is a simple yet effective technique, and there is a theoretical proof that KL-control helps to reduce the variance of IS. We formulate this off-policy RL based on self-critical sequence training. Specifically, we use a Transformer-based captioning model as the target policy and use an image-guided language auto-encoder as the behaviour policy to explore the environment. The proposed algorithm achieves state-of-the-art performance on the visual paragraph generation and improved results on image captioning.
Local- and Holistic- Structure Preserving Image Super Resolution via Deep Joint Component Learning
Jul 25, 2016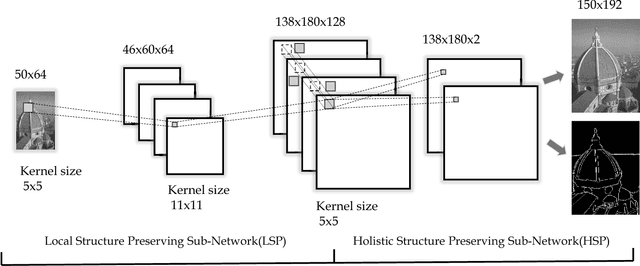
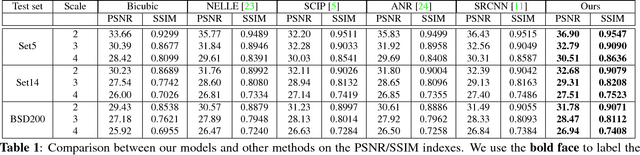
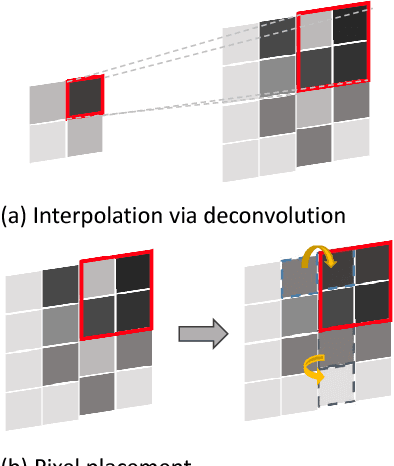
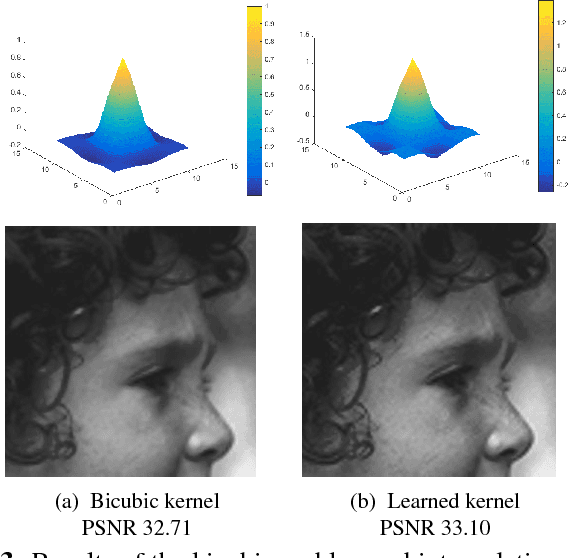
Recently, machine learning based single image super resolution (SR) approaches focus on jointly learning representations for high-resolution (HR) and low-resolution (LR) image patch pairs to improve the quality of the super-resolved images. However, due to treat all image pixels equally without considering the salient structures, these approaches usually fail to produce visual pleasant images with sharp edges and fine details. To address this issue, in this work we present a new novel SR approach, which replaces the main building blocks of the classical interpolation pipeline by a flexible, content-adaptive deep neural networks. In particular, two well-designed structure-aware components, respectively capturing local- and holistic- image contents, are naturally incorporated into the fully-convolutional representation learning to enhance the image sharpness and naturalness. Extensively evaluations on several standard benchmarks (e.g., Set5, Set14 and BSD200) demonstrate that our approach can achieve superior results, especially on the image with salient structures, over many existing state-of-the-art SR methods under both quantitative and qualitative measures.
Decoupled Self Attention for Accurate One Stage Object Detection
Dec 14, 2020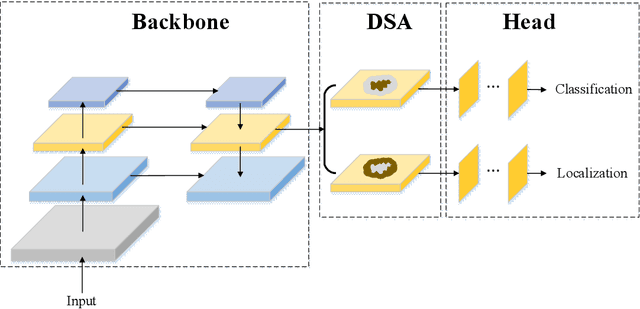
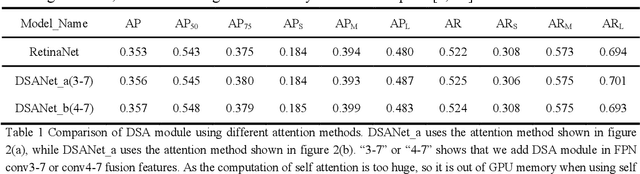
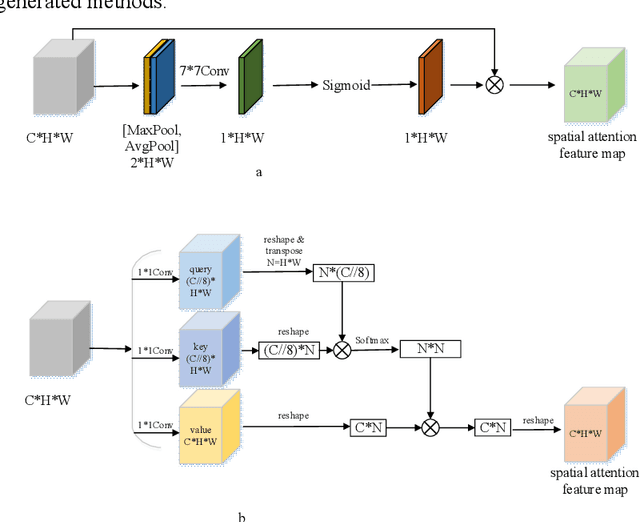
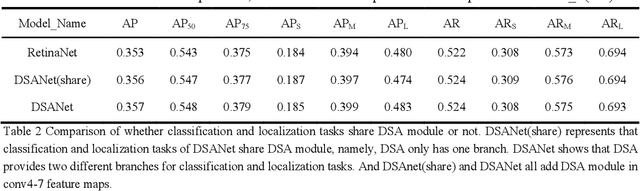
As the scale of object detection dataset is smaller than that of image recognition dataset ImageNet, transfer learning has become a basic training method for deep learning object detection models, which will pretrain the backbone network of object detection model on ImageNet dataset to extract features for classification and localization subtasks. However, the classification task focuses on the salient region features of object, while the location task focuses on the edge features of object, so there is certain deviation between the features extracted by pretrained backbone network and the features used for localization task. In order to solve this problem, a decoupled self attention(DSA) module is proposed for one stage object detection models in this paper. DSA includes two decoupled self-attention branches, so it can extract appropriate features for different tasks. It is located between FPN and head networks of subtasks, so it is used to extract global features based on FPN fused features for different tasks independently. Although the network of DSA module is simple, but it can effectively improve the performance of object detection, also it can be easily embedded in many detection models. Our experiments are based on the representative one-stage detection model RetinaNet. In COCO dataset, when ResNet50 and ResNet101 are used as backbone networks, the detection performances can be increased by 0.4% AP and 0.5% AP respectively. When DSA module and object confidence task are applied in RetinaNet together, the detection performances based on ResNet50 and ResNet101 can be increased by 1.0% AP and 1.4% AP respectively. The experiment results show the effectiveness of DSA module.