 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Investigating the Effect of Emoji in Opinion Classification of Uzbek Movie Review Comments
Aug 02, 2020
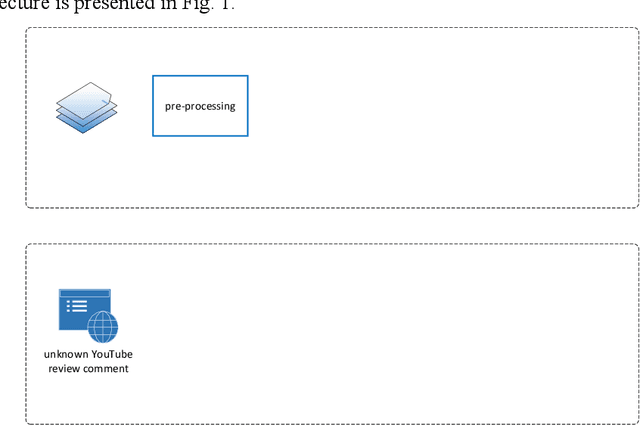
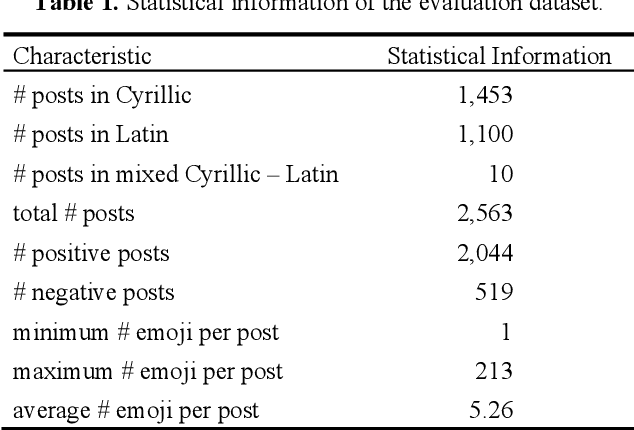
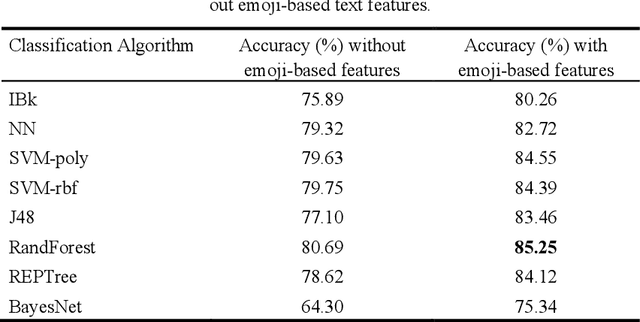
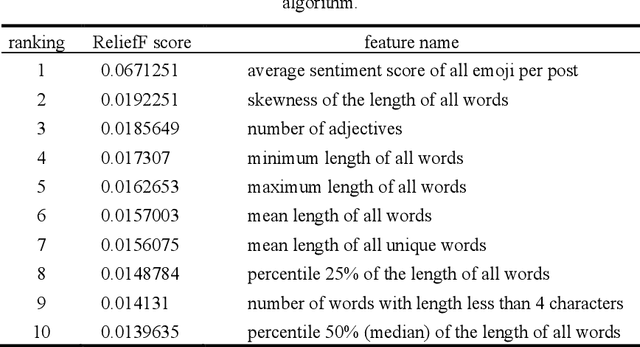
Opinion mining on social media posts has become more and more popular. Users often express their opinion on a topic not only with words but they also use image symbols such as emoticons and emoji. In this paper, we investigate the effect of emoji-based features in opinion classification of Uzbek texts, and more specifically movie review comments from YouTube. Several classification algorithms are tested, and feature ranking is performed to evaluate the discriminative ability of the emoji-based features.
Text Recognition in Scene Image and Video Frame using Color Channel Selection
Jul 27, 2017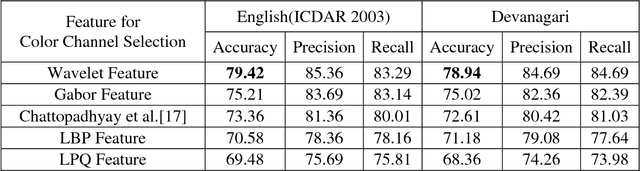
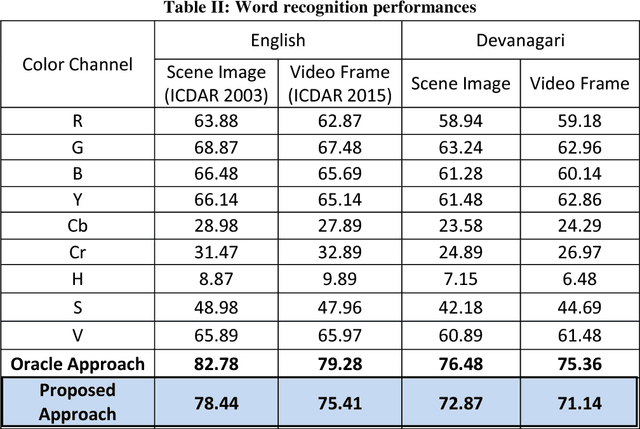
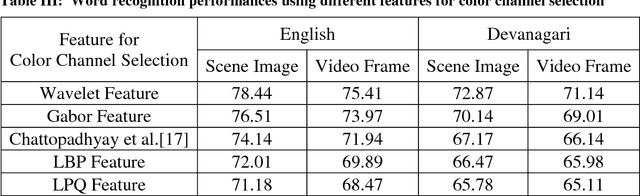
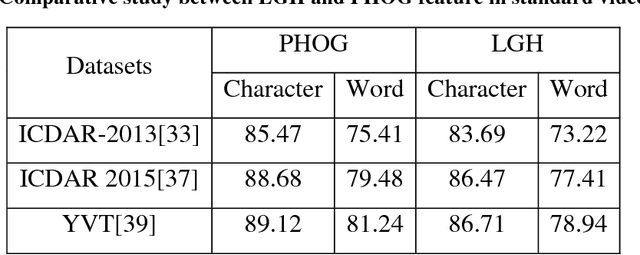
In recent years, recognition of text from natural scene image and video frame has got increased attention among the researchers due to its various complexities and challenges. Because of low resolution, blurring effect, complex background, different fonts, color and variant alignment of text within images and video frames, etc., text recognition in such scenario is difficult. Most of the current approaches usually apply a binarization algorithm to convert them into binary images and next OCR is applied to get the recognition result. In this paper, we present a novel approach based on color channel selection for text recognition from scene images and video frames. In the approach, at first, a color channel is automatically selected and then selected color channel is considered for text recognition. Our text recognition framework is based on Hidden Markov Model (HMM) which uses Pyramidal Histogram of Oriented Gradient features extracted from selected color channel. From each sliding window of a color channel our color-channel selection approach analyzes the image properties from the sliding window and then a multi-label Support Vector Machine (SVM) classifier is applied to select the color channel that will provide the best recognition results in the sliding window. This color channel selection for each sliding window has been found to be more fruitful than considering a single color channel for the whole word image. Five different features have been analyzed for multi-label SVM based color channel selection where wavelet transform based feature outperforms others. Our framework has been tested on different publicly available scene/video text image datasets. For Devanagari script, we collected our own data dataset. The performances obtained from experimental results are encouraging and show the advantage of the proposed method.
Privacy Preserving Visual SLAM
Jul 20, 2020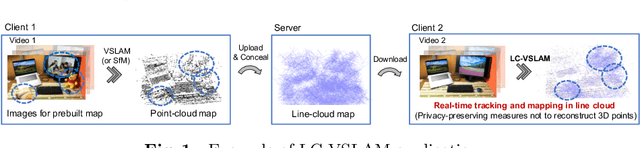

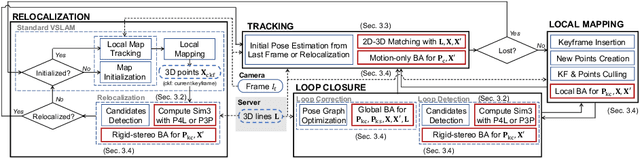

This study proposes a privacy-preserving Visual SLAM framework for estimating camera poses and performing bundle adjustment with mixed line and point clouds in real time. Previous studies have proposed localization methods to estimate a camera pose using a line-cloud map for a single image or a reconstructed point cloud. These methods offer a scene privacy protection against the inversion attacks by converting a point cloud to a line cloud, which reconstruct the scene images from the point cloud. However, they are not directly applicable to a video sequence because they do not address computational efficiency. This is a critical issue to solve for estimating camera poses and performing bundle adjustment with mixed line and point clouds in real time. Moreover, there has been no study on a method to optimize a line-cloud map of a server with a point cloud reconstructed from a client video because any observation points on the image coordinates are not available to prevent the inversion attacks, namely the reversibility of the 3D lines. The experimental results with synthetic and real data show that our Visual SLAM framework achieves the intended privacy-preserving formation and real-time performance using a line-cloud map.
Tele-operative Robotic Lung Ultrasound Scanning Platform for Triage of COVID-19 Patients
Nov 12, 2020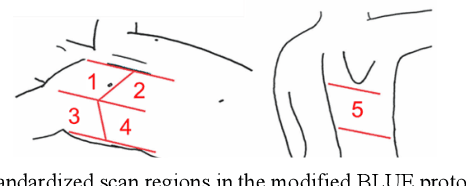
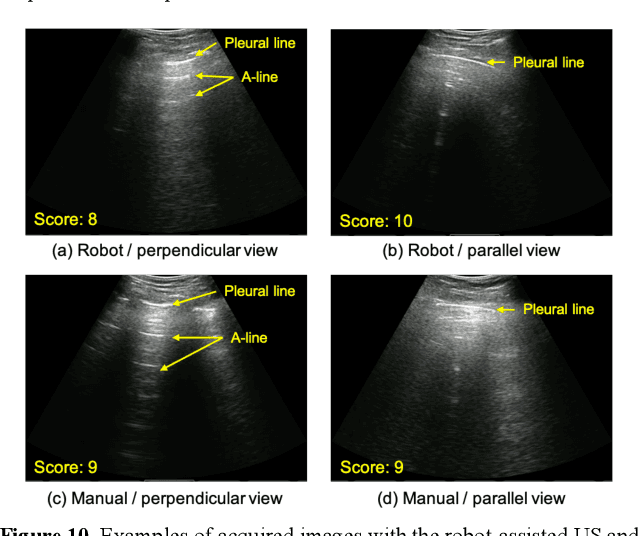
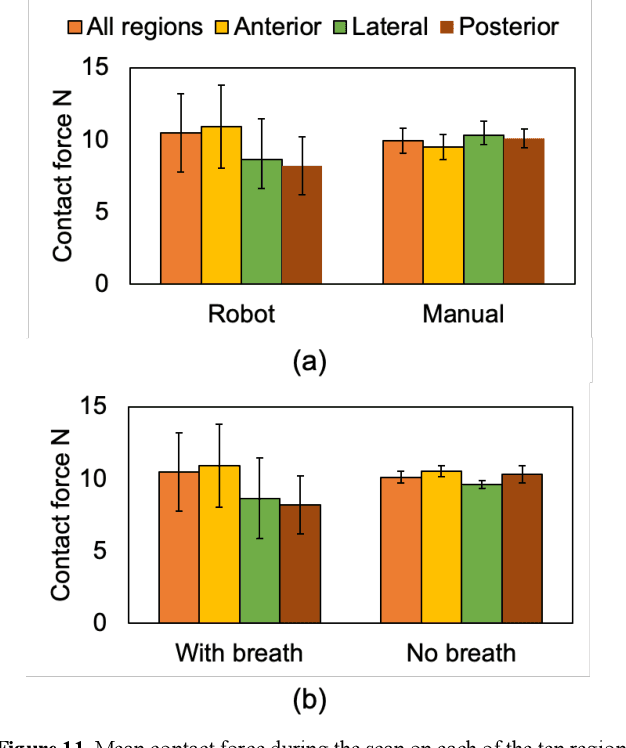
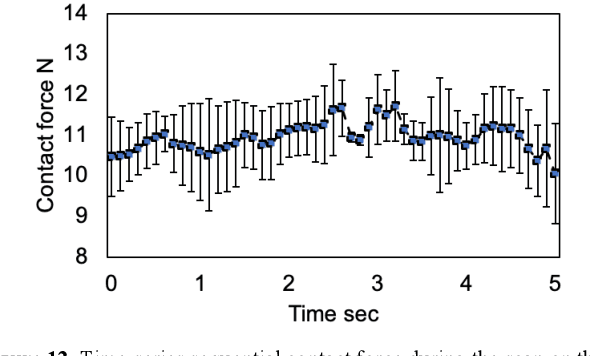
Novel severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) has become a pandemic of epic proportions and a global response to prepare health systems worldwide is of utmost importance. In addition to its cost-effectiveness in a resources-limited setting, lung ultrasound (LUS) has emerged as a rapid noninvasive imaging tool for the diagnosis of COVID-19 infected patients. Concerns surrounding LUS include the disparity of infected patients and healthcare providers, relatively small number of physicians and sonographers capable of performing LUS, and most importantly, the requirement for substantial physical contact between the patient and operator, increasing the risk of transmission. Mitigation of the spread of the virus is of paramount importance. A 2-dimensional (2D) tele-operative robotic platform capable of performing LUS in for COVID-19 infected patients may be of significant benefit. The authors address the aforementioned issues surrounding the use of LUS in the application of COVID- 19 infected patients. In addition, first time application, feasibility and safety were validated in three healthy subjects, along with 2D image optimization and comparison for overall accuracy. Preliminary results demonstrate that the proposed platform allows for successful acquisition and application of LUS in humans.
An Overview of Two Age Synthesis and Estimation Techniques
Jan 26, 2020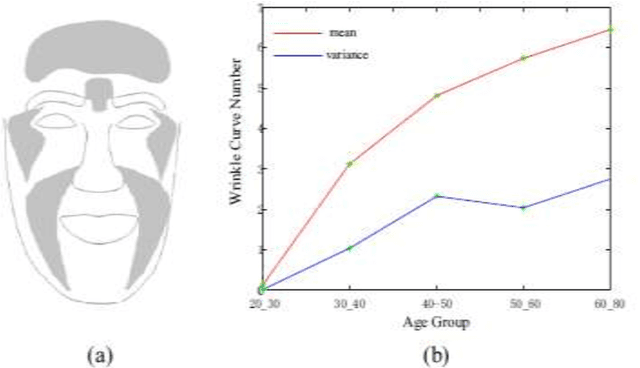
Age estimation is a technique for predicting human ages from digital facial images, which analyzes a person's face image and estimates his/her age based on the year measure. Nowadays, intelligent age estimation and age synthesis have become particularly prevalent research topics in computer vision and face verification systems. Age synthesis is defined to render a facial image aesthetically with rejuvenating and natural aging effects on the person's face. Age estimation is defined to label a facial image automatically with the age group (year range) or the exact age (year) of the person's face. In this case study, we overview the existing models, popular techniques, system performances, and technical challenges related to the facial image-based age synthesis and estimation topics. The main goal of this review is to provide an easy understanding and promising future directions with systematic discussions.
Deep Learning Classification With Noisy Labels
Apr 23, 2020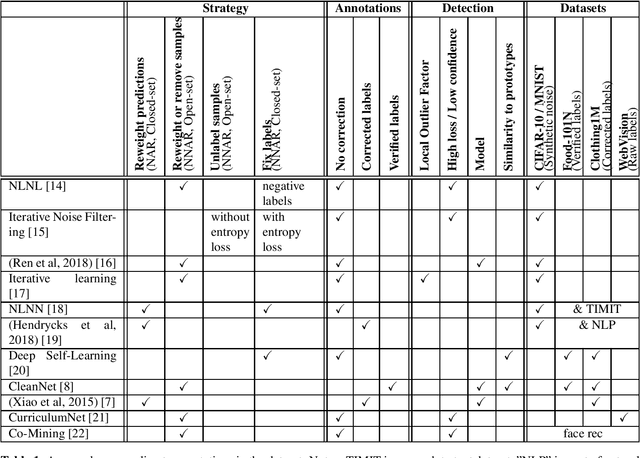
Deep Learning systems have shown tremendous accuracy in image classification, at the cost of big image datasets. Collecting such amounts of data can lead to labelling errors in the training set. Indexing multimedia content for retrieval, classification or recommendation can involve tagging or classification based on multiple criteria. In our case, we train face recognition systems for actors identification with a closed set of identities while being exposed to a significant number of perturbators (actors unknown to our database). Face classifiers are known to be sensitive to label noise. We review recent works on how to manage noisy annotations when training deep learning classifiers, independently from our interest in face recognition.
Phase Consistent Ecological Domain Adaptation
Apr 10, 2020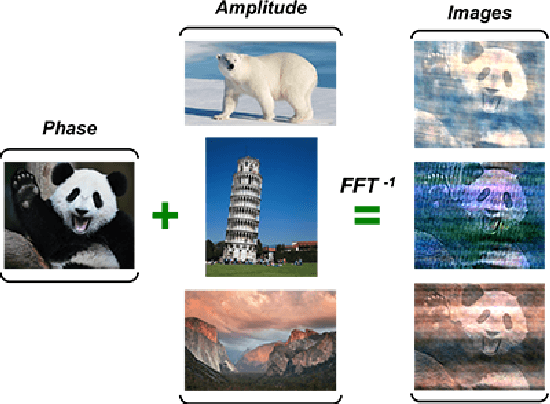
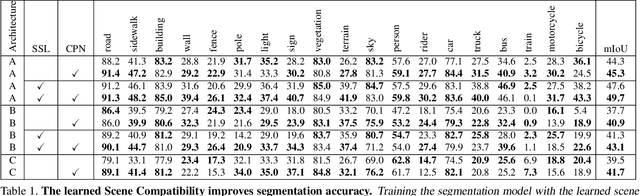

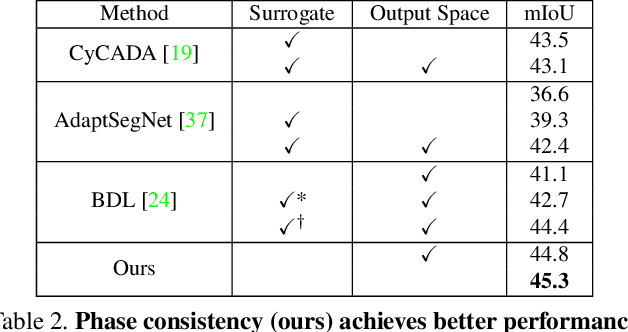
We introduce two criteria to regularize the optimization involved in learning a classifier in a domain where no annotated data are available, leveraging annotated data in a different domain, a problem known as unsupervised domain adaptation. We focus on the task of semantic segmentation, where annotated synthetic data are aplenty, but annotating real data is laborious. The first criterion, inspired by visual psychophysics, is that the map between the two image domains be phase-preserving. This restricts the set of possible learned maps, while enabling enough flexibility to transfer semantic information. The second criterion aims to leverage ecological statistics, or regularities in the scene which are manifest in any image of it, regardless of the characteristics of the illuminant or the imaging sensor. It is implemented using a deep neural network that scores the likelihood of each possible segmentation given a single un-annotated image. Incorporating these two priors in a standard domain adaptation framework improves performance across the board in the most common unsupervised domain adaptation benchmarks for semantic segmentation.
Learning Order Parameters from Videos of Dynamical Phases for Skyrmions with Neural Networks
Dec 02, 2020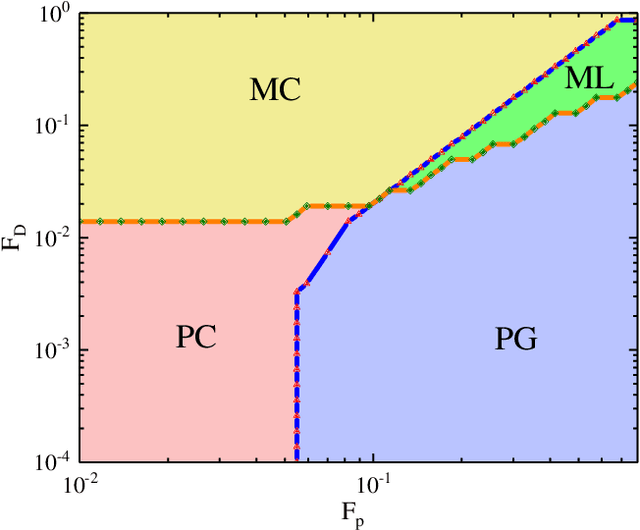

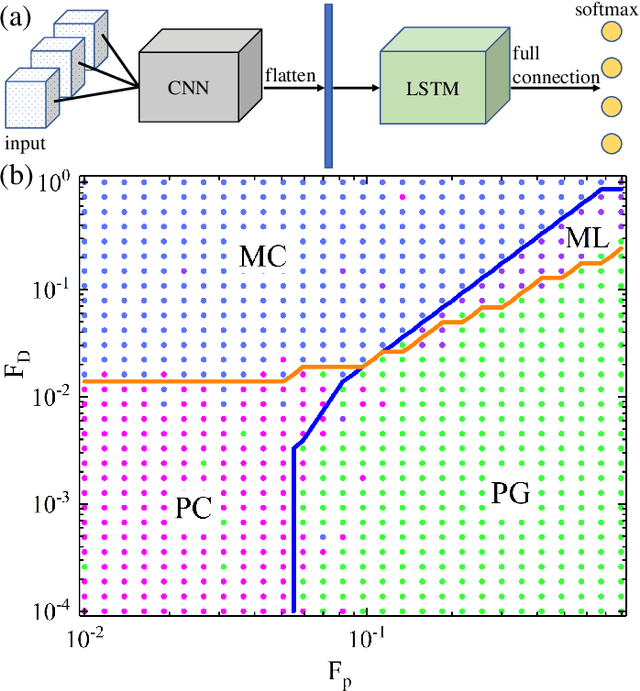
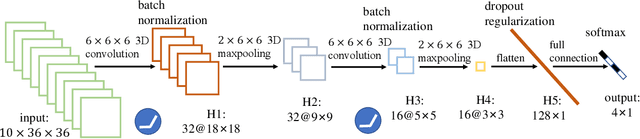
The ability to recognize dynamical phenomena (e.g., dynamical phases) and dynamical processes in physical events from videos, then to abstract physical concepts and reveal physical laws, lies at the core of human intelligence. The main purposes of this paper are to use neural networks for classifying the dynamical phases of some videos and to demonstrate that neural networks can learn physical concepts from them. To this end, we employ multiple neural networks to recognize the static phases (image format) and dynamical phases (video format) of a particle-based skyrmion model. Our results show that neural networks, without any prior knowledge, can not only correctly classify these phases, but also predict the phase boundaries which agree with those obtained by simulation. We further propose a parameter visualization scheme to interpret what neural networks have learned. We show that neural networks can learn two order parameters from videos of dynamical phases and predict the critical values of two order parameters. Finally, we demonstrate that only two order parameters are needed to identify videos of skyrmion dynamical phases. It shows that this parameter visualization scheme can be used to determine how many order parameters are needed to fully recognize the input phases. Our work sheds light on the future use of neural networks in discovering new physical concepts and revealing unknown yet physical laws from videos.
An Auto-Context Deformable Registration Network for Infant Brain MRI
May 19, 2020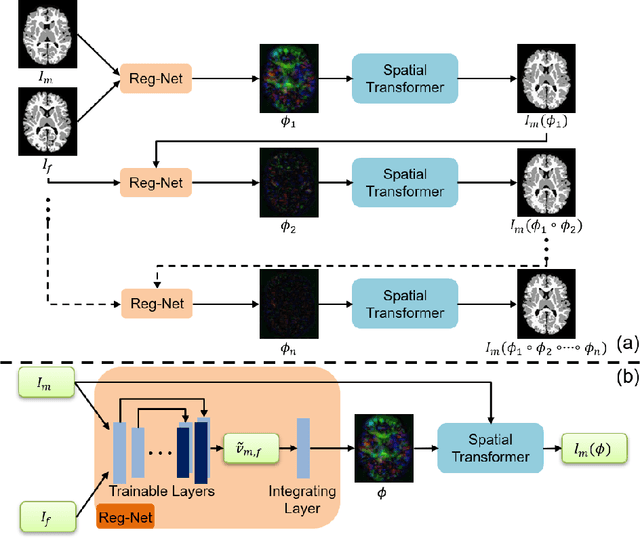
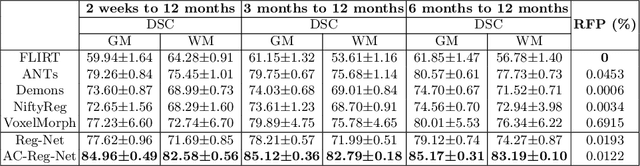
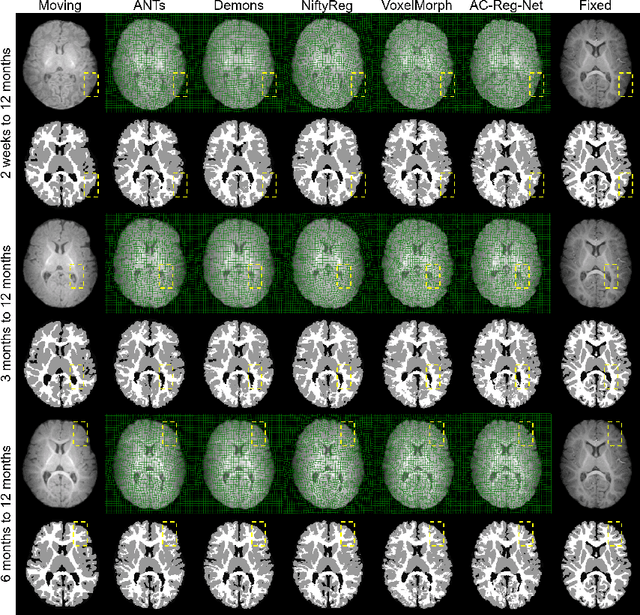
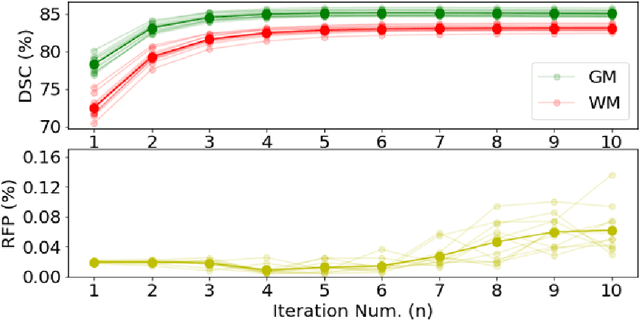
Deformable image registration is fundamental to longitudinal and population analysis. Geometric alignment of the infant brain MR images is challenging, owing to rapid changes in image appearance in association with brain development. In this paper, we propose an infant-dedicated deep registration network that uses the auto-context strategy to gradually refine the deformation fields to obtain highly accurate correspondences. Instead of training multiple registration networks, our method estimates the deformation fields by invoking a single network multiple times for iterative deformation refinement. The final deformation field is obtained by the incremental composition of the deformation fields. Experimental results in comparison with state-of-the-art registration methods indicate that our method achieves higher accuracy while at the same time preserves the smoothness of the deformation fields. Our implementation is available online.
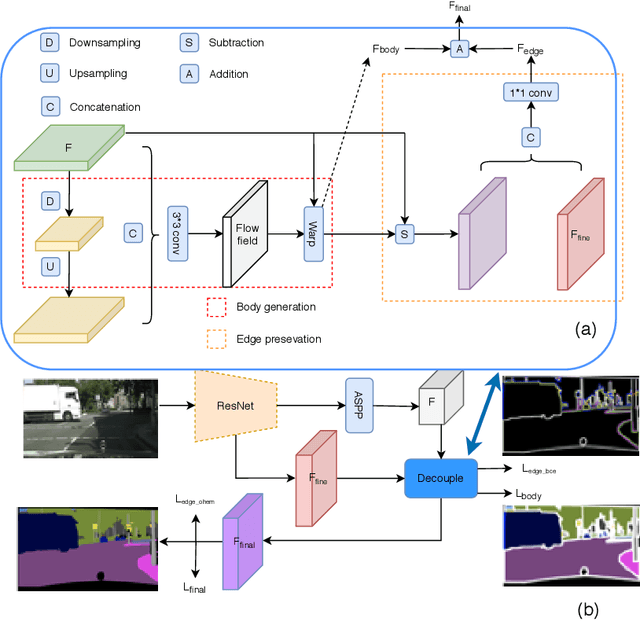
Improving Semantic Segmentation via Decoupled Body and Edge Supervision
Jul 20, 2020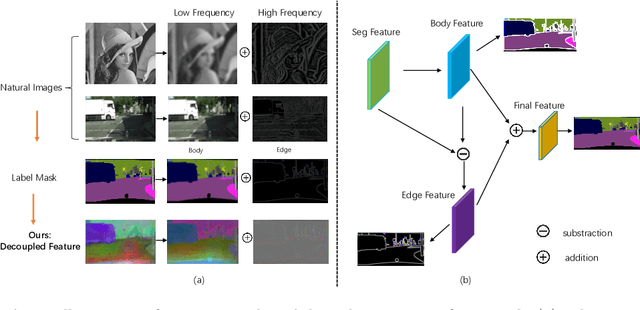
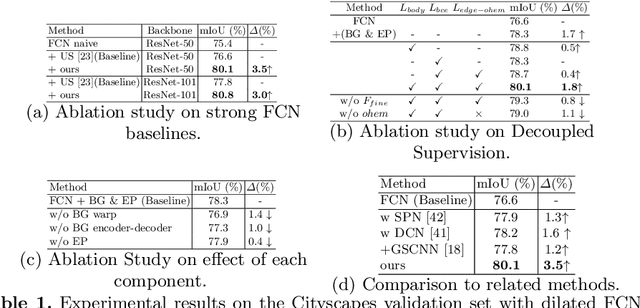

Existing semantic segmentation approaches either aim to improve the object's inner consistency by modeling the global context, or refine objects detail along their boundaries by multi-scale feature fusion. In this paper, a new paradigm for semantic segmentation is proposed. Our insight is that appealing performance of semantic segmentation requires \textit{explicitly} modeling the object \textit{body} and \textit{edge}, which correspond to the high and low frequency of the image. To do so, we first warp the image feature by learning a flow field to make the object part more consistent. The resulting body feature and the residual edge feature are further optimized under decoupled supervision by explicitly sampling different parts (body or edge) pixels. We show that the proposed framework with various baselines or backbone networks leads to better object inner consistency and object boundaries. Extensive experiments on four major road scene semantic segmentation benchmarks including \textit{Cityscapes}, \textit{CamVid}, \textit{KIITI} and \textit{BDD} show that our proposed approach establishes new state of the art while retaining high efficiency in inference. In particular, we achieve 83.7 mIoU \% on Cityscape with only fine-annotated data. Code and models are made available to foster any further research (\url{https://github.com/lxtGH/DecoupleSegNets}).