 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Signs in time: Encoding human motion as a temporal image
Aug 06, 2016
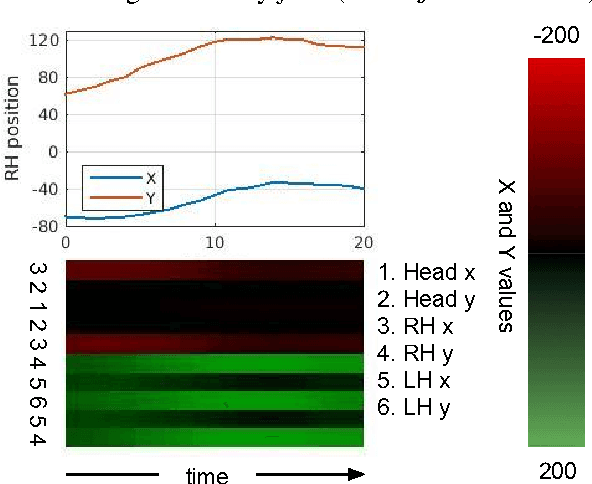
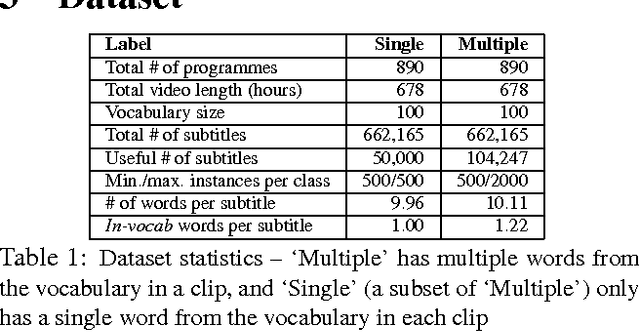

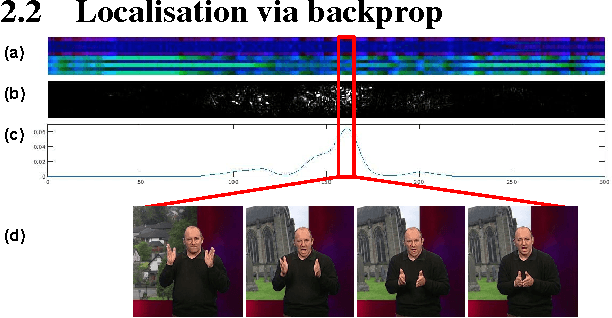
The goal of this work is to recognise and localise short temporal signals in image time series, where strong supervision is not available for training. To this end we propose an image encoding that concisely represents human motion in a video sequence in a form that is suitable for learning with a ConvNet. The encoding reduces the pose information from an image to a single column, dramatically diminishing the input requirements for the network, but retaining the essential information for recognition. The encoding is applied to the task of recognizing and localizing signed gestures in British Sign Language (BSL) videos. We demonstrate that using the proposed encoding, signs as short as 10 frames duration can be learnt from clips lasting hundreds of frames using only weak (clip level) supervision and with considerable label noise.
PFA-GAN: Progressive Face Aging with Generative Adversarial Network
Dec 07, 2020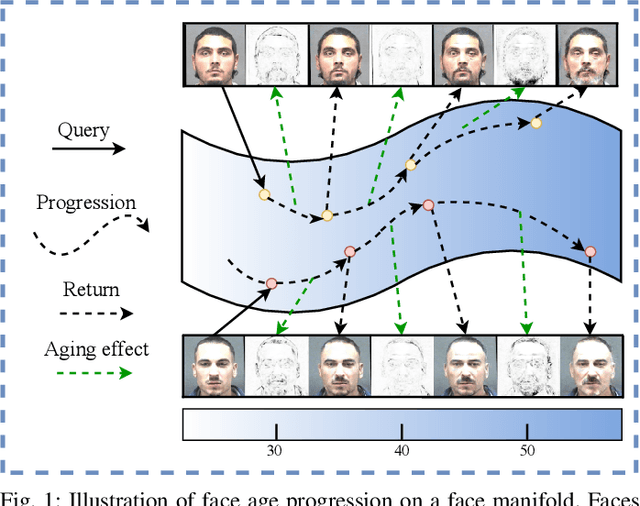



Face aging is to render a given face to predict its future appearance, which plays an important role in the information forensics and security field as the appearance of the face typically varies with age. Although impressive results have been achieved with conditional generative adversarial networks (cGANs), the existing cGANs-based methods typically use a single network to learn various aging effects between any two different age groups. However, they cannot simultaneously meet three essential requirements of face aging -- including image quality, aging accuracy, and identity preservation -- and usually generate aged faces with strong ghost artifacts when the age gap becomes large. Inspired by the fact that faces gradually age over time, this paper proposes a novel progressive face aging framework based on generative adversarial network (PFA-GAN) to mitigate these issues. Unlike the existing cGANs-based methods, the proposed framework contains several sub-networks to mimic the face aging process from young to old, each of which only learns some specific aging effects between two adjacent age groups. The proposed framework can be trained in an end-to-end manner to eliminate accumulative artifacts and blurriness. Moreover, this paper introduces an age estimation loss to take into account the age distribution for an improved aging accuracy, and proposes to use the Pearson correlation coefficient as an evaluation metric measuring the aging smoothness for face aging methods. Extensively experimental results demonstrate superior performance over existing (c)GANs-based methods, including the state-of-the-art one, on two benchmarked datasets. The source code is available at~\url{https://github.com/Hzzone/PFA-GAN}.
Unbiased Gradient Estimation for Variational Auto-Encoders using Coupled Markov Chains
Oct 05, 2020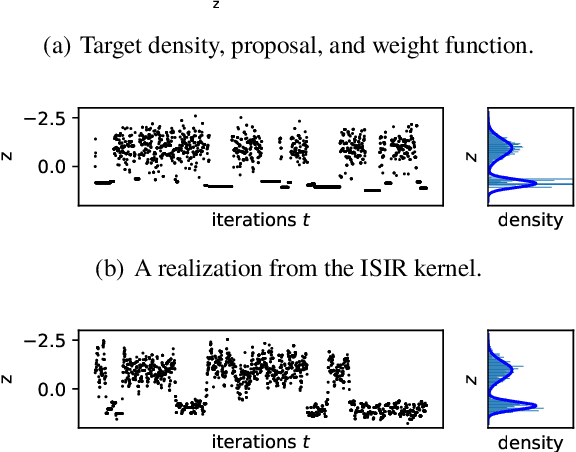
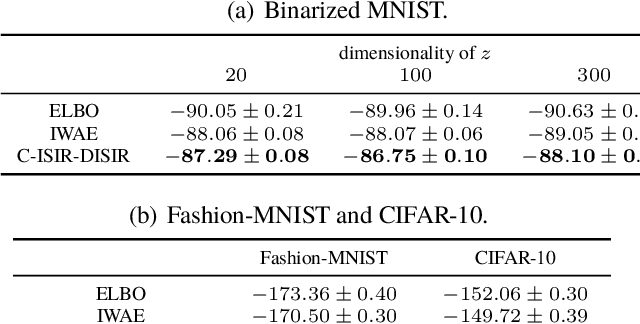
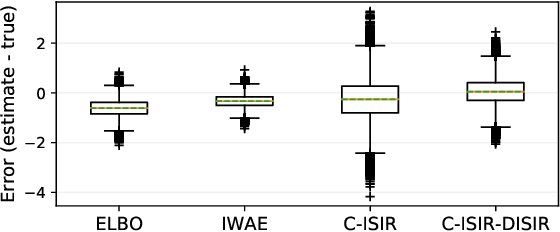
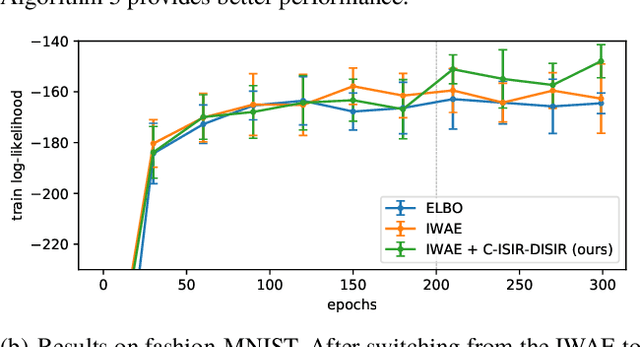
The variational auto-encoder (VAE) is a deep latent variable model that has two neural networks in an autoencoder-like architecture; one of them parameterizes the model's likelihood. Fitting its parameters via maximum likelihood is challenging since the computation of the likelihood involves an intractable integral over the latent space; thus the VAE is trained instead by maximizing a variational lower bound. Here, we develop a maximum likelihood training scheme for VAEs by introducing unbiased gradient estimators of the log-likelihood. We obtain the unbiased estimators by augmenting the latent space with a set of importance samples, similarly to the importance weighted auto-encoder (IWAE), and then constructing a Markov chain Monte Carlo (MCMC) coupling procedure on this augmented space. We provide the conditions under which the estimators can be computed in finite time and have finite variance. We demonstrate experimentally that VAEs fitted with unbiased estimators exhibit better predictive performance on three image datasets.
Exploring Nearest Neighbor Approaches for Image Captioning
May 17, 2015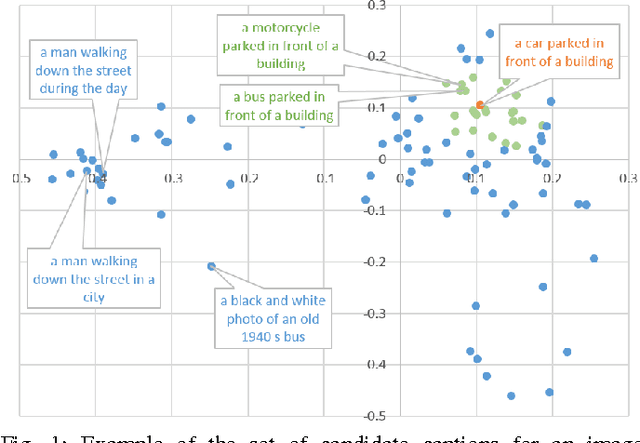
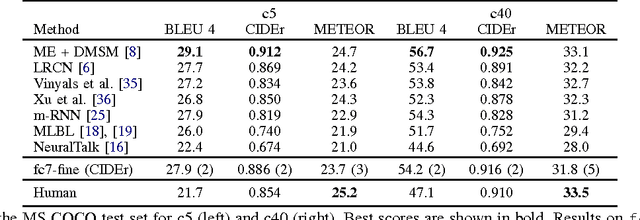

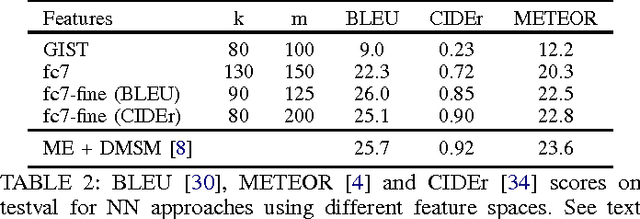
We explore a variety of nearest neighbor baseline approaches for image captioning. These approaches find a set of nearest neighbor images in the training set from which a caption may be borrowed for the query image. We select a caption for the query image by finding the caption that best represents the "consensus" of the set of candidate captions gathered from the nearest neighbor images. When measured by automatic evaluation metrics on the MS COCO caption evaluation server, these approaches perform as well as many recent approaches that generate novel captions. However, human studies show that a method that generates novel captions is still preferred over the nearest neighbor approach.
Find it if You Can: End-to-End Adversarial Erasing for Weakly-Supervised Semantic Segmentation
Nov 09, 2020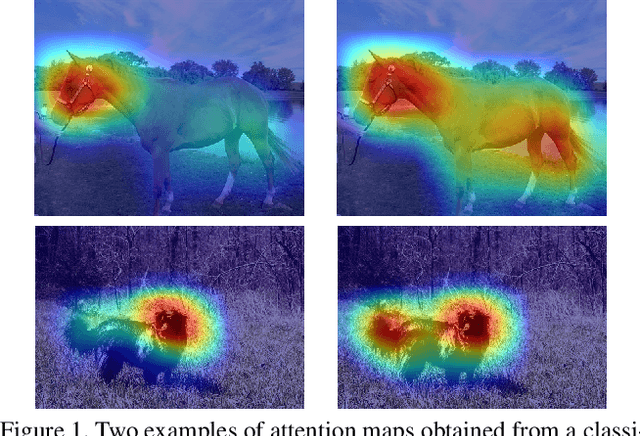
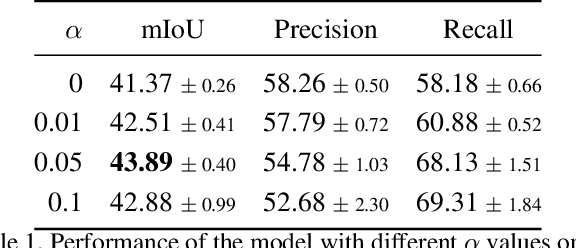


Semantic segmentation is a task that traditionally requires a large dataset of pixel-level ground truth labels, which is time-consuming and expensive to obtain. Recent advancements in the weakly-supervised setting show that reasonable performance can be obtained by using only image-level labels. Classification is often used as a proxy task to train a deep neural network from which attention maps are extracted. However, the classification task needs only the minimum evidence to make predictions, hence it focuses on the most discriminative object regions. To overcome this problem, we propose a novel formulation of adversarial erasing of the attention maps. In contrast to previous adversarial erasing methods, we optimize two networks with opposing loss functions, which eliminates the requirement of certain suboptimal strategies; for instance, having multiple training steps that complicate the training process or a weight sharing policy between networks operating on different distributions that might be suboptimal for performance. The proposed solution does not require saliency masks, instead it uses a regularization loss to prevent the attention maps from spreading to less discriminative object regions. Our experiments on the Pascal VOC dataset demonstrate that our adversarial approach increases segmentation performance by 2.1 mIoU compared to our baseline and by 1.0 mIoU compared to previous adversarial erasing approaches.
DeepGamble: Towards unlocking real-time player intelligence using multi-layer instance segmentation and attribute detection
Dec 14, 2020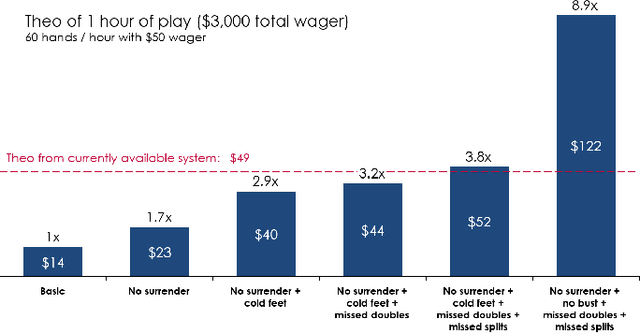
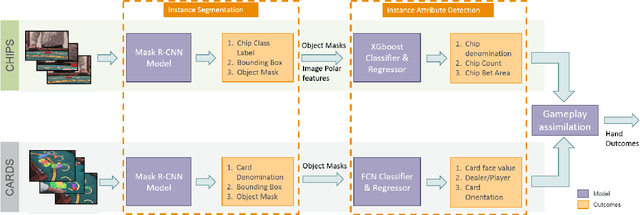
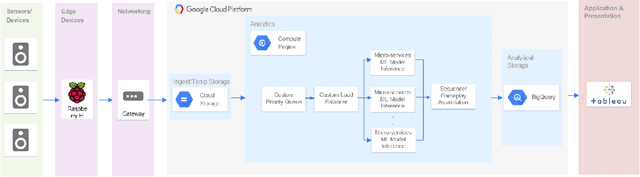

Annually the gaming industry spends approximately $15 billion in marketing reinvestment. However, this amount is spent without any consideration for the skill and luck of the player. For a casino, an unskilled player could fetch ~4 times more revenue than a skilled player. This paper describes a video recognition system that is based on an extension of the Mask R-CNN model. Our system digitizes the game of blackjack by detecting cards and player bets in real-time and processes decisions they took in order to create accurate player personas. Our proposed supervised learning approach consists of a specialized three-stage pipeline that takes images from two viewpoints of the casino table and does instance segmentation to generate masks on proposed regions of interest. These predicted masks along with derivative features are used to classify image attributes that are passed onto the next stage to assimilate the gameplay understanding. Our end-to-end model yields an accuracy of ~95% for the main bet detection and ~97% for card detection in a controlled environment trained using transfer learning approach with 900 training examples. Our approach is generalizable and scalable and shows promising results in varied gaming scenarios and test data. Such granular level gathered data, helped in understanding player's deviation from optimum strategy and thereby separate the skill of the player from the luck of the game. Our system also assesses the likelihood of card counting by correlating the player's betting pattern to the deck's scaled count. Such a system lets casinos flag fraudulent activity and calculate expected personalized profitability for each player and tailor their marketing reinvestment decisions.
A Deep Learning-Based Method for Automatic Segmentation of Proximal Femur from Quantitative Computed Tomography Images
Jun 09, 2020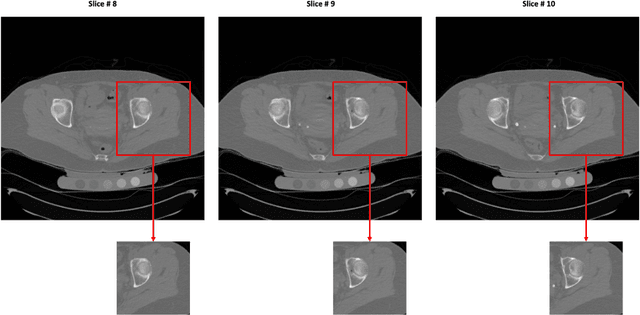
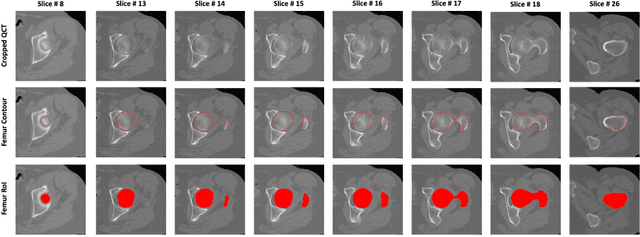

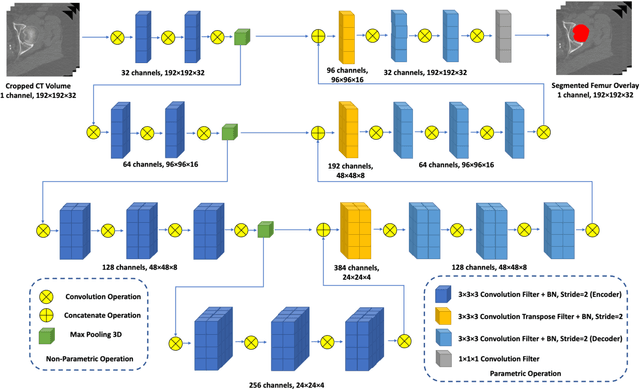
Purpose: Proximal femur image analyses based on quantitative computed tomography (QCT) provide a method to quantify the bone density and evaluate osteoporosis and risk of fracture. We aim to develop a deep-learning-based method for automatic proximal femur segmentation. Methods and Materials: We developed a 3D image segmentation method based on V-Net, an end-to-end fully convolutional neural network (CNN), to extract the proximal femur QCT images automatically. The proposed V-net methodology adopts a compound loss function, which includes a Dice loss and a L2 regularizer. We performed experiments to evaluate the effectiveness of the proposed segmentation method. In the experiments, a QCT dataset which included 397 QCT subjects was used. For the QCT image of each subject, the ground truth for the proximal femur was delineated by a well-trained scientist. During the experiments for the entire cohort then for male and female subjects separately, 90% of the subjects were used in 10-fold cross-validation for training and internal validation, and to select the optimal parameters of the proposed models; the rest of the subjects were used to evaluate the performance of models. Results: Visual comparison demonstrated high agreement between the model prediction and ground truth contours of the proximal femur portion of the QCT images. In the entire cohort, the proposed model achieved a Dice score of 0.9815, a sensitivity of 0.9852 and a specificity of 0.9992. In addition, an R2 score of 0.9956 (p<0.001) was obtained when comparing the volumes measured by our model prediction with the ground truth. Conclusion: This method shows a great promise for clinical application to QCT and QCT-based finite element analysis of the proximal femur for evaluating osteoporosis and hip fracture risk.
Single-Shot 3D Detection of Vehicles from Monocular RGB Images via Geometry Constrained Keypoints in Real-Time
Jun 23, 2020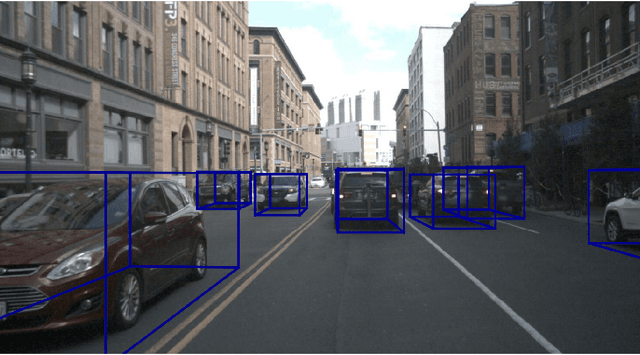
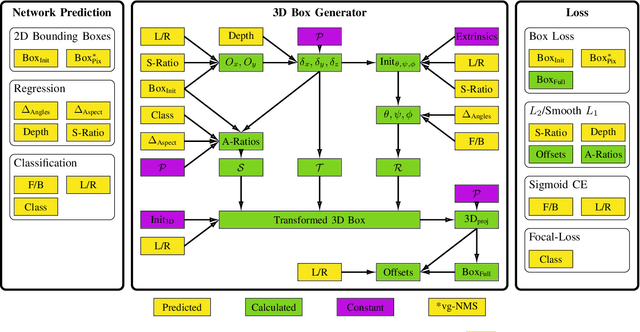
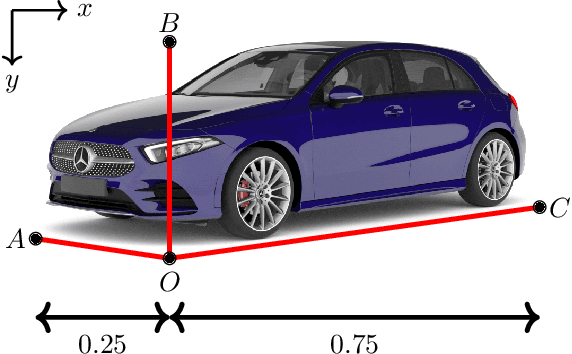

In this paper we propose a novel 3D single-shot object detection method for detecting vehicles in monocular RGB images. Our approach lifts 2D detections to 3D space by predicting additional regression and classification parameters and hence keeping the runtime close to pure 2D object detection. The additional parameters are transformed to 3D bounding box keypoints within the network under geometric constraints. Our proposed method features a full 3D description including all three angles of rotation without supervision by any labeled ground truth data for the object's orientation, as it focuses on certain keypoints within the image plane. While our approach can be combined with any modern object detection framework with only little computational overhead, we exemplify the extension of SSD for the prediction of 3D bounding boxes. We test our approach on different datasets for autonomous driving and evaluate it using the challenging KITTI 3D Object Detection as well as the novel nuScenes Object Detection benchmarks. While we achieve competitive results on both benchmarks we outperform current state-of-the-art methods in terms of speed with more than 20 FPS for all tested datasets and image resolutions.
On Mutual Information in Contrastive Learning for Visual Representations
May 27, 2020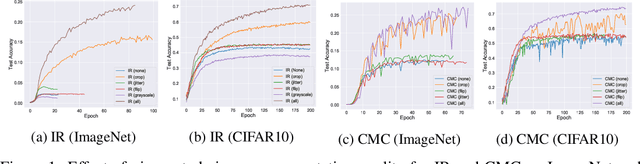
In recent years, several unsupervised, "contrastive" learning algorithms in vision have been shown to learn representations that perform remarkably well on transfer tasks. We show that this family of algorithms maximizes a lower bound on the mutual information between two or more "views" of an image; typical views come from a composition of image augmentations. Our bound generalizes the InfoNCE objective to support negative sampling from a restricted region of "difficult" contrasts. We find that the choice of (1) negative samples and (2) "views" are critical to the success of contrastive learning, the former of which is largely unexplored. The mutual information reformulation also simplifies and stabilizes previous learning objectives. In practice, our new objectives yield representations that outperform those learned with previous approaches for transfer to classification, bounding box detection, instance segmentation, and keypoint detection. The mutual information framework provides a unifying and rigorous comparison of approaches to contrastive learning and uncovers the choices that impact representation learning.
Extreme Consistency: Overcoming Annotation Scarcity and Domain Shifts
Apr 15, 2020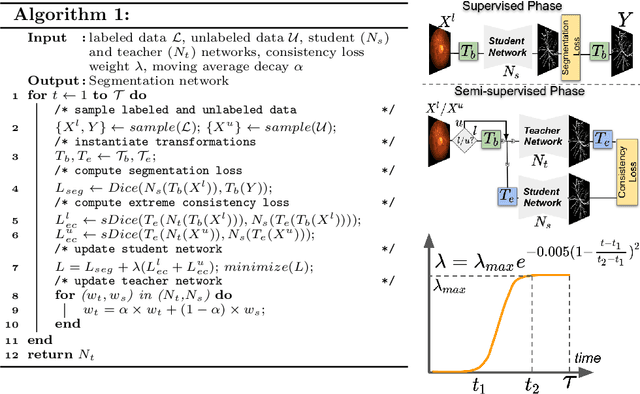
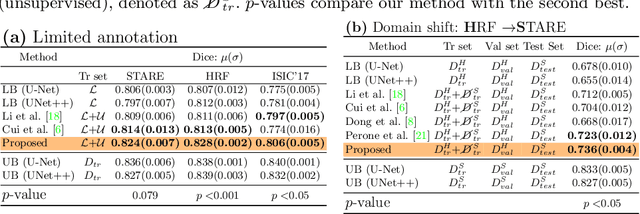
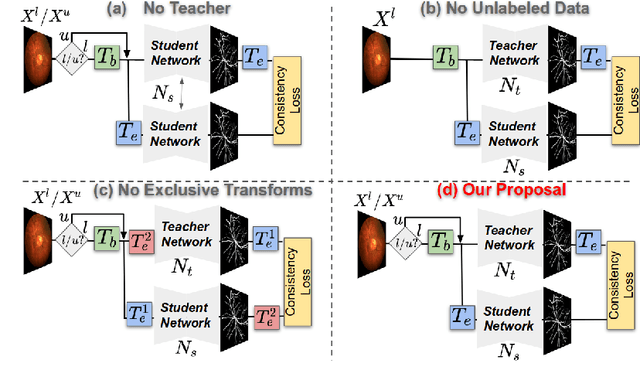
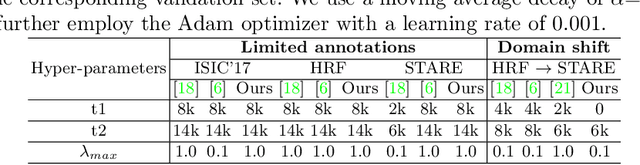
Supervised learning has proved effective for medical image analysis. However, it can utilize only the small labeled portion of data; it fails to leverage the large amounts of unlabeled data that is often available in medical image datasets. Supervised models are further handicapped by domain shifts, when the labeled dataset, despite being large enough, fails to cover different protocols or ethnicities. In this paper, we introduce \emph{extreme consistency}, which overcomes the above limitations, by maximally leveraging unlabeled data from the same or a different domain in a teacher-student semi-supervised paradigm. Extreme consistency is the process of sending an extreme transformation of a given image to the student network and then constraining its prediction to be consistent with the teacher network's prediction for the untransformed image. The extreme nature of our consistency loss distinguishes our method from related works that yield suboptimal performance by exercising only mild prediction consistency. Our method is 1) auto-didactic, as it requires no extra expert annotations; 2) versatile, as it handles both domain shift and limited annotation problems; 3) generic, as it is readily applicable to classification, segmentation, and detection tasks; and 4) simple to implement, as it requires no adversarial training. We evaluate our method for the tasks of lesion and retinal vessel segmentation in skin and fundus images. Our experiments demonstrate a significant performance gain over both modern supervised networks and recent semi-supervised models. This performance is attributed to the strong regularization enforced by extreme consistency, which enables the student network to learn how to handle extreme variants of both labeled and unlabeled images. This enhances the network's ability to tackle the inevitable same- and cross-domain data variability during inference.