 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Boosting the Performance of Semi-Supervised Learning with Unsupervised Clustering
Dec 01, 2020
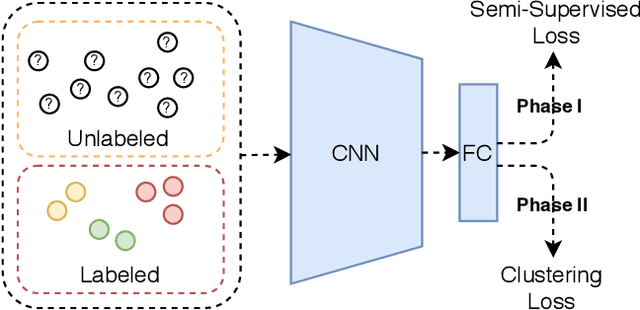
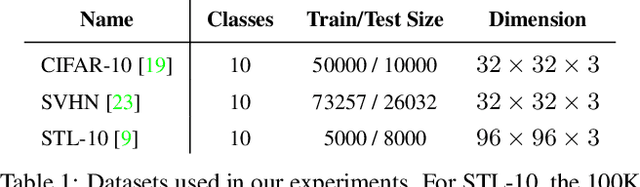
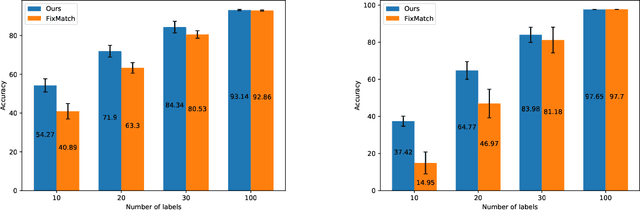
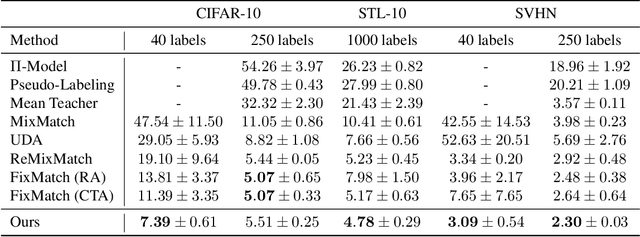
Recently, Semi-Supervised Learning (SSL) has shown much promise in leveraging unlabeled data while being provided with very few labels. In this paper, we show that ignoring the labels altogether for whole epochs intermittently during training can significantly improve performance in the small sample regime. More specifically, we propose to train a network on two tasks jointly. The primary classification task is exposed to both the unlabeled and the scarcely annotated data, whereas the secondary task seeks to cluster the data without any labels. As opposed to hand-crafted pretext tasks frequently used in self-supervision, our clustering phase utilizes the same classification network and head in an attempt to relax the primary task and propagate the information from the labels without overfitting them. On top of that, the self-supervised technique of classifying image rotations is incorporated during the unsupervised learning phase to stabilize training. We demonstrate our method's efficacy in boosting several state-of-the-art SSL algorithms, significantly improving their results and reducing running time in various standard semi-supervised benchmarks, including 92.6% accuracy on CIFAR-10 and 96.9% on SVHN, using only 4 labels per class in each task. We also notably improve the results in the extreme cases of 1,2 and 3 labels per class, and show that features learned by our model are more meaningful for separating the data.
Pix2Shape -- Towards Unsupervised Learning of 3D Scenes from Images using a View-based Representation
Mar 23, 2020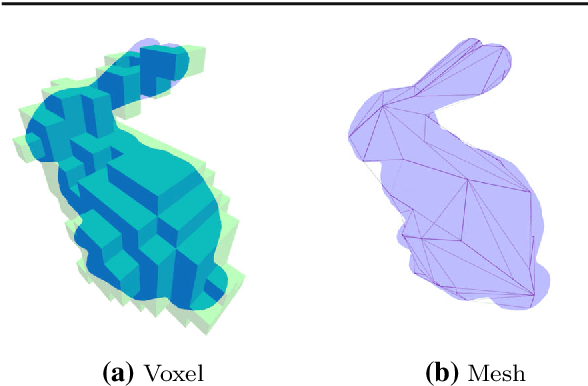
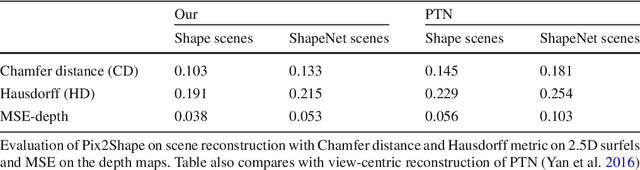

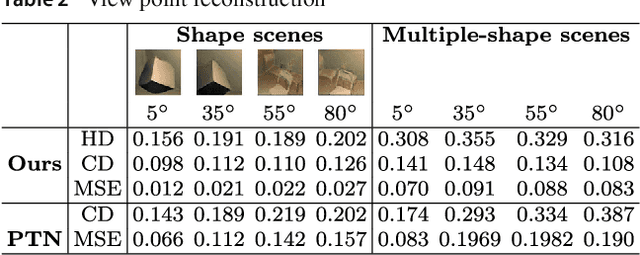
We infer and generate three-dimensional (3D) scene information from a single input image and without supervision. This problem is under-explored, with most prior work relying on supervision from, e.g., 3D ground-truth, multiple images of a scene, image silhouettes or key-points. We propose Pix2Shape, an approach to solve this problem with four components: (i) an encoder that infers the latent 3D representation from an image, (ii) a decoder that generates an explicit 2.5D surfel-based reconstruction of a scene from the latent code (iii) a differentiable renderer that synthesizes a 2D image from the surfel representation, and (iv) a critic network trained to discriminate between images generated by the decoder-renderer and those from a training distribution. Pix2Shape can generate complex 3D scenes that scale with the view-dependent on-screen resolution, unlike representations that capture world-space resolution, i.e., voxels or meshes. We show that Pix2Shape learns a consistent scene representation in its encoded latent space and that the decoder can then be applied to this latent representation in order to synthesize the scene from a novel viewpoint. We evaluate Pix2Shape with experiments on the ShapeNet dataset as well as on a novel benchmark we developed, called 3D-IQTT, to evaluate models based on their ability to enable 3d spatial reasoning. Qualitative and quantitative evaluation demonstrate Pix2Shape's ability to solve scene reconstruction, generation, and understanding tasks.
* This is a pre-print of an article published in International Journal of Computer Vision. The final authenticated version is available online at: https://doi.org/10.1007/s11263-020-01322-1
A Unified Framework for Compressive Video Recovery from Coded Exposure Techniques
Nov 11, 2020
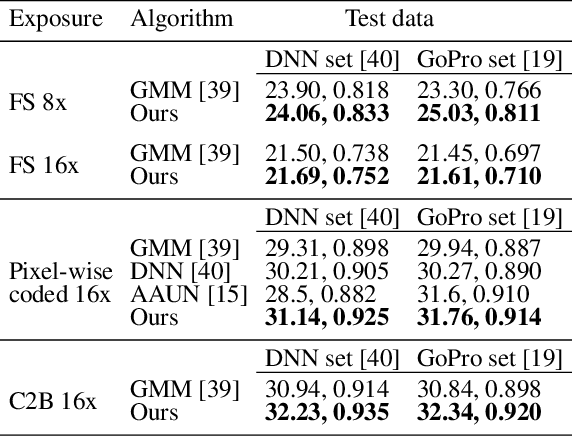
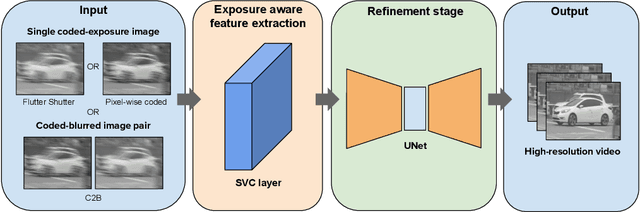

Several coded exposure techniques have been proposed for acquiring high frame rate videos at low bandwidth. Most recently, a Coded-2-Bucket camera has been proposed that can acquire two compressed measurements in a single exposure, unlike previously proposed coded exposure techniques, which can acquire only a single measurement. Although two measurements are better than one for an effective video recovery, we are yet unaware of the clear advantage of two measurements, either quantitatively or qualitatively. Here, we propose a unified learning-based framework to make such a qualitative and quantitative comparison between those which capture only a single coded image (Flutter Shutter, Pixel-wise coded exposure) and those that capture two measurements per exposure (C2B). Our learning-based framework consists of a shift-variant convolutional layer followed by a fully convolutional deep neural network. Our proposed unified framework achieves the state of the art reconstructions in all three sensing techniques. Further analysis shows that when most scene points are static, the C2B sensor has a significant advantage over acquiring a single pixel-wise coded measurement. However, when most scene points undergo motion, the C2B sensor has only a marginal benefit over the single pixel-wise coded exposure measurement.
Transfer Learning by Asymmetric Image Weighting for Segmentation across Scanners
Mar 15, 2017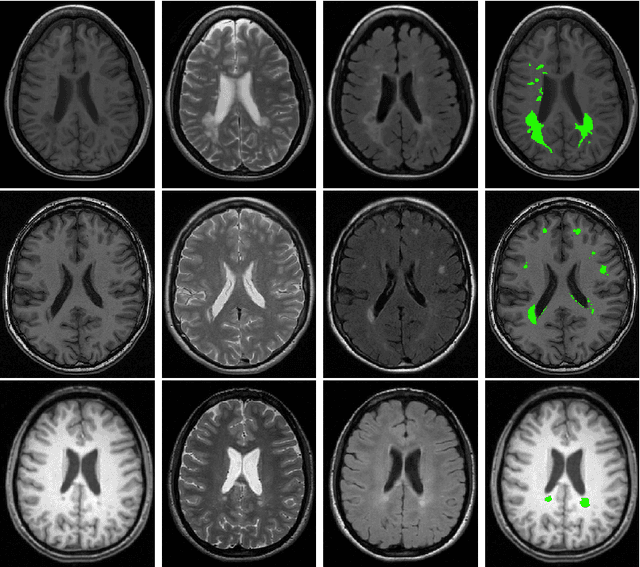
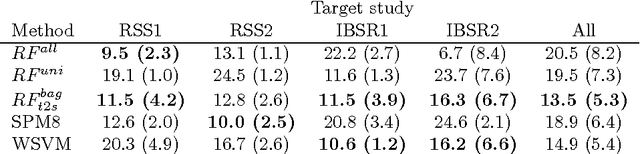
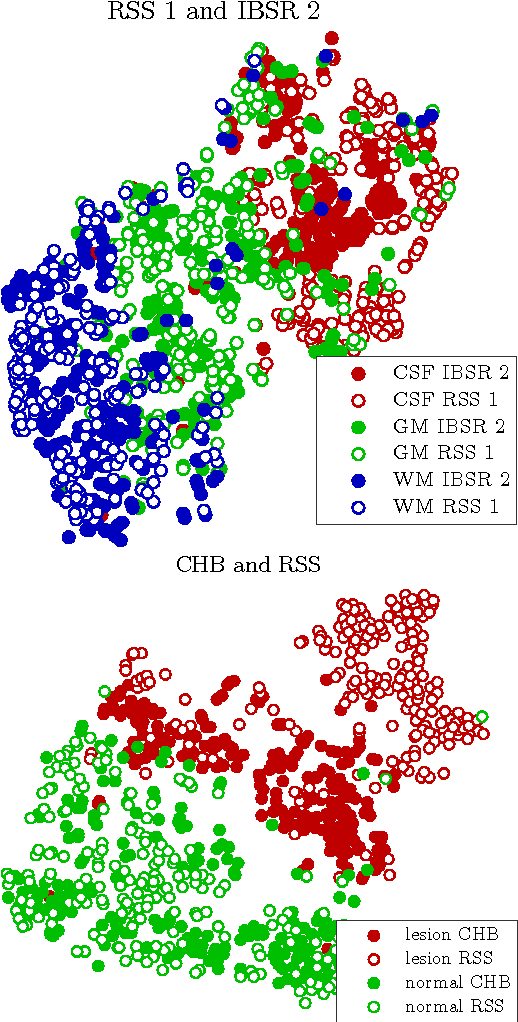
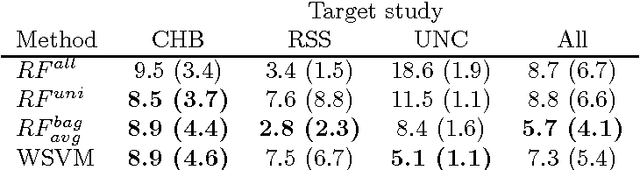
Supervised learning has been very successful for automatic segmentation of images from a single scanner. However, several papers report deteriorated performances when using classifiers trained on images from one scanner to segment images from other scanners. We propose a transfer learning classifier that adapts to differences between training and test images. This method uses a weighted ensemble of classifiers trained on individual images. The weight of each classifier is determined by the similarity between its training image and the test image. We examine three unsupervised similarity measures, which can be used in scenarios where no labeled data from a newly introduced scanner or scanning protocol is available. The measures are based on a divergence, a bag distance, and on estimating the labels with a clustering procedure. These measures are asymmetric. We study whether the asymmetry can improve classification. Out of the three similarity measures, the bag similarity measure is the most robust across different studies and achieves excellent results on four brain tissue segmentation datasets and three white matter lesion segmentation datasets, acquired at different centers and with different scanners and scanning protocols. We show that the asymmetry can indeed be informative, and that computing the similarity from the test image to the training images is more appropriate than the opposite direction.
Evaluation of Cross-View Matching to Improve Ground Vehicle Localization with Aerial Perception
Mar 26, 2020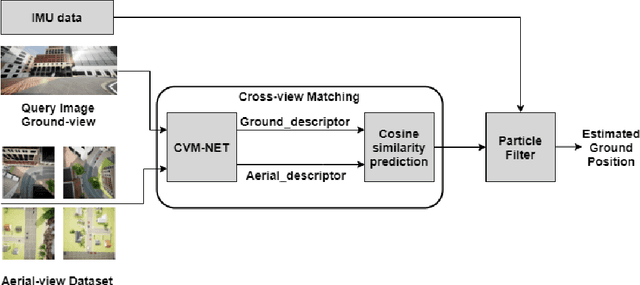
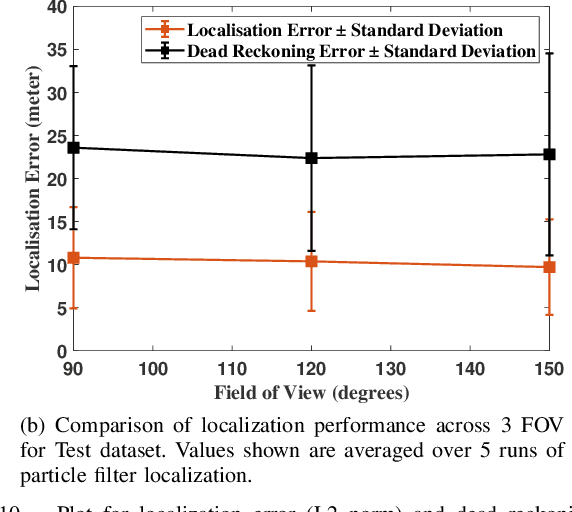

Cross-view matching refers to the problem of finding the closest match to a given query ground-view image to one from a database of aerial images. If the aerial images are geotagged, then the closest matching aerial image can be used to localize the query ground-view image. Recently, due to the success of deep learning methods, a number of cross-view matching techniques have been proposed. These techniques perform well for the matching of isolated query images. In this paper, we evaluate cross-view matching for the task of localizing a ground vehicle over a longer trajectory. We use the cross-view matching module as a sensor measurement fused with a particle filter. We evaluate the performance of this method using a city-wide dataset collected in photorealistic simulation using five parameters: height of aerial images, the pitch of the aerial camera mount, field-of-view of ground camera, measurement model and resampling strategy for the particles in the particle filter.
Weakly supervised one-stage vision and language disease detection using large scale pneumonia and pneumothorax studies
Jul 31, 2020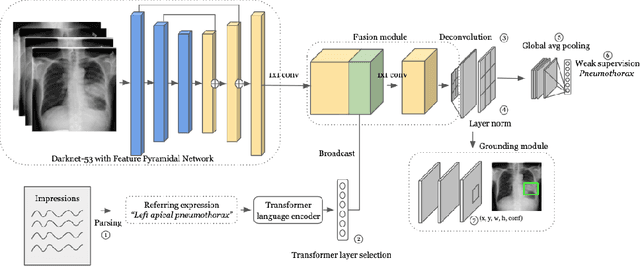
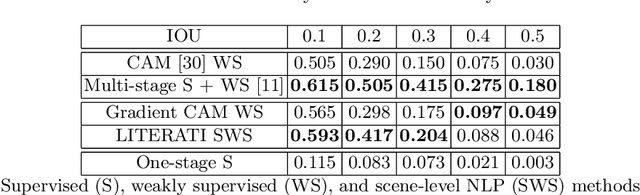
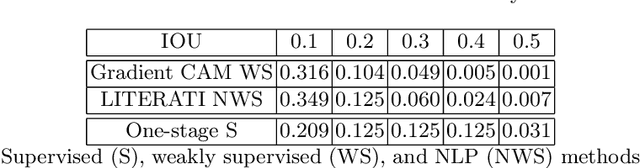
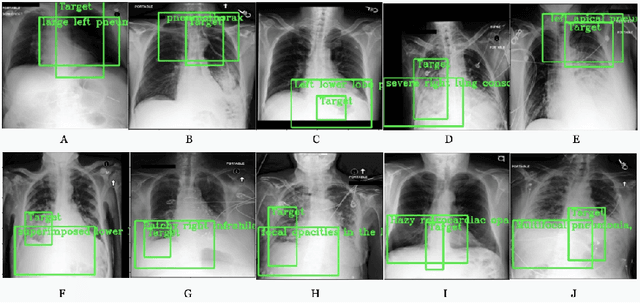
Detecting clinically relevant objects in medical images is a challenge despite large datasets due to the lack of detailed labels. To address the label issue, we utilize the scene-level labels with a detection architecture that incorporates natural language information. We present a challenging new set of radiologist paired bounding box and natural language annotations on the publicly available MIMIC-CXR dataset especially focussed on pneumonia and pneumothorax. Along with the dataset, we present a joint vision language weakly supervised transformer layer-selected one-stage dual head detection architecture (LITERATI) alongside strong baseline comparisons with class activation mapping (CAM), gradient CAM, and relevant implementations on the NIH ChestXray-14 and MIMIC-CXR dataset. Borrowing from advances in vision language architectures, the LITERATI method demonstrates joint image and referring expression (objects localized in the image using natural language) input for detection that scales in a purely weakly supervised fashion. The architectural modifications address three obstacles -- implementing a supervised vision and language detection method in a weakly supervised fashion, incorporating clinical referring expression natural language information, and generating high fidelity detections with map probabilities. Nevertheless, the challenging clinical nature of the radiologist annotations including subtle references, multi-instance specifications, and relatively verbose underlying medical reports, ensures the vision language detection task at scale remains stimulating for future investigation.
A CNN Approach to Simultaneously Count Plants and Detect Plantation-Rows from UAV Imagery
Jan 02, 2021
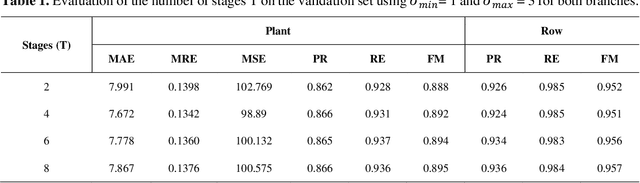
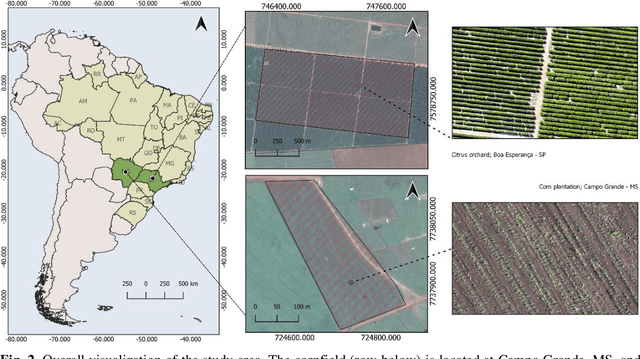
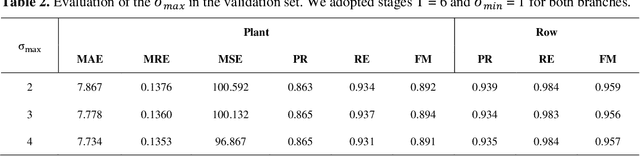
In this paper, we propose a novel deep learning method based on a Convolutional Neural Network (CNN) that simultaneously detects and geolocates plantation-rows while counting its plants considering highly-dense plantation configurations. The experimental setup was evaluated in a cornfield with different growth stages and in a Citrus orchard. Both datasets characterize different plant density scenarios, locations, types of crops, sensors, and dates. A two-branch architecture was implemented in our CNN method, where the information obtained within the plantation-row is updated into the plant detection branch and retro-feed to the row branch; which are then refined by a Multi-Stage Refinement method. In the corn plantation datasets (with both growth phases, young and mature), our approach returned a mean absolute error (MAE) of 6.224 plants per image patch, a mean relative error (MRE) of 0.1038, precision and recall values of 0.856, and 0.905, respectively, and an F-measure equal to 0.876. These results were superior to the results from other deep networks (HRNet, Faster R-CNN, and RetinaNet) evaluated with the same task and dataset. For the plantation-row detection, our approach returned precision, recall, and F-measure scores of 0.913, 0.941, and 0.925, respectively. To test the robustness of our model with a different type of agriculture, we performed the same task in the citrus orchard dataset. It returned an MAE equal to 1.409 citrus-trees per patch, MRE of 0.0615, precision of 0.922, recall of 0.911, and F-measure of 0.965. For citrus plantation-row detection, our approach resulted in precision, recall, and F-measure scores equal to 0.965, 0.970, and 0.964, respectively. The proposed method achieved state-of-the-art performance for counting and geolocating plants and plant-rows in UAV images from different types of crops.
Image Restoration with Locally Selected Class-Adapted Models
Aug 02, 2016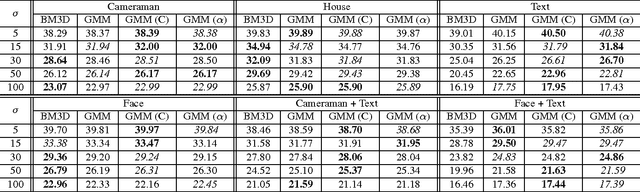

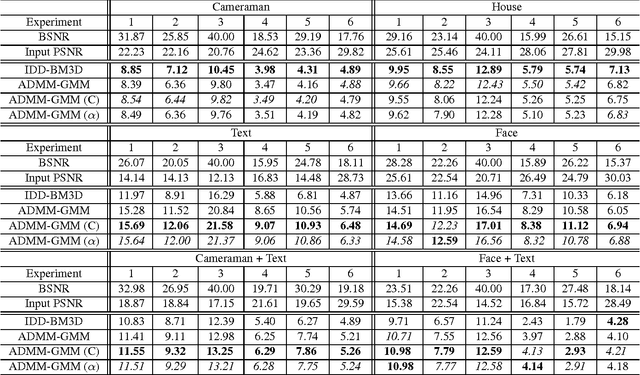

State-of-the-art algorithms for imaging inverse problems (namely deblurring and reconstruction) are typically iterative, involving a denoising operation as one of its steps. Using a state-of-the-art denoising method in this context is not trivial, and is the focus of current work. Recently, we have proposed to use a class-adapted denoiser (patch-based using Gaussian mixture models) in a so-called plug-and-play scheme, wherein a state-of-the-art denoiser is plugged into an iterative algorithm, leading to results that outperform the best general-purpose algorithms, when applied to an image of a known class (e.g. faces, text, brain MRI). In this paper, we extend that approach to handle situations where the image being processed is from one of a collection of possible classes or, more importantly, contains regions of different classes. More specifically, we propose a method to locally select one of a set of class-adapted Gaussian mixture patch priors, previously estimated from clean images of those classes. Our approach may be seen as simultaneously performing segmentation and restoration, thus contributing to bridging the gap between image restoration/reconstruction and analysis.
HetSeq: Distributed GPU Training on Heterogeneous Infrastructure
Sep 25, 2020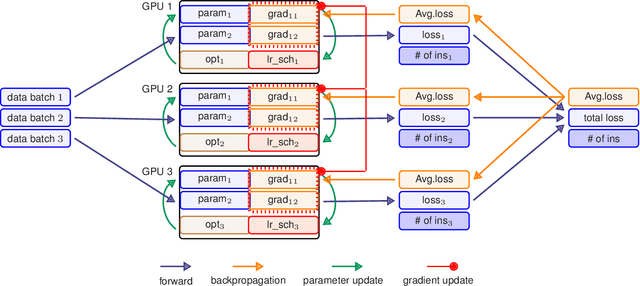
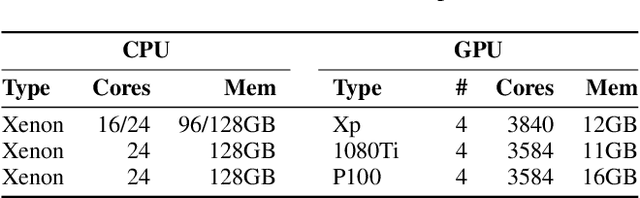
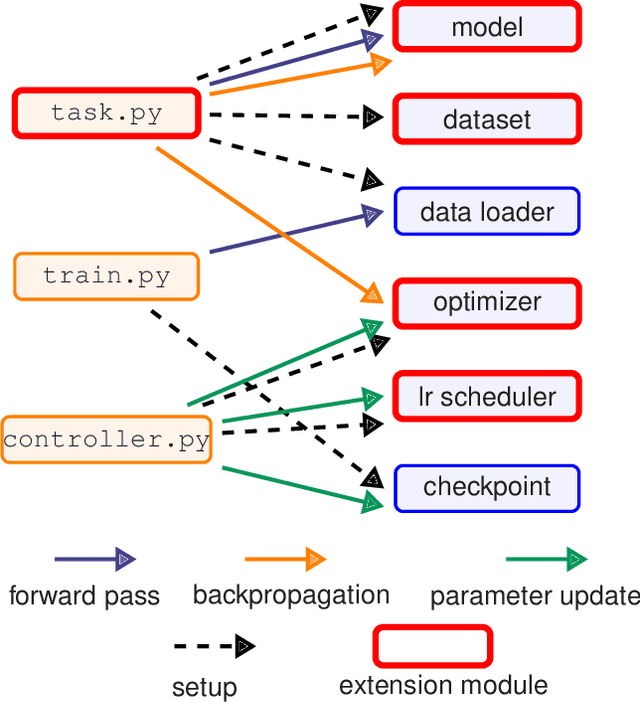

Modern deep learning systems like PyTorch and Tensorflow are able to train enormous models with billions (or trillions) of parameters on a distributed infrastructure. These systems require that the internal nodes have the same memory capacity and compute performance. Unfortunately, most organizations, especially universities, have a piecemeal approach to purchasing computer systems resulting in a heterogeneous infrastructure, which cannot be used to compute large models. The present work describes HetSeq, a software package adapted from the popular PyTorch package that provides the capability to train large neural network models on heterogeneous infrastructure. Experiments with transformer translation and BERT language model shows that HetSeq scales over heterogeneous systems. HetSeq can be easily extended to other models like image classification. Package with supported document is publicly available at https://github.com/yifding/hetseq.
Self-Supervised Out-of-Distribution Detection in Brain CT Scans
Nov 10, 2020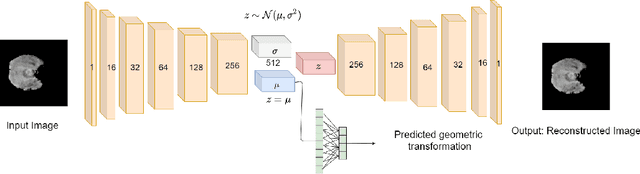

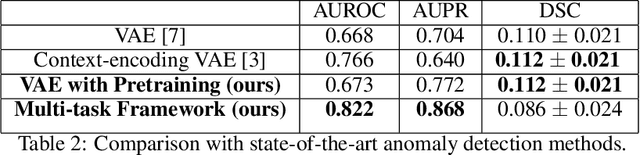
Medical imaging data suffers from the limited availability of annotation because annotating 3D medical data is a time-consuming and expensive task. Moreover, even if the annotation is available, supervised learning-based approaches suffer highly imbalanced data. Most of the scans during the screening are from normal subjects, but there are also large variations in abnormal cases. To address these issues, recently, unsupervised deep anomaly detection methods that train the model on large-sized normal scans and detect abnormal scans by calculating reconstruction error have been reported. In this paper, we propose a novel self-supervised learning technique for anomaly detection. Our architecture largely consists of two parts: 1) Reconstruction and 2) predicting geometric transformations. By training the network to predict geometric transformations, the model could learn better image features and distribution of normal scans. In the test time, the geometric transformation predictor can assign the anomaly score by calculating the error between geometric transformation and prediction. Moreover, we further use self-supervised learning with context restoration for pretraining our model. By comparative experiments on clinical brain CT scans, the effectiveness of the proposed method has been verified.