 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Meta-Learning For Few-Shot Image and Video Classification
Nov 28, 2018

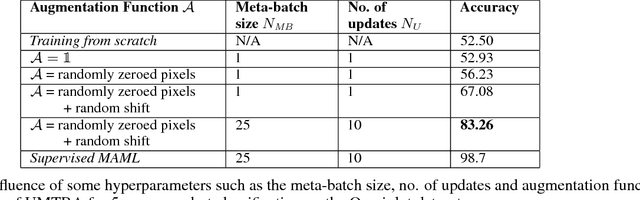
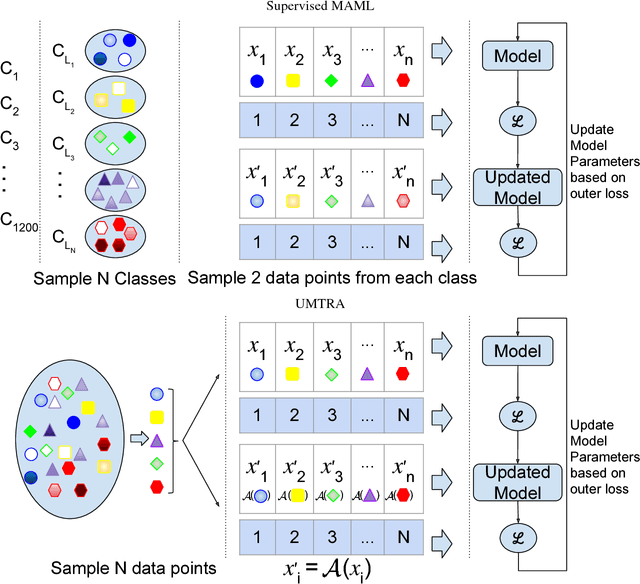
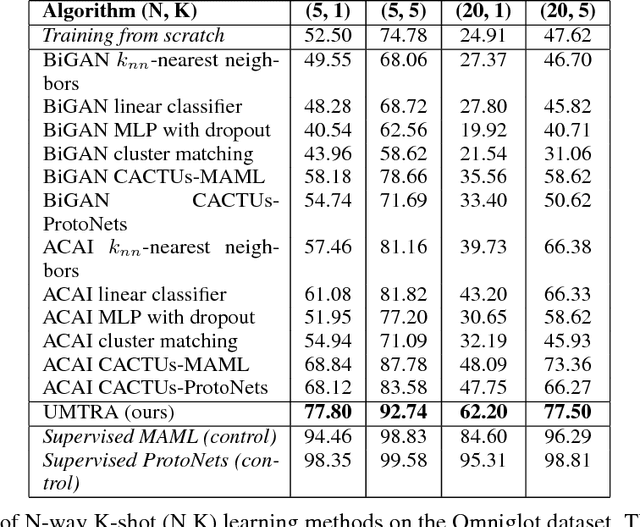
Few-shot or one-shot learning of classifiers for images or videos is an important next frontier in computer vision. The extreme paucity of training data means that the learning must start with a significant inductive bias towards the type of task to be learned. One way to acquire this is by meta-learning on tasks similar to the target task. However, if the meta-learning phase requires labeled data for a large number of tasks closely related to the target task, it not only increases the difficulty and cost, but also conceptually limits the approach to variations of well-understood domains. In this paper, we propose UMTRA, an algorithm that performs meta-learning on an unlabeled dataset in an unsupervised fashion, without putting any constraint on the classifier network architecture. The only requirements towards the dataset are: sufficient size, diversity and number of classes, and relevance of the domain to the one in the target task. Exploiting this information, UMTRA generates synthetic training tasks for the meta-learning phase. We evaluate UMTRA on few-shot and one-shot learning on both image and video domains. To the best of our knowledge, we are the first to evaluate meta-learning approaches on UCF-101. On the Omniglot and Mini-Imagenet few-shot learning benchmarks, UMTRA outperforms every tested approach based on unsupervised learning of representations, while alternating for the best performance with the recent CACTUs algorithm. Compared to supervised model-agnostic meta-learning approaches, UMTRA trades off some classification accuracy for a vast decrease in the number of labeled data needed. For instance, on the five-way one-shot classification on the Omniglot, we retain 85% of the accuracy of MAML, a recently proposed supervised meta-learning algorithm, while reducing the number of required labels from 24005 to 5.
Achievements and Challenges in Explaining Deep Learning based Computer-Aided Diagnosis Systems
Nov 26, 2020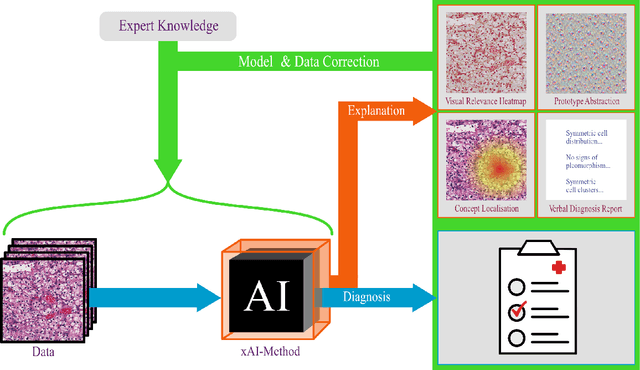
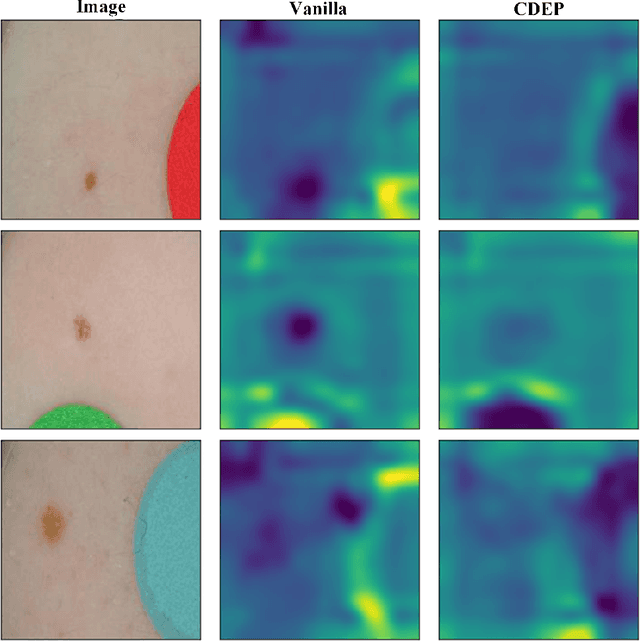
Remarkable success of modern image-based AI methods and the resulting interest in their applications in critical decision-making processes has led to a surge in efforts to make such intelligent systems transparent and explainable. The need for explainable AI does not stem only from ethical and moral grounds but also from stricter legislation around the world mandating clear and justifiable explanations of any decision taken or assisted by AI. Especially in the medical context where Computer-Aided Diagnosis can have a direct influence on the treatment and well-being of patients, transparency is of utmost importance for safe transition from lab research to real world clinical practice. This paper provides a comprehensive overview of current state-of-the-art in explaining and interpreting Deep Learning based algorithms in applications of medical research and diagnosis of diseases. We discuss early achievements in development of explainable AI for validation of known disease criteria, exploration of new potential biomarkers, as well as methods for the subsequent correction of AI models. Various explanation methods like visual, textual, post-hoc, ante-hoc, local and global have been thoroughly and critically analyzed. Subsequently, we also highlight some of the remaining challenges that stand in the way of practical applications of AI as a clinical decision support tool and provide recommendations for the direction of future research.
Video Understanding based on Human Action and Group Activity Recognition
Oct 24, 2020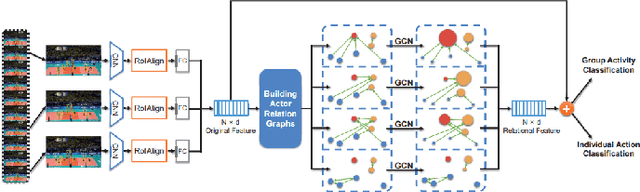
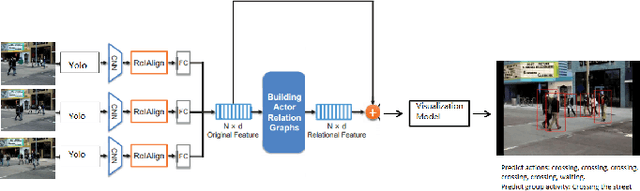
A lot of previous work, such as video captioning, has shown promising performance in producing general video understanding. However, it is still challenging to generate a fine-grained description of human actions and their interactions using state-of-the-art video captioning techniques. The detailed description of human actions and group activities is essential information, which can be used in real-time CCTV video surveillance, health care, sports video analysis, etc. In this study, we will propose and improve the video understanding method based on the Group Activity Recognition model by learning Actor Relation Graph (ARG).We will enhance the functionality and the performance of the ARG based model to perform a better video understanding by applying approaches such as increasing human object detection accuracy with YOLO, increasing process speed by reducing the input image size, and applying ResNet in the CNN layer.We will also introduce a visualization model that will visualize each input video frame with predicted bounding boxes on each human object and predicted "video captioning" to describe each individual's action and their collective activity.
Estimation error analysis of deep learning on the regression problem on the variable exponent Besov space
Sep 27, 2020
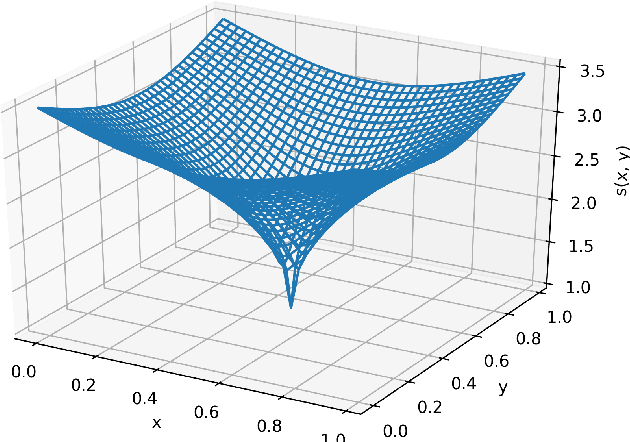
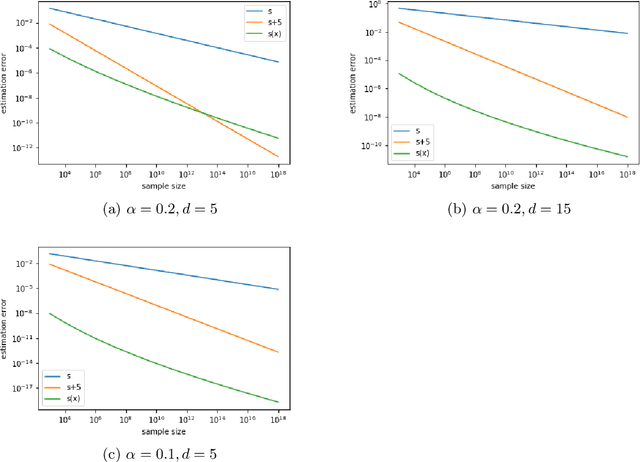
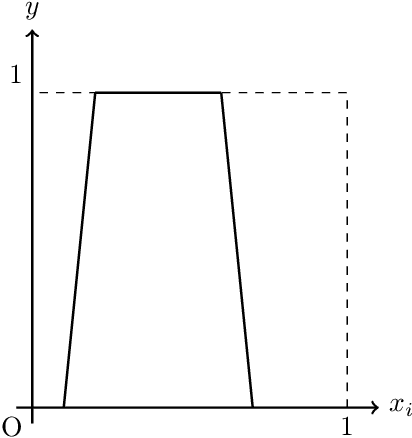
Deep learning has achieved notable success in various fields, including image and speech recognition. One of the factors in the successful performance of deep learning is its high feature extraction ability. In this study, we focus on the adaptivity of deep learning; consequently, we treat the variable exponent Besov space, which has a different smoothness depending on the input location $x$. In other words, the difficulty of the estimation is not uniform within the domain. We analyze the general approximation error of the variable exponent Besov space and the approximation and estimation errors of deep learning. We note that the improvement based on adaptivity is remarkable when the region upon which the target function has less smoothness is small and the dimension is large. Moreover, the superiority to linear estimators is shown with respect to the convergence rate of the estimation error.
Surface Agnostic Metrics for Cortical Volume Segmentation and Regression
Oct 04, 2020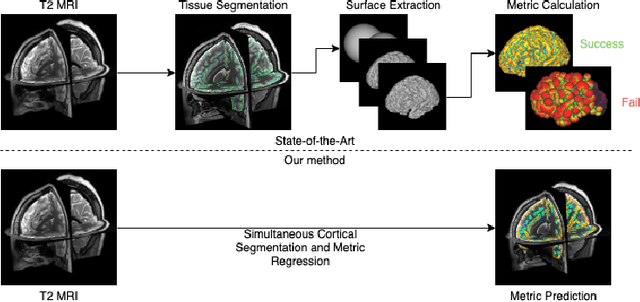
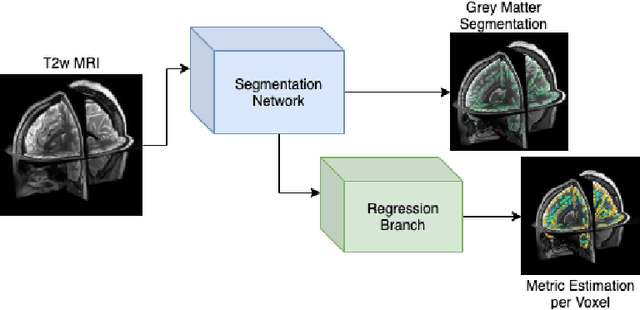
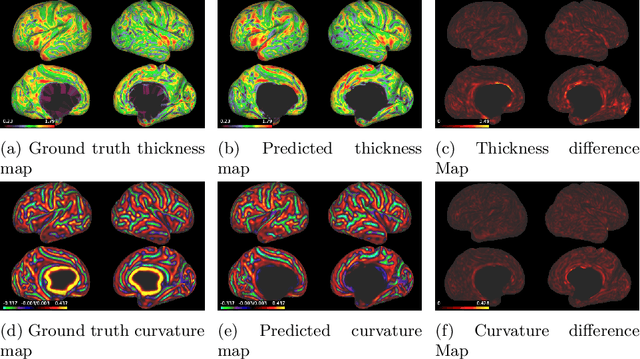
The cerebral cortex performs higher-order brain functions and is thus implicated in a range of cognitive disorders. Current analysis of cortical variation is typically performed by fitting surface mesh models to inner and outer cortical boundaries and investigating metrics such as surface area and cortical curvature or thickness. These, however, take a long time to run, and are sensitive to motion and image and surface resolution, which can prohibit their use in clinical settings. In this paper, we instead propose a machine learning solution, training a novel architecture to predict cortical thickness and curvature metrics from T2 MRI images, while additionally returning metrics of prediction uncertainty. Our proposed model is tested on a clinical cohort (Down Syndrome) for which surface-based modelling often fails. Results suggest that deep convolutional neural networks are a viable option to predict cortical metrics across a range of brain development stages and pathologies.
Fast Object Detection with Latticed Multi-Scale Feature Fusion
Nov 05, 2020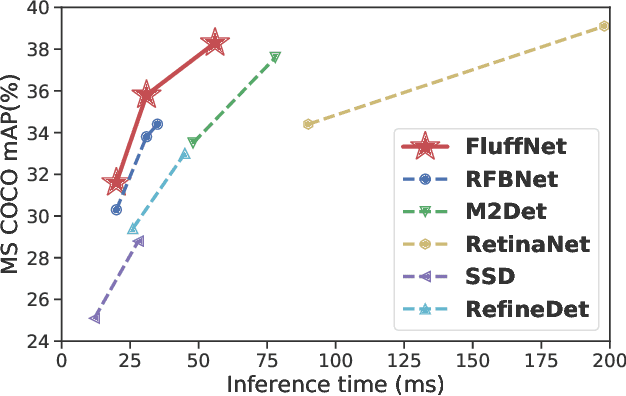
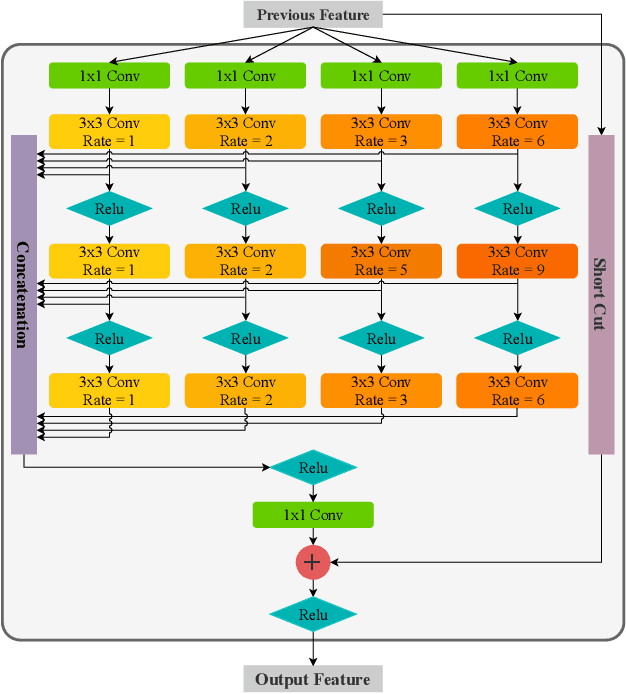
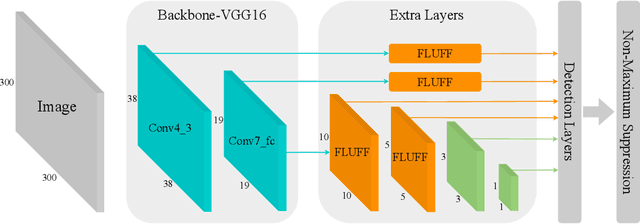
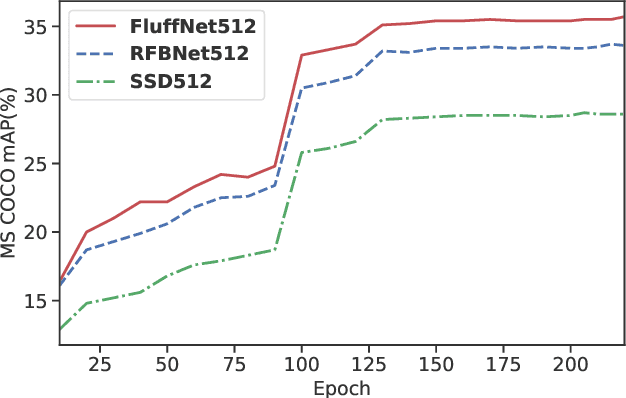
Scale variance is one of the crucial challenges in multi-scale object detection. Early approaches address this problem by exploiting the image and feature pyramid, which raises suboptimal results with computation burden and constrains from inherent network structures. Pioneering works also propose multi-scale (i.e., multi-level and multi-branch) feature fusions to remedy the issue and have achieved encouraging progress. However, existing fusions still have certain limitations such as feature scale inconsistency, ignorance of level-wise semantic transformation, and coarse granularity. In this work, we present a novel module, the Fluff block, to alleviate drawbacks of current multi-scale fusion methods and facilitate multi-scale object detection. Specifically, Fluff leverages both multi-level and multi-branch schemes with dilated convolutions to have rapid, effective and finer-grained feature fusions. Furthermore, we integrate Fluff to SSD as FluffNet, a powerful real-time single-stage detector for multi-scale object detection. Empirical results on MS COCO and PASCAL VOC have demonstrated that FluffNet obtains remarkable efficiency with state-of-the-art accuracy. Additionally, we indicate the great generality of the Fluff block by showing how to embed it to other widely-used detectors as well.
Fast Uncertainty Quantification for Deep Object Pose Estimation
Nov 16, 2020


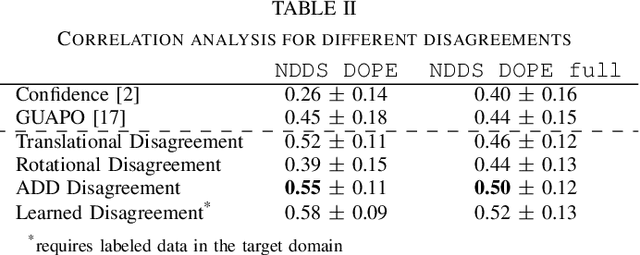
Deep learning-based object pose estimators are often unreliable and overconfident especially when the input image is outside the training domain, for instance, with sim2real transfer. Efficient and robust uncertainty quantification (UQ) in pose estimators is critically needed in many robotic tasks. In this work, we propose a simple, efficient, and plug-and-play UQ method for 6-DoF object pose estimation. We ensemble 2-3 pre-trained models with different neural network architectures and/or training data sources, and compute their average pairwise disagreement against one another to obtain the uncertainty quantification. We propose four disagreement metrics, including a learned metric, and show that the average distance (ADD) is the best learning-free metric and it is only slightly worse than the learned metric, which requires labeled target data. Our method has several advantages compared to the prior art: 1) our method does not require any modification of the training process or the model inputs; and 2) it needs only one forward pass for each model. We evaluate the proposed UQ method on three tasks where our uncertainty quantification yields much stronger correlations with pose estimation errors than the baselines. Moreover, in a real robot grasping task, our method increases the grasping success rate from 35% to 90%.
Learning to Decode 7T-like MR Image Reconstruction from 3T MR Images
Jun 18, 2018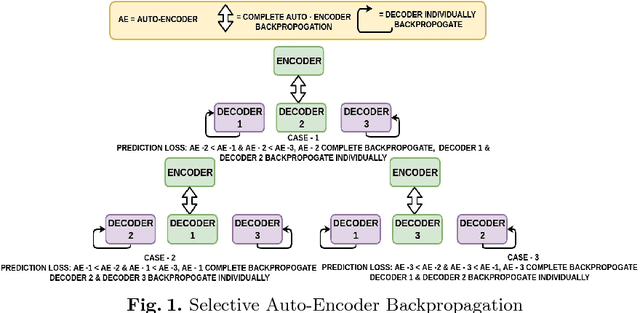
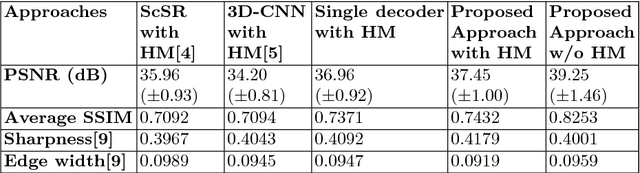
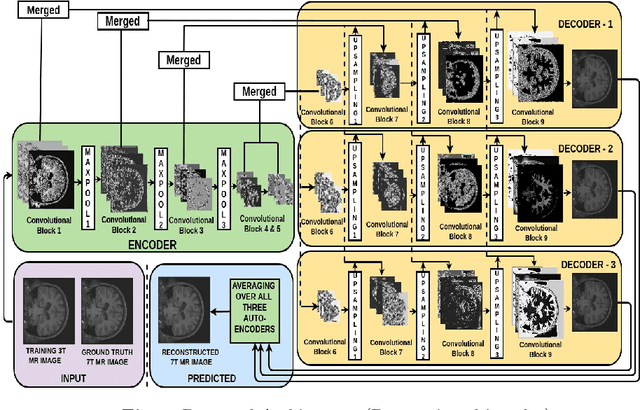
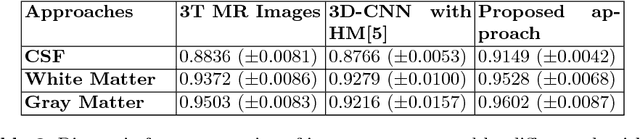
Increasing demand for high field magnetic resonance (MR) scanner indicates the need for high-quality MR images for accurate medical diagnosis. However, cost constraints, instead, motivate a need for algorithms to enhance images from low field scanners. We propose an approach to process the given low field (3T) MR image slices to reconstruct the corresponding high field (7T-like) slices. Our framework involves a novel architecture of a merged convolutional autoencoder with a single encoder and multiple decoders. Specifically, we employ three decoders with random initializations, and the proposed training approach involves selection of a particular decoder in each weight-update iteration for back propagation. We demonstrate that the proposed algorithm outperforms some related contemporary methods in terms of performance and reconstruction time.
DPD-InfoGAN: Differentially Private Distributed InfoGAN
Oct 24, 2020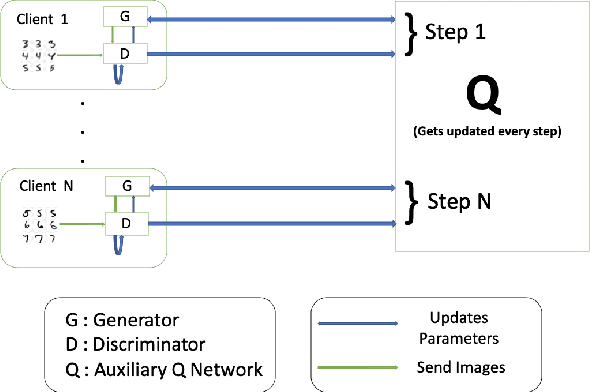
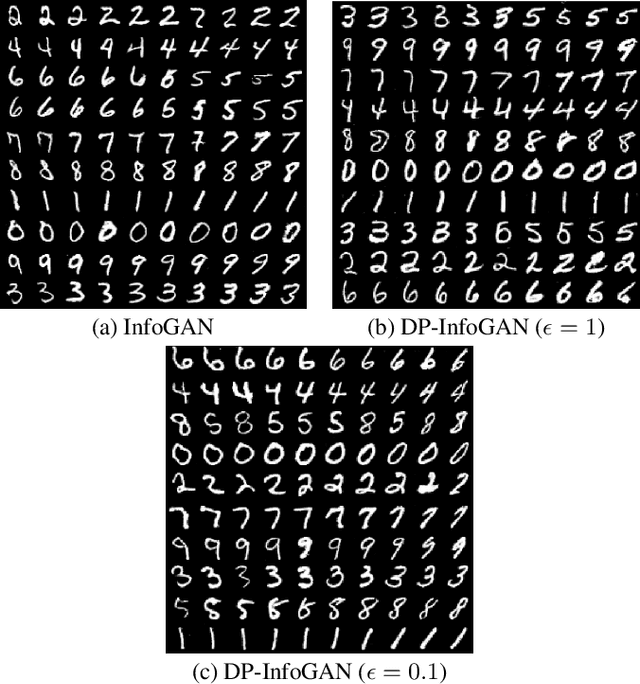


Generative Adversarial Networks (GANs) are deep learning architectures capable of generating synthetic datasets. Despite producing high-quality synthetic images, the default GAN has no control over the kinds of images it generates. The Information Maximizing GAN (InfoGAN) is a variant of the default GAN that introduces feature-control variables that are automatically learned by the framework, hence providing greater control over the different kinds of images produced. Due to the high model complexity of InfoGAN, the generative distribution tends to be concentrated around the training data points. This is a critical problem as the models may inadvertently expose the sensitive and private information present in the dataset. To address this problem, we propose a differentially private version of InfoGAN (DP-InfoGAN). We also extend our framework to a distributed setting (DPD-InfoGAN) to allow clients to learn different attributes present in other clients' datasets in a privacy-preserving manner. In our experiments, we show that both DP-InfoGAN and DPD-InfoGAN can synthesize high-quality images with flexible control over image attributes while preserving privacy.
Fast Adaptation to Super-Resolution Networks via Meta-Learning
Jan 14, 2020
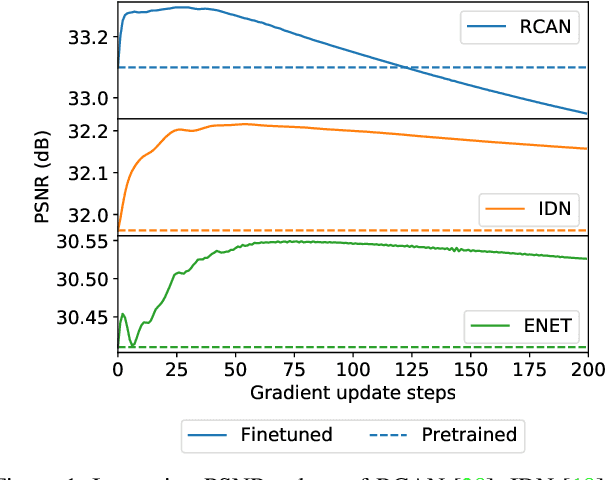
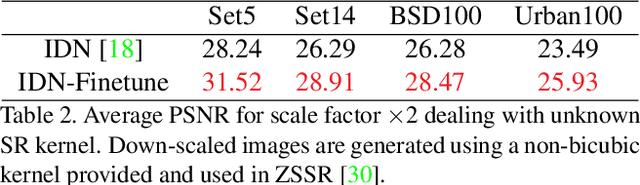
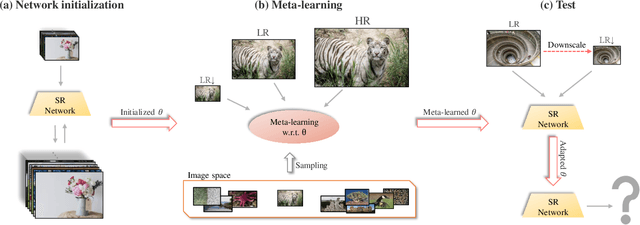
Conventional supervised super-resolution (SR) approaches are trained with massive external SR datasets but fail to exploit desirable properties of the given test image. On the other hand, self-supervised SR approaches utilize the internal information within a test image but suffer from computational complexity in run-time. In this work, we observe the opportunity for further improvement of the performance of SISR without changing the architecture of conventional SR networks by practically exploiting additional information given from the input image. In the training stage, we train the network via meta-learning; thus, the network can quickly adapt to any input image at test time. Then, in the test stage, parameters of this meta-learned network are rapidly fine-tuned with only a few iterations by only using the given low-resolution image. The adaptation at the test time takes full advantage of patch-recurrence property observed in natural images. Our method effectively handles unknown SR kernels and can be applied to any existing model. We demonstrate that the proposed model-agnostic approach consistently improves the performance of conventional SR networks on various benchmark SR datasets.