 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On the Convergence of Continual Learning with Adaptive Methods
Apr 15, 2024
One of the objectives of continual learning is to prevent catastrophic forgetting in learning multiple tasks sequentially, and the existing solutions have been driven by the conceptualization of the plasticity-stability dilemma. However, the convergence of continual learning for each sequential task is less studied so far. In this paper, we provide a convergence analysis of memory-based continual learning with stochastic gradient descent and empirical evidence that training current tasks causes the cumulative degradation of previous tasks. We propose an adaptive method for nonconvex continual learning (NCCL), which adjusts step sizes of both previous and current tasks with the gradients. The proposed method can achieve the same convergence rate as the SGD method when the catastrophic forgetting term which we define in the paper is suppressed at each iteration. Further, we demonstrate that the proposed algorithm improves the performance of continual learning over existing methods for several image classification tasks.
* Proceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence (UAI 2023), see https://proceedings.mlr.press/v216/han23a.html
Reuse out-of-year data to enhance land cover mappingvia feature disentanglement and contrastive learning
Apr 17, 2024Timely up-to-date land use/land cover (LULC) maps play a pivotal role in supporting agricultural territory management, environmental monitoring and facilitating well-informed and sustainable decision-making. Typically, when creating a land cover (LC) map, precise ground truth data is collected through time-consuming and expensive field campaigns. This data is then utilized in conjunction with satellite image time series (SITS) through advanced machine learning algorithms to get the final map. Unfortunately, each time this process is repeated (e.g., annually over a region to estimate agricultural production or potential biodiversity loss), new ground truth data must be collected, leading to the complete disregard of previously gathered reference data despite the substantial financial and time investment they have required. How to make value of historical data, from the same or similar study sites, to enhance the current LULC mapping process constitutes a significant challenge that could enable the financial and human-resource efforts invested in previous data campaigns to be valued again. Aiming to tackle this important challenge, we here propose a deep learning framework based on recent advances in domain adaptation and generalization to combine remote sensing and reference data coming from two different domains (e.g. historical data and fresh ones) to ameliorate the current LC mapping process. Our approach, namely REFeD (data Reuse with Effective Feature Disentanglement for land cover mapping), leverages a disentanglement strategy, based on contrastive learning, where invariant and specific per-domain features are derived to recover the intrinsic information related to the downstream LC mapping task and alleviate possible distribution shifts between domains. Additionally, REFeD is equipped with an effective supervision scheme where feature disentanglement is further enforced via multiple levels of supervision at different granularities. The experimental assessment over two study areas covering extremely diverse and contrasted landscapes, namely Koumbia (located in the West-Africa region, in Burkina Faso) and Centre Val de Loire (located in centre Europe, France), underlines the quality of our framework and the obtained findings demonstrate that out-of-year information coming from the same (or similar) study site, at different periods of time, can constitute a valuable additional source of information to enhance the LC mapping process.
Image-to-Image Matching via Foundation Models: A New Perspective for Open-Vocabulary Semantic Segmentation
Mar 30, 2024Open-vocabulary semantic segmentation (OVS) aims to segment images of arbitrary categories specified by class labels or captions. However, most previous best-performing methods, whether pixel grouping methods or region recognition methods, suffer from false matches between image features and category labels. We attribute this to the natural gap between the textual features and visual features. In this work, we rethink how to mitigate false matches from the perspective of image-to-image matching and propose a novel relation-aware intra-modal matching (RIM) framework for OVS based on visual foundation models. RIM achieves robust region classification by firstly constructing diverse image-modal reference features and then matching them with region features based on relation-aware ranking distribution. The proposed RIM enjoys several merits. First, the intra-modal reference features are better aligned, circumventing potential ambiguities that may arise in cross-modal matching. Second, the ranking-based matching process harnesses the structure information implicit in the inter-class relationships, making it more robust than comparing individually. Extensive experiments on three benchmarks demonstrate that RIM outperforms previous state-of-the-art methods by large margins, obtaining a lead of more than 10% in mIoU on PASCAL VOC benchmark.
A Universal Knowledge Embedded Contrastive Learning Framework for Hyperspectral Image Classification
Apr 06, 2024Hyperspectral image (HSI) classification techniques have been intensively studied and a variety of models have been developed. However, these HSI classification models are confined to pocket models and unrealistic ways of datasets partitioning. The former limits the generalization performance of the model and the latter is partitioned leads to inflated model evaluation metrics, which results in plummeting model performance in the real world. Therefore, we propose a universal knowledge embedded contrastive learning framework (KnowCL) for supervised, unsupervised, and semisupervised HSI classification, which largely closes the gap of HSI classification models between pocket models and standard vision backbones. We present a new HSI processing pipeline in conjunction with a range of data transformation and augmentation techniques that provide diverse data representations and realistic data partitioning. The proposed framework based on this pipeline is compatible with all kinds of backbones and can fully exploit labeled and unlabeled samples with expected training time. Furthermore, we design a new loss function, which can adaptively fuse the supervised loss and unsupervised loss, enhancing the learning performance. This proposed new classification paradigm shows great potentials in exploring for HSI classification technology. The code can be accessed at https://github.com/quanweiliu/KnowCL.
Detecting Image Attribution for Text-to-Image Diffusion Models in RGB and Beyond
Mar 28, 2024Modern text-to-image (T2I) diffusion models can generate images with remarkable realism and creativity. These advancements have sparked research in fake image detection and attribution, yet prior studies have not fully explored the practical and scientific dimensions of this task. In addition to attributing images to 12 state-of-the-art T2I generators, we provide extensive analyses on what inference stage hyperparameters and image modifications are discernible. Our experiments reveal that initialization seeds are highly detectable, along with other subtle variations in the image generation process to some extent. We further investigate what visual traces are leveraged in image attribution by perturbing high-frequency details and employing mid-level representations of image style and structure. Notably, altering high-frequency information causes only slight reductions in accuracy, and training an attributor on style representations outperforms training on RGB images. Our analyses underscore that fake images are detectable and attributable at various levels of visual granularity than previously explored.
TSNet:A Two-stage Network for Image Dehazing with Multi-scale Fusion and Adaptive Learning
Apr 03, 2024Image dehazing has been a popular topic of research for a long time. Previous deep learning-based image dehazing methods have failed to achieve satisfactory dehazing effects on both synthetic datasets and real-world datasets, exhibiting poor generalization. Moreover, single-stage networks often result in many regions with artifacts and color distortion in output images. To address these issues, this paper proposes a two-stage image dehazing network called TSNet, mainly consisting of the multi-scale fusion module (MSFM) and the adaptive learning module (ALM). Specifically, MSFM and ALM enhance the generalization of TSNet. The MSFM can obtain large receptive fields at multiple scales and integrate features at different frequencies to reduce the differences between inputs and learning objectives. The ALM can actively learn of regions of interest in images and restore texture details more effectively. Additionally, TSNet is designed as a two-stage network, where the first-stage network performs image dehazing, and the second-stage network is employed to improve issues such as artifacts and color distortion present in the results of the first-stage network. We also change the learning objective from ground truth images to opposite fog maps, which improves the learning efficiency of TSNet. Extensive experiments demonstrate that TSNet exhibits superior dehazing performance on both synthetic and real-world datasets compared to previous state-of-the-art methods.
MC$^2$: Multi-concept Guidance for Customized Multi-concept Generation
Apr 12, 2024Customized text-to-image generation aims to synthesize instantiations of user-specified concepts and has achieved unprecedented progress in handling individual concept. However, when extending to multiple customized concepts, existing methods exhibit limitations in terms of flexibility and fidelity, only accommodating the combination of limited types of models and potentially resulting in a mix of characteristics from different concepts. In this paper, we introduce the Multi-concept guidance for Multi-concept customization, termed MC$^2$, for improved flexibility and fidelity. MC$^2$ decouples the requirements for model architecture via inference time optimization, allowing the integration of various heterogeneous single-concept customized models. It adaptively refines the attention weights between visual and textual tokens, directing image regions to focus on their associated words while diminishing the impact of irrelevant ones. Extensive experiments demonstrate that MC$^2$ even surpasses previous methods that require additional training in terms of consistency with input prompt and reference images. Moreover, MC$^2$ can be extended to elevate the compositional capabilities of text-to-image generation, yielding appealing results. Code will be publicly available at https://github.com/JIANGJiaXiu/MC-2.
Adapting CNNs for Fisheye Cameras without Retraining
Apr 12, 2024The majority of image processing approaches assume images are in or can be rectified to a perspective projection. However, in many applications it is beneficial to use non conventional cameras, such as fisheye cameras, that have a larger field of view (FOV). The issue arises that these large-FOV images can't be rectified to a perspective projection without significant cropping of the original image. To address this issue we propose Rectified Convolutions (RectConv); a new approach for adapting pre-trained convolutional networks to operate with new non-perspective images, without any retraining. Replacing the convolutional layers of the network with RectConv layers allows the network to see both rectified patches and the entire FOV. We demonstrate RectConv adapting multiple pre-trained networks to perform segmentation and detection on fisheye imagery from two publicly available datasets. Our approach requires no additional data or training, and operates directly on the native image as captured from the camera. We believe this work is a step toward adapting the vast resources available for perspective images to operate across a broad range of camera geometries.
Knowledge-enhanced Visual-Language Pretraining for Computational Pathology
Apr 15, 2024In this paper, we consider the problem of visual representation learning for computational pathology, by exploiting large-scale image-text pairs gathered from public resources, along with the domain specific knowledge in pathology. Specifically, we make the following contributions: (i) We curate a pathology knowledge tree that consists of 50,470 informative attributes for 4,718 diseases requiring pathology diagnosis from 32 human tissues. To our knowledge, this is the first comprehensive structured pathology knowledge base; (ii) We develop a knowledge-enhanced visual-language pretraining approach, where we first project pathology-specific knowledge into latent embedding space via language model, and use it to guide the visual representation learning; (iii) We conduct thorough experiments to validate the effectiveness of our proposed components, demonstrating significant performance improvement on various downstream tasks, including cross-modal retrieval, zero-shot classification on pathology patches, and zero-shot tumor subtyping on whole slide images (WSIs). All codes, models and the pathology knowledge tree will be released to the research community
Flickr30K-CFQ: A Compact and Fragmented Query Dataset for Text-image Retrieval
Apr 01, 2024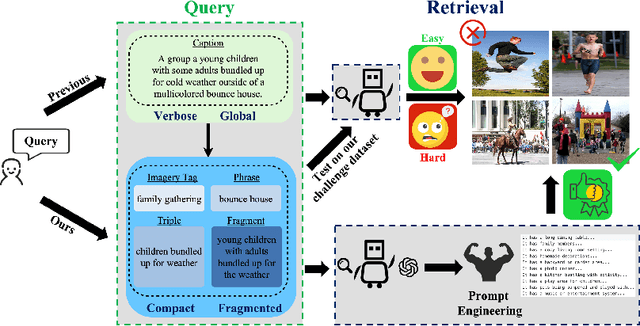

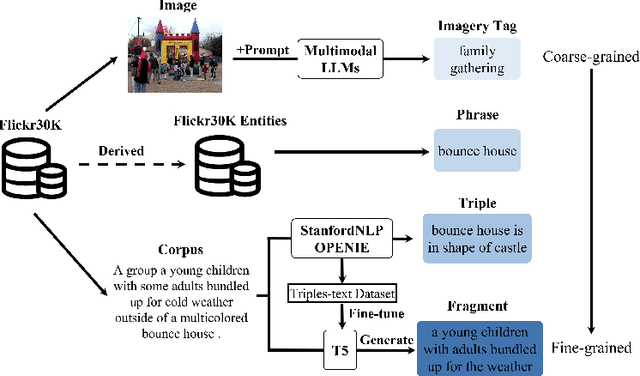

With the explosive growth of multi-modal information on the Internet, unimodal search cannot satisfy the requirement of Internet applications. Text-image retrieval research is needed to realize high-quality and efficient retrieval between different modalities. Existing text-image retrieval research is mostly based on general vision-language datasets (e.g. MS-COCO, Flickr30K), in which the query utterance is rigid and unnatural (i.e. verbosity and formality). To overcome the shortcoming, we construct a new Compact and Fragmented Query challenge dataset (named Flickr30K-CFQ) to model text-image retrieval task considering multiple query content and style, including compact and fine-grained entity-relation corpus. We propose a novel query-enhanced text-image retrieval method using prompt engineering based on LLM. Experiments show that our proposed Flickr30-CFQ reveals the insufficiency of existing vision-language datasets in realistic text-image tasks. Our LLM-based Query-enhanced method applied on different existing text-image retrieval models improves query understanding performance both on public dataset and our challenge set Flickr30-CFQ with over 0.9% and 2.4% respectively. Our project can be available anonymously in https://sites.google.com/view/Flickr30K-cfq.