 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation
Dec 07, 2023
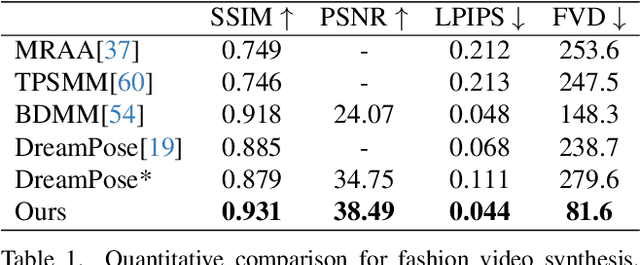
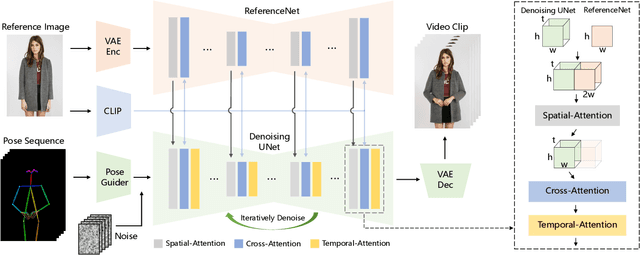
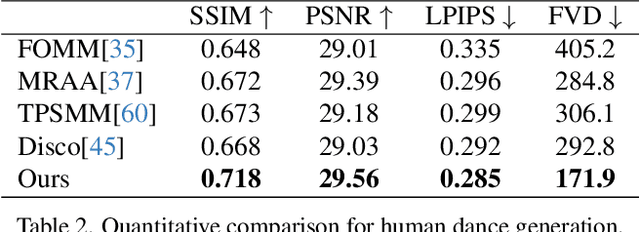

Character Animation aims to generating character videos from still images through driving signals. Currently, diffusion models have become the mainstream in visual generation research, owing to their robust generative capabilities. However, challenges persist in the realm of image-to-video, especially in character animation, where temporally maintaining consistency with detailed information from character remains a formidable problem. In this paper, we leverage the power of diffusion models and propose a novel framework tailored for character animation. To preserve consistency of intricate appearance features from reference image, we design ReferenceNet to merge detail features via spatial attention. To ensure controllability and continuity, we introduce an efficient pose guider to direct character's movements and employ an effective temporal modeling approach to ensure smooth inter-frame transitions between video frames. By expanding the training data, our approach can animate arbitrary characters, yielding superior results in character animation compared to other image-to-video methods. Furthermore, we evaluate our method on benchmarks for fashion video and human dance synthesis, achieving state-of-the-art results.
Enlighten-Your-Voice: When Multimodal Meets Zero-shot Low-light Image Enhancement
Dec 15, 2023Low-light image enhancement is a crucial visual task, and many unsupervised methods tend to overlook the degradation of visible information in low-light scenes, which adversely affects the fusion of complementary information and hinders the generation of satisfactory results. To address this, our study introduces ``Enlighten-Your-Voice'', a multimodal enhancement framework that innovatively enriches user interaction through voice and textual commands. This approach does not merely signify a technical leap but also represents a paradigm shift in user engagement. Our model is equipped with a Dual Collaborative Attention Module (DCAM) that meticulously caters to distinct content and color discrepancies, thereby facilitating nuanced enhancements. Complementarily, we introduce a Semantic Feature Fusion (SFM) plug-and-play module that synergizes semantic context with low-light enhancement operations, sharpening the algorithm's efficacy. Crucially, ``Enlighten-Your-Voice'' showcases remarkable generalization in unsupervised zero-shot scenarios. The source code can be accessed from https://github.com/zhangbaijin/Enlighten-Your-Voice
Reflected Schrödinger Bridge for Constrained Generative Modeling
Jan 06, 2024Diffusion models have become the go-to method for large-scale generative models in real-world applications. These applications often involve data distributions confined within bounded domains, typically requiring ad-hoc thresholding techniques for boundary enforcement. Reflected diffusion models (Lou23) aim to enhance generalizability by generating the data distribution through a backward process governed by reflected Brownian motion. However, reflected diffusion models may not easily adapt to diverse domains without the derivation of proper diffeomorphic mappings and do not guarantee optimal transport properties. To overcome these limitations, we introduce the Reflected Schrodinger Bridge algorithm: an entropy-regularized optimal transport approach tailored for generating data within diverse bounded domains. We derive elegant reflected forward-backward stochastic differential equations with Neumann and Robin boundary conditions, extend divergence-based likelihood training to bounded domains, and explore natural connections to entropic optimal transport for the study of approximate linear convergence - a valuable insight for practical training. Our algorithm yields robust generative modeling in diverse domains, and its scalability is demonstrated in real-world constrained generative modeling through standard image benchmarks.
A Physics-guided Generative AI Toolkit for Geophysical Monitoring
Jan 06, 2024Full-waveform inversion (FWI) plays a vital role in geoscience to explore the subsurface. It utilizes the seismic wave to image the subsurface velocity map. As the machine learning (ML) technique evolves, the data-driven approaches using ML for FWI tasks have emerged, offering enhanced accuracy and reduced computational cost compared to traditional physics-based methods. However, a common challenge in geoscience, the unprivileged data, severely limits ML effectiveness. The issue becomes even worse during model pruning, a step essential in geoscience due to environmental complexities. To tackle this, we introduce the EdGeo toolkit, which employs a diffusion-based model guided by physics principles to generate high-fidelity velocity maps. The toolkit uses the acoustic wave equation to generate corresponding seismic waveform data, facilitating the fine-tuning of pruned ML models. Our results demonstrate significant improvements in SSIM scores and reduction in both MAE and MSE across various pruning ratios. Notably, the ML model fine-tuned using data generated by EdGeo yields superior quality of velocity maps, especially in representing unprivileged features, outperforming other existing methods.
SemiSAM: Exploring SAM for Enhancing Semi-Supervised Medical Image Segmentation with Extremely Limited Annotations
Dec 11, 2023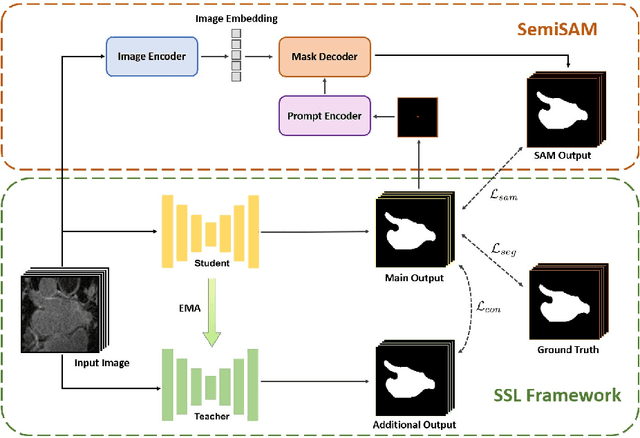
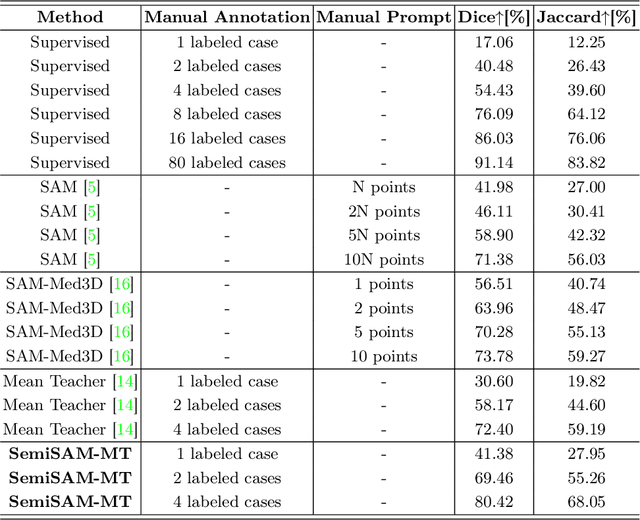
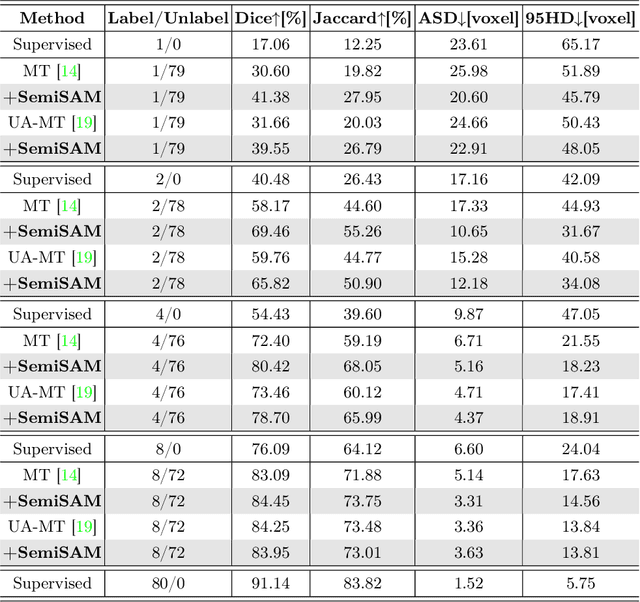
Semi-supervised learning has attracted much attention due to its less dependence on acquiring abundant annotations from experts compared to fully supervised methods, which is especially important for medical image segmentation which typically requires intensive pixel/voxel-wise labeling by domain experts. Although semi-supervised methods can improve the performance by utilizing unlabeled data, there are still gaps between fully supervised methods under extremely limited annotation scenarios. In this paper, we propose a simple yet efficient strategy to explore the usage of the Segment Anything Model (SAM) for enhancing semi-supervised medical image segmentation. Concretely, the segmentation model trained with domain knowledge provides information for localization and generating input prompts to the SAM. Then the generated pseudo-labels of SAM are utilized as additional supervision to assist in the learning procedure of the semi-supervised framework. Experimental results demonstrate that SAM's assistance significantly enhances the performance of existing semi-supervised frameworks, especially when only one or a few labeled images are available.
R2Human: Real-Time 3D Human Appearance Rendering from a Single Image
Dec 10, 2023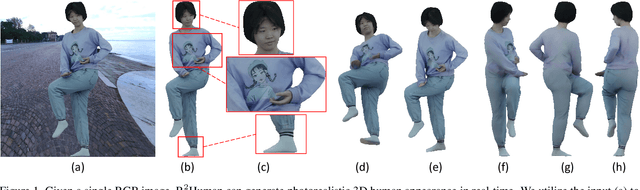
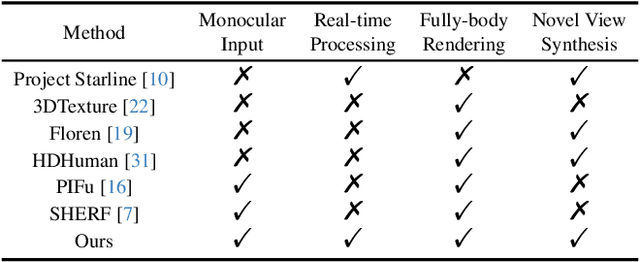
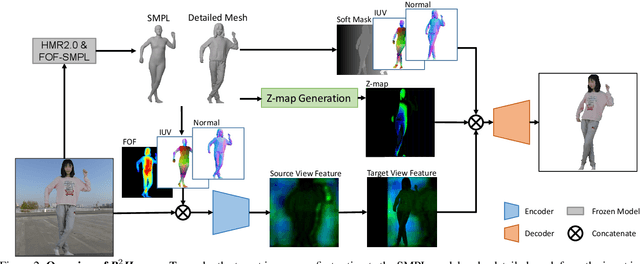
Reconstructing 3D human appearance from a single image is crucial for achieving holographic communication and immersive social experiences. However, this remains a challenge for existing methods, which typically rely on multi-camera setups or are limited to offline operations. In this paper, we propose R$^2$Human, the first approach for real-time inference and rendering of photorealistic 3D human appearance from a single image. The core of our approach is to combine the strengths of implicit texture fields and explicit neural rendering with our novel representation, namely Z-map. Based on this, we present an end-to-end network that performs high-fidelity color reconstruction of visible areas and provides reliable color inference for occluded regions. To further enhance the 3D perception ability of our network, we leverage the Fourier occupancy field to reconstruct a detailed 3D geometry, which serves as a prior for the texture field generation and provides a sampling surface in the rendering stage. Experiments show that our end-to-end method achieves state-of-the-art performance on both synthetic data and challenging real-world images and even outperforms many offline methods. The project page is available for research purposes at http://cic.tju.edu.cn/faculty/likun/projects/R2Human.
Domain Generalization with Vital Phase Augmentation
Jan 08, 2024Deep neural networks have shown remarkable performance in image classification. However, their performance significantly deteriorates with corrupted input data. Domain generalization methods have been proposed to train robust models against out-of-distribution data. Data augmentation in the frequency domain is one of such approaches that enable a model to learn phase features to establish domain-invariant representations. This approach changes the amplitudes of the input data while preserving the phases. However, using fixed phases leads to susceptibility to phase fluctuations because amplitudes and phase fluctuations commonly occur in out-of-distribution. In this study, to address this problem, we introduce an approach using finite variation of the phases of input data rather than maintaining fixed phases. Based on the assumption that the degree of domain-invariant features varies for each phase, we propose a method to distinguish phases based on this degree. In addition, we propose a method called vital phase augmentation (VIPAug) that applies the variation to the phases differently according to the degree of domain-invariant features of given phases. The model depends more on the vital phases that contain more domain-invariant features for attaining robustness to amplitude and phase fluctuations. We present experimental evaluations of our proposed approach, which exhibited improved performance for both clean and corrupted data. VIPAug achieved SOTA performance on the benchmark CIFAR-10 and CIFAR-100 datasets, as well as near-SOTA performance on the ImageNet-100 and ImageNet datasets. Our code is available at https://github.com/excitedkid/vipaug.
DiffusionLight: Light Probes for Free by Painting a Chrome Ball
Jan 01, 2024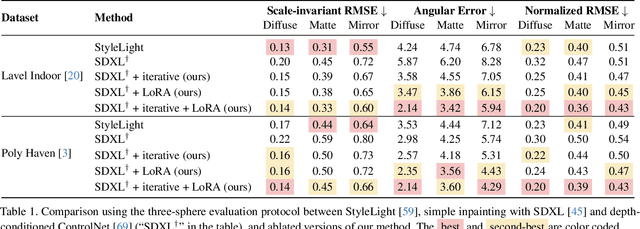


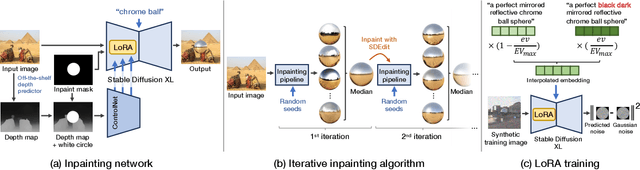
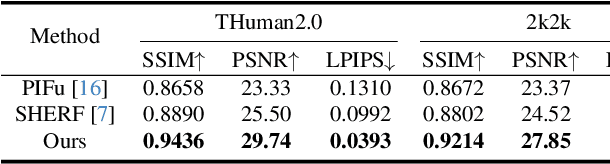
We present a simple yet effective technique to estimate lighting in a single input image. Current techniques rely heavily on HDR panorama datasets to train neural networks to regress an input with limited field-of-view to a full environment map. However, these approaches often struggle with real-world, uncontrolled settings due to the limited diversity and size of their datasets. To address this problem, we leverage diffusion models trained on billions of standard images to render a chrome ball into the input image. Despite its simplicity, this task remains challenging: the diffusion models often insert incorrect or inconsistent objects and cannot readily generate images in HDR format. Our research uncovers a surprising relationship between the appearance of chrome balls and the initial diffusion noise map, which we utilize to consistently generate high-quality chrome balls. We further fine-tune an LDR difusion model (Stable Diffusion XL) with LoRA, enabling it to perform exposure bracketing for HDR light estimation. Our method produces convincing light estimates across diverse settings and demonstrates superior generalization to in-the-wild scenarios.
LivePhoto: Real Image Animation with Text-guided Motion Control
Dec 05, 2023Despite the recent progress in text-to-video generation, existing studies usually overlook the issue that only spatial contents but not temporal motions in synthesized videos are under the control of text. Towards such a challenge, this work presents a practical system, named LivePhoto, which allows users to animate an image of their interest with text descriptions. We first establish a strong baseline that helps a well-learned text-to-image generator (i.e., Stable Diffusion) take an image as a further input. We then equip the improved generator with a motion module for temporal modeling and propose a carefully designed training pipeline to better link texts and motions. In particular, considering the facts that (1) text can only describe motions roughly (e.g., regardless of the moving speed) and (2) text may include both content and motion descriptions, we introduce a motion intensity estimation module as well as a text re-weighting module to reduce the ambiguity of text-to-motion mapping. Empirical evidence suggests that our approach is capable of well decoding motion-related textual instructions into videos, such as actions, camera movements, or even conjuring new contents from thin air (e.g., pouring water into an empty glass). Interestingly, thanks to the proposed intensity learning mechanism, our system offers users an additional control signal (i.e., the motion intensity) besides text for video customization.
Advancements in Content-Based Image Retrieval: A Comprehensive Survey of Relevance Feedback Techniques
Dec 13, 2023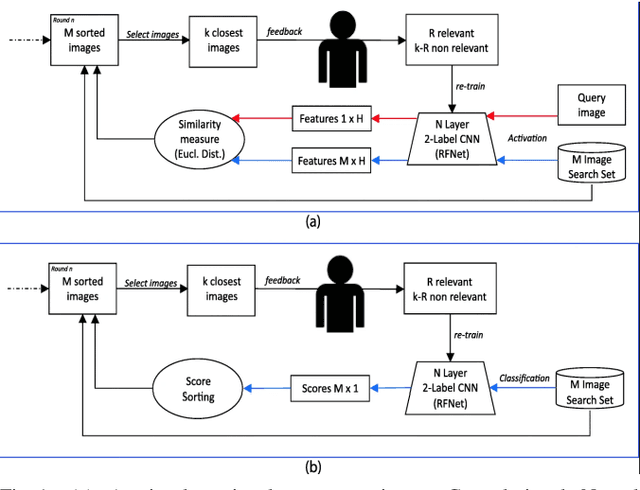
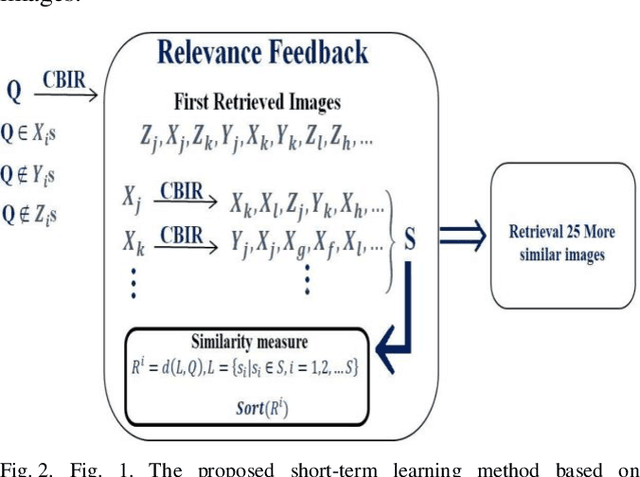
Content-based image retrieval (CBIR) systems have emerged as crucial tools in the field of computer vision, allowing for image search based on visual content rather than relying solely on metadata. This survey paper presents a comprehensive overview of CBIR, emphasizing its role in object detection and its potential to identify and retrieve visually similar images based on content features. Challenges faced by CBIR systems, including the semantic gap and scalability, are discussed, along with potential solutions. It elaborates on the semantic gap, which arises from the disparity between low-level features and high-level semantic concepts, and explores approaches to bridge this gap. One notable solution is the integration of relevance feedback (RF), empowering users to provide feedback on retrieved images and refine search results iteratively. The survey encompasses long-term and short-term learning approaches that leverage RF for enhanced CBIR accuracy and relevance. These methods focus on weight optimization and the utilization of active learning algorithms to select samples for training classifiers. Furthermore, the paper investigates machine learning techniques and the utilization of deep learning and convolutional neural networks to enhance CBIR performance. This survey paper plays a significant role in advancing the understanding of CBIR and RF techniques. It guides researchers and practitioners in comprehending existing methodologies, challenges, and potential solutions while fostering knowledge dissemination and identifying research gaps. By addressing future research directions, it sets the stage for advancements in CBIR that will enhance retrieval accuracy, usability, and effectiveness in various application domains.