 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Verifying the Causes of Adversarial Examples
Oct 19, 2020
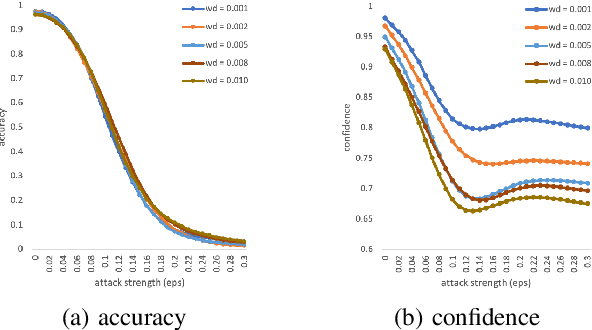
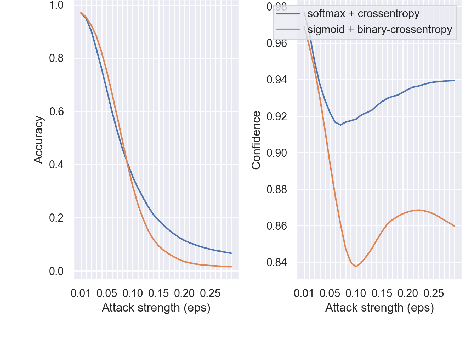
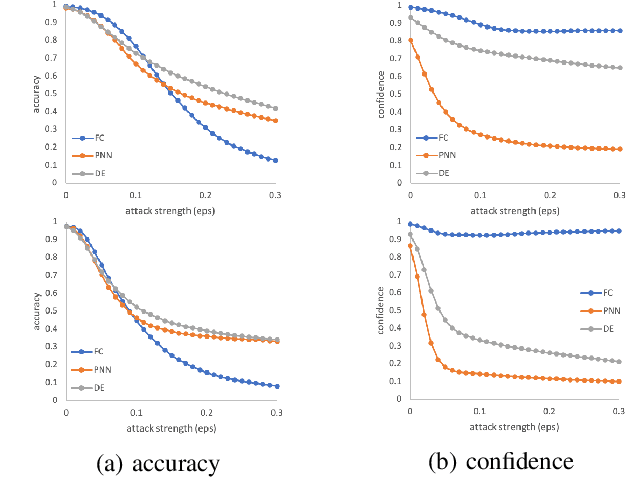
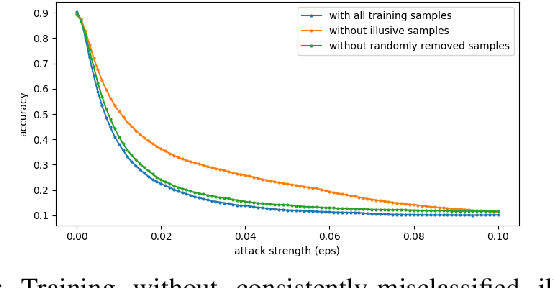
The robustness of neural networks is challenged by adversarial examples that contain almost imperceptible perturbations to inputs, which mislead a classifier to incorrect outputs in high confidence. Limited by the extreme difficulty in examining a high-dimensional image space thoroughly, research on explaining and justifying the causes of adversarial examples falls behind studies on attacks and defenses. In this paper, we present a collection of potential causes of adversarial examples and verify (or partially verify) them through carefully-designed controlled experiments. The major causes of adversarial examples include model linearity, one-sum constraint, and geometry of the categories. To control the effect of those causes, multiple techniques are applied such as $L_2$ normalization, replacement of loss functions, construction of reference datasets, and novel models using multi-layer perceptron probabilistic neural networks (MLP-PNN) and density estimation (DE). Our experiment results show that geometric factors tend to be more direct causes and statistical factors magnify the phenomenon, especially for assigning high prediction confidence. We believe this paper will inspire more studies to rigorously investigate the root causes of adversarial examples, which in turn provide useful guidance on designing more robust models.
Multi-task Supervised Learning via Cross-learning
Oct 30, 2020

In this paper we consider a problem known as multi-task learning, consisting of fitting a set of classifier or regression functions intended for solving different tasks. In our novel formulation, we couple the parameters of these functions, so that they learn in their task specific domains while staying close to each other. This facilitates cross-fertilization in which data collected across different domains help improving the learning performance at each other task. First, we present a simplified case in which the goal is to estimate the means of two Gaussian variables, for the purpose of gaining some insights on the advantage of the proposed cross-learning strategy. Then we provide a stochastic projected gradient algorithm to perform cross-learning over a generic loss function. If the number of parameters is large, then the projection step becomes computationally expensive. To avoid this situation, we derive a primal-dual algorithm that exploits the structure of the dual problem, achieving a formulation whose complexity only depends on the number of tasks. Preliminary numerical experiments for image classification by neural networks trained on a dataset divided in different domains corroborate that the cross-learned function outperforms both the task-specific and the consensus approaches.
Domain Generalized Person Re-Identification via Cross-Domain Episodic Learning
Oct 19, 2020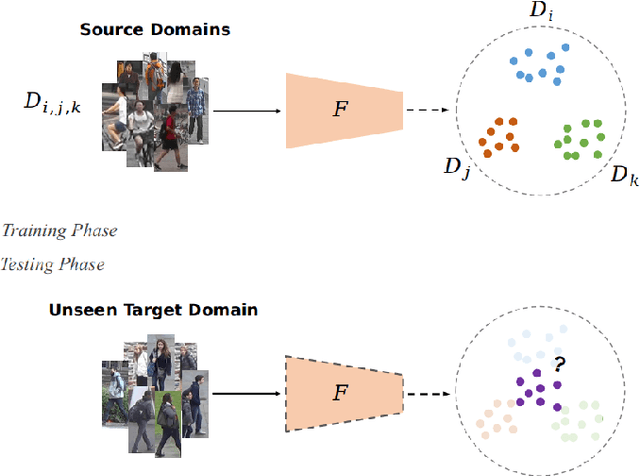
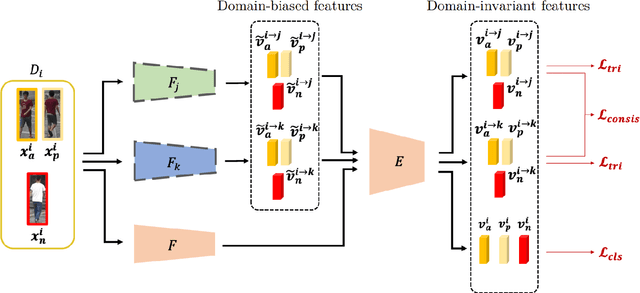
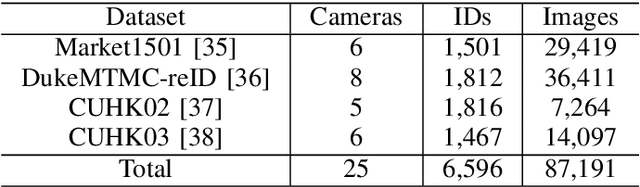

Aiming at recognizing images of the same person across distinct camera views, person re-identification (re-ID) has been among active research topics in computer vision. Most existing re-ID works require collection of a large amount of labeled image data from the scenes of interest. When the data to be recognized are different from the source-domain training ones, a number of domain adaptation approaches have been proposed. Nevertheless, one still needs to collect labeled or unlabelled target-domain data during training. In this paper, we tackle an even more challenging and practical setting, domain generalized (DG) person re-ID. That is, while a number of labeled source-domain datasets are available, we do not have access to any target-domain training data. In order to learn domain-invariant features without knowing the target domain of interest, we present an episodic learning scheme which advances meta learning strategies to exploit the observed source-domain labeled data. The learned features would exhibit sufficient domain-invariant properties while not overfitting the source-domain data or ID labels. Our experiments on four benchmark datasets confirm the superiority of our method over the state-of-the-arts.
A Versatile Crack Inspection Portable System based on Classifier Ensemble and Controlled Illumination
Oct 19, 2020
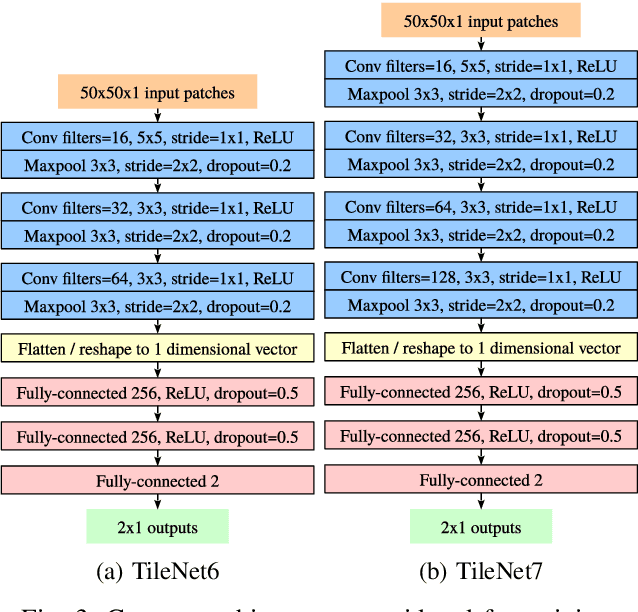

This paper presents a novel setup for automatic visual inspection of cracks in ceramic tile as well as studies the effect of various classifiers and height-varying illumination conditions for this task. The intuition behind this setup is that cracks can be better visualized under specific lighting conditions than others. Our setup, which is designed for field work with constraints in its maximum dimensions, can acquire images for crack detection with multiple lighting conditions using the illumination sources placed at multiple heights. Crack detection is then performed by classifying patches extracted from the acquired images in a sliding window fashion. We study the effect of lights placed at various heights by training classifiers both on customized as well as state-of-the-art architectures and evaluate their performance both at patch-level and image-level, demonstrating the effectiveness of our setup. More importantly, ours is the first study that demonstrates how height-varying illumination conditions can affect crack detection with the use of existing state-of-the-art classifiers. We provide an insight about the illumination conditions that can help in improving crack detection in a challenging real-world industrial environment.
Over a Decade of Social Opinion Mining
Dec 05, 2020
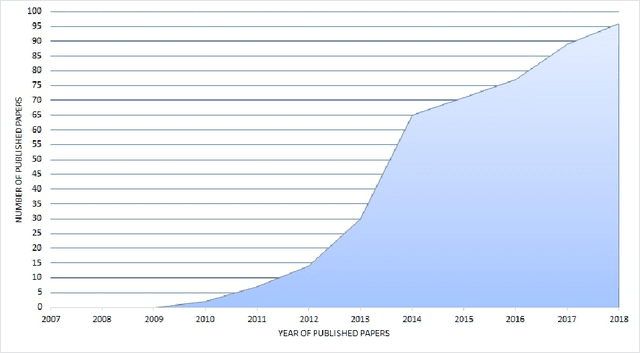
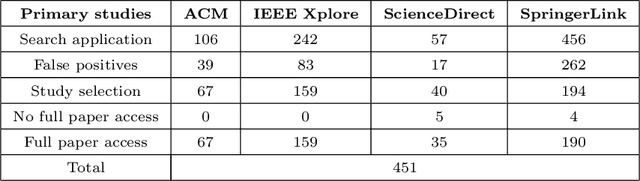
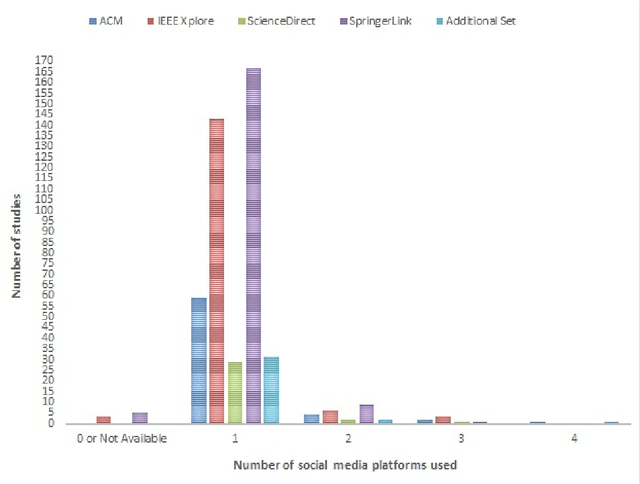
Social media popularity and importance is on the increase, due to people using it for various types of social interaction across multiple channels. This social interaction by online users includes submission of feedback, opinions and recommendations about various individuals, entities, topics, and events. This systematic review focuses on the evolving research area of Social Opinion Mining, tasked with the identification of multiple opinion dimensions, such as subjectivity, sentiment polarity, emotion, affect, sarcasm and irony, from user-generated content represented across multiple social media platforms and in various media formats, like text, image, video and audio. Therefore, through Social Opinion Mining, natural language can be understood in terms of the different opinion dimensions, as expressed by humans. This contributes towards the evolution of Artificial Intelligence, which in turn helps the advancement of several real-world use cases, such as customer service and decision making. A thorough systematic review was carried out on Social Opinion Mining research which totals 485 studies and spans a period of twelve years between 2007 and 2018. The in-depth analysis focuses on the social media platforms, techniques, social datasets, language, modality, tools and technologies, natural language processing tasks and other aspects derived from the published studies. Such multi-source information fusion plays a fundamental role in mining of people's social opinions from social media platforms. These can be utilised in many application areas, ranging from marketing, advertising and sales for product/service management, and in multiple domains and industries, such as politics, technology, finance, healthcare, sports and government. Future research directions are presented, whereas further research and development has the potential of leaving a wider academic and societal impact.
Improving correlation method with convolutional neural networks
Apr 20, 2020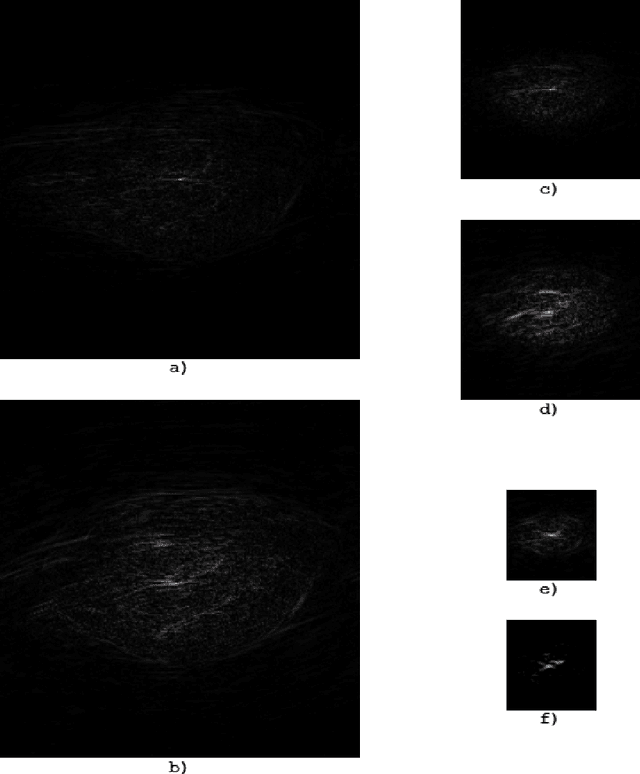
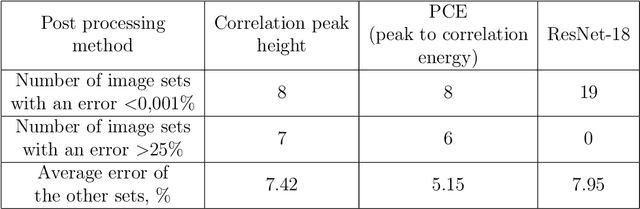

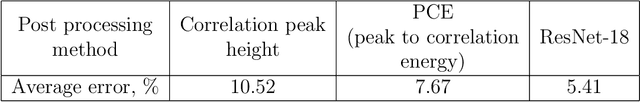
We present a convolutional neural network for the classification of correlation responses obtained by correlation filters. The proposed approach can improve the accuracy of classification, as well as achieve invariance to the image classes and parameters.
An Algorithm to Attack Neural Network Encoder-based Out-Of-Distribution Sample Detector
Sep 17, 2020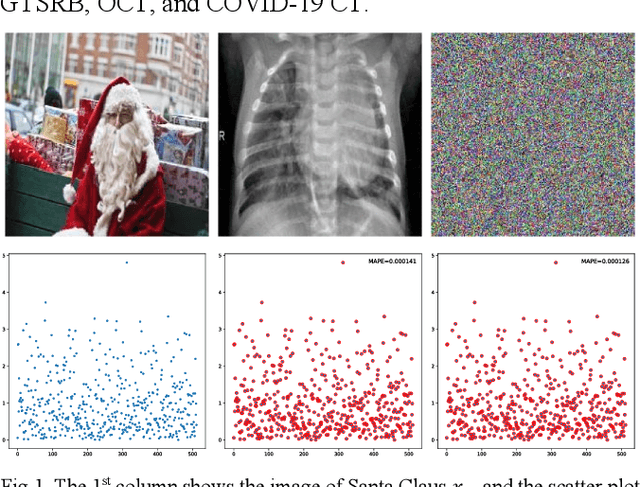
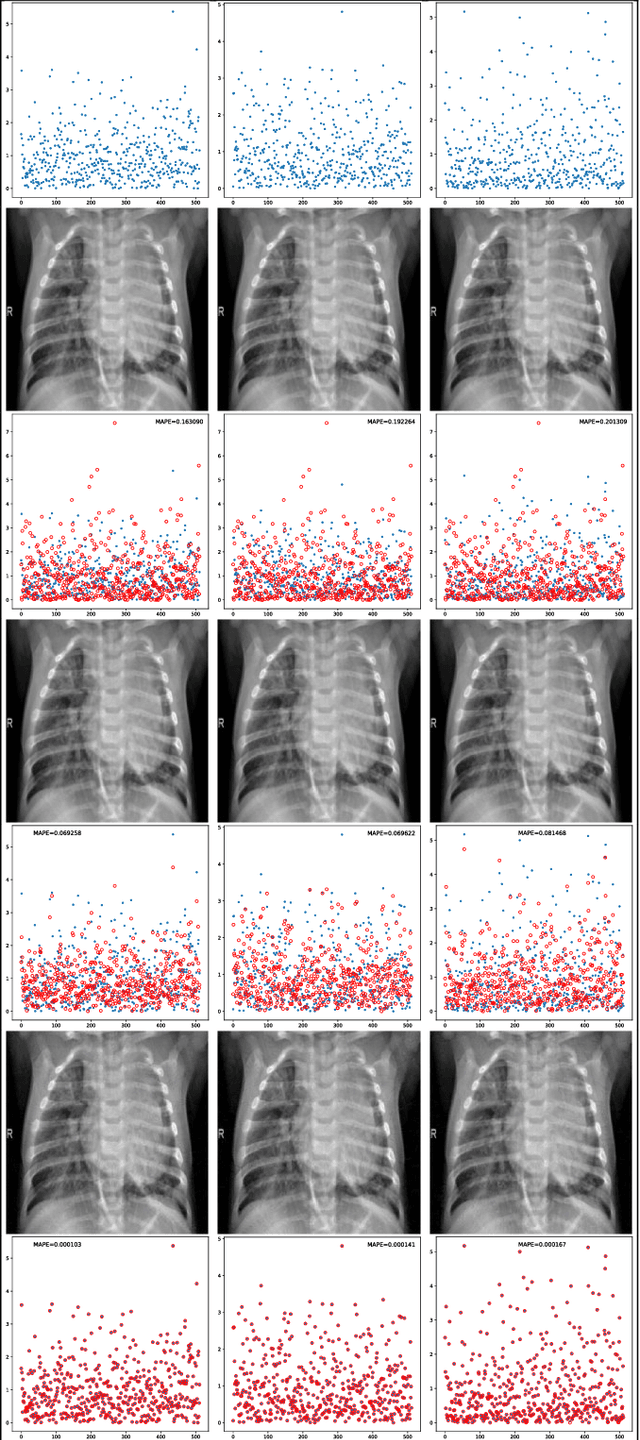
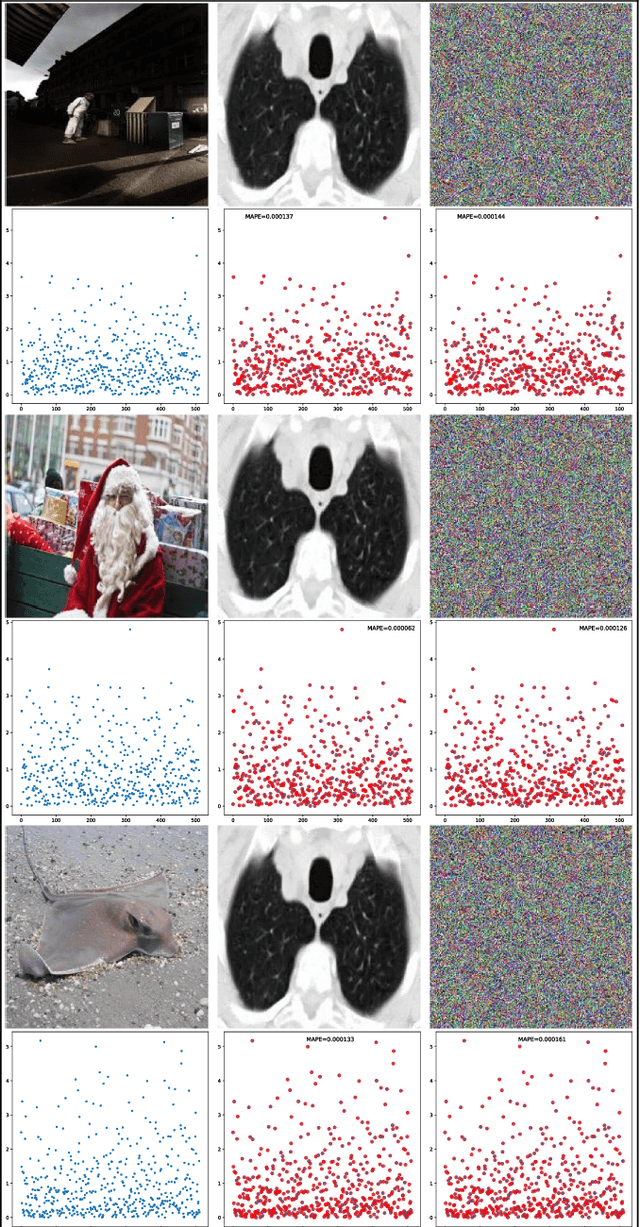
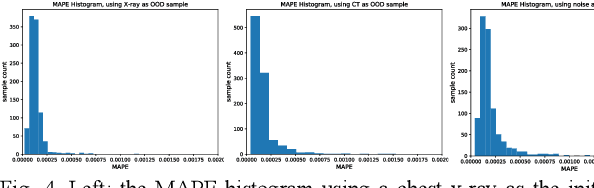
Deep neural network (DNN), especially convolutional neural network, has achieved superior performance on image classification tasks. However, such performance is only guaranteed if the input to a trained model is similar to the training samples, i.e., the input follows the probability distribution of the training set. Out-Of-Distribution (OOD) samples do not follow the distribution of training set, and therefore the predicted class labels on OOD samples become meaningless. Classification-based methods have been proposed for OOD detection; however, in this study we show that this type of method is theoretically ineffective and practically breakable because of dimensionality reduction in the model. We also show that Glow likelihood-based OOD detection is ineffective as well. Our analysis is demonstrated on five open datasets, including a COVID-19 CT dataset. At last, we present a simple theoretical solution with guaranteed performance for OOD detection.
GASNet: Weakly-supervised Framework for COVID-19 Lesion Segmentation
Oct 19, 2020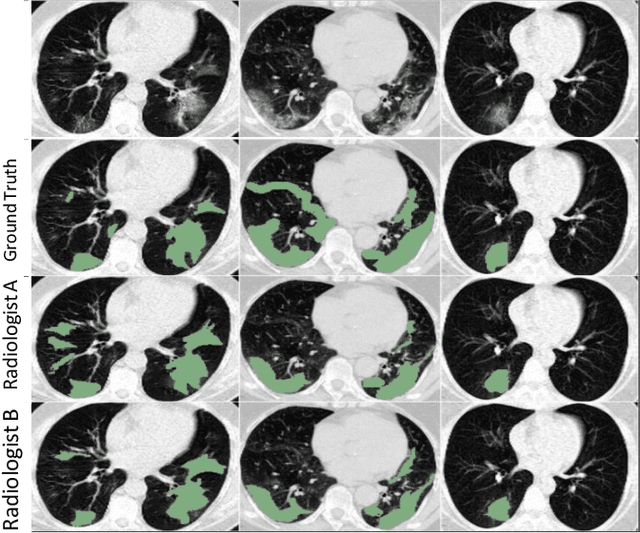
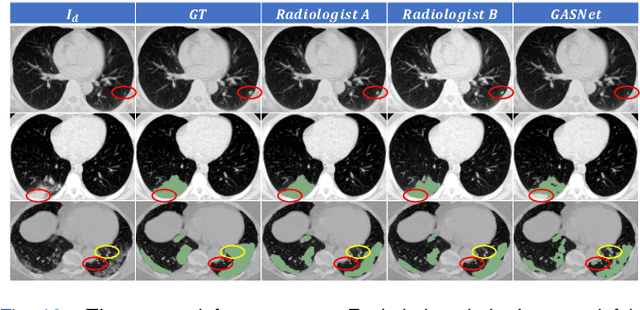
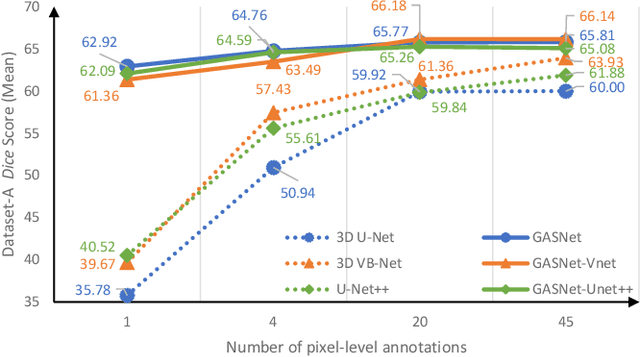
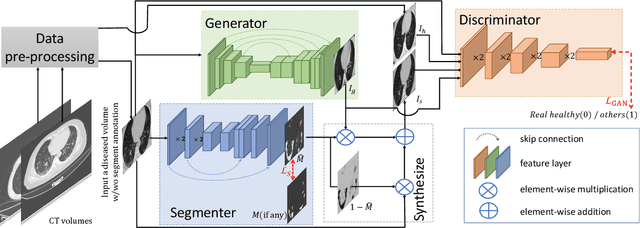
Segmentation of infected areas in chest CT volumes is of great significance for further diagnosis and treatment of COVID-19 patients. Due to the complex shapes and varied appearances of lesions, a large number of voxel-level labeled samples are generally required to train a lesion segmentation network, which is a main bottleneck for developing deep learning based medical image segmentation algorithms. In this paper, we propose a weakly-supervised lesion segmentation framework by embedding the Generative Adversarial training process into the Segmentation Network, which is called GASNet. GASNet is optimized to segment the lesion areas of a COVID-19 CT by the segmenter, and to replace the abnormal appearance with a generated normal appearance by the generator, so that the restored CT volumes are indistinguishable from healthy CT volumes by the discriminator. GASNet is supervised by chest CT volumes of many healthy and COVID-19 subjects without voxel-level annotations. Experiments on three public databases show that when using as few as one voxel-level labeled sample, the performance of GASNet is comparable to fully-supervised segmentation algorithms trained on dozens of voxel-level labeled samples.
Keeping Up Appearances: Computational Modeling of Face Acts in Persuasion Oriented Discussions
Sep 24, 2020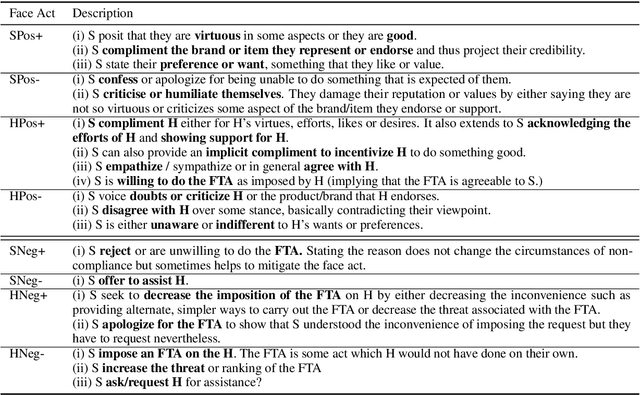
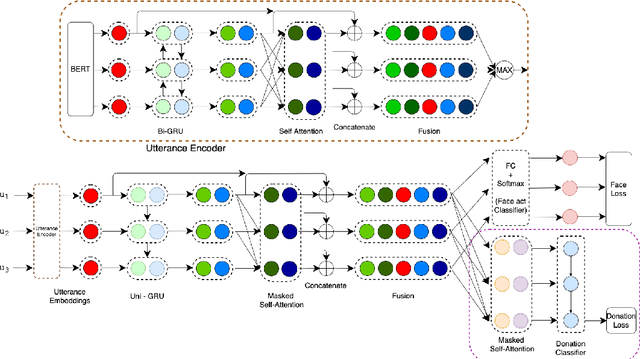
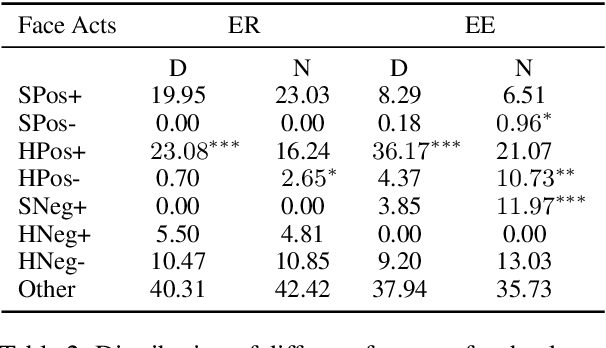
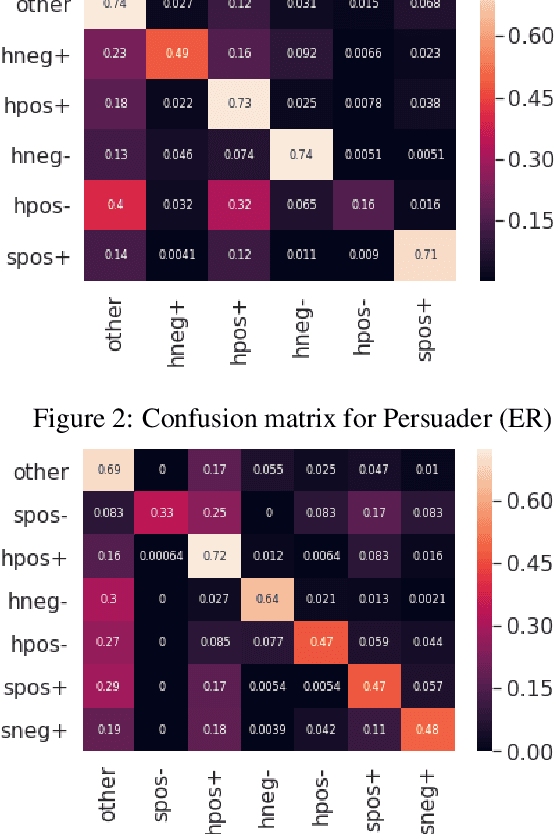
The notion of face refers to the public self-image of an individual that emerges both from the individual's own actions as well as from the interaction with others. Modeling face and understanding its state changes throughout a conversation is critical to the study of maintenance of basic human needs in and through interaction. Grounded in the politeness theory of Brown and Levinson (1978), we propose a generalized framework for modeling face acts in persuasion conversations, resulting in a reliable coding manual, an annotated corpus, and computational models. The framework reveals insights about differences in face act utilization between asymmetric roles in persuasion conversations. Using computational models, we are able to successfully identify face acts as well as predict a key conversational outcome (e.g. donation success). Finally, we model a latent representation of the conversational state to analyze the impact of predicted face acts on the probability of a positive conversational outcome and observe several correlations that corroborate previous findings.
V-variable image compression
Nov 28, 2014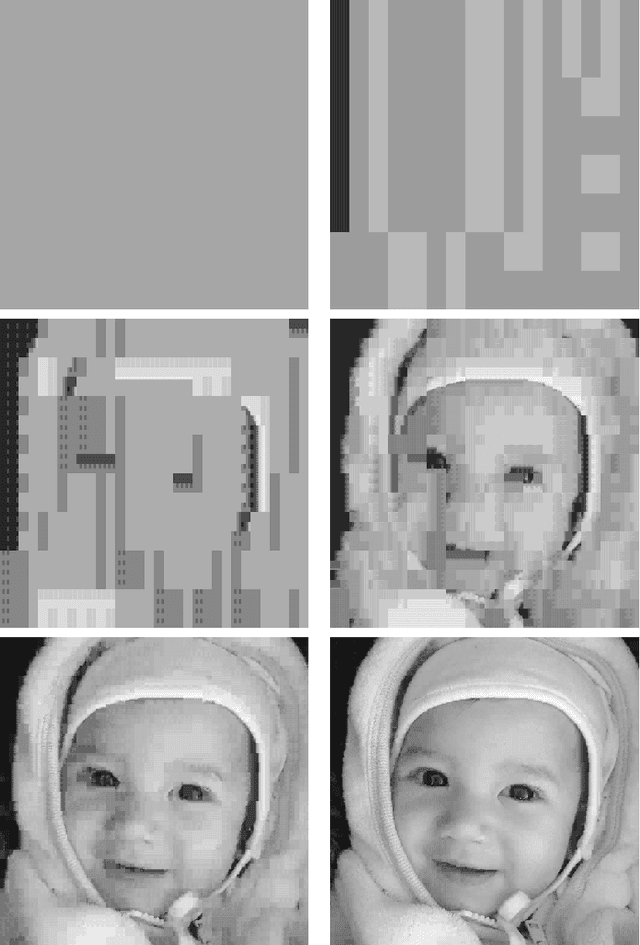
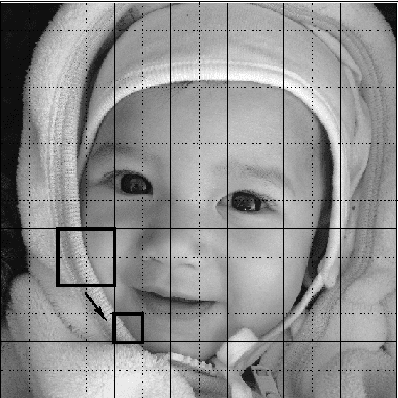


V-variable fractals, where $V$ is a positive integer, are intuitively fractals with at most $V$ different "forms" or "shapes" at all levels of magnification. In this paper we describe how V-variable fractals can be used for the purpose of image compression.
* 15 pages, 22 figures