 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Data Augmentation via Mixed Class Interpolation using Cycle-Consistent Generative Adversarial Networks Applied to Cross-Domain Imagery
May 05, 2020
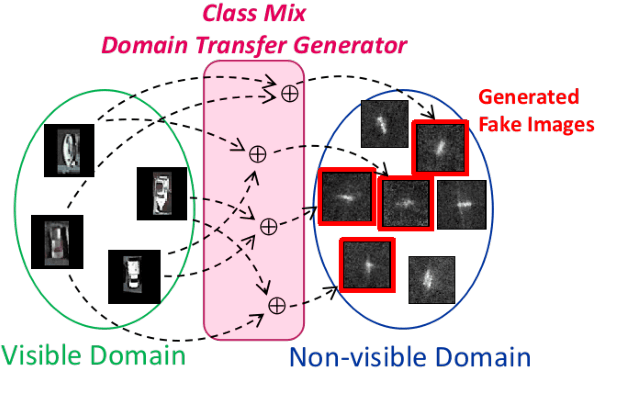
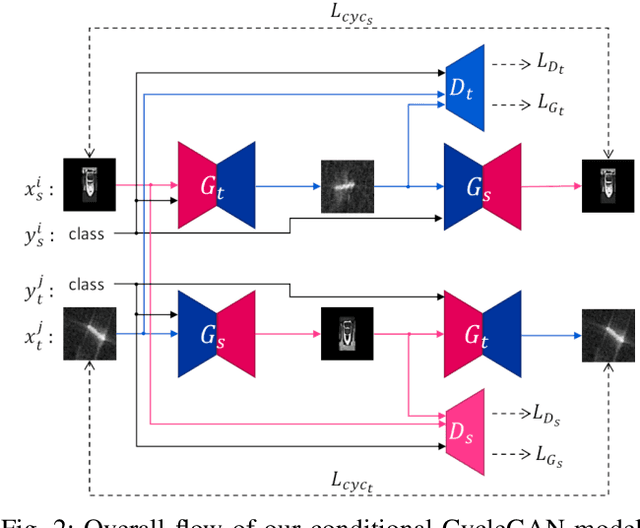


Machine learning driven object detection and classification within non-visible imagery has an important role in many fields such as night vision, all-weather surveillance and aviation security. However, such applications often suffer due to the limited quantity and variety of non-visible spectral domain imagery, where by contrast the high data availability in visible-band imagery readily enables contemporary deep learning driven detection and classification approaches. To address this problem, this paper proposes and evaluates a novel data augmentation approach that leverages the more readily available visible-band imagery via a generative domain transfer model. The model can synthesise large volumes of non-visible domain imagery by image translation from the visible image domain. Furthermore, we show that the generation of interpolated mixed class (non-visible domain) image examples via our novel Conditional CycleGAN Mixup Augmentation (C2GMA) methodology can lead to a significant improvement in the quality for non-visible domain classification tasks that otherwise suffer due to limited data availability. Focusing on classification within the Synthetic Aperture Radar (SAR) domain, our approach is evaluated on a variation of the Statoil/C-CORE Iceberg Classifier Challenge dataset and achieves 75.4% accuracy, demonstrating a significant improvement when compared against traditional data augmentation strategies.
Data Augmentation with norm-VAE for Unsupervised Domain Adaptation
Dec 01, 2020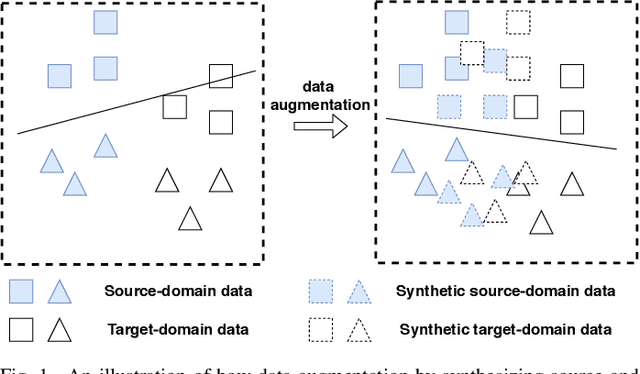
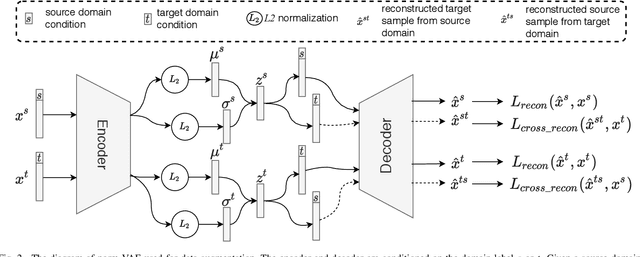

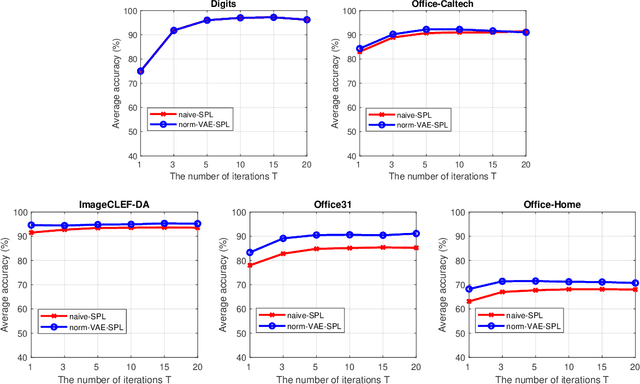
We address the Unsupervised Domain Adaptation (UDA) problem in image classification from a new perspective. In contrast to most existing works which either align the data distributions or learn domain-invariant features, we directly learn a unified classifier for both domains within a high-dimensional homogeneous feature space without explicit domain adaptation. To this end, we employ the effective Selective Pseudo-Labelling (SPL) techniques to take advantage of the unlabelled samples in the target domain. Surprisingly, data distribution discrepancy across the source and target domains can be well handled by a computationally simple classifier (e.g., a shallow Multi-Layer Perceptron) trained in the original feature space. Besides, we propose a novel generative model norm-VAE to generate synthetic features for the target domain as a data augmentation strategy to enhance classifier training. Experimental results on several benchmark datasets demonstrate the pseudo-labelling strategy itself can lead to comparable performance to many state-of-the-art methods whilst the use of norm-VAE for feature augmentation can further improve the performance in most cases. As a result, our proposed methods (i.e. naive-SPL and norm-VAE-SPL) can achieve new state-of-the-art performance with the average accuracy of 93.4% and 90.4% on Office-Caltech and ImageCLEF-DA datasets, and comparable performance on Digits, Office31 and Office-Home datasets with the average accuracy of 97.2%, 87.6% and 67.9% respectively.
Words as Art Materials: Generating Paintings with Sequential GANs
Jul 08, 2020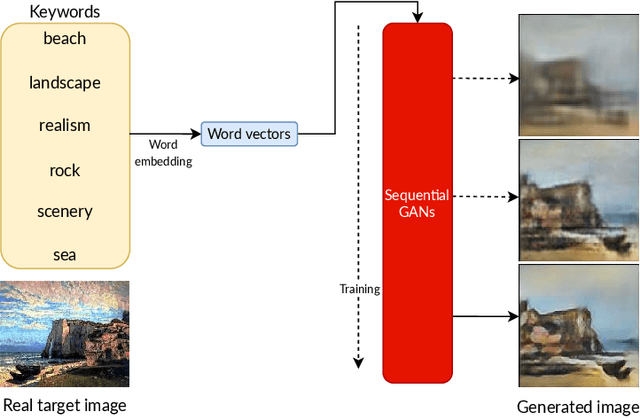
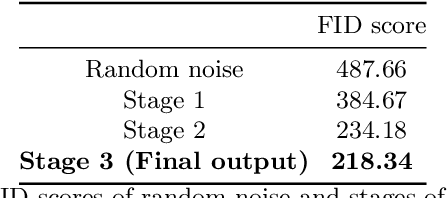
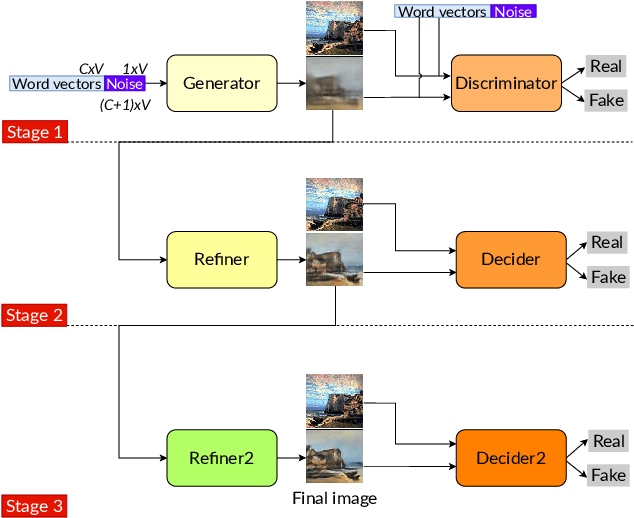
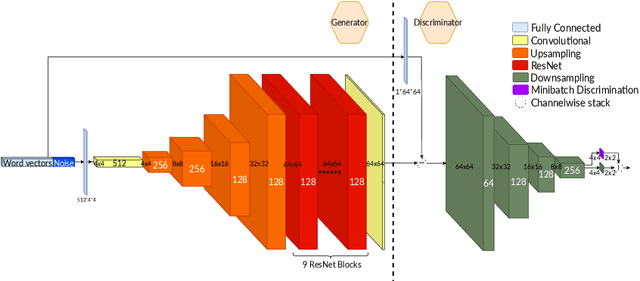
Converting text descriptions into images using Generative Adversarial Networks has become a popular research area. Visually appealing images have been generated successfully in recent years. Inspired by these studies, we investigated the generation of artistic images on a large variance dataset. This dataset includes images with variations, for example, in shape, color, and content. These variations in images provide originality which is an important factor for artistic essence. One major characteristic of our work is that we used keywords as image descriptions, instead of sentences. As the network architecture, we proposed a sequential Generative Adversarial Network model. The first stage of this sequential model processes the word vectors and creates a base image whereas the next stages focus on creating high-resolution artistic-style images without working on word vectors. To deal with the unstable nature of GANs, we proposed a mixture of techniques like Wasserstein loss, spectral normalization, and minibatch discrimination. Ultimately, we were able to generate painting images, which have a variety of styles. We evaluated our results by using the Fr\'echet Inception Distance score and conducted a user study with 186 participants.
Image denoising through bivariate shrinkage function in framelet domain
Jan 02, 2018

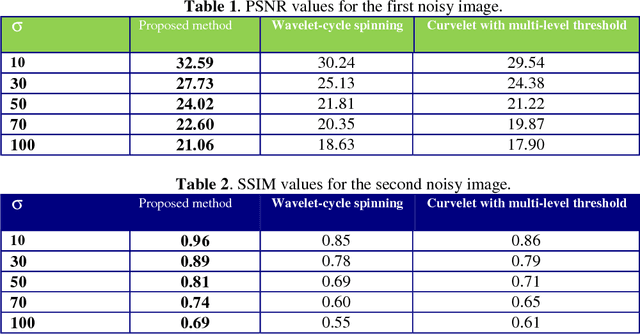
Denoising of coefficients in a sparse domain (e.g. wavelet) has been researched extensively because of its simplicity and effectiveness. Literature mainly has focused on designing the best global threshold. However, this paper proposes a new denoising method using bivariate shrinkage function in framelet domain. In the proposed method, maximum aposteriori probability is used for estimate of the denoised coefficient and non-Gaussian bivariate function is applied to model the statistics of framelet coefficients. For every framelet coefficient, there is a corresponding threshold depending on the local statistics of framelet coefficients. Experimental results show that using bivariate shrinkage function in framelet domain yields significantly superior image quality and higher PSNR than some well-known denoising methods.
GuCNet: A Guided Clustering-based Network for Improved Classification
Oct 11, 2020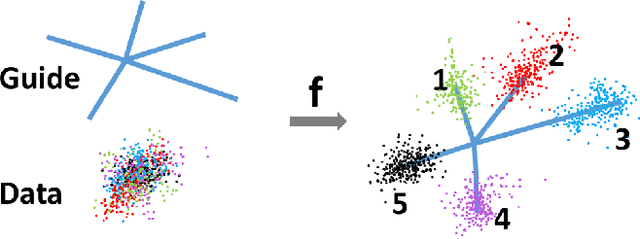
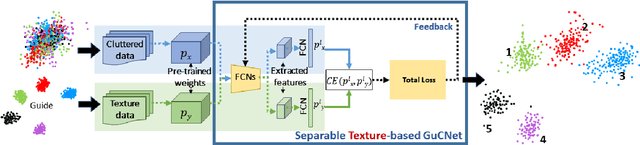
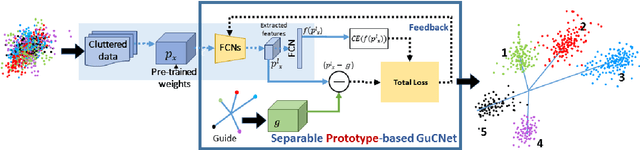

We deal with the problem of semantic classification of challenging and highly-cluttered dataset. We present a novel, and yet a very simple classification technique by leveraging the ease of classifiability of any existing well separable dataset for guidance. Since the guide dataset which may or may not have any semantic relationship with the experimental dataset, forms well separable clusters in the feature set, the proposed network tries to embed class-wise features of the challenging dataset to those distinct clusters of the guide set, making them more separable. Depending on the availability, we propose two types of guide sets: one using texture (image) guides and another using prototype vectors representing cluster centers. Experimental results obtained on the challenging benchmark RSSCN, LSUN, and TU-Berlin datasets establish the efficacy of the proposed method as we outperform the existing state-of-the-art techniques by a considerable margin.
On Improving the Generalization of Face Recognition in the Presence of Occlusions
Jun 11, 2020

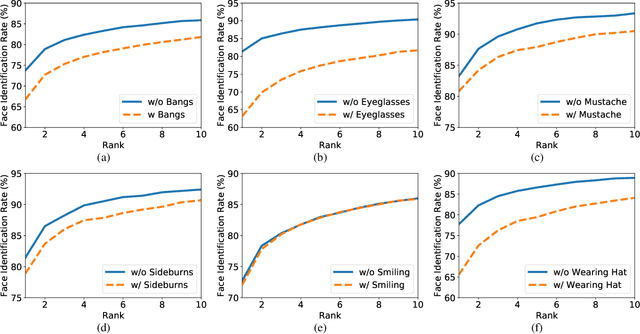

In this paper, we address a key limitation of existing 2D face recognition methods: robustness to occlusions. To accomplish this task, we systematically analyzed the impact of facial attributes on the performance of a state-of-the-art face recognition method and through extensive experimentation, quantitatively analyzed the performance degradation under different types of occlusion. Our proposed Occlusion-aware face REcOgnition (OREO) approach learned discriminative facial templates despite the presence of such occlusions. First, an attention mechanism was proposed that extracted local identity-related region. The local features were then aggregated with the global representations to form a single template. Second, a simple, yet effective, training strategy was introduced to balance the non-occluded and occluded facial images. Extensive experiments demonstrated that OREO improved the generalization ability of face recognition under occlusions by (10.17%) in a single-image-based setting and outperformed the baseline by approximately (2%) in terms of rank-1 accuracy in an image-set-based scenario.
Privacy Preserving Visual SLAM
Jul 20, 2020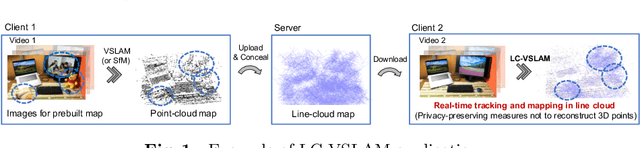

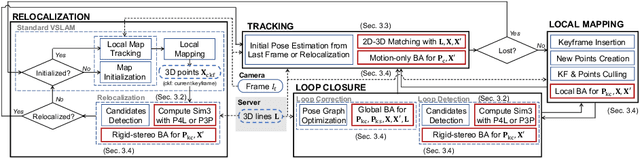

This study proposes a privacy-preserving Visual SLAM framework for estimating camera poses and performing bundle adjustment with mixed line and point clouds in real time. Previous studies have proposed localization methods to estimate a camera pose using a line-cloud map for a single image or a reconstructed point cloud. These methods offer a scene privacy protection against the inversion attacks by converting a point cloud to a line cloud, which reconstruct the scene images from the point cloud. However, they are not directly applicable to a video sequence because they do not address computational efficiency. This is a critical issue to solve for estimating camera poses and performing bundle adjustment with mixed line and point clouds in real time. Moreover, there has been no study on a method to optimize a line-cloud map of a server with a point cloud reconstructed from a client video because any observation points on the image coordinates are not available to prevent the inversion attacks, namely the reversibility of the 3D lines. The experimental results with synthetic and real data show that our Visual SLAM framework achieves the intended privacy-preserving formation and real-time performance using a line-cloud map.
Investigating the Effect of Emoji in Opinion Classification of Uzbek Movie Review Comments
Aug 02, 2020
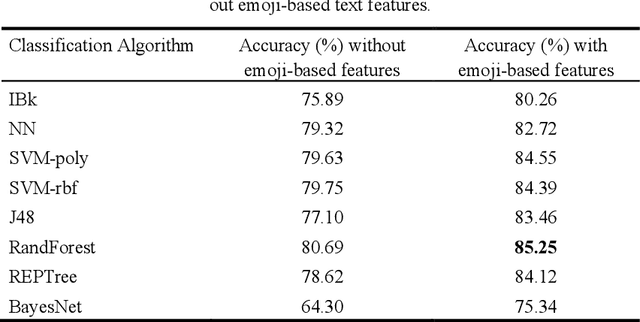
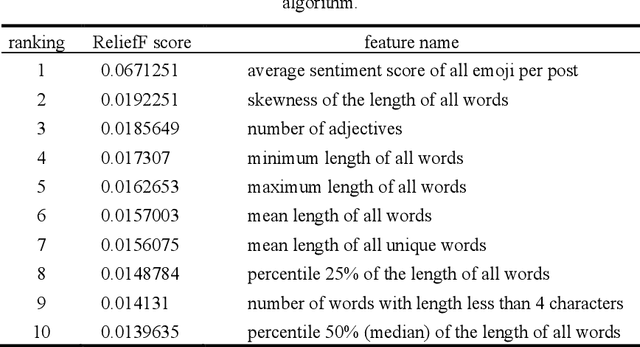
Opinion mining on social media posts has become more and more popular. Users often express their opinion on a topic not only with words but they also use image symbols such as emoticons and emoji. In this paper, we investigate the effect of emoji-based features in opinion classification of Uzbek texts, and more specifically movie review comments from YouTube. Several classification algorithms are tested, and feature ranking is performed to evaluate the discriminative ability of the emoji-based features.
A CNN Approach to Simultaneously Count Plants and Detect Plantation-Rows from UAV Imagery
Jan 02, 2021
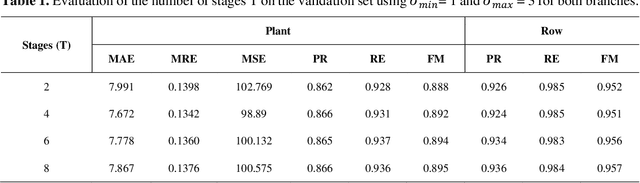
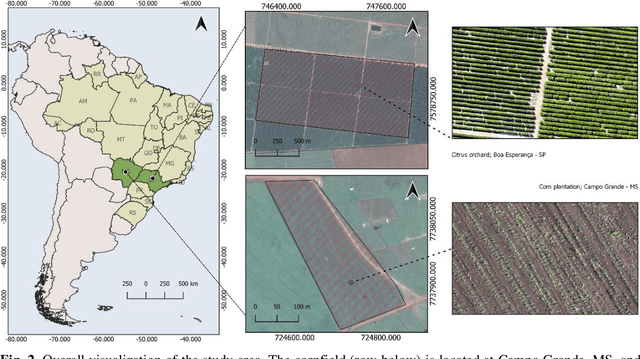
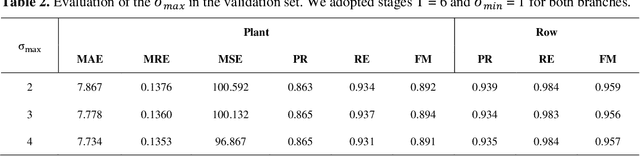
In this paper, we propose a novel deep learning method based on a Convolutional Neural Network (CNN) that simultaneously detects and geolocates plantation-rows while counting its plants considering highly-dense plantation configurations. The experimental setup was evaluated in a cornfield with different growth stages and in a Citrus orchard. Both datasets characterize different plant density scenarios, locations, types of crops, sensors, and dates. A two-branch architecture was implemented in our CNN method, where the information obtained within the plantation-row is updated into the plant detection branch and retro-feed to the row branch; which are then refined by a Multi-Stage Refinement method. In the corn plantation datasets (with both growth phases, young and mature), our approach returned a mean absolute error (MAE) of 6.224 plants per image patch, a mean relative error (MRE) of 0.1038, precision and recall values of 0.856, and 0.905, respectively, and an F-measure equal to 0.876. These results were superior to the results from other deep networks (HRNet, Faster R-CNN, and RetinaNet) evaluated with the same task and dataset. For the plantation-row detection, our approach returned precision, recall, and F-measure scores of 0.913, 0.941, and 0.925, respectively. To test the robustness of our model with a different type of agriculture, we performed the same task in the citrus orchard dataset. It returned an MAE equal to 1.409 citrus-trees per patch, MRE of 0.0615, precision of 0.922, recall of 0.911, and F-measure of 0.965. For citrus plantation-row detection, our approach resulted in precision, recall, and F-measure scores equal to 0.965, 0.970, and 0.964, respectively. The proposed method achieved state-of-the-art performance for counting and geolocating plants and plant-rows in UAV images from different types of crops.
3D FLAT: Feasible Learned Acquisition Trajectories for Accelerated MRI
Aug 11, 2020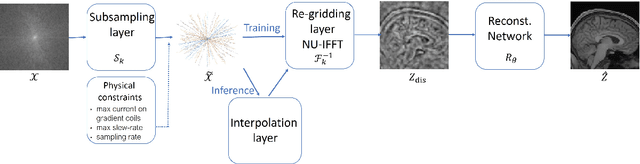

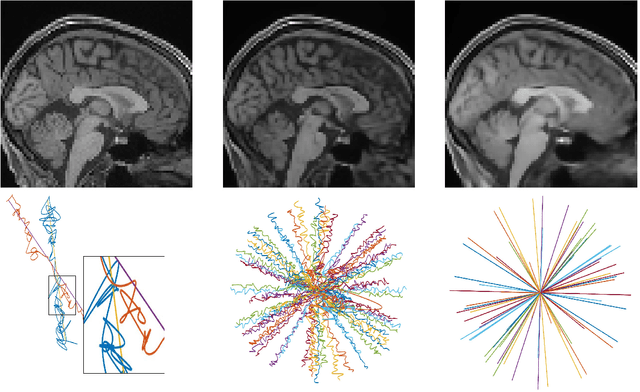
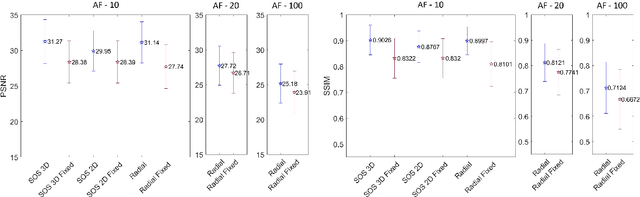
Magnetic Resonance Imaging (MRI) has long been considered to be among the gold standards of today's diagnostic imaging. The most significant drawback of MRI is long acquisition times, prohibiting its use in standard practice for some applications. Compressed sensing (CS) proposes to subsample the k-space (the Fourier domain dual to the physical space of spatial coordinates) leading to significantly accelerated acquisition. However, the benefit of compressed sensing has not been fully exploited; most of the sampling densities obtained through CS do not produce a trajectory that obeys the stringent constraints of the MRI machine imposed in practice. Inspired by recent success of deep learning based approaches for image reconstruction and ideas from computational imaging on learning-based design of imaging systems, we introduce 3D FLAT, a novel protocol for data-driven design of 3D non-Cartesian accelerated trajectories in MRI. Our proposal leverages the entire 3D k-space to simultaneously learn a physically feasible acquisition trajectory with a reconstruction method. Experimental results, performed as a proof-of-concept, suggest that 3D FLAT achieves higher image quality for a given readout time compared to standard trajectories such as radial, stack-of-stars, or 2D learned trajectories (trajectories that evolve only in the 2D plane while fully sampling along the third dimension). Furthermore, we demonstrate evidence supporting the significant benefit of performing MRI acquisitions using non-Cartesian 3D trajectories over 2D non-Cartesian trajectories acquired slice-wise.