 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Image Analysis Approach to the Calligraphy of Books
Aug 24, 2017
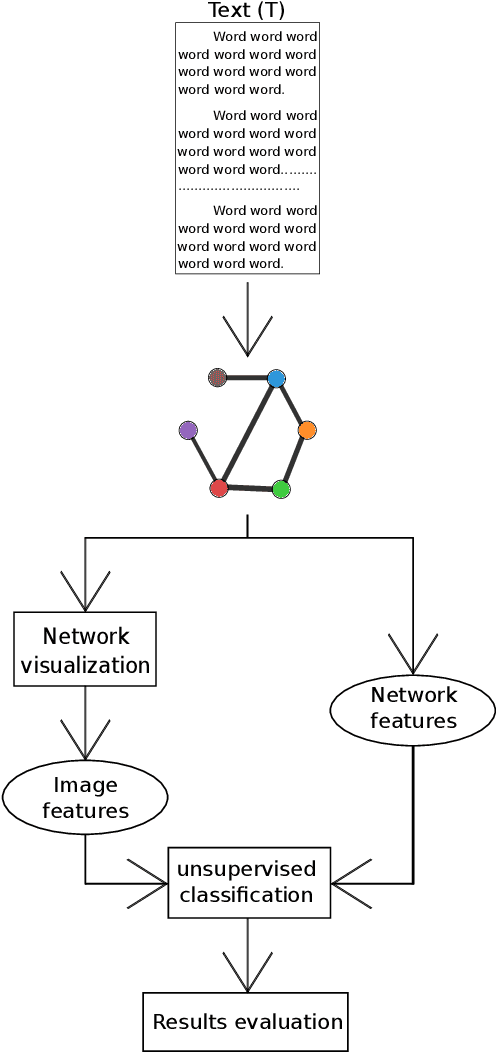
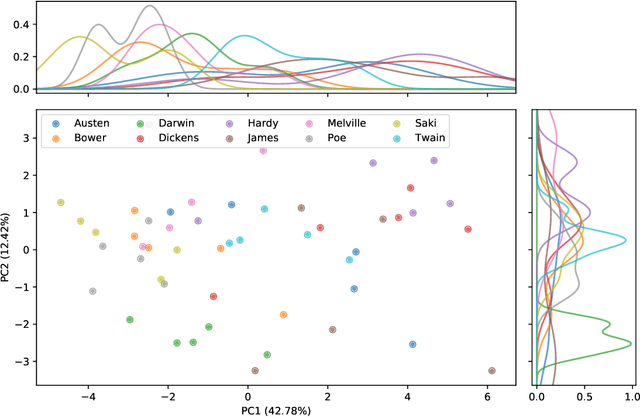
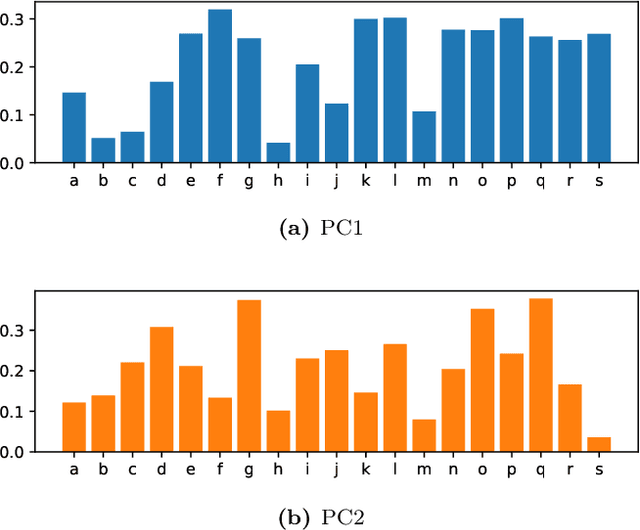
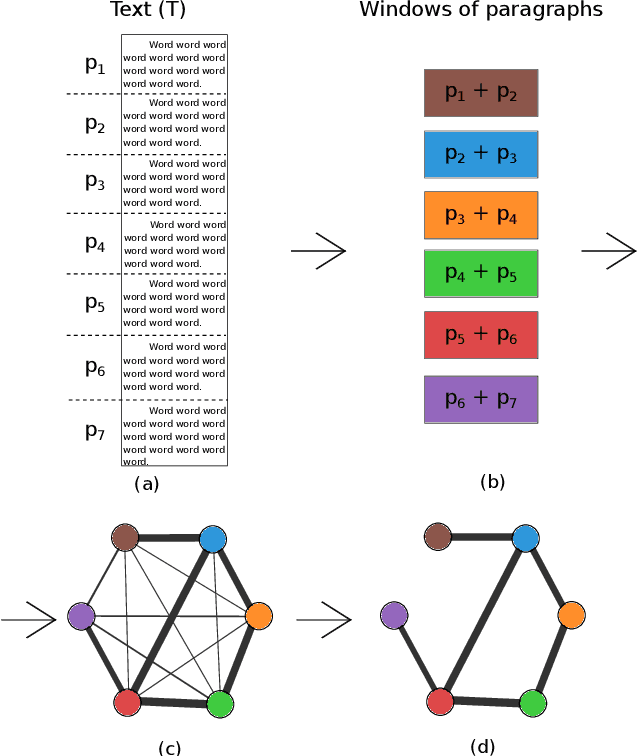
Text network analysis has received increasing attention as a consequence of its wide range of applications. In this work, we extend a previous work founded on the study of topological features of mesoscopic networks. Here, the geometrical properties of visualized networks are quantified in terms of several image analysis techniques and used as subsidies for authorship attribution. It was found that the visual features account for performance similar to that achieved by using topological measurements. In addition, the combination of these two types of features improved the performance.
Coronavirus: Comparing COVID-19, SARS and MERS in the eyes of AI
Jun 08, 2020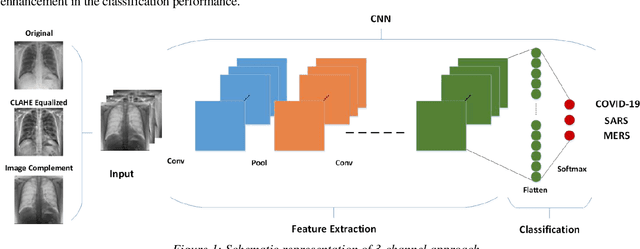

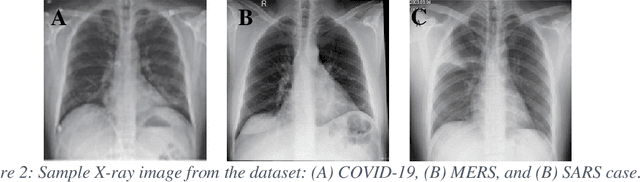
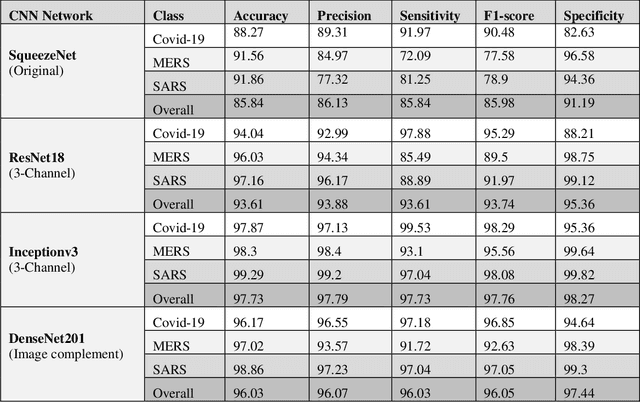
Novel Coronavirus disease (COVID-19) is an extremely contagious and quickly spreading Coronavirus disease. Severe Acute Respiratory Syndrome (SARS)-CoV, Middle East Respiratory Syndrome (MERS)-CoV outbreak in 2002 and 2011 and current COVID-19 pandemic all from the same family of Coronavirus. The fatality rate due to SARS and MERS were higher than COVID-19 however, the spread of those were limited to few countries while COVID-19 affected more than two-hundred countries of the world. In this work, authors used deep machine learning algorithms along with innovative image pre-processing techniques to distinguish COVID-19 images from SARS and MERS images. Several deep learning algorithms were trained, and tested and four outperforming algorithms were reported: SqueezeNet, ResNet18, Inceptionv3 and DenseNet201. Original, Contrast limited adaptive histogram equalized and complemented image were used individually and in concatenation as the inputs to the networks. It was observed that inceptionv3 outperforms all networks for 3-channel concatenation technique and provide an excellent sensitivity of 99.5%, 93.1% and 97% for classifying COVID-19, MERS and SARS images respectively. Investigating deep layer activation mapping of the correctly classified images and miss-classified images, it was observed that some overlapping features between COVID-19 and MERS images were identified by the deep layer network. Interestingly these features were present in MERS images and 10 out of 144 images were miss-classified as COVID while only one out of 423 COVID-19 images was miss-classified as MERS. None of the MERS images was miss-classified to SARS and only one COVID-19 image was miss-classified as SARS. Therefore, it can be summarized that SARS images are significantly different from MERS and COVID-19 in the eyes of AI while there are some overlapping feature available between MERS and COVID-19.
Where Does the Robustness Come from? A Study of the Transformation-based Ensemble Defence
Sep 28, 2020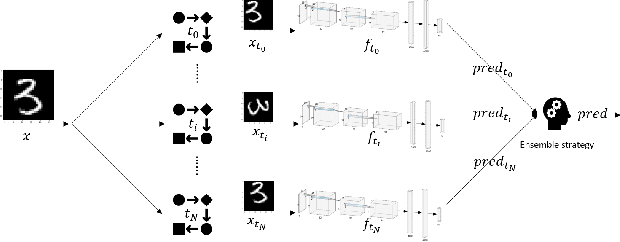
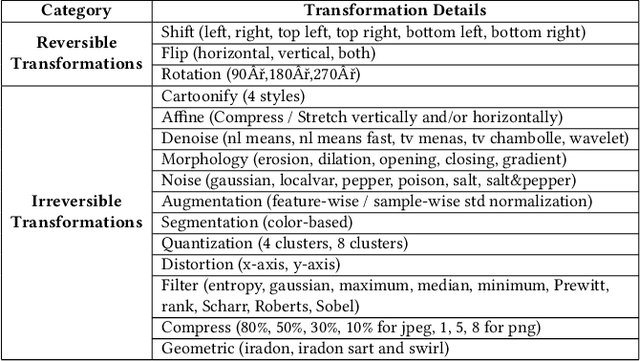
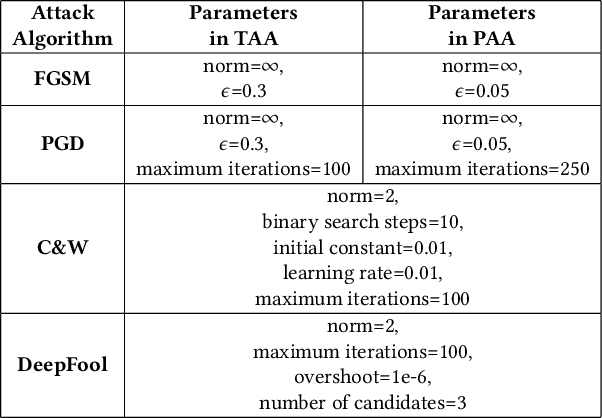
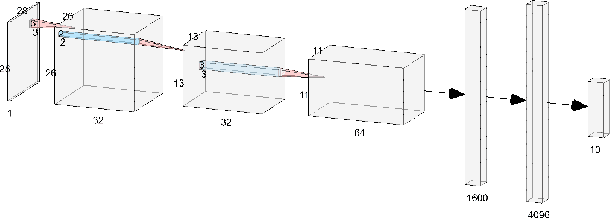
This paper aims to provide a thorough study on the effectiveness of the transformation-based ensemble defence for image classification and its reasons. It has been empirically shown that they can enhance the robustness against evasion attacks, while there is little analysis on the reasons. In particular, it is not clear whether the robustness improvement is a result of transformation or ensemble. In this paper, we design two adaptive attacks to better evaluate the transformation-based ensemble defence. We conduct experiments to show that 1) the transferability of adversarial examples exists among the models trained on data records after different reversible transformations; 2) the robustness gained through transformation-based ensemble is limited; 3) this limited robustness is mainly from the irreversible transformations rather than the ensemble of a number of models; and 4) blindly increasing the number of sub-models in a transformation-based ensemble does not bring extra robustness gain.
* 12 pages, 4 figures, AISec 2020
Tele-operative Robotic Lung Ultrasound Scanning Platform for Triage of COVID-19 Patients
Oct 30, 2020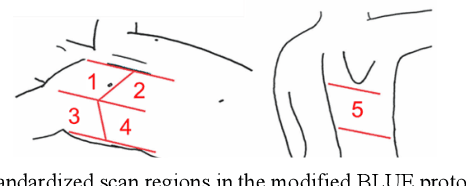
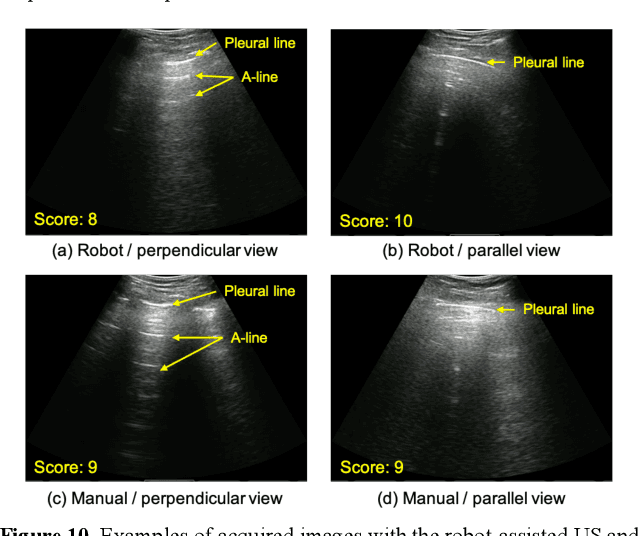
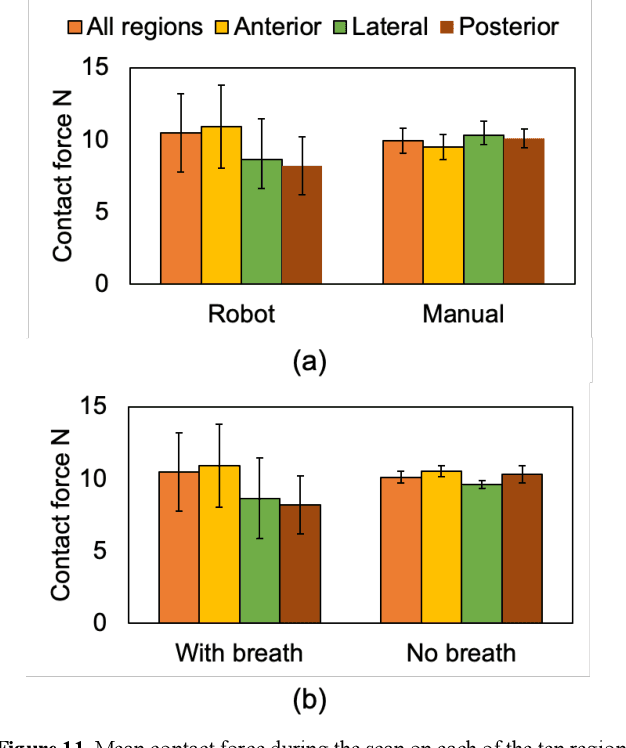
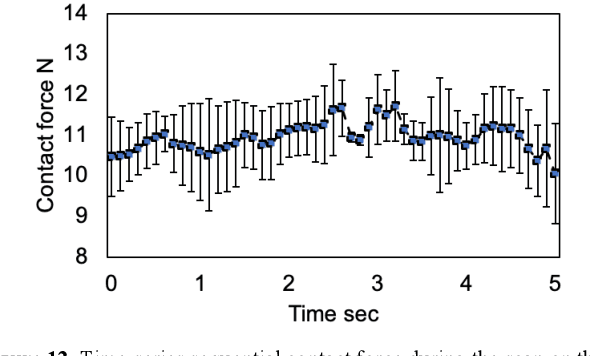
Novel severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) has become a pandemic of epic proportions and a global response to prepare health systems worldwide is of utmost importance. In addition to its cost-effectiveness in a resources-limited setting, lung ultrasound (LUS) has emerged as a rapid noninvasive imaging tool for the diagnosis of COVID-19 infected patients. Concerns surrounding LUS include the disparity of infected patients and healthcare providers, relatively small number of physicians and sonographers capable of performing LUS, and most importantly, the requirement for substantial physical contact between the patient and operator, increasing the risk of transmission. Mitigation of the spread of the virus is of paramount importance. A 2-dimensional (2D) tele-operative robotic platform capable of performing LUS in for COVID-19 infected patients may be of significant benefit. The authors address the aforementioned issues surrounding the use of LUS in the application of COVID- 19 infected patients. In addition, first time application, feasibility and safety were validated in three healthy subjects, along with 2D image optimization and comparison for overall accuracy. Preliminary results demonstrate that the proposed platform allows for successful acquisition and application of LUS in humans.
Information Mandala: Statistical Distance Matrix with Clustering
Jun 22, 2020

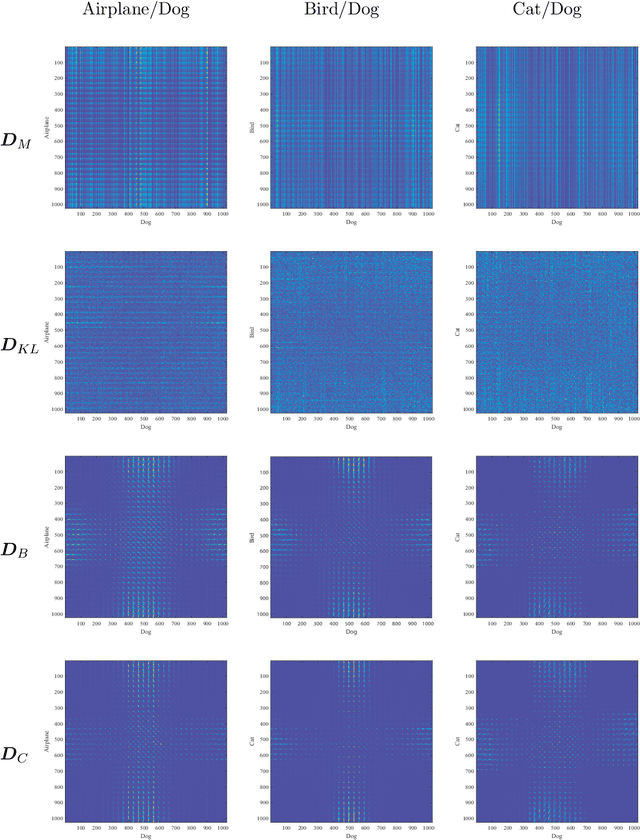
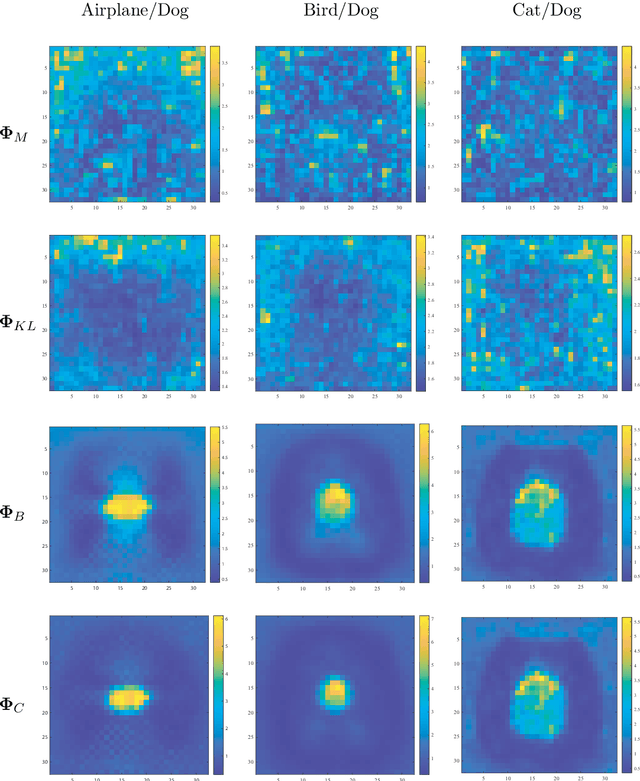
In machine learning, observation features are measured in a metric space to obtain their distance function for optimization. Given similar features that are statistically sufficient as a population, a statistical distance between two probability distributions can be calculated for more precise learning. Provided the observed features are multi-valued, the statistical distance function is still efficient. However, due to its scalar output, it cannot be applied to represent detailed distances between feature elements. To resolve this problem, this paper extends the traditional statistical distance to a matrix form, called a statistical distance matrix. In experiments, the proposed approach performs well in object recognition tasks and clearly and intuitively represents the dissimilarities between cat and dog images in the CIFAR dataset, even when directly calculated using the image pixels. By using the hierarchical clustering of the statistical distance matrix, the image pixels can be separated into several clusters that are geometrically arranged around a center like a Mandala pattern. The statistical distance matrix with clustering, called the Information Mandala, is beyond ordinary saliency maps and can help to understand the basic principles of the convolution neural network.
Weighing Counts: Sequential Crowd Counting by Reinforcement Learning
Jul 16, 2020
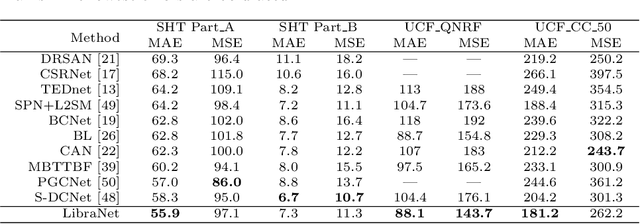
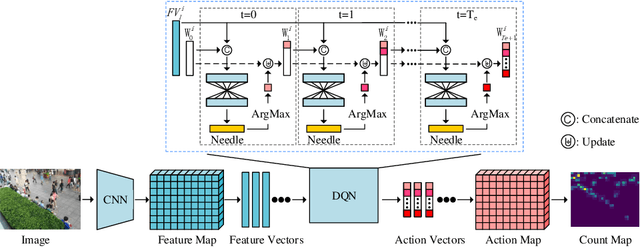
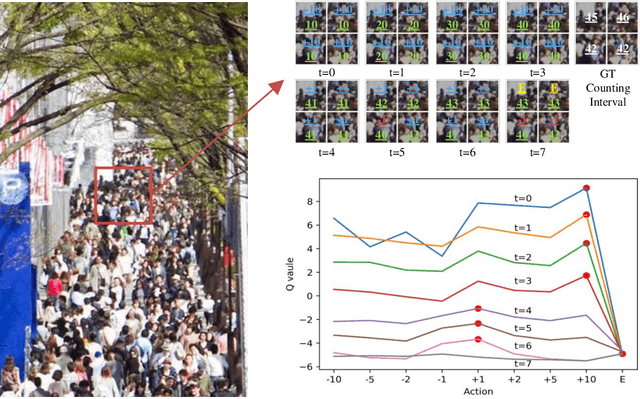
We formulate counting as a sequential decision problem and present a novel crowd counting model solvable by deep reinforcement learning. In contrast to existing counting models that directly output count values, we divide one-step estimation into a sequence of much easier and more tractable sub-decision problems. Such sequential decision nature corresponds exactly to a physical process in reality scale weighing. Inspired by scale weighing, we propose a novel 'counting scale' termed LibraNet where the count value is analogized by weight. By virtually placing a crowd image on one side of a scale, LibraNet (agent) sequentially learns to place appropriate weights on the other side to match the crowd count. At each step, LibraNet chooses one weight (action) from the weight box (the pre-defined action pool) according to the current crowd image features and weights placed on the scale pan (state). LibraNet is required to learn to balance the scale according to the feedback of the needle (Q values). We show that LibraNet exactly implements scale weighing by visualizing the decision process how LibraNet chooses actions. Extensive experiments demonstrate the effectiveness of our design choices and report state-of-the-art results on a few crowd counting benchmarks. We also demonstrate good cross-dataset generalization of LibraNet. Code and models are made available at: https://git.io/libranet
Divergence-Based Adaptive Extreme Video Completion
Apr 14, 2020

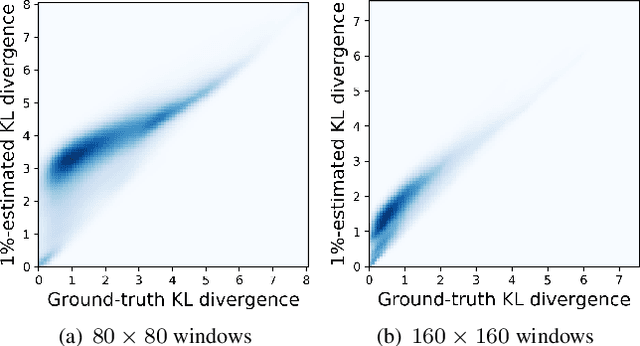
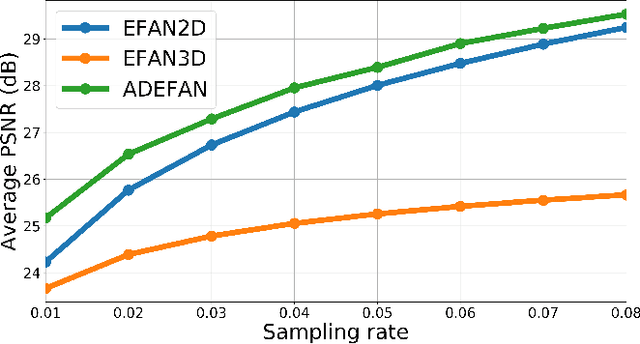
Extreme image or video completion, where, for instance, we only retain 1% of pixels in random locations, allows for very cheap sampling in terms of the required pre-processing. The consequence is, however, a reconstruction that is challenging for humans and inpainting algorithms alike. We propose an extension of a state-of-the-art extreme image completion algorithm to extreme video completion. We analyze a color-motion estimation approach based on color KL-divergence that is suitable for extremely sparse scenarios. Our algorithm leverages the estimate to adapt between its spatial and temporal filtering when reconstructing the sparse randomly-sampled video. We validate our results on 50 publicly-available videos using reconstruction PSNR and mean opinion scores.
Robust 2D Assembly Sequencing via Geometric Planning with Learned Scores
Sep 20, 2020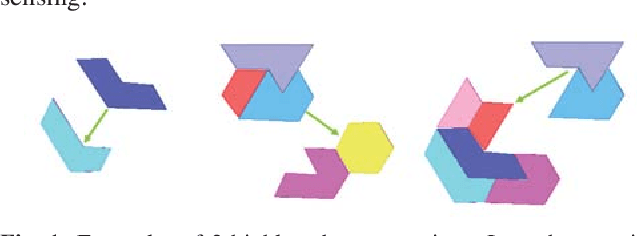
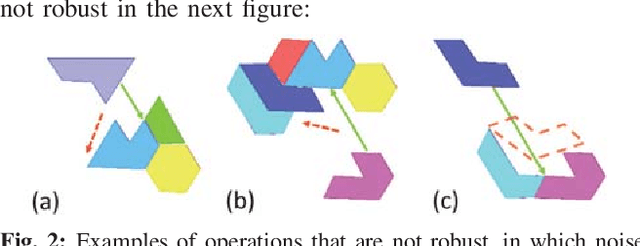
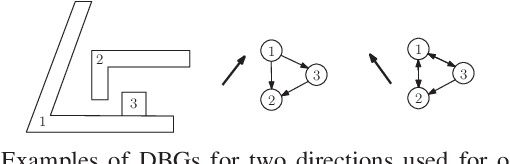
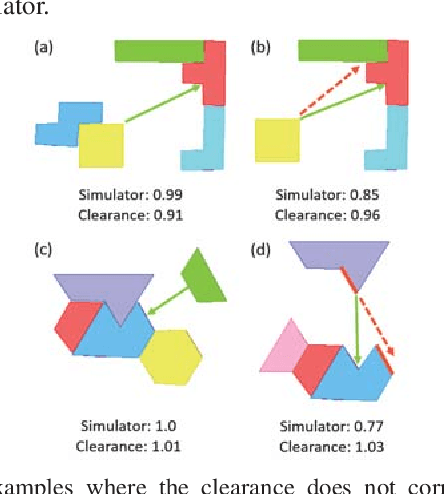
To compute robust 2D assembly plans, we present an approach that combines geometric planning with a deep neural network. We train the network using the Box2D physics simulator with added stochastic noise to yield robustness scores--the success probabilities of planned assembly motions. As running a simulation for every assembly motion is impractical, we train a convolutional neural network to map assembly operations, given as an image pair of the subassemblies before and after they are mated, to a robustness score. The neural network prediction is used within a planner to quickly prune out motions that are not robust. We demonstrate this approach on two-handed planar assemblies, where the motions are one-step translations. Results suggest that the neural network can learn robustness to plan robust sequences an order of magnitude faster than physics simulation.
Multiple instance learning on deep features for weakly supervised object detection with extreme domain shifts
Sep 12, 2020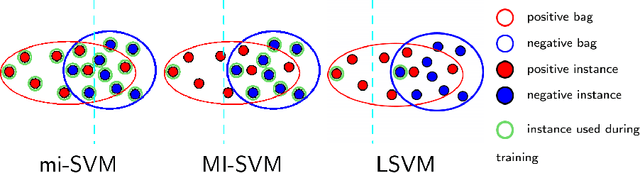
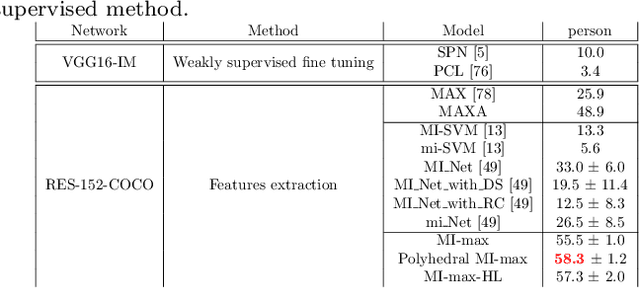
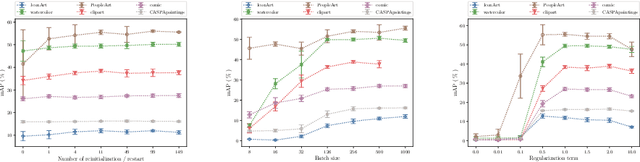
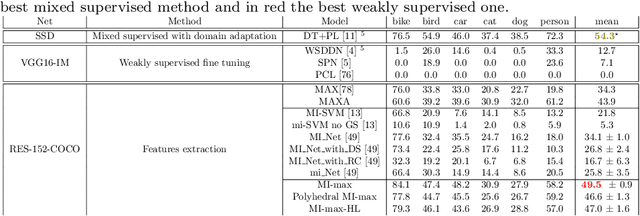
Weakly supervised object detection (WSOD) using only image-level annotations has attracted a growing attention over the past few years. Whereas such task is typically addressed with a domain-specific solution focused on natural images, we show that a simple multiple instance approach applied on pre-trained deep features yields excellent performances on non-photographic datasets, possibly including new classes. The approach does not include any fine-tuning or cross-domain learning and is therefore efficient and possibly applicable to arbitrary datasets and classes. We investigate several flavors of the proposed approach, some including multi-layers perceptron and polyhedral classifiers. Despite its simplicity, our method shows competitive results on a range of publicly available datasets, including paintings (People-Art, IconArt), watercolors, cliparts and comics and allows to quickly learn unseen visual categories.
Find it if You Can: End-to-End Adversarial Erasing for Weakly-Supervised Semantic Segmentation
Nov 09, 2020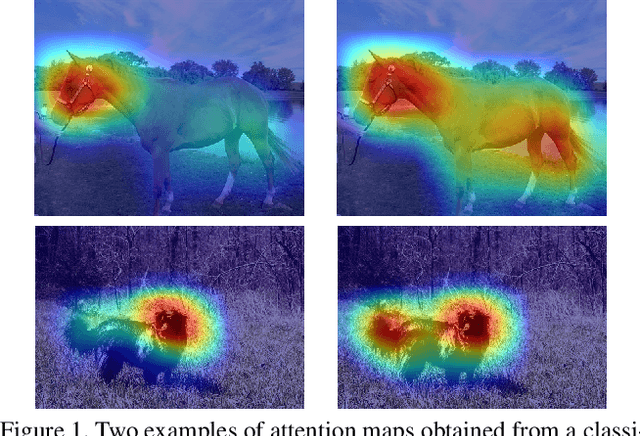
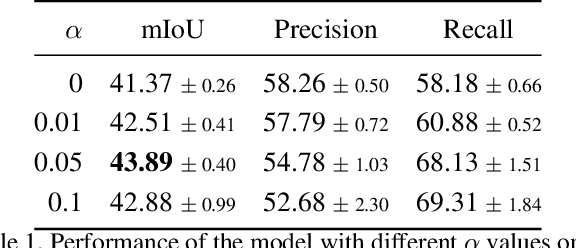


Semantic segmentation is a task that traditionally requires a large dataset of pixel-level ground truth labels, which is time-consuming and expensive to obtain. Recent advancements in the weakly-supervised setting show that reasonable performance can be obtained by using only image-level labels. Classification is often used as a proxy task to train a deep neural network from which attention maps are extracted. However, the classification task needs only the minimum evidence to make predictions, hence it focuses on the most discriminative object regions. To overcome this problem, we propose a novel formulation of adversarial erasing of the attention maps. In contrast to previous adversarial erasing methods, we optimize two networks with opposing loss functions, which eliminates the requirement of certain suboptimal strategies; for instance, having multiple training steps that complicate the training process or a weight sharing policy between networks operating on different distributions that might be suboptimal for performance. The proposed solution does not require saliency masks, instead it uses a regularization loss to prevent the attention maps from spreading to less discriminative object regions. Our experiments on the Pascal VOC dataset demonstrate that our adversarial approach increases segmentation performance by 2.1 mIoU compared to our baseline and by 1.0 mIoU compared to previous adversarial erasing approaches.