 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
3D-DEEP: 3-Dimensional Deep-learning based on elevation patterns forroad scene interpretation
Sep 01, 2020


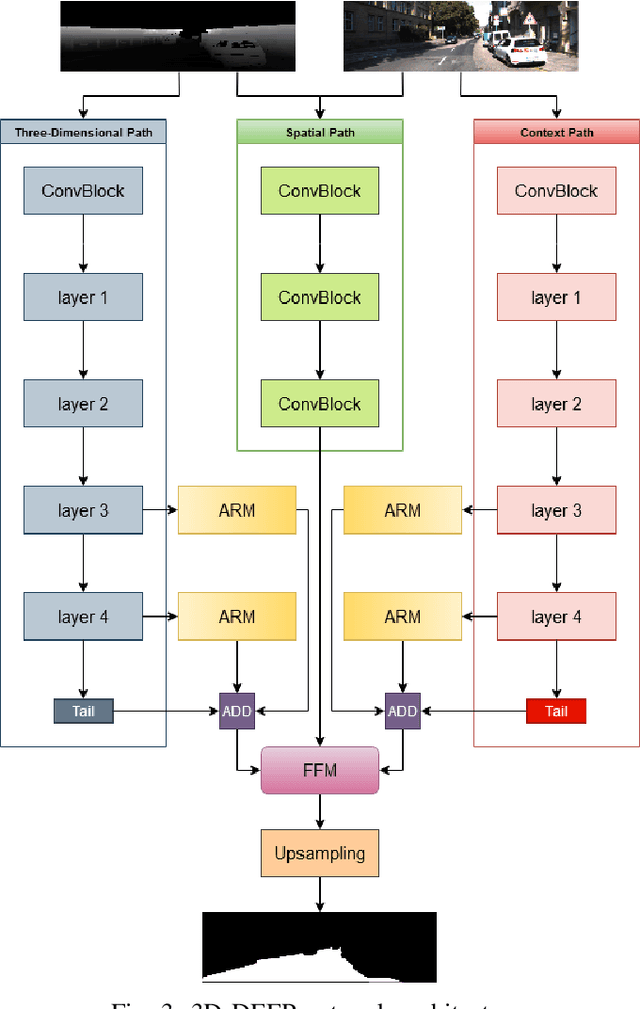
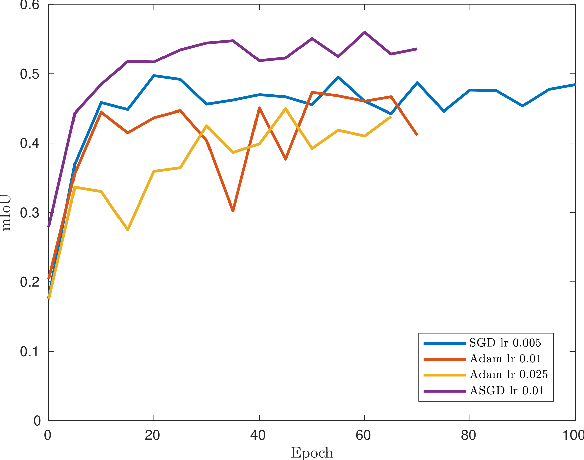
Road detection and segmentation is a crucial task in computer vision for safe autonomous driving. With this in mind, a new net architecture (3D-DEEP) and its end-to-end training methodology for CNN-based semantic segmentation are described along this paper for. The method relies on disparity filtered and LiDAR projected images for three-dimensional information and image feature extraction through fully convolutional networks architectures. The developed models were trained and validated over Cityscapes dataset using just fine annotation examples with 19 different training classes, and over KITTI road dataset. 72.32% mean intersection over union(mIoU) has been obtained for the 19 Cityscapes training classes using the validation images. On the other hand, over KITTIdataset the model has achieved an F1 error value of 97.85% invalidation and 96.02% using the test images.
Group Equivariant Generative Adversarial Networks
May 04, 2020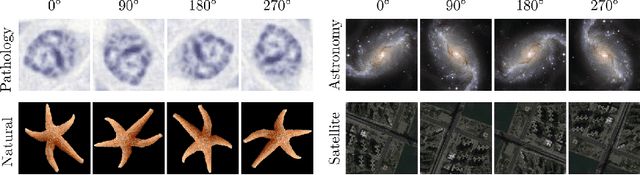
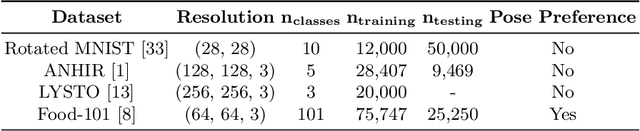
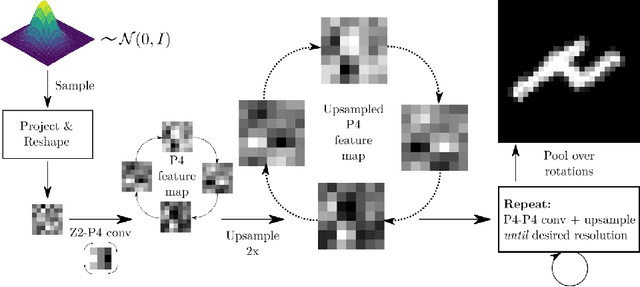
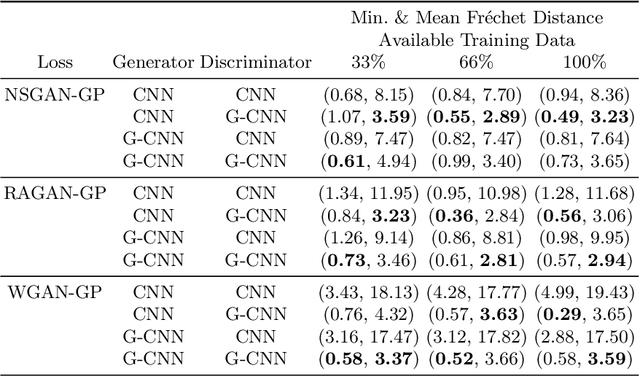
Generative adversarial networks are the state of the art for generative modeling in vision, yet are notoriously unstable in practice. This instability is further exacerbated with limited training data. However, in the synthesis of domains such as medical or satellite imaging, it is often overlooked that the image label is invariant to global image symmetries (e.g., rotations and reflections). In this work, we improve gradient feedback between generator and discriminator using an inductive symmetry prior via group-equivariant convolutional networks. We replace convolutional layers with equivalent group-convolutional layers in both generator and discriminator, allowing for better optimization steps and increased expressive power with limited samples. In the process, we extend recent GAN developments to the group-equivariant setting. We demonstrate the utility of our methods by improving both sample fidelity and diversity in the class-conditional synthesis of a diverse set of globally-symmetric imaging modalities.
Learning the Best Pooling Strategy for Visual Semantic Embedding
Nov 09, 2020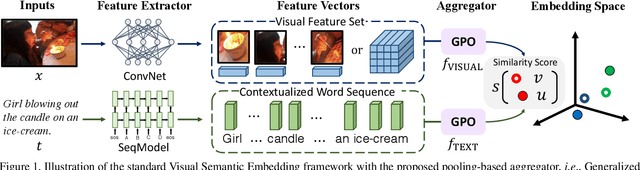
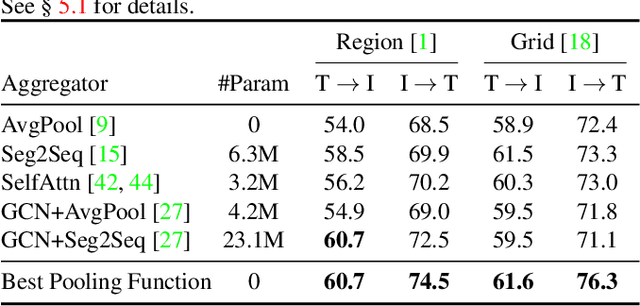
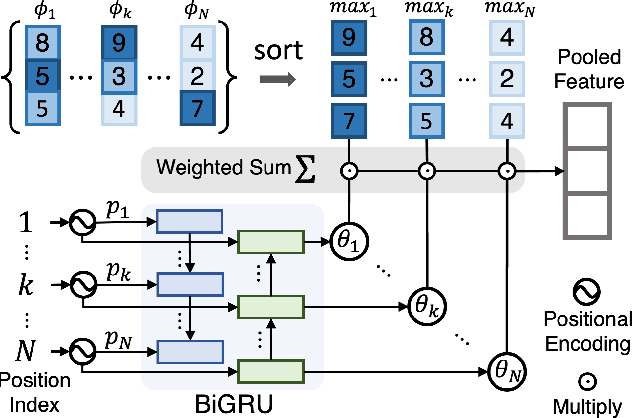
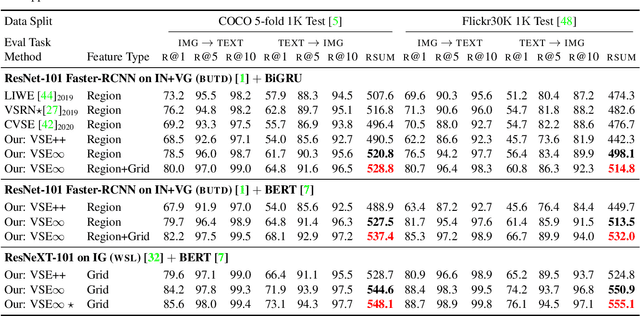
Visual Semantic Embedding (VSE) is a dominant approach for vision-language retrieval, which aims at learning a deep embedding space such that visual data are embedded close to their semantic text labels or descriptions. Recent VSE models use complex methods to better contextualize and aggregate multi-modal features into holistic embeddings. However, we discover that surprisingly simple (but carefully selected) global pooling functions (e.g., max pooling) outperform those complex models, across different feature extractors. Despite its simplicity and effectiveness, seeking the best pooling function for different data modality and feature extractor is costly and tedious, especially when the size of features varies (e.g., text, video). Therefore, we propose a Generalized Pooling Operator (GPO), which learns to automatically adapt itself to the best pooling strategy for different features, requiring no manual tuning while staying effective and efficient. We extend the VSE model using this proposed GPO and denote it as VSE$\infty$. Without bells and whistles, VSE$\infty$ outperforms previous VSE methods significantly on image-text retrieval benchmarks across popular feature extractors. With a simple adaptation, variants of VSE$\infty$ further demonstrate its strength by achieving the new state of the art on two video-text retrieval datasets. Comprehensive experiments and visualizations confirm that GPO always discovers the best pooling strategy and can be a plug-and-play feature aggregation module for standard VSE models.
Is Robustness the Cost of Accuracy? -- A Comprehensive Study on the Robustness of 18 Deep Image Classification Models
Aug 05, 2018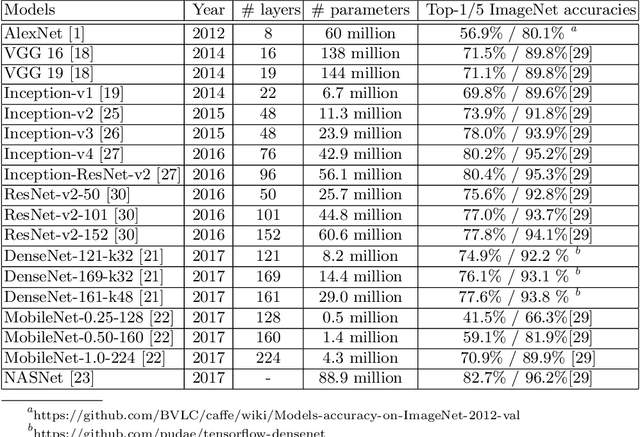
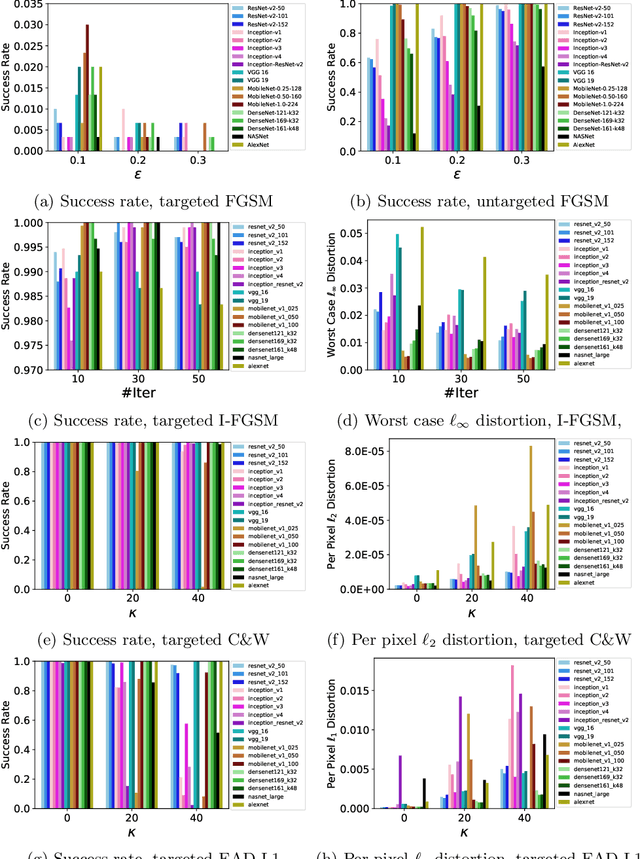
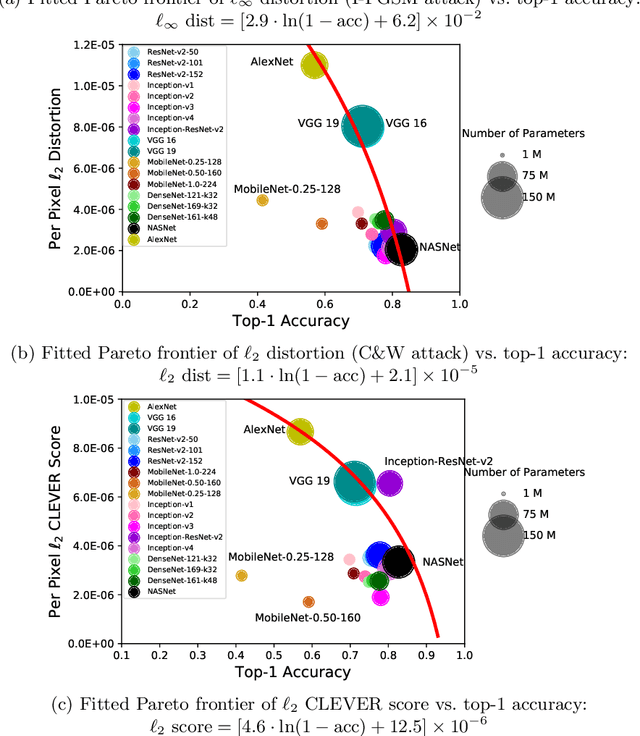
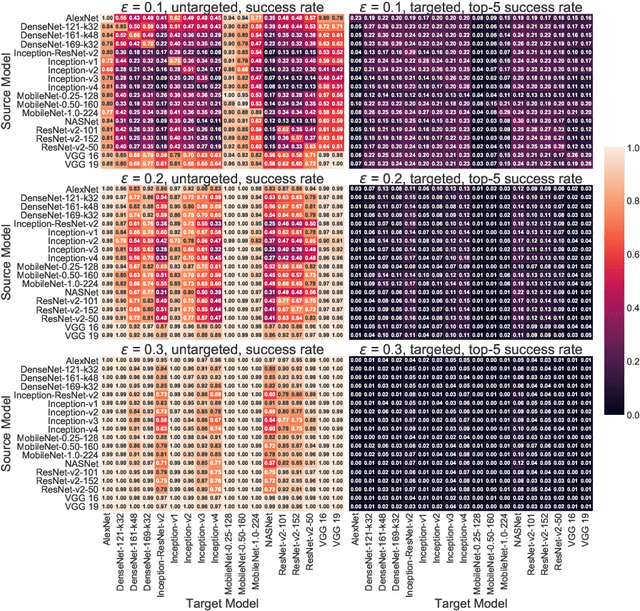
The prediction accuracy has been the long-lasting and sole standard for comparing the performance of different image classification models, including the ImageNet competition. However, recent studies have highlighted the lack of robustness in well-trained deep neural networks to adversarial examples. Visually imperceptible perturbations to natural images can easily be crafted and mislead the image classifiers towards misclassification. To demystify the trade-offs between robustness and accuracy, in this paper we thoroughly benchmark 18 ImageNet models using multiple robustness metrics, including the distortion, success rate and transferability of adversarial examples between 306 pairs of models. Our extensive experimental results reveal several new insights: (1) linear scaling law - the empirical $\ell_2$ and $\ell_\infty$ distortion metrics scale linearly with the logarithm of classification error; (2) model architecture is a more critical factor to robustness than model size, and the disclosed accuracy-robustness Pareto frontier can be used as an evaluation criterion for ImageNet model designers; (3) for a similar network architecture, increasing network depth slightly improves robustness in $\ell_\infty$ distortion; (4) there exist models (in VGG family) that exhibit high adversarial transferability, while most adversarial examples crafted from one model can only be transferred within the same family. Experiment code is publicly available at \url{https://github.com/huanzhang12/Adversarial_Survey}.
V-variable image compression
Nov 28, 2014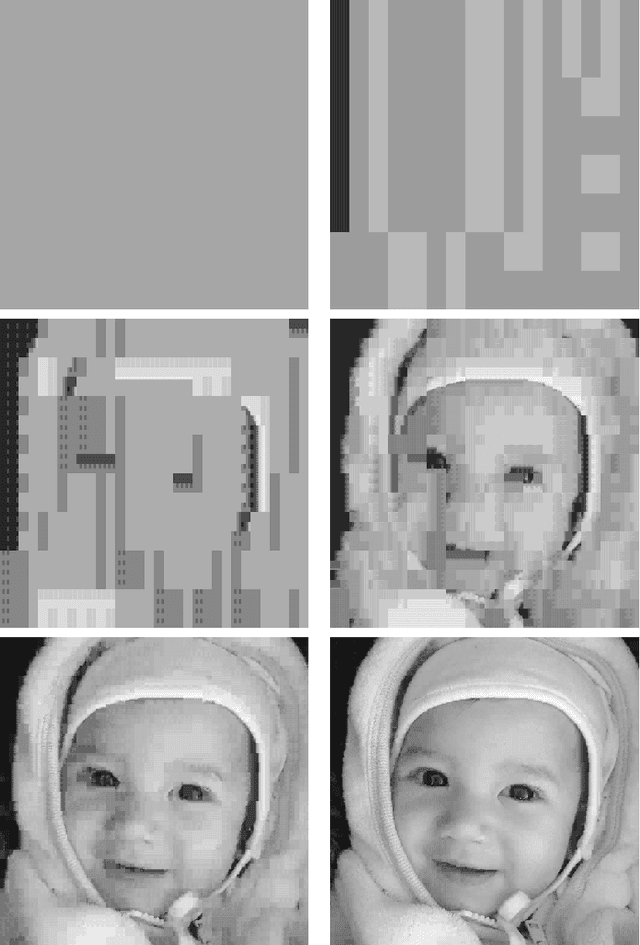
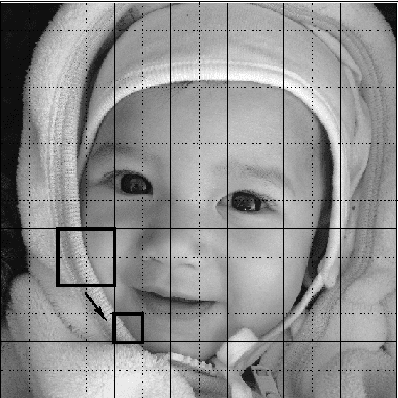


V-variable fractals, where $V$ is a positive integer, are intuitively fractals with at most $V$ different "forms" or "shapes" at all levels of magnification. In this paper we describe how V-variable fractals can be used for the purpose of image compression.
* 15 pages, 22 figures
CT-CAPS: Feature Extraction-based Automated Framework for COVID-19 Disease Identification from Chest CT Scans using Capsule Networks
Oct 30, 2020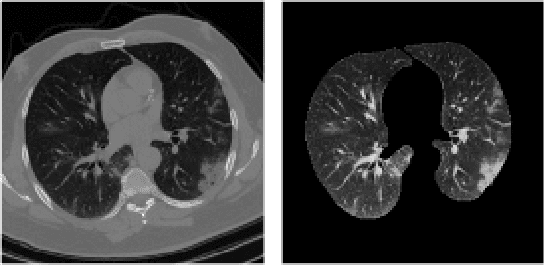
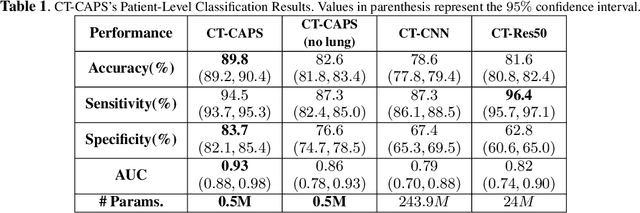

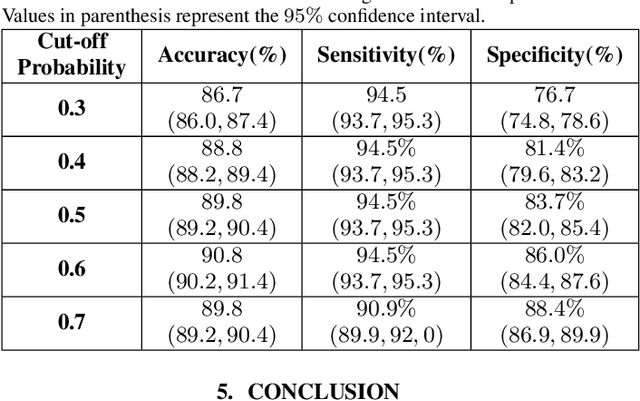
The global outbreak of the novel corona virus (COVID-19) disease has drastically impacted the world and led to one of the most challenging crisis across the globe since World War II. The early diagnosis and isolation of COVID-19 positive cases are considered as crucial steps towards preventing the spread of the disease and flattening the epidemic curve. Chest Computed Tomography (CT) scan is a highly sensitive, rapid, and accurate diagnostic technique that can complement Reverse Transcription Polymerase Chain Reaction (RT-PCR) test. Recently, deep learning-based models, mostly based on Convolutional Neural Networks (CNN), have shown promising diagnostic results. CNNs, however, are incapable of capturing spatial relations between image instances and require large datasets. Capsule Networks, on the other hand, can capture spatial relations, require smaller datasets, and have considerably fewer parameters. In this paper, a Capsule network framework, referred to as the "CT-CAPS", is presented to automatically extract distinctive features of chest CT scans. These features, which are extracted from the layer before the final capsule layer, are then leveraged to differentiate COVID-19 from Non-COVID cases. The experiments on our in-house dataset of 307 patients show the state-of-the-art performance with the accuracy of 90.8%, sensitivity of 94.5%, and specificity of 86.0%.
Deep DIH : Statistically Inferred Reconstruction of Digital In-Line Holography by Deep Learning
Apr 25, 2020
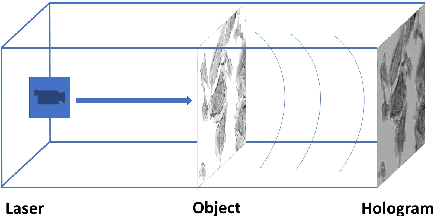
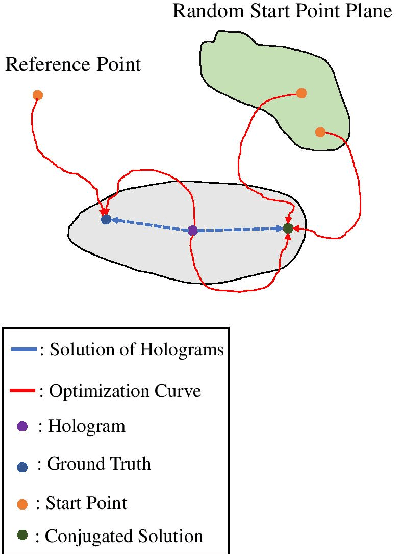
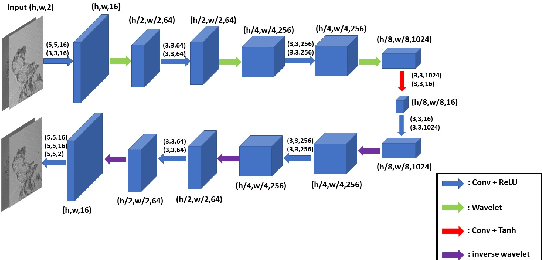
Digital in-line holography is commonly used to reconstruct 3D images from 2D holograms for microscopic objects. One of the technical challenges that arise in the signal processing stage is removing the twin image that is caused by the phase-conjugate wavefront from the recorded holograms. Twin image removal is typically formulated as a non-linear inverse problem due to the irreversible scattering process when generating the hologram. Recently, end-to-end deep learning-based methods have been utilized to reconstruct the object wavefront (as a surrogate for the 3D structure of the object) directly from a single-shot in-line digital hologram. However, massive data pairs are required to train deep learning models for acceptable reconstruction precision. In contrast to typical image processing problems, well-curated datasets for in-line digital holography does not exist. Also, the trained model highly influenced by the morphological properties of the object and hence can vary for different applications. Therefore, data collection can be prohibitively cumbersome in practice as a major hindrance to using deep learning for digital holography. In this paper, we proposed a novel implementation of autoencoder-based deep learning architecture for single-shot hologram reconstruction solely based on the current sample without the need for massive datasets to train the model. The simulations results demonstrate the superior performance of the proposed method compared to the state of the art single-shot compressive digital in-line hologram reconstruction method.
Information-Theoretic Visual Explanation for Black-Box Classifiers
Sep 23, 2020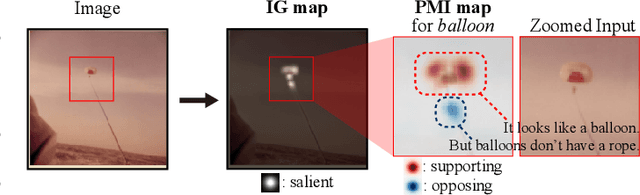
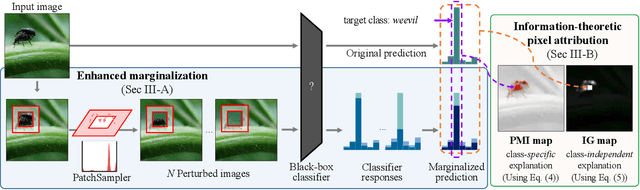
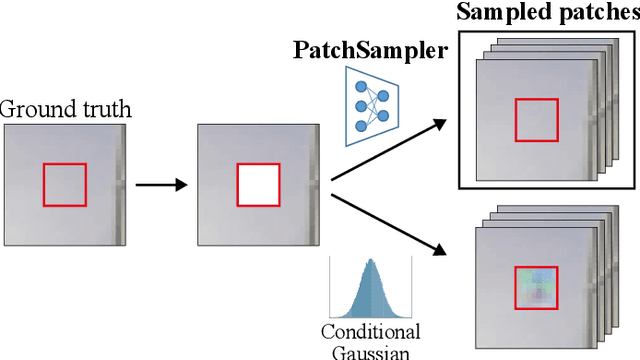
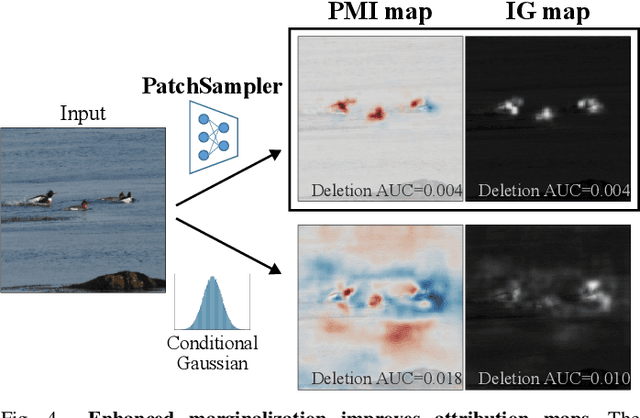
In this work, we attempt to explain the prediction of any black-box classifier from an information-theoretic perspective. For this purpose, we propose two attribution maps: an information gain (IG) map and a point-wise mutual information (PMI) map. IG map provides a class-independent answer to "How informative is each pixel?", and PMI map offers a class-specific explanation by answering "How much does each pixel support a specific class?" In this manner, we propose (i) a theory-backed attribution method. The attribution (ii) provides both supporting and opposing explanations for each class and (iii) pinpoints most decisive parts in the image, not just the relevant objects. In addition, the method (iv) offers a complementary class-independent explanation. Lastly, the algorithmic enhancement in our method (v) improves faithfulness of the explanation in terms of a quantitative evaluation metric. We showed the five strengths of our method through various experiments on the ImageNet dataset. The code of the proposed method is available online.
Data-Driven Color Augmentation Techniques for Deep Skin Image Analysis
Mar 10, 2017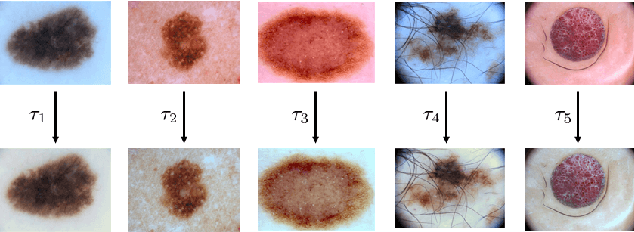

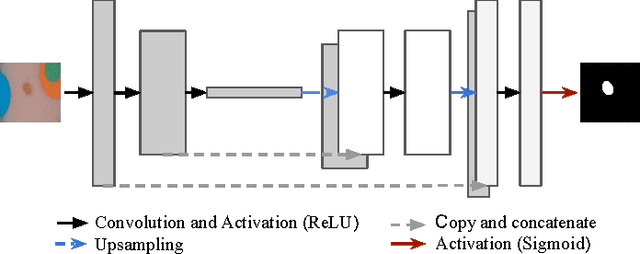
Dermoscopic skin images are often obtained with different imaging devices, under varying acquisition conditions. In this work, instead of attempting to perform intensity and color normalization, we propose to leverage computational color constancy techniques to build an artificial data augmentation technique suitable for this kind of images. Specifically, we apply the \emph{shades of gray} color constancy technique to color-normalize the entire training set of images, while retaining the estimated illuminants. We then draw one sample from the distribution of training set illuminants and apply it on the normalized image. We employ this technique for training two deep convolutional neural networks for the tasks of skin lesion segmentation and skin lesion classification, in the context of the ISIC 2017 challenge and without using any external dermatologic image set. Our results on the validation set are promising, and will be supplemented with extended results on the hidden test set when available.
NCP-VAE: Variational Autoencoders with Noise Contrastive Priors
Oct 06, 2020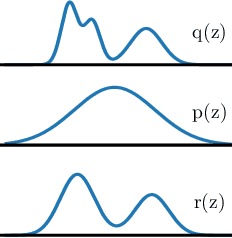
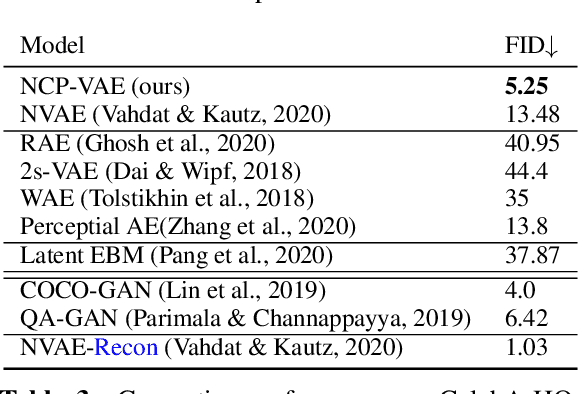
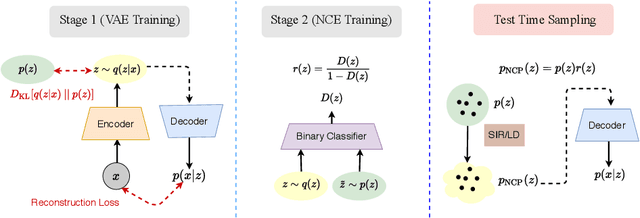

Variational autoencoders (VAEs) are one of the powerful likelihood-based generative models with applications in various domains. However, they struggle to generate high-quality images, especially when samples are obtained from the prior without any tempering. One explanation for VAEs' poor generative quality is the prior hole problem: the prior distribution fails to match the aggregate approximate posterior. Due to this mismatch, there exist areas in the latent space with high density under the prior that do not correspond to any encoded image. Samples from those areas are decoded to corrupted images. To tackle this issue, we propose an energy-based prior defined by the product of a base prior distribution and a reweighting factor, designed to bring the base closer to the aggregate posterior. We train the reweighting factor by noise contrastive estimation, and we generalize it to hierarchical VAEs with many latent variable groups. Our experiments confirm that the proposed noise contrastive priors improve the generative performance of state-of-the-art VAEs by a large margin on the MNIST, CIFAR-10, CelebA 64, and CelebA HQ 256 datasets.