 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Evaluation of Cross-View Matching to Improve Ground Vehicle Localization with Aerial Perception
Mar 26, 2020
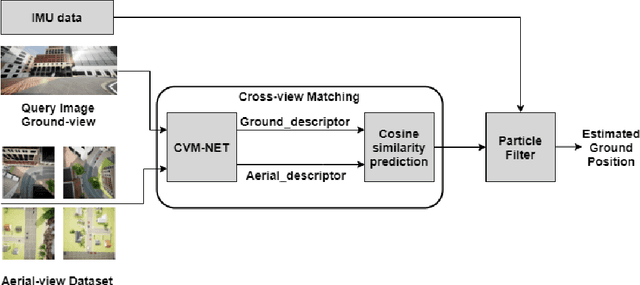
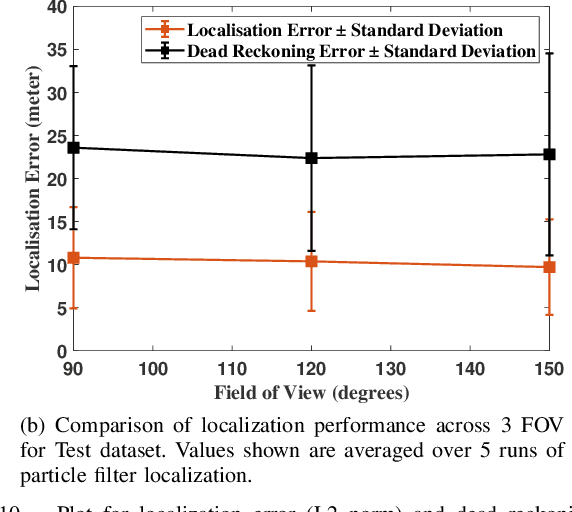

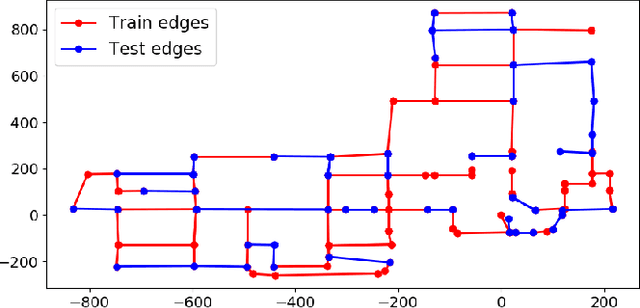
Cross-view matching refers to the problem of finding the closest match to a given query ground-view image to one from a database of aerial images. If the aerial images are geotagged, then the closest matching aerial image can be used to localize the query ground-view image. Recently, due to the success of deep learning methods, a number of cross-view matching techniques have been proposed. These techniques perform well for the matching of isolated query images. In this paper, we evaluate cross-view matching for the task of localizing a ground vehicle over a longer trajectory. We use the cross-view matching module as a sensor measurement fused with a particle filter. We evaluate the performance of this method using a city-wide dataset collected in photorealistic simulation using five parameters: height of aerial images, the pitch of the aerial camera mount, field-of-view of ground camera, measurement model and resampling strategy for the particles in the particle filter.
A Few-Shot Sequential Approach for Object Counting
Jul 07, 2020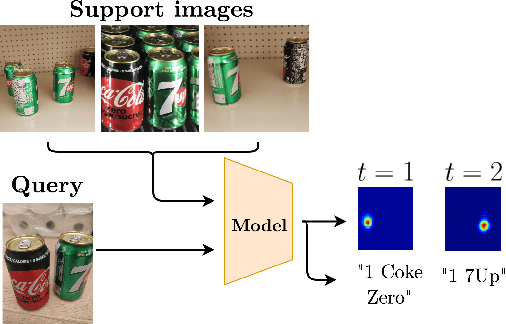
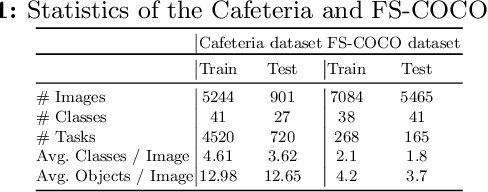
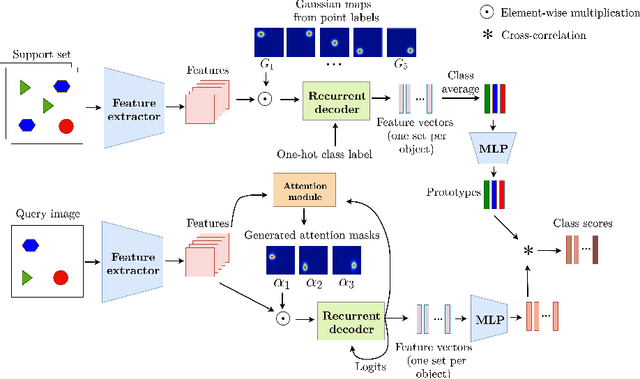
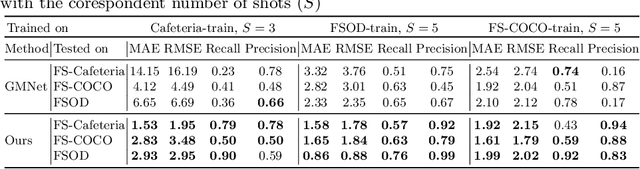
In this work, we address the problem of few-shot multi-class object counting with point-level annotations. The proposed technique leverages a class agnostic attention mechanism that sequentially attends to objects in the image and extracts their relevant features. This process is employed on an adapted prototypical-based few-shot approach that uses the extracted features to classify each one either as one of the classes present in the support set images or as background. The proposed technique is trained on point-level annotations and uses a novel loss function that disentangles class-dependent and class-agnostic aspects of the model to help with the task of few-shot object counting. We present our results on a variety of object-counting/detection datasets, including FSOD and MS COCO. In addition, we introduce a new dataset that is specifically designed for weakly supervised multi-class object counting/detection and contains considerably different classes and distribution of number of classes/instances per image compared to the existing datasets. We demonstrate the robustness of our approach by testing our system on a totally different distribution of classes from what it has been trained on.
Image2StyleGAN++: How to Edit the Embedded Images?
Nov 26, 2019



We propose Image2StyleGAN++, a flexible image editing framework with many applications. Our framework extends the recent Image2StyleGAN in three ways. First, we introduce noise optimization as a complement to the $W^+$ latent space embedding. Our noise optimization can restore high frequency features in images and thus significantly improves the quality of reconstructed images, e.g. a big increase of PSNR from 20 dB to 45 dB. Second, we extend the global $W^+$ latent space embedding to enable local embeddings. Third, we combine embedding with activation tensor manipulation to perform high quality local edits along with global semantic edits on images. Such edits motivate various high quality image editing applications, e.g. image reconstruction, image inpainting, image crossover, local style transfer, image editing using scribbles, and attribute level feature transfer. Examples of the edited images are shown across the paper for visual inspection.
Embedding Task Knowledge into 3D Neural Networks via Self-supervised Learning
Jun 10, 2020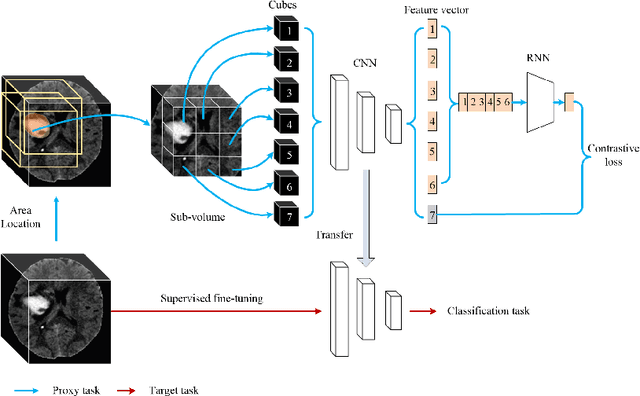
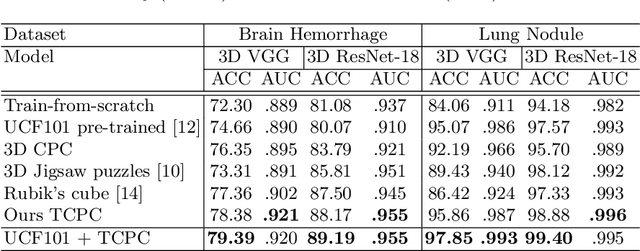

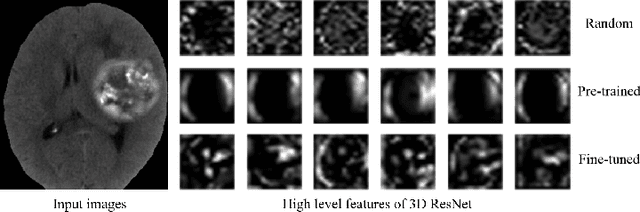
Deep learning highly relies on the amount of annotated data. However, annotating medical images is extremely laborious and expensive. To this end, self-supervised learning (SSL), as a potential solution for deficient annotated data, attracts increasing attentions from the community. However, SSL approaches often design a proxy task that is not necessarily related to target task. In this paper, we propose a novel SSL approach for 3D medical image classification, namely Task-related Contrastive Prediction Coding (TCPC), which embeds task knowledge into training 3D neural networks. The proposed TCPC first locates the initial candidate lesions via supervoxel estimation using simple linear iterative clustering. Then, we extract features from the sub-volume cropped around potential lesion areas, and construct a calibrated contrastive predictive coding scheme for self-supervised learning. Extensive experiments are conducted on public and private datasets. The experimental results demonstrate the effectiveness of embedding lesion-related prior-knowledge into neural networks for 3D medical image classification.
Radon-Nikodym approximation in application to image analysis
Dec 15, 2015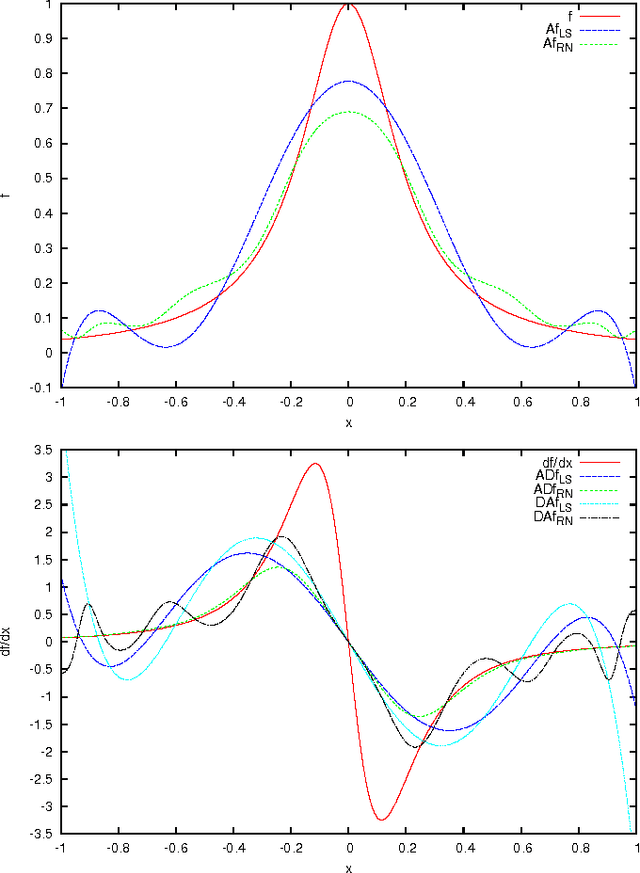


For an image pixel information can be converted to the moments of some basis $Q_k$, e.g. Fourier-Mellin, Zernike, monomials, etc. Given sufficient number of moments pixel information can be completely recovered, for insufficient number of moments only partial information can be recovered and the image reconstruction is, at best, of interpolatory type. Standard approach is to present interpolated value as a linear combination of basis functions, what is equivalent to least squares expansion. However, recent progress in numerical stability of moments estimation allows image information to be recovered from moments in a completely different manner, applying Radon-Nikodym type of expansion, what gives the result as a ratio of two quadratic forms of basis functions. In contrast with least squares the Radon-Nikodym approach has oscillation near the boundaries very much suppressed and does not diverge outside of basis support. While least squares theory operate with vectors $<fQ_k>$, Radon-Nikodym theory operates with matrices $<fQ_jQ_k>$, what make the approach much more suitable to image transforms and statistical property estimation.
Scribble2Label: Scribble-Supervised Cell Segmentation via Self-Generating Pseudo-Labels with Consistency
Jun 24, 2020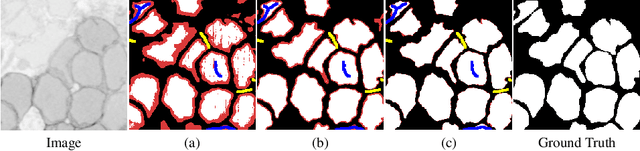
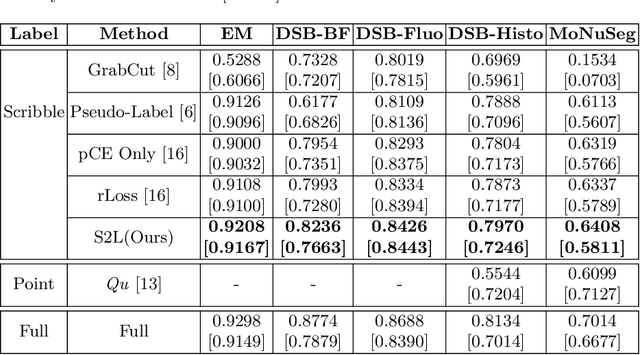
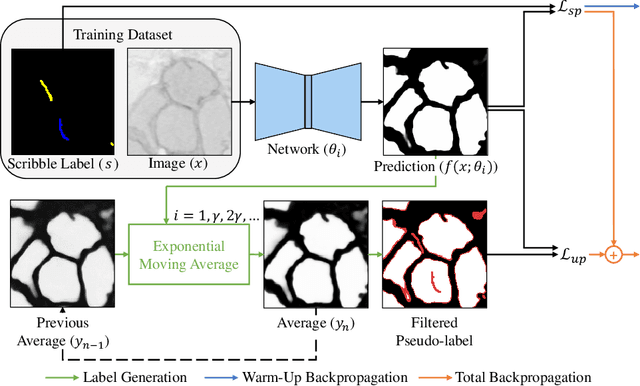
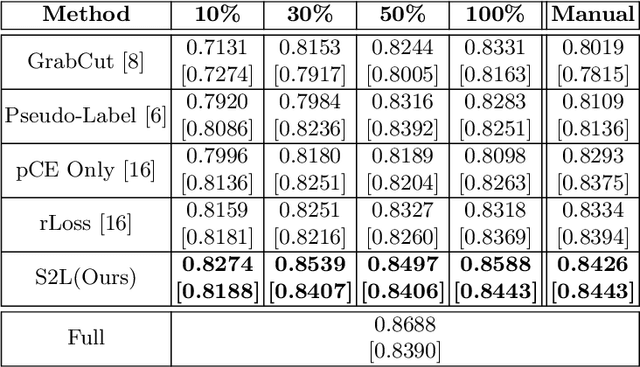
Segmentation is a fundamental process in microscopic cell image analysis. With the advent of recent advances in deep learning, more accurate and high-throughput cell segmentation has become feasible. However, most existing deep learning-based cell segmentation algorithms require fully annotated ground-truth cell labels, which are time-consuming and labor-intensive to generate. In this paper, we introduce Scribble2Label, a novel weakly-supervised cell segmentation framework that exploits only a handful of scribble annotations without full segmentation labels. The core idea is to combine pseudo-labeling and label filtering to generate reliable labels from weak supervision. For this, we leverage the consistency of predictions by iteratively averaging the predictions to improve pseudo labels. We demonstrate the performance of Scribble2Label by comparing it to several state-of-the-art cell segmentation methods with various cell image modalities, including bright-field, fluorescence, and electron microscopy. We also show that our method performs robustly across different levels of scribble details, which confirms that only a few scribble annotations are required in real-use cases.
Sparse and redundant signal representations for x-ray computed tomography
Dec 06, 2019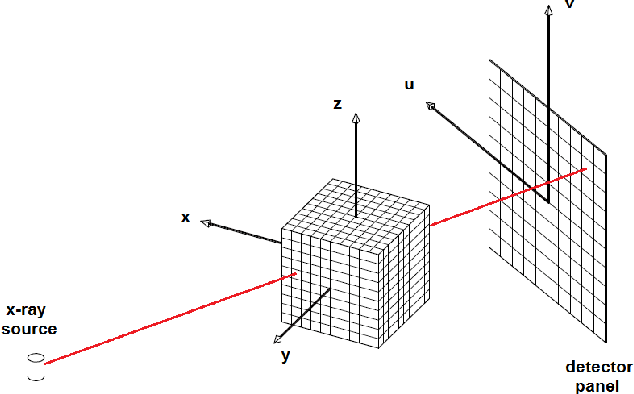
Image models are central to all image processing tasks. The great advancements in digital image processing would not have been made possible without powerful models which, themselves, have evolved over time. In the past decade, patch-based models have emerged as one of the most effective models for natural images. Patch-based methods have outperformed other competing methods in many image processing tasks. These developments have come at a time when greater availability of powerful computational resources and growing concerns over the health risks of the ionizing radiation encourage research on image processing algorithms for computed tomography (CT). The goal of this paper is to explain the principles of patch-based methods and to review some of their recent applications in CT. We review the central concepts in patch-based image processing and explain some of the state-of-the-art algorithms, with a focus on aspects that are more relevant to CT. Then, we review some of the recent application of patch-based methods in CT.
Tele-operative Robotic Lung Ultrasound Scanning Platform for Triage of COVID-19 Patients
Nov 12, 2020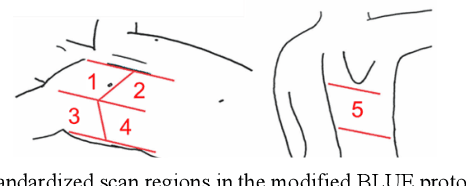
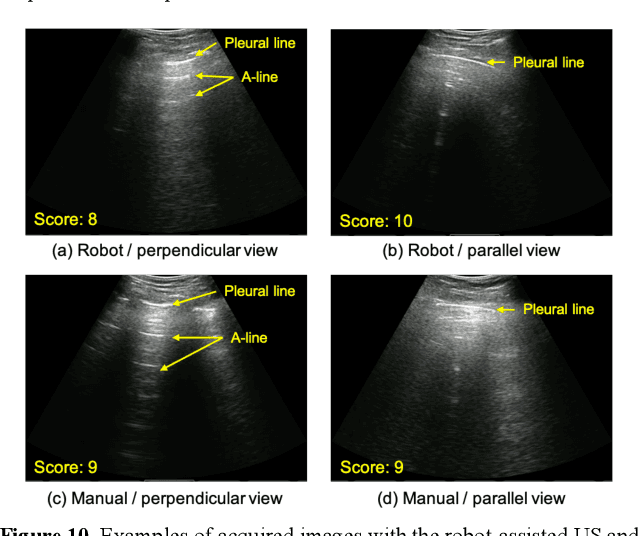
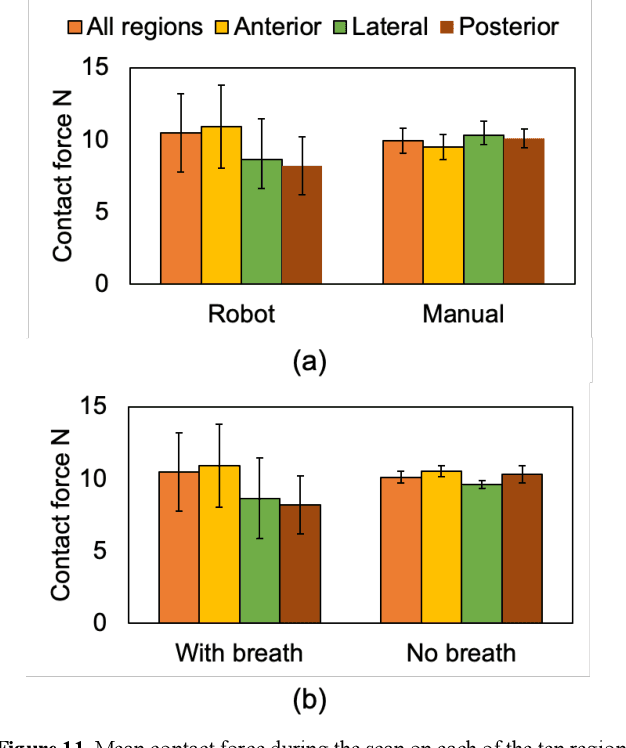
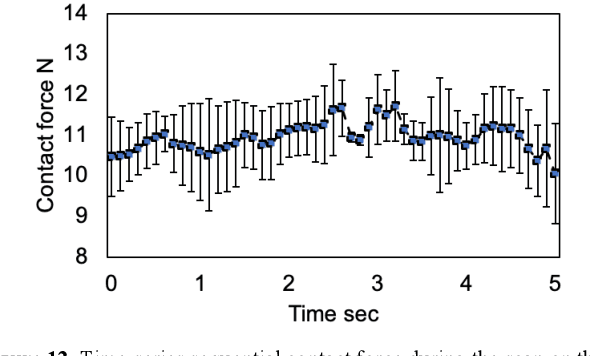
Novel severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) has become a pandemic of epic proportions and a global response to prepare health systems worldwide is of utmost importance. In addition to its cost-effectiveness in a resources-limited setting, lung ultrasound (LUS) has emerged as a rapid noninvasive imaging tool for the diagnosis of COVID-19 infected patients. Concerns surrounding LUS include the disparity of infected patients and healthcare providers, relatively small number of physicians and sonographers capable of performing LUS, and most importantly, the requirement for substantial physical contact between the patient and operator, increasing the risk of transmission. Mitigation of the spread of the virus is of paramount importance. A 2-dimensional (2D) tele-operative robotic platform capable of performing LUS in for COVID-19 infected patients may be of significant benefit. The authors address the aforementioned issues surrounding the use of LUS in the application of COVID- 19 infected patients. In addition, first time application, feasibility and safety were validated in three healthy subjects, along with 2D image optimization and comparison for overall accuracy. Preliminary results demonstrate that the proposed platform allows for successful acquisition and application of LUS in humans.
Search and Rescue with Airborne Optical Sectioning
Sep 18, 2020
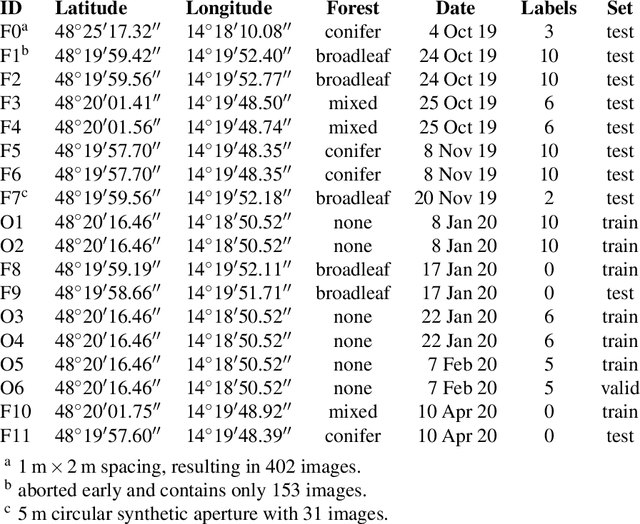
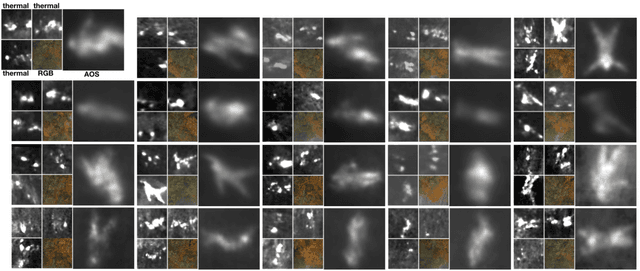
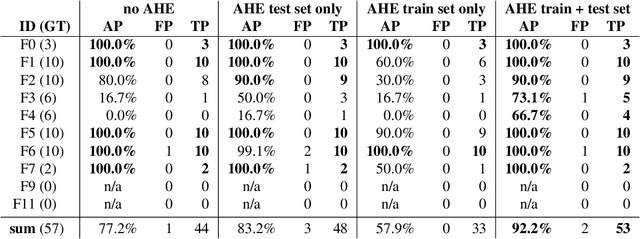
We show that automated person detection under occlusion conditions can be significantly improved by combining multi-perspective images before classification. Here, we employed image integration by Airborne Optical Sectioning (AOS)---a synthetic aperture imaging technique that uses camera drones to capture unstructured thermal light fields---to achieve this with a precision/recall of 96/93%. Finding lost or injured people in dense forests is not generally feasible with thermal recordings, but becomes practical with use of AOS integral images. Our findings lay the foundation for effective future search and rescue technologies that can be applied in combination with autonomous or manned aircraft. They can also be beneficial for other fields that currently suffer from inaccurate classification of partially occluded people, animals, or objects.
Random Projections for Adversarial Attack Detection
Dec 11, 2020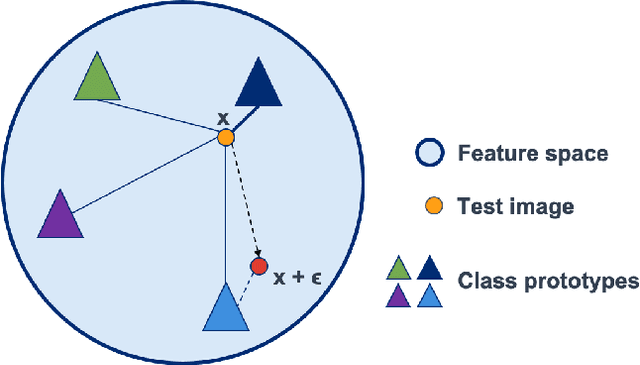
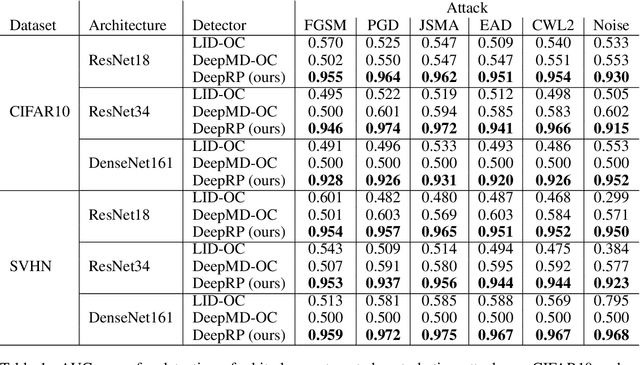
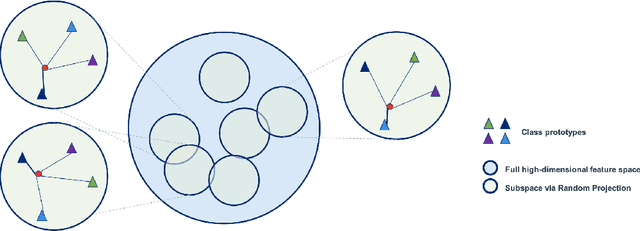
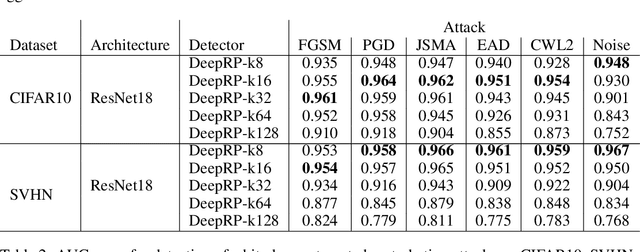
Whilst adversarial attack detection has received considerable attention, it remains a fundamentally challenging problem from two perspectives. First, while threat models can be well-defined, attacker strategies may still vary widely within those constraints. Therefore, detection should be considered as an open-set problem, standing in contrast to most current detection strategies. These methods take a closed-set view and train binary detectors, thus biasing detection toward attacks seen during detector training. Second, information is limited at test time and confounded by nuisance factors including the label and underlying content of the image. Many of the current high-performing techniques use training sets for dealing with some of these issues, but can be limited by the overall size and diversity of those sets during the detection step. We address these challenges via a novel strategy based on random subspace analysis. We present a technique that makes use of special properties of random projections, whereby we can characterize the behavior of clean and adversarial examples across a diverse set of subspaces. We then leverage the self-consistency (or inconsistency) of model activations to discern clean from adversarial examples. Performance evaluation demonstrates that our technique outperforms ($>0.92$ AUC) competing state of the art (SOTA) attack strategies, while remaining truly agnostic to the attack method itself. It also requires significantly less training data, composed only of clean examples, when compared to competing SOTA methods, which achieve only chance performance, when evaluated in a more rigorous testing scenario.