 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Unified Framework for Compressive Video Recovery from Coded Exposure Techniques
Nov 11, 2020

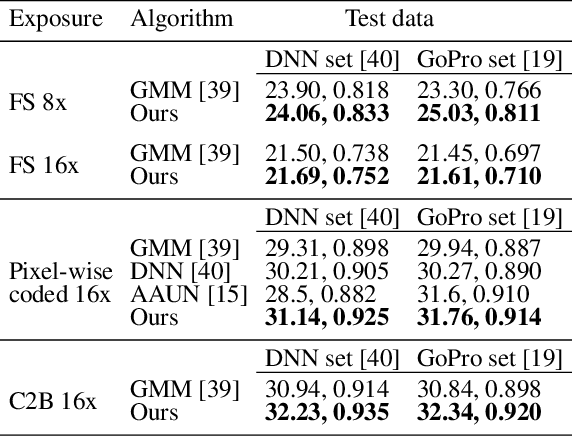
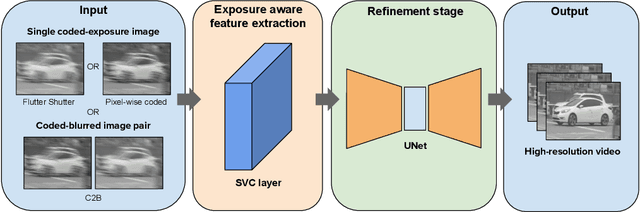

Several coded exposure techniques have been proposed for acquiring high frame rate videos at low bandwidth. Most recently, a Coded-2-Bucket camera has been proposed that can acquire two compressed measurements in a single exposure, unlike previously proposed coded exposure techniques, which can acquire only a single measurement. Although two measurements are better than one for an effective video recovery, we are yet unaware of the clear advantage of two measurements, either quantitatively or qualitatively. Here, we propose a unified learning-based framework to make such a qualitative and quantitative comparison between those which capture only a single coded image (Flutter Shutter, Pixel-wise coded exposure) and those that capture two measurements per exposure (C2B). Our learning-based framework consists of a shift-variant convolutional layer followed by a fully convolutional deep neural network. Our proposed unified framework achieves the state of the art reconstructions in all three sensing techniques. Further analysis shows that when most scene points are static, the C2B sensor has a significant advantage over acquiring a single pixel-wise coded measurement. However, when most scene points undergo motion, the C2B sensor has only a marginal benefit over the single pixel-wise coded exposure measurement.
AutoGAN-Distiller: Searching to Compress Generative Adversarial Networks
Jul 06, 2020
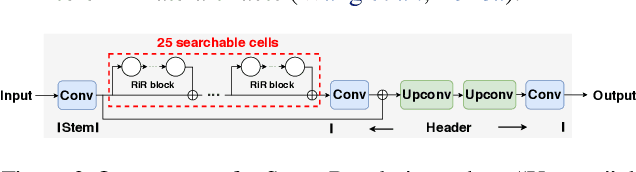
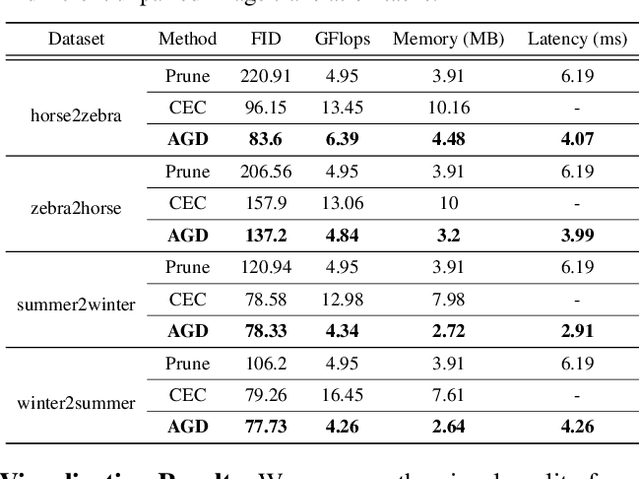

The compression of Generative Adversarial Networks (GANs) has lately drawn attention, due to the increasing demand for deploying GANs into mobile devices for numerous applications such as image translation, enhancement and editing. However, compared to the substantial efforts to compressing other deep models, the research on compressing GANs (usually the generators) remains at its infancy stage. Existing GAN compression algorithms are limited to handling specific GAN architectures and losses. Inspired by the recent success of AutoML in deep compression, we introduce AutoML to GAN compression and develop an AutoGAN-Distiller (AGD) framework. Starting with a specifically designed efficient search space, AGD performs an end-to-end discovery for new efficient generators, given the target computational resource constraints. The search is guided by the original GAN model via knowledge distillation, therefore fulfilling the compression. AGD is fully automatic, standalone (i.e., needing no trained discriminators), and generically applicable to various GAN models. We evaluate AGD in two representative GAN tasks: image translation and super resolution. Without bells and whistles, AGD yields remarkably lightweight yet more competitive compressed models, that largely outperform existing alternatives. Our codes and pretrained models are available at https://github.com/TAMU-VITA/AGD.
mr2NST: Multi-Resolution and Multi-Reference Neural Style Transfer for Mammography
May 25, 2020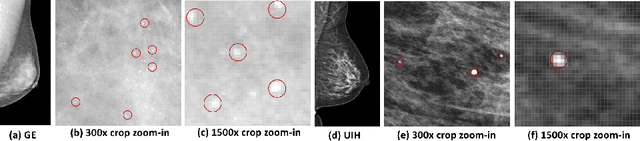

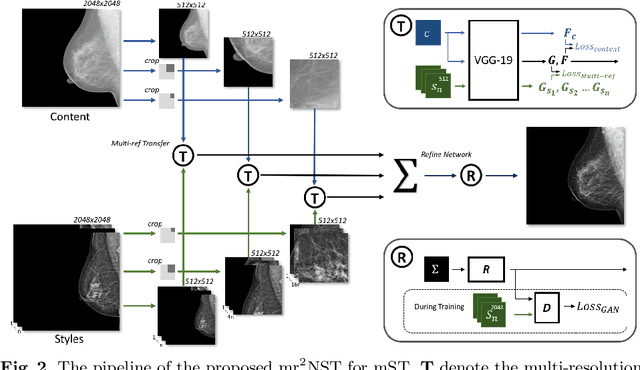
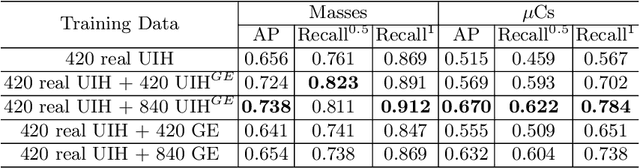
Computer-aided diagnosis with deep learning techniques has been shown to be helpful for the diagnosis of the mammography in many clinical studies. However, the image styles of different vendors are very distinctive, and there may exist domain gap among different vendors that could potentially compromise the universal applicability of one deep learning model. In this study, we explicitly address style variety issue with the proposed multi-resolution and multi-reference neural style transfer (mr2NST) network. The mr2NST can normalize the styles from different vendors to the same style baseline with very high resolution. We illustrate that the image quality of the transferred images is comparable to the quality of original images of the target domain (vendor) in terms of NIMA scores. Meanwhile, the mr2NST results are also shown to be helpful for the lesion detection in mammograms.
Scribble2Label: Scribble-Supervised Cell Segmentation via Self-Generating Pseudo-Labels with Consistency
Jun 23, 2020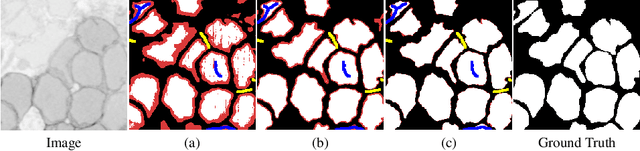
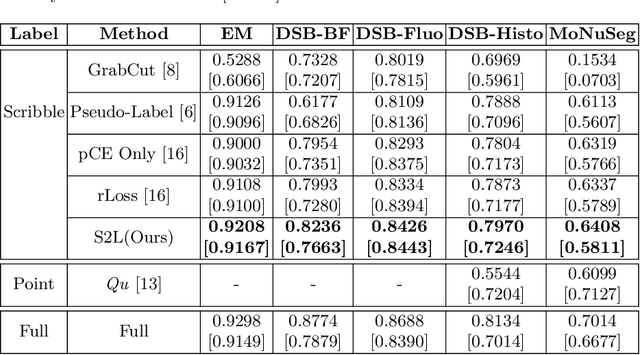
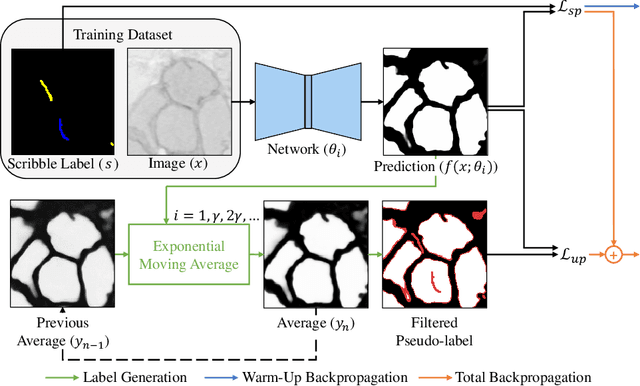
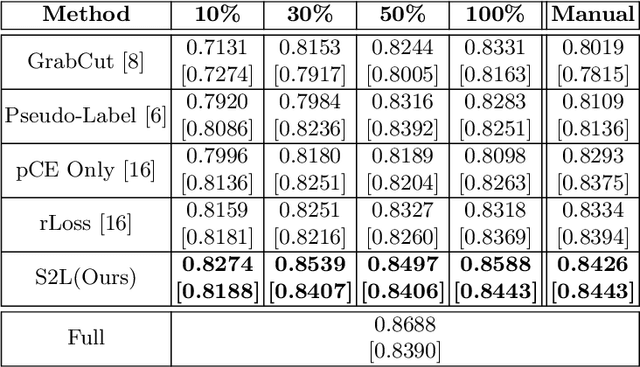
Segmentation is a fundamental process in microscopic cell image analysis. With the advent of recent advances in deep learning, more accurate and high-throughput cell segmentation has become feasible. However, most existing deep learning-based cell segmentation algorithms require fully annotated ground-truth cell labels, which are time-consuming and labor-intensive to generate. In this paper, we introduce Scribble2Label, a novel weakly-supervised cell segmentation framework that exploits only a handful of scribble annotations without full segmentation labels. The core idea is to combine pseudo-labeling and label filtering to generate reliable labels from weak supervision. For this, we leverage the consistency of predictions by iteratively averaging the predictions to improve pseudo labels. We demonstrate the performance of Scribble2Label by comparing it to several state-of-the-art cell segmentation methods with various cell image modalities, including bright-field, fluorescence, and electron microscopy. We also show that our method performs robustly across different levels of scribble details, which confirms that only a few scribble annotations are required in real-use cases.
CAD2Real: Deep learning with domain randomization of CAD data for 3D pose estimation of electronic control unit housings
Sep 25, 2020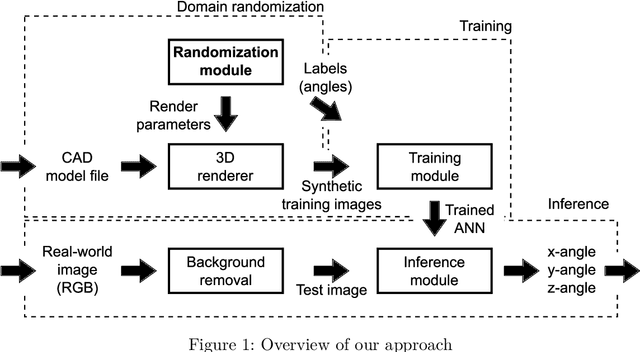
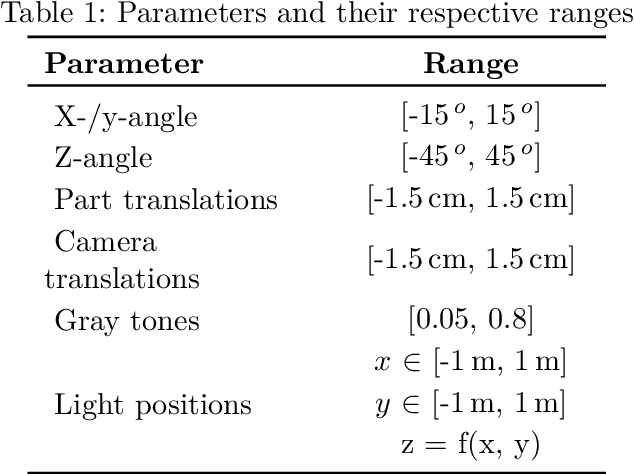

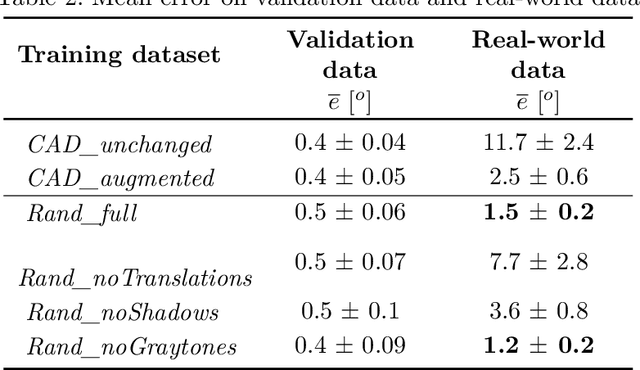
Electronic control units (ECUs) are essential for many automobile components, e.g. engine, anti-lock braking system (ABS), steering and airbags. For some products, the 3D pose of each single ECU needs to be determined during series production. Deep learning approaches can not easily be applied to this problem, because labeled training data is not available in sufficient numbers. Thus, we train state-of-the-art artificial neural networks (ANNs) on purely synthetic training data, which is automatically created from a single CAD file. By randomizing parameters during rendering of training images, we enable inference on RGB images of a real sample part. In contrast to classic image processing approaches, this data-driven approach poses only few requirements regarding the measurement setup and transfers to related use cases with little development effort.
Boosting the Performance of Semi-Supervised Learning with Unsupervised Clustering
Dec 01, 2020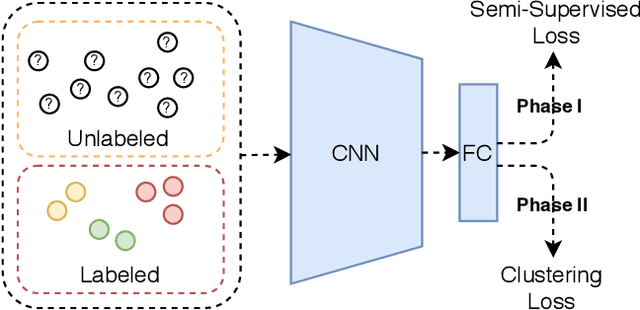
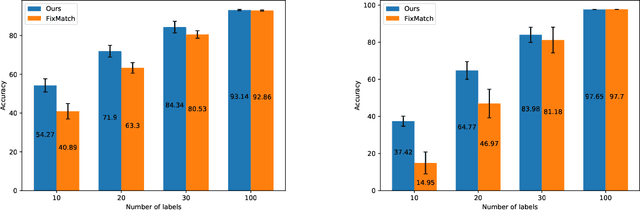
Recently, Semi-Supervised Learning (SSL) has shown much promise in leveraging unlabeled data while being provided with very few labels. In this paper, we show that ignoring the labels altogether for whole epochs intermittently during training can significantly improve performance in the small sample regime. More specifically, we propose to train a network on two tasks jointly. The primary classification task is exposed to both the unlabeled and the scarcely annotated data, whereas the secondary task seeks to cluster the data without any labels. As opposed to hand-crafted pretext tasks frequently used in self-supervision, our clustering phase utilizes the same classification network and head in an attempt to relax the primary task and propagate the information from the labels without overfitting them. On top of that, the self-supervised technique of classifying image rotations is incorporated during the unsupervised learning phase to stabilize training. We demonstrate our method's efficacy in boosting several state-of-the-art SSL algorithms, significantly improving their results and reducing running time in various standard semi-supervised benchmarks, including 92.6% accuracy on CIFAR-10 and 96.9% on SVHN, using only 4 labels per class in each task. We also notably improve the results in the extreme cases of 1,2 and 3 labels per class, and show that features learned by our model are more meaningful for separating the data.
DE-GAN: A Conditional Generative Adversarial Network for Document Enhancement
Oct 17, 2020
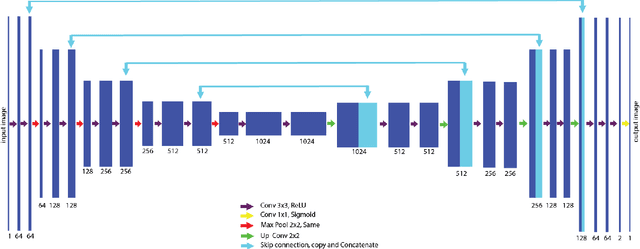
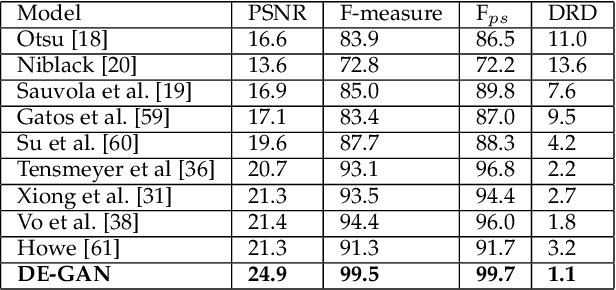
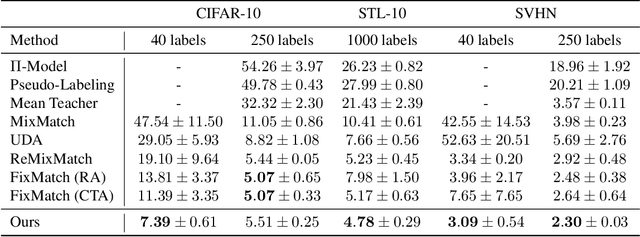
Documents often exhibit various forms of degradation, which make it hard to be read and substantially deteriorate the performance of an OCR system. In this paper, we propose an effective end-to-end framework named Document Enhancement Generative Adversarial Networks (DE-GAN) that uses the conditional GANs (cGANs) to restore severely degraded document images. To the best of our knowledge, this practice has not been studied within the context of generative adversarial deep networks. We demonstrate that, in different tasks (document clean up, binarization, deblurring and watermark removal), DE-GAN can produce an enhanced version of the degraded document with a high quality. In addition, our approach provides consistent improvements compared to state-of-the-art methods over the widely used DIBCO 2013, DIBCO 2017 and H-DIBCO 2018 datasets, proving its ability to restore a degraded document image to its ideal condition. The obtained results on a wide variety of degradation reveal the flexibility of the proposed model to be exploited in other document enhancement problems.
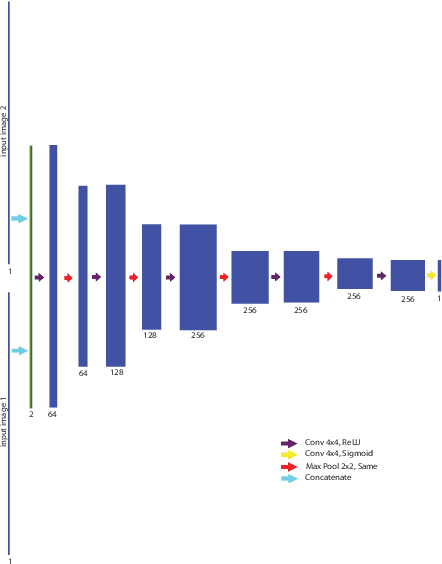
Deep Learning Based Detection and Correction of Cardiac MR Motion Artefacts During Reconstruction for High-Quality Segmentation
Oct 21, 2019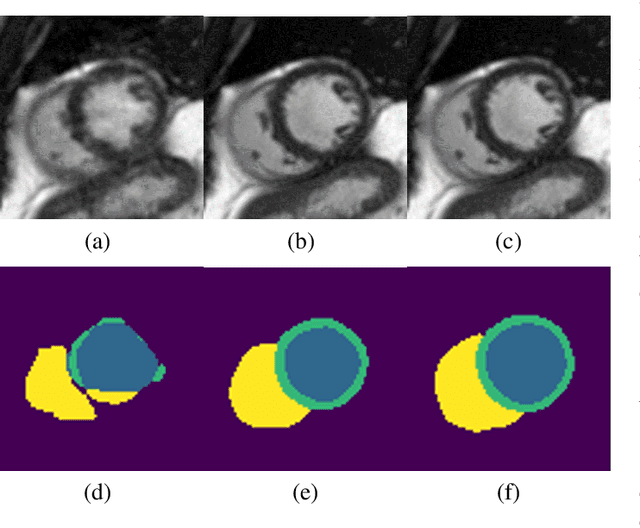
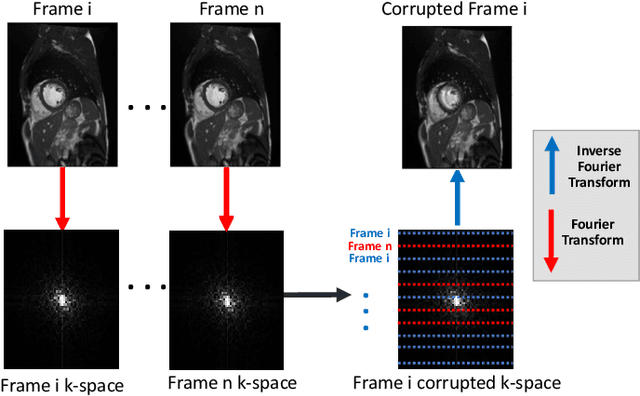
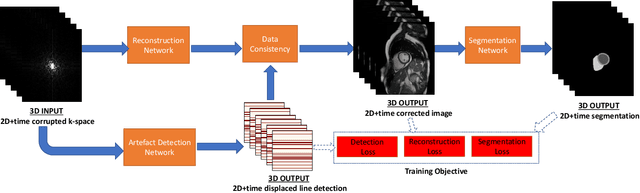
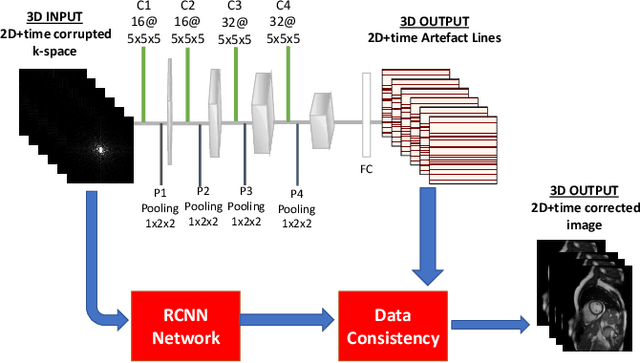
Segmenting anatomical structures in medical images has been successfully addressed with deep learning methods for a range of applications. However, this success is heavily dependent on the quality of the image that is being segmented. A commonly neglected point in the medical image analysis community is the vast amount of clinical images that have severe image artefacts due to organ motion, movement of the patient and/or image acquisition related issues. In this paper, we discuss the implications of image motion artefacts on cardiac MR segmentation and compare a variety of approaches for jointly correcting for artefacts and segmenting the cardiac cavity. We propose to use a segmentation network coupled with this in an end-to-end framework. Our training optimises three different tasks: 1) image artefact detection, 2) artefact correction and 3) image segmentation. We train the reconstruction network to automatically correct for motion-related artefacts using synthetically corrupted cardiac MR k-space data and uncorrected reconstructed images. Using a test set of 500 2D+time cine MR acquisitions from the UK Biobank data set, we achieve demonstrably good image quality and high segmentation accuracy in the presence of synthetic motion artefacts. We quantitatively compare our method with a variety of techniques for jointly recovering image quality and performing image segmentation. We showcase better performance compared to state-of-the-art image correction techniques. Moreover, our method preserves the quality of uncorrupted images and therefore can be utilised as a global image reconstruction algorithm.
Variational Dynamic for Self-Supervised Exploration in Deep Reinforcement Learning
Oct 17, 2020
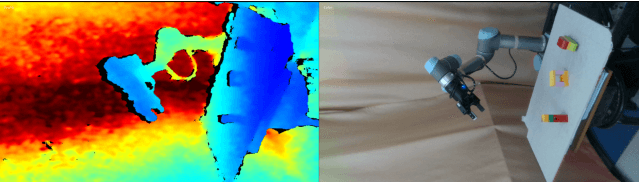
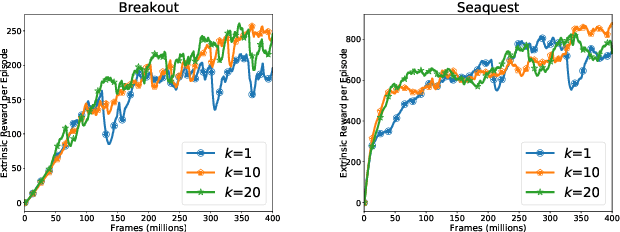
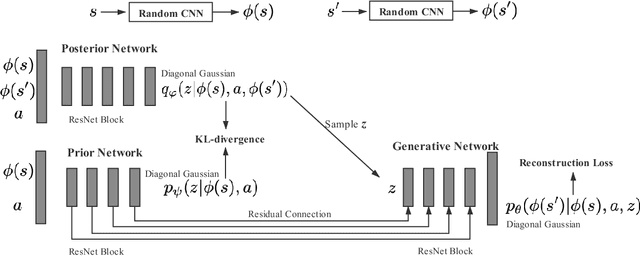
Efficient exploration remains a challenging problem in reinforcement learning, especially for tasks where extrinsic rewards from environments are sparse or even totally disregarded. Significant advances based on intrinsic motivation show promising results in simple environments but often get stuck in environments with multimodal and stochastic dynamics. In this work, we propose a variational dynamic model based on the conditional variational inference to model the multimodality and stochasticity. We consider the environmental state-action transition as a conditional generative process by generating the next-state prediction under the condition of the current state, action, and latent variable. We derive an upper bound of the negative log-likelihood of the environmental transition and use such an upper bound as the intrinsic reward for exploration, which allows the agent to learn skills by self-supervised exploration without observing extrinsic rewards. We evaluate the proposed method on several image-based simulation tasks and a real robotic manipulating task. Our method outperforms several state-of-the-art environment model-based exploration approaches.
Deep Learning Approaches to Classification of Production Technology for 19th Century Books
Sep 17, 2020



Cultural research is dedicated to understanding the processes of knowledge dissemination and the social and technological practices in the book industry. Research on children books in the 19th century can be supported by computer systems. Specifically, the advances in digital image processing seem to offer great opportunities for analyzing and quantifying the visual components in the books. The production technology for illustrations in books in the 19th century was characterized by a shift from wood or copper engraving to lithography. We report classification experiments which intend to classify images based on the production technology. For a classification task that is also difficult for humans, the classification quality reaches only around 70%. We analyze some further error sources and identify reasons for the low performance.
* LWDA 2018: Mannheim, Germany