 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cross-Modal Information Maximization for Medical Imaging: CMIM
Oct 20, 2020
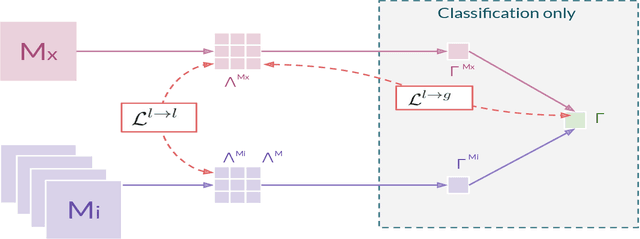
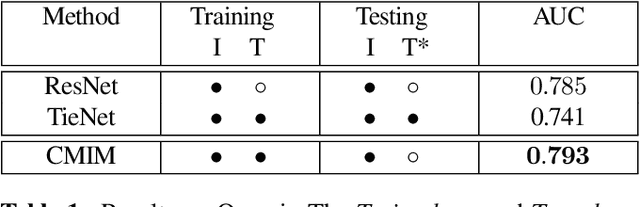
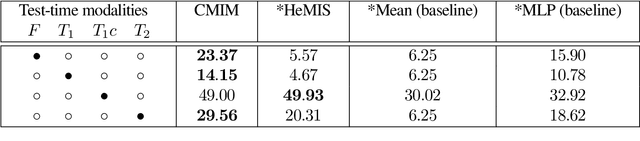
In hospitals, data are siloed to specific information systems that make the same information available under different modalities such as the different medical imaging exams the patient undergoes (CT scans, MRI, PET, Ultrasound, etc.) and their associated radiology reports. This offers unique opportunities to obtain and use at train-time those multiple views of the same information that might not always be available at test-time. In this paper, we propose an innovative framework that makes the most of available data by learning good representations of a multi-modal input that are resilient to modality dropping at test-time, using recent advances in mutual information maximization. By maximizing cross-modal information at train time, we are able to outperform several state-of-the-art baselines in two different settings, medical image classification, and segmentation. In particular, our method is shown to have a strong impact on the inference-time performance of weaker modalities.
SMPLy Benchmarking 3D Human Pose Estimation in the Wild
Dec 04, 2020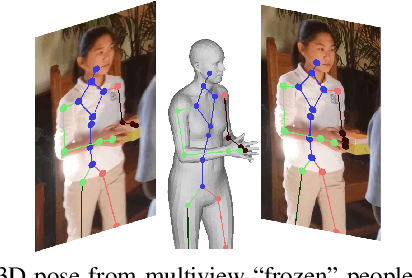
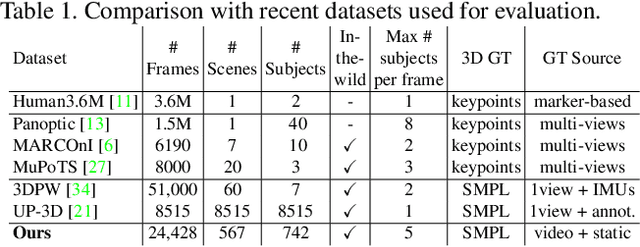
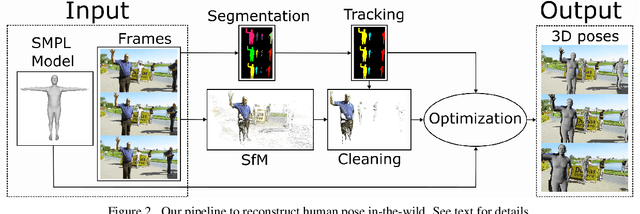
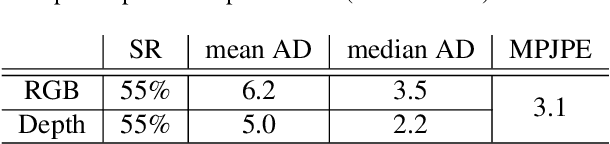
Predicting 3D human pose from images has seen great recent improvements. Novel approaches that can even predict both pose and shape from a single input image have been introduced, often relying on a parametric model of the human body such as SMPL. While qualitative results for such methods are often shown for images captured in-the-wild, a proper benchmark in such conditions is still missing, as it is cumbersome to obtain ground-truth 3D poses elsewhere than in a motion capture room. This paper presents a pipeline to easily produce and validate such a dataset with accurate ground-truth, with which we benchmark recent 3D human pose estimation methods in-the-wild. We make use of the recently introduced Mannequin Challenge dataset which contains in-the-wild videos of people frozen in action like statues and leverage the fact that people are static and the camera moving to accurately fit the SMPL model on the sequences. A total of 24,428 frames with registered body models are then selected from 567 scenes at almost no cost, using only online RGB videos. We benchmark state-of-the-art SMPL-based human pose estimation methods on this dataset. Our results highlight that challenges remain, in particular for difficult poses or for scenes where the persons are partially truncated or occluded.
ASIST: Annotation-free synthetic instance segmentation and tracking for microscope video analysis
Nov 02, 2020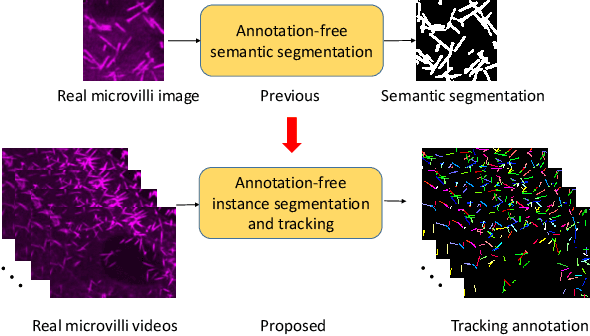
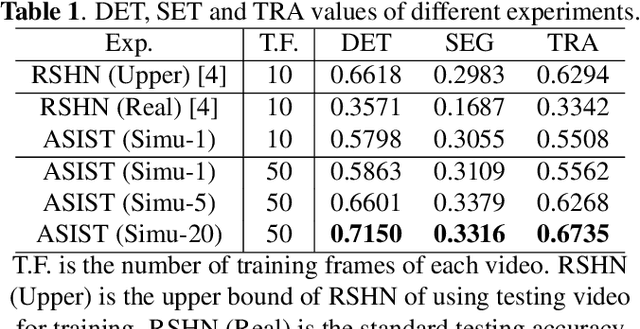
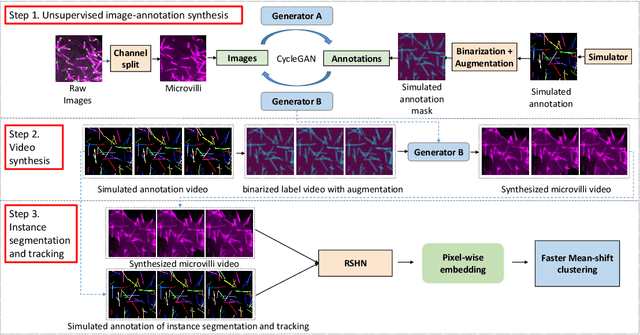
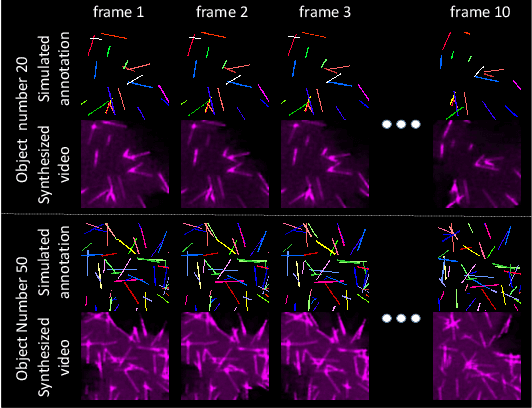
Instance object segmentation and tracking provide comprehensive quantification of objects across microscope videos. The recent single-stage pixel-embedding based deep learning approach has shown its superior performance compared with "segment-then-associate" two-stage solutions. However, one major limitation of applying a supervised pixel-embedding based method to microscope videos is the resource-intensive manual labeling, which involves tracing hundreds of overlapped objects with their temporal associations across video frames. Inspired by the recent generative adversarial network (GAN) based annotation-free image segmentation, we propose a novel annotation-free synthetic instance segmentation and tracking (ASIST) algorithm for analyzing microscope videos of sub-cellular microvilli. The contributions of this paper are three-fold: (1) proposing a new annotation-free video analysis paradigm is proposed. (2) aggregating the embedding based instance segmentation and tracking with annotation-free synthetic learning as a holistic framework; and (3) to the best of our knowledge, this is first study to investigate microvilli instance segmentation and tracking using embedding based deep learning. From the experimental results, the proposed annotation-free method achieved superior performance compared with supervised learning.
Sparse Separable Nonnegative Matrix Factorization
Jun 13, 2020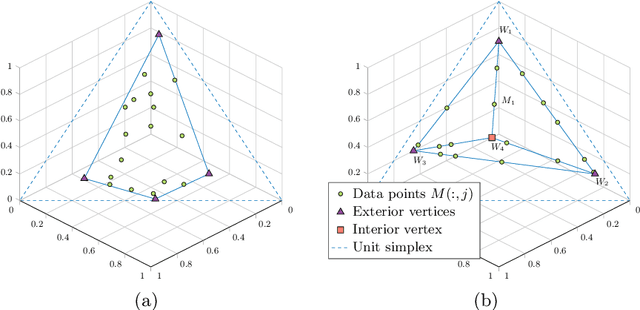


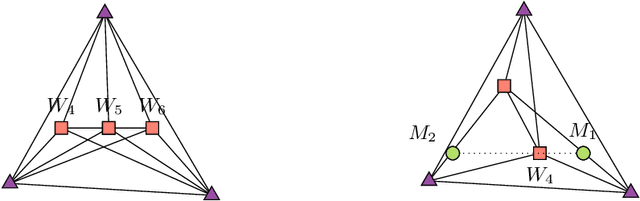
We propose a new variant of nonnegative matrix factorization (NMF), combining separability and sparsity assumptions. Separability requires that the columns of the first NMF factor are equal to columns of the input matrix, while sparsity requires that the columns of the second NMF factor are sparse. We call this variant sparse separable NMF (SSNMF), which we prove to be NP-complete, as opposed to separable NMF which can be solved in polynomial time. The main motivation to consider this new model is to handle underdetermined blind source separation problems, such as multispectral image unmixing. We introduce an algorithm to solve SSNMF, based on the successive nonnegative projection algorithm (SNPA, an effective algorithm for separable NMF), and an exact sparse nonnegative least squares solver. We prove that, in noiseless settings and under mild assumptions, our algorithm recovers the true underlying sources. This is illustrated by experiments on synthetic data sets and the unmixing of a multispectral image.
Feature based Sequential Classifier with Attention Mechanism
Jul 22, 2020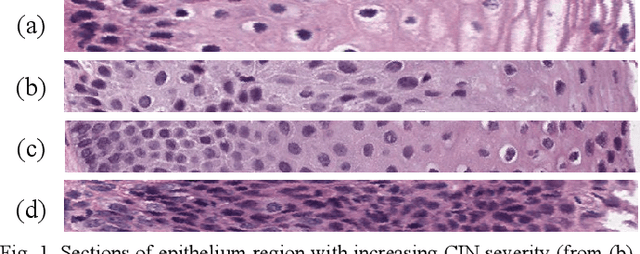
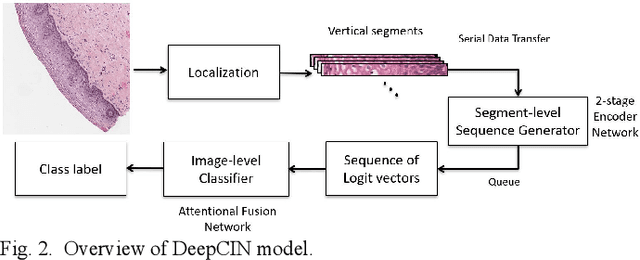
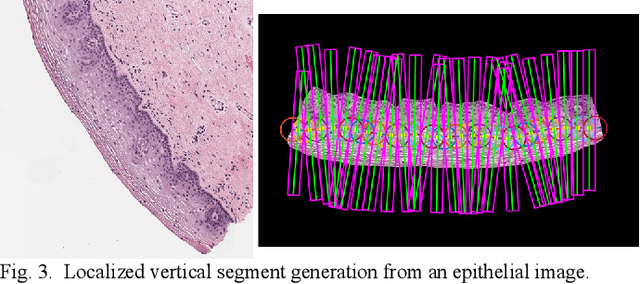
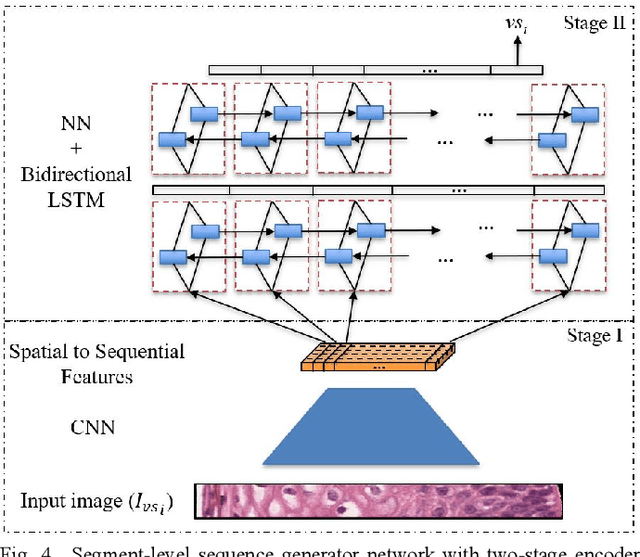
Cervical cancer is one of the deadliest cancers affecting women globally. Cervical intraepithelial neoplasia (CIN) assessment using histopathological examination of cervical biopsy slides is subject to interobserver variability. Automated processing of digitized histopathology slides has the potential for more accurate classification for CIN grades from normal to increasing grades of pre-malignancy: CIN1, CIN2 and CIN3. Cervix disease is generally understood to progress from the bottom (basement membrane) to the top of the epithelium. To model this relationship of disease severity to spatial distribution of abnormalities, we propose a network pipeline, DeepCIN, to analyze high-resolution epithelium images (manually extracted from whole-slide images) hierarchically by focusing on localized vertical regions and fusing this local information for determining Normal/CIN classification. The pipeline contains two classifier networks: 1) a cross-sectional, vertical segment-level sequence generator (two-stage encoder model) is trained using weak supervision to generate feature sequences from the vertical segments to preserve the bottom-to-top feature relationships in the epithelium image data; 2) an attention-based fusion network image-level classifier predicting the final CIN grade by merging vertical segment sequences. The model produces the CIN classification results and also determines the vertical segment contributions to CIN grade prediction. Experiments show that DeepCIN achieves pathologist-level CIN classification accuracy.
Transfer Learning by Asymmetric Image Weighting for Segmentation across Scanners
Mar 15, 2017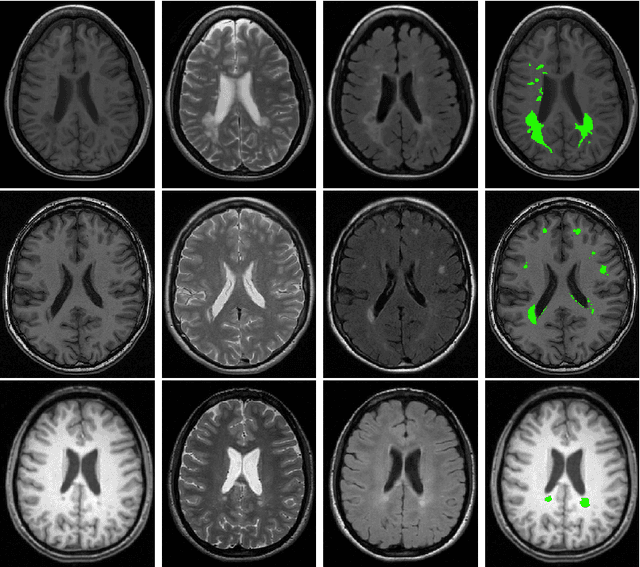
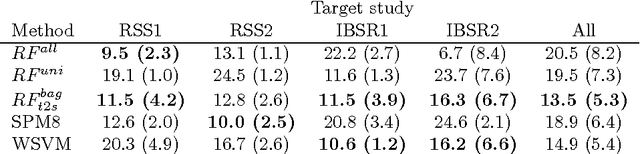
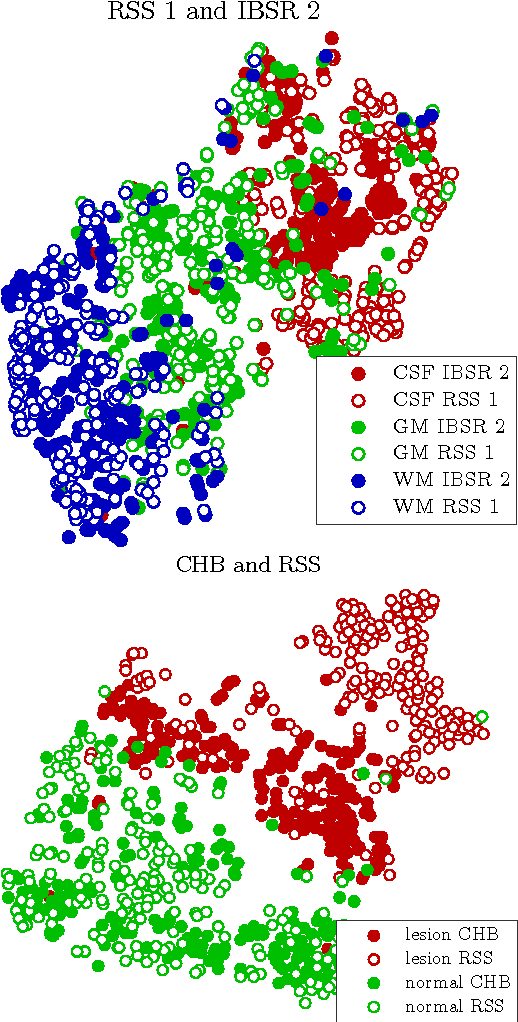
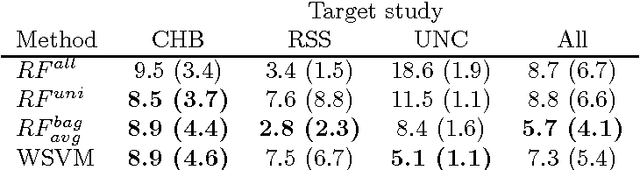
Supervised learning has been very successful for automatic segmentation of images from a single scanner. However, several papers report deteriorated performances when using classifiers trained on images from one scanner to segment images from other scanners. We propose a transfer learning classifier that adapts to differences between training and test images. This method uses a weighted ensemble of classifiers trained on individual images. The weight of each classifier is determined by the similarity between its training image and the test image. We examine three unsupervised similarity measures, which can be used in scenarios where no labeled data from a newly introduced scanner or scanning protocol is available. The measures are based on a divergence, a bag distance, and on estimating the labels with a clustering procedure. These measures are asymmetric. We study whether the asymmetry can improve classification. Out of the three similarity measures, the bag similarity measure is the most robust across different studies and achieves excellent results on four brain tissue segmentation datasets and three white matter lesion segmentation datasets, acquired at different centers and with different scanners and scanning protocols. We show that the asymmetry can indeed be informative, and that computing the similarity from the test image to the training images is more appropriate than the opposite direction.
Image Restoration with Locally Selected Class-Adapted Models
Aug 02, 2016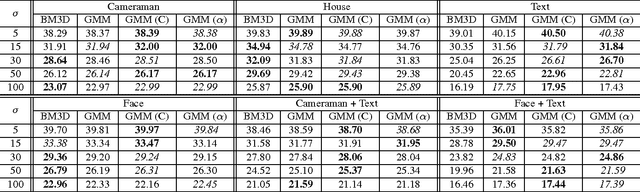

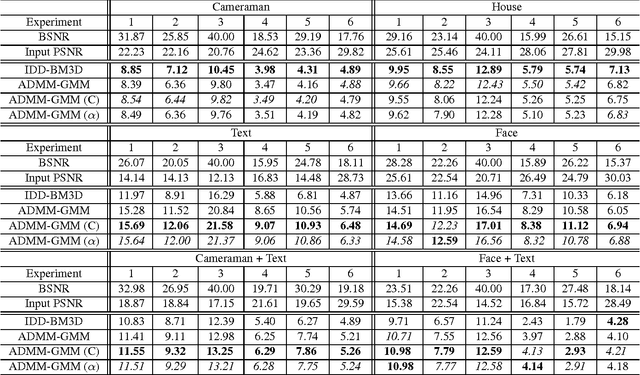

State-of-the-art algorithms for imaging inverse problems (namely deblurring and reconstruction) are typically iterative, involving a denoising operation as one of its steps. Using a state-of-the-art denoising method in this context is not trivial, and is the focus of current work. Recently, we have proposed to use a class-adapted denoiser (patch-based using Gaussian mixture models) in a so-called plug-and-play scheme, wherein a state-of-the-art denoiser is plugged into an iterative algorithm, leading to results that outperform the best general-purpose algorithms, when applied to an image of a known class (e.g. faces, text, brain MRI). In this paper, we extend that approach to handle situations where the image being processed is from one of a collection of possible classes or, more importantly, contains regions of different classes. More specifically, we propose a method to locally select one of a set of class-adapted Gaussian mixture patch priors, previously estimated from clean images of those classes. Our approach may be seen as simultaneously performing segmentation and restoration, thus contributing to bridging the gap between image restoration/reconstruction and analysis.
SoftGym: Benchmarking Deep Reinforcement Learning for Deformable Object Manipulation
Nov 14, 2020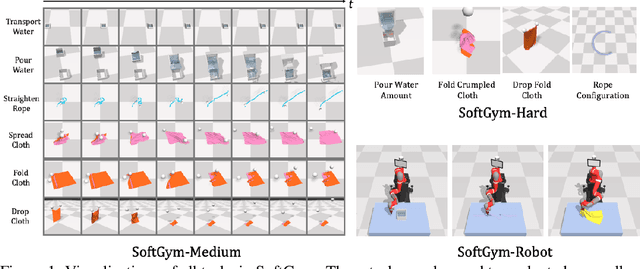

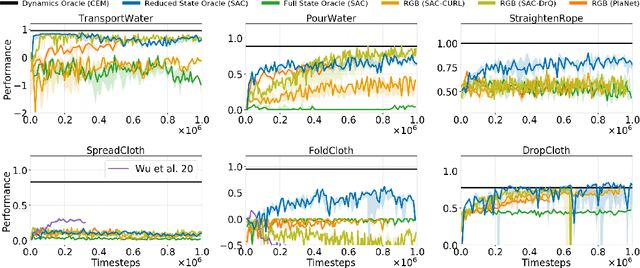

Manipulating deformable objects has long been a challenge in robotics due to its high dimensional state representation and complex dynamics. Recent success in deep reinforcement learning provides a promising direction for learning to manipulate deformable objects with data driven methods. However, existing reinforcement learning benchmarks only cover tasks with direct state observability and simple low-dimensional dynamics or with relatively simple image-based environments, such as those with rigid objects. In this paper, we present SoftGym, a set of open-source simulated benchmarks for manipulating deformable objects, with a standard OpenAI Gym API and a Python interface for creating new environments. Our benchmark will enable reproducible research in this important area. Further, we evaluate a variety of algorithms on these tasks and highlight challenges for reinforcement learning algorithms, including dealing with a state representation that has a high intrinsic dimensionality and is partially observable. The experiments and analysis indicate the strengths and limitations of existing methods in the context of deformable object manipulation that can help point the way forward for future methods development. Code and videos of the learned policies can be found on our project website.
Effective Label Propagation for Discriminative Semi-Supervised Domain Adaptation
Dec 04, 2020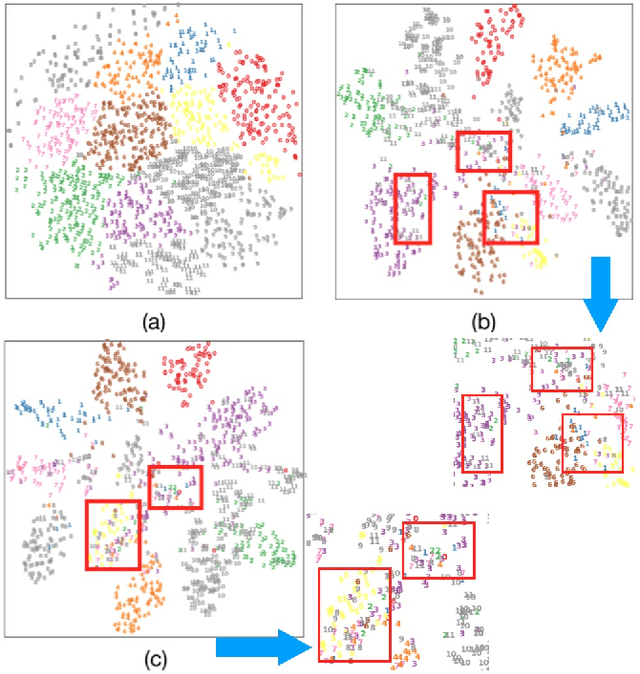
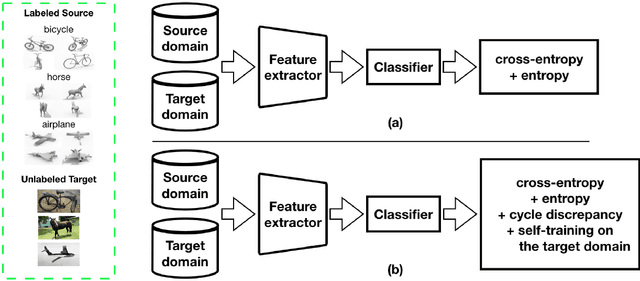
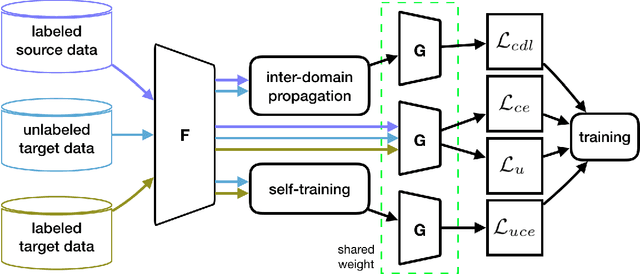
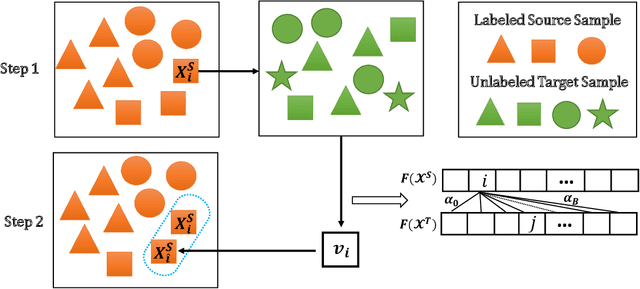
Semi-supervised domain adaptation (SSDA) methods have demonstrated great potential in large-scale image classification tasks when massive labeled data are available in the source domain but very few labeled samples are provided in the target domain. Existing solutions usually focus on feature alignment between the two domains while paying little attention to the discrimination capability of learned representations in the target domain. In this paper, we present a novel and effective method, namely Effective Label Propagation (ELP), to tackle this problem by using effective inter-domain and intra-domain semantic information propagation. For inter-domain propagation, we propose a new cycle discrepancy loss to encourage consistency of semantic information between the two domains. For intra-domain propagation, we propose an effective self-training strategy to mitigate the noises in pseudo-labeled target domain data and improve the feature discriminability in the target domain. As a general method, our ELP can be easily applied to various domain adaptation approaches and can facilitate their feature discrimination in the target domain. Experiments on Office-Home and DomainNet benchmarks show ELP consistently improves the classification accuracy of mainstream SSDA methods by 2%~3%. Additionally, ELP also improves the performance of UDA methods as well (81.5% vs 86.1%), based on UDA experiments on the VisDA-2017 benchmark. Our source code and pre-trained models will be released soon.
Identifying Implementation Bugs in Machine Learning based Image Classifiers using Metamorphic Testing
Aug 16, 2018
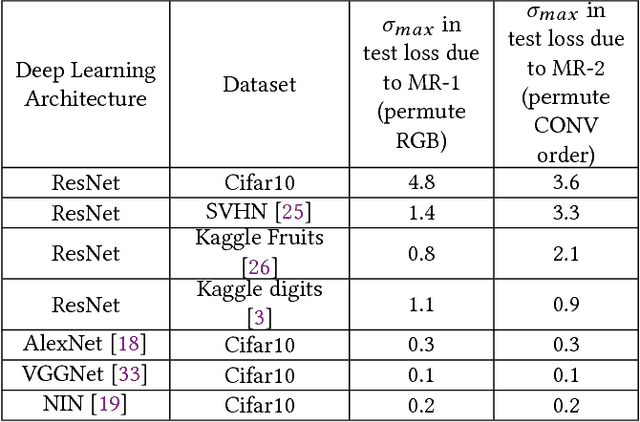

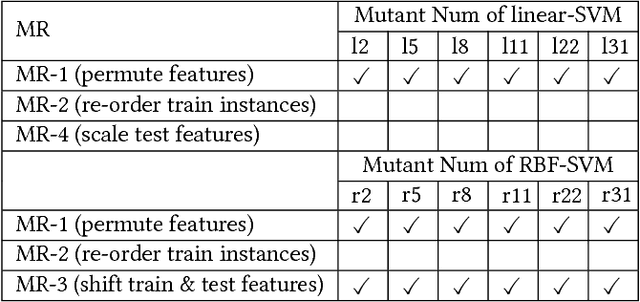
We have recently witnessed tremendous success of Machine Learning (ML) in practical applications. Computer vision, speech recognition and language translation have all seen a near human level performance. We expect, in the near future, most business applications will have some form of ML. However, testing such applications is extremely challenging and would be very expensive if we follow today's methodologies. In this work, we present an articulation of the challenges in testing ML based applications. We then present our solution approach, based on the concept of Metamorphic Testing, which aims to identify implementation bugs in ML based image classifiers. We have developed metamorphic relations for an application based on Support Vector Machine and a Deep Learning based application. Empirical validation showed that our approach was able to catch 71% of the implementation bugs in the ML applications.