 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fast Object Detection with Latticed Multi-Scale Feature Fusion
Nov 05, 2020
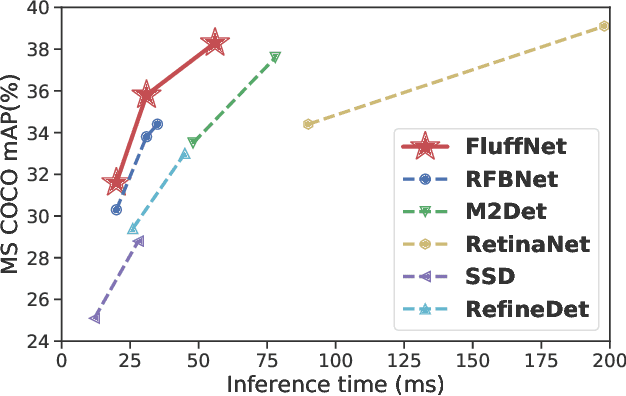
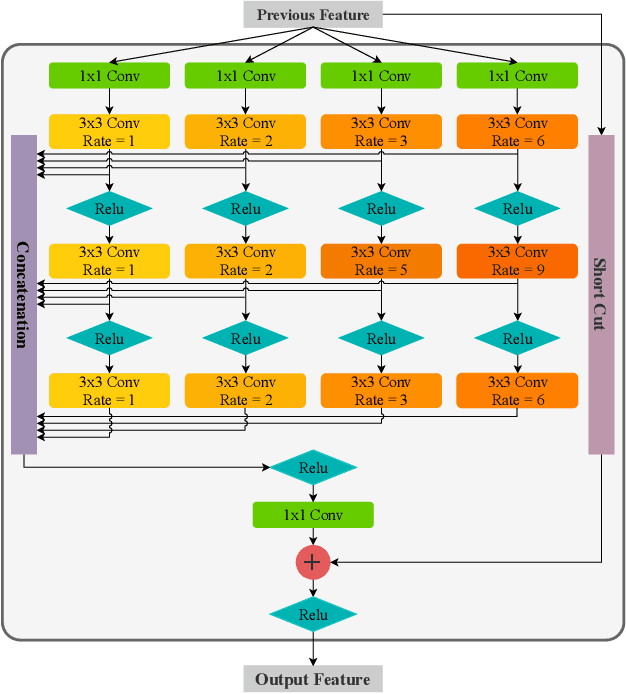
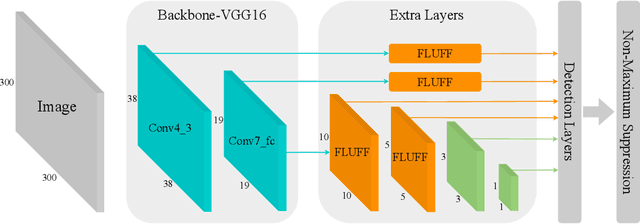
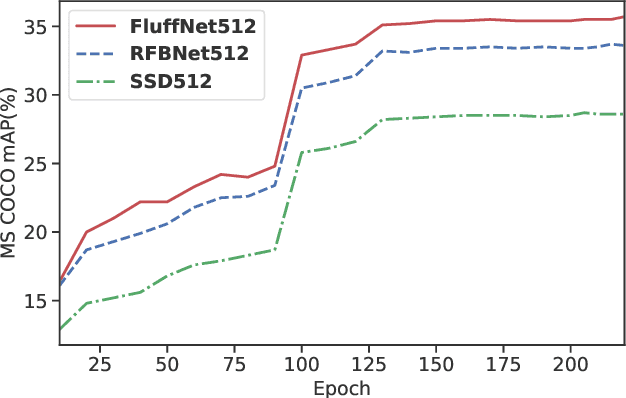
Scale variance is one of the crucial challenges in multi-scale object detection. Early approaches address this problem by exploiting the image and feature pyramid, which raises suboptimal results with computation burden and constrains from inherent network structures. Pioneering works also propose multi-scale (i.e., multi-level and multi-branch) feature fusions to remedy the issue and have achieved encouraging progress. However, existing fusions still have certain limitations such as feature scale inconsistency, ignorance of level-wise semantic transformation, and coarse granularity. In this work, we present a novel module, the Fluff block, to alleviate drawbacks of current multi-scale fusion methods and facilitate multi-scale object detection. Specifically, Fluff leverages both multi-level and multi-branch schemes with dilated convolutions to have rapid, effective and finer-grained feature fusions. Furthermore, we integrate Fluff to SSD as FluffNet, a powerful real-time single-stage detector for multi-scale object detection. Empirical results on MS COCO and PASCAL VOC have demonstrated that FluffNet obtains remarkable efficiency with state-of-the-art accuracy. Additionally, we indicate the great generality of the Fluff block by showing how to embed it to other widely-used detectors as well.
Fast Uncertainty Quantification for Deep Object Pose Estimation
Nov 16, 2020


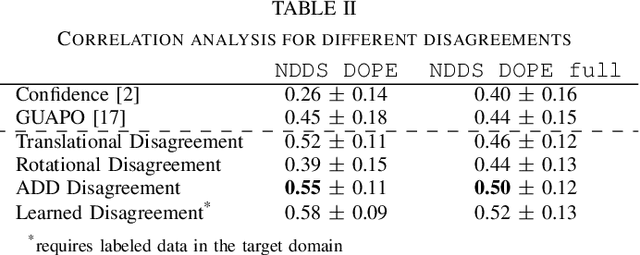
Deep learning-based object pose estimators are often unreliable and overconfident especially when the input image is outside the training domain, for instance, with sim2real transfer. Efficient and robust uncertainty quantification (UQ) in pose estimators is critically needed in many robotic tasks. In this work, we propose a simple, efficient, and plug-and-play UQ method for 6-DoF object pose estimation. We ensemble 2-3 pre-trained models with different neural network architectures and/or training data sources, and compute their average pairwise disagreement against one another to obtain the uncertainty quantification. We propose four disagreement metrics, including a learned metric, and show that the average distance (ADD) is the best learning-free metric and it is only slightly worse than the learned metric, which requires labeled target data. Our method has several advantages compared to the prior art: 1) our method does not require any modification of the training process or the model inputs; and 2) it needs only one forward pass for each model. We evaluate the proposed UQ method on three tasks where our uncertainty quantification yields much stronger correlations with pose estimation errors than the baselines. Moreover, in a real robot grasping task, our method increases the grasping success rate from 35% to 90%.
Fast Adaptation to Super-Resolution Networks via Meta-Learning
Jan 14, 2020
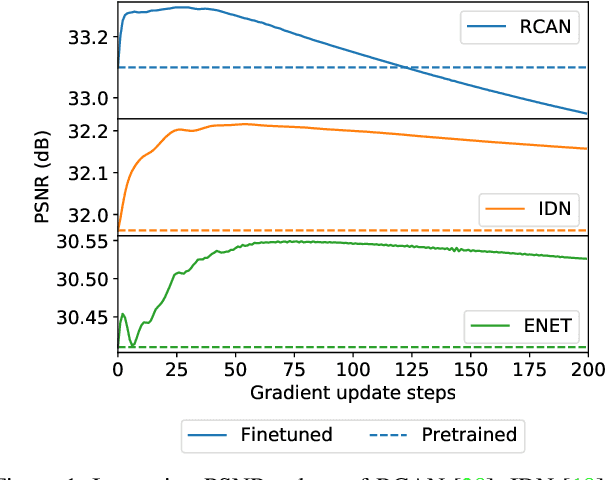
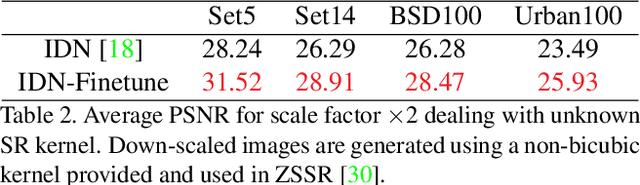
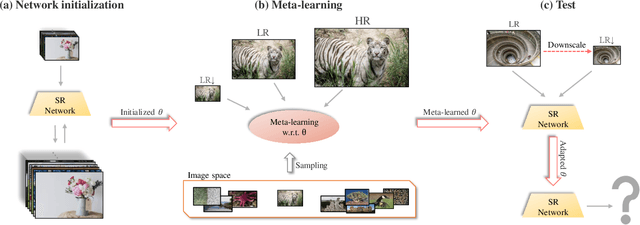
Conventional supervised super-resolution (SR) approaches are trained with massive external SR datasets but fail to exploit desirable properties of the given test image. On the other hand, self-supervised SR approaches utilize the internal information within a test image but suffer from computational complexity in run-time. In this work, we observe the opportunity for further improvement of the performance of SISR without changing the architecture of conventional SR networks by practically exploiting additional information given from the input image. In the training stage, we train the network via meta-learning; thus, the network can quickly adapt to any input image at test time. Then, in the test stage, parameters of this meta-learned network are rapidly fine-tuned with only a few iterations by only using the given low-resolution image. The adaptation at the test time takes full advantage of patch-recurrence property observed in natural images. Our method effectively handles unknown SR kernels and can be applied to any existing model. We demonstrate that the proposed model-agnostic approach consistently improves the performance of conventional SR networks on various benchmark SR datasets.
DPD-InfoGAN: Differentially Private Distributed InfoGAN
Oct 24, 2020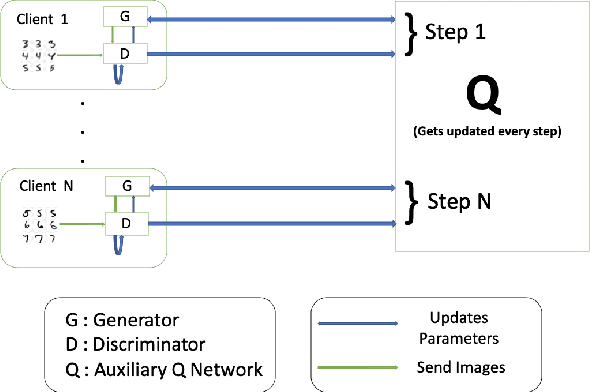
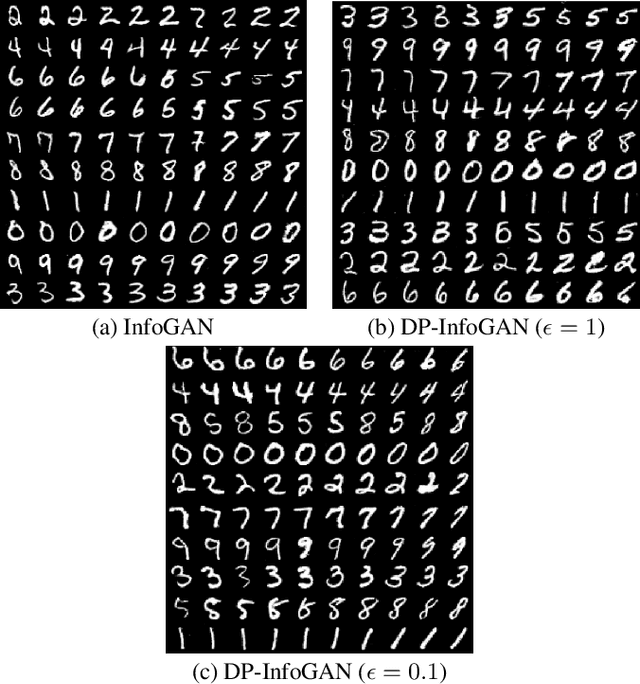


Generative Adversarial Networks (GANs) are deep learning architectures capable of generating synthetic datasets. Despite producing high-quality synthetic images, the default GAN has no control over the kinds of images it generates. The Information Maximizing GAN (InfoGAN) is a variant of the default GAN that introduces feature-control variables that are automatically learned by the framework, hence providing greater control over the different kinds of images produced. Due to the high model complexity of InfoGAN, the generative distribution tends to be concentrated around the training data points. This is a critical problem as the models may inadvertently expose the sensitive and private information present in the dataset. To address this problem, we propose a differentially private version of InfoGAN (DP-InfoGAN). We also extend our framework to a distributed setting (DPD-InfoGAN) to allow clients to learn different attributes present in other clients' datasets in a privacy-preserving manner. In our experiments, we show that both DP-InfoGAN and DPD-InfoGAN can synthesize high-quality images with flexible control over image attributes while preserving privacy.
Learning to Transfer Texture from Clothing Images to 3D Humans
Mar 30, 2020
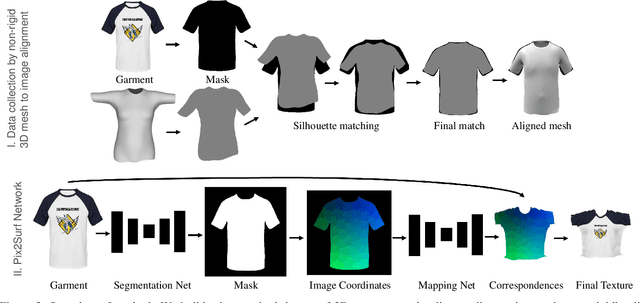

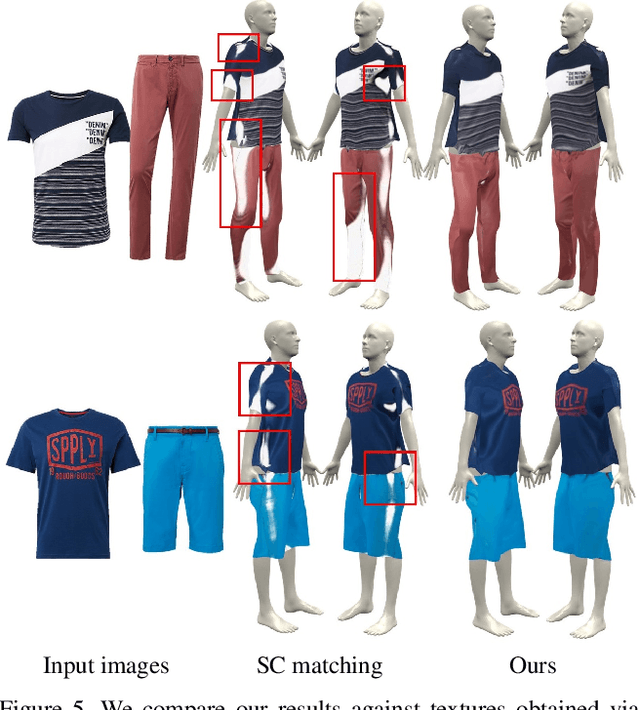
In this paper, we present a simple yet effective method to automatically transfer textures of clothing images (front and back) to 3D garments worn on top SMPL, in real time. We first automatically compute training pairs of images with aligned 3D garments using a custom non-rigid 3D to 2D registration method, which is accurate but slow. Using these pairs, we learn a mapping from pixels to the 3D garment surface. Our idea is to learn dense correspondences from garment image silhouettes to a 2D-UV map of a 3D garment surface using shape information alone, completely ignoring texture, which allows us to generalize to the wide range of web images. Several experiments demonstrate that our model is more accurate than widely used baselines such as thin-plate-spline warping and image-to-image translation networks while being orders of magnitude faster. Our model opens the door for applications such as virtual try-on, and allows for generation of 3D humans with varied textures which is necessary for learning.
Efficient Decentralized Visual Place Recognition From Full-Image Descriptors
May 30, 2017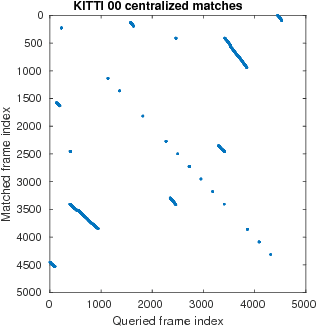
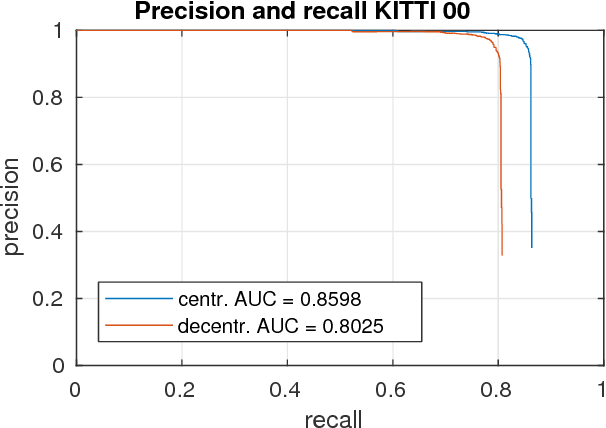
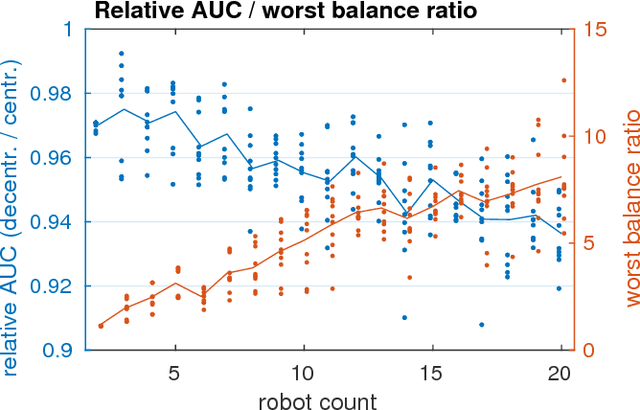
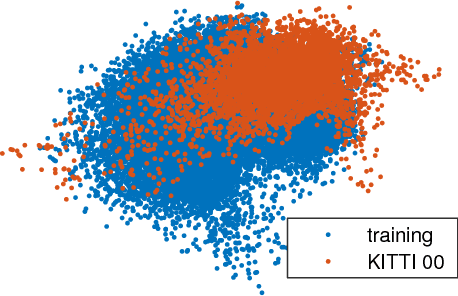
In this paper, we discuss the adaptation of our decentralized place recognition method described in [1] to full image descriptors. As we had shown, the key to making a scalable decentralized visual place recognition lies in exploting deterministic key assignment in a distributed key-value map. Through this, it is possible to reduce bandwidth by up to a factor of n, the robot count, by casting visual place recognition to a key-value lookup problem. In [1], we exploited this for the bag-of-words method [3], [4]. Our method of casting bag-of-words, however, results in a complex decentralized system, which has inherently worse recall than its centralized counterpart. In this paper, we instead start from the recent full-image description method NetVLAD [5]. As we show, casting this to a key-value lookup problem can be achieved with k-means clustering, and results in a much simpler system than [1]. The resulting system still has some flaws, albeit of a completely different nature: it suffers when the environment seen during deployment lies in a different distribution in feature space than the environment seen during training.
* 3 pages, 4 figures. This is a self-published paper that accompanies our original work [1] as well as the ICRA 2017 Workshop on Multi-robot Perception-Driven Control and Planning [2]
Prominent Attribute Modification using Attribute Dependent Generative Adversarial Network
Apr 24, 2020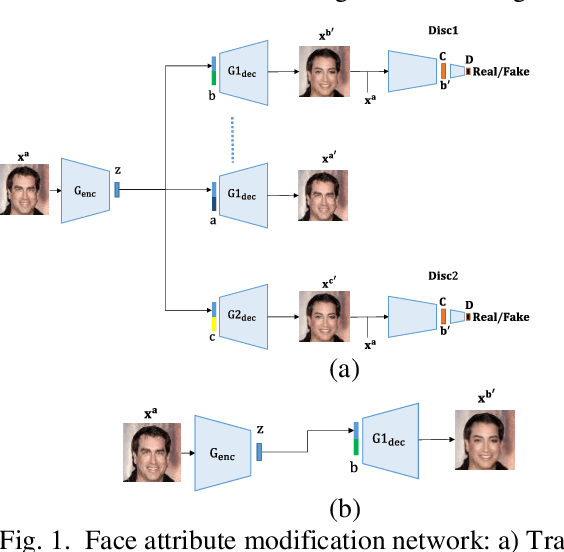



Modifying the facial images with desired attributes is important, though challenging tasks in computer vision, where it aims to modify single or multiple attributes of the face image. Some of the existing methods are either based on attribute independent approaches where the modification is done in the latent representation or attribute dependent approaches. The attribute independent methods are limited in performance as they require the desired paired data for changing the desired attributes. Secondly, the attribute independent constraint may result in the loss of information and, hence, fail in generating the required attributes in the face image. In contrast, the attribute dependent approaches are effective as these approaches are capable of modifying the required features along with preserving the information in the given image. However, attribute dependent approaches are sensitive and require a careful model design in generating high-quality results. To address this problem, we propose an attribute dependent face modification approach. The proposed approach is based on two generators and two discriminators that utilize the binary as well as the real representation of the attributes and, in return, generate high-quality attribute modification results. Experiments on the CelebA dataset show that our method effectively performs the multiple attribute editing with preserving other facial details intactly.
Latent Normalizing Flows for Many-to-Many Cross-Domain Mappings
Feb 16, 2020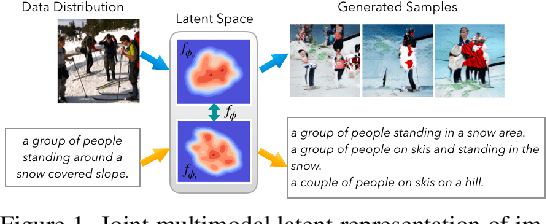
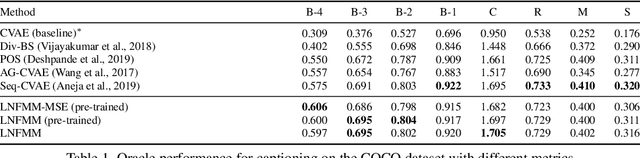
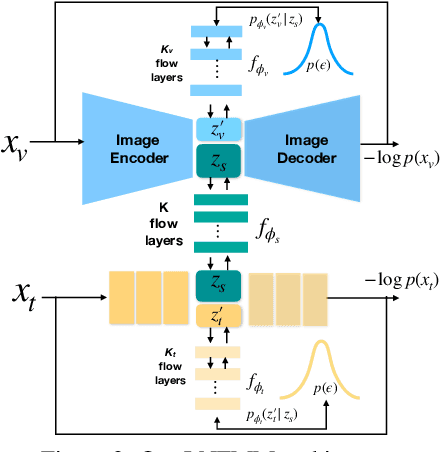
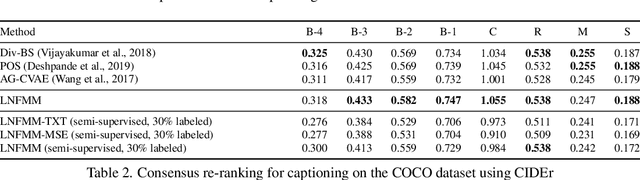
Learned joint representations of images and text form the backbone of several important cross-domain tasks such as image captioning. Prior work mostly maps both domains into a common latent representation in a purely supervised fashion. This is rather restrictive, however, as the two domains follow distinct generative processes. Therefore, we propose a novel semi-supervised framework, which models shared information between domains and domain-specific information separately. The information shared between the domains is aligned with an invertible neural network. Our model integrates normalizing flow-based priors for the domain-specific information, which allows us to learn diverse many-to-many mappings between the two domains. We demonstrate the effectiveness of our model on diverse tasks, including image captioning and text-to-image synthesis.
A Two-Stage Multiple Instance Learning Framework for the Detection of Breast Cancer in Mammograms
Apr 24, 2020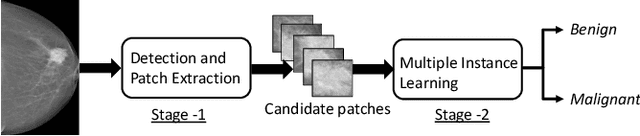
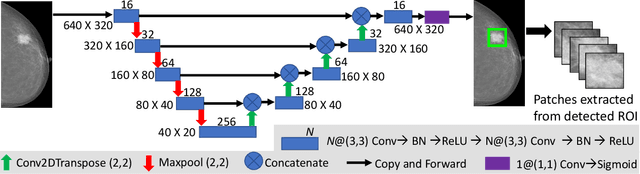
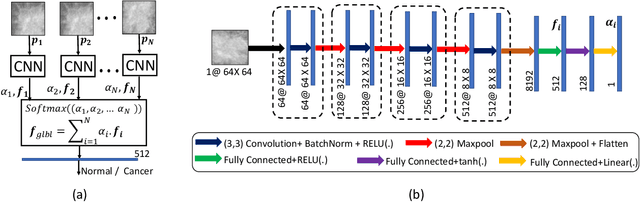
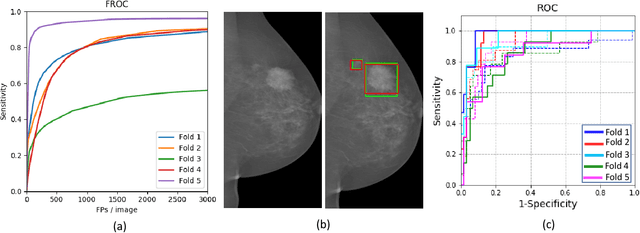
Mammograms are commonly employed in the large scale screening of breast cancer which is primarily characterized by the presence of malignant masses. However, automated image-level detection of malignancy is a challenging task given the small size of the mass regions and difficulty in discriminating between malignant, benign mass and healthy dense fibro-glandular tissue. To address these issues, we explore a two-stage Multiple Instance Learning (MIL) framework. A Convolutional Neural Network (CNN) is trained in the first stage to extract local candidate patches in the mammograms that may contain either a benign or malignant mass. The second stage employs a MIL strategy for an image level benign vs. malignant classification. A global image-level feature is computed as a weighted average of patch-level features learned using a CNN. Our method performed well on the task of localization of masses with an average Precision/Recall of 0.76/0.80 and acheived an average AUC of 0.91 on the imagelevel classification task using a five-fold cross-validation on the INbreast dataset. Restricting the MIL only to the candidate patches extracted in Stage 1 led to a significant improvement in classification performance in comparison to a dense extraction of patches from the entire mammogram.
Harnessing spatial homogeneity of neuroimaging data: patch individual filter layers for CNNs
Jul 23, 2020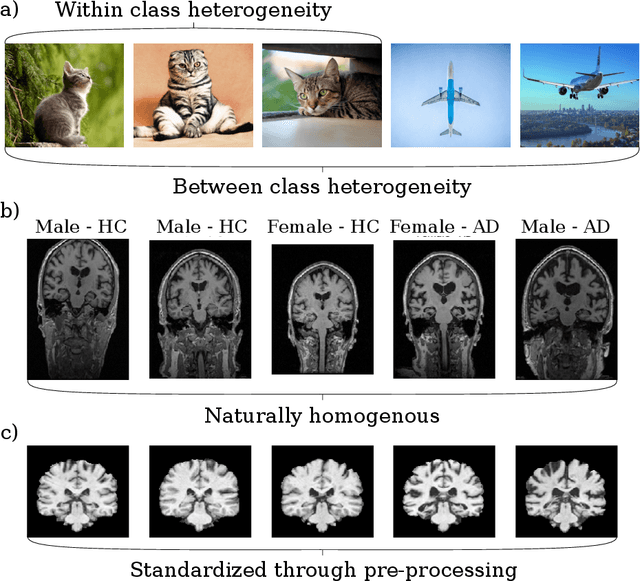
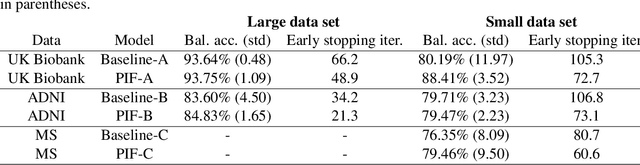
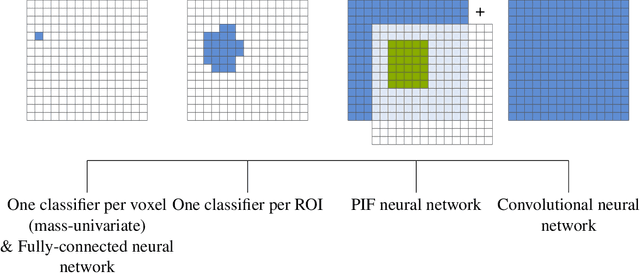
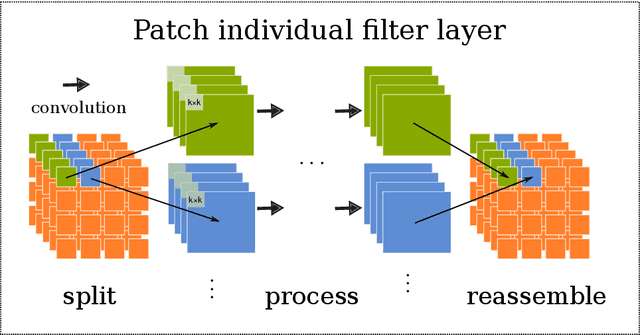
Neuroimaging data, e.g. obtained from magnetic resonance imaging (MRI), is comparably homogeneous due to (1) the uniform structure of the brain and (2) additional efforts to spatially normalize the data to a standard template using linear and non-linear transformations. Convolutional neural networks (CNNs), in contrast, have been specifically designed for highly heterogeneous data, such as natural images, by sliding convolutional filters over different positions in an image. Here, we suggest a new CNN architecture that combines the idea of hierarchical abstraction in neural networks with a prior on the spatial homogeneity of neuroimaging data: Whereas early layers are trained globally using standard convolutional layers, we introduce for higher, more abstract layers patch individual filters (PIF). By learning filters in individual image regions (patches) without sharing weights, PIF layers can learn abstract features faster and with fewer samples. We thoroughly evaluated PIF layers for three different tasks and data sets, namely sex classification on UK Biobank data, Alzheimer's disease detection on ADNI data and multiple sclerosis detection on private hospital data. We demonstrate that CNNs using PIF layers result in higher accuracies, especially in low sample size settings, and need fewer training epochs for convergence. To the best of our knowledge, this is the first study which introduces a prior on brain MRI for CNN learning.