 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Video Understanding based on Human Action and Group Activity Recognition
Oct 24, 2020
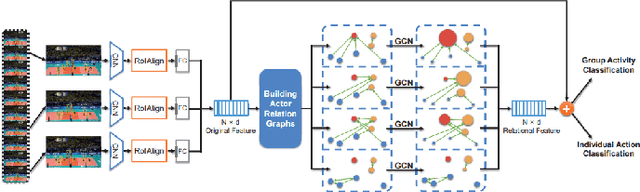
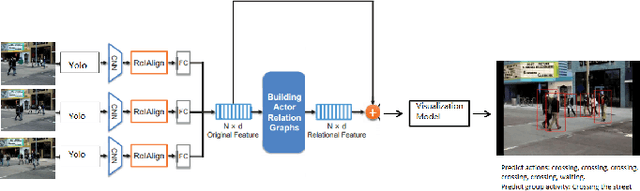
A lot of previous work, such as video captioning, has shown promising performance in producing general video understanding. However, it is still challenging to generate a fine-grained description of human actions and their interactions using state-of-the-art video captioning techniques. The detailed description of human actions and group activities is essential information, which can be used in real-time CCTV video surveillance, health care, sports video analysis, etc. In this study, we will propose and improve the video understanding method based on the Group Activity Recognition model by learning Actor Relation Graph (ARG).We will enhance the functionality and the performance of the ARG based model to perform a better video understanding by applying approaches such as increasing human object detection accuracy with YOLO, increasing process speed by reducing the input image size, and applying ResNet in the CNN layer.We will also introduce a visualization model that will visualize each input video frame with predicted bounding boxes on each human object and predicted "video captioning" to describe each individual's action and their collective activity.
Fast Object Detection with Latticed Multi-Scale Feature Fusion
Nov 05, 2020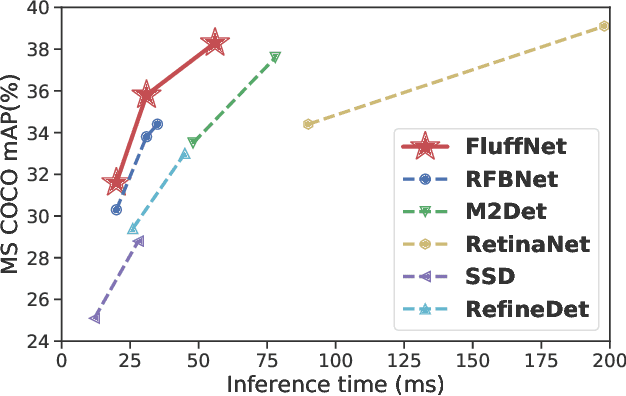
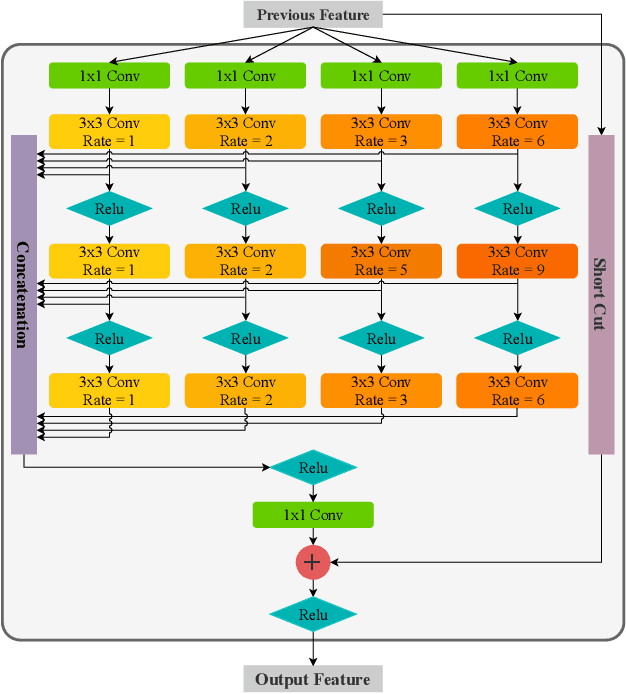
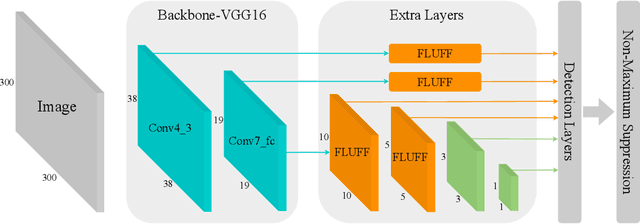
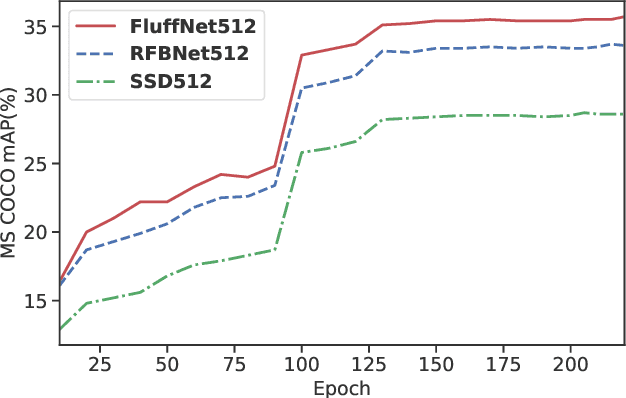
Scale variance is one of the crucial challenges in multi-scale object detection. Early approaches address this problem by exploiting the image and feature pyramid, which raises suboptimal results with computation burden and constrains from inherent network structures. Pioneering works also propose multi-scale (i.e., multi-level and multi-branch) feature fusions to remedy the issue and have achieved encouraging progress. However, existing fusions still have certain limitations such as feature scale inconsistency, ignorance of level-wise semantic transformation, and coarse granularity. In this work, we present a novel module, the Fluff block, to alleviate drawbacks of current multi-scale fusion methods and facilitate multi-scale object detection. Specifically, Fluff leverages both multi-level and multi-branch schemes with dilated convolutions to have rapid, effective and finer-grained feature fusions. Furthermore, we integrate Fluff to SSD as FluffNet, a powerful real-time single-stage detector for multi-scale object detection. Empirical results on MS COCO and PASCAL VOC have demonstrated that FluffNet obtains remarkable efficiency with state-of-the-art accuracy. Additionally, we indicate the great generality of the Fluff block by showing how to embed it to other widely-used detectors as well.
Learning Multi-Modal Nonlinear Embeddings: Performance Bounds and an Algorithm
Jun 03, 2020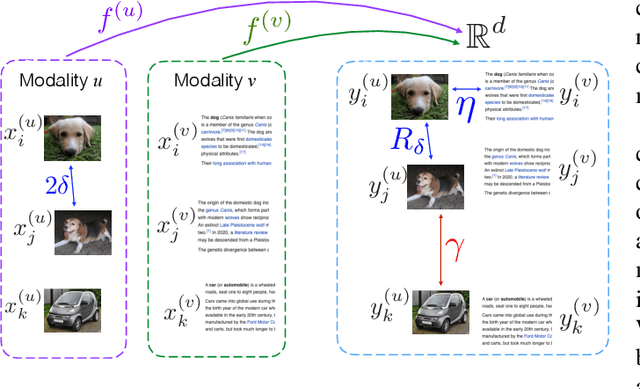

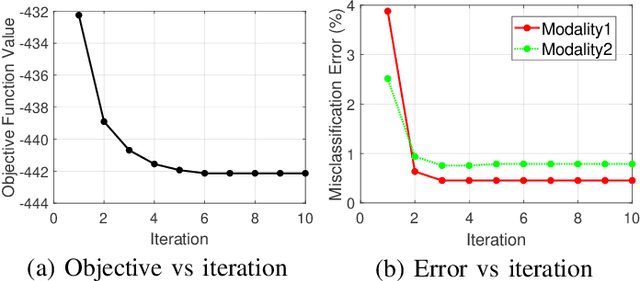
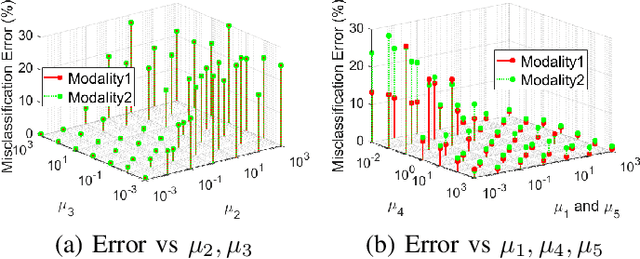
While many approaches exist in the literature to learn representations for data collections in multiple modalities, the generalizability of the learnt representations to previously unseen data is a largely overlooked subject. In this work, we first present a theoretical analysis of learning multi-modal nonlinear embeddings in a supervised setting. Our performance bounds indicate that for successful generalization in multi-modal classification and retrieval problems, the regularity of the interpolation functions extending the embedding to the whole data space is as important as the between-class separation and cross-modal alignment criteria. We then propose a multi-modal nonlinear representation learning algorithm that is motivated by these theoretical findings, where the embeddings of the training samples are optimized jointly with the Lipschitz regularity of the interpolators. Experimental comparison to recent multi-modal and single-modal learning algorithms suggests that the proposed method yields promising performance in multi-modal image classification and cross-modal image-text retrieval applications.
The Impact of Hole Geometry on Relative Robustness of In-Painting Networks: An Empirical Study
Mar 04, 2020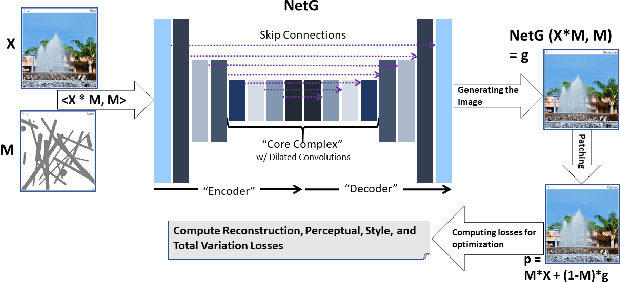


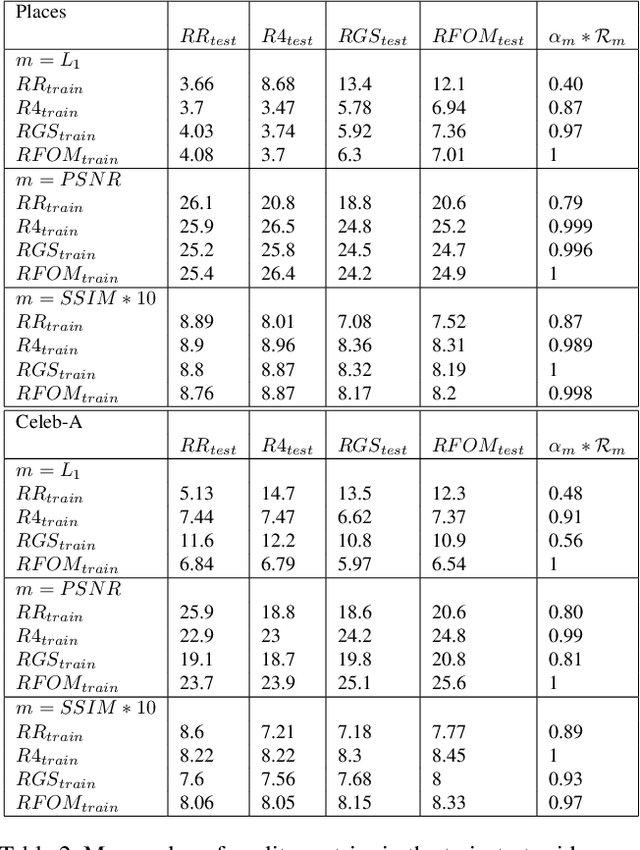
In-painting networks use existing pixels to generate appropriate pixels to fill "holes" placed on parts of an image. A 2-D in-painting network's input usually consists of (1) a three-channel 2-D image, and (2) an additional channel for the "holes" to be in-painted in that image. In this paper, we study the robustness of a given in-painting neural network against variations in hole geometry distributions. We observe that the robustness of an in-painting network is dependent on the probability distribution function (PDF) of the hole geometry presented to it during its training even if the underlying image dataset used (in training and testing) does not alter. We develop an experimental methodology for testing and evaluating relative robustness of in-painting networks against four different kinds of hole geometry PDFs. We examine a number of hypothesis regarding (1) the natural bias of in-painting networks to the hole distribution used for their training, (2) the underlying dataset's ability to differentiate relative robustness as hole distributions vary in a train-test (cross-comparison) grid, and (3) the impact of the directional distribution of edges in the holes and in the image dataset. We present results for L1, PSNR and SSIM quality metrics and develop a specific measure of relative in-painting robustness to be used in cross-comparison grids based on these quality metrics. (One can incorporate other quality metrics in this relative measure.) The empirical work reported here is an initial step in a broader and deeper investigation of "filling the blank" neural networks' sensitivity, robustness and regularization with respect to hole "geometry" PDFs, and it suggests further research in this domain.
Estimation error analysis of deep learning on the regression problem on the variable exponent Besov space
Sep 27, 2020
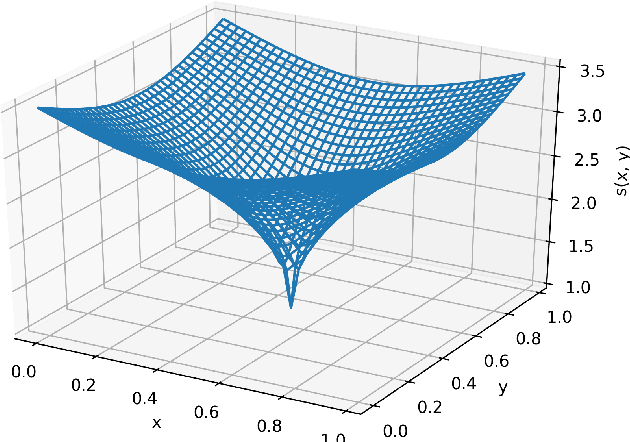
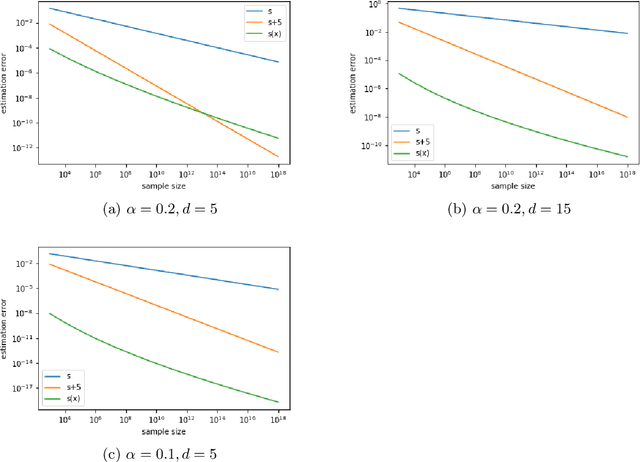
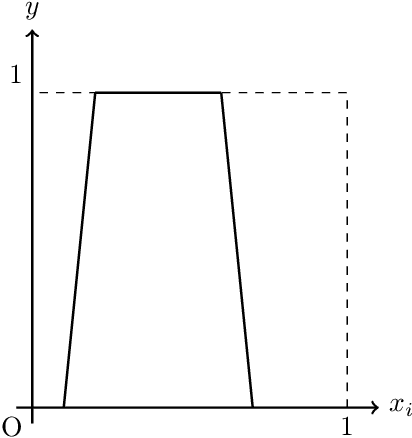
Deep learning has achieved notable success in various fields, including image and speech recognition. One of the factors in the successful performance of deep learning is its high feature extraction ability. In this study, we focus on the adaptivity of deep learning; consequently, we treat the variable exponent Besov space, which has a different smoothness depending on the input location $x$. In other words, the difficulty of the estimation is not uniform within the domain. We analyze the general approximation error of the variable exponent Besov space and the approximation and estimation errors of deep learning. We note that the improvement based on adaptivity is remarkable when the region upon which the target function has less smoothness is small and the dimension is large. Moreover, the superiority to linear estimators is shown with respect to the convergence rate of the estimation error.
Self-Supervised 3D Human Pose Estimation via Part Guided Novel Image Synthesis
Apr 09, 2020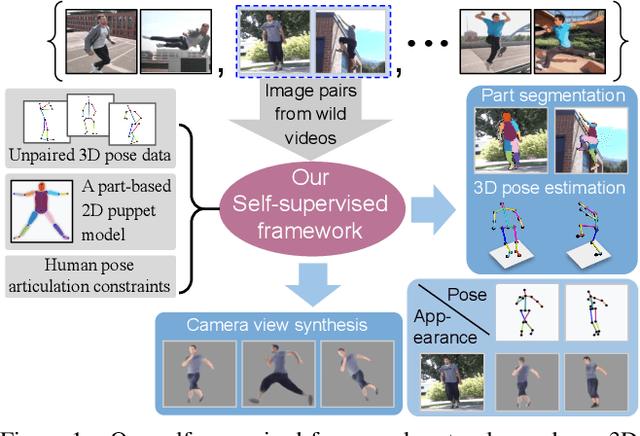
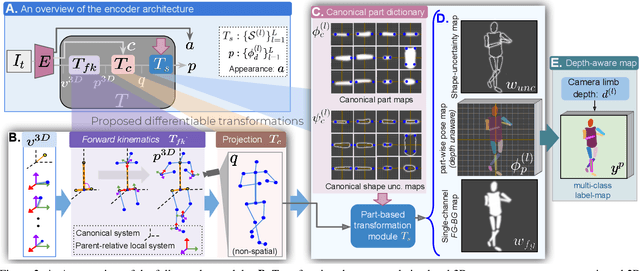
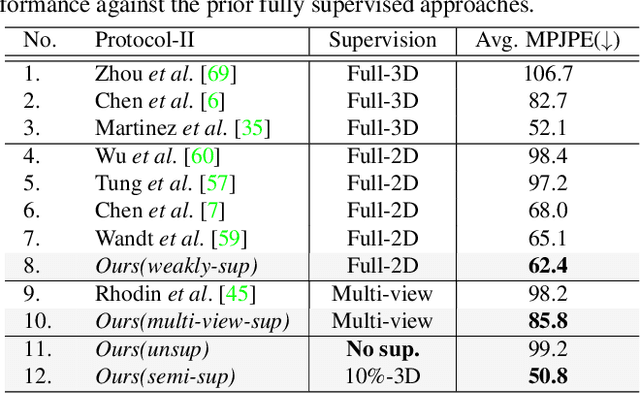
Camera captured human pose is an outcome of several sources of variation. Performance of supervised 3D pose estimation approaches comes at the cost of dispensing with variations, such as shape and appearance, that may be useful for solving other related tasks. As a result, the learned model not only inculcates task-bias but also dataset-bias because of its strong reliance on the annotated samples, which also holds true for weakly-supervised models. Acknowledging this, we propose a self-supervised learning framework to disentangle such variations from unlabeled video frames. We leverage the prior knowledge on human skeleton and poses in the form of a single part-based 2D puppet model, human pose articulation constraints, and a set of unpaired 3D poses. Our differentiable formalization, bridging the representation gap between the 3D pose and spatial part maps, not only facilitates discovery of interpretable pose disentanglement but also allows us to operate on videos with diverse camera movements. Qualitative results on unseen in-the-wild datasets establish our superior generalization across multiple tasks beyond the primary tasks of 3D pose estimation and part segmentation. Furthermore, we demonstrate state-of-the-art weakly-supervised 3D pose estimation performance on both Human3.6M and MPI-INF-3DHP datasets.
Surface Agnostic Metrics for Cortical Volume Segmentation and Regression
Oct 04, 2020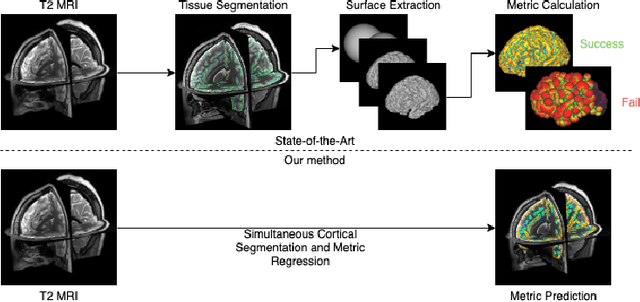
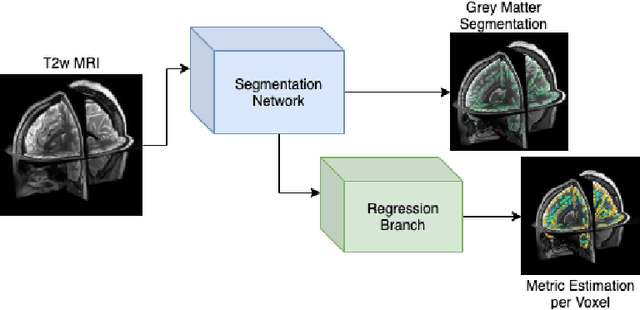
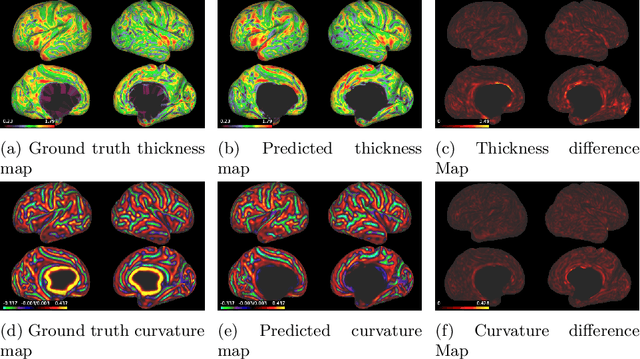
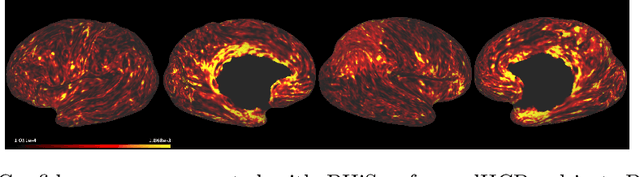
The cerebral cortex performs higher-order brain functions and is thus implicated in a range of cognitive disorders. Current analysis of cortical variation is typically performed by fitting surface mesh models to inner and outer cortical boundaries and investigating metrics such as surface area and cortical curvature or thickness. These, however, take a long time to run, and are sensitive to motion and image and surface resolution, which can prohibit their use in clinical settings. In this paper, we instead propose a machine learning solution, training a novel architecture to predict cortical thickness and curvature metrics from T2 MRI images, while additionally returning metrics of prediction uncertainty. Our proposed model is tested on a clinical cohort (Down Syndrome) for which surface-based modelling often fails. Results suggest that deep convolutional neural networks are a viable option to predict cortical metrics across a range of brain development stages and pathologies.
DPD-InfoGAN: Differentially Private Distributed InfoGAN
Oct 24, 2020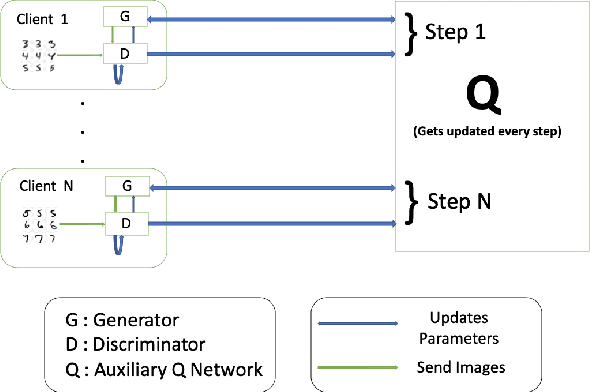
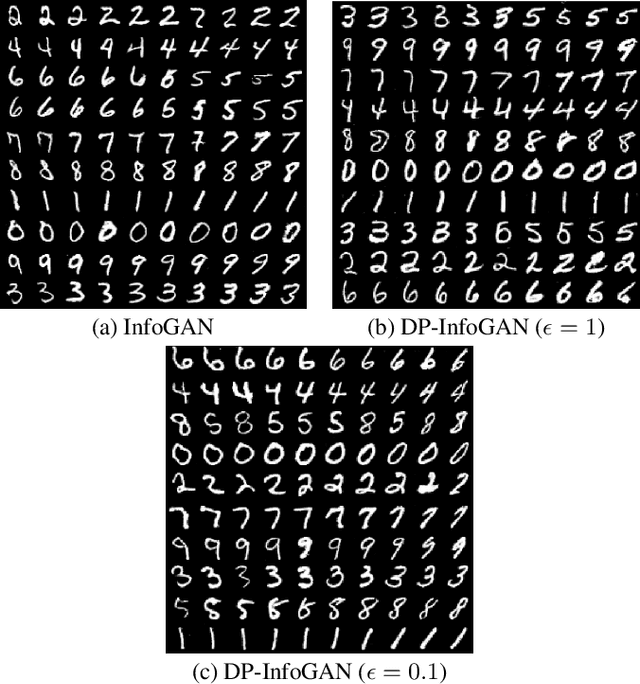


Generative Adversarial Networks (GANs) are deep learning architectures capable of generating synthetic datasets. Despite producing high-quality synthetic images, the default GAN has no control over the kinds of images it generates. The Information Maximizing GAN (InfoGAN) is a variant of the default GAN that introduces feature-control variables that are automatically learned by the framework, hence providing greater control over the different kinds of images produced. Due to the high model complexity of InfoGAN, the generative distribution tends to be concentrated around the training data points. This is a critical problem as the models may inadvertently expose the sensitive and private information present in the dataset. To address this problem, we propose a differentially private version of InfoGAN (DP-InfoGAN). We also extend our framework to a distributed setting (DPD-InfoGAN) to allow clients to learn different attributes present in other clients' datasets in a privacy-preserving manner. In our experiments, we show that both DP-InfoGAN and DPD-InfoGAN can synthesize high-quality images with flexible control over image attributes while preserving privacy.
VINNAS: Variational Inference-based Neural Network Architecture Search
Jul 12, 2020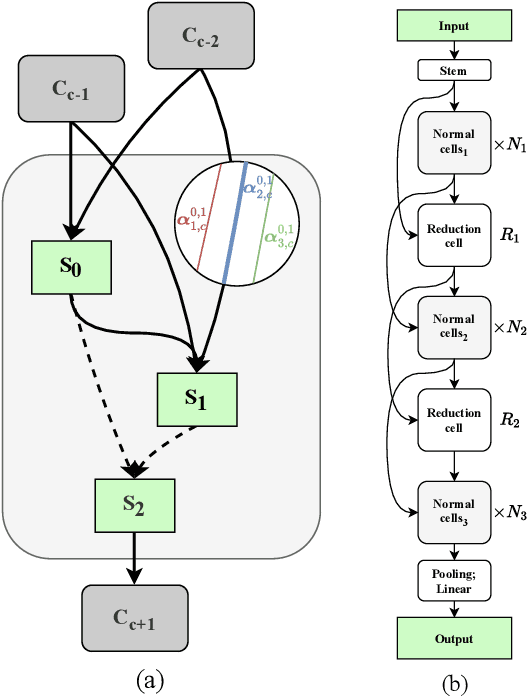
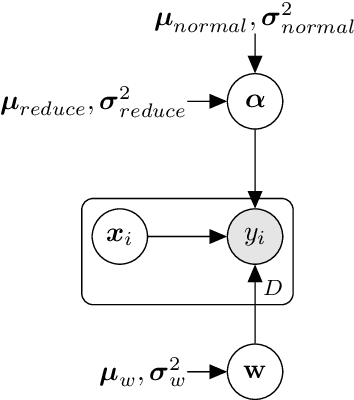
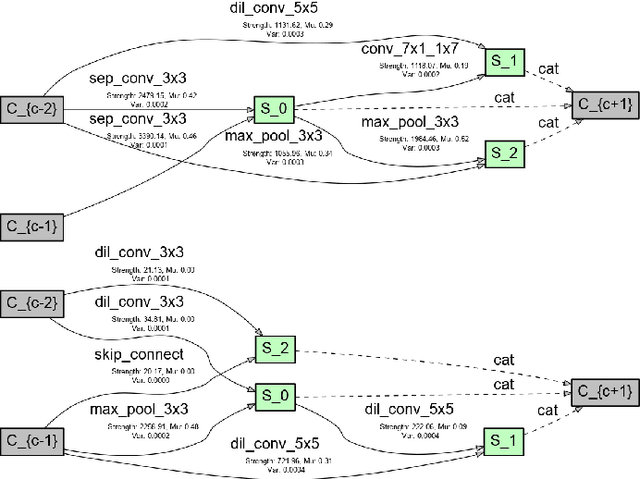
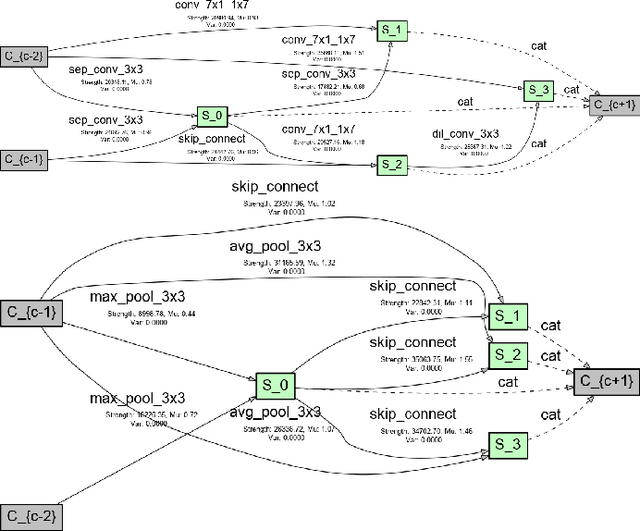
In recent years, neural architecture search (NAS) has received intensive scientific and industrial interest due to its capability of finding a neural architecture with high accuracy for various artificial intelligence tasks such as image classification or object detection. In particular, gradient-based NAS approaches have become one of the more popular approaches thanks to their computational efficiency during the search. However, these methods often experience a mode collapse, where the quality of the found architectures is poor due to the algorithm resorting to choosing a single operation type for the entire network, or stagnating at a local minima for various datasets or search spaces. To address these defects, we present a differentiable variational inference-based NAS method for searching sparse convolutional neural networks. Our approach finds the optimal neural architecture by dropping out candidate operations in an over-parameterised supergraph using variational dropout with automatic relevance determination prior, which makes the algorithm gradually remove unnecessary operations and connections without risking mode collapse. The evaluation is conducted through searching two types of convolutional cells that shape the neural network for classifying different image datasets. Our method finds diverse network cells, while showing state-of-the-art accuracy with up to $3 \times$ fewer parameters.
Hierarchical Context Embedding for Region-based Object Detection
Aug 04, 2020
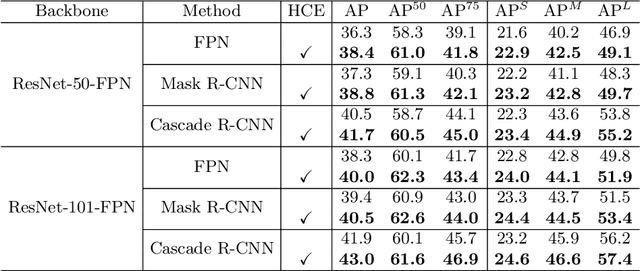
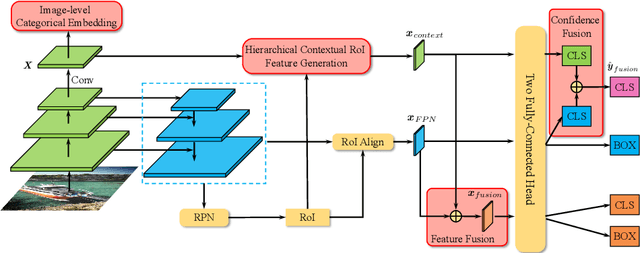
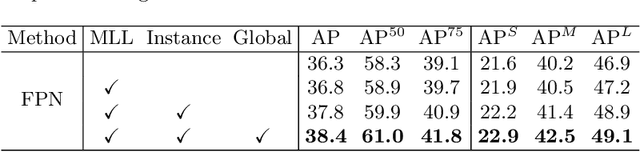
State-of-the-art two-stage object detectors apply a classifier to a sparse set of object proposals, relying on region-wise features extracted by RoIPool or RoIAlign as inputs. The region-wise features, in spite of aligning well with the proposal locations, may still lack the crucial context information which is necessary for filtering out noisy background detections, as well as recognizing objects possessing no distinctive appearances. To address this issue, we present a simple but effective Hierarchical Context Embedding (HCE) framework, which can be applied as a plug-and-play component, to facilitate the classification ability of a series of region-based detectors by mining contextual cues. Specifically, to advance the recognition of context-dependent object categories, we propose an image-level categorical embedding module which leverages the holistic image-level context to learn object-level concepts. Then, novel RoI features are generated by exploiting hierarchically embedded context information beneath both whole images and interested regions, which are also complementary to conventional RoI features. Moreover, to make full use of our hierarchical contextual RoI features, we propose the early-and-late fusion strategies (i.e., feature fusion and confidence fusion), which can be combined to boost the classification accuracy of region-based detectors. Comprehensive experiments demonstrate that our HCE framework is flexible and generalizable, leading to significant and consistent improvements upon various region-based detectors, including FPN, Cascade R-CNN and Mask R-CNN.