 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Estimation, Confidence Intervals, and Large-Scale Hypotheses Testing for High-Dimensional Mixed Linear Regression
Nov 06, 2020
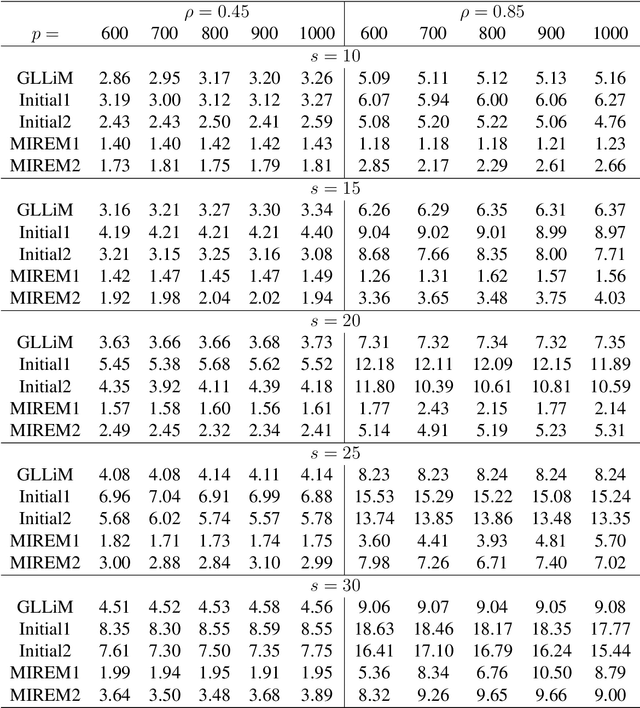
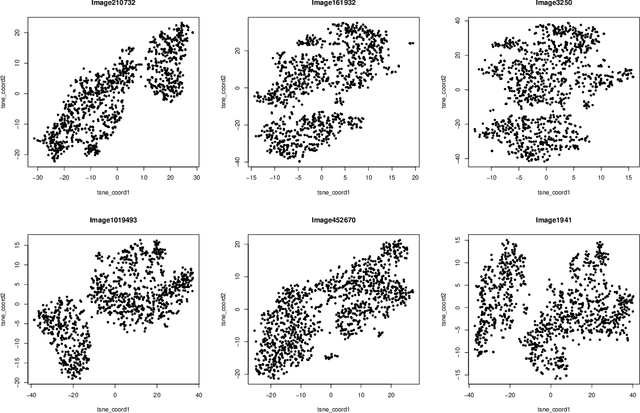
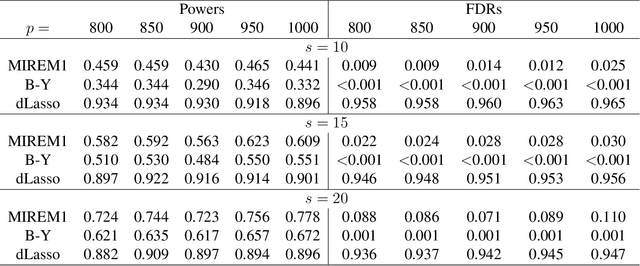
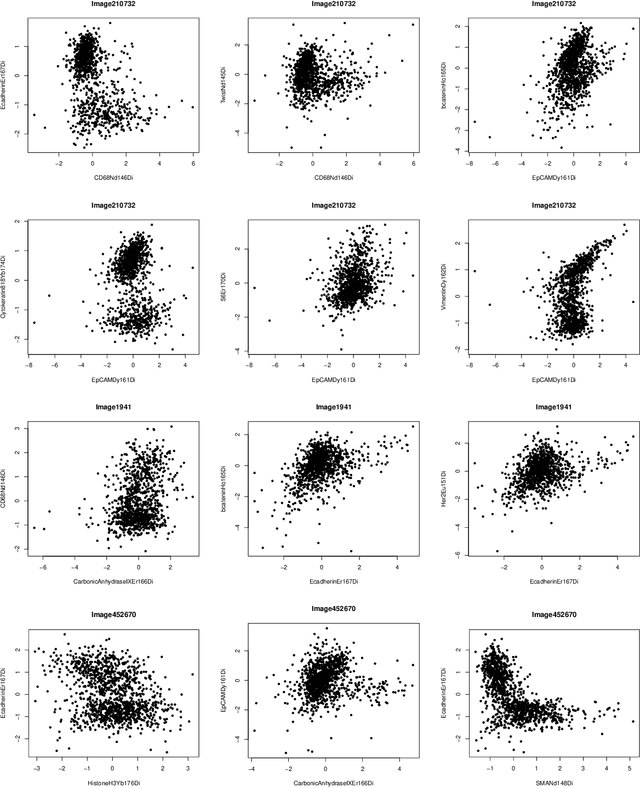
This paper studies the high-dimensional mixed linear regression (MLR) where the output variable comes from one of the two linear regression models with an unknown mixing proportion and an unknown covariance structure of the random covariates. Building upon a high-dimensional EM algorithm, we propose an iterative procedure for estimating the two regression vectors and establish their rates of convergence. Based on the iterative estimators, we further construct debiased estimators and establish their asymptotic normality. For individual coordinates, confidence intervals centered at the debiased estimators are constructed. Furthermore, a large-scale multiple testing procedure is proposed for testing the regression coefficients and is shown to control the false discovery rate (FDR) asymptotically. Simulation studies are carried out to examine the numerical performance of the proposed methods and their superiority over existing methods. The proposed methods are further illustrated through an analysis of a dataset of multiplex image cytometry, which investigates the interaction networks among the cellular phenotypes that include the expression levels of 20 epitopes or combinations of markers.
Privacy Preserving Visual SLAM
Jul 27, 2020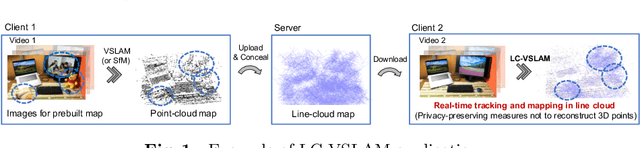

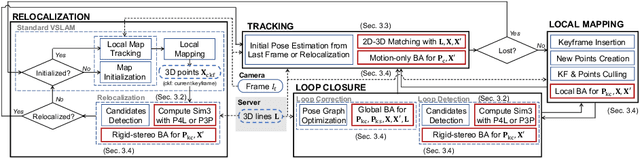

This study proposes a privacy-preserving Visual SLAM framework for estimating camera poses and performing bundle adjustment with mixed line and point clouds in real time. Previous studies have proposed localization methods to estimate a camera pose using a line-cloud map for a single image or a reconstructed point cloud. These methods offer a scene privacy protection against the inversion attacks by converting a point cloud to a line cloud, which reconstruct the scene images from the point cloud. However, they are not directly applicable to a video sequence because they do not address computational efficiency. This is a critical issue to solve for estimating camera poses and performing bundle adjustment with mixed line and point clouds in real time. Moreover, there has been no study on a method to optimize a line-cloud map of a server with a point cloud reconstructed from a client video because any observation points on the image coordinates are not available to prevent the inversion attacks, namely the reversibility of the 3D lines. The experimental results with synthetic and real data show that our Visual SLAM framework achieves the intended privacy-preserving formation and real-time performance using a line-cloud map.
TRLG: Fragile blind quad watermarking for image tamper detection and recovery by providing compact digests with quality optimized using LWT and GA
Mar 07, 2018
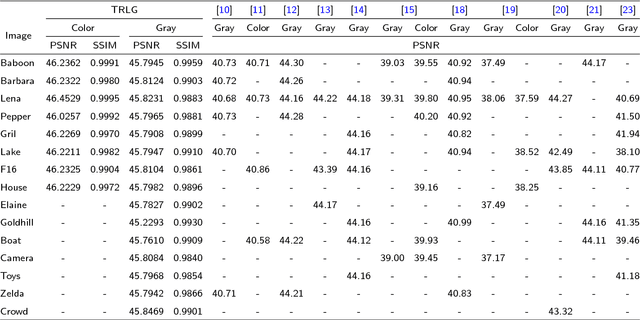
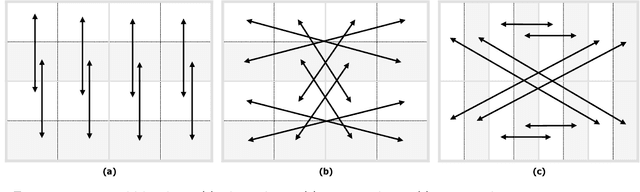
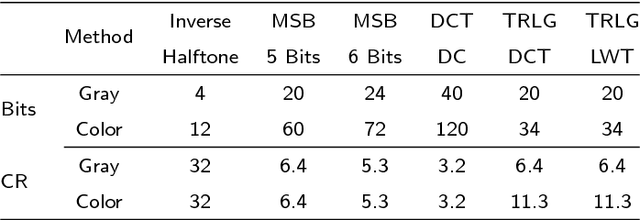
In this paper, an efficient fragile blind quad watermarking scheme for image tamper detection and recovery based on lifting wavelet transform and genetic algorithm is proposed. TRLG generates four compact digests with super quality based on lifting wavelet transform and halftoning technique by distinguishing the types of image blocks. In other words, for each 2*2 non-overlap blocks, four chances for recovering destroyed blocks are considered. A special parameter estimation technique based on genetic algorithm is performed to improve and optimize the quality of digests and watermarked image. Furthermore, CCS map is used to determine the mapping block for embedding information, encrypting and confusing the embedded information. In order to improve the recovery rate, Mirror-aside and Partner-block are proposed. The experiments that have been conducted to evaluate the performance of TRLG proved the superiority in terms of quality of the watermarked and recovered image, tamper localization and security compared with state-of-the-art methods. The results indicate that the PSNR and SSIM of the watermarked image are about 46 dB and approximately one, respectively. Also, the mean of PSNR and SSIM of several recovered images which has been destroyed about 90% is reached to 24 dB and 0.86, respectively.
Flickr30k Entities: Collecting Region-to-Phrase Correspondences for Richer Image-to-Sentence Models
Sep 19, 2016
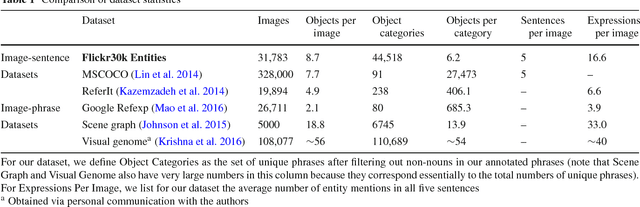
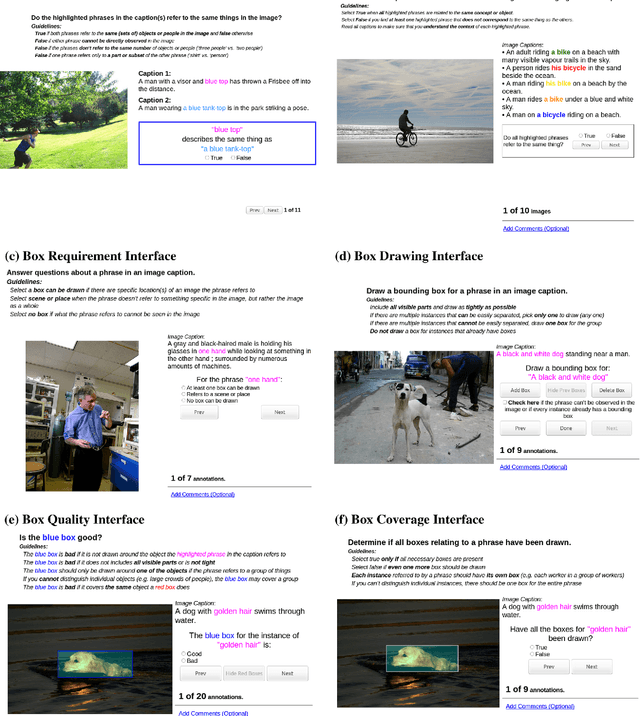

The Flickr30k dataset has become a standard benchmark for sentence-based image description. This paper presents Flickr30k Entities, which augments the 158k captions from Flickr30k with 244k coreference chains, linking mentions of the same entities across different captions for the same image, and associating them with 276k manually annotated bounding boxes. Such annotations are essential for continued progress in automatic image description and grounded language understanding. They enable us to define a new benchmark for localization of textual entity mentions in an image. We present a strong baseline for this task that combines an image-text embedding, detectors for common objects, a color classifier, and a bias towards selecting larger objects. While our baseline rivals in accuracy more complex state-of-the-art models, we show that its gains cannot be easily parlayed into improvements on such tasks as image-sentence retrieval, thus underlining the limitations of current methods and the need for further research.
A Deep Learning-Based Method for Automatic Segmentation of Proximal Femur from Quantitative Computed Tomography Images
Jul 01, 2020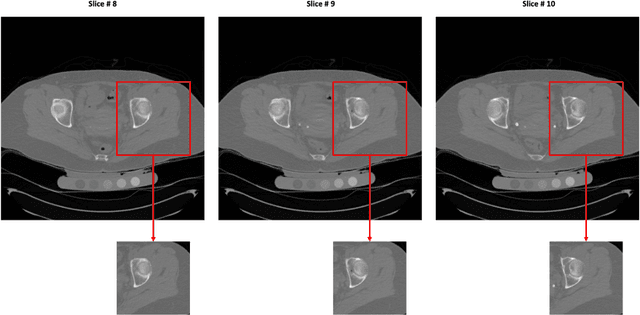
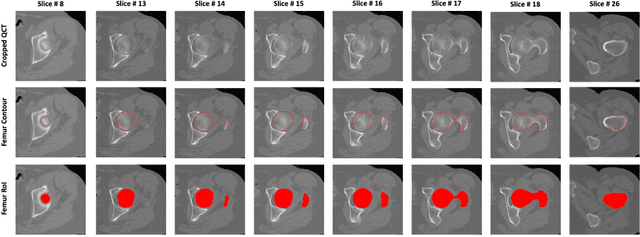

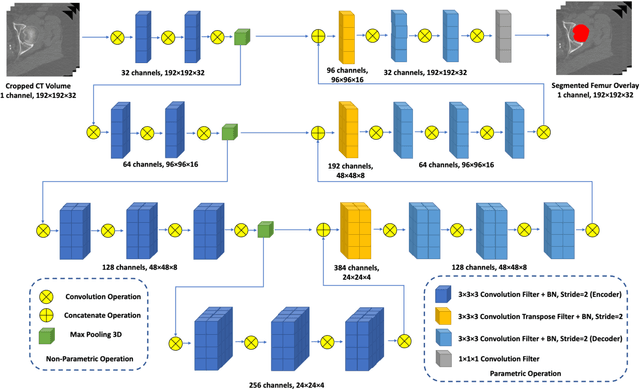
Purpose: Proximal femur image analyses based on quantitative computed tomography (QCT) provide a method to quantify the bone density and evaluate osteoporosis and risk of fracture. We aim to develop a deep-learning-based method for automatic proximal femur segmentation. Methods and Materials: We developed a 3D image segmentation method based on V-Net, an end-to-end fully convolutional neural network (CNN), to extract the proximal femur QCT images automatically. The proposed V-net methodology adopts a compound loss function, which includes a Dice loss and a L2 regularizer. We performed experiments to evaluate the effectiveness of the proposed segmentation method. In the experiments, a QCT dataset which included 397 QCT subjects was used. For the QCT image of each subject, the ground truth for the proximal femur was delineated by a well-trained scientist. During the experiments for the entire cohort then for male and female subjects separately, 90% of the subjects were used in 10-fold cross-validation for training and internal validation, and to select the optimal parameters of the proposed models; the rest of the subjects were used to evaluate the performance of models. Results: Visual comparison demonstrated high agreement between the model prediction and ground truth contours of the proximal femur portion of the QCT images. In the entire cohort, the proposed model achieved a Dice score of 0.9815, a sensitivity of 0.9852 and a specificity of 0.9992. In addition, an R2 score of 0.9956 (p<0.001) was obtained when comparing the volumes measured by our model prediction with the ground truth. Conclusion: This method shows a great promise for clinical application to QCT and QCT-based finite element analysis of the proximal femur for evaluating osteoporosis and hip fracture risk.
DeepNAG: Deep Non-Adversarial Gesture Generation
Nov 18, 2020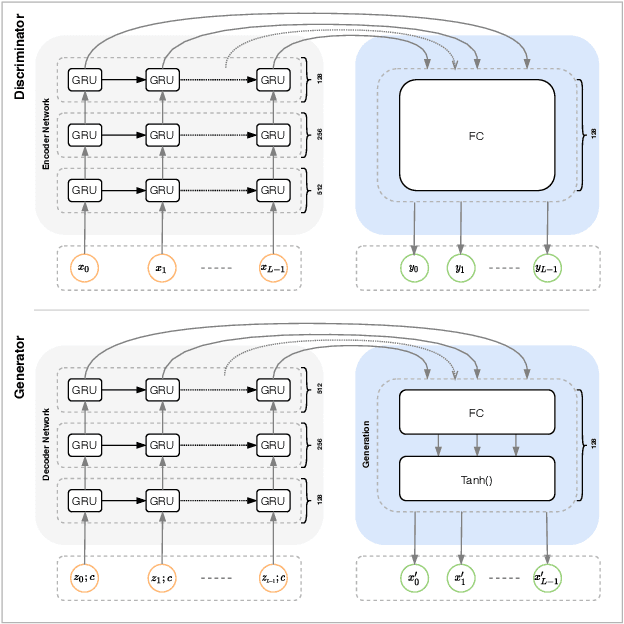
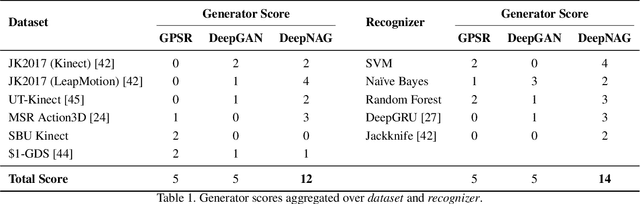
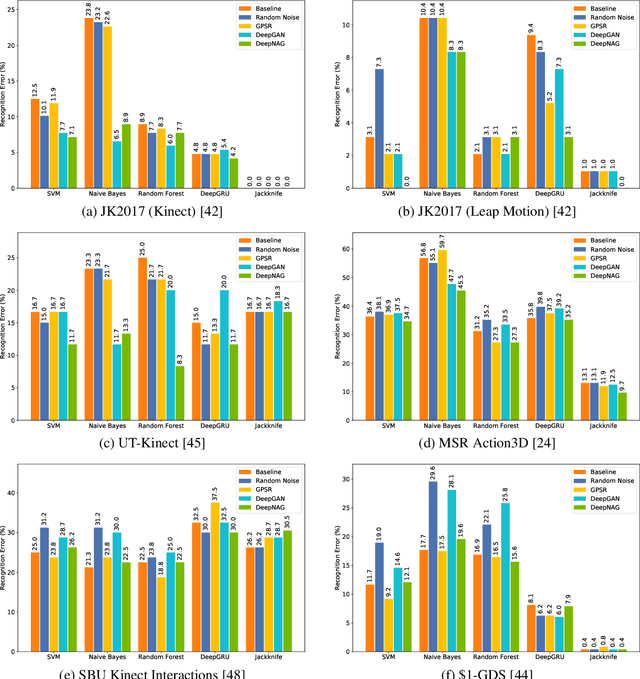

Synthetic data generation to improve classification performance (data augmentation) is a well-studied problem. Recently, generative adversarial networks (GAN) have shown superior image data augmentation performance, but their suitability in gesture synthesis has received inadequate attention. Further, GANs prohibitively require simultaneous generator and discriminator network training. We tackle both issues in this work. We first discuss a novel, device-agnostic GAN model for gesture synthesis called DeepGAN. Thereafter, we formulate DeepNAG by introducing a new differentiable loss function based on dynamic time warping and the average Hausdorff distance, which allows us to train DeepGAN's generator without requiring a discriminator. Through evaluations, we compare the utility of DeepGAN and DeepNAG against two alternative techniques for training five recognizers using data augmentation over six datasets. We further investigate the perceived quality of synthesized samples via an Amazon Mechanical Turk user study based on the HYPE benchmark. We find that DeepNAG outperforms DeepGAN in accuracy, training time (up to 17x faster), and realism, thereby opening the door to a new line of research in generator network design and training for gesture synthesis. Our source code is available at https://www.deepnag.com.
Tackling the Problem of Limited Data and Annotations in Semantic Segmentation
Jul 14, 2020
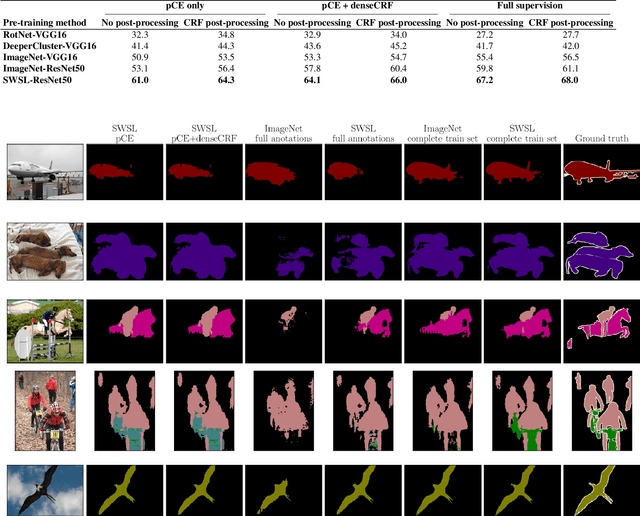

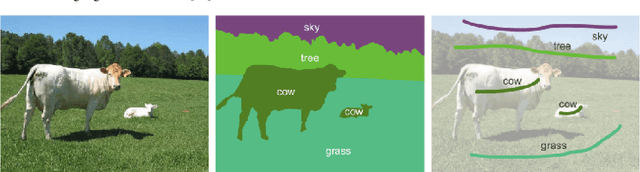
In this work, the case of semantic segmentation on a small image dataset (simulated by 1000 randomly selected images from PASCAL VOC 2012), where only weak supervision signals (scribbles from user interaction) are available is studied. Especially, to tackle the problem of limited data annotations in image segmentation, transferring different pre-trained models and CRF based methods are applied to enhance the segmentation performance. To this end, RotNet, DeeperCluster, and Semi&Weakly Supervised Learning (SWSL) pre-trained models are transferred and finetuned in a DeepLab-v2 baseline, and dense CRF is applied both as a post-processing and loss regularization technique. The results of my study show that, on this small dataset, using a pre-trained ResNet50 SWSL model gives results that are 7.4% better than applying an ImageNet pre-trained model; moreover, for the case of training on the full PASCAL VOC 2012 training data, this pre-training approach increases the mIoU results by almost 4%. On the other hand, dense CRF is shown to be very effective as well, enhancing the results both as a loss regularization technique in weakly supervised training and as a post-processing tool.
Class-agnostic Object Detection
Nov 28, 2020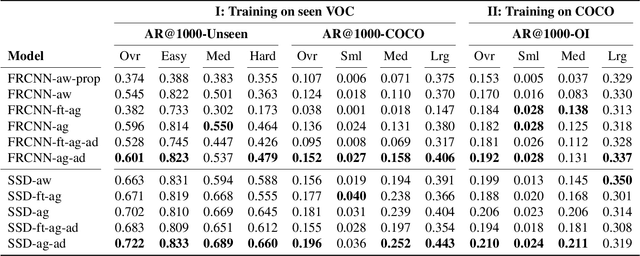
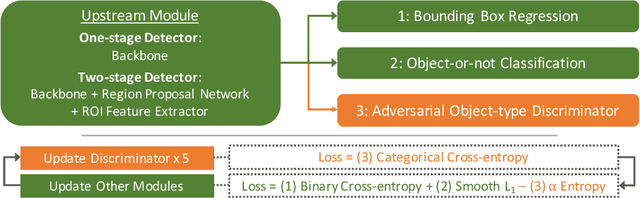
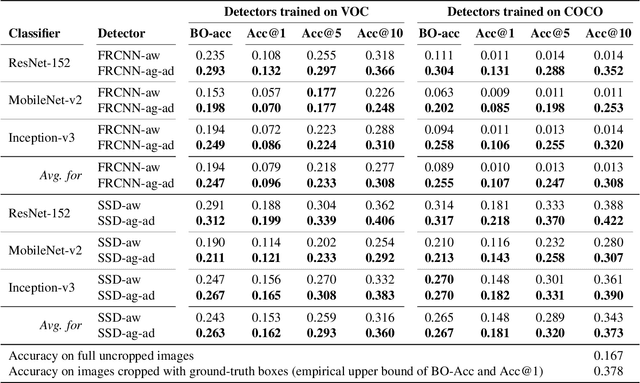
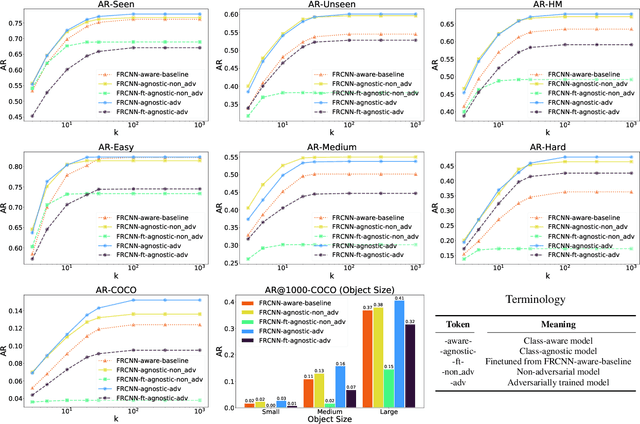
Object detection models perform well at localizing and classifying objects that they are shown during training. However, due to the difficulty and cost associated with creating and annotating detection datasets, trained models detect a limited number of object types with unknown objects treated as background content. This hinders the adoption of conventional detectors in real-world applications like large-scale object matching, visual grounding, visual relation prediction, obstacle detection (where it is more important to determine the presence and location of objects than to find specific types), etc. We propose class-agnostic object detection as a new problem that focuses on detecting objects irrespective of their object-classes. Specifically, the goal is to predict bounding boxes for all objects in an image but not their object-classes. The predicted boxes can then be consumed by another system to perform application-specific classification, retrieval, etc. We propose training and evaluation protocols for benchmarking class-agnostic detectors to advance future research in this domain. Finally, we propose (1) baseline methods and (2) a new adversarial learning framework for class-agnostic detection that forces the model to exclude class-specific information from features used for predictions. Experimental results show that adversarial learning improves class-agnostic detection efficacy.
CAD2RL: Real Single-Image Flight without a Single Real Image
Jun 08, 2017
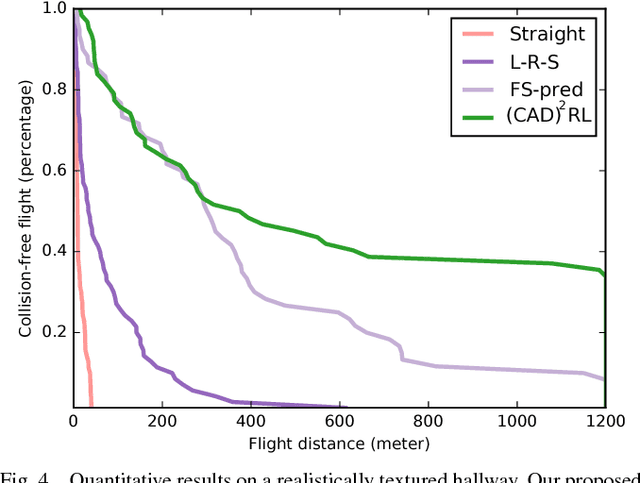

Deep reinforcement learning has emerged as a promising and powerful technique for automatically acquiring control policies that can process raw sensory inputs, such as images, and perform complex behaviors. However, extending deep RL to real-world robotic tasks has proven challenging, particularly in safety-critical domains such as autonomous flight, where a trial-and-error learning process is often impractical. In this paper, we explore the following question: can we train vision-based navigation policies entirely in simulation, and then transfer them into the real world to achieve real-world flight without a single real training image? We propose a learning method that we call CAD$^2$RL, which can be used to perform collision-free indoor flight in the real world while being trained entirely on 3D CAD models. Our method uses single RGB images from a monocular camera, without needing to explicitly reconstruct the 3D geometry of the environment or perform explicit motion planning. Our learned collision avoidance policy is represented by a deep convolutional neural network that directly processes raw monocular images and outputs velocity commands. This policy is trained entirely on simulated images, with a Monte Carlo policy evaluation algorithm that directly optimizes the network's ability to produce collision-free flight. By highly randomizing the rendering settings for our simulated training set, we show that we can train a policy that generalizes to the real world, without requiring the simulator to be particularly realistic or high-fidelity. We evaluate our method by flying a real quadrotor through indoor environments, and further evaluate the design choices in our simulator through a series of ablation studies on depth prediction. For supplementary video see: https://youtu.be/nXBWmzFrj5s
A Unified Plug-and-Play Framework for Effective Data Denoising and Robust Abstention
Sep 25, 2020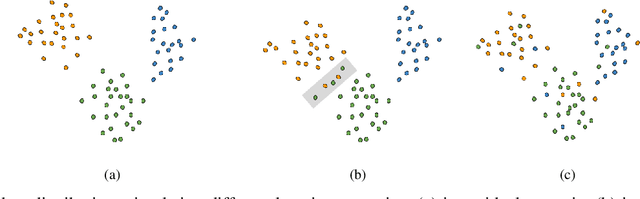
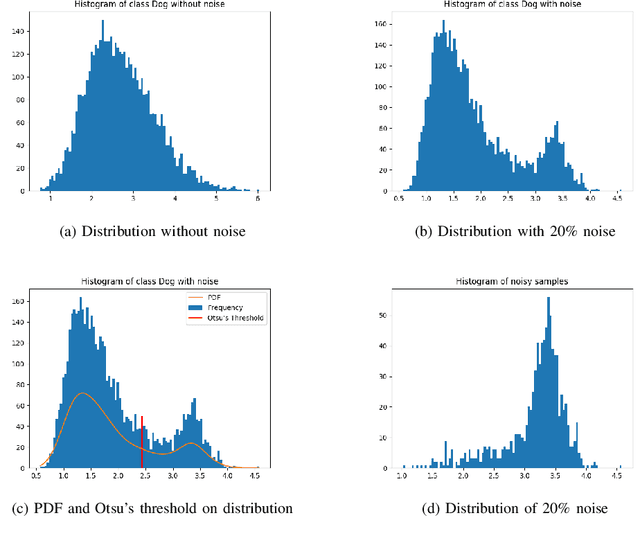
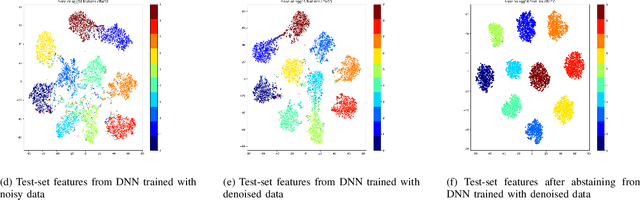

The success of Deep Neural Networks (DNNs) highly depends on data quality. Moreover, predictive uncertainty makes high performing DNNs risky for real-world deployment. In this paper, we aim to address these two issues by proposing a unified filtering framework leveraging underlying data density, that can effectively denoise training data as well as avoid predicting uncertain test data points. Our proposed framework leverages underlying data distribution to differentiate between noise and clean data samples without requiring any modification to existing DNN architectures or loss functions. Extensive experiments on multiple image classification datasets and multiple CNN architectures demonstrate that our simple yet effective framework can outperform the state-of-the-art techniques in denoising training data and abstaining uncertain test data.