 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Knowledge Capture and Replay for Continual Learning
Dec 12, 2020
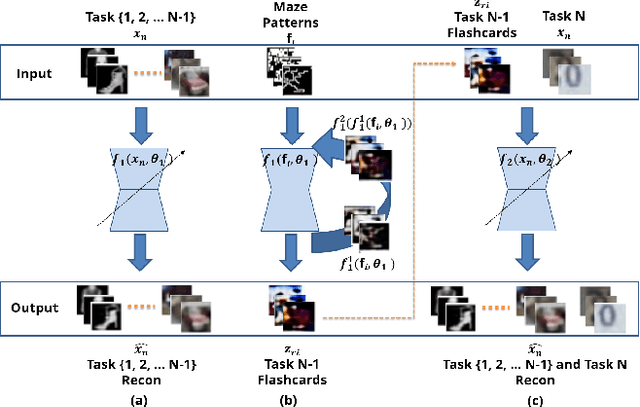
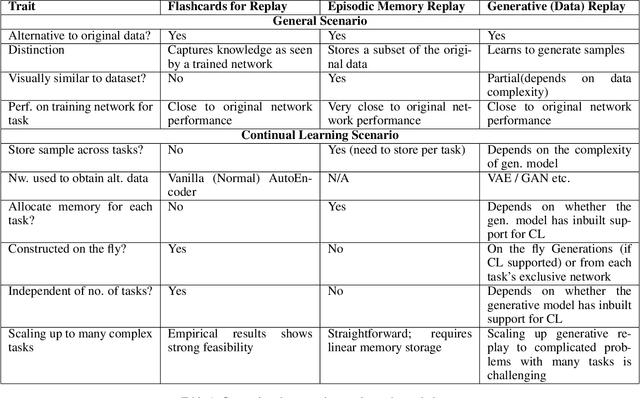
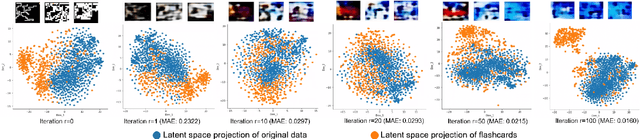
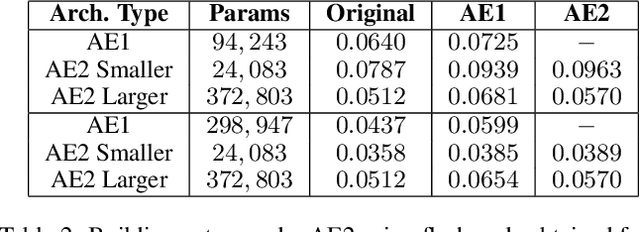
Deep neural networks have shown promise in several domains, and the learned task-specific information is implicitly stored in the network parameters. It will be vital to utilize representations from these networks for downstream tasks such as continual learning. In this paper, we introduce the notion of {\em flashcards} that are visual representations to {\em capture} the encoded knowledge of a network, as a function of random image patterns. We demonstrate the effectiveness of flashcards in capturing representations and show that they are efficient replay methods for general and task agnostic continual learning setting. Thus, while adapting to a new task, a limited number of constructed flashcards, help to prevent catastrophic forgetting of the previously learned tasks. Most interestingly, such flashcards neither require external memory storage nor need to be accumulated over multiple tasks and only need to be constructed just before learning the subsequent new task, irrespective of the number of tasks trained before and are hence task agnostic. We first demonstrate the efficacy of flashcards in capturing knowledge representation from a trained network, and empirically validate the efficacy of flashcards on a variety of continual learning tasks: continual unsupervised reconstruction, continual denoising, and new-instance learning classification, using a number of heterogeneous benchmark datasets. These studies also indicate that continual learning algorithms with flashcards as the replay strategy perform better than other state-of-the-art replay methods, and exhibits on par performance with the best possible baseline using coreset sampling, with the least additional computational complexity and storage.
StegColNet: Steganalysis based on an ensemble colorspace approach
Feb 06, 2020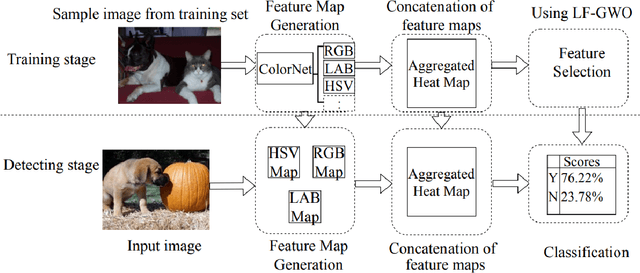
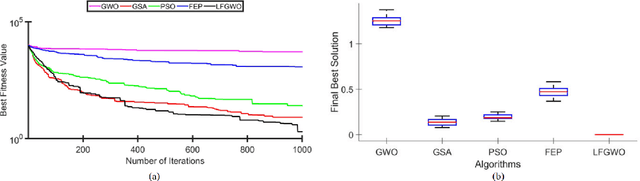
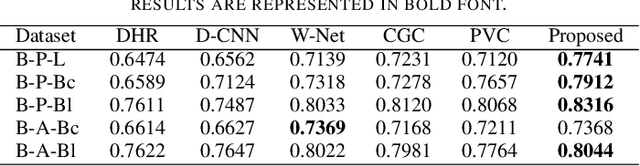
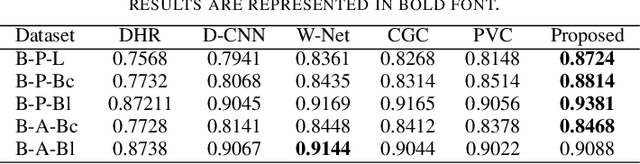
Image steganography refers to the process of hiding information inside images. Steganalysis is the process of detecting a steganographic image. We introduce a steganalysis approach that uses an ensemble color space model to obtain a weighted concatenated feature activation map. The concatenated map helps to obtain certain features explicit to each color space. We use a levy-flight grey wolf optimization strategy to reduce the number of features selected in the map. We then use these features to classify the image into one of two classes: whether the given image has secret information stored or not. Extensive experiments have been done on a large scale dataset extracted from the Bossbase dataset. Also, we show that the model can be transferred to different datasets and perform extensive experiments on a mixture of datasets. Our results show that the proposed approach outperforms the recent state of the art deep learning steganalytical approaches by 2.32 percent on average for 0.2 bits per channel (bpc) and 1.87 percent on average for 0.4 bpc.
AdaCrowd: Unlabeled Scene Adaptation for Crowd Counting
Oct 23, 2020
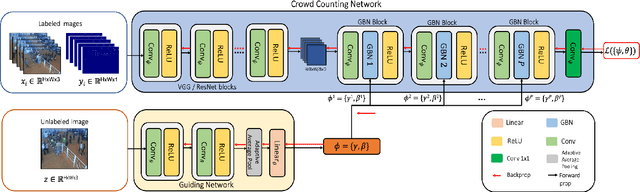
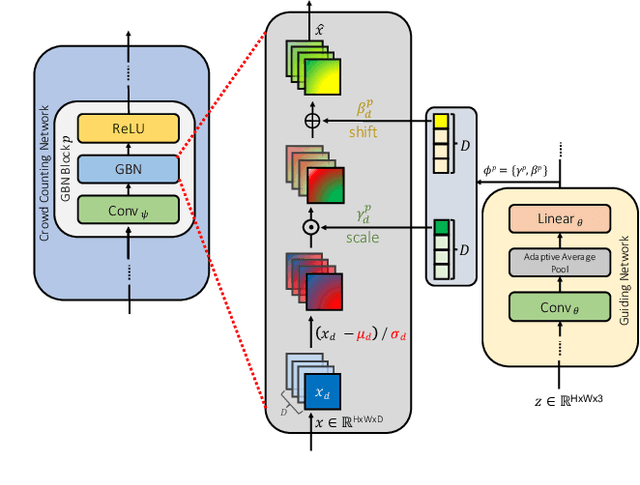
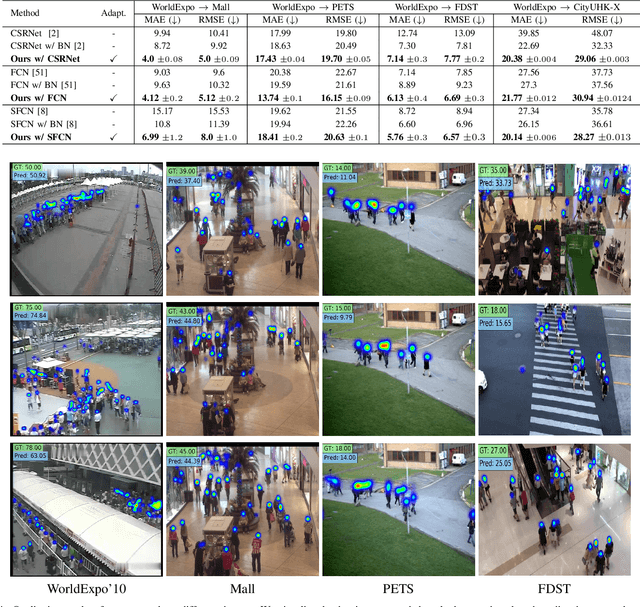
We address the problem of image-based crowd counting. In particular, we propose a new problem called unlabeled scene adaptive crowd counting. Given a new target scene, we would like to have a crowd counting model specifically adapted to this particular scene based on the target data that capture some information about the new scene. In this paper, we propose to use one or more unlabeled images from the target scene to perform the adaptation. In comparison with the existing problem setups (e.g. fully supervised), our proposed problem setup is closer to the real-world applications of crowd counting systems. We introduce a novel AdaCrowd framework to solve this problem. Our framework consists of a crowd counting network and a guiding network. The guiding network predicts some parameters in the crowd counting network based on the unlabeled images from a particular scene. This allows our model to adapt to different target scenes. The experimental results on several challenging benchmark datasets demonstrate the effectiveness of our proposed approach compared with other alternative methods.
Height estimation from single aerial images using a deep ordinal regression network
Jun 04, 2020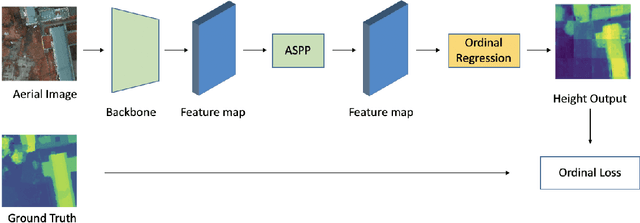
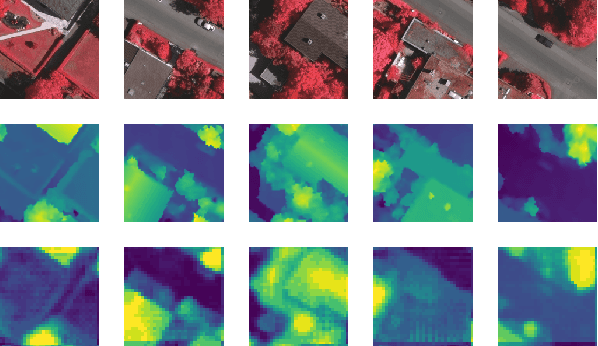

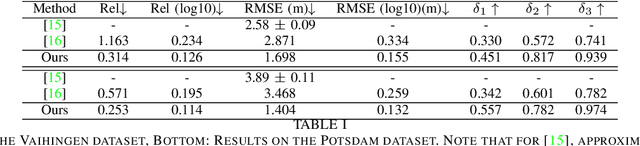
Understanding the 3D geometric structure of the Earth's surface has been an active research topic in photogrammetry and remote sensing community for decades, serving as an essential building block for various applications such as 3D digital city modeling, change detection, and city management. Previous researches have extensively studied the problem of height estimation from aerial images based on stereo or multi-view image matching. These methods require two or more images from different perspectives to reconstruct 3D coordinates with camera information provided. In this paper, we deal with the ambiguous and unsolved problem of height estimation from a single aerial image. Driven by the great success of deep learning, especially deep convolution neural networks (CNNs), some researches have proposed to estimate height information from a single aerial image by training a deep CNN model with large-scale annotated datasets. These methods treat height estimation as a regression problem and directly use an encoder-decoder network to regress the height values. In this paper, we proposed to divide height values into spacing-increasing intervals and transform the regression problem into an ordinal regression problem, using an ordinal loss for network training. To enable multi-scale feature extraction, we further incorporate an Atrous Spatial Pyramid Pooling (ASPP) module to extract features from multiple dilated convolution layers. After that, a post-processing technique is designed to transform the predicted height map of each patch into a seamless height map. Finally, we conduct extensive experiments on ISPRS Vaihingen and Potsdam datasets. Experimental results demonstrate significantly better performance of our method compared to the state-of-the-art methods.
CCML: A Novel Collaborative Learning Model for Classification of Remote Sensing Images with Noisy Multi-Labels
Dec 27, 2020
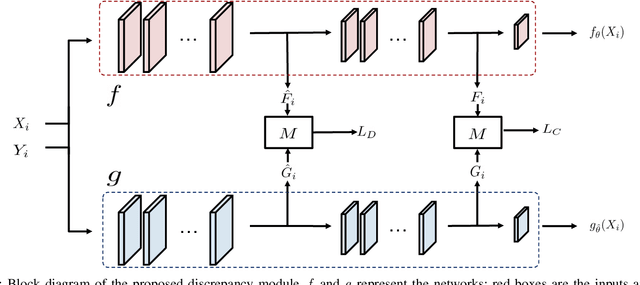
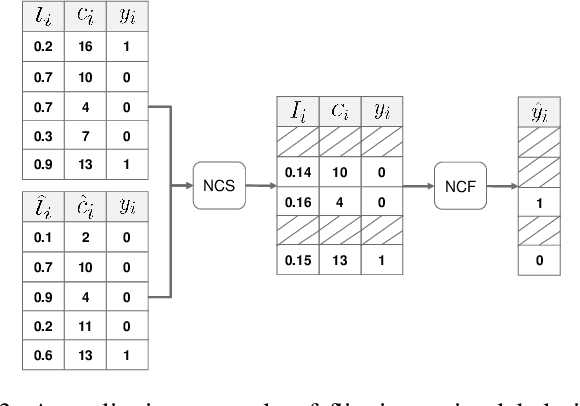
The development of accurate methods for multi-label classification (MLC) of remote sensing (RS) images is one of the most important research topics in RS. Deep Convolutional Neural Networks (CNNs) based methods have triggered substantial performance gains in RS MLC problems, requiring a large number of reliable training images annotated by multiple land-cover class labels. Collecting such data is time-consuming and costly. To address this problem, the publicly available thematic products, which can include noisy labels, can be used for annotating RS images with zero-labeling cost. However, multi-label noise (which can be associated with wrong as well as missing label annotations) can distort the learning process of the MLC algorithm, resulting in inaccurate predictions. The detection and correction of label noise are challenging tasks, especially in a multi-label scenario, where each image can be associated with more than one label. To address this problem, we propose a novel Consensual Collaborative Multi-Label Learning (CCML) method to alleviate the adverse effects of multi-label noise during the training phase of the CNN model. CCML identifies, ranks, and corrects noisy multi-labels in RS images based on four main modules: 1) group lasso module; 2) discrepancy module; 3) flipping module; and 4) swap module. The task of the group lasso module is to detect the potentially noisy labels assigned to the multi-labeled training images, and the discrepancy module ensures that the two collaborative networks learn diverse features, while obtaining the same predictions. The flipping module is designed to correct the identified noisy multi-labels, while the swap module task is devoted to exchanging the ranking information between two networks. Our code is publicly available online: http://www.noisy-labels-in-rs.org
Three dimensional Deep Learning approach for remote sensing image classification
Jun 15, 2018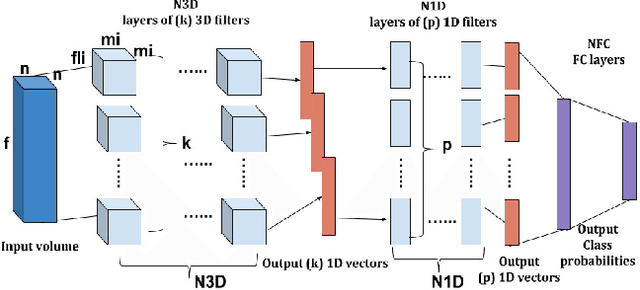
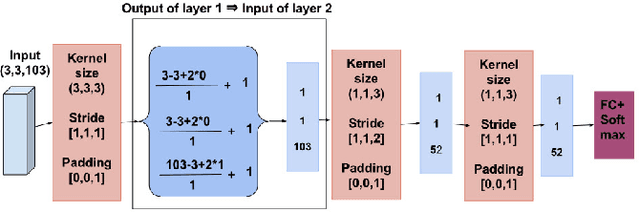

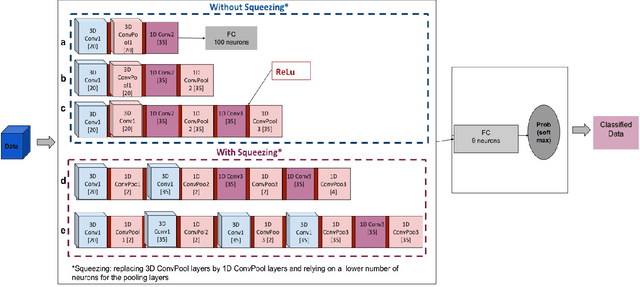
Recently, a variety of approaches has been enriching the field of Remote Sensing (RS) image processing and analysis. Unfortunately, existing methods remain limited faced to the rich spatio-spectral content of today's large datasets. It would seem intriguing to resort to Deep Learning (DL) based approaches at this stage with regards to their ability to offer accurate semantic interpretation of the data. However, the specificity introduced by the coexistence of spectral and spatial content in the RS datasets widens the scope of the challenges presented to adapt DL methods to these contexts. Therefore, the aim of this paper is firstly to explore the performance of DL architectures for the RS hyperspectral dataset classification and secondly to introduce a new three-dimensional DL approach that enables a joint spectral and spatial information process. A set of three-dimensional schemes is proposed and evaluated. Experimental results based on well knownhyperspectral datasets demonstrate that the proposed method is able to achieve a better classification rate than state of the art methods with lower computational costs.
Behind the Scene: Revealing the Secrets of Pre-trained Vision-and-Language Models
May 15, 2020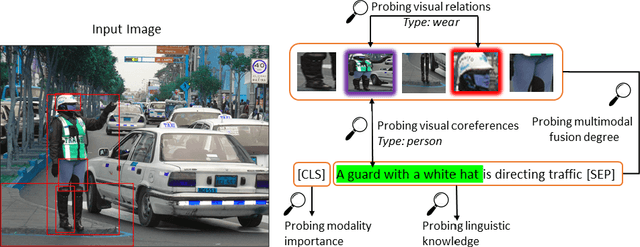

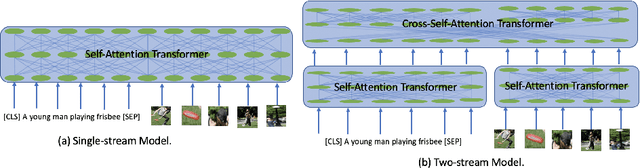
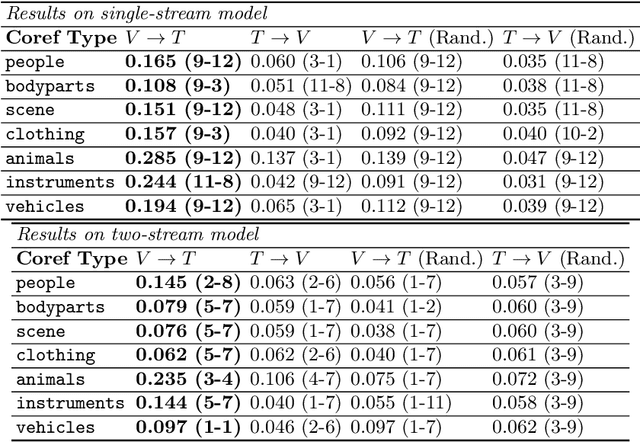
Recent Transformer-based large-scale pre-trained models have revolutionized vision-and-language (V+L) research. Models such as ViLBERT, LXMERT and UNITER have significantly lifted state of the art across a wide range of V+L benchmarks with joint image-text pre-training. However, little is known about the inner mechanisms that destine their impressive success. To reveal the secrets behind the scene of these powerful models, we present VALUE (Vision-And-Language Understanding Evaluation), a set of meticulously designed probing tasks (e.g., Visual Coreference Resolution, Visual Relation Detection, Linguistic Probing Tasks) generalizable to standard pre-trained V+L models, aiming to decipher the inner workings of multimodal pre-training (e.g., the implicit knowledge garnered in individual attention heads, the inherent cross-modal alignment learned through contextualized multimodal embeddings). Through extensive analysis of each archetypal model architecture via these probing tasks, our key observations are: (i) Pre-trained models exhibit a propensity for attending over text rather than images during inference. (ii) There exists a subset of attention heads that are tailored for capturing cross-modal interactions. (iii) Learned attention matrix in pre-trained models demonstrates patterns coherent with the latent alignment between image regions and textual words. (iv) Plotted attention patterns reveal visually-interpretable relations among image regions. (v) Pure linguistic knowledge is also effectively encoded in the attention heads. These are valuable insights serving to guide future work towards designing better model architecture and objectives for multimodal pre-training.
Graph Contrastive Learning with Augmentations
Oct 22, 2020
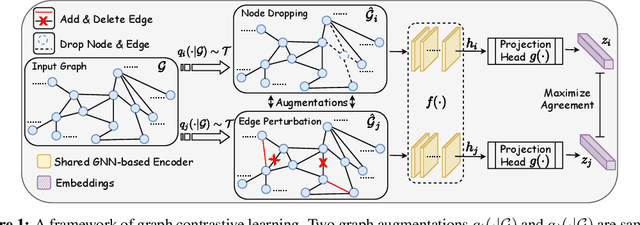

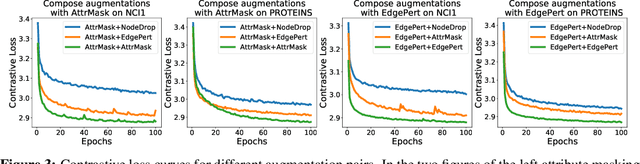
Generalizable, transferrable, and robust representation learning on graph-structured data remains a challenge for current graph neural networks (GNNs). Unlike what has been developed for convolutional neural networks (CNNs) for image data, self-supervised learning and pre-training are less explored for GNNs. In this paper, we propose a graph contrastive learning (GraphCL) framework for learning unsupervised representations of graph data. We first design four types of graph augmentations to incorporate various priors. We then systematically study the impact of various combinations of graph augmentations on multiple datasets, in four different settings: semi-supervised, unsupervised, and transfer learning as well as adversarial attacks. The results show that, even without tuning augmentation extents nor using sophisticated GNN architectures, our GraphCL framework can produce graph representations of similar or better generalizability, transferrability, and robustness compared to state-of-the-art methods. We also investigate the impact of parameterized graph augmentation extents and patterns, and observe further performance gains in preliminary experiments. Our codes are available at https://github.com/Shen-Lab/GraphCL.
Learning to Generate Customized Dynamic 3D Facial Expressions
Jul 21, 2020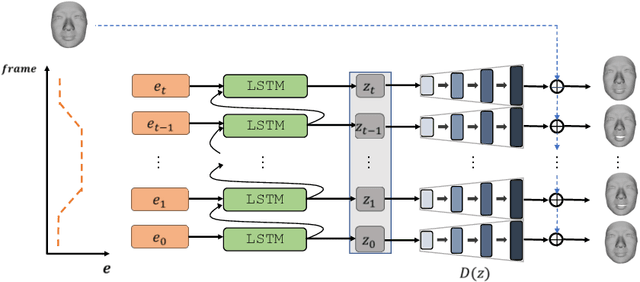
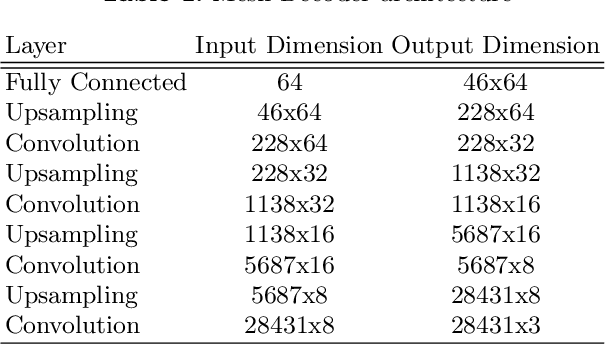
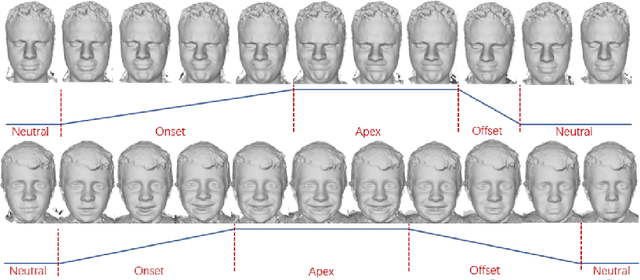

Recent advances in deep learning have significantly pushed the state-of-the-art in photorealistic video animation given a single image. In this paper, we extrapolate those advances to the 3D domain, by studying 3D image-to-video translation with a particular focus on 4D facial expressions. Although 3D facial generative models have been widely explored during the past years, 4D animation remains relatively unexplored. To this end, in this study we employ a deep mesh encoder-decoder like architecture to synthesize realistic high resolution facial expressions by using a single neutral frame along with an expression identification. In addition, processing 3D meshes remains a non-trivial task compared to data that live on grid-like structures, such as images. Given the recent progress in mesh processing with graph convolutions, we make use of a recently introduced learnable operator which acts directly on the mesh structure by taking advantage of local vertex orderings. In order to generalize to 4D facial expressions across subjects, we trained our model using a high resolution dataset with 4D scans of six facial expressions from 180 subjects. Experimental results demonstrate that our approach preserves the subject's identity information even for unseen subjects and generates high quality expressions. To the best of our knowledge, this is the first study tackling the problem of 4D facial expression synthesis.
Learning to Answer Questions From Image Using Convolutional Neural Network
Nov 13, 2015
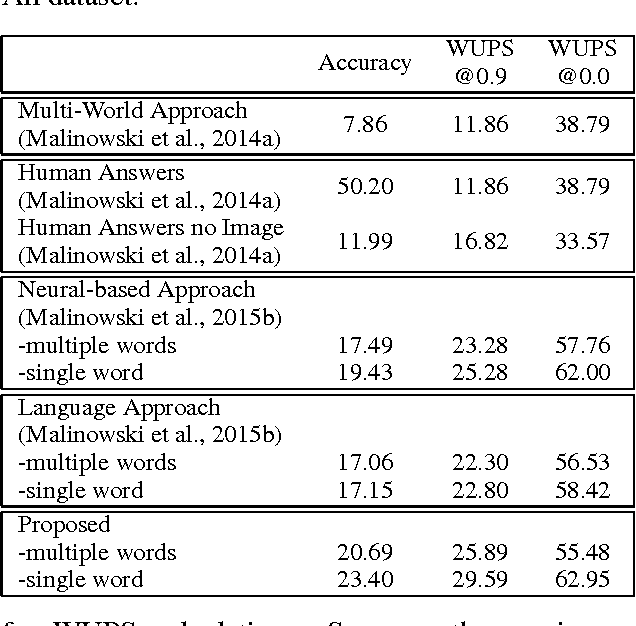
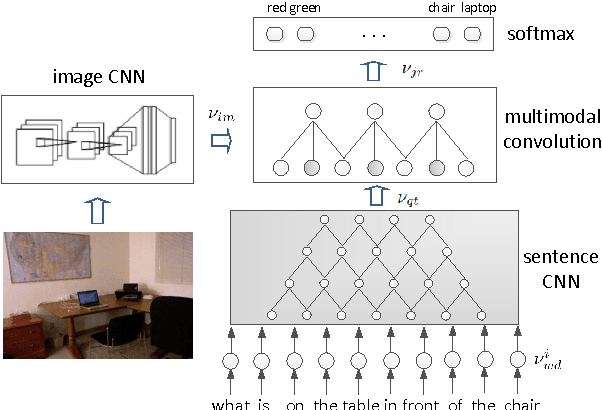
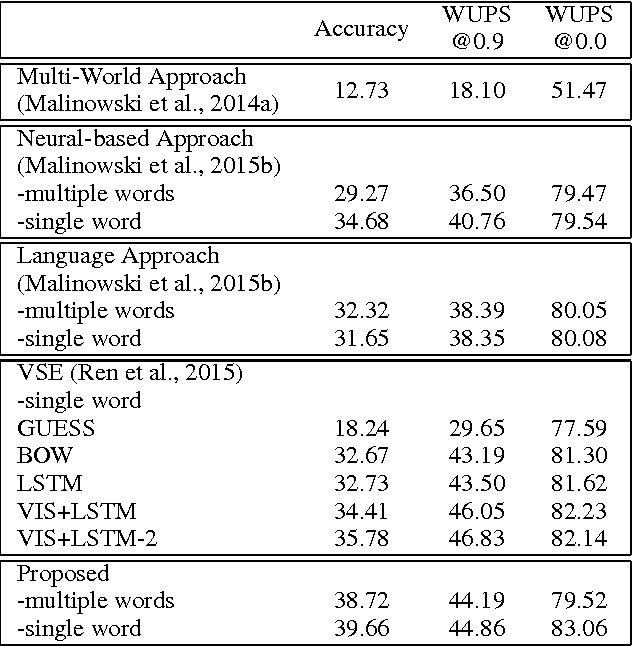
In this paper, we propose to employ the convolutional neural network (CNN) for the image question answering (QA). Our proposed CNN provides an end-to-end framework with convolutional architectures for learning not only the image and question representations, but also their inter-modal interactions to produce the answer. More specifically, our model consists of three CNNs: one image CNN to encode the image content, one sentence CNN to compose the words of the question, and one multimodal convolution layer to learn their joint representation for the classification in the space of candidate answer words. We demonstrate the efficacy of our proposed model on the DAQUAR and COCO-QA datasets, which are two benchmark datasets for the image QA, with the performances significantly outperforming the state-of-the-art.