 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visually-Aware Fashion Recommendation and Design with Generative Image Models
Nov 07, 2017

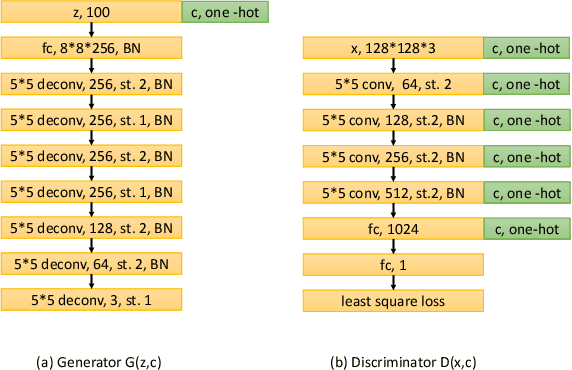

Building effective recommender systems for domains like fashion is challenging due to the high level of subjectivity and the semantic complexity of the features involved (i.e., fashion styles). Recent work has shown that approaches to `visual' recommendation (e.g.~clothing, art, etc.) can be made more accurate by incorporating visual signals directly into the recommendation objective, using `off-the-shelf' feature representations derived from deep networks. Here, we seek to extend this contribution by showing that recommendation performance can be significantly improved by learning `fashion aware' image representations directly, i.e., by training the image representation (from the pixel level) and the recommender system jointly; this contribution is related to recent work using Siamese CNNs, though we are able to show improvements over state-of-the-art recommendation techniques such as BPR and variants that make use of pre-trained visual features. Furthermore, we show that our model can be used \emph{generatively}, i.e., given a user and a product category, we can generate new images (i.e., clothing items) that are most consistent with their personal taste. This represents a first step towards building systems that go beyond recommending existing items from a product corpus, but which can be used to suggest styles and aid the design of new products.
CRNet: Cross-Reference Networks for Few-Shot Segmentation
Mar 24, 2020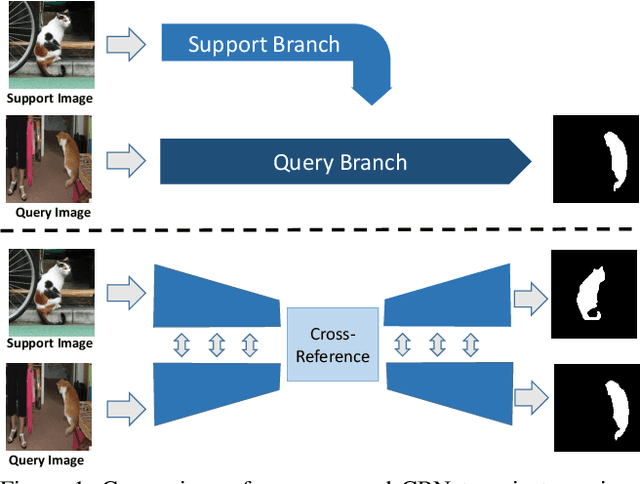

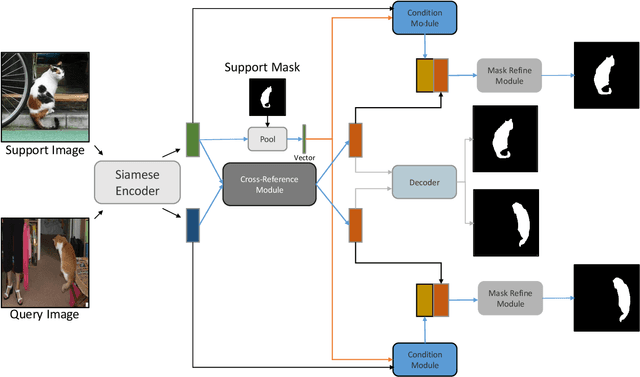

Over the past few years, state-of-the-art image segmentation algorithms are based on deep convolutional neural networks. To render a deep network with the ability to understand a concept, humans need to collect a large amount of pixel-level annotated data to train the models, which is time-consuming and tedious. Recently, few-shot segmentation is proposed to solve this problem. Few-shot segmentation aims to learn a segmentation model that can be generalized to novel classes with only a few training images. In this paper, we propose a cross-reference network (CRNet) for few-shot segmentation. Unlike previous works which only predict the mask in the query image, our proposed model concurrently make predictions for both the support image and the query image. With a cross-reference mechanism, our network can better find the co-occurrent objects in the two images, thus helping the few-shot segmentation task. We also develop a mask refinement module to recurrently refine the prediction of the foreground regions. For the $k$-shot learning, we propose to finetune parts of networks to take advantage of multiple labeled support images. Experiments on the PASCAL VOC 2012 dataset show that our network achieves state-of-the-art performance.
Data-Efficient Deep Learning Method for Image Classification Using Data Augmentation, Focal Cosine Loss, and Ensemble
Jul 15, 2020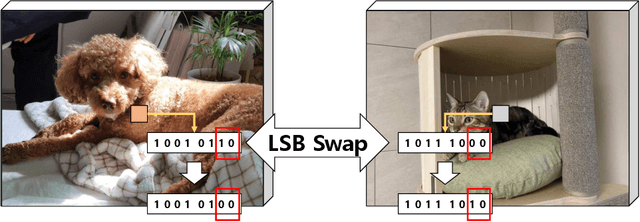

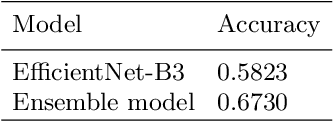
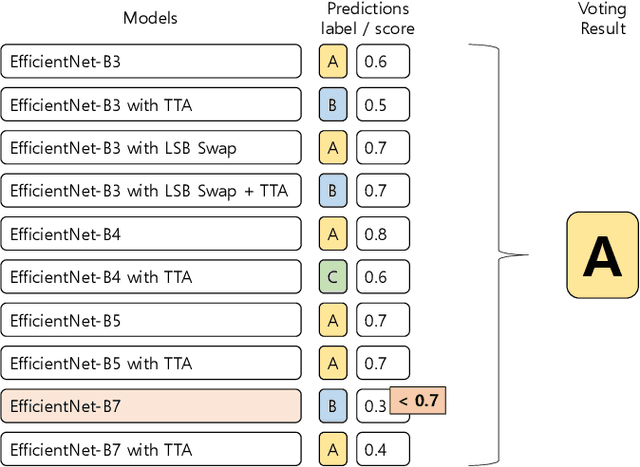
In general, sufficient data is essential for the better performance and generalization of deep-learning models. However, lots of limitations(cost, resources, etc.) of data collection leads to lack of enough data in most of the areas. In addition, various domains of each data sources and licenses also lead to difficulties in collection of sufficient data. This situation makes us hard to utilize not only the pre-trained model, but also the external knowledge. Therefore, it is important to leverage small dataset effectively for achieving the better performance. We applied some techniques in three aspects: data, loss function, and prediction to enable training from scratch with less data. With these methods, we obtain high accuracy by leveraging ImageNet data which consist of only 50 images per class. Furthermore, our model is ranked 4th in Visual Inductive Printers for Data-Effective Computer Vision Challenge.
Neural Codes for Image Retrieval
Jul 07, 2014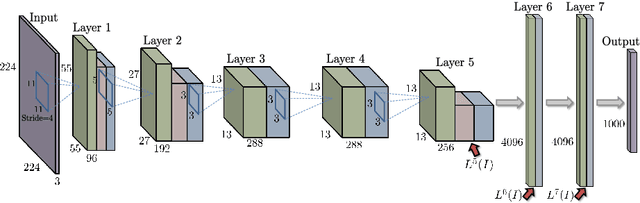
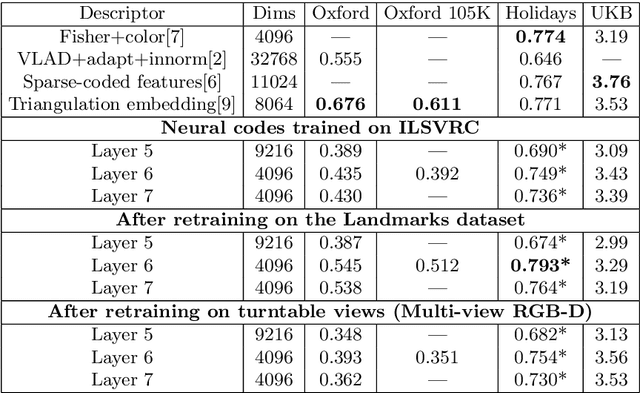

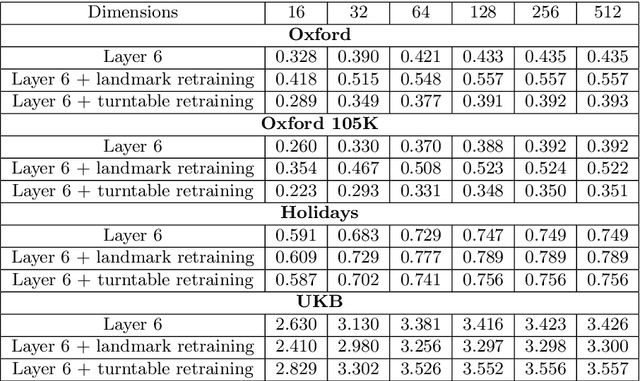
It has been shown that the activations invoked by an image within the top layers of a large convolutional neural network provide a high-level descriptor of the visual content of the image. In this paper, we investigate the use of such descriptors (neural codes) within the image retrieval application. In the experiments with several standard retrieval benchmarks, we establish that neural codes perform competitively even when the convolutional neural network has been trained for an unrelated classification task (e.g.\ Image-Net). We also evaluate the improvement in the retrieval performance of neural codes, when the network is retrained on a dataset of images that are similar to images encountered at test time. We further evaluate the performance of the compressed neural codes and show that a simple PCA compression provides very good short codes that give state-of-the-art accuracy on a number of datasets. In general, neural codes turn out to be much more resilient to such compression in comparison other state-of-the-art descriptors. Finally, we show that discriminative dimensionality reduction trained on a dataset of pairs of matched photographs improves the performance of PCA-compressed neural codes even further. Overall, our quantitative experiments demonstrate the promise of neural codes as visual descriptors for image retrieval.
Multi-level Knowledge Distillation
Dec 01, 2020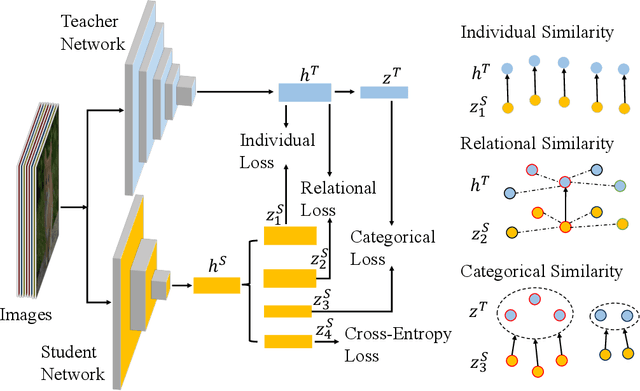
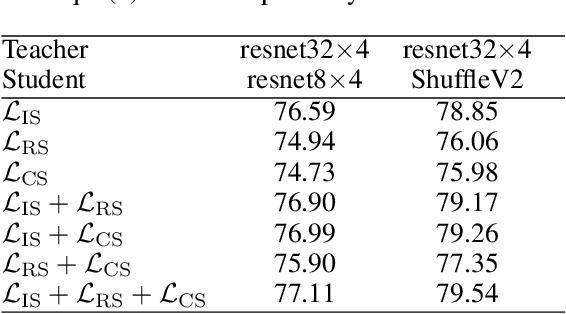
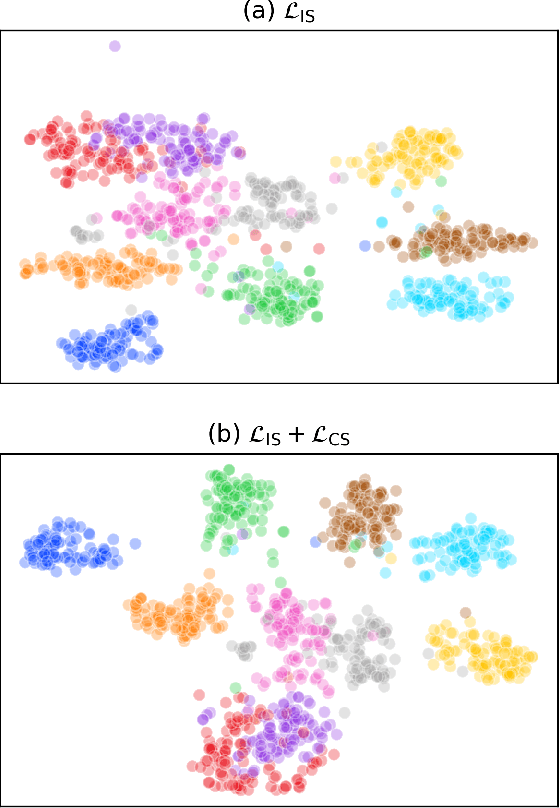
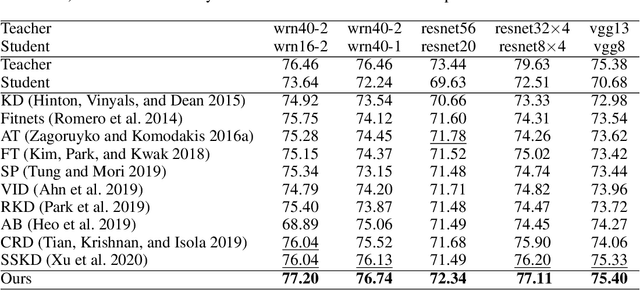
Knowledge distillation has become an important technique for model compression and acceleration. The conventional knowledge distillation approaches aim to transfer knowledge from teacher to student networks by minimizing the KL-divergence between their probabilistic outputs, which only consider the mutual relationship between individual representations of teacher and student networks. Recently, the contrastive loss-based knowledge distillation is proposed to enable a student to learn the instance discriminative knowledge of a teacher by mapping the same image close and different images far away in the representation space. However, all of these methods ignore that the teacher's knowledge is multi-level, e.g., individual, relational and categorical level. These different levels of knowledge cannot be effectively captured by only one kind of supervisory signal. Here, we introduce Multi-level Knowledge Distillation (MLKD) to transfer richer representational knowledge from teacher to student networks. MLKD employs three novel teacher-student similarities: individual similarity, relational similarity, and categorical similarity, to encourage the student network to learn sample-wise, structure-wise and category-wise knowledge in the teacher network. Experiments demonstrate that MLKD outperforms other state-of-the-art methods on both similar-architecture and cross-architecture tasks. We further show that MLKD can improve the transferability of learned representations in the student network.
SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning
Apr 12, 2017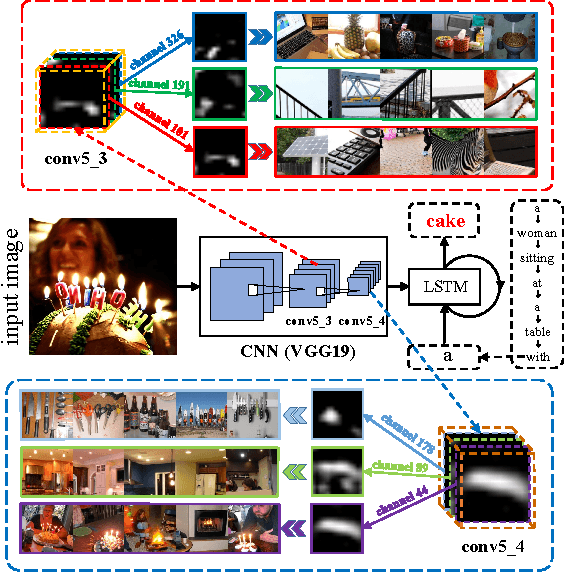
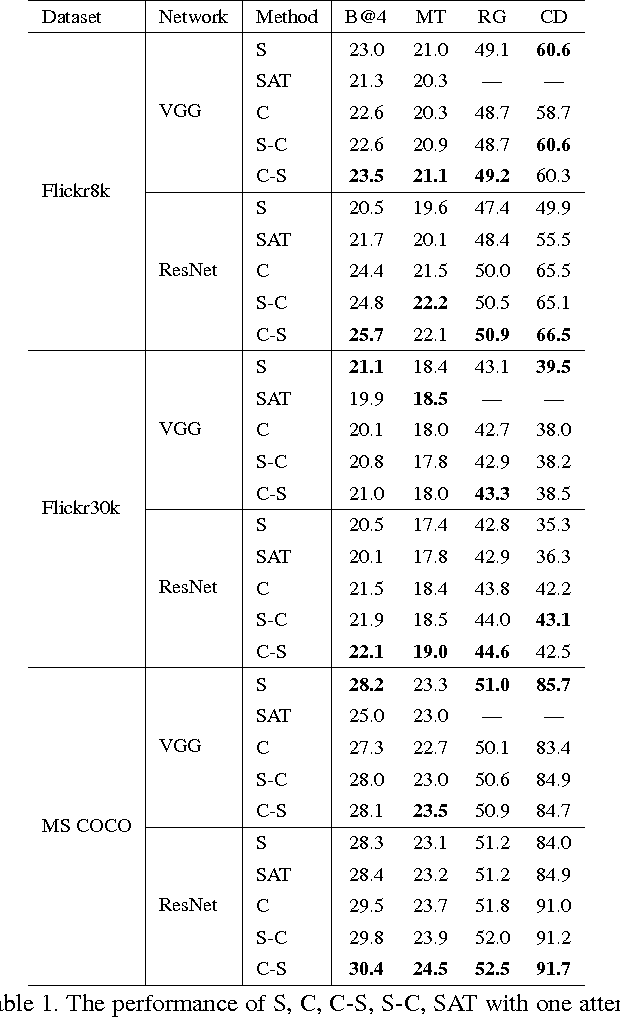
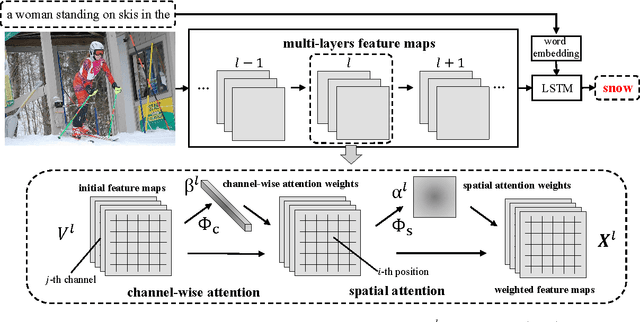
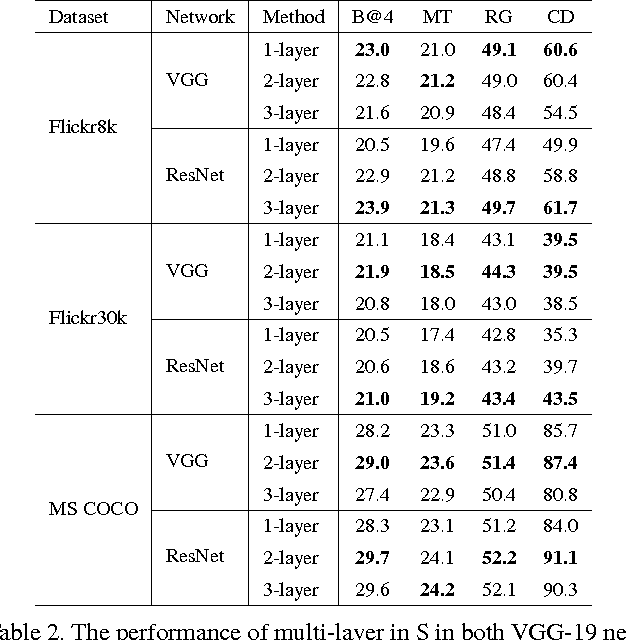
Visual attention has been successfully applied in structural prediction tasks such as visual captioning and question answering. Existing visual attention models are generally spatial, i.e., the attention is modeled as spatial probabilities that re-weight the last conv-layer feature map of a CNN encoding an input image. However, we argue that such spatial attention does not necessarily conform to the attention mechanism --- a dynamic feature extractor that combines contextual fixations over time, as CNN features are naturally spatial, channel-wise and multi-layer. In this paper, we introduce a novel convolutional neural network dubbed SCA-CNN that incorporates Spatial and Channel-wise Attentions in a CNN. In the task of image captioning, SCA-CNN dynamically modulates the sentence generation context in multi-layer feature maps, encoding where (i.e., attentive spatial locations at multiple layers) and what (i.e., attentive channels) the visual attention is. We evaluate the proposed SCA-CNN architecture on three benchmark image captioning datasets: Flickr8K, Flickr30K, and MSCOCO. It is consistently observed that SCA-CNN significantly outperforms state-of-the-art visual attention-based image captioning methods.
DeepURL: Deep Pose Estimation Framework for Underwater Relative Localization
Mar 13, 2020
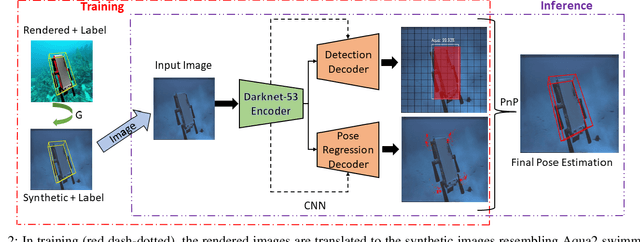
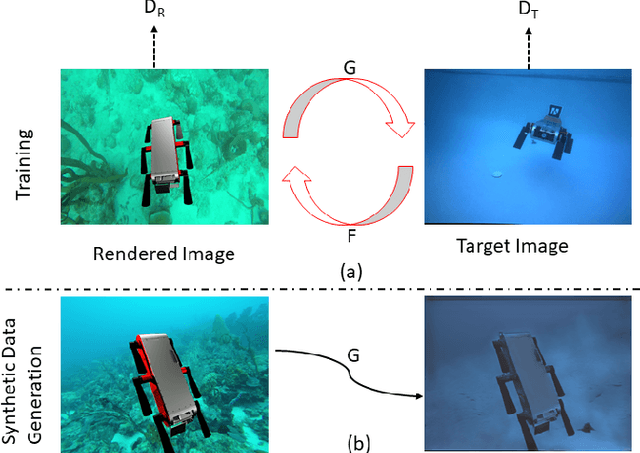
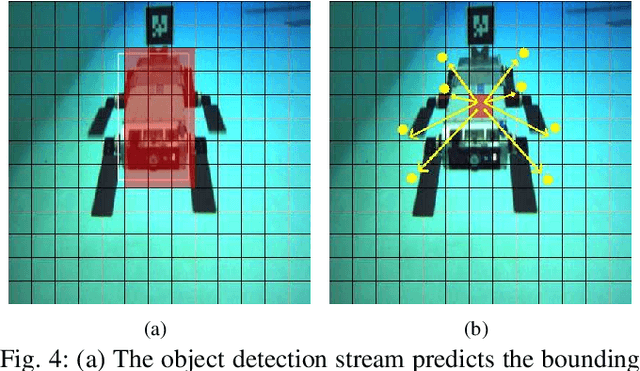
In this paper, we propose a real-time deep-learning approach for determining the 6D relative pose of Autonomous Underwater Vehicles (AUV) from a single image. A team of autonomous robots localizing themselves, in a communication-constrained underwater environment, is essential for many applications such as underwater exploration, mapping, multi-robot convoying, and other multi-robot tasks. Due to the profound difficulty of collecting ground truth images with accurate 6D poses underwater, this work utilizes rendered images from the Unreal Game Engine simulation for training. An image translation network is employed to bridge the gap between the rendered and the real images producing synthetic images for training. The proposed method predicts the 6D pose of an AUV from a single image as 2D image keypoints representing 8 corners of the 3D model of the AUV, and then the 6D pose in the camera coordinates is determined using RANSAC-based PnP. Experimental results in underwater environments (swimming pool and ocean) with different cameras demonstrate the robustness of the proposed technique, where the trained system decreased translation error by 75.5% and orientation error by 64.6% over the state-of-the-art methods.
A Review and Comparative Study on Probabilistic Object Detection in Autonomous Driving
Nov 20, 2020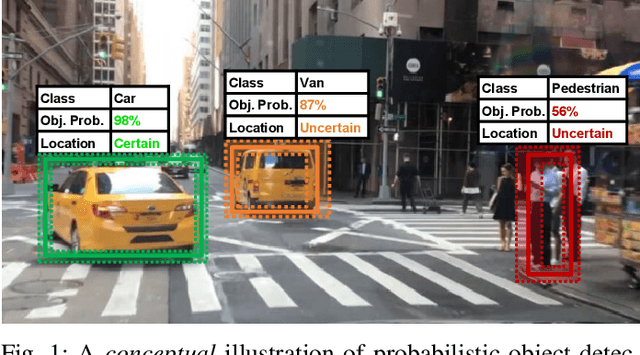
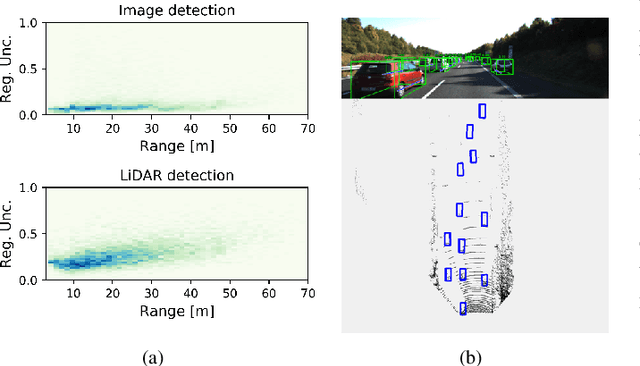
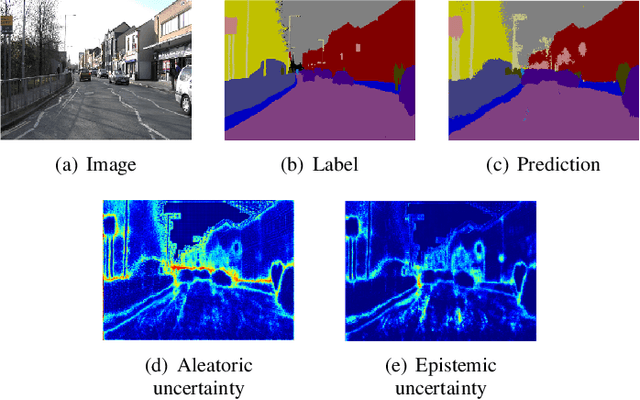
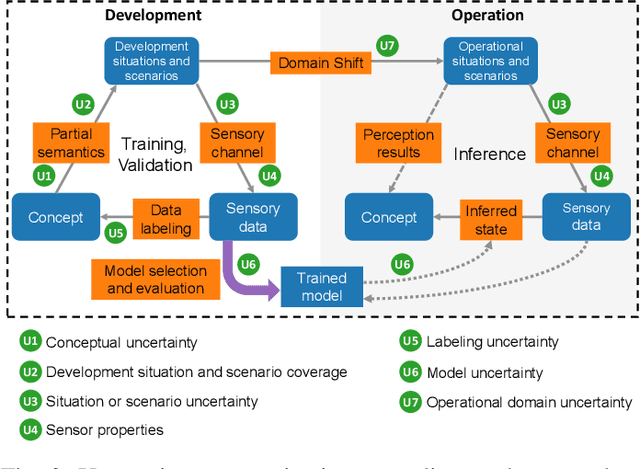
Capturing uncertainty in object detection is indispensable for safe autonomous driving. In recent years, deep learning has become the de-facto approach for object detection, and many probabilistic object detectors have been proposed. However, there is no summary on uncertainty estimation in deep object detection, and existing methods are not only built with different network architectures and uncertainty estimation methods, but also evaluated on different datasets with a wide range of evaluation metrics. As a result, a comparison among methods remains challenging, as does the selection of a model that best suits a particular application. This paper aims to alleviate this problem by providing a review and comparative study on existing probabilistic object detection methods for autonomous driving applications. First, we provide an overview of generic uncertainty estimation in deep learning, and then systematically survey existing methods and evaluation metrics for probabilistic object detection. Next, we present a strict comparative study for probabilistic object detection based on an image detector and three public autonomous driving datasets. Finally, we present a discussion of the remaining challenges and future works. Code has been made available at https://github.com/asharakeh/pod_compare.git
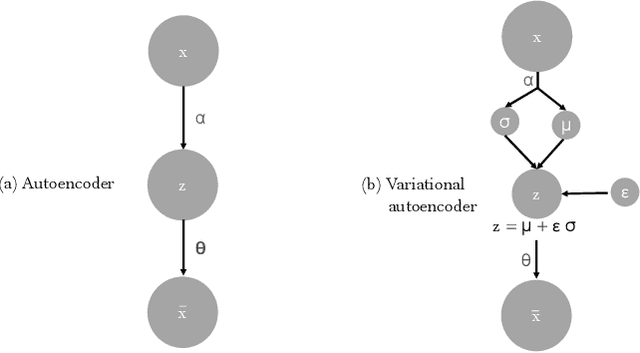
Compressing Images by Encoding Their Latent Representations with Relative Entropy Coding
Oct 27, 2020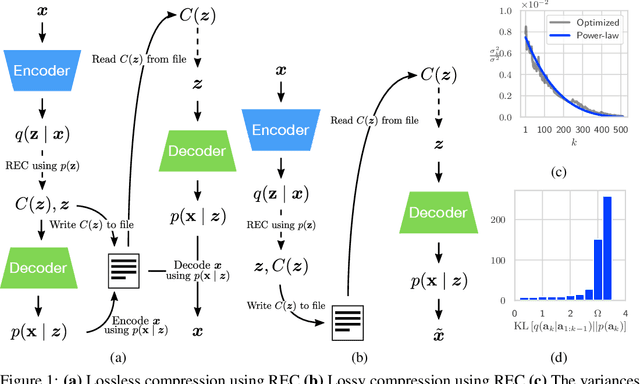
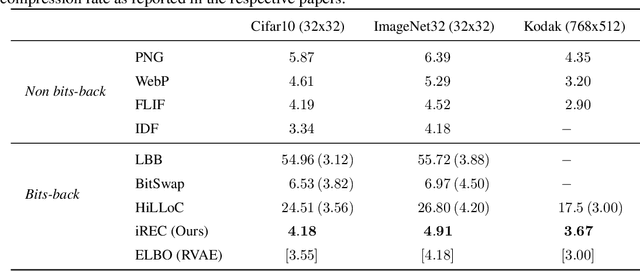
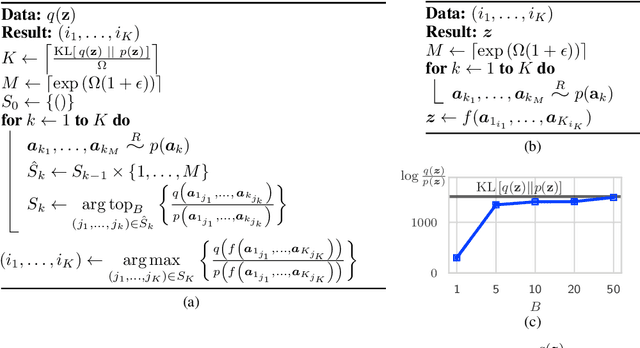
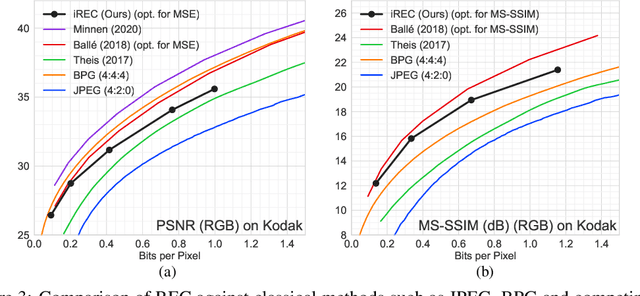
Variational Autoencoders (VAEs) have seen widespread use in learned image compression. They are used to learn expressive latent representations on which downstream compression methods can operate with high efficiency. Recently proposed 'bits-back' methods can indirectly encode the latent representation of images with codelength close to the relative entropy between the latent posterior and the prior. However, due to the underlying algorithm, these methods can only be used for lossless compression, and they only achieve their nominal efficiency when compressing multiple images simultaneously; they are inefficient for compressing single images. As an alternative, we propose a novel method, Relative Entropy Coding (REC), that can directly encode the latent representation with codelength close to the relative entropy for single images, supported by our empirical results obtained on the Cifar10, ImageNet32 and Kodak datasets. Moreover, unlike previous bits-back methods, REC is immediately applicable to lossy compression, where it is competitive with the state-of-the-art on the Kodak dataset.
PRVNet: Variational Autoencoders for Massive MIMO CSI Feedback
Nov 09, 2020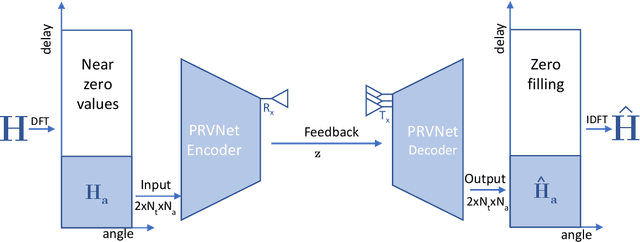
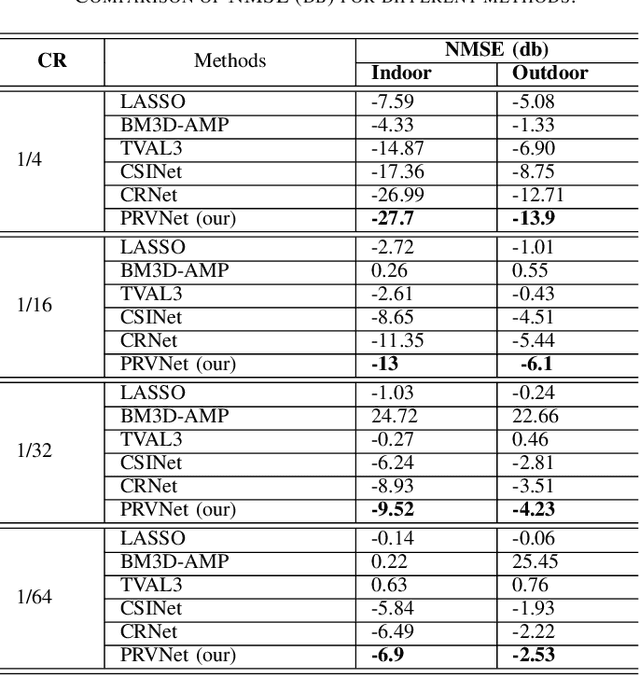

In a frequency division duplexing multiple-input multiple-output (FDD-MIMO) system, the user equipment (UE) send the downlink channel state information (CSI) to the base station for performance improvement. However, with the growing complexity of MIMO systems, this feedback becomes expensive and has a negative impact on the bandwidth. Although this problem has been largely studied in the literature, the noisy nature of the feedback channel is less considered. In this paper, we introduce PRVNet, a neural architecture based on variational autoencoders (VAE). VAE gained large attention in many fields (e.g., image processing, language models, or recommendation system). However, it received less attention in the communication domain generally and in CSI feedback problem specifically. We also introduce a different regularization parameter for the learning objective, which proved to be crucial for achieving competitive performance. In addition, we provide an efficient way to tune this parameter using KL-annealing. Empirically, we show that the proposed model significantly outperforms state-of-the-art, including two neural network approaches. The proposed model is also proved to be more robust against different levels of noise.