 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cosine meets Softmax: A tough-to-beat baseline for visual grounding
Sep 13, 2020

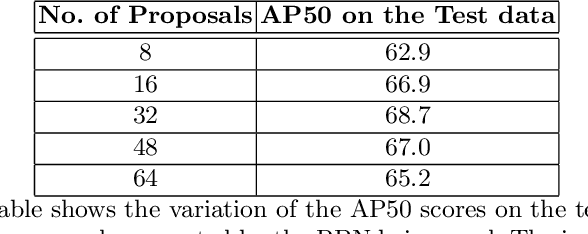

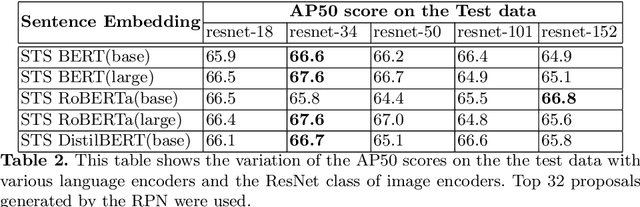
In this paper, we present a simple baseline for visual grounding for autonomous driving which outperforms the state of the art methods, while retaining minimal design choices. Our framework minimizes the cross-entropy loss over the cosine distance between multiple image ROI features with a text embedding (representing the give sentence/phrase). We use pre-trained networks for obtaining the initial embeddings and learn a transformation layer on top of the text embedding. We perform experiments on the Talk2Car dataset and achieve 68.7% AP50 accuracy, improving upon the previous state of the art by 8.6%. Our investigation suggests reconsideration towards more approaches employing sophisticated attention mechanisms or multi-stage reasoning or complex metric learning loss functions by showing promise in simpler alternatives.
Linking Image and Text with 2-Way Nets
Feb 10, 2017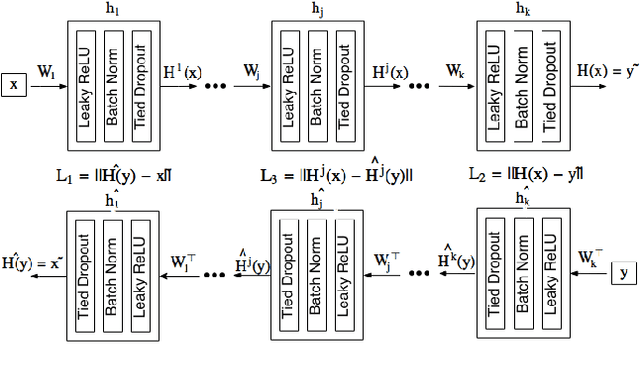
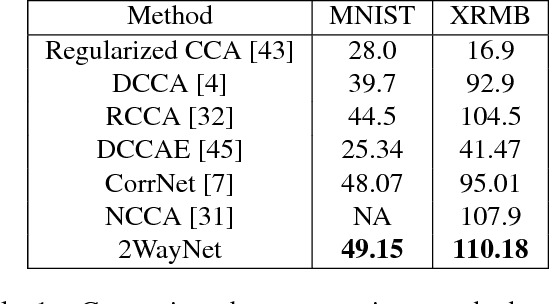
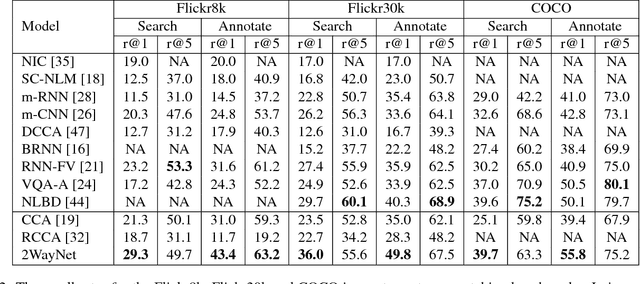
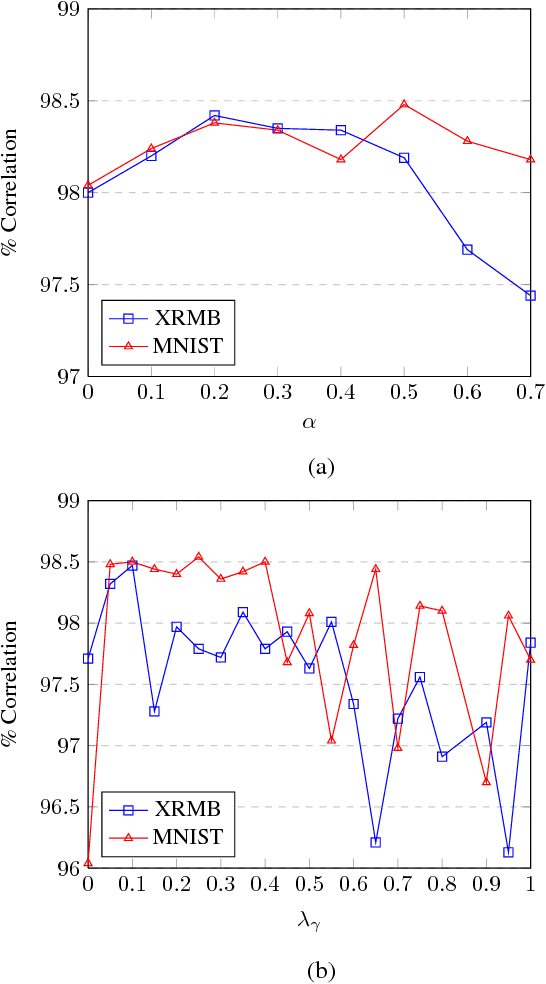
Linking two data sources is a basic building block in numerous computer vision problems. Canonical Correlation Analysis (CCA) achieves this by utilizing a linear optimizer in order to maximize the correlation between the two views. Recent work makes use of non-linear models, including deep learning techniques, that optimize the CCA loss in some feature space. In this paper, we introduce a novel, bi-directional neural network architecture for the task of matching vectors from two data sources. Our approach employs two tied neural network channels that project the two views into a common, maximally correlated space using the Euclidean loss. We show a direct link between the correlation-based loss and Euclidean loss, enabling the use of Euclidean loss for correlation maximization. To overcome common Euclidean regression optimization problems, we modify well-known techniques to our problem, including batch normalization and dropout. We show state of the art results on a number of computer vision matching tasks including MNIST image matching and sentence-image matching on the Flickr8k, Flickr30k and COCO datasets.
Oral-3D: Reconstructing the 3D Bone Structure of Oral Cavity from 2D Panoramic X-ray
Mar 18, 2020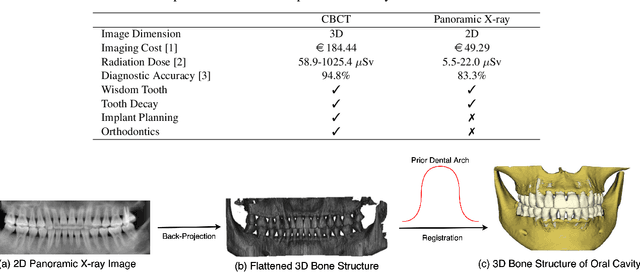

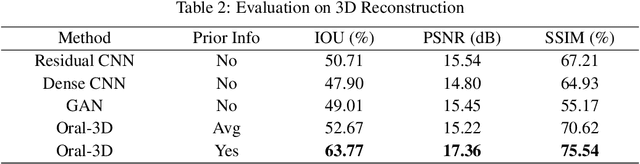
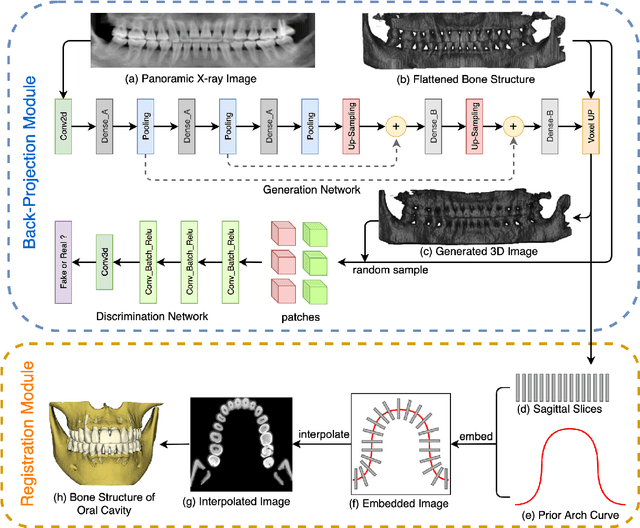
Panoramic X-ray and Cone Beam Computed Tomography (CBCT) are two of the most general imaging methods in digital dentistry. While CBCT can provide higher-dimension information, the panoramic X-ray has the advantages of lower radiation dose and cost. Consequently, generating 3D information of bony tissues from the X-ray that can reflect dental diseases is of great interest. This technique can be even more helpful for developing areas where the CBCT is not always available due to the lack of screening machines or high screening cost. In this paper, we present \textit{Oral-3D} to reconstruct the bone structure of oral cavity from a single panoramic X-ray image by taking advantage of some prior knowledge in oral structure, which conventionally can only be obtained by a 3D imaging method like CBCT. Specifically, we first train a generative network to back project the 2D X-ray image into 3D space, then restore the bone structure by registering the generated 3D image with the prior shape of the dental arch. To be noted, \textit{Oral-3D} can restore both the density of bony tissues and the curved mandible surface. Experimental results show that our framework can reconstruct the 3D structure with significantly high quality. To the best of our knowledge, this is the first work that explores 3D reconstruction from a 2D image in dental health.
Advances in deep learning methods for pavement surface crack detection and identification with visible light visual images
Dec 29, 2020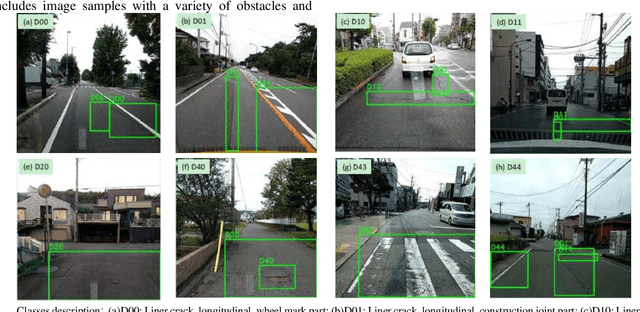
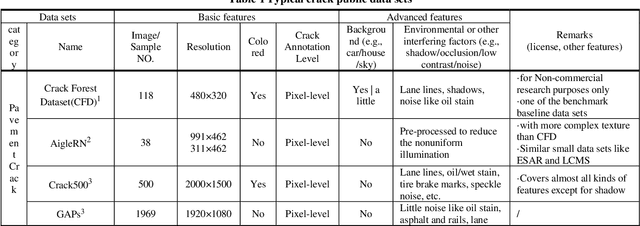


Compared to NDT and health monitoring method for cracks in engineering structures, surface crack detection or identification based on visible light images is non-contact, with the advantages of fast speed, low cost and high precision. Firstly, typical pavement (concrete also) crack public data sets were collected, and the characteristics of sample images as well as the random variable factors, including environmental, noise and interference etc., were summarized. Subsequently, the advantages and disadvantages of three main crack identification methods (i.e., hand-crafted feature engineering, machine learning, deep learning) were compared. Finally, from the aspects of model architecture, testing performance and predicting effectiveness, the development and progress of typical deep learning models, including self-built CNN, transfer learning(TL) and encoder-decoder(ED), which can be easily deployed on embedded platform, were reviewed. The benchmark test shows that: 1) It has been able to realize real-time pixel-level crack identification on embedded platform: the entire crack detection average time cost of an image sample is less than 100ms, either using the ED method (i.e., FPCNet) or the TL method based on InceptionV3. It can be reduced to less than 10ms with TL method based on MobileNet (a lightweight backbone base network). 2) In terms of accuracy, it can reach over 99.8% on CCIC which is easily identified by human eyes. On SDNET2018, some samples of which are difficult to be identified, FPCNet can reach 97.5%, while TL method is close to 96.1%. To the best of our knowledge, this paper for the first time comprehensively summarizes the pavement crack public data sets, and the performance and effectiveness of surface crack detection and identification deep learning methods for embedded platform, are reviewed and evaluated.
Systolic-CNN: An OpenCL-defined Scalable Run-time-flexible FPGA Accelerator Architecture for Accelerating Convolutional Neural Network Inference in Cloud/Edge Computing
Dec 06, 2020This paper presents Systolic-CNN, an OpenCL-defined scalable, run-time-flexible FPGA accelerator architecture, optimized for accelerating the inference of various convolutional neural networks (CNNs) in multi-tenancy cloud/edge computing. The existing OpenCL-defined FPGA accelerators for CNN inference are insufficient due to limited flexibility for supporting multiple CNN models at run time and poor scalability resulting in underutilized FPGA resources and limited computational parallelism. Systolic-CNN adopts a highly pipelined and paralleled 1-D systolic array architecture, which efficiently explores both spatial and temporal parallelism for accelerating CNN inference on FPGAs. Systolic-CNN is highly scalable and parameterized, which can be easily adapted by users to achieve up to 100% utilization of the coarse-grained computation resources (i.e., DSP blocks) for a given FPGA. Systolic-CNN is also run-time-flexible in the context of multi-tenancy cloud/edge computing, which can be time-shared to accelerate a variety of CNN models at run time without the need of recompiling the FPGA kernel hardware nor reprogramming the FPGA. The experiment results based on an Intel Arria/Stratix 10 GX FPGA Development board show that the optimized single-precision implementation of Systolic-CNN can achieve an average inference latency of 7ms/2ms, 84ms/33ms, 202ms/73ms, 1615ms/873ms, and 900ms/498ms per image for accelerating AlexNet, ResNet-50, ResNet-152, RetinaNet, and Light-weight RetinaNet, respectively. Codes are available at https://github.com/PSCLab-ASU/Systolic-CNN.
Unsupervised Object Detection with LiDAR Clues
Nov 27, 2020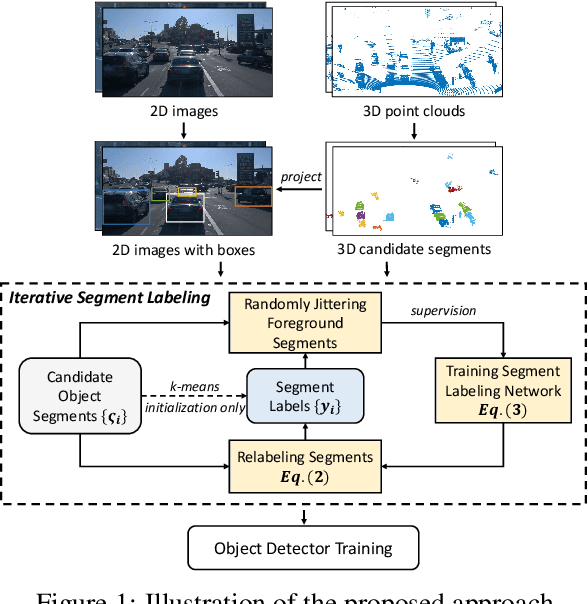



Despite the importance of unsupervised object detection, to the best of our knowledge, there is no previous work addressing this problem. One main issue, widely known to the community, is that object boundaries derived only from 2D image appearance are ambiguous and unreliable. To address this, we exploit LiDAR clues to aid unsupervised object detection. By exploiting the 3D scene structure, the issue of localization can be considerably mitigated. We further identify another major issue, seldom noticed by the community, that the long-tailed and open-ended (sub-)category distribution should be accommodated. In this paper, we present the first practical method for unsupervised object detection with the aid of LiDAR clues. In our approach, candidate object segments based on 3D point clouds are firstly generated. Then, an iterative segment labeling process is conducted to assign segment labels and to train a segment labeling network, which is based on features from both 2D images and 3D point clouds. The labeling process is carefully designed so as to mitigate the issue of long-tailed and open-ended distribution. The final segment labels are set as pseudo annotations for object detection network training. Extensive experiments on the large-scale Waymo Open dataset suggest that the derived unsupervised object detection method achieves reasonable accuracy compared with that of strong supervision within the LiDAR visible range. Code shall be released.
Fork or Fail: Cycle-Consistent Training with Many-to-One Mappings
Dec 14, 2020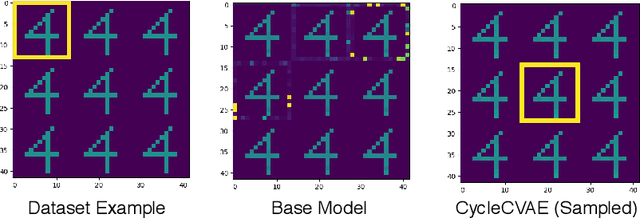
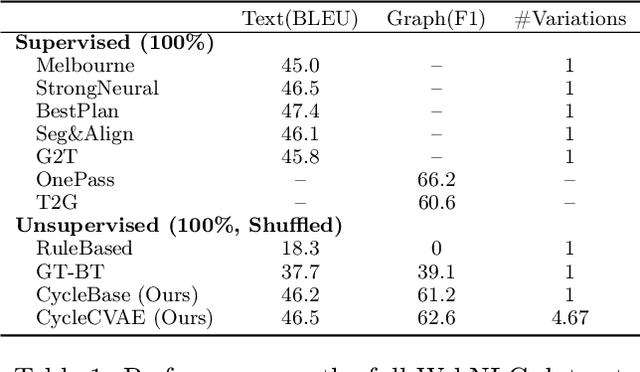
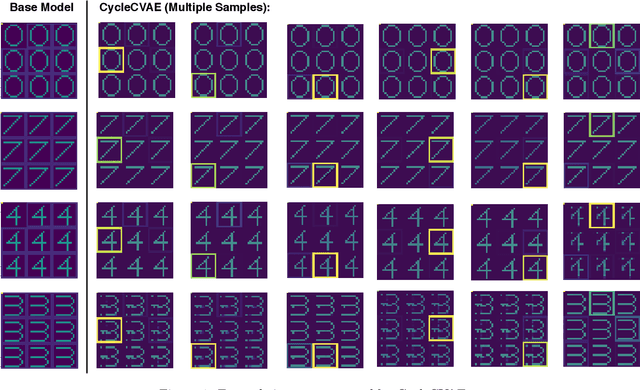
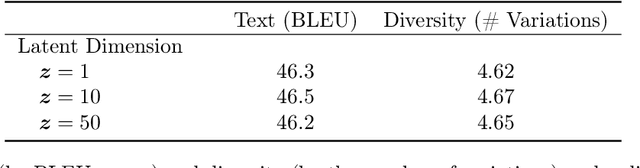
Cycle-consistent training is widely used for jointly learning a forward and inverse mapping between two domains of interest without the cumbersome requirement of collecting matched pairs within each domain. In this regard, the implicit assumption is that there exists (at least approximately) a ground-truth bijection such that a given input from either domain can be accurately reconstructed from successive application of the respective mappings. But in many applications no such bijection can be expected to exist and large reconstruction errors can compromise the success of cycle-consistent training. As one important instance of this limitation, we consider practically-relevant situations where there exists a many-to-one or surjective mapping between domains. To address this regime, we develop a conditional variational autoencoder (CVAE) approach that can be viewed as converting surjective mappings to implicit bijections whereby reconstruction errors in both directions can be minimized, and as a natural byproduct, realistic output diversity can be obtained in the one-to-many direction. As theoretical motivation, we analyze a simplified scenario whereby minima of the proposed CVAE-based energy function align with the recovery of ground-truth surjective mappings. On the empirical side, we consider a synthetic image dataset with known ground-truth, as well as a real-world application involving natural language generation from knowledge graphs and vice versa, a prototypical surjective case. For the latter, our CVAE pipeline can capture such many-to-one mappings during cycle training while promoting textural diversity for graph-to-text tasks. Our code is available at github.com/QipengGuo/CycleGT
Self-Supervised Variational Auto-Encoders
Oct 06, 2020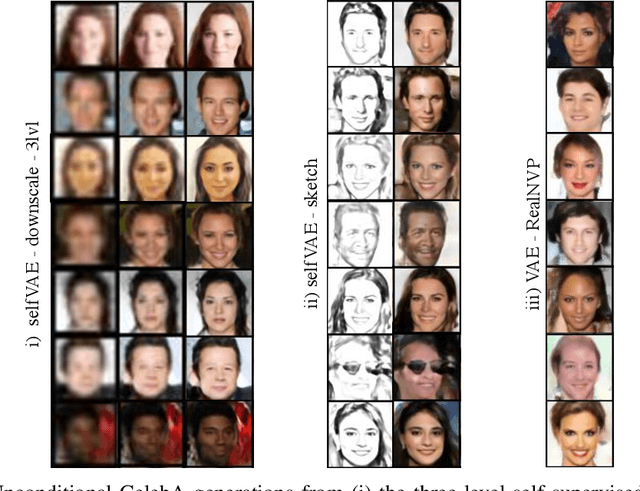
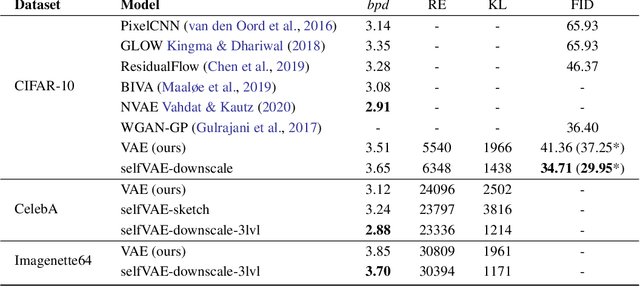
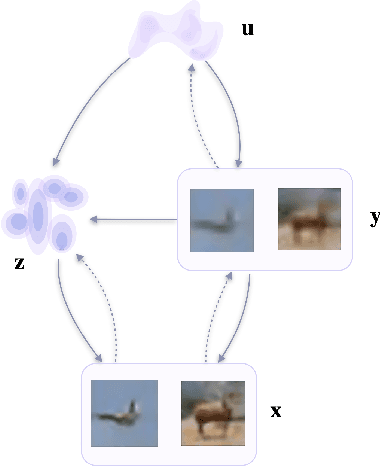

Density estimation, compression and data generation are crucial tasks in artificial intelligence. Variational Auto-Encoders (VAEs) constitute a single framework to achieve these goals. Here, we present a novel class of generative models, called self-supervised Variational Auto-Encoder (selfVAE), that utilizes deterministic and discrete variational posteriors. This class of models allows to perform both conditional and unconditional sampling, while simplifying the objective function. First, we use a single self-supervised transformation as a latent variable, where a transformation is either downscaling or edge detection. Next, we consider a hierarchical architecture, i.e., multiple transformations, and we show its benefits compared to the VAE. The flexibility of selfVAE in data reconstruction finds a particularly interesting use case in data compression tasks, where we can trade-off memory for better data quality, and vice-versa. We present performance of our approach on three benchmark image data (Cifar10, Imagenette64, and CelebA).
Disentangling 3D Prototypical Networks For Few-Shot Concept Learning
Nov 06, 2020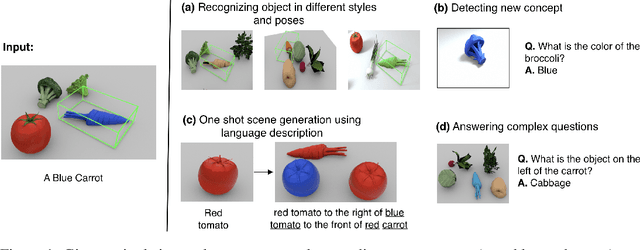
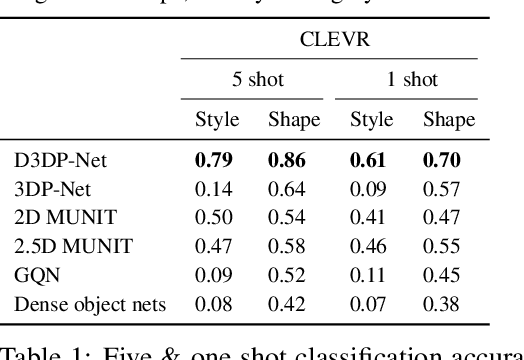
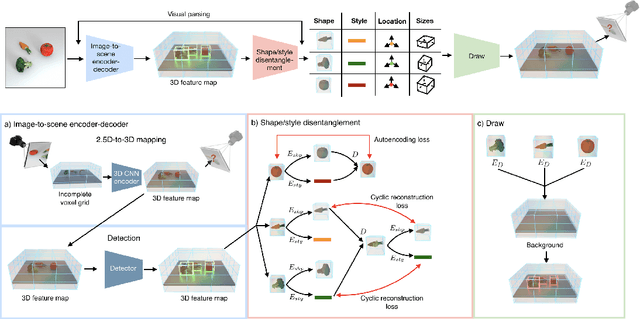
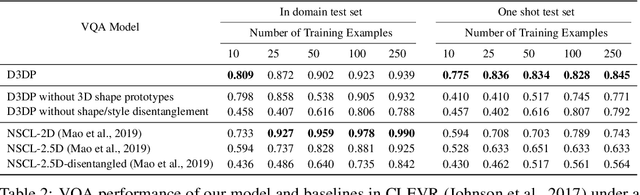
We present neural architectures that disentangle RGB-D images into objects' shapes and styles and a map of the background scene, and explore their applications for few-shot 3D object detection and few-shot concept classification. Our networks incorporate architectural biases that reflect the image formation process, 3D geometry of the world scene, and shape-style interplay. They are trained end-to-end self-supervised by predicting views in static scenes, alongside a small number of 3D object boxes. Objects and scenes are represented in terms of 3D feature grids in the bottleneck of the network. We show that the proposed 3D neural representations are compositional: they can generate novel 3D scene feature maps by mixing object shapes and styles, resizing and adding the resulting object 3D feature maps over background scene feature maps. We show that classifiers for object categories, color, materials, and spatial relationships trained over the disentangled 3D feature sub-spaces generalize better with dramatically fewer examples than the current state-of-the-art, and enable a visual question answering system that uses them as its modules to generalize one-shot to novel objects in the scene.
Self-Supervised 3D Human Pose Estimation via Part Guided Novel Image Synthesis
Apr 09, 2020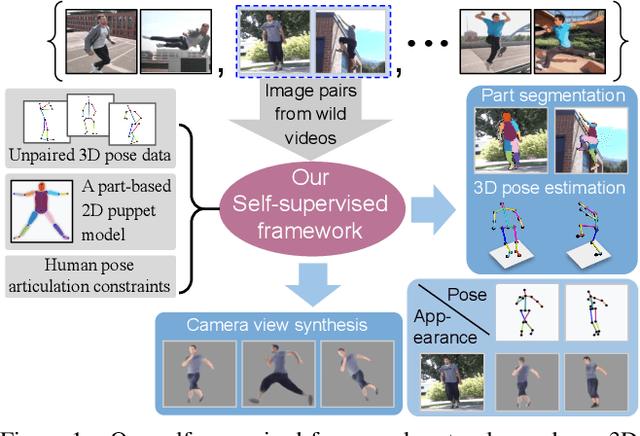
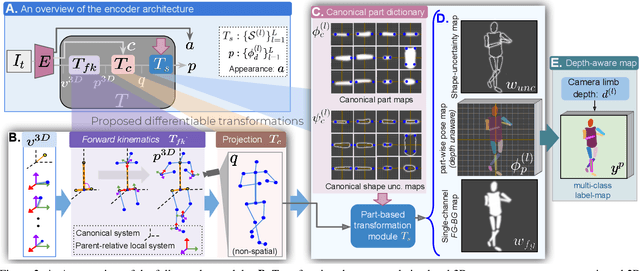
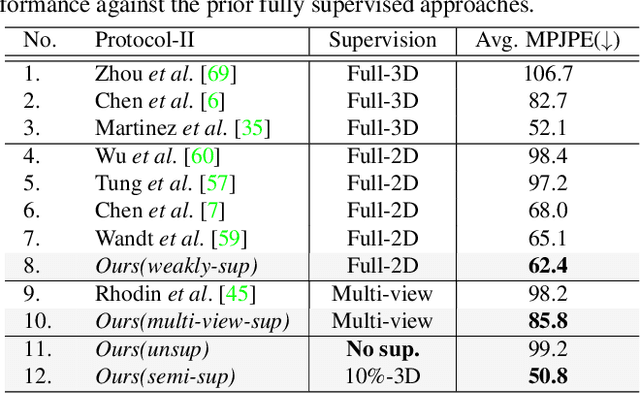
Camera captured human pose is an outcome of several sources of variation. Performance of supervised 3D pose estimation approaches comes at the cost of dispensing with variations, such as shape and appearance, that may be useful for solving other related tasks. As a result, the learned model not only inculcates task-bias but also dataset-bias because of its strong reliance on the annotated samples, which also holds true for weakly-supervised models. Acknowledging this, we propose a self-supervised learning framework to disentangle such variations from unlabeled video frames. We leverage the prior knowledge on human skeleton and poses in the form of a single part-based 2D puppet model, human pose articulation constraints, and a set of unpaired 3D poses. Our differentiable formalization, bridging the representation gap between the 3D pose and spatial part maps, not only facilitates discovery of interpretable pose disentanglement but also allows us to operate on videos with diverse camera movements. Qualitative results on unseen in-the-wild datasets establish our superior generalization across multiple tasks beyond the primary tasks of 3D pose estimation and part segmentation. Furthermore, we demonstrate state-of-the-art weakly-supervised 3D pose estimation performance on both Human3.6M and MPI-INF-3DHP datasets.