 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
6D-Diff: A Keypoint Diffusion Framework for 6D Object Pose Estimation
Jan 02, 2024
Estimating the 6D object pose from a single RGB image often involves noise and indeterminacy due to challenges such as occlusions and cluttered backgrounds. Meanwhile, diffusion models have shown appealing performance in generating high-quality images from random noise with high indeterminacy through step-by-step denoising. Inspired by their denoising capability, we propose a novel diffusion-based framework (6D-Diff) to handle the noise and indeterminacy in object pose estimation for better performance. In our framework, to establish accurate 2D-3D correspondence, we formulate 2D keypoints detection as a reverse diffusion (denoising) process. To facilitate such a denoising process, we design a Mixture-of-Cauchy-based forward diffusion process and condition the reverse process on the object features. Extensive experiments on the LM-O and YCB-V datasets demonstrate the effectiveness of our framework.
Joint Deep Image Restoration and Unsupervised Quality Assessment
Nov 27, 2023Deep learning techniques have revolutionized the fields of image restoration and image quality assessment in recent years. While image restoration methods typically utilize synthetically distorted training data for training, deep quality assessment models often require expensive labeled subjective data. However, recent studies have shown that activations of deep neural networks trained for visual modeling tasks can also be used for perceptual quality assessment of images. Following this intuition, we propose a novel attention-based convolutional neural network capable of simultaneously performing both image restoration and quality assessment. We achieve this by training a JPEG deblocking network augmented with "quality attention" maps and demonstrating state-of-the-art deblocking accuracy, achieving a high correlation of predicted quality with human opinion scores.
TPatch: A Triggered Physical Adversarial Patch
Dec 30, 2023Autonomous vehicles increasingly utilize the vision-based perception module to acquire information about driving environments and detect obstacles. Correct detection and classification are important to ensure safe driving decisions. Existing works have demonstrated the feasibility of fooling the perception models such as object detectors and image classifiers with printed adversarial patches. However, most of them are indiscriminately offensive to every passing autonomous vehicle. In this paper, we propose TPatch, a physical adversarial patch triggered by acoustic signals. Unlike other adversarial patches, TPatch remains benign under normal circumstances but can be triggered to launch a hiding, creating or altering attack by a designed distortion introduced by signal injection attacks towards cameras. To avoid the suspicion of human drivers and make the attack practical and robust in the real world, we propose a content-based camouflage method and an attack robustness enhancement method to strengthen it. Evaluations with three object detectors, YOLO V3/V5 and Faster R-CNN, and eight image classifiers demonstrate the effectiveness of TPatch in both the simulation and the real world. We also discuss possible defenses at the sensor, algorithm, and system levels.
Large Language Models are Good Prompt Learners for Low-Shot Image Classification
Dec 07, 2023Low-shot image classification, where training images are limited or inaccessible, has benefited from recent progress on pre-trained vision-language (VL) models with strong generalizability, e.g. CLIP. Prompt learning methods built with VL models generate text features from the class names that only have confined class-specific information. Large Language Models (LLMs), with their vast encyclopedic knowledge, emerge as the complement. Thus, in this paper, we discuss the integration of LLMs to enhance pre-trained VL models, specifically on low-shot classification. However, the domain gap between language and vision blocks the direct application of LLMs. Thus, we propose LLaMP, Large Language Models as Prompt learners, that produces adaptive prompts for the CLIP text encoder, establishing it as the connecting bridge. Experiments show that, compared with other state-of-the-art prompt learning methods, LLaMP yields better performance on both zero-shot generalization and few-shot image classification, over a spectrum of 11 datasets.
Image Super-Resolution with Text Prompt Diffusion
Nov 24, 2023
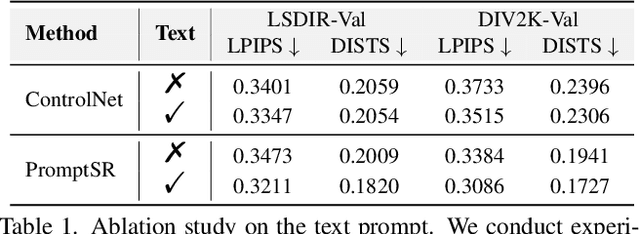
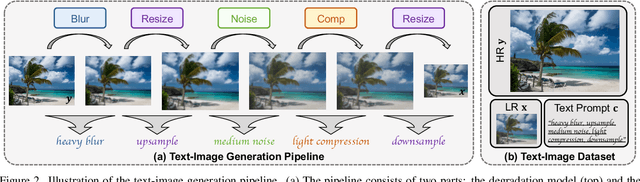
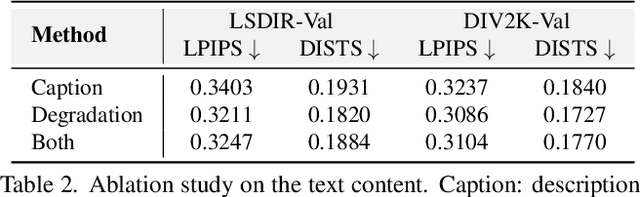
Image super-resolution (SR) methods typically model degradation to improve reconstruction accuracy in complex and unknown degradation scenarios. However, extracting degradation information from low-resolution images is challenging, which limits the model performance. To boost image SR performance, one feasible approach is to introduce additional priors. Inspired by advancements in multi-modal methods and text prompt image processing, we introduce text prompts to image SR to provide degradation priors. Specifically, we first design a text-image generation pipeline to integrate text into SR dataset through the text degradation representation and degradation model. The text representation applies a discretization manner based on the binning method to describe the degradation abstractly. This representation method can also maintain the flexibility of language. Meanwhile, we propose the PromptSR to realize the text prompt SR. The PromptSR employs the diffusion model and the pre-trained language model (e.g., T5 and CLIP). We train the model on the generated text-image dataset. Extensive experiments indicate that introducing text prompts into image SR, yields excellent results on both synthetic and real-world images. Code: https://github.com/zhengchen1999/PromptSR.
DarkShot: Lighting Dark Images with Low-Compute and High-Quality
Dec 29, 2023Nighttime photography encounters escalating challenges in extremely low-light conditions, primarily attributable to the ultra-low signal-to-noise ratio. For real-world deployment, a practical solution must not only produce visually appealing results but also require minimal computation. However, most existing methods are either focused on improving restoration performance or employ lightweight models at the cost of quality. This paper proposes a lightweight network that outperforms existing state-of-the-art (SOTA) methods in low-light enhancement tasks while minimizing computation. The proposed network incorporates Siamese Self-Attention Block (SSAB) and Skip-Channel Attention (SCA) modules, which enhance the model's capacity to aggregate global information and are well-suited for high-resolution images. Additionally, based on our analysis of the low-light image restoration process, we propose a Two-Stage Framework that achieves superior results. Our model can restore a UHD 4K resolution image with minimal computation while keeping SOTA restoration quality.
Perceptual Image Compression with Cooperative Cross-Modal Side Information
Nov 28, 2023The explosion of data has resulted in more and more associated text being transmitted along with images. Inspired by from distributed source coding, many works utilize image side information to enhance image compression. However, existing methods generally do not consider using text as side information to enhance perceptual compression of images, even though the benefits of multimodal synergy have been widely demonstrated in research. This begs the following question: How can we effectively transfer text-level semantic dependencies to help image compression, which is only available to the decoder? In this work, we propose a novel deep image compression method with text-guided side information to achieve a better rate-perception-distortion tradeoff. Specifically, we employ the CLIP text encoder and an effective Semantic-Spatial Aware block to fuse the text and image features. This is done by predicting a semantic mask to guide the learned text-adaptive affine transformation at the pixel level. Furthermore, we design a text-conditional generative adversarial networks to improve the perceptual quality of reconstructed images. Extensive experiments involving four datasets and ten image quality assessment metrics demonstrate that the proposed approach achieves superior results in terms of rate-perception trade-off and semantic distortion.
Passive Non-Line-of-Sight Imaging with Light Transport Modulation
Dec 26, 2023Passive non-line-of-sight (NLOS) imaging has witnessed rapid development in recent years, due to its ability to image objects that are out of sight. The light transport condition plays an important role in this task since changing the conditions will lead to different imaging models. Existing learning-based NLOS methods usually train independent models for different light transport conditions, which is computationally inefficient and impairs the practicality of the models. In this work, we propose NLOS-LTM, a novel passive NLOS imaging method that effectively handles multiple light transport conditions with a single network. We achieve this by inferring a latent light transport representation from the projection image and using this representation to modulate the network that reconstructs the hidden image from the projection image. We train a light transport encoder together with a vector quantizer to obtain the light transport representation. To further regulate this representation, we jointly learn both the reconstruction network and the reprojection network during training. A set of light transport modulation blocks is used to modulate the two jointly trained networks in a multi-scale way. Extensive experiments on a large-scale passive NLOS dataset demonstrate the superiority of the proposed method. The code is available at https://github.com/JerryOctopus/NLOS-LTM.
Learning Generalizable Perceptual Representations for Data-Efficient No-Reference Image Quality Assessment
Dec 08, 2023No-reference (NR) image quality assessment (IQA) is an important tool in enhancing the user experience in diverse visual applications. A major drawback of state-of-the-art NR-IQA techniques is their reliance on a large number of human annotations to train models for a target IQA application. To mitigate this requirement, there is a need for unsupervised learning of generalizable quality representations that capture diverse distortions. We enable the learning of low-level quality features agnostic to distortion types by introducing a novel quality-aware contrastive loss. Further, we leverage the generalizability of vision-language models by fine-tuning one such model to extract high-level image quality information through relevant text prompts. The two sets of features are combined to effectively predict quality by training a simple regressor with very few samples on a target dataset. Additionally, we design zero-shot quality predictions from both pathways in a completely blind setting. Our experiments on diverse datasets encompassing various distortions show the generalizability of the features and their superior performance in the data-efficient and zero-shot settings. Code will be made available at https://github.com/suhas-srinath/GRepQ.
Personalized Restoration via Dual-Pivot Tuning
Dec 28, 2023Generative diffusion models can serve as a prior which ensures that solutions of image restoration systems adhere to the manifold of natural images. However, for restoring facial images, a personalized prior is necessary to accurately represent and reconstruct unique facial features of a given individual. In this paper, we propose a simple, yet effective, method for personalized restoration, called Dual-Pivot Tuning - a two-stage approach that personalize a blind restoration system while maintaining the integrity of the general prior and the distinct role of each component. Our key observation is that for optimal personalization, the generative model should be tuned around a fixed text pivot, while the guiding network should be tuned in a generic (non-personalized) manner, using the personalized generative model as a fixed ``pivot". This approach ensures that personalization does not interfere with the restoration process, resulting in a natural appearance with high fidelity to the person's identity and the attributes of the degraded image. We evaluated our approach both qualitatively and quantitatively through extensive experiments with images of widely recognized individuals, comparing it against relevant baselines. Surprisingly, we found that our personalized prior not only achieves higher fidelity to identity with respect to the person's identity, but also outperforms state-of-the-art generic priors in terms of general image quality. Project webpage: https://personalized-restoration.github.io