 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Heatmap-Based Method for Estimating Drivers' Cognitive Distraction
May 28, 2020
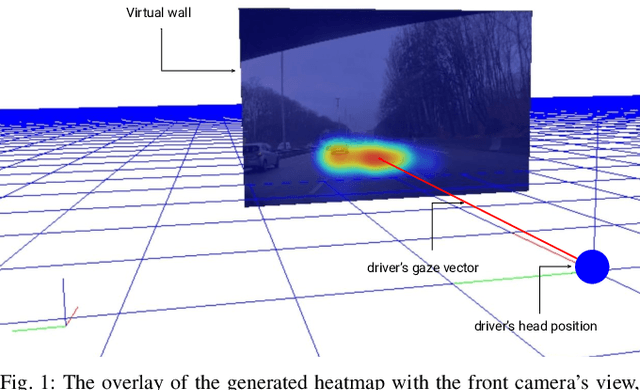
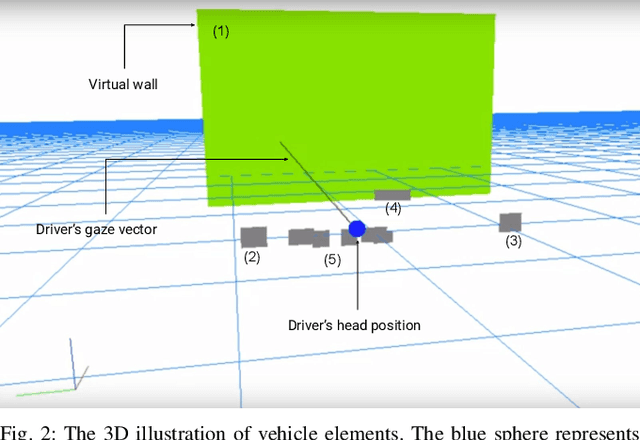

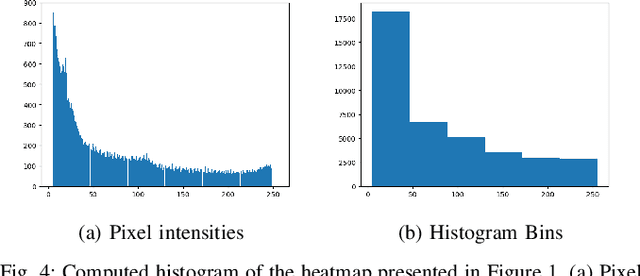
In order to increase road safety, among the visual and manual distractions, modern intelligent vehicles need also to detect cognitive distracted driving (i.e., the drivers mind wandering). In this study, the influence of cognitive processes on the drivers gaze behavior is explored. A novel image-based representation of the driver's eye-gaze dispersion is proposed to estimate cognitive distraction. Data are collected on open highway roads, with a tailored protocol to create cognitive distraction. The visual difference of created shapes shows that a driver explores a wider area in neutral driving compared to distracted driving. Thus, support vector machine (SVM)-based classifiers are trained, and 85.2% of accuracy is achieved for a two-class problem, even with a small dataset. Thus, the proposed method has the discriminative power to recognize cognitive distraction using gaze information. Finally, this work details how this image-based representation could be useful for other cases of distracted driving detection.
DOT: Dynamic Object Tracking for Visual SLAM
Sep 30, 2020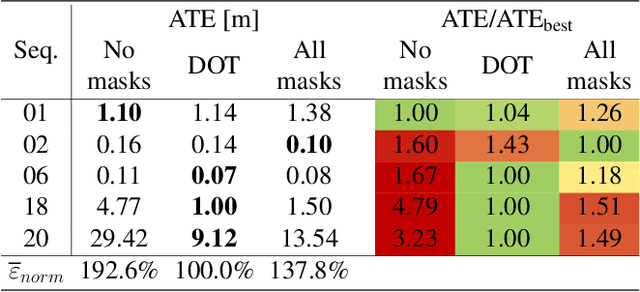
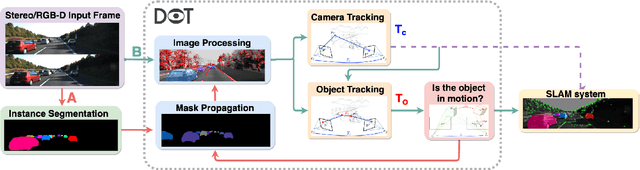

In this paper we present DOT (Dynamic Object Tracking), a front-end that added to existing SLAM systems can significantly improve their robustness and accuracy in highly dynamic environments. DOT combines instance segmentation and multi-view geometry to generate masks for dynamic objects in order to allow SLAM systems based on rigid scene models to avoid such image areas in their optimizations. To determine which objects are actually moving, DOT segments first instances of potentially dynamic objects and then, with the estimated camera motion, tracks such objects by minimizing the photometric reprojection error. This short-term tracking improves the accuracy of the segmentation with respect to other approaches. In the end, only actually dynamic masks are generated. We have evaluated DOT with ORB-SLAM 2 in three public datasets. Our results show that our approach improves significantly the accuracy and robustness of ORB-SLAM 2, especially in highly dynamic scenes.
On the Evaluation of Generative Adversarial Networks By Discriminative Models
Oct 07, 2020

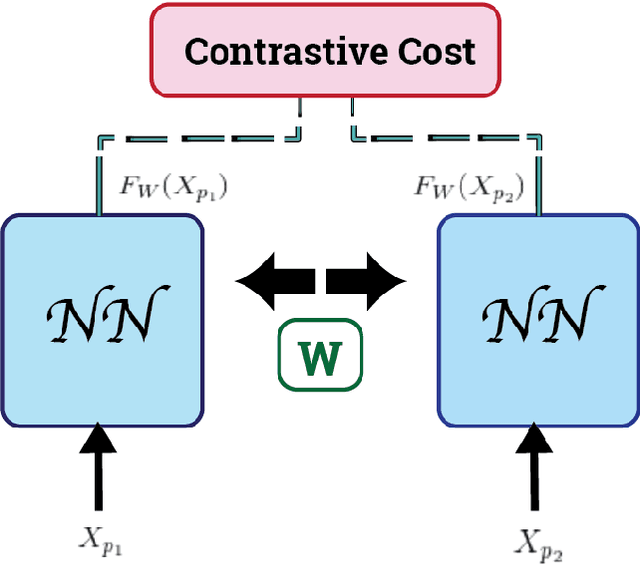
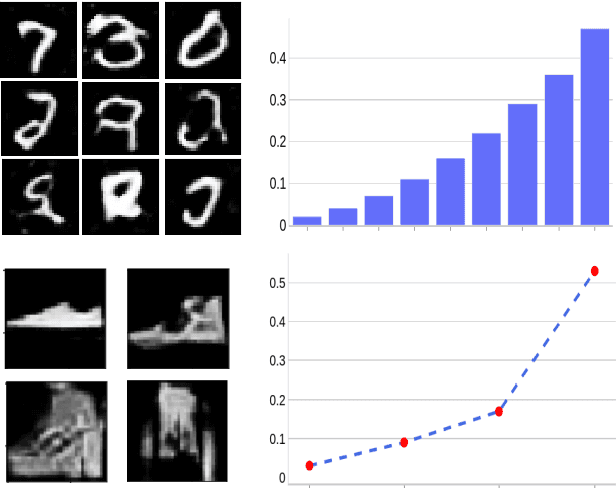
Generative Adversarial Networks (GANs) can accurately model complex multi-dimensional data and generate realistic samples. However, due to their implicit estimation of data distributions, their evaluation is a challenging task. The majority of research efforts associated with tackling this issue were validated by qualitative visual evaluation. Such approaches do not generalize well beyond the image domain. Since many of those evaluation metrics are proposed and bound to the vision domain, they are difficult to apply to other domains. Quantitative measures are necessary to better guide the training and comparison of different GANs models. In this work, we leverage Siamese neural networks to propose a domain-agnostic evaluation metric: (1) with a qualitative evaluation that is consistent with human evaluation, (2) that is robust relative to common GAN issues such as mode dropping and invention, and (3) does not require any pretrained classifier. The empirical results in this paper demonstrate the superiority of this method compared to the popular Inception Score and are competitive with the FID score.
Learning Deep Features in Instrumental Variable Regression
Nov 01, 2020
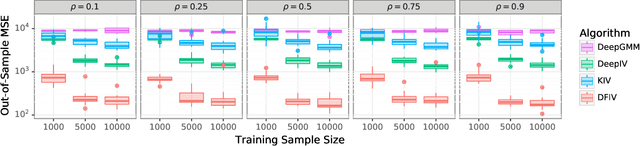

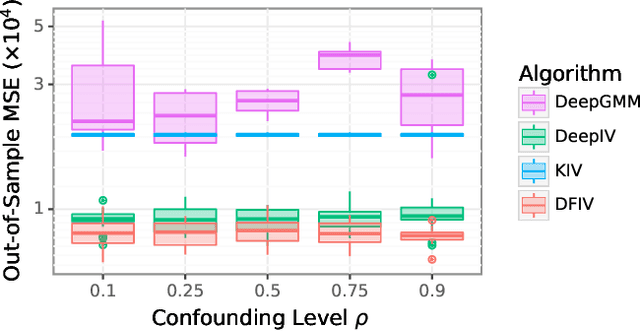
Instrumental variable (IV) regression is a standard strategy for learning causal relationships between confounded treatment and outcome variables from observational data by utilizing an instrumental variable, which affects the outcome only through the treatment. In classical IV regression, learning proceeds in two stages: stage 1 performs linear regression from the instrument to the treatment; and stage 2 performs linear regression from the treatment to the outcome, conditioned on the instrument. We propose a novel method, deep feature instrumental variable regression (DFIV), to address the case where relations between instruments, treatments, and outcomes may be nonlinear. In this case, deep neural nets are trained to define informative nonlinear features on the instruments and treatments. We propose an alternating training regime for these features to ensure good end-to-end performance when composing stages 1 and 2, thus obtaining highly flexible feature maps in a computationally efficient manner. DFIV outperforms recent state-of-the-art methods on challenging IV benchmarks, including settings involving high dimensional image data. DFIV also exhibits competitive performance in off-policy policy evaluation for reinforcement learning, which can be understood as an IV regression task.
Flow-Guided Attention Networks for Video-Based Person Re-Identification
Aug 09, 2020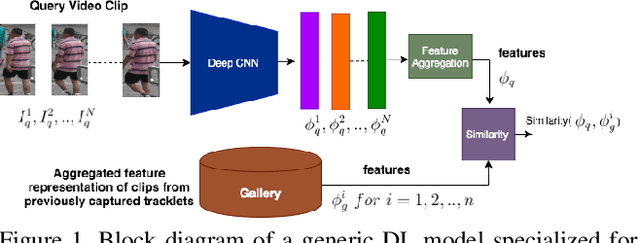
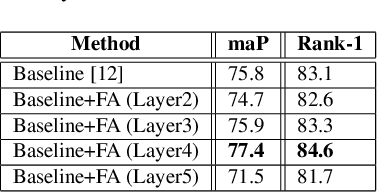


Person Re-Identification (ReID) is an important problem in many video analytics and surveillance applications,where a person's identity must be associated across a distributed network of cameras. Video-based person ReID has recently gained much interest because it can capture discriminant spatio-temporal information that is unavailable for image-based ReID. Despite recent advances, deep learning models for video ReID often fail to leverage this information to improve the robustness of feature representations. In this paper, the motion pattern of a person is explored as an additional cue for ReID. In particular, two different flow-guided attention networks are proposed for fusion with any 2D-CNN backbone, allowing to encode temporal information along with spatial appearance information.Our first proposed network called Gated Attention relies on optical flow to generate gated attention with video-based feature that embed spatially. Hence the proposed framework allows to activate a common set of salient features across multiple frames. In contrast, our second network called Mutual Attention relies on the joint attention between image and optical flow features. This enables spatial attention between both sources of features, across motion and appearance cues. Both methods introduce a feature aggregation method that produce video features by identifying salient spatio-temporal information.Extensive experiments on two challenging video datasets indicate that using the proposed flow-guided spatio-temporal attention networks allows to improve recognition accuracy considerably, outperforming state-of-the-art methods for video-based person ReID. Additionally, our Mutual Attention network is able to process longer frame sequences with a wider range of appearance variations for highly accurate recognition.
Weakly Supervised Context Encoder using DICOM metadata in Ultrasound Imaging
Mar 20, 2020

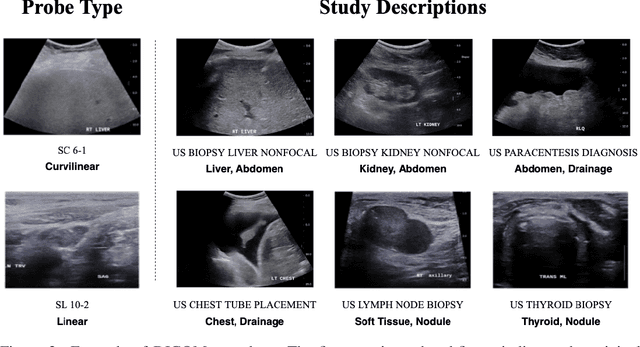
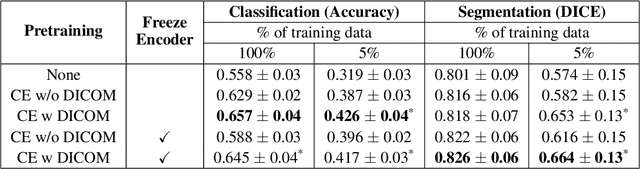
Modern deep learning algorithms geared towards clinical adaption rely on a significant amount of high fidelity labeled data. Low-resource settings pose challenges like acquiring high fidelity data and becomes the bottleneck for developing artificial intelligence applications. Ultrasound images, stored in Digital Imaging and Communication in Medicine (DICOM) format, have additional metadata data corresponding to ultrasound image parameters and medical exams. In this work, we leverage DICOM metadata from ultrasound images to help learn representations of the ultrasound image. We demonstrate that the proposed method outperforms the non-metadata based approaches across different downstream tasks.
CAS-CNN: A Deep Convolutional Neural Network for Image Compression Artifact Suppression
Nov 22, 2016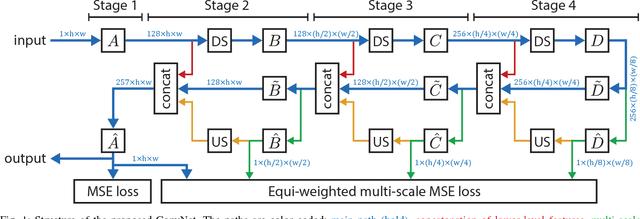
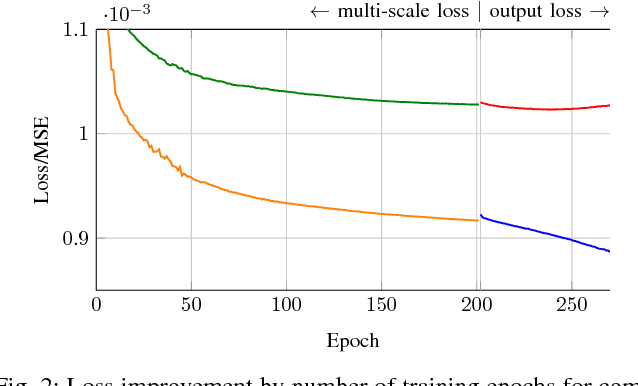
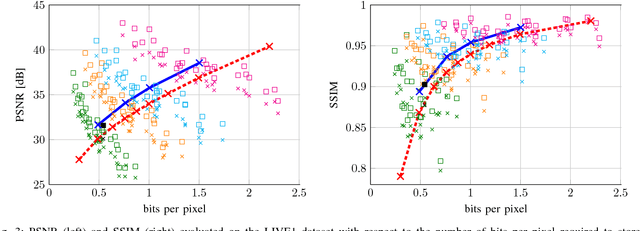
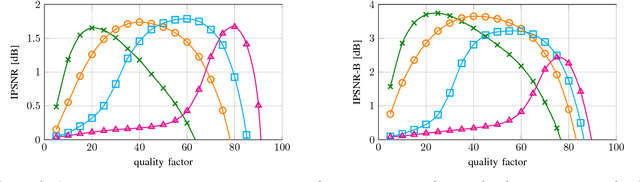
Lossy image compression algorithms are pervasively used to reduce the size of images transmitted over the web and recorded on data storage media. However, we pay for their high compression rate with visual artifacts degrading the user experience. Deep convolutional neural networks have become a widespread tool to address high-level computer vision tasks very successfully. Recently, they have found their way into the areas of low-level computer vision and image processing to solve regression problems mostly with relatively shallow networks. We present a novel 12-layer deep convolutional network for image compression artifact suppression with hierarchical skip connections and a multi-scale loss function. We achieve a boost of up to 1.79 dB in PSNR over ordinary JPEG and an improvement of up to 0.36 dB over the best previous ConvNet result. We show that a network trained for a specific quality factor (QF) is resilient to the QF used to compress the input image - a single network trained for QF 60 provides a PSNR gain of more than 1.5 dB over the wide QF range from 40 to 76.
k-Modulus Method for Image Transformation
Apr 24, 2013

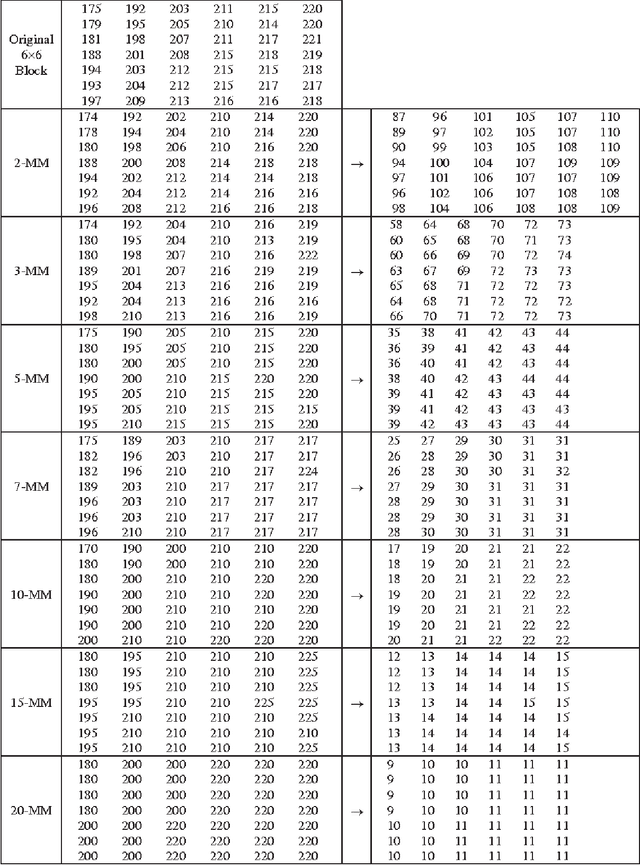

In this paper, we propose a new algorithm to make a novel spatial image transformation. The proposed approach aims to reduce the bit depth used for image storage. The basic technique for the proposed transformation is based of the modulus operator. The goal is to transform the whole image into multiples of predefined integer. The division of the whole image by that integer will guarantee that the new image surely less in size from the original image. The k-Modulus Method could not be used as a stand alone transform for image compression because of its high compression ratio. It could be used as a scheme embedded in other image processing fields especially compression. According to its high PSNR value, it could be amalgamated with other methods to facilitate the redundancy criterion.
* 5 pages, 2 tables, 6 figures
Learning to Zoom-in via Learning to Zoom-out: Real-world Super-resolution by Generating and Adapting Degradation
Jan 08, 2020
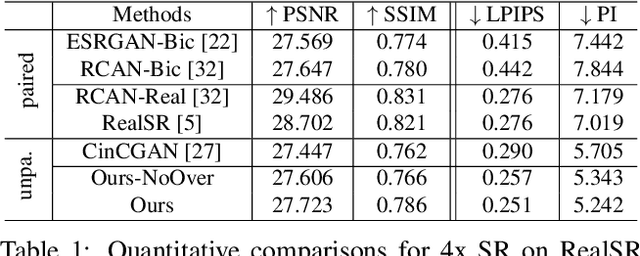

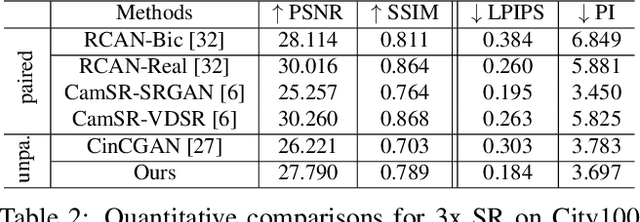
Most learning-based super-resolution (SR) methods aim to recover high-resolution (HR) image from a given low-resolution (LR) image via learning on LR-HR image pairs. The SR methods learned on synthetic data do not perform well in real-world, due to the domain gap between the artificially synthesized and real LR images. Some efforts are thus taken to capture real-world image pairs. The captured LR-HR image pairs usually suffer from unavoidable misalignment, which hampers the performance of end-to-end learning, however. Here, focusing on the real-world SR, we ask a different question: since misalignment is unavoidable, can we propose a method that does not need LR-HR image pairing and alignment at all and utilize real images as they are? Hence we propose a framework to learn SR from an arbitrary set of unpaired LR and HR images and see how far a step can go in such a realistic and "unsupervised" setting. To do so, we firstly train a degradation generation network to generate realistic LR images and, more importantly, to capture their distribution (i.e., learning to zoom out). Instead of assuming the domain gap has been eliminated, we minimize the discrepancy between the generated data and real data while learning a degradation adaptive SR network (i.e., learning to zoom in). The proposed unpaired method achieves state-of-the-art SR results on real-world images, even in the datasets that favor the paired-learning methods more.
Scribble-Supervised Semantic Segmentation by Random Walk on Neural Representation and Self-Supervision on Neural Eigenspace
Nov 12, 2020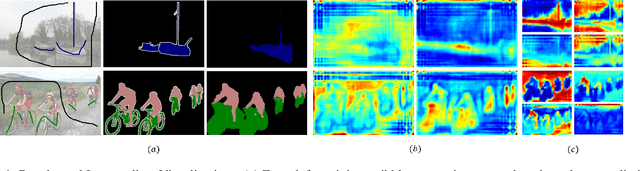
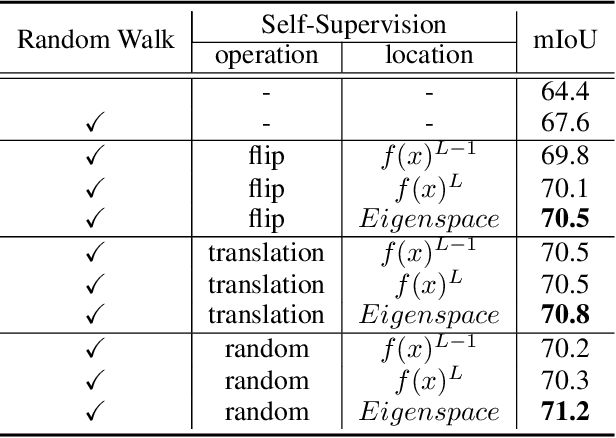
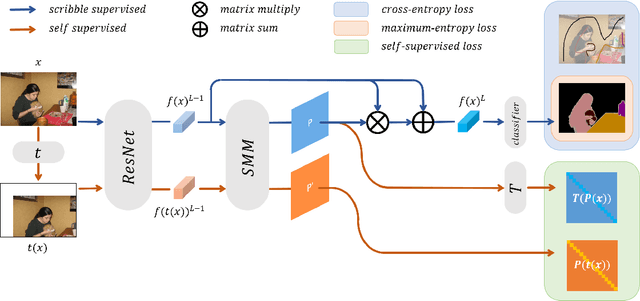
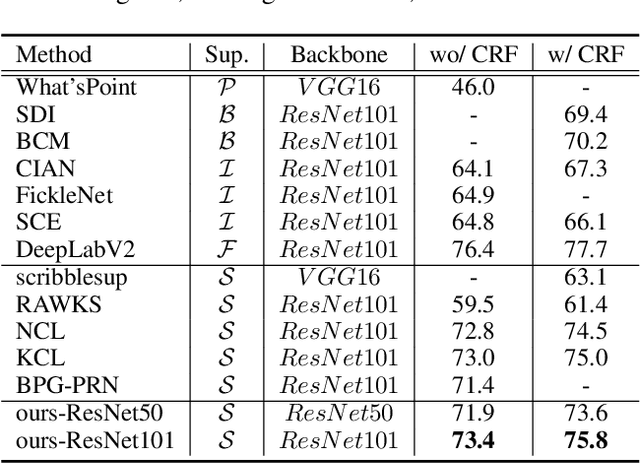
Scribble-supervised semantic segmentation has gained much attention recently for its promising performance without high-quality annotations. Many approaches have been proposed. Typically, they handle this problem to either introduce a well-labeled dataset from another related task, turn to iterative refinement and post-processing with the graphical model, or manipulate the scribble label. This work aims to achieve semantic segmentation supervised by scribble label directly without auxiliary information and other intermediate manipulation. Specifically, we impose diffusion on neural representation by random walk and consistency on neural eigenspace by self-supervision, which forces the neural network to produce dense and consistent predictions over the whole dataset. The random walk embedded in the network will compute a probabilistic transition matrix, with which the neural representation diffused to be uniform. Moreover, given the probabilistic transition matrix, we apply the self-supervision on its eigenspace for consistency in the image's main parts. In addition to comparing the common scribble dataset, we also conduct experiments on the modified datasets that randomly shrink and even drop the scribbles on image objects. The results demonstrate the superiority of the proposed method and are even comparable to some full-label supervised ones. The code and datasets are available at https://github.com/panzhiyi/RW-SS.