 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dense Semantic 3D Map Based Long-Term Visual Localization with Hybrid Features
May 21, 2020
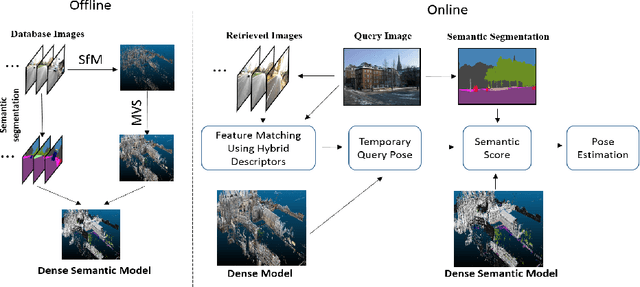
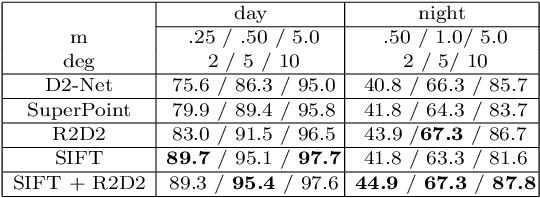

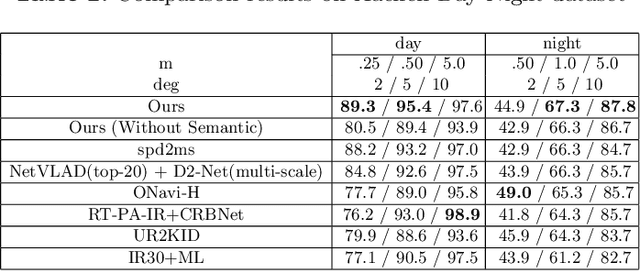
Visual localization plays an important role in many applications. However, due to the large appearance variations such as season and illumination changes, as well as weather and day-night variations, it's still a big challenge for robust long-term visual localization algorithms. In this paper, we present a novel visual localization method using hybrid handcrafted and learned features with dense semantic 3D map. Hybrid features help us to make full use of their strengths in different imaging conditions, and the dense semantic map provide us reliable and complete geometric and semantic information for constructing sufficient 2D-3D matching pairs with semantic consistency scores. In our pipeline, we retrieve and score each candidate database image through the semantic consistency between the dense model and the query image. Then the semantic consistency score is used as a soft constraint in the weighted RANSAC-based PnP pose solver. Experimental results on long-term visual localization benchmarks demonstrate the effectiveness of our method compared with state-of-the-arts.
A statistical theory of semi-supervised learning
Aug 13, 2020
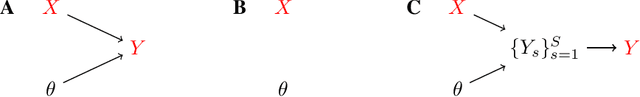
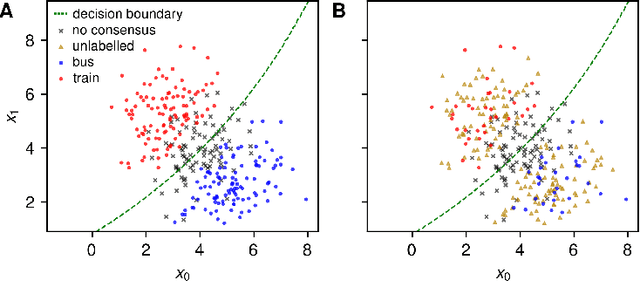
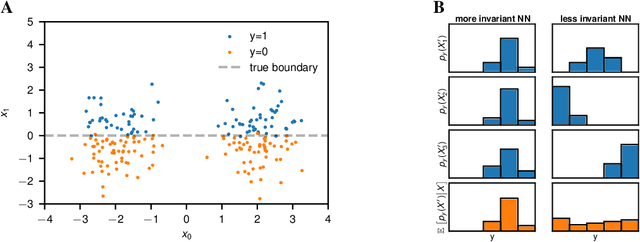
We currently lack a solid statistical understanding of semi-supervised learning methods, instead treating them as a collection of highly effective tricks. This precludes the principled combination e.g. of Bayesian methods and semi-supervised learning, as semi-supervised learning objectives are not currently formulated as likelihoods for an underlying generative model of the data. Here, we note that standard image benchmark datasets such as CIFAR-10 are carefully curated, and we provide a generative model describing the curation process. Under this generative model, several state-of-the-art semi-supervised learning techniques, including entropy minimization, pseudo-labelling and the FixMatch family emerge naturally as variational lower-bounds on the log-likelihood.
Stacked U-Nets: A No-Frills Approach to Natural Image Segmentation
Apr 27, 2018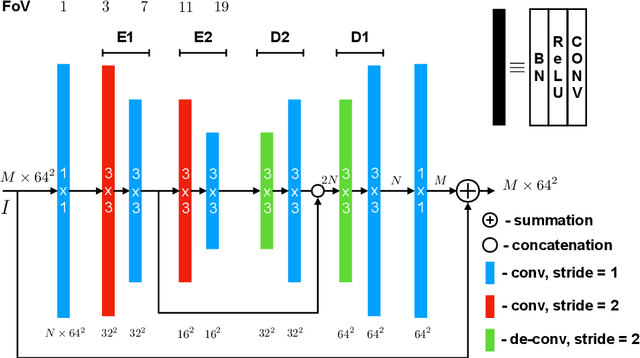
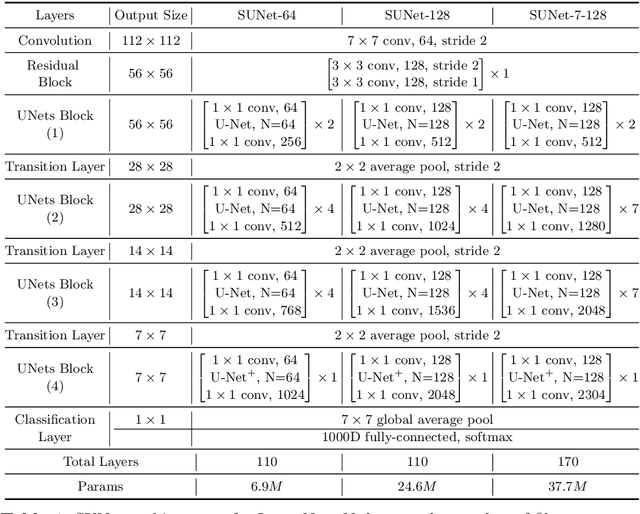
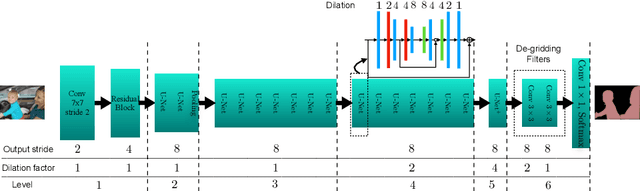
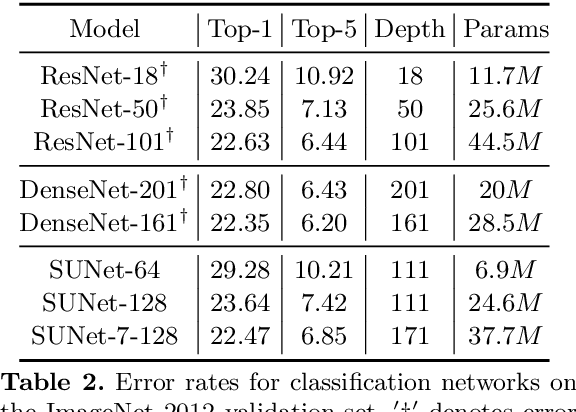
Many imaging tasks require global information about all pixels in an image. Conventional bottom-up classification networks globalize information by decreasing resolution; features are pooled and downsampled into a single output. But for semantic segmentation and object detection tasks, a network must provide higher-resolution pixel-level outputs. To globalize information while preserving resolution, many researchers propose the inclusion of sophisticated auxiliary blocks, but these come at the cost of a considerable increase in network size and computational cost. This paper proposes stacked u-nets (SUNets), which iteratively combine features from different resolution scales while maintaining resolution. SUNets leverage the information globalization power of u-nets in a deeper network architectures that is capable of handling the complexity of natural images. SUNets perform extremely well on semantic segmentation tasks using a small number of parameters.
Spatiotemporal Imaging with Diffeomorphic Optimal Transportation
Nov 24, 2020
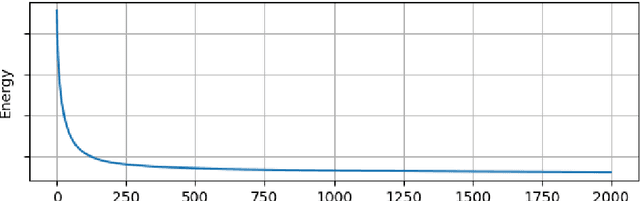

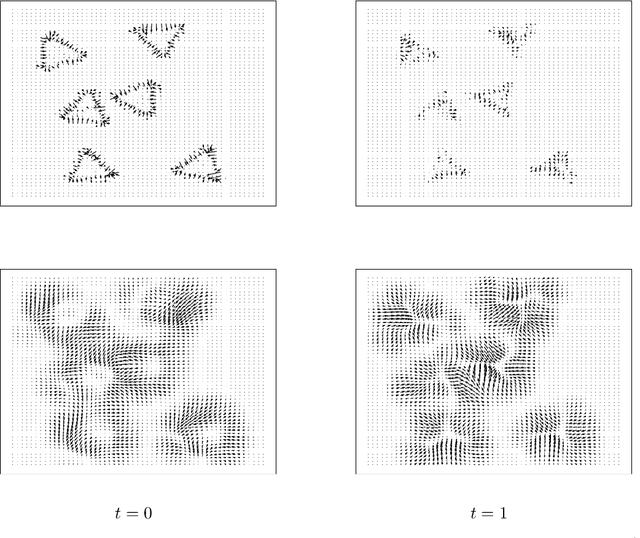
We propose a variational model with diffeomorphic optimal transportation for joint image reconstruction and motion estimation. The proposed model is a production of assembling the Wasserstein distance with the Benamou--Brenier formula in optimal transportation and the flow of diffeomorphisms involved in large deformation diffeomorphic metric mapping, which is suitable for the scenario of spatiotemporal imaging with large diffeomorphic and mass-preserving deformations. Specifically, we first use the Benamou--Brenier formula to characterize the optimal transport cost among the flow of mass-preserving images, and restrict the velocity field into the admissible Hilbert space to guarantee the generated deformation flow being diffeomorphic. We then gain the ODE-constrained equivalent formulation for Benamou--Brenier formula. We finally obtain the proposed model with ODE constraint following the framework that presented in our previous work. We further get the equivalent PDE-constrained optimal control formulation. The proposed model is compared against several existing alternatives theoretically. The alternating minimization algorithm is presented for solving the time-discretized version of the proposed model with ODE constraint. Several important issues on the proposed model and associated algorithms are also discussed. Particularly, we present several potential models based on the proposed diffeomorphic optimal transportation. Under appropriate conditions, the proposed algorithm also provides a new scheme to solve the models using quadratic Wasserstein distance. The performance is finally evaluated by several numerical experiments in space-time tomography, where the data is measured from the concerned sequential images with sparse views and/or various noise levels.
Learning Normalized Inputs for Iterative Estimation in Medical Image Segmentation
Feb 16, 2017
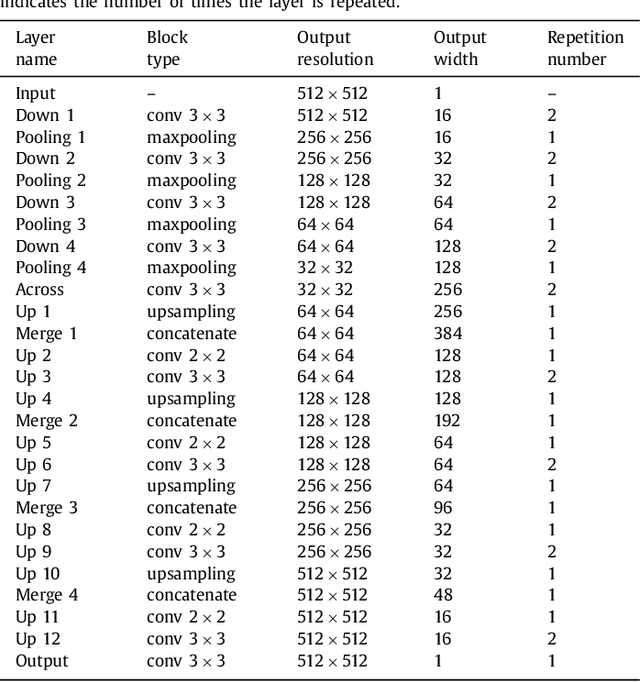
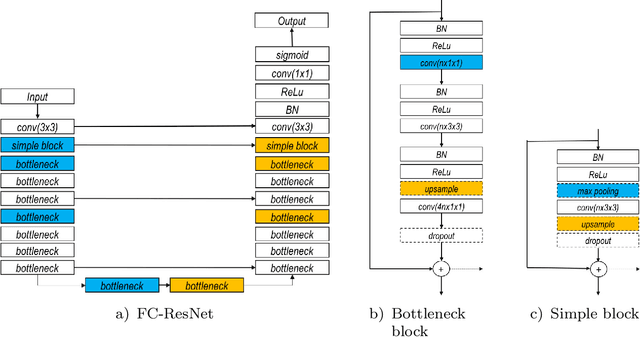
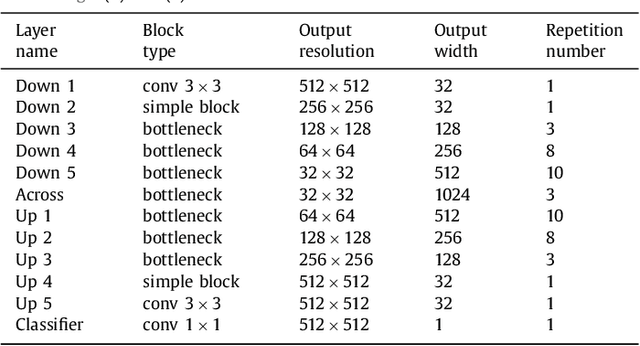
In this paper, we introduce a simple, yet powerful pipeline for medical image segmentation that combines Fully Convolutional Networks (FCNs) with Fully Convolutional Residual Networks (FC-ResNets). We propose and examine a design that takes particular advantage of recent advances in the understanding of both Convolutional Neural Networks as well as ResNets. Our approach focuses upon the importance of a trainable pre-processing when using FC-ResNets and we show that a low-capacity FCN model can serve as a pre-processor to normalize medical input data. In our image segmentation pipeline, we use FCNs to obtain normalized images, which are then iteratively refined by means of a FC-ResNet to generate a segmentation prediction. As in other fully convolutional approaches, our pipeline can be used off-the-shelf on different image modalities. We show that using this pipeline, we exhibit state-of-the-art performance on the challenging Electron Microscopy benchmark, when compared to other 2D methods. We improve segmentation results on CT images of liver lesions, when contrasting with standard FCN methods. Moreover, when applying our 2D pipeline on a challenging 3D MRI prostate segmentation challenge we reach results that are competitive even when compared to 3D methods. The obtained results illustrate the strong potential and versatility of the pipeline by achieving highly accurate results on multi-modality images from different anatomical regions and organs.
Stochastic Precision Ensemble: Self-Knowledge Distillation for Quantized Deep Neural Networks
Sep 30, 2020
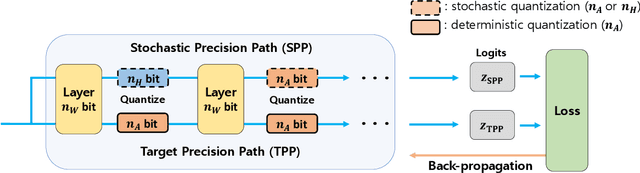
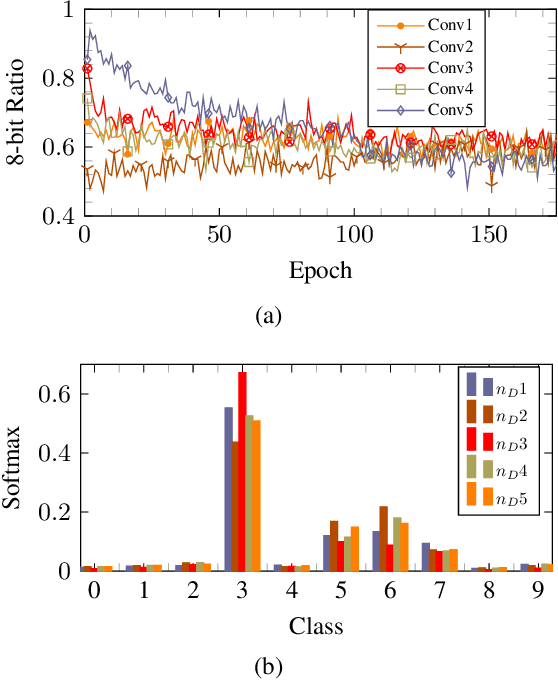
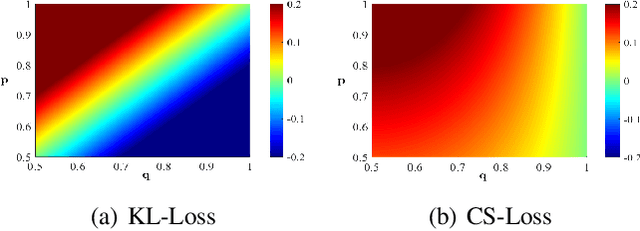
The quantization of deep neural networks (QDNNs) has been actively studied for deployment in edge devices. Recent studies employ the knowledge distillation (KD) method to improve the performance of quantized networks. In this study, we propose stochastic precision ensemble training for QDNNs (SPEQ). SPEQ is a knowledge distillation training scheme; however, the teacher is formed by sharing the model parameters of the student network. We obtain the soft labels of the teacher by changing the bit precision of the activation stochastically at each layer of the forward-pass computation. The student model is trained with these soft labels to reduce the activation quantization noise. The cosine similarity loss is employed, instead of the KL-divergence, for KD training. As the teacher model changes continuously by random bit-precision assignment, it exploits the effect of stochastic ensemble KD. SPEQ outperforms the existing quantization training methods in various tasks, such as image classification, question-answering, and transfer learning without the need for cumbersome teacher networks.
Recurrent Image Captioner: Describing Images with Spatial-Invariant Transformation and Attention Filtering
Dec 15, 2016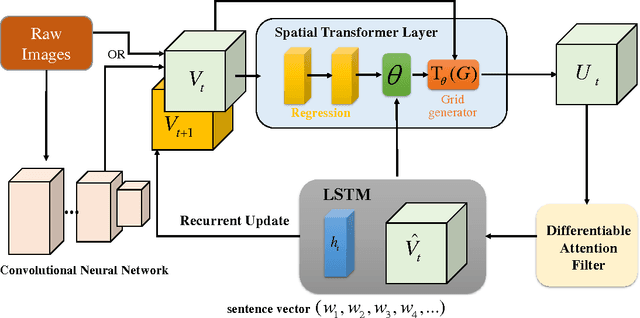
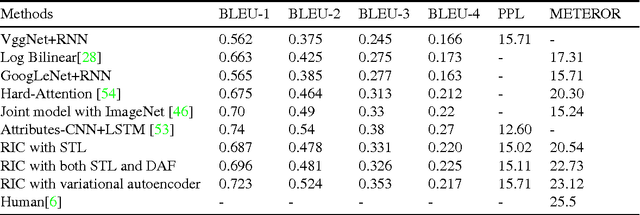
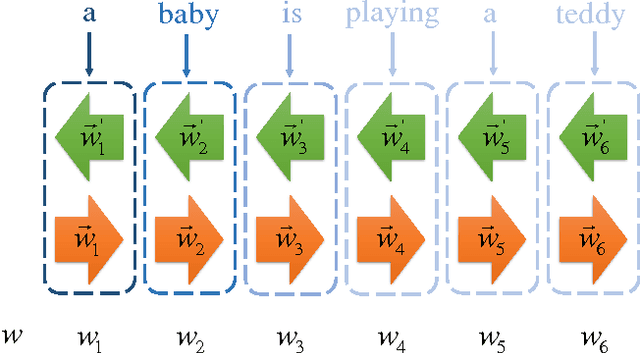
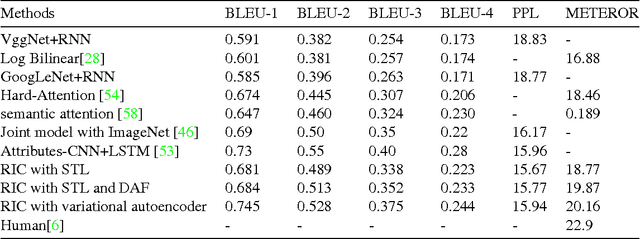
Along with the prosperity of recurrent neural network in modelling sequential data and the power of attention mechanism in automatically identify salient information, image captioning, a.k.a., image description, has been remarkably advanced in recent years. Nonetheless, most existing paradigms may suffer from the deficiency of invariance to images with different scaling, rotation, etc.; and effective integration of standalone attention to form a holistic end-to-end system. In this paper, we propose a novel image captioning architecture, termed Recurrent Image Captioner (\textbf{RIC}), which allows visual encoder and language decoder to coherently cooperate in a recurrent manner. Specifically, we first equip CNN-based visual encoder with a differentiable layer to enable spatially invariant transformation of visual signals. Moreover, we deploy an attention filter module (differentiable) between encoder and decoder to dynamically determine salient visual parts. We also employ bidirectional LSTM to preprocess sentences for generating better textual representations. Besides, we propose to exploit variational inference to optimize the whole architecture. Extensive experimental results on three benchmark datasets (i.e., Flickr8k, Flickr30k and MS COCO) demonstrate the superiority of our proposed architecture as compared to most of the state-of-the-art methods.
Self-Supervised Multi-View Synchronization Learning for 3D Pose Estimation
Oct 13, 2020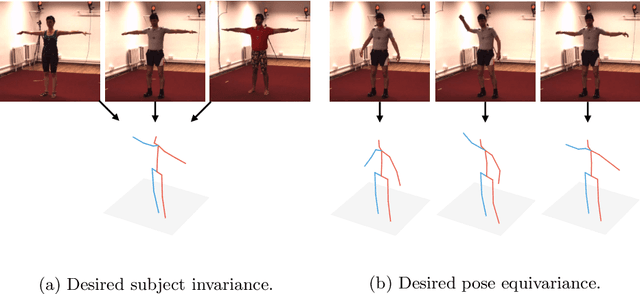
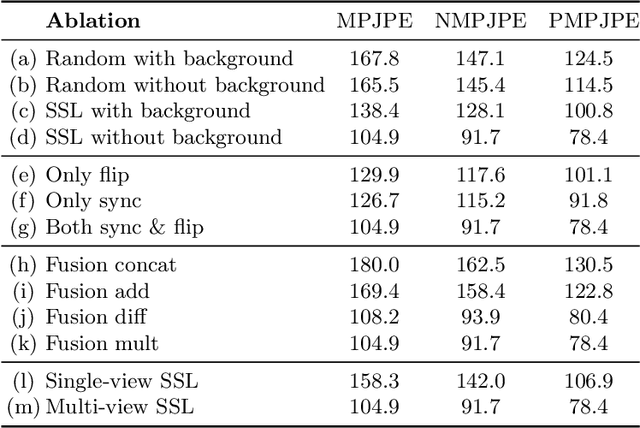
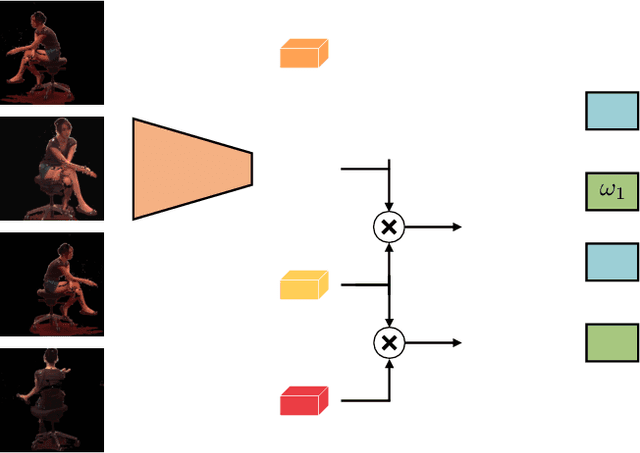
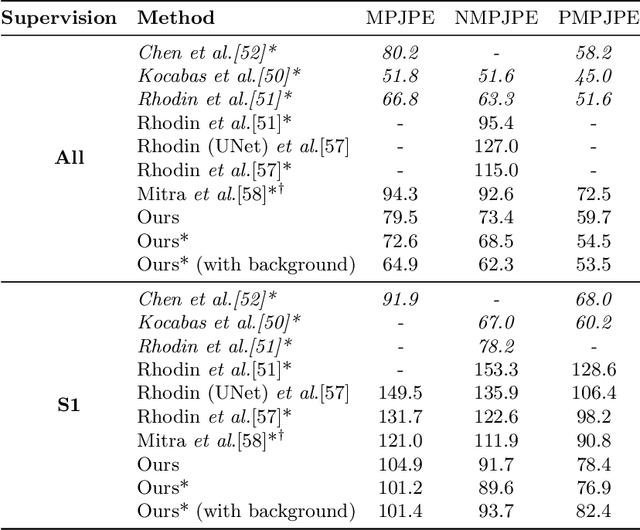
Current state-of-the-art methods cast monocular 3D human pose estimation as a learning problem by training neural networks on large data sets of images and corresponding skeleton poses. In contrast, we propose an approach that can exploit small annotated data sets by fine-tuning networks pre-trained via self-supervised learning on (large) unlabeled data sets. To drive such networks towards supporting 3D pose estimation during the pre-training step, we introduce a novel self-supervised feature learning task designed to focus on the 3D structure in an image. We exploit images extracted from videos captured with a multi-view camera system. The task is to classify whether two images depict two views of the same scene up to a rigid transformation. In a multi-view data set, where objects deform in a non-rigid manner, a rigid transformation occurs only between two views taken at the exact same time, i.e., when they are synchronized. We demonstrate the effectiveness of the synchronization task on the Human3.6M data set and achieve state-of-the-art results in 3D human pose estimation.
Learning Image Matching by Simply Watching Video
Mar 29, 2016

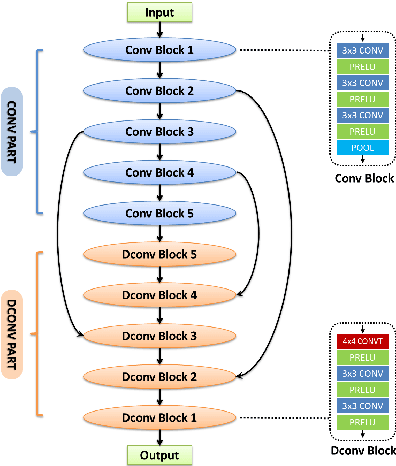
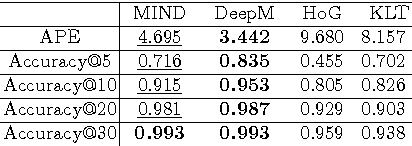
This work presents an unsupervised learning based approach to the ubiquitous computer vision problem of image matching. We start from the insight that the problem of frame-interpolation implicitly solves for inter-frame correspondences. This permits the application of analysis-by-synthesis: we firstly train and apply a Convolutional Neural Network for frame-interpolation, then obtain correspondences by inverting the learned CNN. The key benefit behind this strategy is that the CNN for frame-interpolation can be trained in an unsupervised manner by exploiting the temporal coherency that is naturally contained in real-world video sequences. The present model therefore learns image matching by simply watching videos. Besides a promise to be more generally applicable, the presented approach achieves surprising performance comparable to traditional empirically designed methods.
Needle tip force estimation by deep learning from raw spectral OCT data
Jun 30, 2020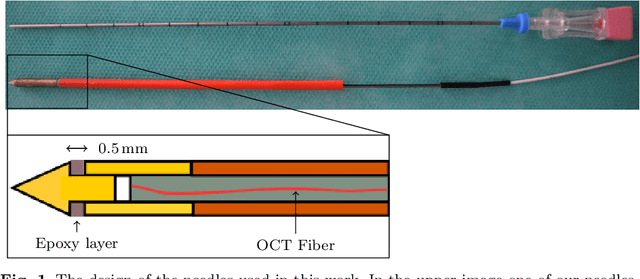
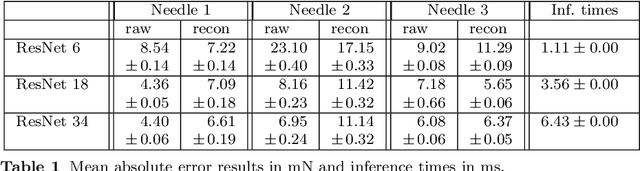

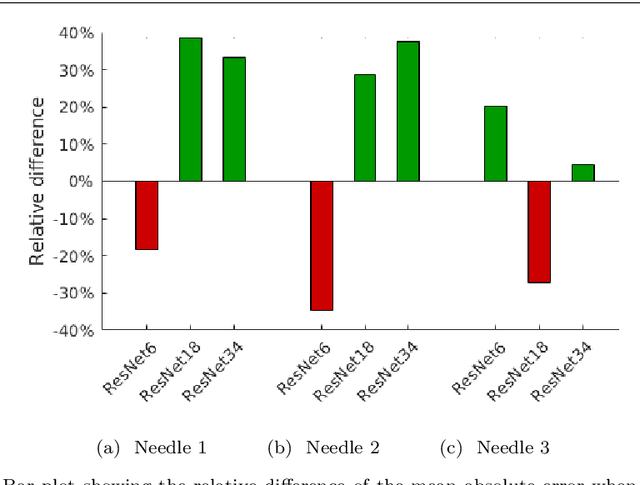
Purpose. Needle placement is a challenging problem for applications such as biopsy or brachytherapy. Tip force sensing can provide valuable feedback for needle navigation inside the tissue. For this purpose, fiber-optical sensors can be directly integrated into the needle tip. Optical coherence tomography (OCT) can be used to image tissue. Here, we study how to calibrate OCT to sense forces, e.g. during robotic needle placement. Methods. We investigate whether using raw spectral OCT data without a typical image reconstruction can improve a deep learning-based calibration between optical signal and forces. For this purpose, we consider three different needles with a new, more robust design which are calibrated using convolutional neural networks (CNNs). We compare training the CNNs with the raw OCT signal and the reconstructed depth profiles. Results. We find that using raw data as an input for the largest CNN model outperforms the use of reconstructed data with a mean absolute error of 5.81 mN compared to 8.04 mN. Conclusions. We find that deep learning with raw spectral OCT data can improve learning for the task of force estimation. Our needle design and calibration approach constitute a very accurate fiber-optical sensor for measuring forces at the needle tip.