 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Attribute-Graph: A Graph based approach to Image Ranking
Oct 08, 2015




We propose a novel image representation, termed Attribute-Graph, to rank images by their semantic similarity to a given query image. An Attribute-Graph is an undirected fully connected graph, incorporating both local and global image characteristics. The graph nodes characterise objects as well as the overall scene context using mid-level semantic attributes, while the edges capture the object topology. We demonstrate the effectiveness of Attribute-Graphs by applying them to the problem of image ranking. We benchmark the performance of our algorithm on the 'rPascal' and 'rImageNet' datasets, which we have created in order to evaluate the ranking performance on complex queries containing multiple objects. Our experimental evaluation shows that modelling images as Attribute-Graphs results in improved ranking performance over existing techniques.
Global Texture Enhancement for Fake Face Detection in the Wild
Feb 01, 2020


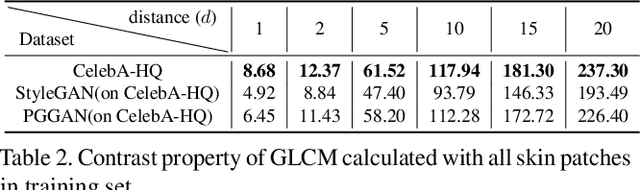
Generative Adversarial Networks (GANs) can generate realistic fake face images that can easily fool human beings.On the contrary, a common Convolutional Neural Network(CNN) discriminator can achieve more than 99.9% accuracyin discerning fake/real images. In this paper, we conduct an empirical study on fake/real faces, and have two important observations: firstly, the texture of fake faces is substantially different from real ones; secondly, global texture statistics are more robust to image editing and transferable to fake faces from different GANs and datasets. Motivated by the above observations, we propose a new architecture coined as Gram-Net, which leverages global image texture representations for robust fake image detection. Experimental results on several datasets demonstrate that our Gram-Net outperforms existing approaches. Especially, our Gram-Netis more robust to image editings, e.g. down-sampling, JPEG compression, blur, and noise. More importantly, our Gram-Net generalizes significantly better in detecting fake faces from GAN models not seen in the training phase and can perform decently in detecting fake natural images.
Learning a Reinforced Agent for Flexible Exposure Bracketing Selection
May 26, 2020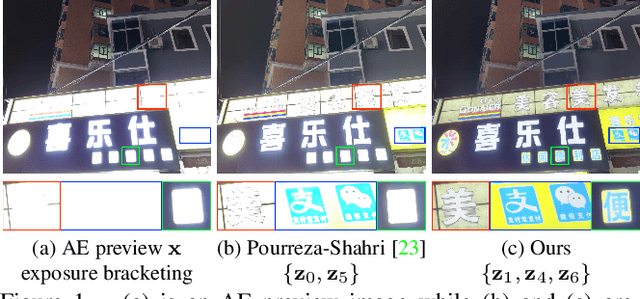

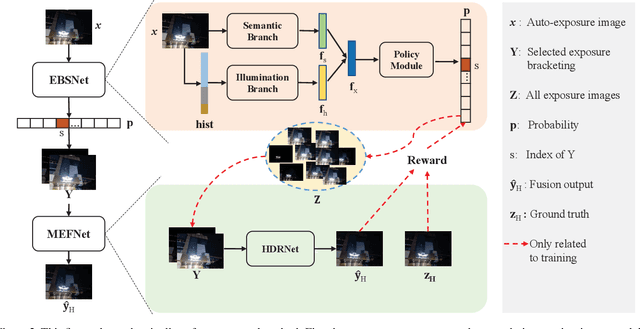
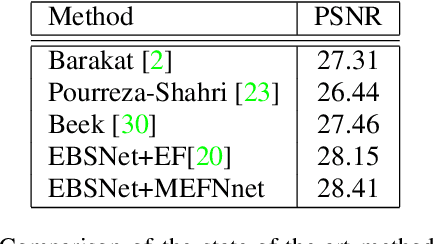
Automatically selecting exposure bracketing (images exposed differently) is important to obtain a high dynamic range image by using multi-exposure fusion. Unlike previous methods that have many restrictions such as requiring camera response function, sensor noise model, and a stream of preview images with different exposures (not accessible in some scenarios e.g. some mobile applications), we propose a novel deep neural network to automatically select exposure bracketing, named EBSNet, which is sufficiently flexible without having the above restrictions. EBSNet is formulated as a reinforced agent that is trained by maximizing rewards provided by a multi-exposure fusion network (MEFNet). By utilizing the illumination and semantic information extracted from just a single auto-exposure preview image, EBSNet can select an optimal exposure bracketing for multi-exposure fusion. EBSNet and MEFNet can be jointly trained to produce favorable results against recent state-of-the-art approaches. To facilitate future research, we provide a new benchmark dataset for multi-exposure selection and fusion.
EasierPath: An Open-source Tool for Human-in-the-loop Deep Learning of Renal Pathology
Jul 28, 2020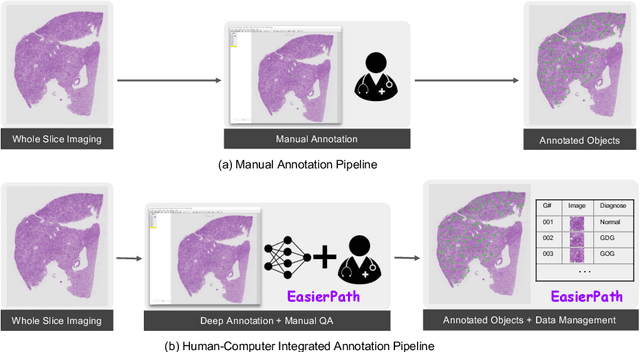
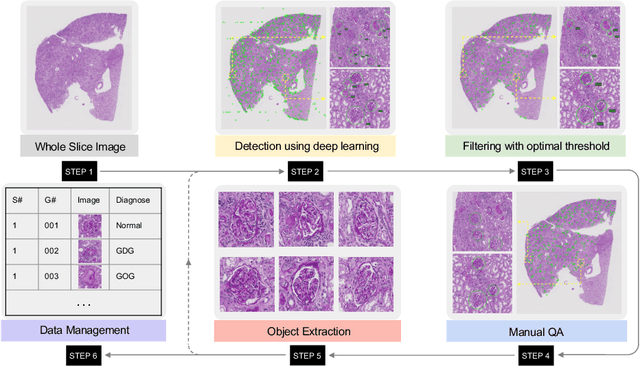
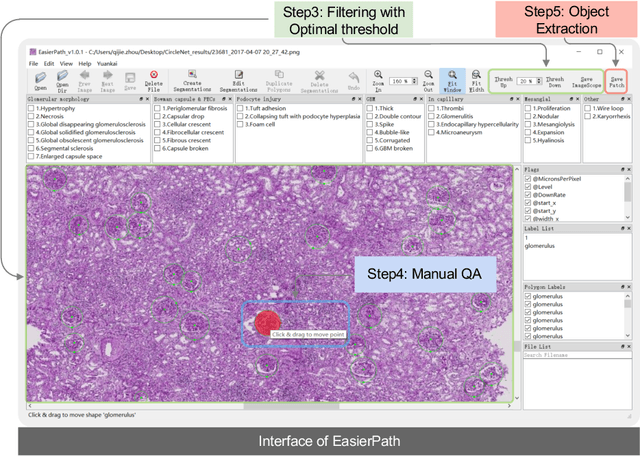
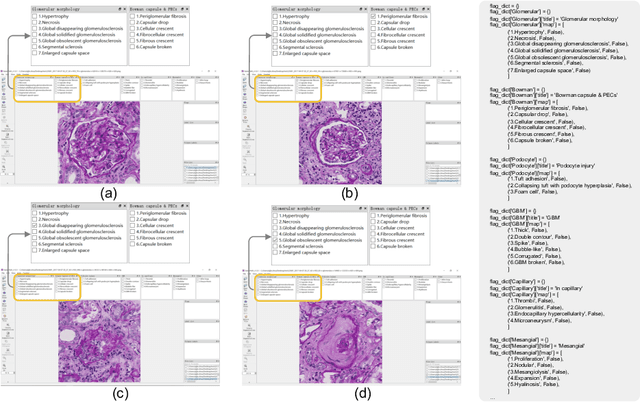
Considerable morphological phenotyping studies in nephrology have emerged in the past few years, aiming to discover hidden regularities between clinical and imaging phenotypes. Such studies have been largely enabled by deep learning based image analysis to extract sparsely located targeting objects (e.g., glomeruli) on high-resolution whole slide images (WSI). However, such methods need to be trained using labor-intensive high-quality annotations, ideally labeled by pathologists. Inspired by the recent "human-in-the-loop" strategy, we developed EasierPath, an open-source tool to integrate human physicians and deep learning algorithms for efficient large-scale pathological image quantification as a loop. Using EasierPath, physicians are able to (1) optimize the recall and precision of deep learning object detection outcomes adaptively, (2) seamlessly support deep learning outcomes refining using either our EasierPath or prevalent ImageScope software without changing physician's user habit, and (3) manage and phenotype each object with user-defined classes. As a user case of EasierPath, we present the procedure of curating large-scale glomeruli in an efficient human-in-the-loop fashion (with two loops). From the experiments, the EasierPath saved 57 % of the annotation efforts to curate 8,833 glomeruli during the second loop. Meanwhile, the average precision of glomerular detection was leveraged from 0.504 to 0.620. The EasierPath software has been released as open-source to enable the large-scale glomerular prototyping. The code can be found in https://github.com/yuankaihuo/EasierPath
Multi-spectral Facial Landmark Detection
Jun 09, 2020
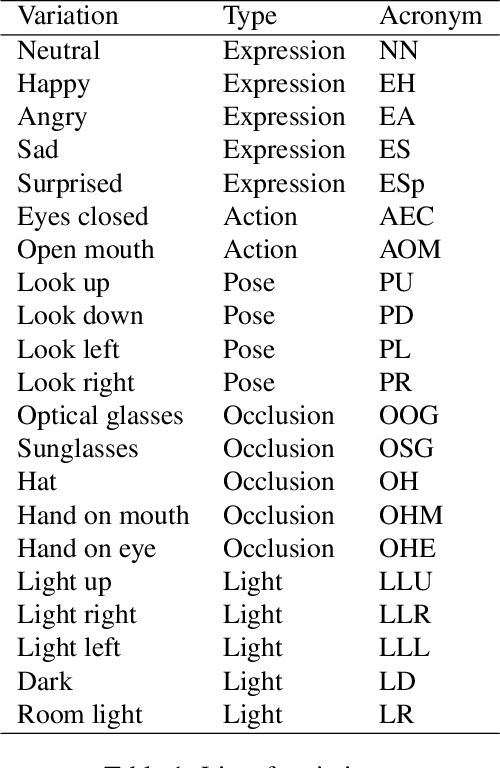
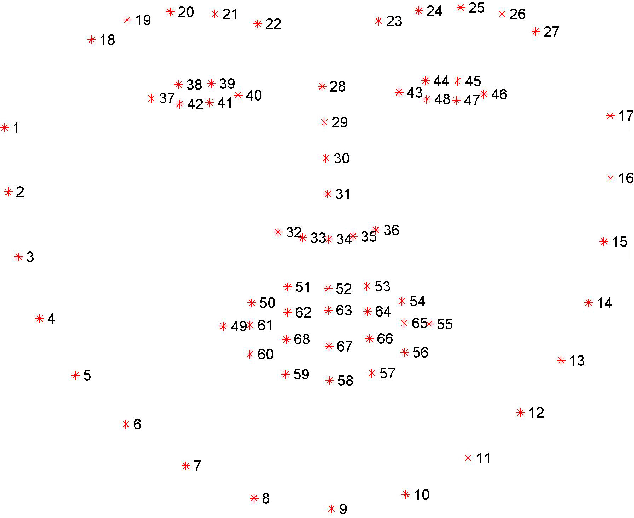
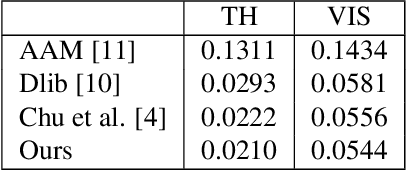
Thermal face image analysis is favorable for certain circumstances. For example, illumination-sensitive applications, like nighttime surveillance; and privacy-preserving demanded access control. However, the inadequate study on thermal face image analysis calls for attention in responding to the industry requirements. Detecting facial landmark points are important for many face analysis tasks, such as face recognition, 3D face reconstruction, and face expression recognition. In this paper, we propose a robust neural network enabled facial landmark detection, namely Deep Multi-Spectral Learning (DMSL). Briefly, DMSL consists of two sub-models, i.e. face boundary detection, and landmark coordinates detection. Such an architecture demonstrates the capability of detecting the facial landmarks on both visible and thermal images. Particularly, the proposed DMSL model is robust in facial landmark detection where the face is partially occluded, or facing different directions. The experiment conducted on Eurecom's visible and thermal paired database shows the superior performance of DMSL over the state-of-the-art for thermal facial landmark detection. In addition to that, we have annotated a thermal face dataset with their respective facial landmark for the purpose of experimentation.
Classification of Arrhythmia by Using Deep Learning with 2-D ECG Spectral Image Representation
May 14, 2020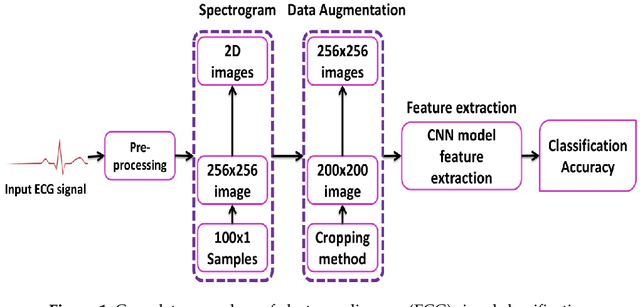
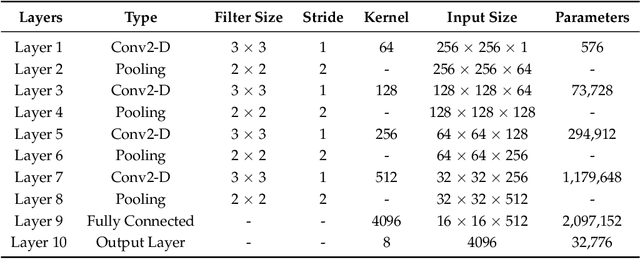
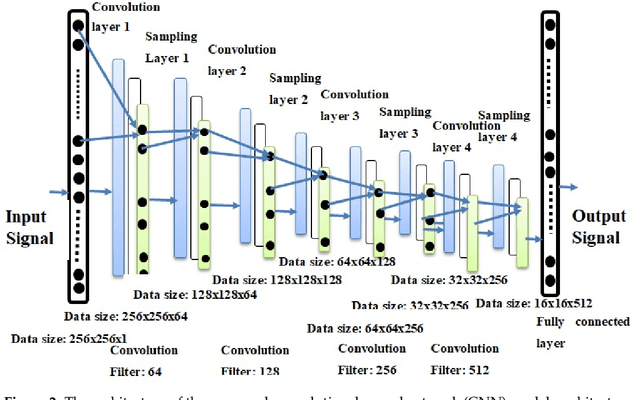
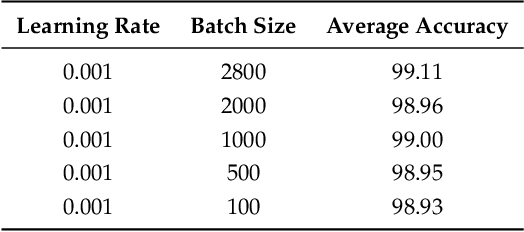
The electrocardiogram (ECG) is one of the most extensively employed signals used in the diagnosis and prediction of cardiovascular diseases (CVDs). The ECG signals can capture the heart's rhythmic irregularities, commonly known as arrhythmias. A careful study of ECG signals is crucial for precise diagnoses of patients' acute and chronic heart conditions. In this study, we propose a two-dimensional (2-D) convolutional neural network (CNN) model for the classification of ECG signals into eight classes; namely, normal beat, premature ventricular contraction beat, paced beat, right bundle branch block beat, left bundle branch block beat, atrial premature contraction beat, ventricular flutter wave beat, and ventricular escape beat. The one-dimensional ECG time series signals are transformed into 2-D spectrograms through short-time Fourier transform. The 2-D CNN model consisting of four convolutional layers and four pooling layers is designed for extracting robust features from the input spectrograms. Our proposed methodology is evaluated on a publicly available MIT-BIH arrhythmia dataset. We achieved a state-of-the-art average classification accuracy of 99.11\%, which is better than those of recently reported results in classifying similar types of arrhythmias. The performance is significant in other indices as well, including sensitivity and specificity, which indicates the success of the proposed method.
Unbiased Gradient Estimation for Variational Auto-Encoders using Coupled Markov Chains
Oct 05, 2020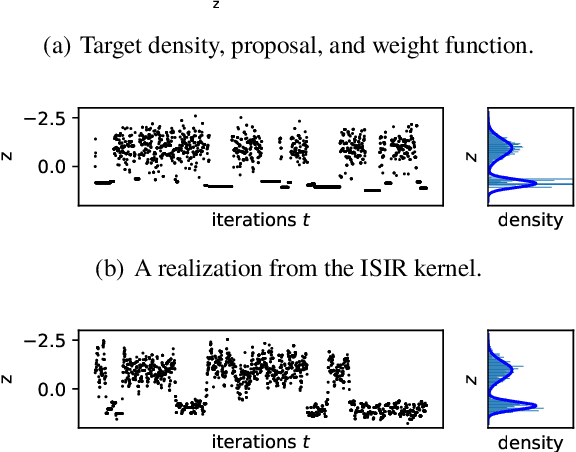
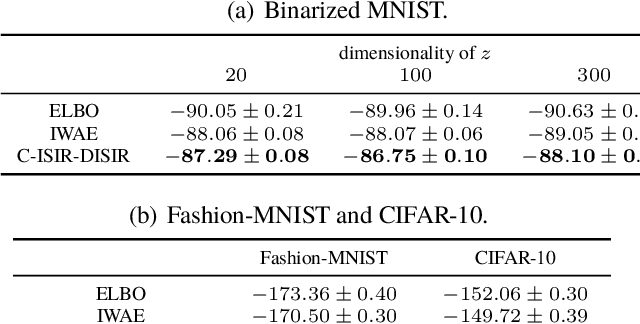
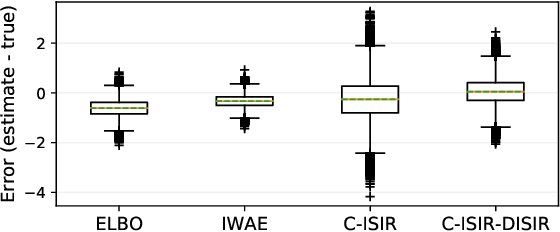
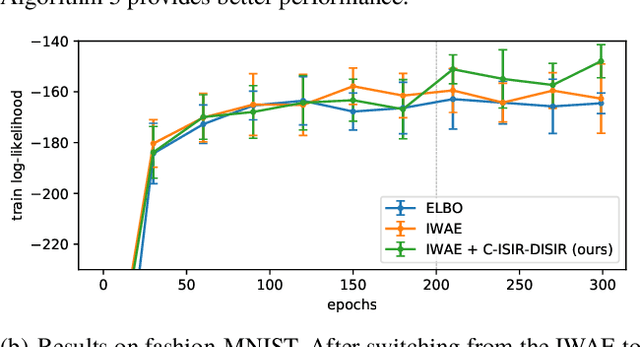
The variational auto-encoder (VAE) is a deep latent variable model that has two neural networks in an autoencoder-like architecture; one of them parameterizes the model's likelihood. Fitting its parameters via maximum likelihood is challenging since the computation of the likelihood involves an intractable integral over the latent space; thus the VAE is trained instead by maximizing a variational lower bound. Here, we develop a maximum likelihood training scheme for VAEs by introducing unbiased gradient estimators of the log-likelihood. We obtain the unbiased estimators by augmenting the latent space with a set of importance samples, similarly to the importance weighted auto-encoder (IWAE), and then constructing a Markov chain Monte Carlo (MCMC) coupling procedure on this augmented space. We provide the conditions under which the estimators can be computed in finite time and have finite variance. We demonstrate experimentally that VAEs fitted with unbiased estimators exhibit better predictive performance on three image datasets.
Blind Super-Resolution Kernel Estimation using an Internal-GAN
Oct 24, 2019
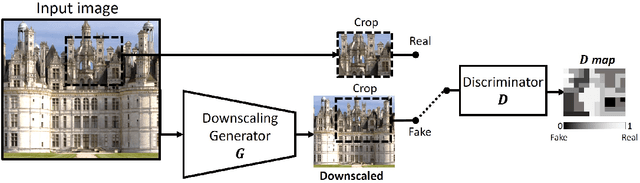
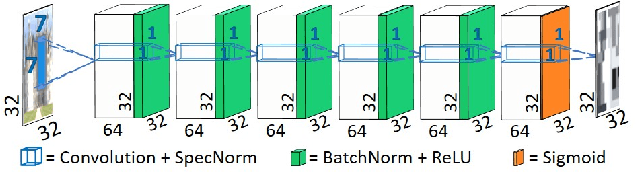
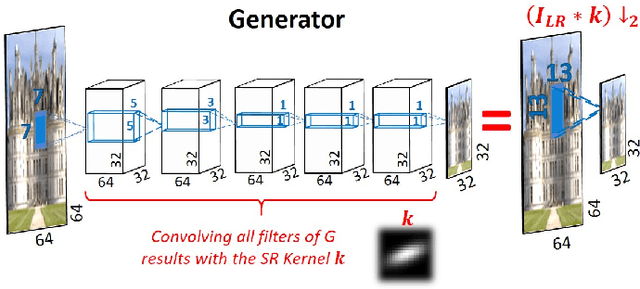
Super resolution (SR) methods typically assume that the low-resolution (LR) image was downscaled from the unknown high-resolution (HR) image by a fixed 'ideal' downscaling kernel (e.g. Bicubic downscaling). However, this is rarely the case in real LR images, in contrast to synthetically generated SR datasets. When the assumed downscaling kernel deviates from the true one, the performance of SR methods significantly deteriorates. This gave rise to Blind-SR - namely, SR when the downscaling kernel ("SR-kernel") is unknown. It was further shown that the true SR-kernel is the one that maximizes the recurrence of patches across scales of the LR image. In this paper we show how this powerful cross-scale recurrence property can be realized using Deep Internal Learning. We introduce "KernelGAN", an image-specific Internal-GAN, which trains solely on the LR test image at test time, and learns its internal distribution of patches. Its Generator is trained to produce a downscaled version of the LR test image, such that its Discriminator cannot distinguish between the patch distribution of the downscaled image, and the patch distribution of the original LR image. The Generator, once trained, constitutes the downscaling operation with the correct image-specific SR-kernel. KernelGAN is fully unsupervised, requires no training data other than the input image itself, and leads to state-of-the-art results in Blind-SR when plugged into existing SR algorithms.
DeepCorn: A Semi-Supervised Deep Learning Method for High-Throughput Image-Based Corn Kernel Counting and Yield Estimation
Jul 20, 2020

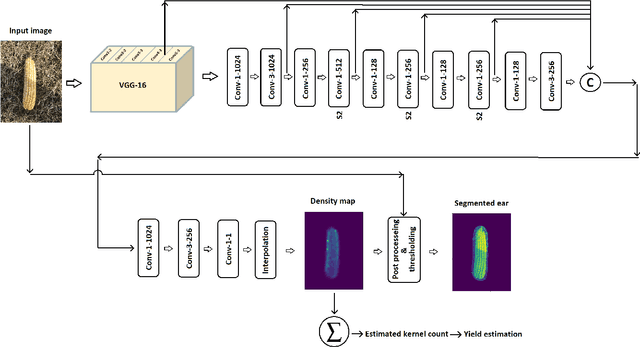
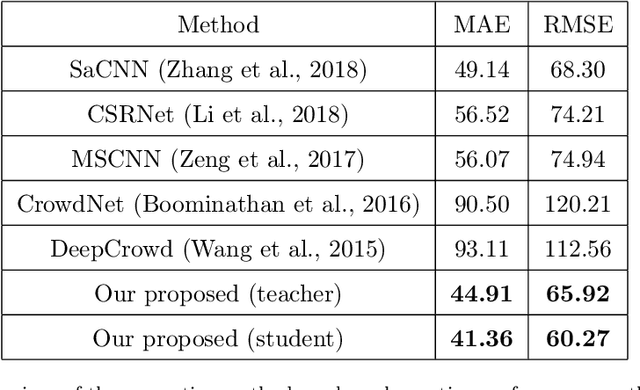
The success of modern farming and plant breeding relies on accurate and efficient collection of data. For a commercial organization that manages large amounts of crops, collecting accurate and consistent data is a bottleneck. Due to limited time and labor, accurately phenotyping crops to record color, head count, height, weight, etc. is severely limited. However, this information, combined with other genetic and environmental factors, is vital for developing new superior crop species that help feed the world's growing population. Recent advances in machine learning, in particular deep learning, have shown promise in mitigating this bottleneck. In this paper, we propose a novel deep learning method for counting on-ear corn kernels in-field to aid in the gathering of real-time data and, ultimately, to improve decision making to maximize yield. We name this approach DeepCorn, and show that this framework is robust under various conditions and can accurately and efficiently count corn kernels. We also adopt a semi-supervised learning approach to further improve the performance of our proposed method. Our experimental results demonstrate the superiority and effectiveness of our proposed method compared to other state-of-the-art methods.
Adaptive Tag Selection for Image Annotation
Sep 17, 2014

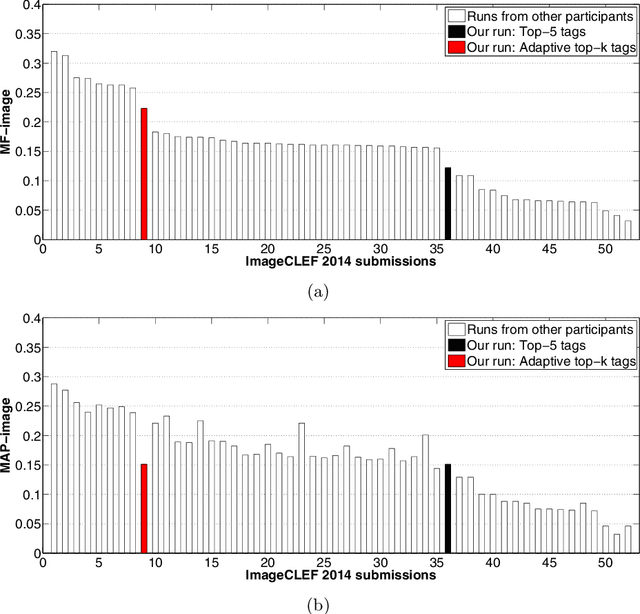

Not all tags are relevant to an image, and the number of relevant tags is image-dependent. Although many methods have been proposed for image auto-annotation, the question of how to determine the number of tags to be selected per image remains open. The main challenge is that for a large tag vocabulary, there is often a lack of ground truth data for acquiring optimal cutoff thresholds per tag. In contrast to previous works that pre-specify the number of tags to be selected, we propose in this paper adaptive tag selection. The key insight is to divide the vocabulary into two disjoint subsets, namely a seen set consisting of tags having ground truth available for optimizing their thresholds and a novel set consisting of tags without any ground truth. Such a division allows us to estimate how many tags shall be selected from the novel set according to the tags that have been selected from the seen set. The effectiveness of the proposed method is justified by our participation in the ImageCLEF 2014 image annotation task. On a set of 2,065 test images with ground truth available for 207 tags, the benchmark evaluation shows that compared to the popular top-$k$ strategy which obtains an F-score of 0.122, adaptive tag selection achieves a higher F-score of 0.223. Moreover, by treating the underlying image annotation system as a black box, the new method can be used as an easy plug-in to boost the performance of existing systems.