 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Weakly Supervised Fine-Grained Image Categorization
Apr 20, 2015
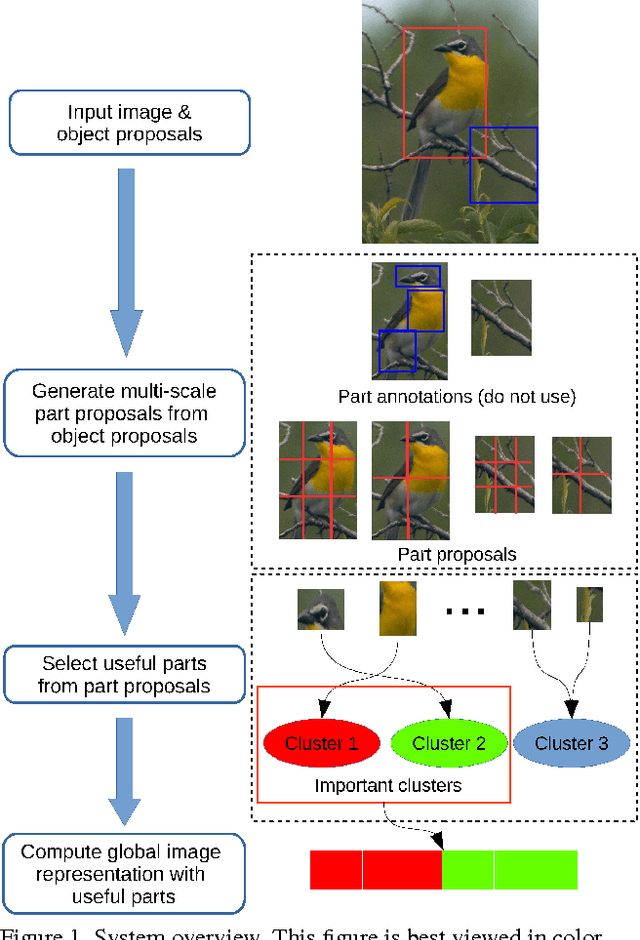
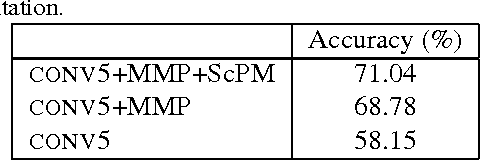
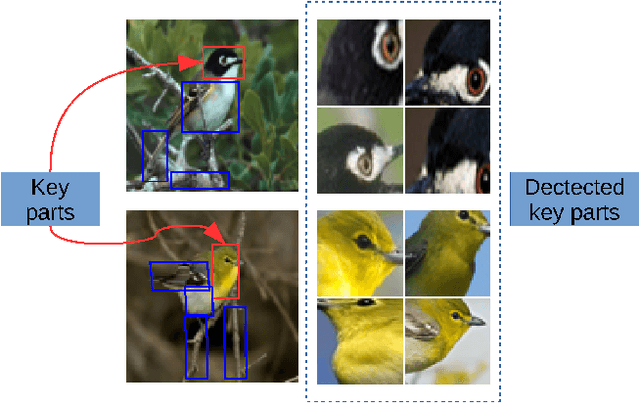
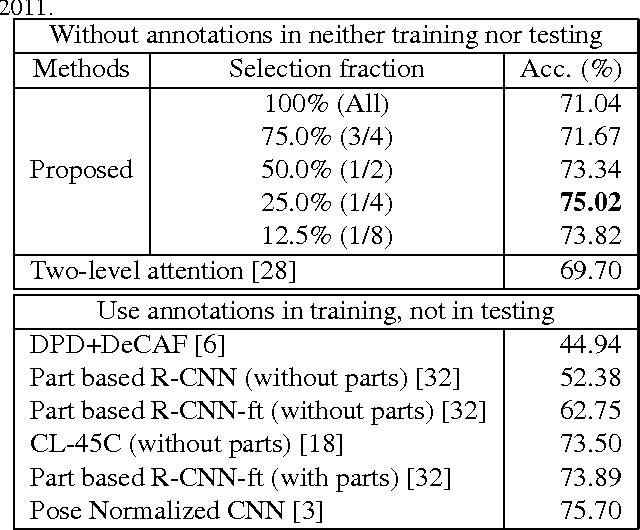
In this paper, we categorize fine-grained images without using any object / part annotation neither in the training nor in the testing stage, a step towards making it suitable for deployments. Fine-grained image categorization aims to classify objects with subtle distinctions. Most existing works heavily rely on object / part detectors to build the correspondence between object parts by using object or object part annotations inside training images. The need for expensive object annotations prevents the wide usage of these methods. Instead, we propose to select useful parts from multi-scale part proposals in objects, and use them to compute a global image representation for categorization. This is specially designed for the annotation-free fine-grained categorization task, because useful parts have shown to play an important role in existing annotation-dependent works but accurate part detectors can be hardly acquired. With the proposed image representation, we can further detect and visualize the key (most discriminative) parts in objects of different classes. In the experiment, the proposed annotation-free method achieves better accuracy than that of state-of-the-art annotation-free and most existing annotation-dependent methods on two challenging datasets, which shows that it is not always necessary to use accurate object / part annotations in fine-grained image categorization.
Robust navigation with tinyML for autonomous mini-vehicles
Jul 01, 2020

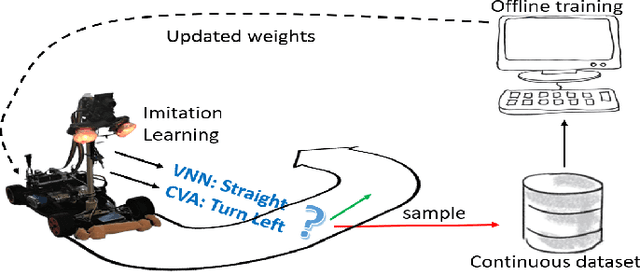
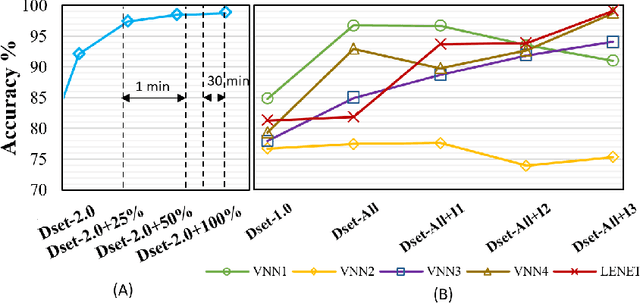
Autonomous navigation vehicles have rapidly improved thanks to the breakthroughs of Deep Learning. However, scaling autonomous driving to low-power and real-time systems deployed on dynamic environments poses several challenges that prevent their adoption. In this work, we show an end-to-end integration of data, algorithms, and deployment tools that enables the deployment of a family of tiny-CNNs on extra-low-power MCUs for autonomous driving mini-vehicles (image classification task). Our end-to-end environment enables a closed-loop learning system that allows the CNNs (learners) to learn through demonstration by imitating the original computer-vision algorithm (teacher) while doubling the throughput. Thereby, our CNNs gain robustness to lighting conditions and increase their accuracy up to 20% when deployed in the most challenging setup with a very fast-rate camera. Further, we leverage GAP8, a parallel ultra-low-power RISC-V SoC, to meet the real-time requirements. When running a family of CNN for an image classification task, GAP8 reduces their latency by over 20x compared to using an STM32L4 (Cortex-M4) or obtains +21.4% accuracy than an NXP k64f (Cortex-M4) solution with the same energy budget.
Self-Supervised 3D Human Pose Estimation via Part Guided Novel Image Synthesis
Apr 09, 2020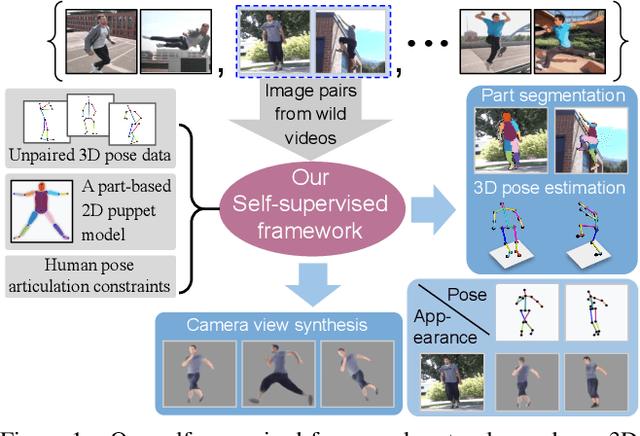
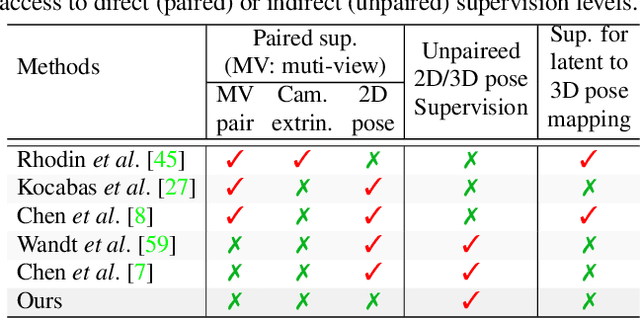
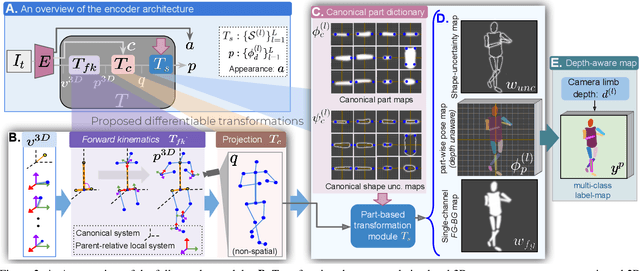
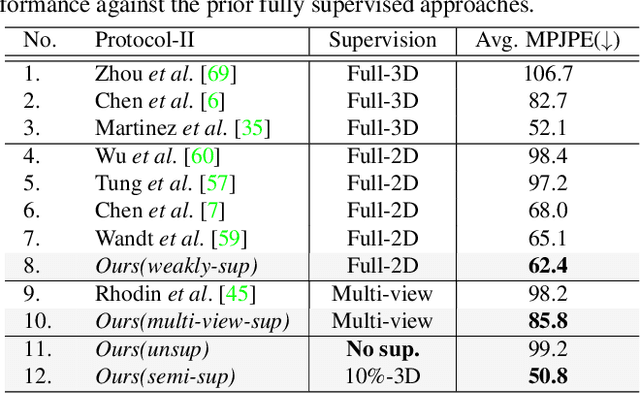
Camera captured human pose is an outcome of several sources of variation. Performance of supervised 3D pose estimation approaches comes at the cost of dispensing with variations, such as shape and appearance, that may be useful for solving other related tasks. As a result, the learned model not only inculcates task-bias but also dataset-bias because of its strong reliance on the annotated samples, which also holds true for weakly-supervised models. Acknowledging this, we propose a self-supervised learning framework to disentangle such variations from unlabeled video frames. We leverage the prior knowledge on human skeleton and poses in the form of a single part-based 2D puppet model, human pose articulation constraints, and a set of unpaired 3D poses. Our differentiable formalization, bridging the representation gap between the 3D pose and spatial part maps, not only facilitates discovery of interpretable pose disentanglement but also allows us to operate on videos with diverse camera movements. Qualitative results on unseen in-the-wild datasets establish our superior generalization across multiple tasks beyond the primary tasks of 3D pose estimation and part segmentation. Furthermore, we demonstrate state-of-the-art weakly-supervised 3D pose estimation performance on both Human3.6M and MPI-INF-3DHP datasets.
Exploiting inter-image similarity and ensemble of extreme learners for fixation prediction using deep features
Oct 20, 2016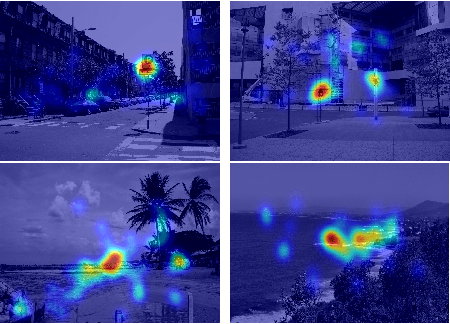
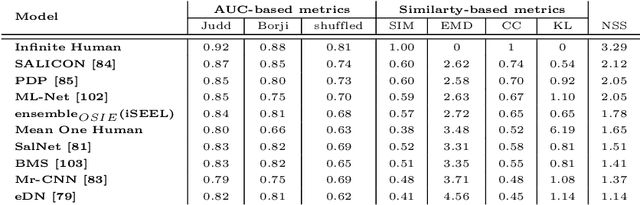
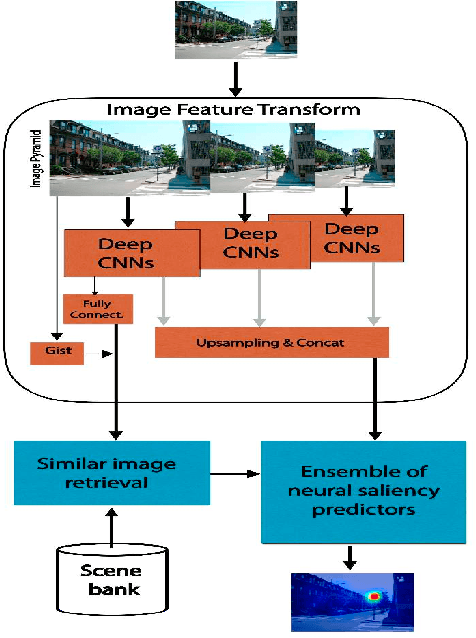
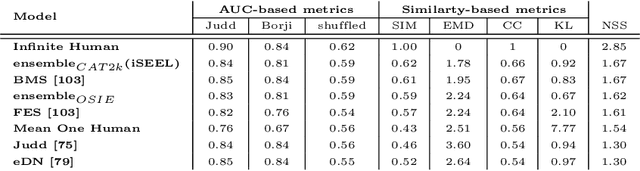
This paper presents a novel fixation prediction and saliency modeling framework based on inter-image similarities and ensemble of Extreme Learning Machines (ELM). The proposed framework is inspired by two observations, 1) the contextual information of a scene along with low-level visual cues modulates attention, 2) the influence of scene memorability on eye movement patterns caused by the resemblance of a scene to a former visual experience. Motivated by such observations, we develop a framework that estimates the saliency of a given image using an ensemble of extreme learners, each trained on an image similar to the input image. That is, after retrieving a set of similar images for a given image, a saliency predictor is learnt from each of the images in the retrieved image set using an ELM, resulting in an ensemble. The saliency of the given image is then measured in terms of the mean of predicted saliency value by the ensemble's members.
Disentangling 3D Prototypical Networks For Few-Shot Concept Learning
Nov 06, 2020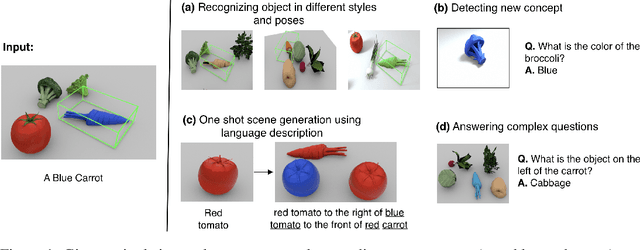
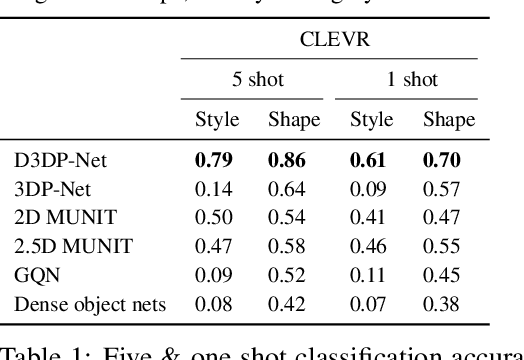
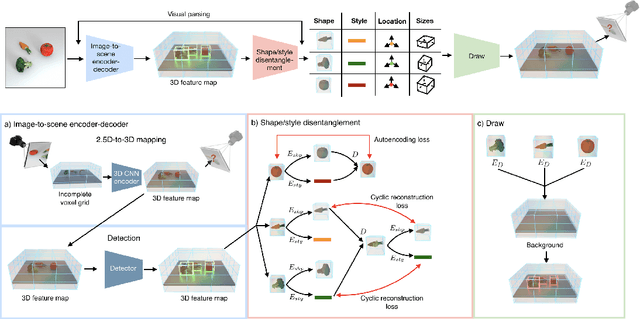
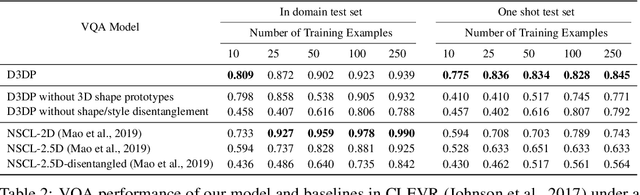
We present neural architectures that disentangle RGB-D images into objects' shapes and styles and a map of the background scene, and explore their applications for few-shot 3D object detection and few-shot concept classification. Our networks incorporate architectural biases that reflect the image formation process, 3D geometry of the world scene, and shape-style interplay. They are trained end-to-end self-supervised by predicting views in static scenes, alongside a small number of 3D object boxes. Objects and scenes are represented in terms of 3D feature grids in the bottleneck of the network. We show that the proposed 3D neural representations are compositional: they can generate novel 3D scene feature maps by mixing object shapes and styles, resizing and adding the resulting object 3D feature maps over background scene feature maps. We show that classifiers for object categories, color, materials, and spatial relationships trained over the disentangled 3D feature sub-spaces generalize better with dramatically fewer examples than the current state-of-the-art, and enable a visual question answering system that uses them as its modules to generalize one-shot to novel objects in the scene.
Object Level Deep Feature Pooling for Compact Image Representation
Apr 24, 2015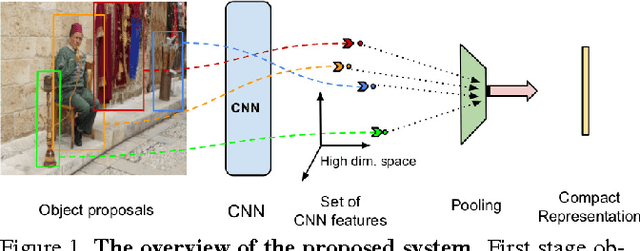
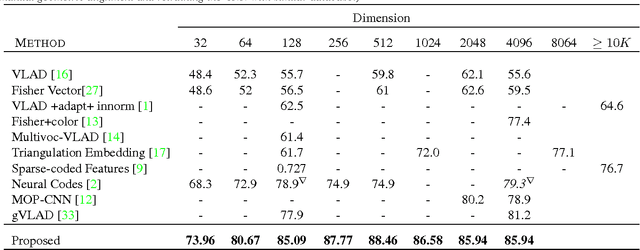
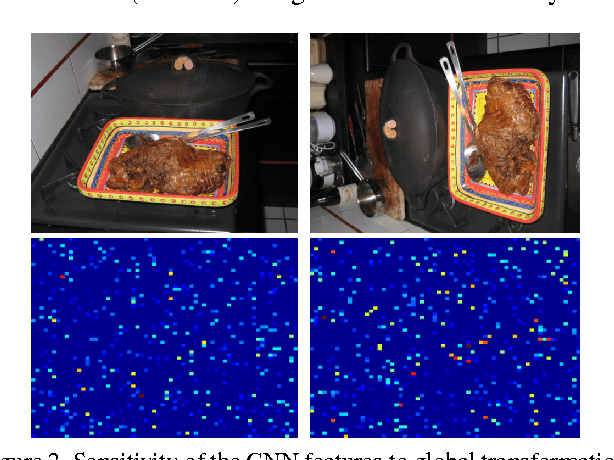
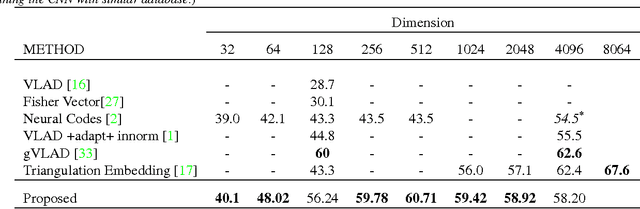
Convolutional Neural Network (CNN) features have been successfully employed in recent works as an image descriptor for various vision tasks. But the inability of the deep CNN features to exhibit invariance to geometric transformations and object compositions poses a great challenge for image search. In this work, we demonstrate the effectiveness of the objectness prior over the deep CNN features of image regions for obtaining an invariant image representation. The proposed approach represents the image as a vector of pooled CNN features describing the underlying objects. This representation provides robustness to spatial layout of the objects in the scene and achieves invariance to general geometric transformations, such as translation, rotation and scaling. The proposed approach also leads to a compact representation of the scene, making each image occupy a smaller memory footprint. Experiments show that the proposed representation achieves state of the art retrieval results on a set of challenging benchmark image datasets, while maintaining a compact representation.
Unsupervised Super-Resolution: Creating High-Resolution Medical Images from Low-Resolution Anisotropic Examples
Oct 25, 2020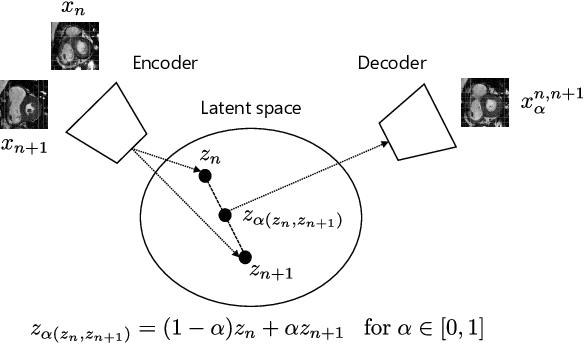
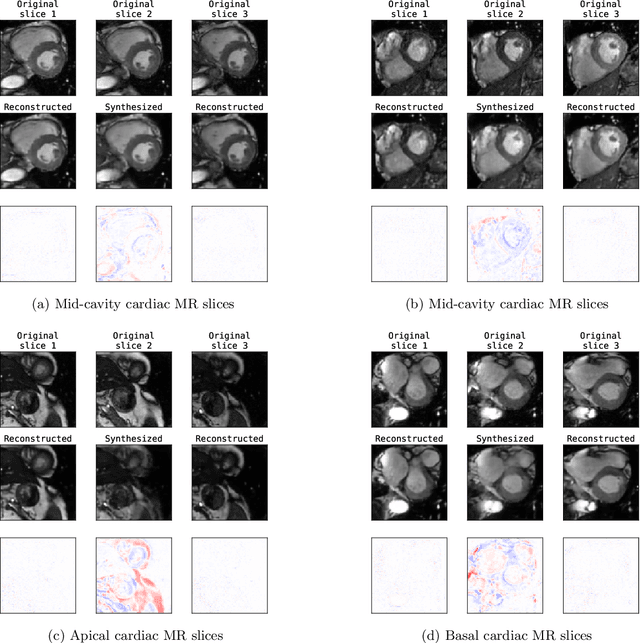
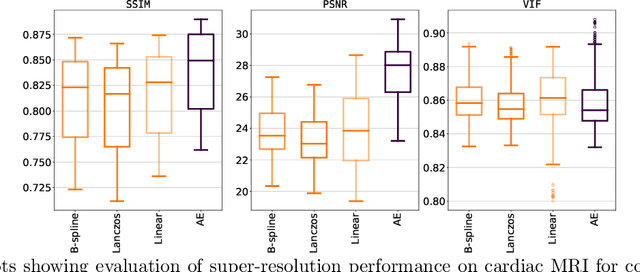
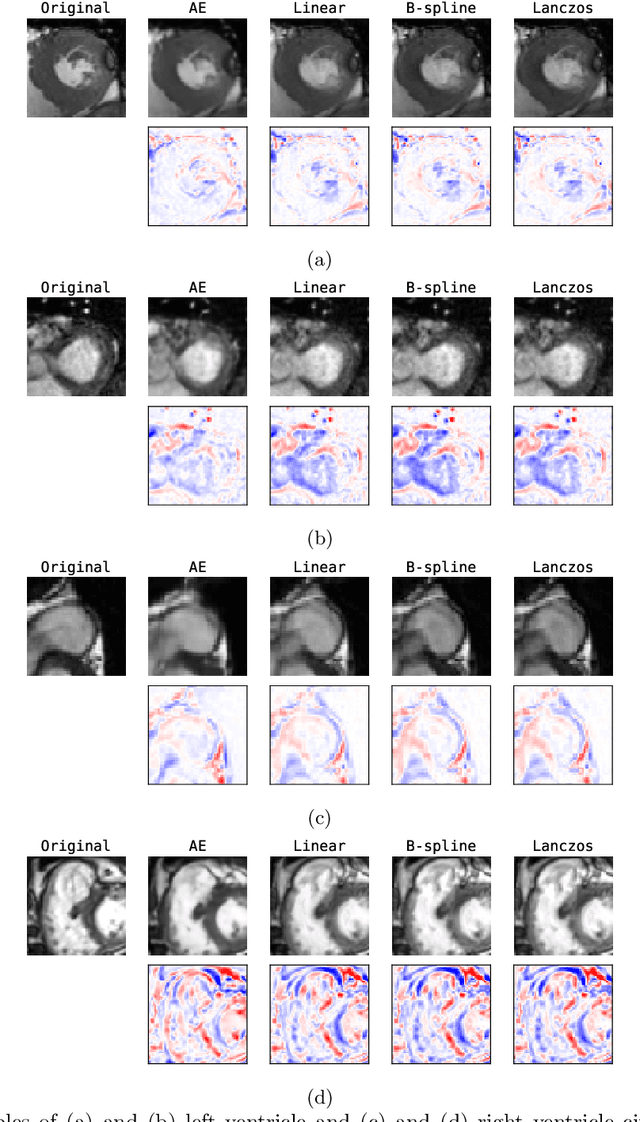
Although high resolution isotropic 3D medical images are desired in clinical practice, their acquisition is not always feasible. Instead, lower resolution images are upsampled to higher resolution using conventional interpolation methods. Sophisticated learning-based super-resolution approaches are frequently unavailable in clinical setting, because such methods require training with high-resolution isotropic examples. To address this issue, we propose a learning-based super-resolution approach that can be trained using solely anisotropic images, i.e. without high-resolution ground truth data. The method exploits the latent space, generated by autoencoders trained on anisotropic images, to increase spatial resolution in low-resolution images. The method was trained and evaluated using 100 publicly available cardiac cine MR scans from the Automated Cardiac Diagnosis Challenge (ACDC). The quantitative results show that the proposed method performs better than conventional interpolation methods. Furthermore, the qualitative results indicate that especially finer cardiac structures are synthesized with high quality. The method has the potential to be applied to other anatomies and modalities and can be easily applied to any 3D anisotropic medical image dataset.
Learning Multi-Modal Nonlinear Embeddings: Performance Bounds and an Algorithm
Jun 03, 2020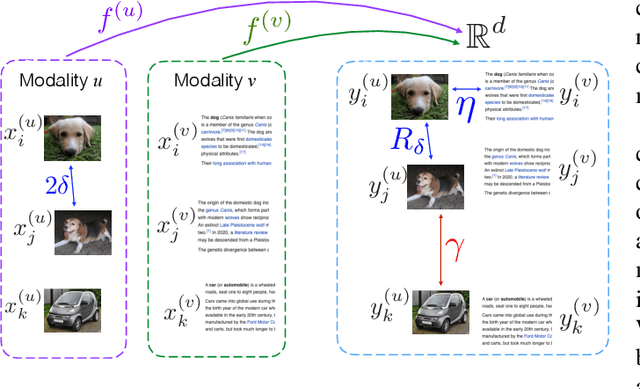

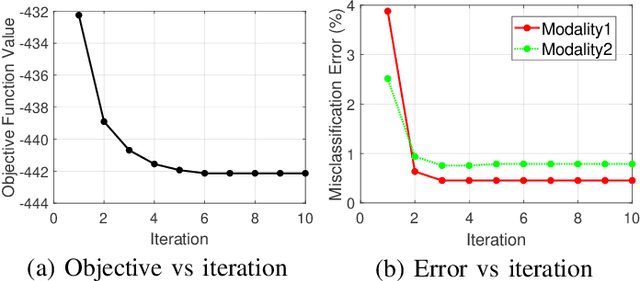
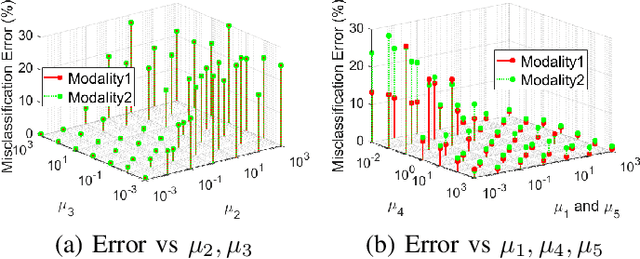
While many approaches exist in the literature to learn representations for data collections in multiple modalities, the generalizability of the learnt representations to previously unseen data is a largely overlooked subject. In this work, we first present a theoretical analysis of learning multi-modal nonlinear embeddings in a supervised setting. Our performance bounds indicate that for successful generalization in multi-modal classification and retrieval problems, the regularity of the interpolation functions extending the embedding to the whole data space is as important as the between-class separation and cross-modal alignment criteria. We then propose a multi-modal nonlinear representation learning algorithm that is motivated by these theoretical findings, where the embeddings of the training samples are optimized jointly with the Lipschitz regularity of the interpolators. Experimental comparison to recent multi-modal and single-modal learning algorithms suggests that the proposed method yields promising performance in multi-modal image classification and cross-modal image-text retrieval applications.
Unsupervised Object Detection with LiDAR Clues
Nov 27, 2020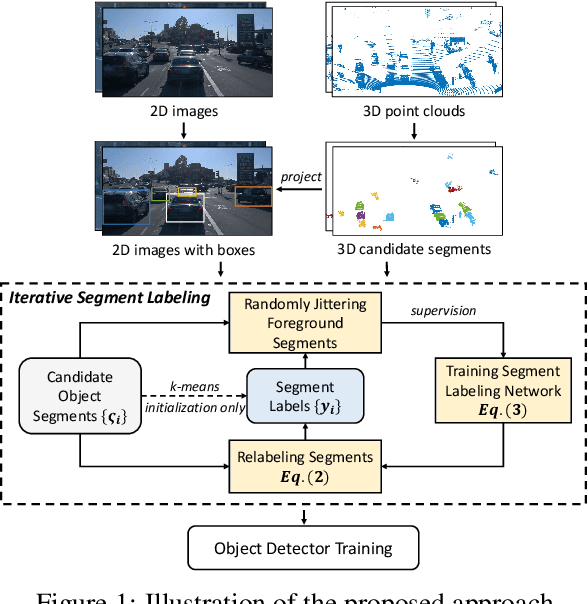



Despite the importance of unsupervised object detection, to the best of our knowledge, there is no previous work addressing this problem. One main issue, widely known to the community, is that object boundaries derived only from 2D image appearance are ambiguous and unreliable. To address this, we exploit LiDAR clues to aid unsupervised object detection. By exploiting the 3D scene structure, the issue of localization can be considerably mitigated. We further identify another major issue, seldom noticed by the community, that the long-tailed and open-ended (sub-)category distribution should be accommodated. In this paper, we present the first practical method for unsupervised object detection with the aid of LiDAR clues. In our approach, candidate object segments based on 3D point clouds are firstly generated. Then, an iterative segment labeling process is conducted to assign segment labels and to train a segment labeling network, which is based on features from both 2D images and 3D point clouds. The labeling process is carefully designed so as to mitigate the issue of long-tailed and open-ended distribution. The final segment labels are set as pseudo annotations for object detection network training. Extensive experiments on the large-scale Waymo Open dataset suggest that the derived unsupervised object detection method achieves reasonable accuracy compared with that of strong supervision within the LiDAR visible range. Code shall be released.
Mastering Atari with Discrete World Models
Oct 05, 2020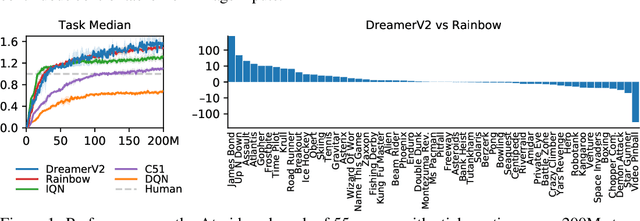
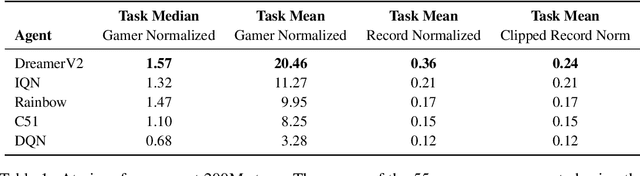
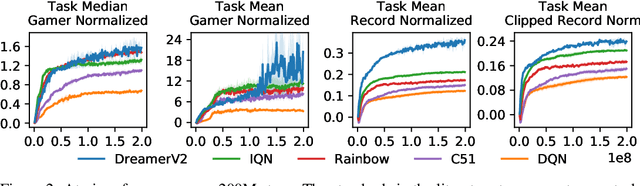

Intelligent agents need to generalize from past experience to achieve goals in complex environments. World models facilitate such generalization and allow learning behaviors from imagined outcomes to increase sample-efficiency. While learning world models from image inputs has recently become feasible for some tasks, modeling Atari games accurately enough to derive successful behaviors has remained an open challenge for many years. We introduce DreamerV2, a reinforcement learning agent that learns behaviors purely from predictions in the compact latent space of a powerful world model. The world model uses discrete representations and is trained separately from the policy. DreamerV2 constitutes the first agent that achieves human-level performance on the Atari benchmark of 55 tasks by learning behaviors inside a separately trained world model. With the same computational budget and wall-clock time, DreamerV2 reaches 200M frames and exceeds the final performance of the top single-GPU agents IQN and Rainbow.