 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Block-matching in FPGA
Jun 24, 2020

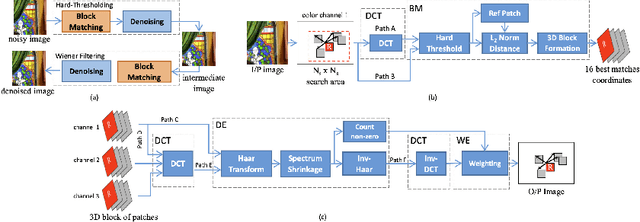
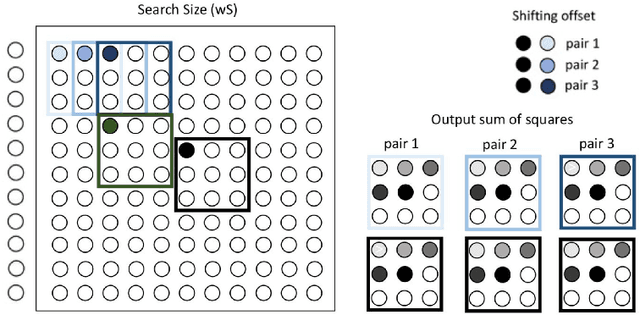
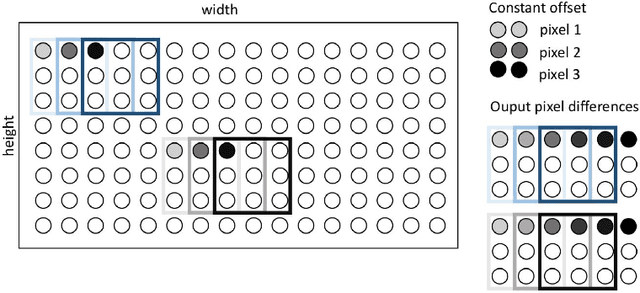
Block-matching and 3D filtering (BM3D) is an image denoising algorithm that works in two similar steps. Both of these steps need to perform grouping by block-matching. We implement the block-matching in an FPGA, leveraging its ability to perform parallel computations. Our goal is to enable other researchers to use our solution in the future for real-time video denoising in video cameras that use FPGAs (such as the AXIOM Beta).
Feature Sensitive Label Fusion with Random Walker for Atlas-based Image Segmentation
Nov 09, 2017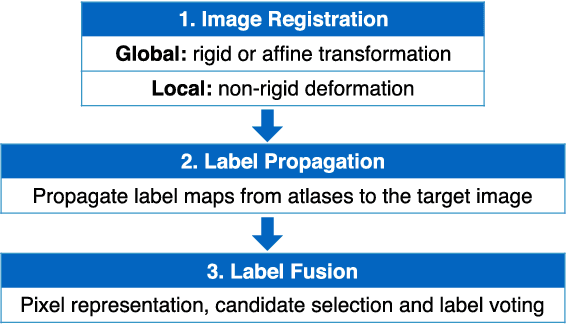
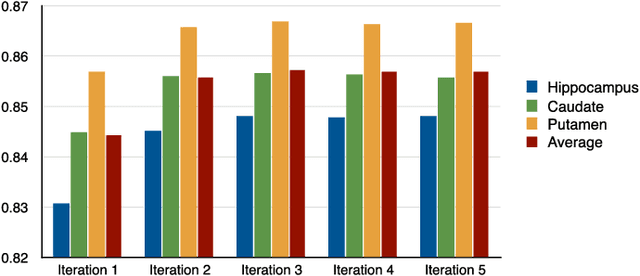
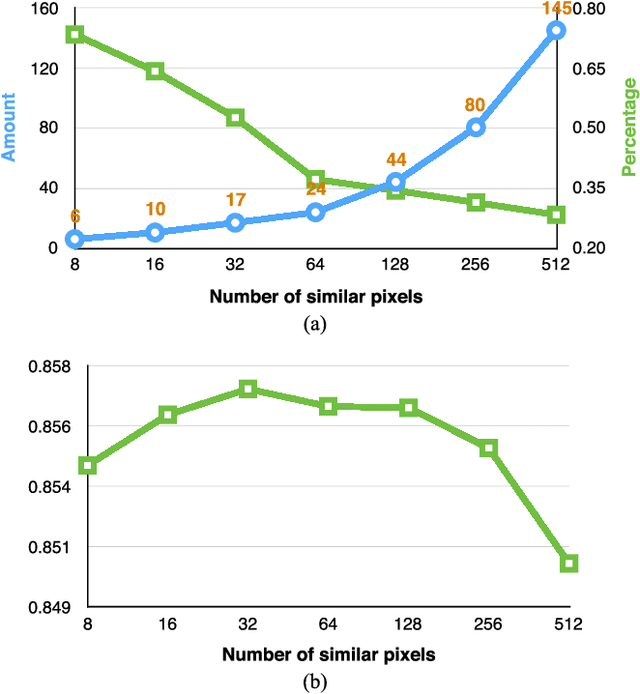
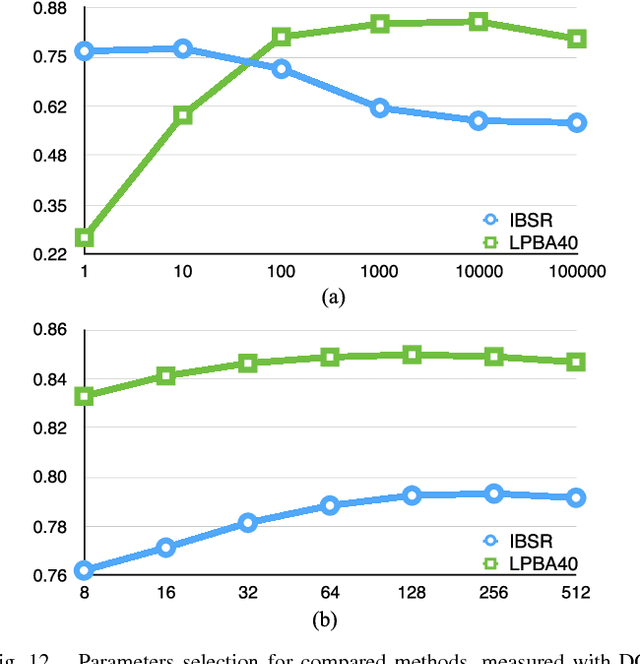
In this paper, a novel label fusion method is proposed for brain magnetic resonance image segmentation. This label fusion method is formulated on a graph, which embraces both label priors from atlases and anatomical priors from target image. To represent a pixel in a comprehensive way, three kinds of feature vectors are generated, including intensity, gradient and structural signature. To select candidate atlas nodes for fusion, rather than exact searching, randomized k-d tree with spatial constraint is introduced as an efficient approximation for high-dimensional feature matching. Feature Sensitive Label Prior (FSLP), which takes both the consistency and variety of different features into consideration, is proposed to gather atlas priors. As FSLP is a non-convex problem, one heuristic approach is further designed to solve it efficiently. Moreover, based on the anatomical knowledge, parts of the target pixels are also employed as graph seeds to assist the label fusion process and an iterative strategy is utilized to gradually update the label map. The comprehensive experiments carried out on two publicly available databases give results to demonstrate that the proposed method can obtain better segmentation quality.
Factoring Shape, Pose, and Layout from the 2D Image of a 3D Scene
Apr 24, 2018
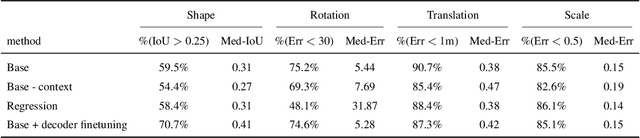
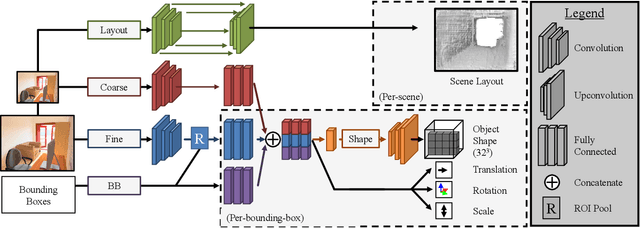

The goal of this paper is to take a single 2D image of a scene and recover the 3D structure in terms of a small set of factors: a layout representing the enclosing surfaces as well as a set of objects represented in terms of shape and pose. We propose a convolutional neural network-based approach to predict this representation and benchmark it on a large dataset of indoor scenes. Our experiments evaluate a number of practical design questions, demonstrate that we can infer this representation, and quantitatively and qualitatively demonstrate its merits compared to alternate representations.
Texture and Color-based Image Retrieval Using the Local Extrema Features and Riemannian Distance
Mar 03, 2017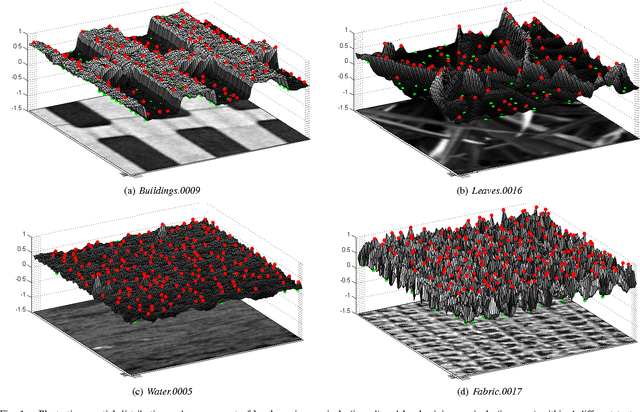
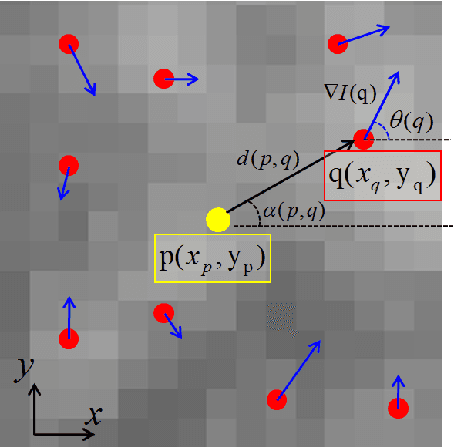
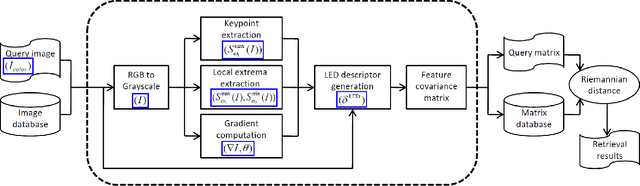

A novel efficient method for content-based image retrieval (CBIR) is developed in this paper using both texture and color features. Our motivation is to represent and characterize an input image by a set of local descriptors extracted at characteristic points (i.e. keypoints) within the image. Then, dissimilarity measure between images is calculated based on the geometric distance between the topological feature spaces (i.e. manifolds) formed by the sets of local descriptors generated from these images. In this work, we propose to extract and use the local extrema pixels as our feature points. Then, the so-called local extrema-based descriptor (LED) is generated for each keypoint by integrating all color, spatial as well as gradient information captured by a set of its nearest local extrema. Hence, each image is encoded by a LED feature point cloud and riemannian distances between these point clouds enable us to tackle CBIR. Experiments performed on Vistex, Stex and colored Brodatz texture databases using the proposed approach provide very efficient and competitive results compared to the state-of-the-art methods.
SteReFo: Efficient Image Refocusing with Stereo Vision
Sep 29, 2019



Whether to attract viewer attention to a particular object, give the impression of depth or simply reproduce human-like scene perception, shallow depth of field images are used extensively by professional and amateur photographers alike. To this end, high quality optical systems are used in DSLR cameras to focus on a specific depth plane while producing visually pleasing bokeh. We propose a physically motivated pipeline to mimic this effect from all-in-focus stereo images, typically retrieved by mobile cameras. It is capable to change the focal plane a posteriori at 76 FPS on KITTI images to enable real-time applications. As our portmanteau suggests, SteReFo interrelates stereo-based depth estimation and refocusing efficiently. In contrast to other approaches, our pipeline is simultaneously fully differentiable, physically motivated, and agnostic to scene content. It also enables computational video focus tracking for moving objects in addition to refocusing of static images. We evaluate our approach on the publicly available datasets SceneFlow, KITTI, CityScapes and quantify the quality of architectural changes.
WGANVO: Monocular Visual Odometry based on Generative Adversarial Networks
Jul 27, 2020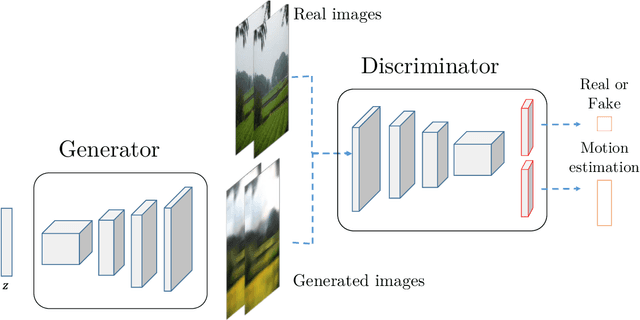
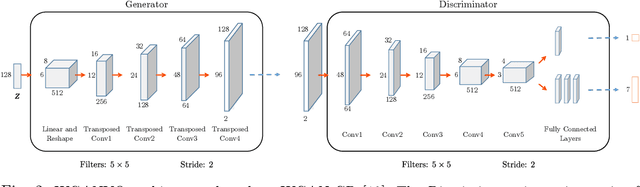

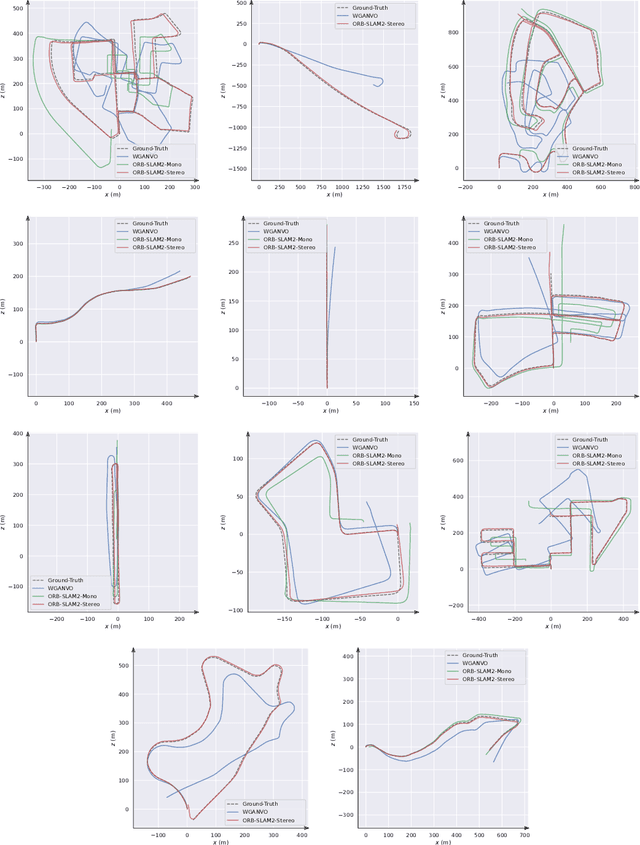
In this work we present WGANVO, a Deep Learning based monocular Visual Odometry method. In particular, a neural network is trained to regress a pose estimate from an image pair. The training is performed using a semi-supervised approach. Unlike geometry based monocular methods, the proposed method can recover the absolute scale of the scene without neither prior knowledge nor extra information. The evaluation of the system is carried out on the well-known KITTI dataset where it is shown to work in real time and the accuracy obtained is encouraging to continue the development of Deep Learning based methods.
Permute, Quantize, and Fine-tune: Efficient Compression of Neural Networks
Oct 29, 2020



Compressing large neural networks is an important step for their deployment in resource-constrained computational platforms. In this context, vector quantization is an appealing framework that expresses multiple parameters using a single code, and has recently achieved state-of-the-art network compression on a range of core vision and natural language processing tasks. Key to the success of vector quantization is deciding which parameter groups should be compressed together. Previous work has relied on heuristics that group the spatial dimension of individual convolutional filters, but a general solution remains unaddressed. This is desirable for pointwise convolutions (which dominate modern architectures), linear layers (which have no notion of spatial dimension), and convolutions (when more than one filter is compressed to the same codeword). In this paper we make the observation that the weights of two adjacent layers can be permuted while expressing the same function. We then establish a connection to rate-distortion theory and search for permutations that result in networks that are easier to compress. Finally, we rely on an annealed quantization algorithm to better compress the network and achieve higher final accuracy. We show results on image classification, object detection, and segmentation, reducing the gap with the uncompressed model by 40 to 70% with respect to the current state of the art.
Interpretable Survival Prediction for Colorectal Cancer using Deep Learning
Nov 17, 2020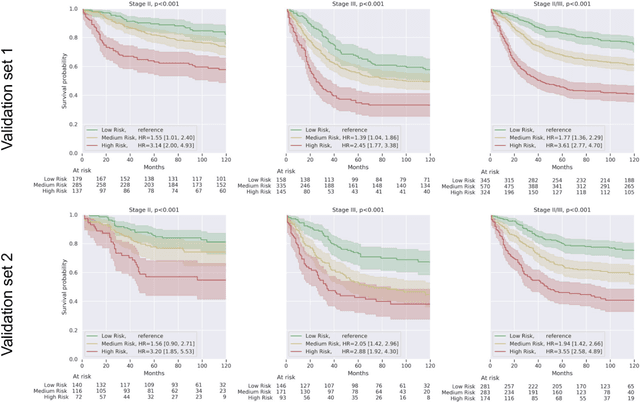
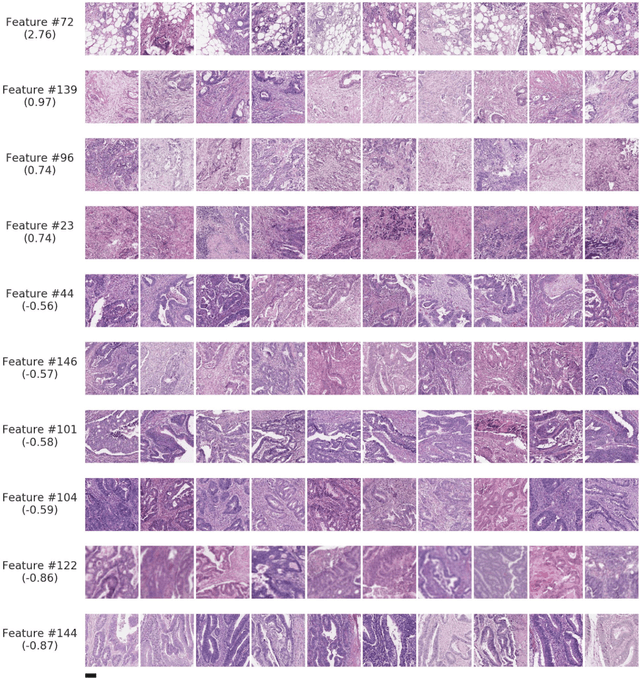
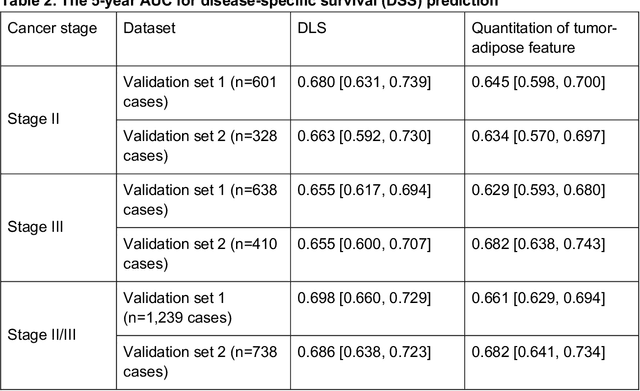
Deriving interpretable prognostic features from deep-learning-based prognostic histopathology models remains a challenge. In this study, we developed a deep learning system (DLS) for predicting disease specific survival for stage II and III colorectal cancer using 3,652 cases (27,300 slides). When evaluated on two validation datasets containing 1,239 cases (9,340 slides) and 738 cases (7,140 slides) respectively, the DLS achieved a 5-year disease-specific survival AUC of 0.70 (95%CI 0.66-0.73) and 0.69 (95%CI 0.64-0.72), and added significant predictive value to a set of 9 clinicopathologic features. To interpret the DLS, we explored the ability of different human-interpretable features to explain the variance in DLS scores. We observed that clinicopathologic features such as T-category, N-category, and grade explained a small fraction of the variance in DLS scores (R2=18% in both validation sets). Next, we generated human-interpretable histologic features by clustering embeddings from a deep-learning based image-similarity model and showed that they explain the majority of the variance (R2 of 73% to 80%). Furthermore, the clustering-derived feature most strongly associated with high DLS scores was also highly prognostic in isolation. With a distinct visual appearance (poorly differentiated tumor cell clusters adjacent to adipose tissue), this feature was identified by annotators with 87.0-95.5% accuracy. Our approach can be used to explain predictions from a prognostic deep learning model and uncover potentially-novel prognostic features that can be reliably identified by people for future validation studies.
3D-DEEP: 3-Dimensional Deep-learning based on elevation patterns forroad scene interpretation
Sep 01, 2020

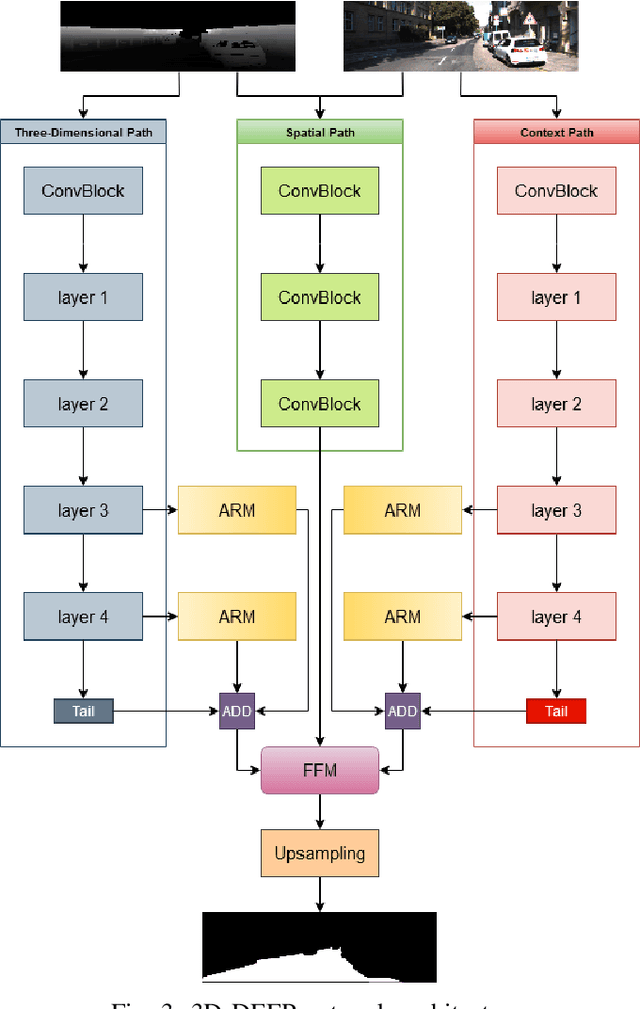
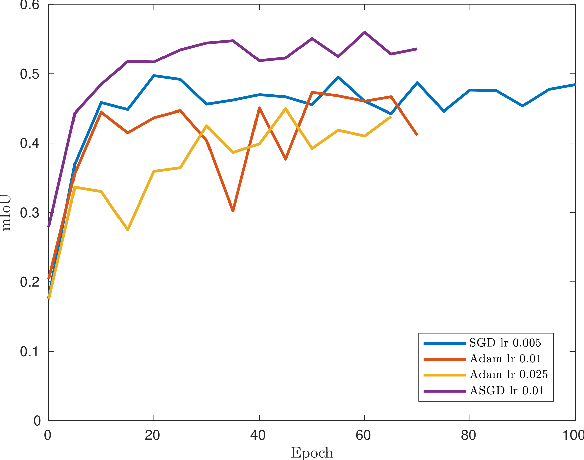
Road detection and segmentation is a crucial task in computer vision for safe autonomous driving. With this in mind, a new net architecture (3D-DEEP) and its end-to-end training methodology for CNN-based semantic segmentation are described along this paper for. The method relies on disparity filtered and LiDAR projected images for three-dimensional information and image feature extraction through fully convolutional networks architectures. The developed models were trained and validated over Cityscapes dataset using just fine annotation examples with 19 different training classes, and over KITTI road dataset. 72.32% mean intersection over union(mIoU) has been obtained for the 19 Cityscapes training classes using the validation images. On the other hand, over KITTIdataset the model has achieved an F1 error value of 97.85% invalidation and 96.02% using the test images.
NCP-VAE: Variational Autoencoders with Noise Contrastive Priors
Oct 06, 2020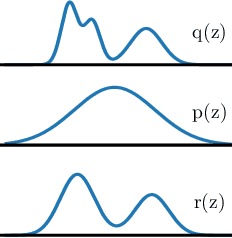
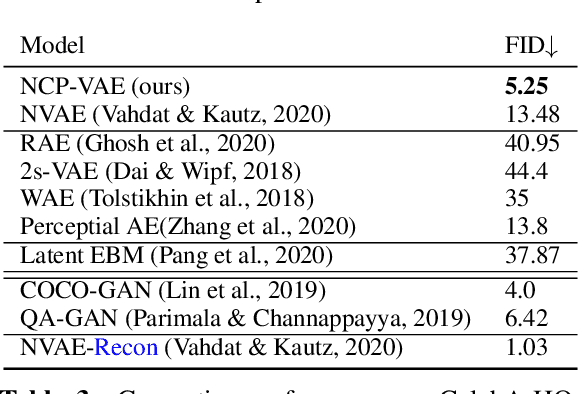
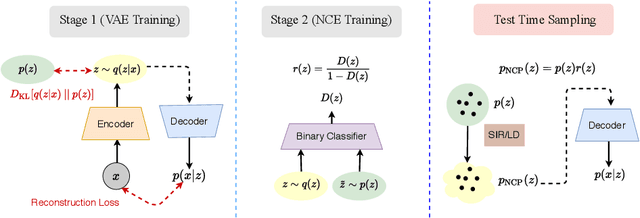

Variational autoencoders (VAEs) are one of the powerful likelihood-based generative models with applications in various domains. However, they struggle to generate high-quality images, especially when samples are obtained from the prior without any tempering. One explanation for VAEs' poor generative quality is the prior hole problem: the prior distribution fails to match the aggregate approximate posterior. Due to this mismatch, there exist areas in the latent space with high density under the prior that do not correspond to any encoded image. Samples from those areas are decoded to corrupted images. To tackle this issue, we propose an energy-based prior defined by the product of a base prior distribution and a reweighting factor, designed to bring the base closer to the aggregate posterior. We train the reweighting factor by noise contrastive estimation, and we generalize it to hierarchical VAEs with many latent variable groups. Our experiments confirm that the proposed noise contrastive priors improve the generative performance of state-of-the-art VAEs by a large margin on the MNIST, CIFAR-10, CelebA 64, and CelebA HQ 256 datasets.