 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hierarchical Roofline Performance Analysis for Deep Learning Applications
Sep 22, 2020
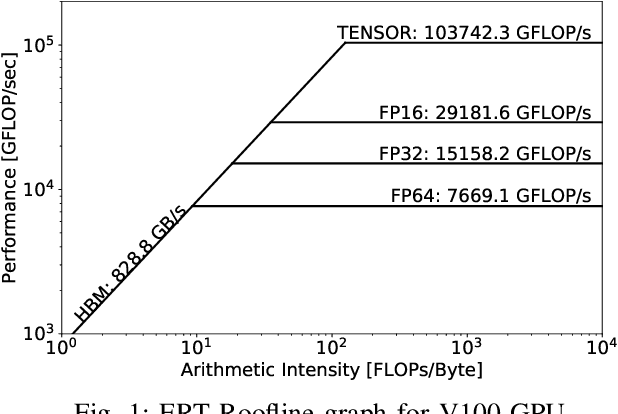
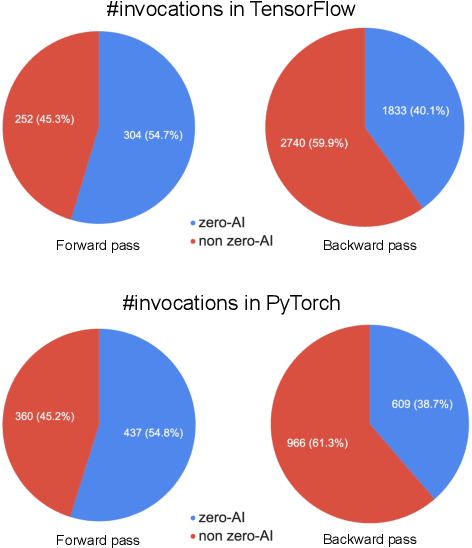
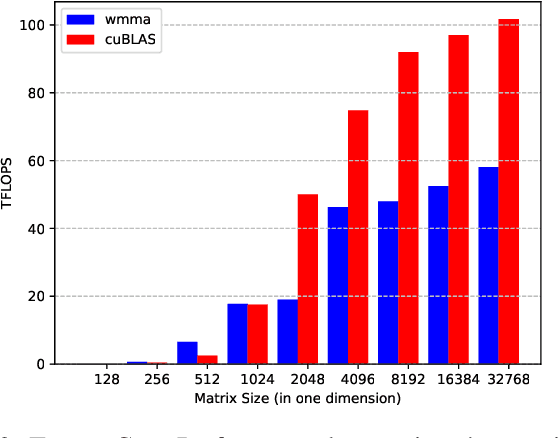
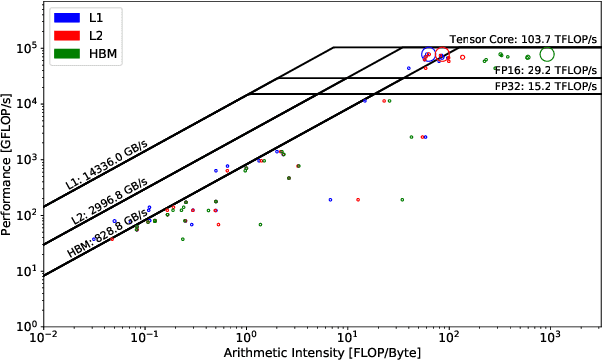
This paper presents a practical methodology for collecting performance data necessary to conduct hierarchical Roofline analysis on NVIDIA GPUs. It discusses the extension of the Empirical Roofline Toolkit for broader support of a range of data precisions and Tensor Core support and introduces a Nsight Compute based method to accurately collect application performance information. This methodology allows for automated machine characterization and application characterization for Roofline analysis across the entire memory hierarchy on NVIDIA GPUs, and it is validated by a complex deep learning application used for climate image segmentation. We use two versions of the code, in TensorFlow and PyTorch respectively, to demonstrate the use and effectiveness of this methodology. We highlight how the application utilizes the compute and memory capabilities on the GPU and how the implementation and performance differ in two deep learning frameworks.
Flow-Guided Attention Networks for Video-Based Person Re-Identification
Aug 09, 2020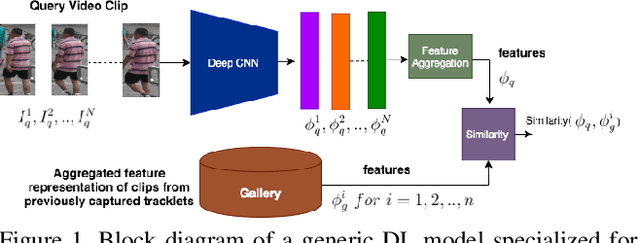
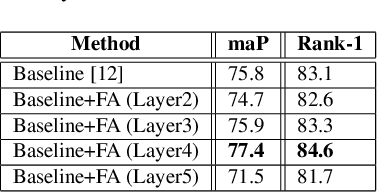


Person Re-Identification (ReID) is an important problem in many video analytics and surveillance applications,where a person's identity must be associated across a distributed network of cameras. Video-based person ReID has recently gained much interest because it can capture discriminant spatio-temporal information that is unavailable for image-based ReID. Despite recent advances, deep learning models for video ReID often fail to leverage this information to improve the robustness of feature representations. In this paper, the motion pattern of a person is explored as an additional cue for ReID. In particular, two different flow-guided attention networks are proposed for fusion with any 2D-CNN backbone, allowing to encode temporal information along with spatial appearance information.Our first proposed network called Gated Attention relies on optical flow to generate gated attention with video-based feature that embed spatially. Hence the proposed framework allows to activate a common set of salient features across multiple frames. In contrast, our second network called Mutual Attention relies on the joint attention between image and optical flow features. This enables spatial attention between both sources of features, across motion and appearance cues. Both methods introduce a feature aggregation method that produce video features by identifying salient spatio-temporal information.Extensive experiments on two challenging video datasets indicate that using the proposed flow-guided spatio-temporal attention networks allows to improve recognition accuracy considerably, outperforming state-of-the-art methods for video-based person ReID. Additionally, our Mutual Attention network is able to process longer frame sequences with a wider range of appearance variations for highly accurate recognition.
CovidCTNet: An Open-Source Deep Learning Approach to Identify Covid-19 Using CT Image
May 16, 2020Coronavirus disease 2019 (Covid-19) is highly contagious with limited treatment options. Early and accurate diagnosis of Covid-19 is crucial in reducing the spread of the disease and its accompanied mortality. Currently, detection by reverse transcriptase polymerase chain reaction (RT-PCR) is the gold standard of outpatient and inpatient detection of Covid-19. RT-PCR is a rapid method, however, its accuracy in detection is only ~70-75%. Another approved strategy is computed tomography (CT) imaging. CT imaging has a much higher sensitivity of ~80-98%, but similar accuracy of 70%. To enhance the accuracy of CT imaging detection, we developed an open-source set of algorithms called CovidCTNet that successfully differentiates Covid-19 from community-acquired pneumonia (CAP) and other lung diseases. CovidCTNet increases the accuracy of CT imaging detection to 90% compared to radiologists (70%). The model is designed to work with heterogeneous and small sample sizes independent of the CT imaging hardware. In order to facilitate the detection of Covid-19 globally and assist radiologists and physicians in the screening process, we are releasing all algorithms and parametric details in an open-source format. Open-source sharing of our CovidCTNet enables developers to rapidly improve and optimize services, while preserving user privacy and data ownership.
Evaluating the performance of the LIME and Grad-CAM explanation methods on a LEGO multi-label image classification task
Aug 04, 2020

In this paper, we run two methods of explanation, namely LIME and Grad-CAM, on a convolutional neural network trained to label images with the LEGO bricks that are visible in them. We evaluate them on two criteria, the improvement of the network's core performance and the trust they are able to generate for users of the system. We find that in general, Grad-CAM seems to outperform LIME on this specific task: it yields more detailed insight from the point of view of core performance and 80\% of respondents asked to choose between them when it comes to the trust they inspire in the model choose Grad-CAM. However, we also posit that it is more useful to employ these two methods together, as the insights they yield are complementary.
Efficient Decentralized Visual Place Recognition From Full-Image Descriptors
May 30, 2017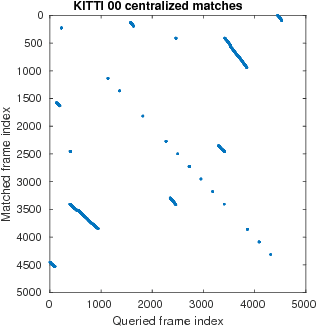
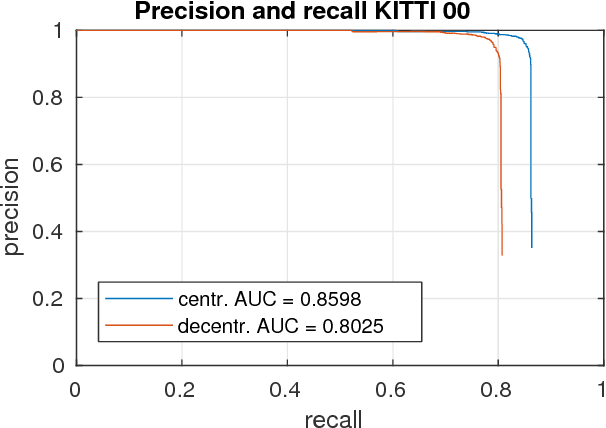
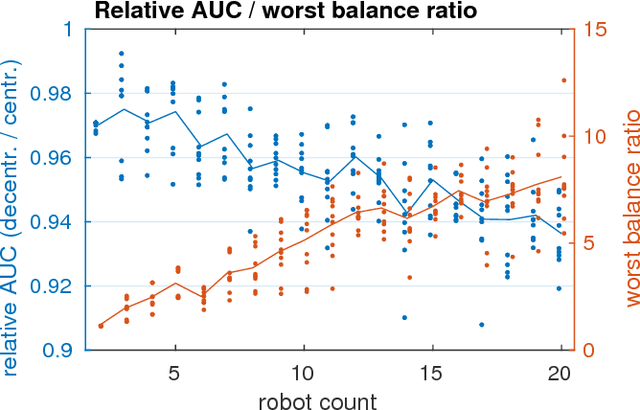
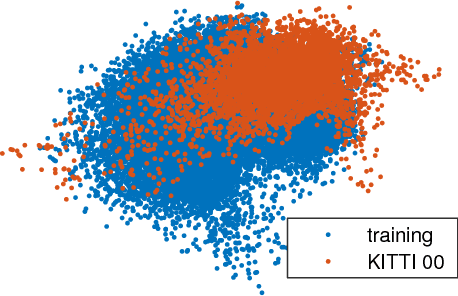
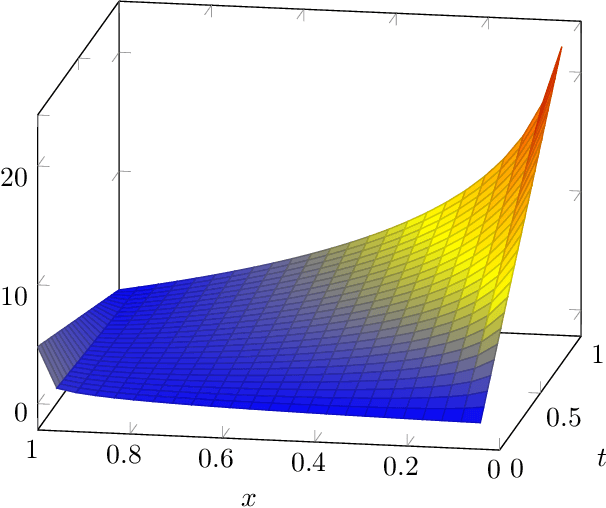
In this paper, we discuss the adaptation of our decentralized place recognition method described in [1] to full image descriptors. As we had shown, the key to making a scalable decentralized visual place recognition lies in exploting deterministic key assignment in a distributed key-value map. Through this, it is possible to reduce bandwidth by up to a factor of n, the robot count, by casting visual place recognition to a key-value lookup problem. In [1], we exploited this for the bag-of-words method [3], [4]. Our method of casting bag-of-words, however, results in a complex decentralized system, which has inherently worse recall than its centralized counterpart. In this paper, we instead start from the recent full-image description method NetVLAD [5]. As we show, casting this to a key-value lookup problem can be achieved with k-means clustering, and results in a much simpler system than [1]. The resulting system still has some flaws, albeit of a completely different nature: it suffers when the environment seen during deployment lies in a different distribution in feature space than the environment seen during training.
* 3 pages, 4 figures. This is a self-published paper that accompanies our original work [1] as well as the ICRA 2017 Workshop on Multi-robot Perception-Driven Control and Planning [2]
Adaptive Debanding Filter
Sep 22, 2020
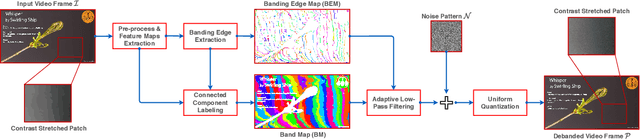
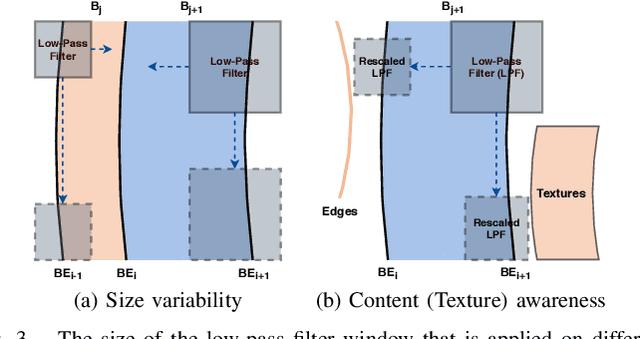
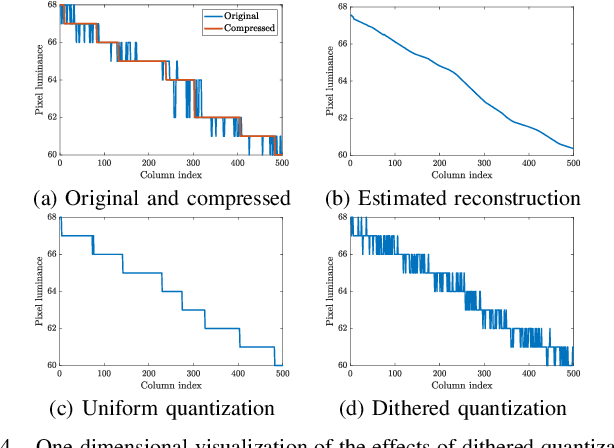
Banding artifacts, which manifest as staircase-like color bands on pictures or video frames, is a common distortion caused by compression of low-textured smooth regions. These false contours can be very noticeable even on high-quality videos, especially when displayed on high-definition screens. Yet, relatively little attention has been applied to this problem. Here we consider banding artifact removal as a visual enhancement problem, and accordingly, we solve it by applying a form of content-adaptive smoothing filtering followed by dithered quantization, as a post-processing module. The proposed debanding filter is able to adaptively smooth banded regions while preserving image edges and details, yielding perceptually enhanced gradient rendering with limited bit-depths. Experimental results show that our proposed debanding filter outperforms state-of-the-art false contour removing algorithms both visually and quantitatively.
RG-Flow: A hierarchical and explainable flow model based on renormalization group and sparse prior
Oct 07, 2020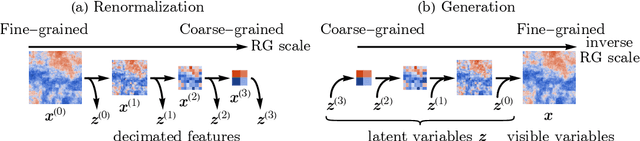
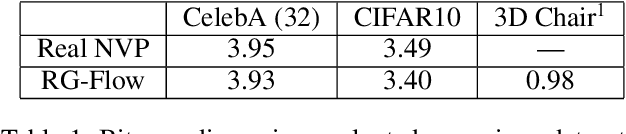
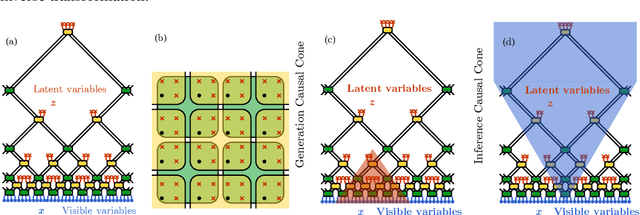

Flow-based generative models have become an important class of unsupervised learning approaches. In this work, we incorporate the key idea of renormalization group (RG) and sparse prior distribution to design a hierarchical flow-based generative model, called RG-Flow, which can separate different scale information of images with disentangle representations at each scale. We demonstrate our method mainly on the CelebA dataset and show that the disentangled representation at different scales enables semantic manipulation and style mixing of the images. To visualize the latent representation, we introduce the receptive fields for flow-based models and find receptive fields learned by RG-Flow are similar to convolutional neural networks. In addition, we replace the widely adopted Gaussian prior distribution by sparse prior distributions to further enhance the disentanglement of representations. From a theoretical perspective, the proposed method has $O(\log L)$ complexity for image inpainting compared to previous flow-based models with $O(L^2)$ complexity.
Monocular Depth Estimation via Listwise Ranking using the Plackett-Luce Model
Oct 31, 2020


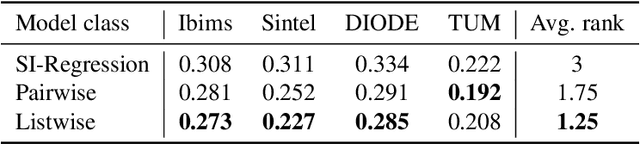
In many real-world applications, the relative depth of objects in an image is crucial for scene understanding, e.g., to calculate occlusions in augmented reality scenes. Predicting depth in monocular images has recently been tackled using machine learning methods, mainly by treating the problem as a regression task. Yet, being interested in an order relation in the first place, ranking methods suggest themselves as a natural alternative to regression, and indeed, ranking approaches leveraging pairwise comparisons as training information ("object A is closer to the camera than B") have shown promising performance on this problem. In this paper, we elaborate on the use of so-called listwise ranking as a generalization of the pairwise approach. Listwise ranking goes beyond pairwise comparisons between objects and considers rankings of arbitrary length as training information. Our approach is based on the Plackett-Luce model, a probability distribution on rankings, which we combine with a state-of-the-art neural network architecture and a sampling strategy to reduce training complexity. An empirical evaluation on benchmark data in a "zero-shot" setting demonstrates the effectiveness of our proposal compared to existing ranking and regression methods.
Object Level Deep Feature Pooling for Compact Image Representation
Apr 24, 2015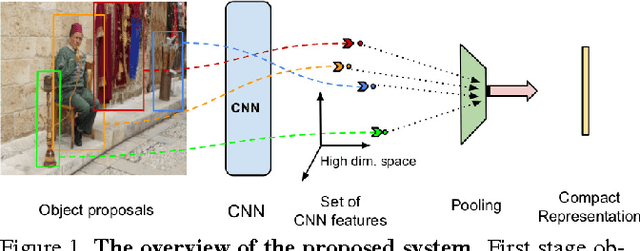
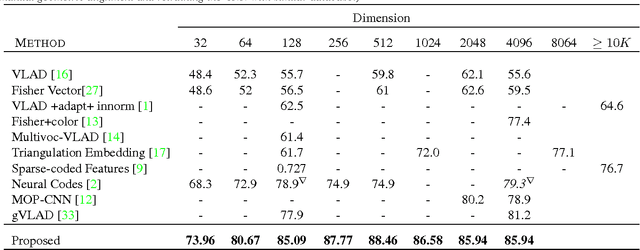
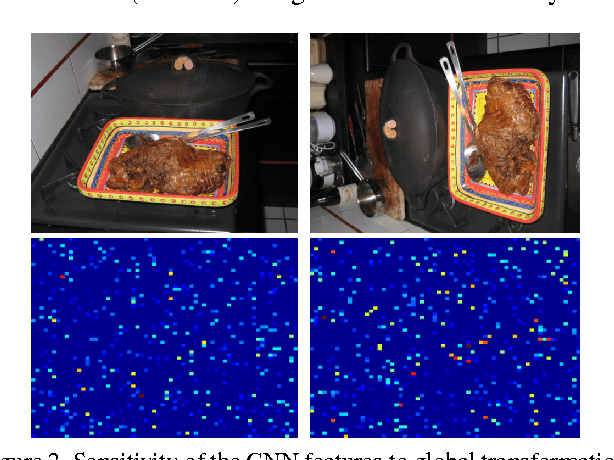
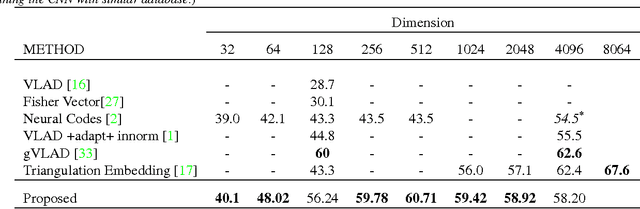
Convolutional Neural Network (CNN) features have been successfully employed in recent works as an image descriptor for various vision tasks. But the inability of the deep CNN features to exhibit invariance to geometric transformations and object compositions poses a great challenge for image search. In this work, we demonstrate the effectiveness of the objectness prior over the deep CNN features of image regions for obtaining an invariant image representation. The proposed approach represents the image as a vector of pooled CNN features describing the underlying objects. This representation provides robustness to spatial layout of the objects in the scene and achieves invariance to general geometric transformations, such as translation, rotation and scaling. The proposed approach also leads to a compact representation of the scene, making each image occupy a smaller memory footprint. Experiments show that the proposed representation achieves state of the art retrieval results on a set of challenging benchmark image datasets, while maintaining a compact representation.
Is the winner really the best? A critical analysis of common research practice in biomedical image analysis competitions
Jun 06, 2018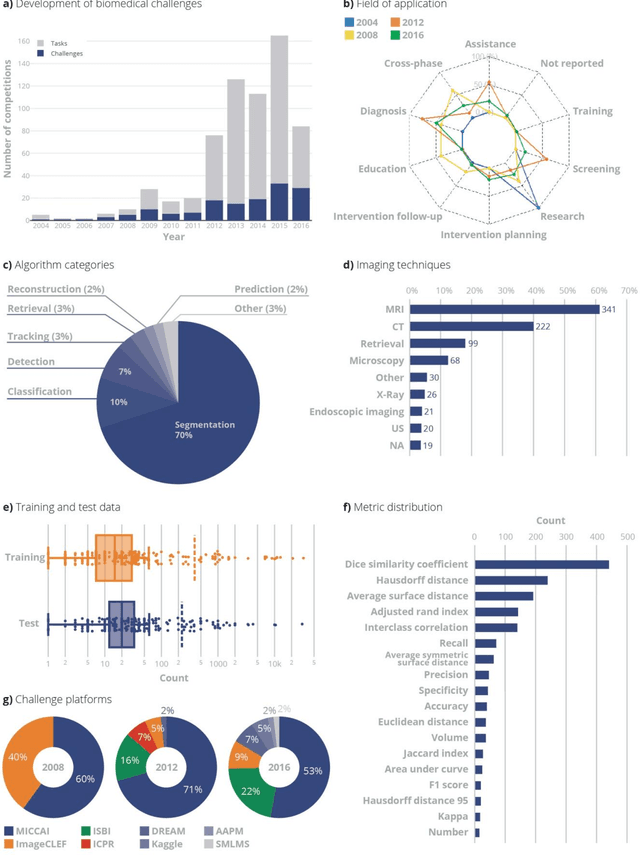
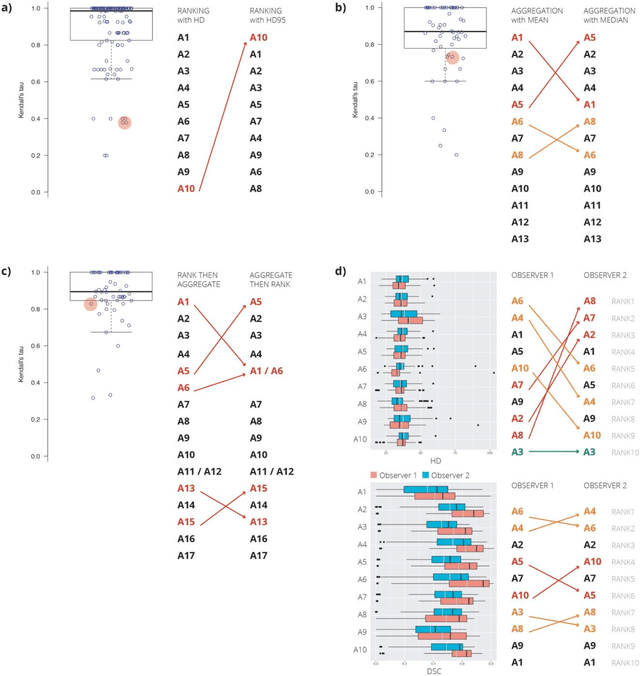
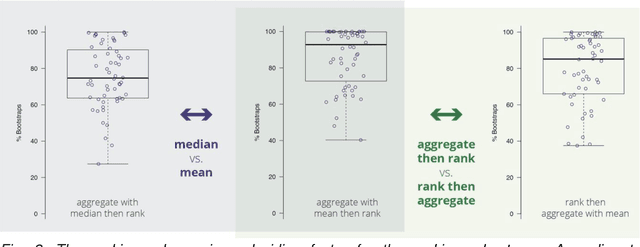
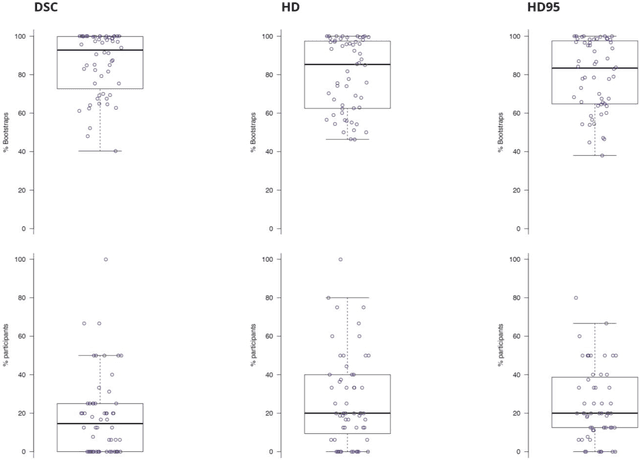
International challenges have become the standard for validation of biomedical image analysis methods. Given their scientific impact, it is surprising that a critical analysis of common practices related to the organization of challenges has not yet been performed. In this paper, we present a comprehensive analysis of biomedical image analysis challenges conducted up to now. We demonstrate the importance of challenges and show that the lack of quality control has critical consequences. First, reproducibility and interpretation of the results is often hampered as only a fraction of relevant information is typically provided. Second, the rank of an algorithm is generally not robust to a number of variables such as the test data used for validation, the ranking scheme applied and the observers that make the reference annotations. To overcome these problems, we recommend best practice guidelines and define open research questions to be addressed in the future.