 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Auto-Context Deformable Registration Network for Infant Brain MRI
May 19, 2020
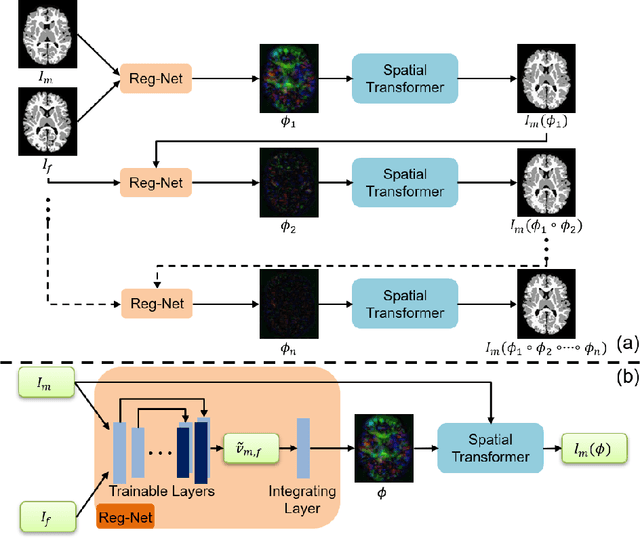
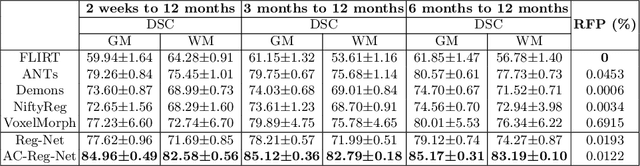
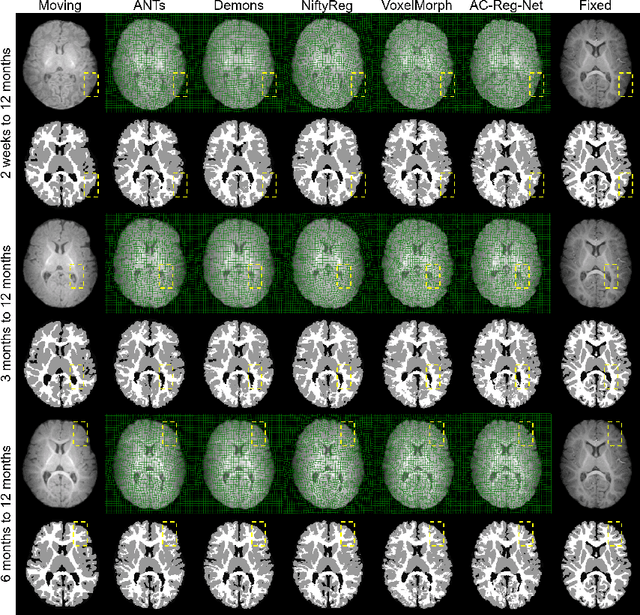
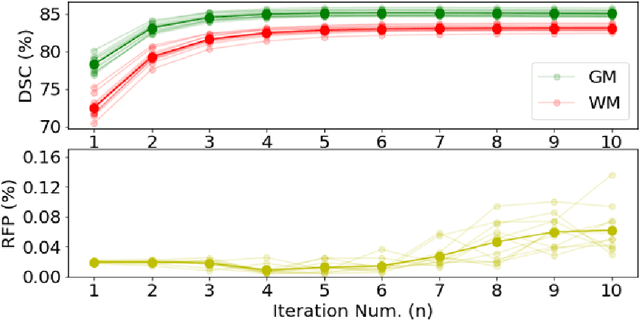
Deformable image registration is fundamental to longitudinal and population analysis. Geometric alignment of the infant brain MR images is challenging, owing to rapid changes in image appearance in association with brain development. In this paper, we propose an infant-dedicated deep registration network that uses the auto-context strategy to gradually refine the deformation fields to obtain highly accurate correspondences. Instead of training multiple registration networks, our method estimates the deformation fields by invoking a single network multiple times for iterative deformation refinement. The final deformation field is obtained by the incremental composition of the deformation fields. Experimental results in comparison with state-of-the-art registration methods indicate that our method achieves higher accuracy while at the same time preserves the smoothness of the deformation fields. Our implementation is available online.
A Few-Shot Sequential Approach for Object Counting
Jul 07, 2020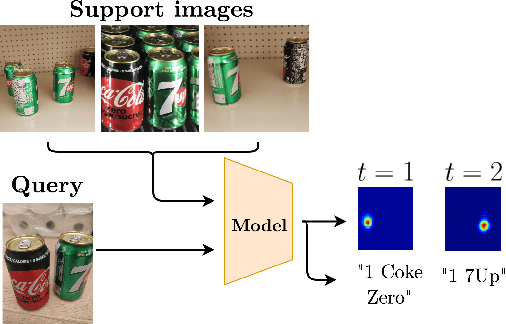
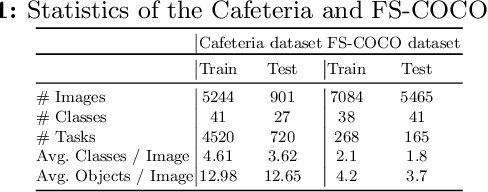
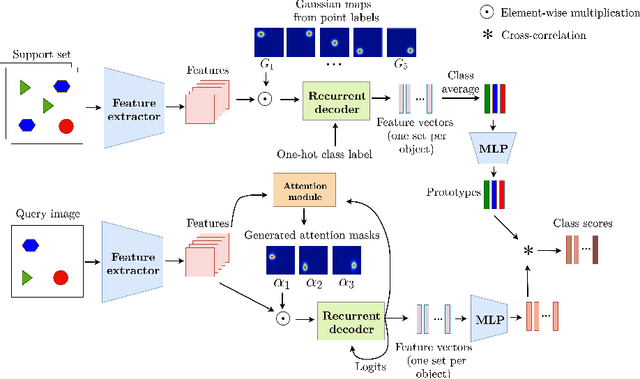
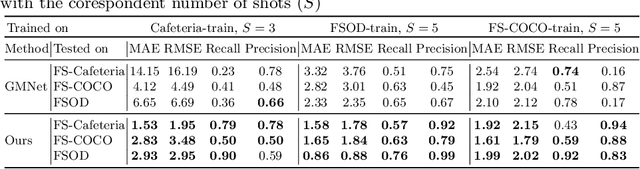
In this work, we address the problem of few-shot multi-class object counting with point-level annotations. The proposed technique leverages a class agnostic attention mechanism that sequentially attends to objects in the image and extracts their relevant features. This process is employed on an adapted prototypical-based few-shot approach that uses the extracted features to classify each one either as one of the classes present in the support set images or as background. The proposed technique is trained on point-level annotations and uses a novel loss function that disentangles class-dependent and class-agnostic aspects of the model to help with the task of few-shot object counting. We present our results on a variety of object-counting/detection datasets, including FSOD and MS COCO. In addition, we introduce a new dataset that is specifically designed for weakly supervised multi-class object counting/detection and contains considerably different classes and distribution of number of classes/instances per image compared to the existing datasets. We demonstrate the robustness of our approach by testing our system on a totally different distribution of classes from what it has been trained on.
DE-GAN: A Conditional Generative Adversarial Network for Document Enhancement
Oct 17, 2020
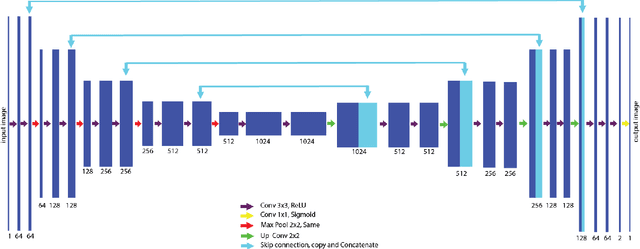
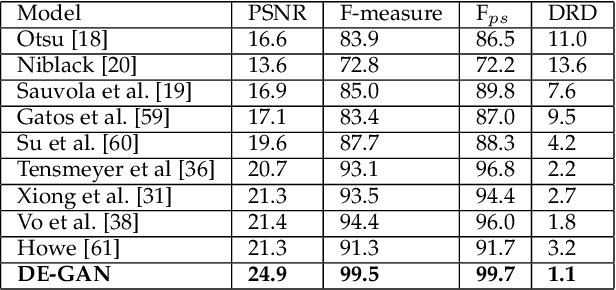
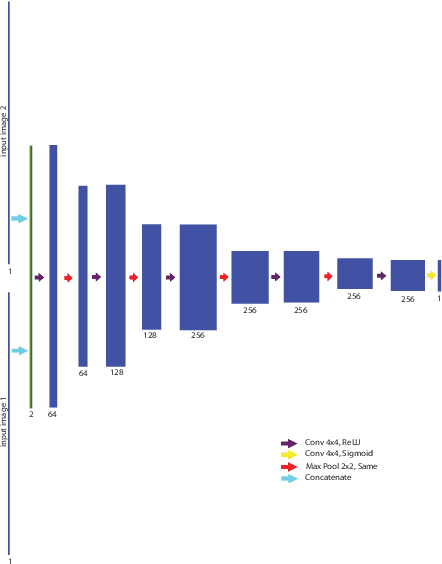
Documents often exhibit various forms of degradation, which make it hard to be read and substantially deteriorate the performance of an OCR system. In this paper, we propose an effective end-to-end framework named Document Enhancement Generative Adversarial Networks (DE-GAN) that uses the conditional GANs (cGANs) to restore severely degraded document images. To the best of our knowledge, this practice has not been studied within the context of generative adversarial deep networks. We demonstrate that, in different tasks (document clean up, binarization, deblurring and watermark removal), DE-GAN can produce an enhanced version of the degraded document with a high quality. In addition, our approach provides consistent improvements compared to state-of-the-art methods over the widely used DIBCO 2013, DIBCO 2017 and H-DIBCO 2018 datasets, proving its ability to restore a degraded document image to its ideal condition. The obtained results on a wide variety of degradation reveal the flexibility of the proposed model to be exploited in other document enhancement problems.
Modality-Balanced Models for Visual Dialogue
Jan 17, 2020

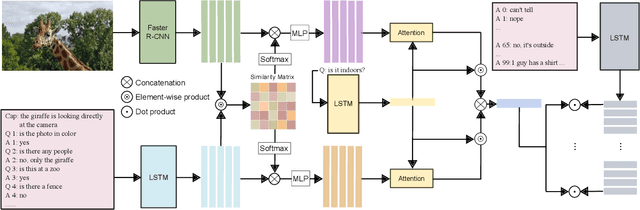
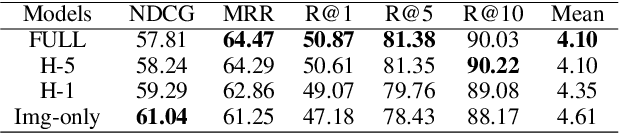
The Visual Dialog task requires a model to exploit both image and conversational context information to generate the next response to the dialogue. However, via manual analysis, we find that a large number of conversational questions can be answered by only looking at the image without any access to the context history, while others still need the conversation context to predict the correct answers. We demonstrate that due to this reason, previous joint-modality (history and image) models over-rely on and are more prone to memorizing the dialogue history (e.g., by extracting certain keywords or patterns in the context information), whereas image-only models are more generalizable (because they cannot memorize or extract keywords from history) and perform substantially better at the primary normalized discounted cumulative gain (NDCG) task metric which allows multiple correct answers. Hence, this observation encourages us to explicitly maintain two models, i.e., an image-only model and an image-history joint model, and combine their complementary abilities for a more balanced multimodal model. We present multiple methods for this integration of the two models, via ensemble and consensus dropout fusion with shared parameters. Empirically, our models achieve strong results on the Visual Dialog challenge 2019 (rank 3 on NDCG and high balance across metrics), and substantially outperform the winner of the Visual Dialog challenge 2018 on most metrics.
Variational Dynamic for Self-Supervised Exploration in Deep Reinforcement Learning
Oct 17, 2020
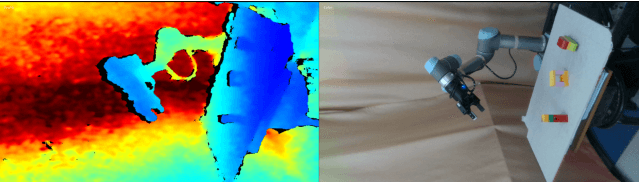
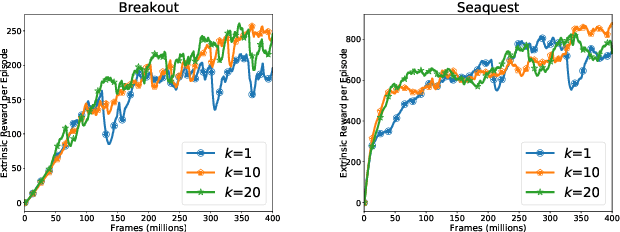
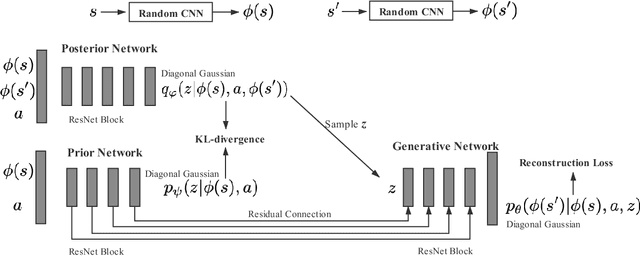
Efficient exploration remains a challenging problem in reinforcement learning, especially for tasks where extrinsic rewards from environments are sparse or even totally disregarded. Significant advances based on intrinsic motivation show promising results in simple environments but often get stuck in environments with multimodal and stochastic dynamics. In this work, we propose a variational dynamic model based on the conditional variational inference to model the multimodality and stochasticity. We consider the environmental state-action transition as a conditional generative process by generating the next-state prediction under the condition of the current state, action, and latent variable. We derive an upper bound of the negative log-likelihood of the environmental transition and use such an upper bound as the intrinsic reward for exploration, which allows the agent to learn skills by self-supervised exploration without observing extrinsic rewards. We evaluate the proposed method on several image-based simulation tasks and a real robotic manipulating task. Our method outperforms several state-of-the-art environment model-based exploration approaches.
HetSeq: Distributed GPU Training on Heterogeneous Infrastructure
Sep 25, 2020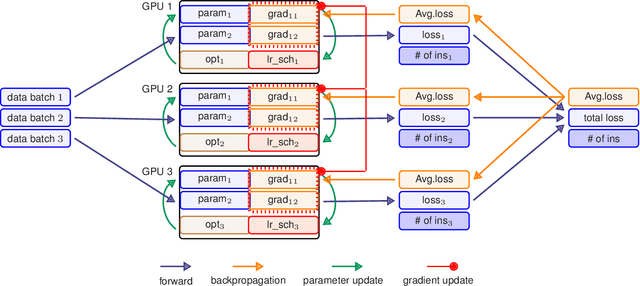
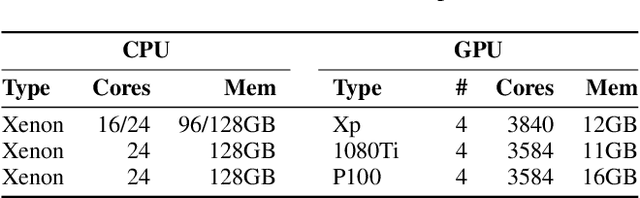
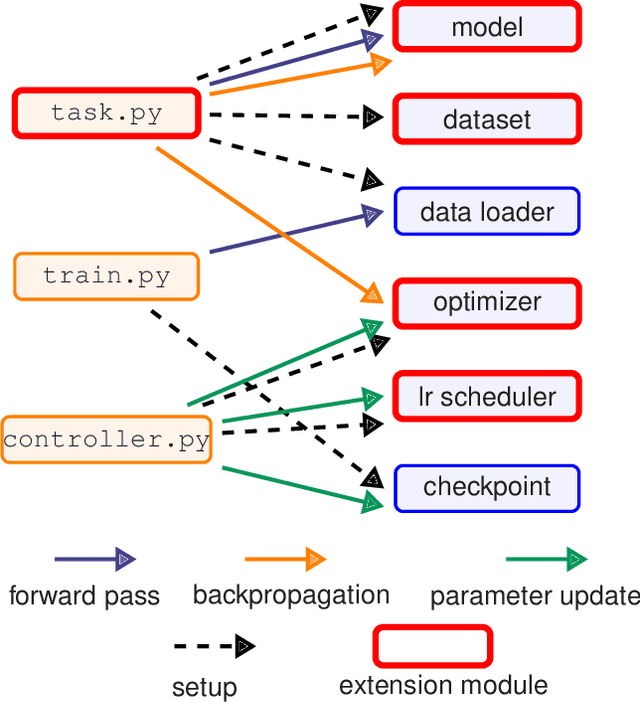

Modern deep learning systems like PyTorch and Tensorflow are able to train enormous models with billions (or trillions) of parameters on a distributed infrastructure. These systems require that the internal nodes have the same memory capacity and compute performance. Unfortunately, most organizations, especially universities, have a piecemeal approach to purchasing computer systems resulting in a heterogeneous infrastructure, which cannot be used to compute large models. The present work describes HetSeq, a software package adapted from the popular PyTorch package that provides the capability to train large neural network models on heterogeneous infrastructure. Experiments with transformer translation and BERT language model shows that HetSeq scales over heterogeneous systems. HetSeq can be easily extended to other models like image classification. Package with supported document is publicly available at https://github.com/yifding/hetseq.
Explaining AI-based Decision Support Systems using Concept Localization Maps
May 04, 2020
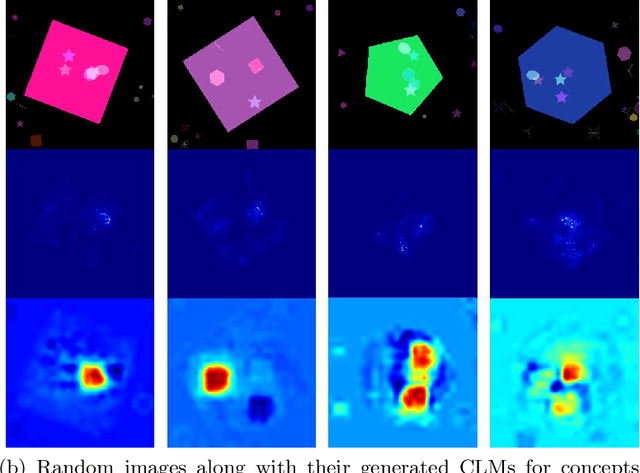
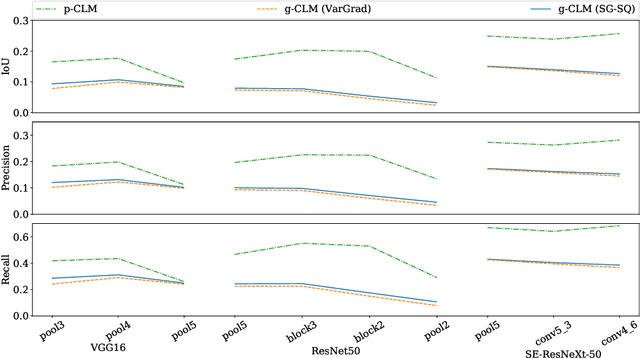

Human-centric explainability of AI-based Decision Support Systems (DSS) using visual input modalities is directly related to reliability and practicality of such algorithms. An otherwise accurate and robust DSS might not enjoy trust of experts in critical application areas if it is not able to provide reasonable justification of its predictions. This paper introduces Concept Localization Maps (CLMs), which is a novel approach towards explainable image classifiers employed as DSS. CLMs extend Concept Activation Vectors (CAVs) by locating significant regions corresponding to a learned concept in the latent space of a trained image classifier. They provide qualitative and quantitative assurance of a classifier's ability to learn and focus on similar concepts important for humans during image recognition. To better understand the effectiveness of the proposed method, we generated a new synthetic dataset called Simple Concept DataBase (SCDB) that includes annotations for 10 distinguishable concepts, and made it publicly available. We evaluated our proposed method on SCDB as well as a real-world dataset called CelebA. We achieved localization recall of above 80% for most relevant concepts and average recall above 60% for all concepts using SE-ResNeXt-50 on SCDB. Our results on both datasets show great promise of CLMs for easing acceptance of DSS in practice.
Deep Learning Classification With Noisy Labels
Apr 23, 2020
Deep Learning systems have shown tremendous accuracy in image classification, at the cost of big image datasets. Collecting such amounts of data can lead to labelling errors in the training set. Indexing multimedia content for retrieval, classification or recommendation can involve tagging or classification based on multiple criteria. In our case, we train face recognition systems for actors identification with a closed set of identities while being exposed to a significant number of perturbators (actors unknown to our database). Face classifiers are known to be sensitive to label noise. We review recent works on how to manage noisy annotations when training deep learning classifiers, independently from our interest in face recognition.
Phase Consistent Ecological Domain Adaptation
Apr 10, 2020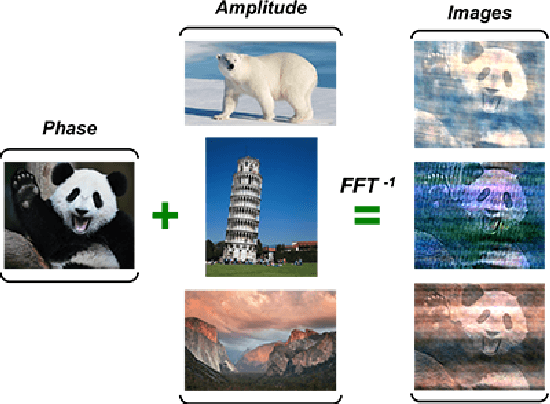
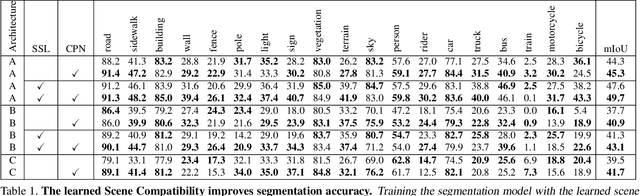

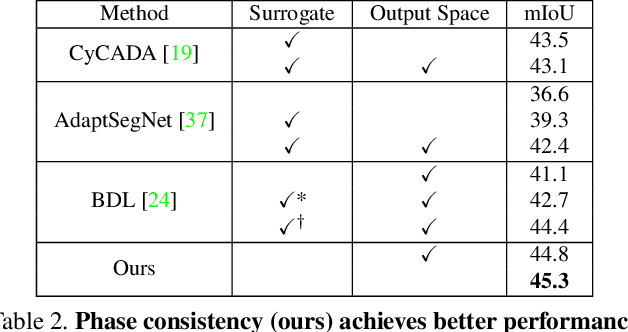
We introduce two criteria to regularize the optimization involved in learning a classifier in a domain where no annotated data are available, leveraging annotated data in a different domain, a problem known as unsupervised domain adaptation. We focus on the task of semantic segmentation, where annotated synthetic data are aplenty, but annotating real data is laborious. The first criterion, inspired by visual psychophysics, is that the map between the two image domains be phase-preserving. This restricts the set of possible learned maps, while enabling enough flexibility to transfer semantic information. The second criterion aims to leverage ecological statistics, or regularities in the scene which are manifest in any image of it, regardless of the characteristics of the illuminant or the imaging sensor. It is implemented using a deep neural network that scores the likelihood of each possible segmentation given a single un-annotated image. Incorporating these two priors in a standard domain adaptation framework improves performance across the board in the most common unsupervised domain adaptation benchmarks for semantic segmentation.
Image Retargeting by Content-Aware Synthesis
Aug 21, 2014

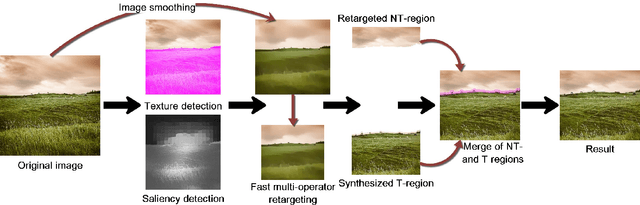

Real-world images usually contain vivid contents and rich textural details, which will complicate the manipulation on them. In this paper, we design a new framework based on content-aware synthesis to enhance content-aware image retargeting. By detecting the textural regions in an image, the textural image content can be synthesized rather than simply distorted or cropped. This method enables the manipulation of textural & non-textural regions with different strategy since they have different natures. We propose to retarget the textural regions by content-aware synthesis and non-textural regions by fast multi-operators. To achieve practical retargeting applications for general images, we develop an automatic and fast texture detection method that can detect multiple disjoint textural regions. We adjust the saliency of the image according to the features of the textural regions. To validate the proposed method, comparisons with state-of-the-art image targeting techniques and a user study were conducted. Convincing visual results are shown to demonstrate the effectiveness of the proposed method.