 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Extreme Consistency: Overcoming Annotation Scarcity and Domain Shifts
Apr 15, 2020
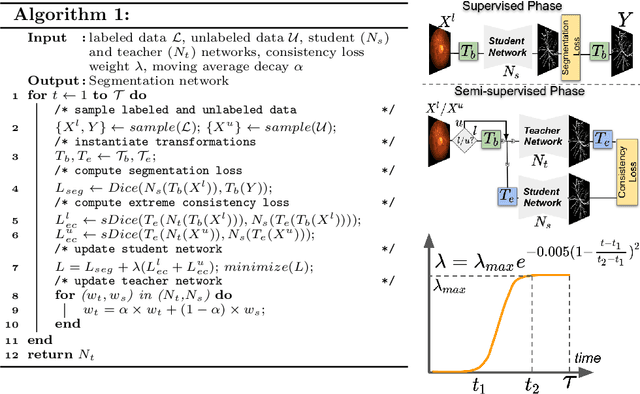
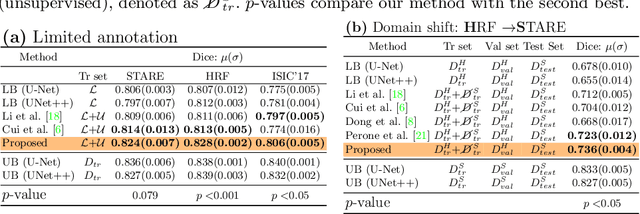
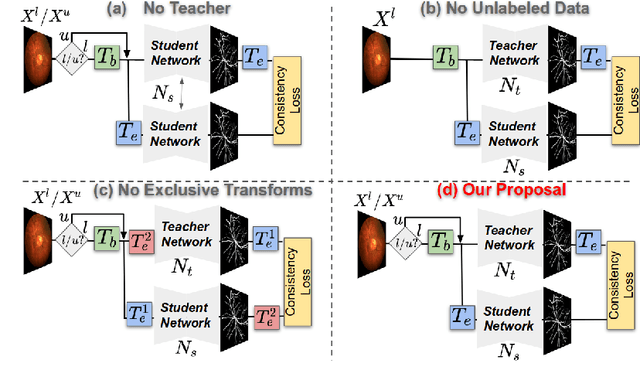
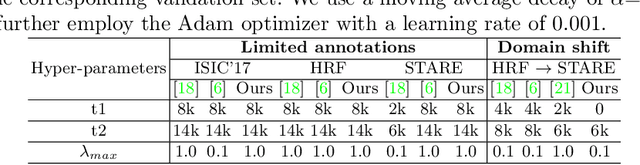
Supervised learning has proved effective for medical image analysis. However, it can utilize only the small labeled portion of data; it fails to leverage the large amounts of unlabeled data that is often available in medical image datasets. Supervised models are further handicapped by domain shifts, when the labeled dataset, despite being large enough, fails to cover different protocols or ethnicities. In this paper, we introduce \emph{extreme consistency}, which overcomes the above limitations, by maximally leveraging unlabeled data from the same or a different domain in a teacher-student semi-supervised paradigm. Extreme consistency is the process of sending an extreme transformation of a given image to the student network and then constraining its prediction to be consistent with the teacher network's prediction for the untransformed image. The extreme nature of our consistency loss distinguishes our method from related works that yield suboptimal performance by exercising only mild prediction consistency. Our method is 1) auto-didactic, as it requires no extra expert annotations; 2) versatile, as it handles both domain shift and limited annotation problems; 3) generic, as it is readily applicable to classification, segmentation, and detection tasks; and 4) simple to implement, as it requires no adversarial training. We evaluate our method for the tasks of lesion and retinal vessel segmentation in skin and fundus images. Our experiments demonstrate a significant performance gain over both modern supervised networks and recent semi-supervised models. This performance is attributed to the strong regularization enforced by extreme consistency, which enables the student network to learn how to handle extreme variants of both labeled and unlabeled images. This enhances the network's ability to tackle the inevitable same- and cross-domain data variability during inference.
Deep learning in the ultrasound evaluation of neonatal respiratory status
Oct 31, 2020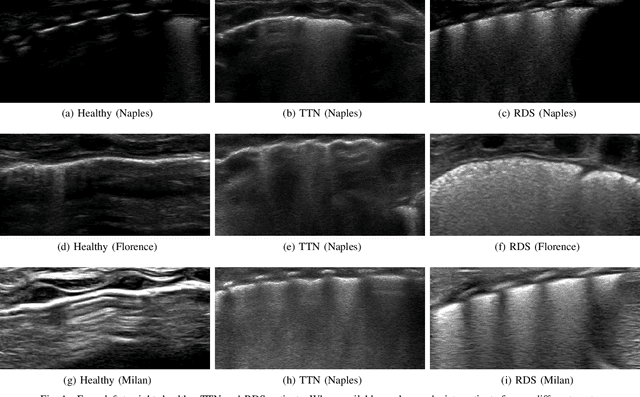
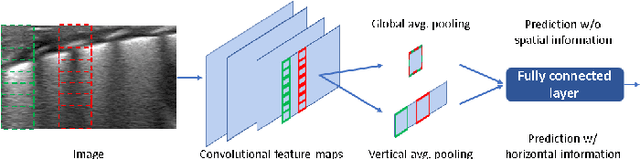
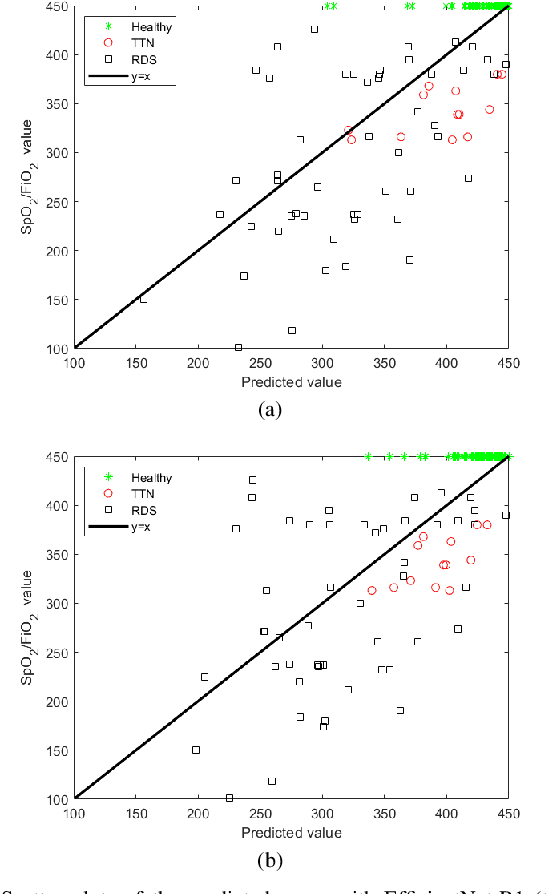
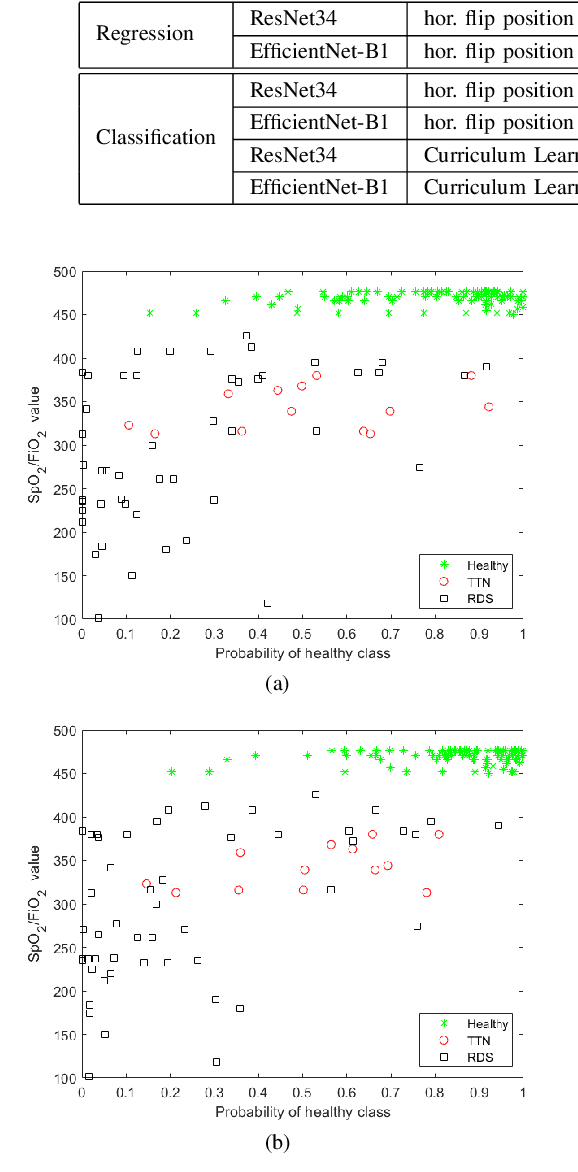
Lung ultrasound imaging is reaching growing interest from the scientific community. On one side, thanks to its harmlessness and high descriptive power, this kind of diagnostic imaging has been largely adopted in sensitive applications, like the diagnosis and follow-up of preterm newborns in neonatal intensive care units. On the other side, state-of-the-art image analysis and pattern recognition approaches have recently proven their ability to fully exploit the rich information contained in these data, making them attractive for the research community. In this work, we present a thorough analysis of recent deep learning networks and training strategies carried out on a vast and challenging multicenter dataset comprising 87 patients with different diseases and gestational ages. These approaches are employed to assess the lung respiratory status from ultrasound images and are evaluated against a reference marker. The conducted analysis sheds some light on this problem by showing the critical points that can mislead the training procedure and proposes some adaptations to the specific data and task. The achieved results sensibly outperform those obtained by a previous work, which is based on textural features, and narrow the gap with the visual score predicted by the human experts.
SAFENet: Self-Supervised Monocular Depth Estimation with Semantic-Aware Feature Extraction
Oct 06, 2020
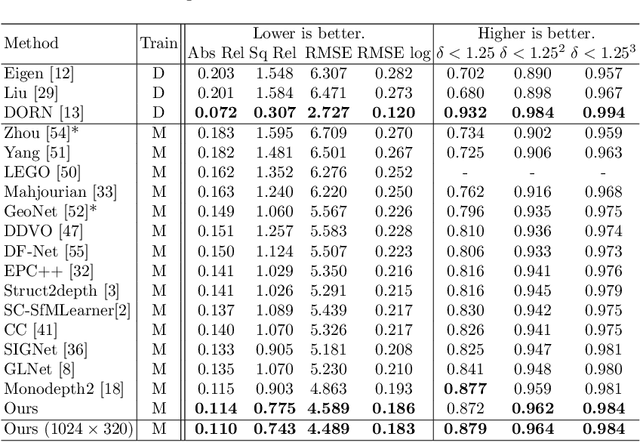
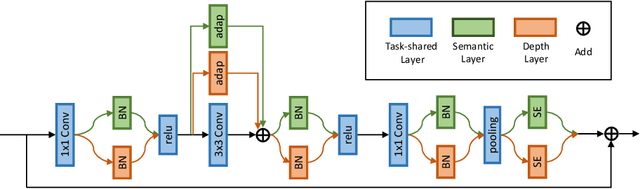
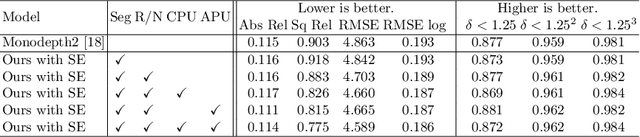
Self-supervised monocular depth estimation has emerged as a promising method because it does not require groundtruth depth maps during training. As an alternative for the groundtruth depth map, the photometric loss enables to provide self-supervision on depth prediction by matching the input image frames. However, the photometric loss causes various problems, resulting in less accurate depth values compared with supervised approaches. In this paper, we propose SAFENet that is designed to leverage semantic information to overcome the limitations of the photometric loss. Our key idea is to exploit semantic-aware depth features that integrate the semantic and geometric knowledge. Therefore, we introduce multi-task learning schemes to incorporate semantic-awareness into the representation of depth features. Experiments on KITTI dataset demonstrate that our methods compete or even outperform the state-of-the-art methods. Furthermore, extensive experiments on different datasets show its better generalization ability and robustness to various conditions, such as low-light or adverse weather.
Deep Lesion Tracker: Monitoring Lesions in 4D Longitudinal Imaging Studies
Dec 09, 2020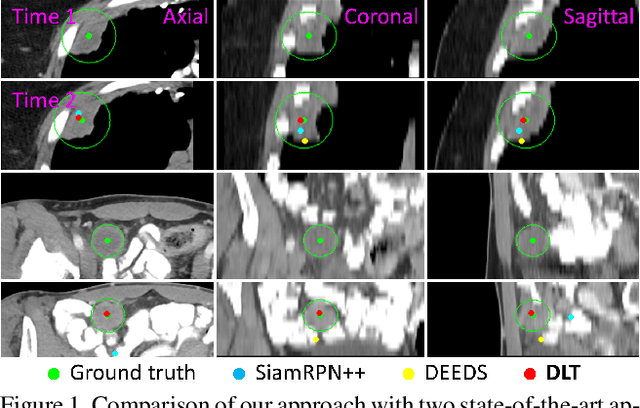
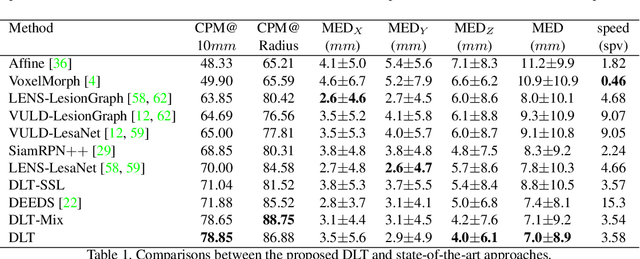
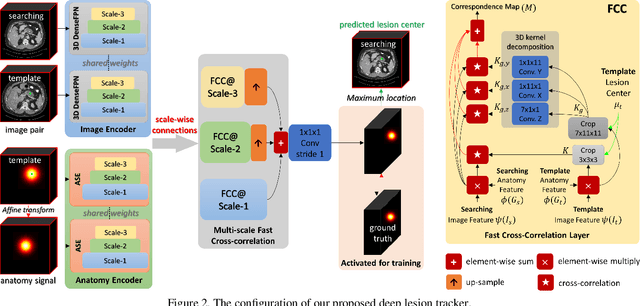
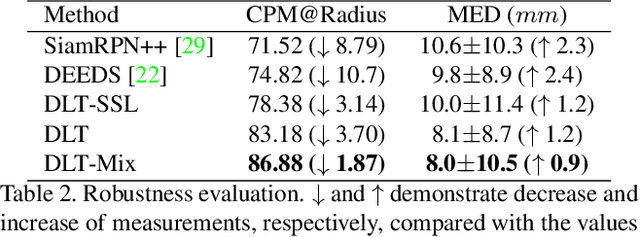
Monitoring treatment response in longitudinal studies plays an important role in clinical practice. Accurately identifying lesions across serial imaging follow-up is the core to the monitoring procedure. Typically this incorporates both image and anatomical considerations. However, matching lesions manually is labor-intensive and time-consuming. In this work, we present deep lesion tracker (DLT), a deep learning approach that uses both appearance- and anatomical-based signals. To incorporate anatomical constraints, we propose an anatomical signal encoder, which prevents lesions being matched with visually similar but spurious regions. In addition, we present a new formulation for Siamese networks that avoids the heavy computational loads of 3D cross-correlation. To present our network with greater varieties of images, we also propose a self-supervised learning (SSL) strategy to train trackers with unpaired images, overcoming barriers to data collection. To train and evaluate our tracker, we introduce and release the first lesion tracking benchmark, consisting of 3891 lesion pairs from the public DeepLesion database. The proposed method, DLT, locates lesion centers with a mean error distance of 7 mm. This is 5% better than a leading registration algorithm while running 14 times faster on whole CT volumes. We demonstrate even greater improvements over detector or similarity-learning alternatives. DLT also generalizes well on an external clinical test set of 100 longitudinal studies, achieving 88% accuracy. Finally, we plug DLT into an automatic tumor monitoring workflow where it leads to an accuracy of 85% in assessing lesion treatment responses, which is only 0.46% lower than the accuracy of manual inputs.
PseudoSeg: Designing Pseudo Labels for Semantic Segmentation
Oct 19, 2020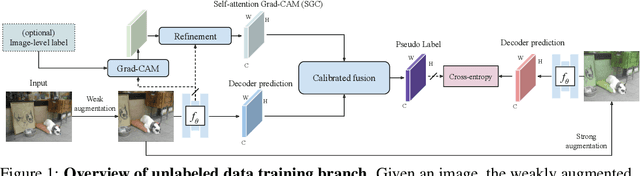
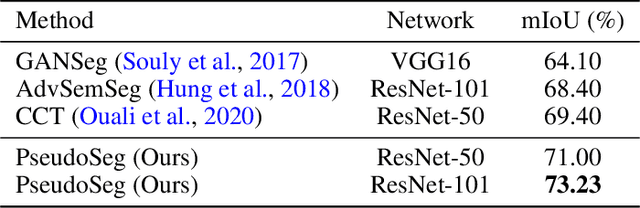

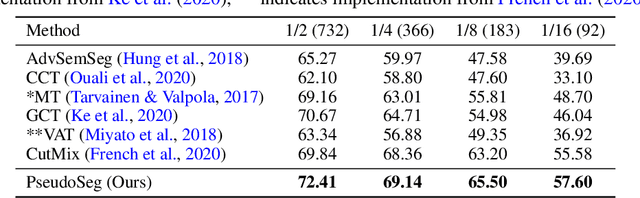
Recent advances in semi-supervised learning (SSL) demonstrate that a combination of consistency regularization and pseudo-labeling can effectively improve image classification accuracy in the low-data regime. Compared to classification, semantic segmentation tasks require much more intensive labeling costs. Thus, these tasks greatly benefit from data-efficient training methods. However, structured outputs in segmentation render particular difficulties (e.g., designing pseudo-labeling and augmentation) to apply existing SSL strategies. To address this problem, we present a simple and novel re-design of pseudo-labeling to generate well-calibrated structured pseudo labels for training with unlabeled or weakly-labeled data. Our proposed pseudo-labeling strategy is network structure agnostic to apply in a one-stage consistency training framework. We demonstrate the effectiveness of the proposed pseudo-labeling strategy in both low-data and high-data regimes. Extensive experiments have validated that pseudo labels generated from wisely fusing diverse sources and strong data augmentation are crucial to consistency training for segmentation. The source code is available at https://github.com/googleinterns/wss.
Monocular Depth Estimation via Listwise Ranking using the Plackett-Luce Model
Oct 31, 2020


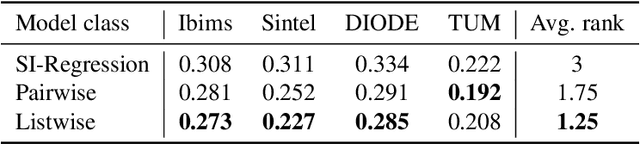
In many real-world applications, the relative depth of objects in an image is crucial for scene understanding, e.g., to calculate occlusions in augmented reality scenes. Predicting depth in monocular images has recently been tackled using machine learning methods, mainly by treating the problem as a regression task. Yet, being interested in an order relation in the first place, ranking methods suggest themselves as a natural alternative to regression, and indeed, ranking approaches leveraging pairwise comparisons as training information ("object A is closer to the camera than B") have shown promising performance on this problem. In this paper, we elaborate on the use of so-called listwise ranking as a generalization of the pairwise approach. Listwise ranking goes beyond pairwise comparisons between objects and considers rankings of arbitrary length as training information. Our approach is based on the Plackett-Luce model, a probability distribution on rankings, which we combine with a state-of-the-art neural network architecture and a sampling strategy to reduce training complexity. An empirical evaluation on benchmark data in a "zero-shot" setting demonstrates the effectiveness of our proposal compared to existing ranking and regression methods.
Generalizing Spatial Transformers to Projective Geometry with Applications to 2D/3D Registration
Mar 24, 2020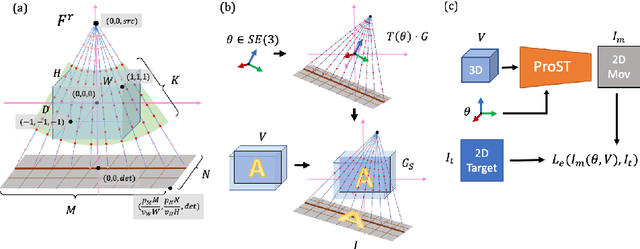
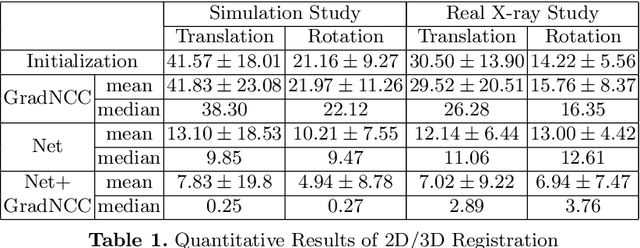
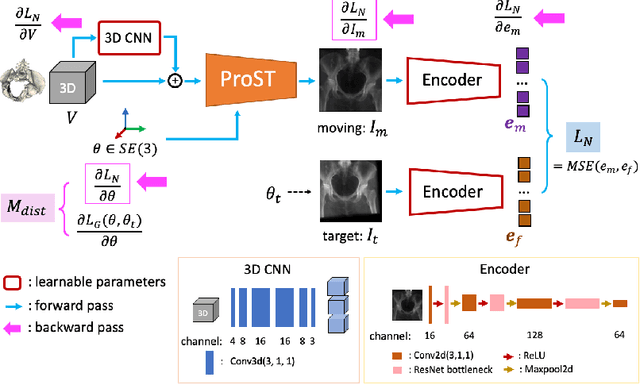
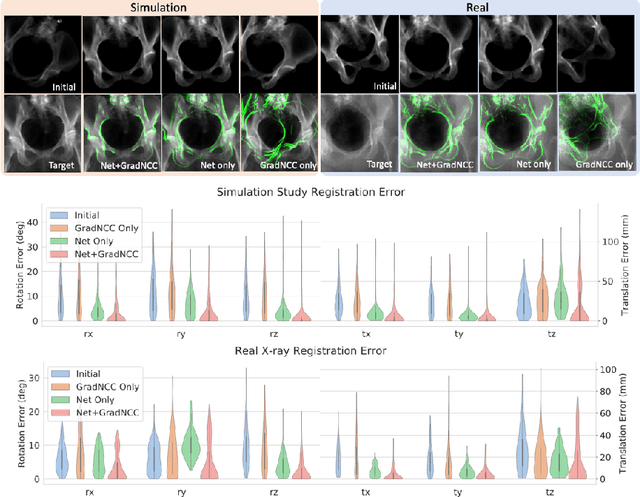
Differentiable rendering is a technique to connect 3D scenes with corresponding 2D images. Since it is differentiable, processes during image formation can be learned. Previous approaches to differentiable rendering focus on mesh-based representations of 3D scenes, which is inappropriate for medical applications where volumetric, voxelized models are used to represent anatomy. We propose a novel Projective Spatial Transformer module that generalizes spatial transformers to projective geometry, thus enabling differentiable volume rendering. We demonstrate the usefulness of this architecture on the example of 2D/3D registration between radiographs and CT scans. Specifically, we show that our transformer enables end-to-end learning of an image processing and projection model that approximates an image similarity function that is convex with respect to the pose parameters, and can thus be optimized effectively using conventional gradient descent. To the best of our knowledge, this is the first time that spatial transformers have been described for projective geometry. The source code will be made public upon publication of this manuscript and we hope that our developments will benefit related 3D research applications.
Adaptive Tag Selection for Image Annotation
Sep 17, 2014

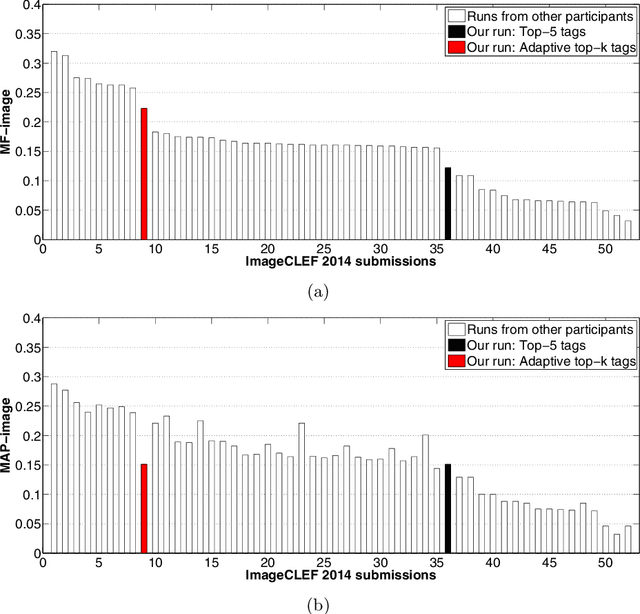

Not all tags are relevant to an image, and the number of relevant tags is image-dependent. Although many methods have been proposed for image auto-annotation, the question of how to determine the number of tags to be selected per image remains open. The main challenge is that for a large tag vocabulary, there is often a lack of ground truth data for acquiring optimal cutoff thresholds per tag. In contrast to previous works that pre-specify the number of tags to be selected, we propose in this paper adaptive tag selection. The key insight is to divide the vocabulary into two disjoint subsets, namely a seen set consisting of tags having ground truth available for optimizing their thresholds and a novel set consisting of tags without any ground truth. Such a division allows us to estimate how many tags shall be selected from the novel set according to the tags that have been selected from the seen set. The effectiveness of the proposed method is justified by our participation in the ImageCLEF 2014 image annotation task. On a set of 2,065 test images with ground truth available for 207 tags, the benchmark evaluation shows that compared to the popular top-$k$ strategy which obtains an F-score of 0.122, adaptive tag selection achieves a higher F-score of 0.223. Moreover, by treating the underlying image annotation system as a black box, the new method can be used as an easy plug-in to boost the performance of existing systems.
Comparative study of variational quantum circuit and quantum backpropagation multilayer perceptron for COVID-19 outbreak predictions
Aug 19, 2020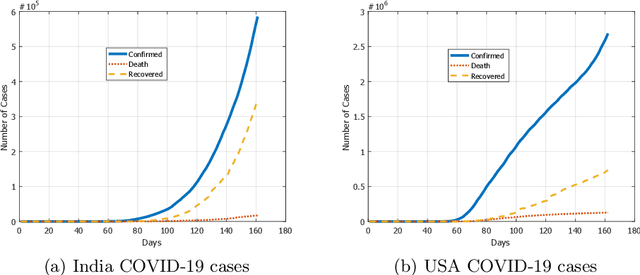

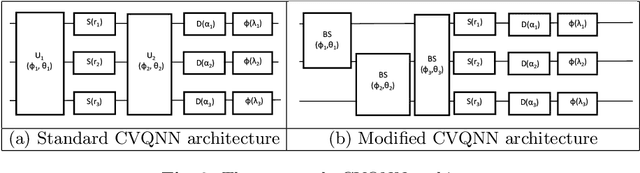
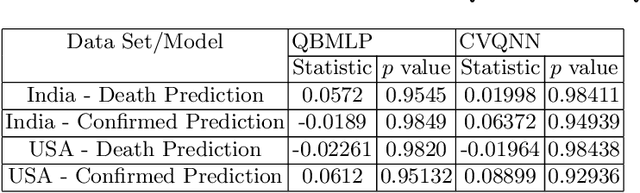
There are numerous models of quantum neural networks that have been applied to variegated problems such as image classification, pattern recognition etc.Quantum inspired algorithms have been relevant for quite awhile. More recently, in the NISQ era, hybrid quantum classical models have shown promising results. Multi-feature regression is common problem in classical machine learning. Hence we present a comparative analysis of continuous variable quantum neural networks (Variational circuits) and quantum backpropagating multi layer perceptron (QBMLP). We have chosen the contemporary problem of predicting rise in COVID-19 cases in India and USA. We provide a statistical comparison between two models , both of which perform better than the classical artificial neural networks.
Ground and Non-Ground Separation Filter for UAV Lidar Point Cloud
Nov 16, 2019

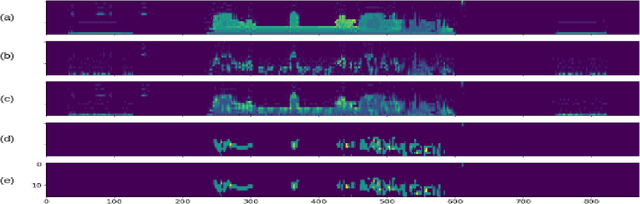
This paper proposes a novel approach for separating ground plane and non-ground objects on Lidar 3D point cloud as a filter. It is specially designed for real-time applications on unmanned aerial vehicles and works on sparse Lidar point clouds without preliminary mapping. We use this filter as a crucial component of fast obstacle avoidance system for agriculture drone operating at low altitude. As the first step, a point cloud is transformed into a depth image and then places with high density nearest to the vehicle (local maxima) are identified. Then we merge original depth image with identified locations after maximizing intensities of pixels in which local maxima were found. Next step is to calculate range angle image which represents angles between two consecutive laser beams based on improved depth image. Once a range angle image is constructed, smoothing is applied to reduce the noise. Finally, we find out connected components in the improved depth image while incorporating smoothed range angle image. This allows separating the non-ground objects. The rest of the locations of depth image belong to the ground plane. The filter has been tested on a simulated environment as well as an actual drone and provides real-time performance. We make our source code and dataset available online\footnote[2]{Source code and dataset are available at https://github.com/GPrathap/hagen.git