 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Attribute-Guided Adversarial Training for Robustness to Natural Perturbations
Dec 03, 2020
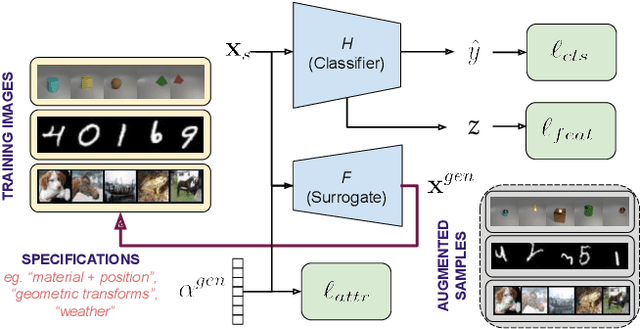
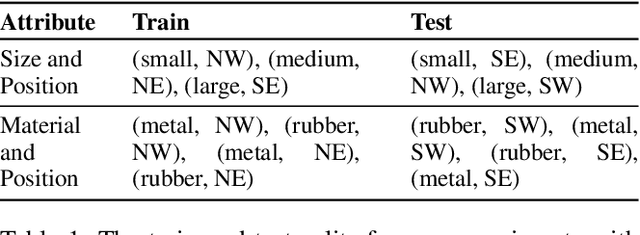

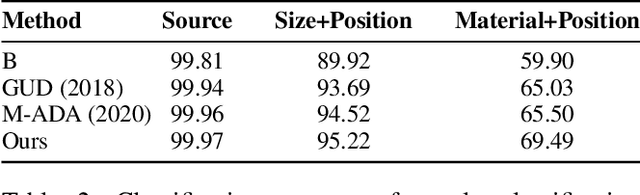
While existing work in robust deep learning has focused on small pixel-level $\ell_p$ norm-based perturbations, this may not account for perturbations encountered in several real world settings. In many such cases although test data might not be available, broad specifications about the types of perturbations (such as an unknown degree of rotation) may be known. We consider a setup where robustness is expected over an unseen test domain that is not i.i.d. but deviates from the training domain. While this deviation may not be exactly known, its broad characterization is specified a priori, in terms of attributes. We propose an adversarial training approach which learns to generate new samples so as to maximize exposure of the classifier to the attributes-space, without having access to the data from the test domain. Our adversarial training solves a min-max optimization problem, with the inner maximization generating adversarial perturbations, and the outer minimization finding model parameters by optimizing the loss on adversarial perturbations generated from the inner maximization. We demonstrate the applicability of our approach on three types of naturally occurring perturbations -- object-related shifts, geometric transformations, and common image corruptions. Our approach enables deep neural networks to be robust against a wide range of naturally occurring perturbations. We demonstrate the usefulness of the proposed approach by showing the robustness gains of deep neural networks trained using our adversarial training on MNIST, CIFAR-10, and a new variant of the CLEVR dataset.
Probabilistic self-learning framework for Low-dose CT Denoising
May 30, 2020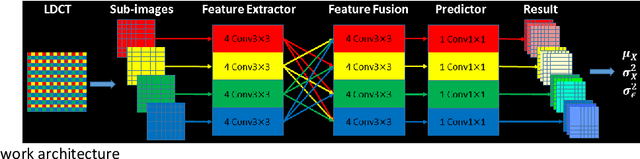
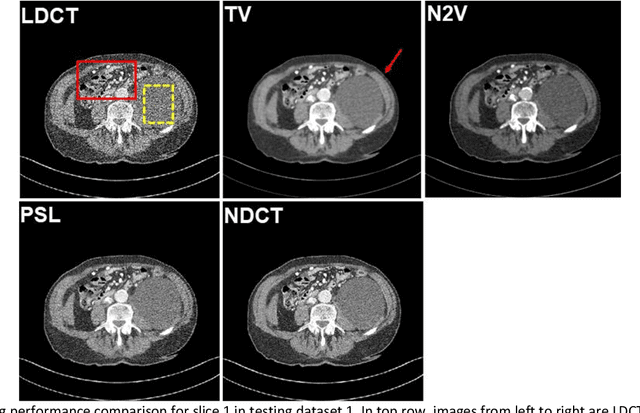
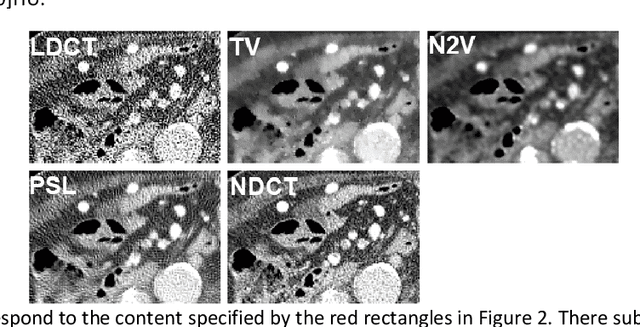
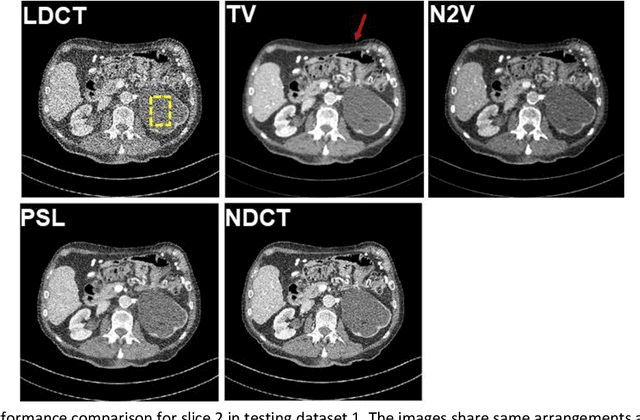
Despite the indispensable role of X-ray computed tomography (CT) in diagnostic medicine field, the associated ionizing radiation is still a major concern considering that it may cause genetic and cancerous diseases. Decreasing the exposure can reduce the dose and hence the radiation-related risk, but will also induce higher quantum noise. Supervised deep learning can be used to train a neural network to denoise the low-dose CT (LDCT). However, its success requires massive pixel-wise paired LDCT and normal-dose CT (NDCT) images, which are rarely available in real practice. To alleviate this problem, in this paper, a shift-invariant property based neural network was devised to learn the inherent pixel correlations and also the noise distribution by only using the LDCT images, shaping into our probabilistic self-learning framework. Experimental results demonstrated that the proposed method outperformed the competitors, producing an enhanced LDCT image that has similar image style as the routine NDCT which is highly-preferable in clinic practice.
DTG-Net: Differentiated Teachers Guided Self-Supervised Video Action Recognition
Jun 13, 2020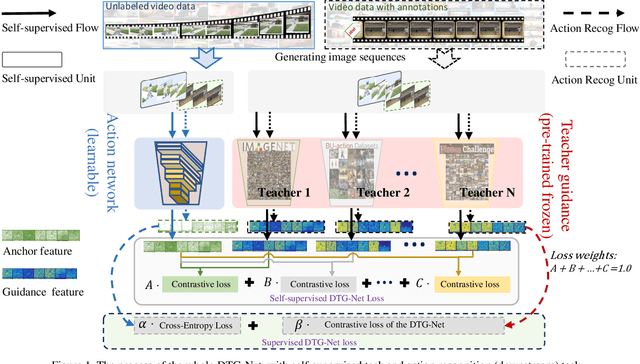
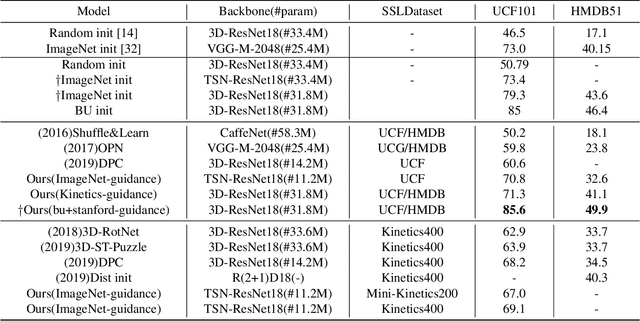
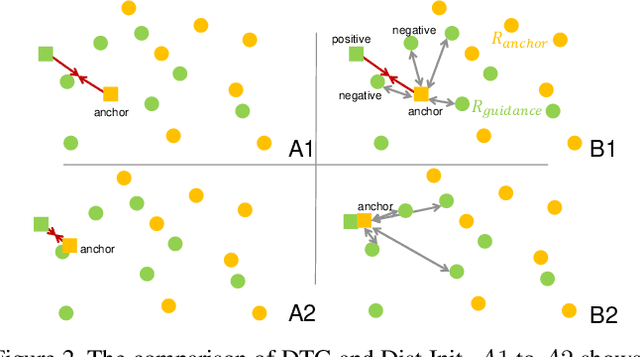

State-of-the-art video action recognition models with complex network architecture have archived significant improvements, but these models heavily depend on large-scale well-labeled datasets. To reduce such dependency, we propose a self-supervised teacher-student architecture, i.e., the Differentiated Teachers Guided self-supervised Network (DTG-Net). In DTG-Net, except for reducing labeled data dependency by self-supervised learning (SSL), pre-trained action related models are used as teacher guidance providing prior knowledge to alleviate the demand for a large number of unlabeled videos in SSL. Specifically, leveraging the years of effort in action-related tasks, e.g., image classification, image-based action recognition, the DTG-Net learns the self-supervised video representation under various teacher guidance, i.e., those well-trained models of action-related tasks. Meanwhile, the DTG-Net is optimized in the way of contrastive self-supervised learning. When two image sequences are randomly sampled from the same video or different videos as the positive or negative pairs, respectively, they are then sent to the teacher and student networks for feature embedding. After that, the contrastive feature consistency is defined between features embedding of each pair, i.e., consistent for positive pair and inconsistent for negative pairs. Meanwhile, to reflect various teacher tasks' different guidance, we also explore different weighted guidance on teacher tasks. Finally, the DTG-Net is evaluated in two ways: (i) the self-supervised DTG-Net to pre-train the supervised action recognition models with only unlabeled videos; (ii) the supervised DTG-Net to be jointly trained with the supervised action networks in an end-to-end way. Its performance is better than most pre-training methods but also has excellent competitiveness compared to supervised action recognition methods.
Neural Enhancement in Content Delivery Systems: The State-of-the-Art and Future Directions
Oct 22, 2020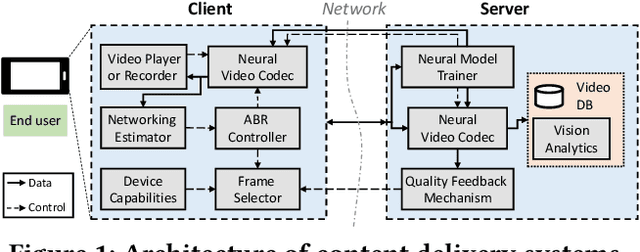


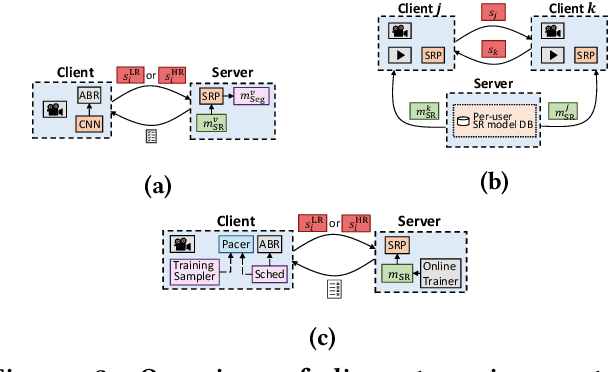
Internet-enabled smartphones and ultra-wide displays are transforming a variety of visual apps spanning from on-demand movies and 360-degree videos to video-conferencing and live streaming. However, robustly delivering visual content under fluctuating networking conditions on devices of diverse capabilities remains an open problem. In recent years, advances in the field of deep learning on tasks such as super-resolution and image enhancement have led to unprecedented performance in generating high-quality images from low-quality ones, a process we refer to as neural enhancement. In this paper, we survey state-of-the-art content delivery systems that employ neural enhancement as a key component in achieving both fast response time and high visual quality. We first present the deployment challenges of neural enhancement models. We then cover systems targeting diverse use-cases and analyze their design decisions in overcoming technical challenges. Moreover, we present promising directions based on the latest insights from deep learning research to further boost the quality of experience of these systems.
Confused Modulo Projection based Somewhat Homomorphic Encryption -- Cryptosystem, Library and Applications on Secure Smart Cities
Dec 19, 2020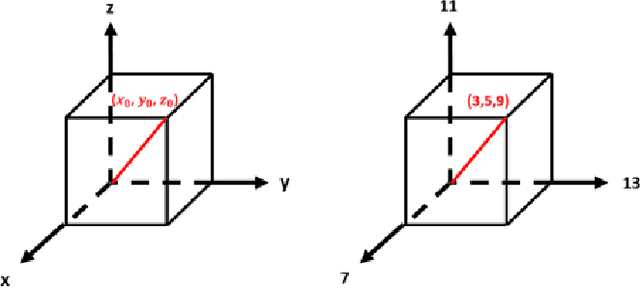
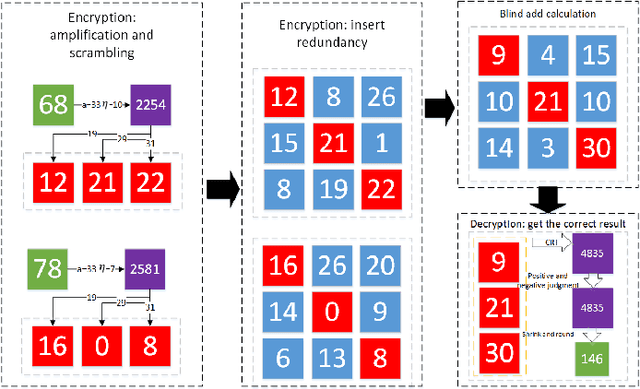


With the development of cloud computing, the storage and processing of massive visual media data has gradually transferred to the cloud server. For example, if the intelligent video monitoring system cannot process a large amount of data locally, the data will be uploaded to the cloud. Therefore, how to process data in the cloud without exposing the original data has become an important research topic. We propose a single-server version of somewhat homomorphic encryption cryptosystem based on confused modulo projection theorem named CMP-SWHE, which allows the server to complete blind data processing without \emph{seeing} the effective information of user data. On the client side, the original data is encrypted by amplification, randomization, and setting confusing redundancy. Operating on the encrypted data on the server side is equivalent to operating on the original data. As an extension, we designed and implemented a blind computing scheme of accelerated version based on batch processing technology to improve efficiency. To make this algorithm easy to use, we also designed and implemented an efficient general blind computing library based on CMP-SWHE. We have applied this library to foreground extraction, optical flow tracking and object detection with satisfactory results, which are helpful for building smart cities. We also discuss how to extend the algorithm to deep learning applications. Compared with other homomorphic encryption cryptosystems and libraries, the results show that our method has obvious advantages in computing efficiency. Although our algorithm has some tiny errors ($10^{-6}$) when the data is too large, it is very efficient and practical, especially suitable for blind image and video processing.
Evolving Normalization-Activation Layers
Apr 28, 2020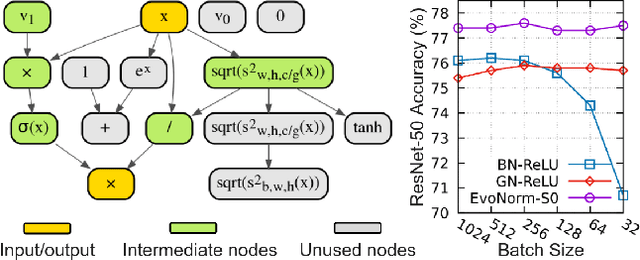

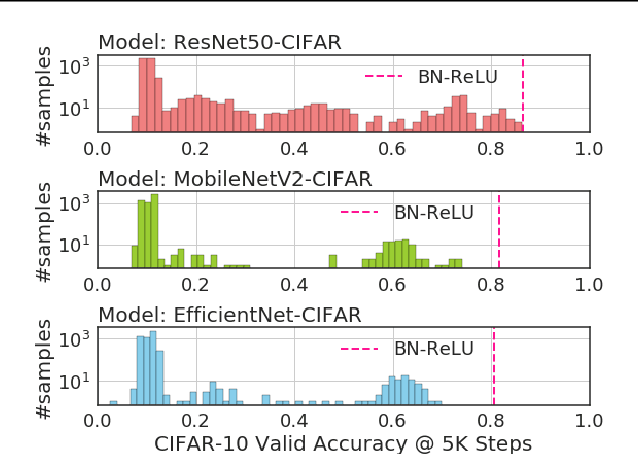
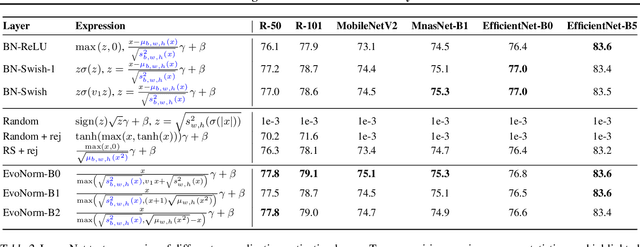
Normalization layers and activation functions are critical components in deep neural networks that frequently co-locate with each other. Instead of designing them separately, we unify them into a single computation graph, and evolve its structure starting from low-level primitives. Our layer search algorithm leads to the discovery of EvoNorms, a set of new normalization-activation layers that go beyond existing design patterns. Several of these layers enjoy the property of being independent from the batch statistics. Our experiments show that EvoNorms not only work well on a variety of image classification models including ResNets, MobileNets and EfficientNets but also transfer well to Mask R-CNN, SpineNet for instance segmentation and BigGAN for image synthesis, significantly outperforming BatchNorm and GroupNorm based layers in many cases.
Learning to Answer Questions From Image Using Convolutional Neural Network
Nov 13, 2015
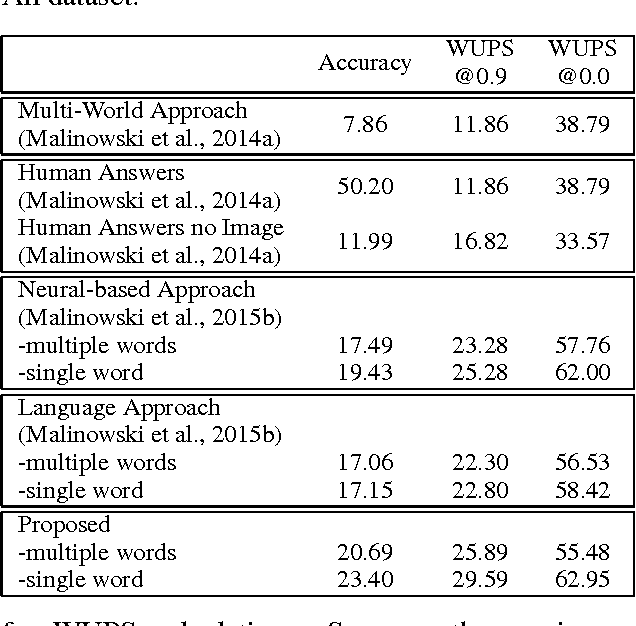
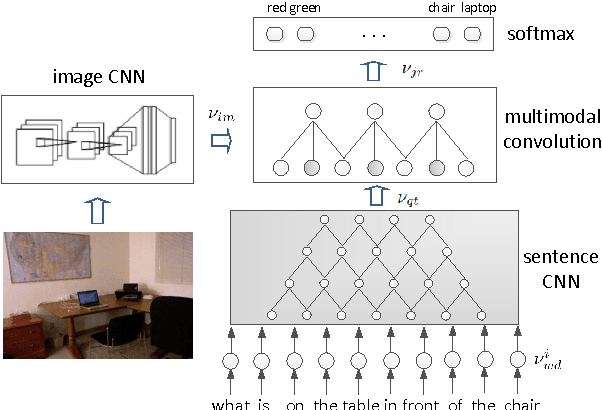
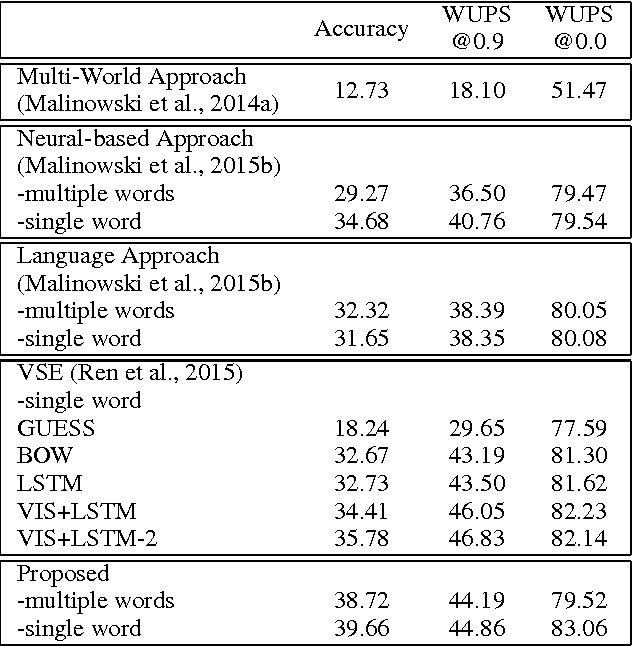
In this paper, we propose to employ the convolutional neural network (CNN) for the image question answering (QA). Our proposed CNN provides an end-to-end framework with convolutional architectures for learning not only the image and question representations, but also their inter-modal interactions to produce the answer. More specifically, our model consists of three CNNs: one image CNN to encode the image content, one sentence CNN to compose the words of the question, and one multimodal convolution layer to learn their joint representation for the classification in the space of candidate answer words. We demonstrate the efficacy of our proposed model on the DAQUAR and COCO-QA datasets, which are two benchmark datasets for the image QA, with the performances significantly outperforming the state-of-the-art.
A Two-step-training Deep Learning Framework for Real-time Computational Imaging without Physics Priors
Jan 10, 2020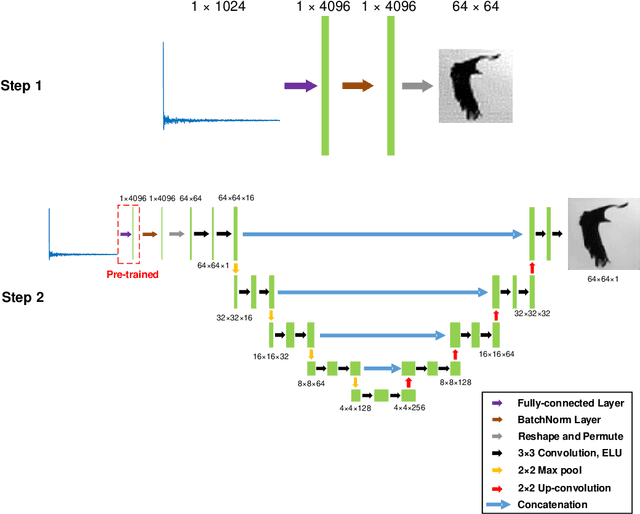
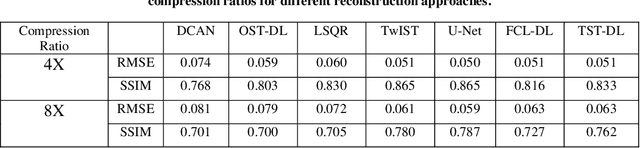

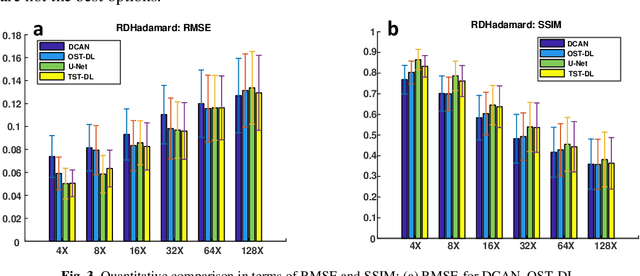
Deep learning (DL) is a powerful tool in computational imaging for many applications. A common strategy is to reconstruct a preliminary image as the input of a neural network to achieve an optimized image. Usually, the preliminary image is acquired with the prior knowledge of the model. One outstanding challenge, however, is that the model is sometimes difficult to acquire with high accuracy. In this work, a two-step-training DL (TST-DL) framework is proposed for real-time computational imaging without prior knowledge of the model. A single fully-connected layer (FCL) is trained to directly learn the model with the raw measurement data as input and the image as output. Then, this pre-trained FCL is fixed and connected with an un-trained deep convolutional network for a second-step training to improve the output image fidelity. This approach has three main advantages. First, no prior knowledge of the model is required since the first-step training is to directly learn the model. Second, real-time imaging can be achieved since the raw measurement data is directly used as the input to the model. Third, it can handle any dimension of the network input and solve the input-output dimension mismatch issues which arise in convolutional neural networks. We demonstrate this framework in the applications of single-pixel imaging and photoacoustic imaging for linear model cases. The results are quantitatively compared with those from other DL frameworks and model-based optimization approaches. Noise robustness and the required size of the training dataset are studied for this framework. We further extend this concept to nonlinear models in the application of image de-autocorrelation by using multiple FCLs in the first-step training. Overall, this TST-DL framework is widely applicable to many computational imaging techniques for real-time image reconstruction without the physics priors.
Learning Monocular Dense Depth from Events
Oct 22, 2020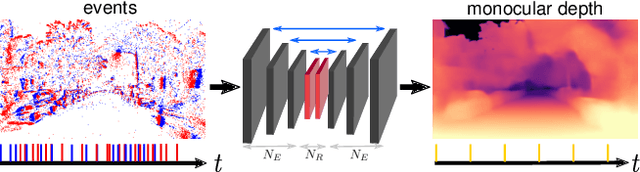
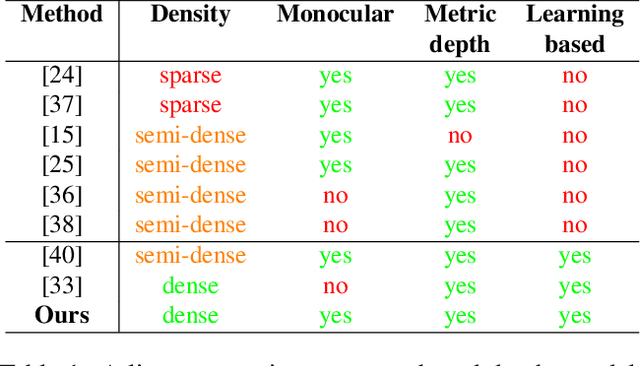
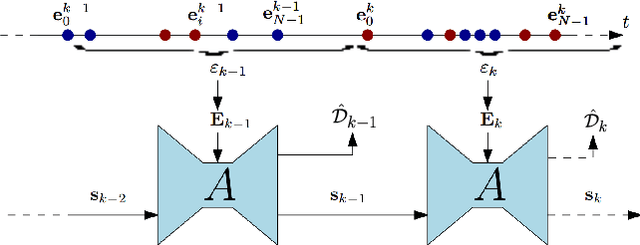
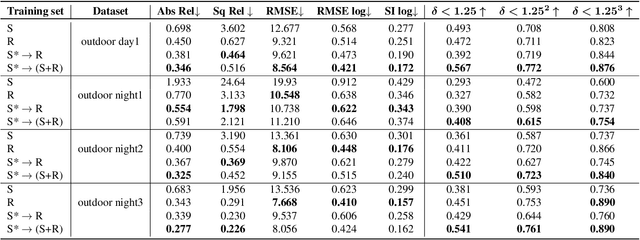
Event cameras are novel sensors that output brightness changes in the form of a stream of asynchronous events instead of intensity frames. Compared to conventional image sensors, they offer significant advantages: high temporal resolution, high dynamic range, no motion blur, and much lower bandwidth. Recently, learning-based approaches have been applied to event-based data, thus unlocking their potential and making significant progress in a variety of tasks, such as monocular depth prediction. Most existing approaches use standard feed-forward architectures to generate network predictions, which do not leverage the temporal consistency presents in the event stream. We propose a recurrent architecture to solve this task and show significant improvement over standard feed-forward methods. In particular, our method generates dense depth predictions using a monocular setup, which has not been shown previously. We pretrain our model using a new dataset containing events and depth maps recorded in the CARLA simulator. We test our method on the Multi Vehicle Stereo Event Camera Dataset (MVSEC). Quantitative experiments show up to 50% improvement in average depth error with respect to previous event-based methods.
Implicit Dual-domain Convolutional Network for Robust Color Image Compression Artifact Reduction
Oct 18, 2018

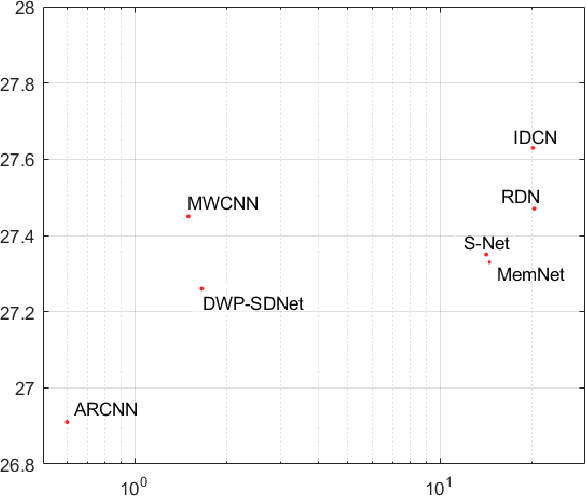
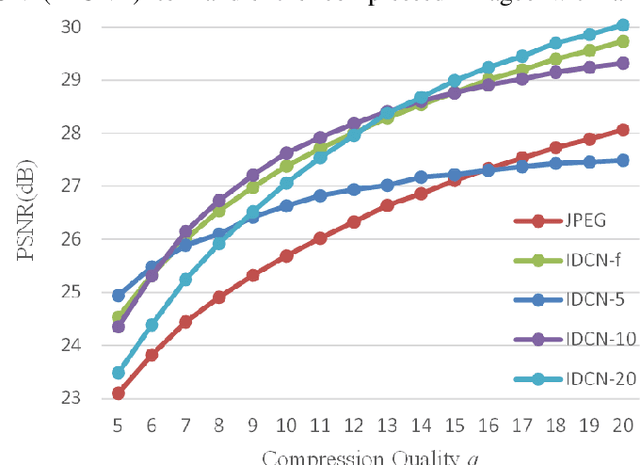
Several dual-domain convolutional neural network-based methods show outstanding performance in reducing image compression artifacts. However, they suffer from handling color images because the compression processes for gray-scale and color images are completely different. Moreover, these methods train a specific model for each compression quality and require multiple models to achieve different compression qualities. To address these problems, we proposed an implicit dual-domain convolutional network (IDCN) with the pixel position labeling map and the quantization tables as inputs. Specifically, we proposed an extractor-corrector framework-based dual-domain correction unit (DRU) as the basic component to formulate the IDCN. A dense block was introduced to improve the performance of extractor in DRU. The implicit dual-domain translation allows the IDCN to handle color images with the discrete cosine transform (DCT)-domain priors. A flexible version of IDCN (IDCN-f) was developed to handle a wide range of compression qualities. Experiments for both objective and subjective evaluations on benchmark datasets show that IDCN is superior to the state-of-the-art methods and IDCN-f exhibits excellent abilities to handle a wide range of compression qualities with little performance sacrifice and demonstrates great potential for practical applications.