 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hierarchical Context Embedding for Region-based Object Detection
Aug 04, 2020

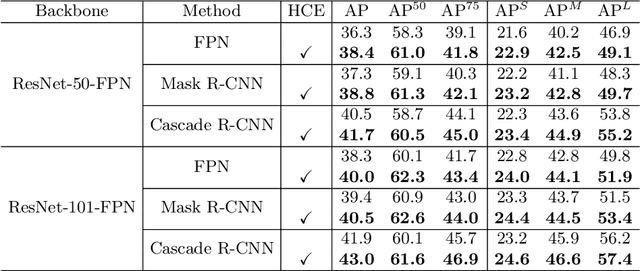
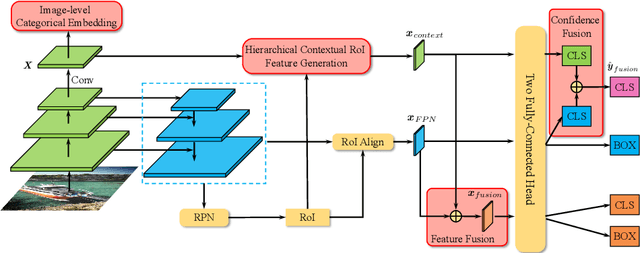
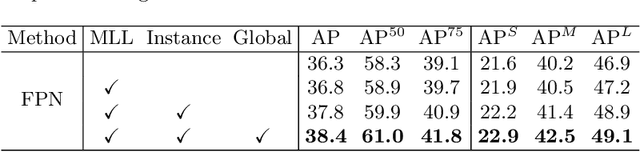
State-of-the-art two-stage object detectors apply a classifier to a sparse set of object proposals, relying on region-wise features extracted by RoIPool or RoIAlign as inputs. The region-wise features, in spite of aligning well with the proposal locations, may still lack the crucial context information which is necessary for filtering out noisy background detections, as well as recognizing objects possessing no distinctive appearances. To address this issue, we present a simple but effective Hierarchical Context Embedding (HCE) framework, which can be applied as a plug-and-play component, to facilitate the classification ability of a series of region-based detectors by mining contextual cues. Specifically, to advance the recognition of context-dependent object categories, we propose an image-level categorical embedding module which leverages the holistic image-level context to learn object-level concepts. Then, novel RoI features are generated by exploiting hierarchically embedded context information beneath both whole images and interested regions, which are also complementary to conventional RoI features. Moreover, to make full use of our hierarchical contextual RoI features, we propose the early-and-late fusion strategies (i.e., feature fusion and confidence fusion), which can be combined to boost the classification accuracy of region-based detectors. Comprehensive experiments demonstrate that our HCE framework is flexible and generalizable, leading to significant and consistent improvements upon various region-based detectors, including FPN, Cascade R-CNN and Mask R-CNN.
Color Channel Perturbation Attacks for Fooling Convolutional Neural Networks and A Defense Against Such Attacks
Dec 20, 2020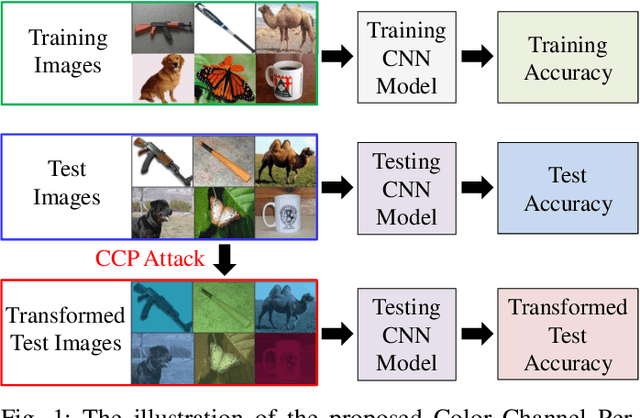

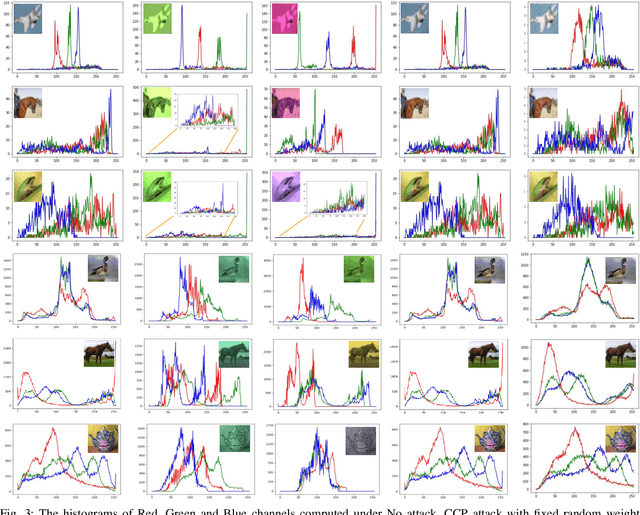
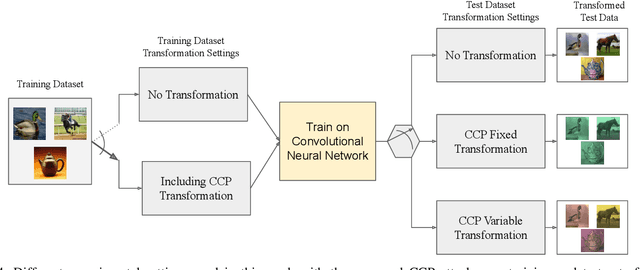
The Convolutional Neural Networks (CNNs) have emerged as a very powerful data dependent hierarchical feature extraction method. It is widely used in several computer vision problems. The CNNs learn the important visual features from training samples automatically. It is observed that the network overfits the training samples very easily. Several regularization methods have been proposed to avoid the overfitting. In spite of this, the network is sensitive to the color distribution within the images which is ignored by the existing approaches. In this paper, we discover the color robustness problem of CNN by proposing a Color Channel Perturbation (CCP) attack to fool the CNNs. In CCP attack new images are generated with new channels created by combining the original channels with the stochastic weights. Experiments were carried out over widely used CIFAR10, Caltech256 and TinyImageNet datasets in the image classification framework. The VGG, ResNet and DenseNet models are used to test the impact of the proposed attack. It is observed that the performance of the CNNs degrades drastically under the proposed CCP attack. Result show the effect of the proposed simple CCP attack over the robustness of the CNN trained model. The results are also compared with existing CNN fooling approaches to evaluate the accuracy drop. We also propose a primary defense mechanism to this problem by augmenting the training dataset with the proposed CCP attack. The state-of-the-art performance using the proposed solution in terms of the CNN robustness under CCP attack is observed in the experiments. The code is made publicly available at \url{https://github.com/jayendrakantipudi/Color-Channel-Perturbation-Attack}.
Learning Multi-Modal Nonlinear Embeddings: Performance Bounds and an Algorithm
Jun 03, 2020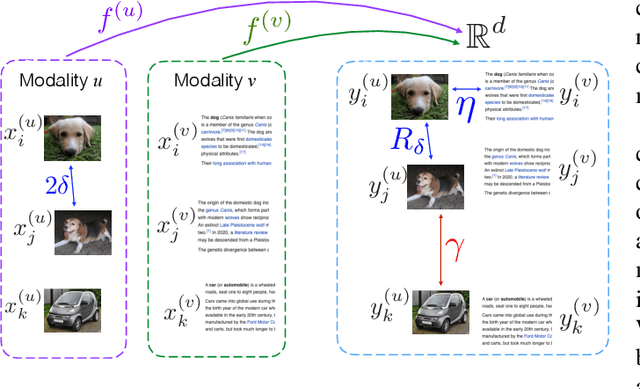

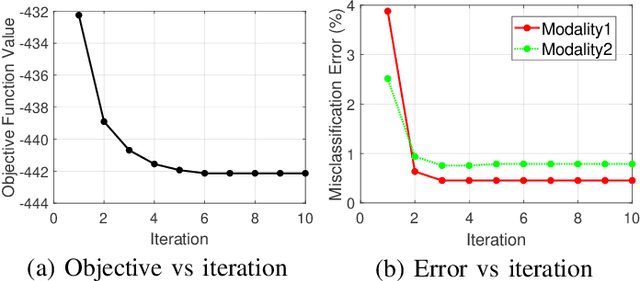
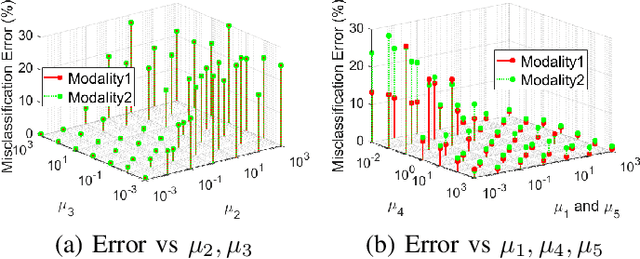
While many approaches exist in the literature to learn representations for data collections in multiple modalities, the generalizability of the learnt representations to previously unseen data is a largely overlooked subject. In this work, we first present a theoretical analysis of learning multi-modal nonlinear embeddings in a supervised setting. Our performance bounds indicate that for successful generalization in multi-modal classification and retrieval problems, the regularity of the interpolation functions extending the embedding to the whole data space is as important as the between-class separation and cross-modal alignment criteria. We then propose a multi-modal nonlinear representation learning algorithm that is motivated by these theoretical findings, where the embeddings of the training samples are optimized jointly with the Lipschitz regularity of the interpolators. Experimental comparison to recent multi-modal and single-modal learning algorithms suggests that the proposed method yields promising performance in multi-modal image classification and cross-modal image-text retrieval applications.
Conditional Generative Refinement Adversarial Networks for Unbalanced Medical Image Semantic Segmentation
Oct 09, 2018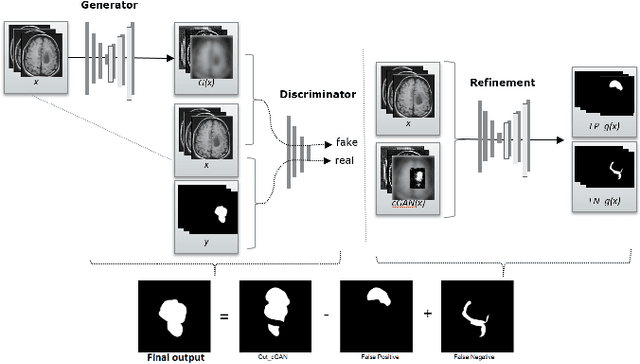
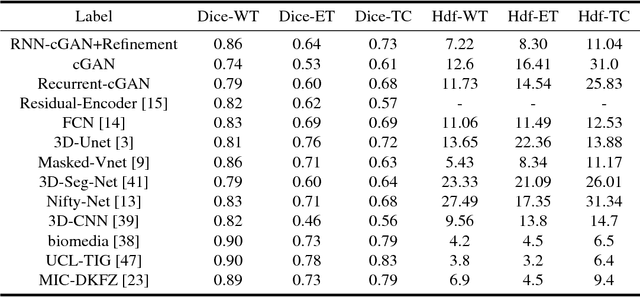

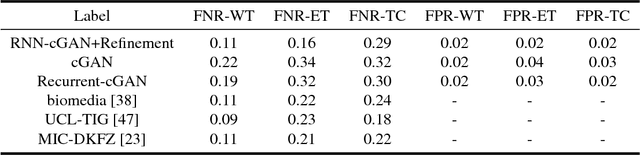
We propose a new generative adversarial architecture to mitigate imbalance data problem in medical image semantic segmentation where the majority of pixels belongs to a healthy region and few belong to lesion or non-health region. A model trained with imbalanced data tends to bias toward healthy data which is not desired in clinical applications and predicted outputs by these networks have high precision and low sensitivity. We propose a new conditional generative refinement network with three components: a generative, a discriminative, and a refinement network to mitigate unbalanced data problem through ensemble learning. The generative network learns to a segment at the pixel level by getting feedback from the discriminative network according to the true positive and true negative maps. On the other hand, the refinement network learns to predict the false positive and the false negative masks produced by the generative network that has significant value, especially in medical application. The final semantic segmentation masks are then composed by the output of the three networks. The proposed architecture shows state-of-the-art results on LiTS-2017 for liver lesion segmentation, and two microscopic cell segmentation datasets MDA231, PhC-HeLa. We have achieved competitive results on BraTS-2017 for brain tumour segmentation.
VINNAS: Variational Inference-based Neural Network Architecture Search
Jul 12, 2020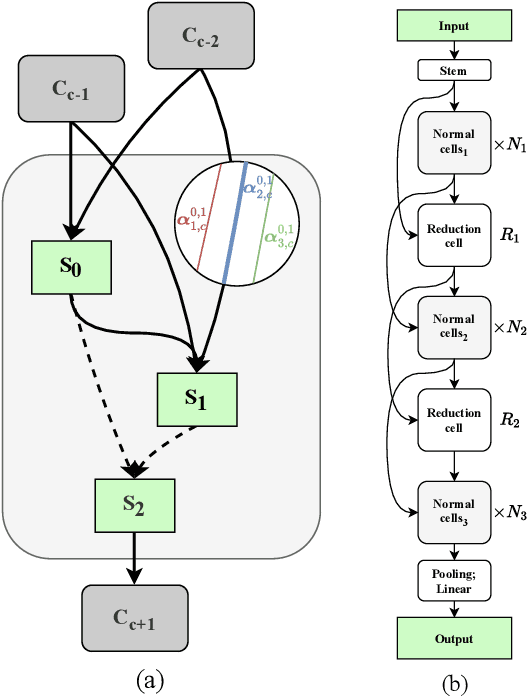
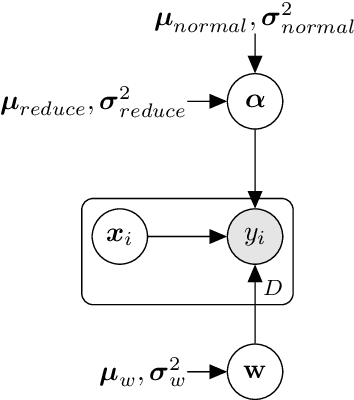
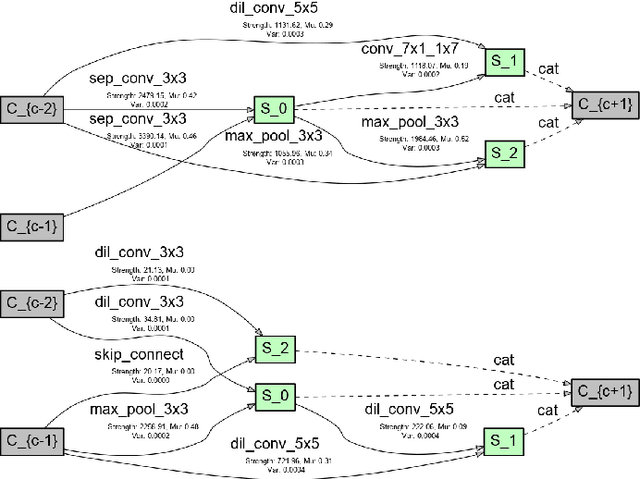
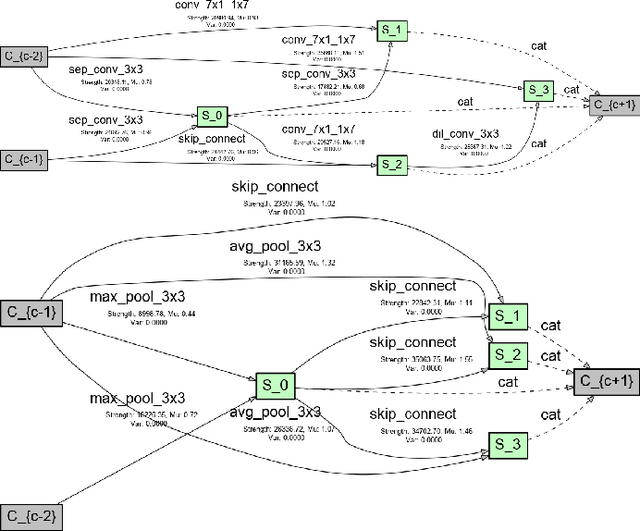
In recent years, neural architecture search (NAS) has received intensive scientific and industrial interest due to its capability of finding a neural architecture with high accuracy for various artificial intelligence tasks such as image classification or object detection. In particular, gradient-based NAS approaches have become one of the more popular approaches thanks to their computational efficiency during the search. However, these methods often experience a mode collapse, where the quality of the found architectures is poor due to the algorithm resorting to choosing a single operation type for the entire network, or stagnating at a local minima for various datasets or search spaces. To address these defects, we present a differentiable variational inference-based NAS method for searching sparse convolutional neural networks. Our approach finds the optimal neural architecture by dropping out candidate operations in an over-parameterised supergraph using variational dropout with automatic relevance determination prior, which makes the algorithm gradually remove unnecessary operations and connections without risking mode collapse. The evaluation is conducted through searching two types of convolutional cells that shape the neural network for classifying different image datasets. Our method finds diverse network cells, while showing state-of-the-art accuracy with up to $3 \times$ fewer parameters.
Knowledge Capture and Replay for Continual Learning
Dec 12, 2020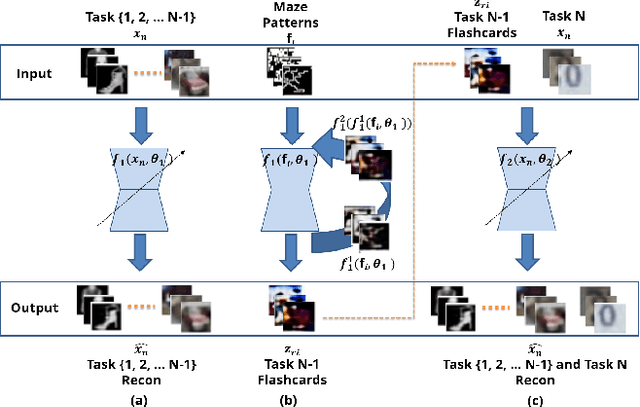
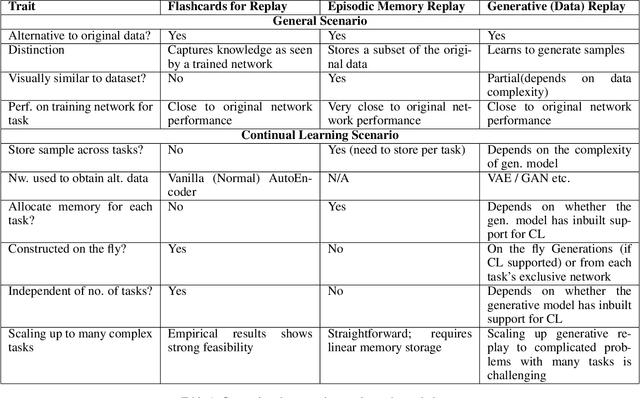
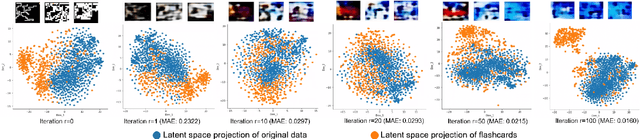
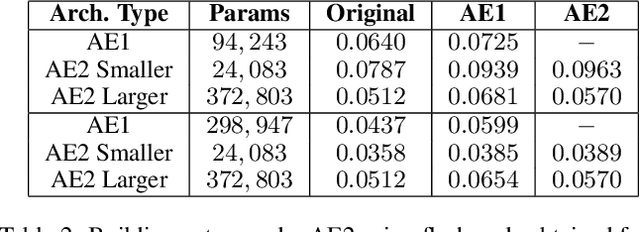
Deep neural networks have shown promise in several domains, and the learned task-specific information is implicitly stored in the network parameters. It will be vital to utilize representations from these networks for downstream tasks such as continual learning. In this paper, we introduce the notion of {\em flashcards} that are visual representations to {\em capture} the encoded knowledge of a network, as a function of random image patterns. We demonstrate the effectiveness of flashcards in capturing representations and show that they are efficient replay methods for general and task agnostic continual learning setting. Thus, while adapting to a new task, a limited number of constructed flashcards, help to prevent catastrophic forgetting of the previously learned tasks. Most interestingly, such flashcards neither require external memory storage nor need to be accumulated over multiple tasks and only need to be constructed just before learning the subsequent new task, irrespective of the number of tasks trained before and are hence task agnostic. We first demonstrate the efficacy of flashcards in capturing knowledge representation from a trained network, and empirically validate the efficacy of flashcards on a variety of continual learning tasks: continual unsupervised reconstruction, continual denoising, and new-instance learning classification, using a number of heterogeneous benchmark datasets. These studies also indicate that continual learning algorithms with flashcards as the replay strategy perform better than other state-of-the-art replay methods, and exhibits on par performance with the best possible baseline using coreset sampling, with the least additional computational complexity and storage.
CCML: A Novel Collaborative Learning Model for Classification of Remote Sensing Images with Noisy Multi-Labels
Dec 27, 2020
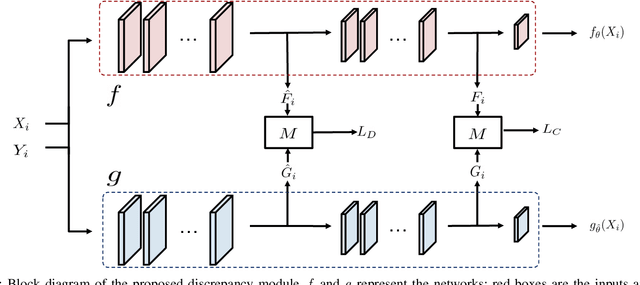
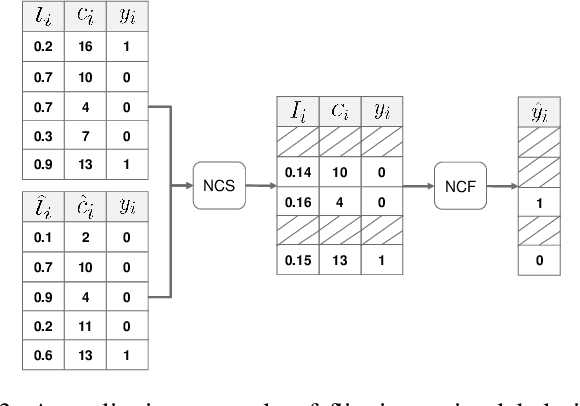
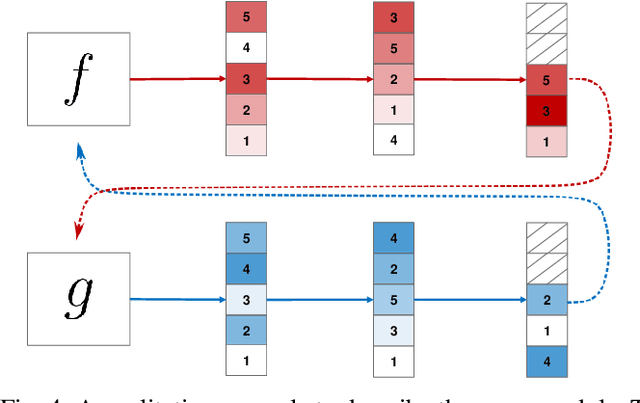
The development of accurate methods for multi-label classification (MLC) of remote sensing (RS) images is one of the most important research topics in RS. Deep Convolutional Neural Networks (CNNs) based methods have triggered substantial performance gains in RS MLC problems, requiring a large number of reliable training images annotated by multiple land-cover class labels. Collecting such data is time-consuming and costly. To address this problem, the publicly available thematic products, which can include noisy labels, can be used for annotating RS images with zero-labeling cost. However, multi-label noise (which can be associated with wrong as well as missing label annotations) can distort the learning process of the MLC algorithm, resulting in inaccurate predictions. The detection and correction of label noise are challenging tasks, especially in a multi-label scenario, where each image can be associated with more than one label. To address this problem, we propose a novel Consensual Collaborative Multi-Label Learning (CCML) method to alleviate the adverse effects of multi-label noise during the training phase of the CNN model. CCML identifies, ranks, and corrects noisy multi-labels in RS images based on four main modules: 1) group lasso module; 2) discrepancy module; 3) flipping module; and 4) swap module. The task of the group lasso module is to detect the potentially noisy labels assigned to the multi-labeled training images, and the discrepancy module ensures that the two collaborative networks learn diverse features, while obtaining the same predictions. The flipping module is designed to correct the identified noisy multi-labels, while the swap module task is devoted to exchanging the ranking information between two networks. Our code is publicly available online: http://www.noisy-labels-in-rs.org
Emotional Semantics-Preserved and Feature-Aligned CycleGAN for Visual Emotion Adaptation
Nov 25, 2020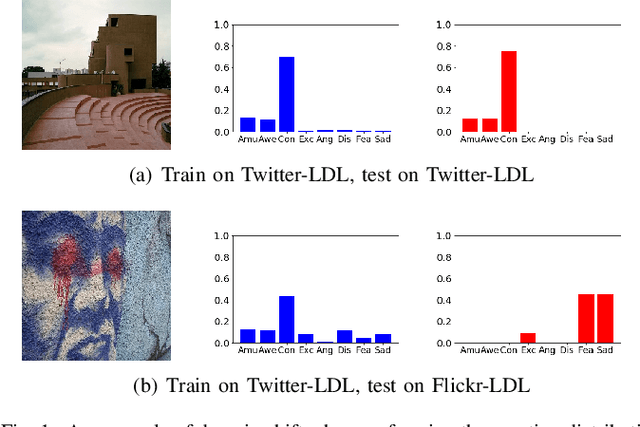

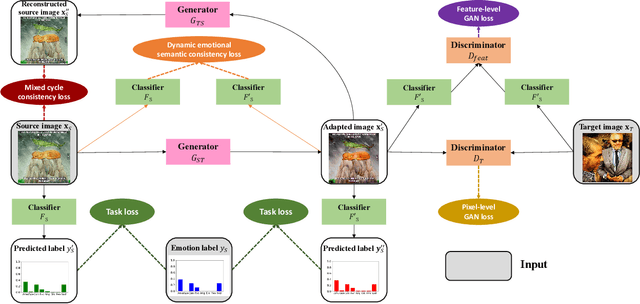
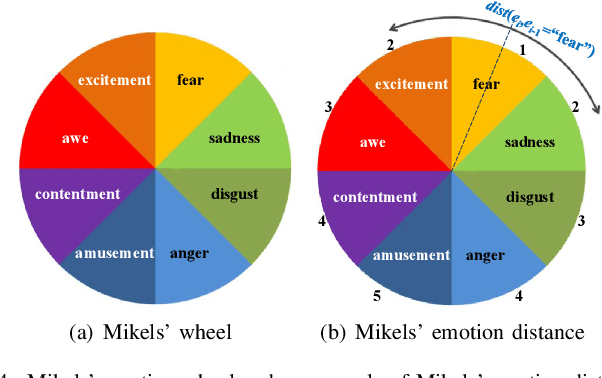
Thanks to large-scale labeled training data, deep neural networks (DNNs) have obtained remarkable success in many vision and multimedia tasks. However, because of the presence of domain shift, the learned knowledge of the well-trained DNNs cannot be well generalized to new domains or datasets that have few labels. Unsupervised domain adaptation (UDA) studies the problem of transferring models trained on one labeled source domain to another unlabeled target domain. In this paper, we focus on UDA in visual emotion analysis for both emotion distribution learning and dominant emotion classification. Specifically, we design a novel end-to-end cycle-consistent adversarial model, termed CycleEmotionGAN++. First, we generate an adapted domain to align the source and target domains on the pixel-level by improving CycleGAN with a multi-scale structured cycle-consistency loss. During the image translation, we propose a dynamic emotional semantic consistency loss to preserve the emotion labels of the source images. Second, we train a transferable task classifier on the adapted domain with feature-level alignment between the adapted and target domains. We conduct extensive UDA experiments on the Flickr-LDL & Twitter-LDL datasets for distribution learning and ArtPhoto & FI datasets for emotion classification. The results demonstrate the significant improvements yielded by the proposed CycleEmotionGAN++ as compared to state-of-the-art UDA approaches.
Joint Dictionary Learning for Example-based Image Super-resolution
Jan 12, 2017
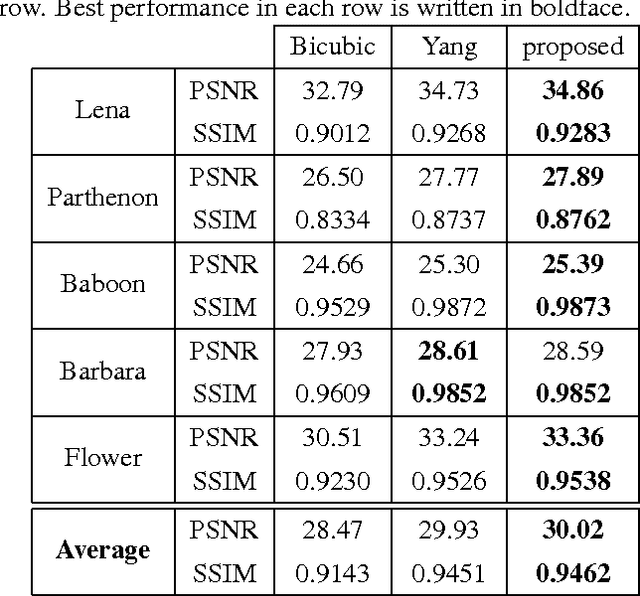
In this paper, we propose a new joint dictionary learning method for example-based image super-resolution (SR), using sparse representation. The low-resolution (LR) dictionary is trained from a set of LR sample image patches. Using the sparse representation coefficients of these LR patches over the LR dictionary, the high-resolution (HR) dictionary is trained by minimizing the reconstruction error of HR sample patches. The error criterion used here is the mean square error. In this way we guarantee that the HR patches have the same sparse representation over HR dictionary as the LR patches over the LR dictionary, and at the same time, these sparse representations can well reconstruct the HR patches. Simulation results show the effectiveness of our method compared to the state-of-art SR algorithms.
The Impact of Hole Geometry on Relative Robustness of In-Painting Networks: An Empirical Study
Mar 04, 2020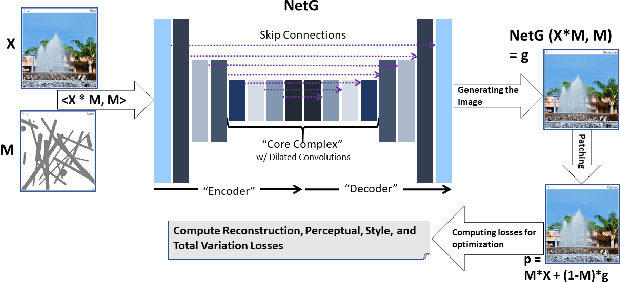


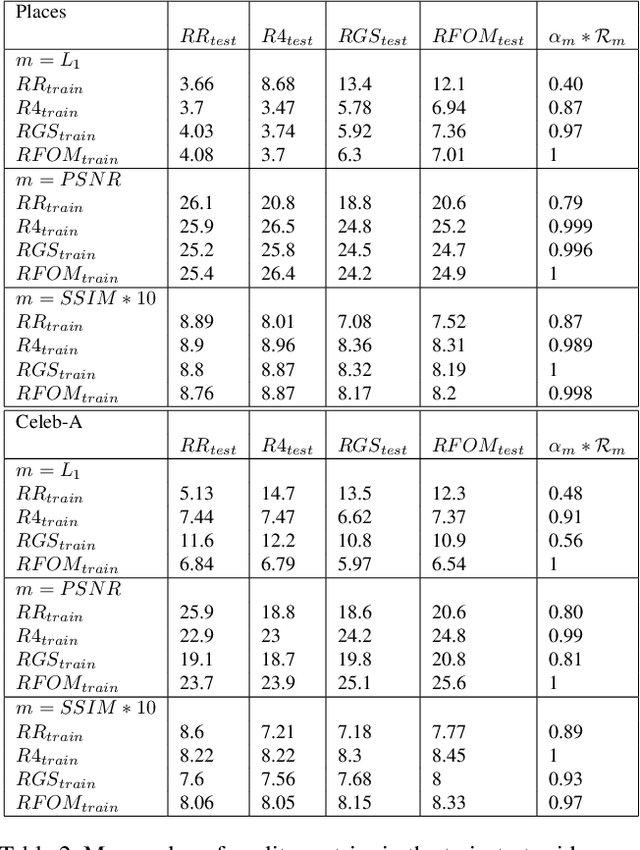
In-painting networks use existing pixels to generate appropriate pixels to fill "holes" placed on parts of an image. A 2-D in-painting network's input usually consists of (1) a three-channel 2-D image, and (2) an additional channel for the "holes" to be in-painted in that image. In this paper, we study the robustness of a given in-painting neural network against variations in hole geometry distributions. We observe that the robustness of an in-painting network is dependent on the probability distribution function (PDF) of the hole geometry presented to it during its training even if the underlying image dataset used (in training and testing) does not alter. We develop an experimental methodology for testing and evaluating relative robustness of in-painting networks against four different kinds of hole geometry PDFs. We examine a number of hypothesis regarding (1) the natural bias of in-painting networks to the hole distribution used for their training, (2) the underlying dataset's ability to differentiate relative robustness as hole distributions vary in a train-test (cross-comparison) grid, and (3) the impact of the directional distribution of edges in the holes and in the image dataset. We present results for L1, PSNR and SSIM quality metrics and develop a specific measure of relative in-painting robustness to be used in cross-comparison grids based on these quality metrics. (One can incorporate other quality metrics in this relative measure.) The empirical work reported here is an initial step in a broader and deeper investigation of "filling the blank" neural networks' sensitivity, robustness and regularization with respect to hole "geometry" PDFs, and it suggests further research in this domain.