 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Line Art Video Colorization with a Few References
Mar 24, 2020


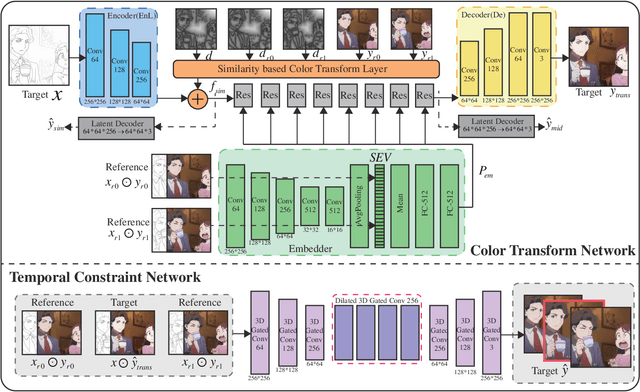

Coloring line art images based on the colors of reference images is an important stage in animation production, which is time-consuming and tedious. In this paper, we propose a deep architecture to automatically color line art videos with the same color style as the given reference images. Our framework consists of a color transform network and a temporal constraint network. The color transform network takes the target line art images as well as the line art and color images of one or more reference images as input, and generates corresponding target color images. To cope with larger differences between the target line art image and reference color images, our architecture utilizes non-local similarity matching to determine the region correspondences between the target image and the reference images, which are used to transform the local color information from the references to the target. To ensure global color style consistency, we further incorporate Adaptive Instance Normalization (AdaIN) with the transformation parameters obtained from a style embedding vector that describes the global color style of the references, extracted by an embedder. The temporal constraint network takes the reference images and the target image together in chronological order, and learns the spatiotemporal features through 3D convolution to ensure the temporal consistency of the target image and the reference image. Our model can achieve even better coloring results by fine-tuning the parameters with only a small amount of samples when dealing with an animation of a new style. To evaluate our method, we build a line art coloring dataset. Experiments show that our method achieves the best performance on line art video coloring compared to the state-of-the-art methods and other baselines.
Large Receptive Field Networks for High-Scale Image Super-Resolution
Apr 22, 2018
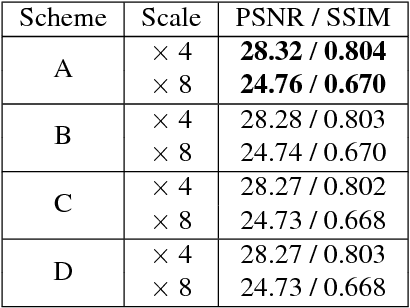
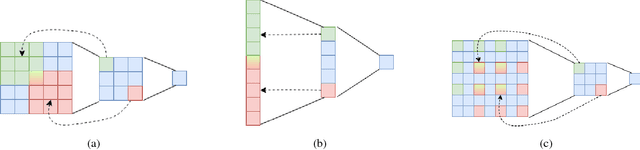
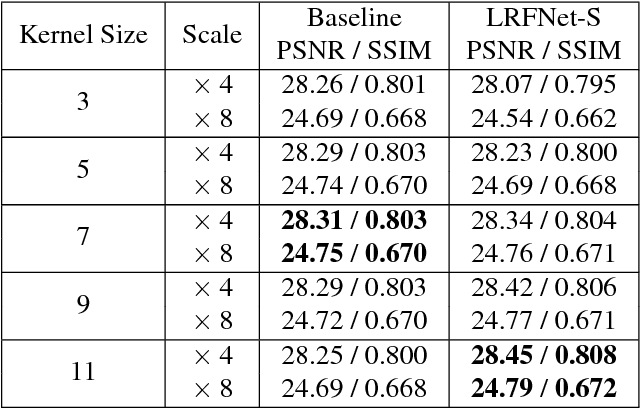
Convolutional Neural Networks have been the backbone of recent rapid progress in Single-Image Super-Resolution. However, existing networks are very deep with many network parameters, thus having a large memory footprint and being challenging to train. We propose Large Receptive Field Networks which strive to directly expand the receptive field of Super-Resolution networks without increasing depth or parameter count. In particular, we use two different methods to expand the network receptive field: 1-D separable kernels and atrous convolutions. We conduct considerable experiments to study the performance of various arrangement schemes of the 1-D separable kernels and atrous convolution in terms of accuracy (PSNR / SSIM), parameter count, and speed, while focusing on the more challenging high upscaling factors. Extensive benchmark evaluations demonstrate the effectiveness of our approach.
Multi-Modal Active Learning for Automatic Liver Fibrosis Diagnosis based on Ultrasound Shear Wave Elastography
Nov 02, 2020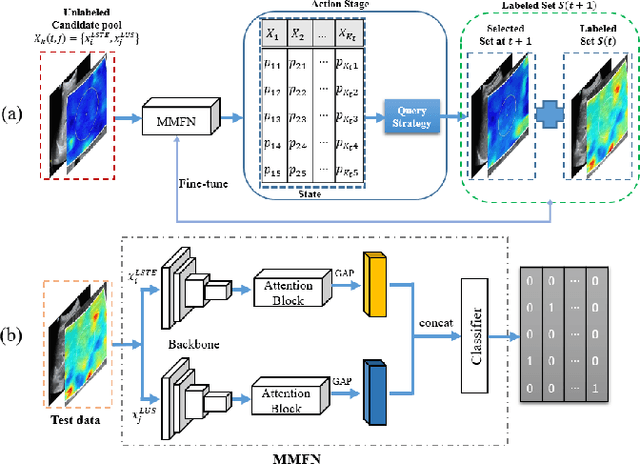
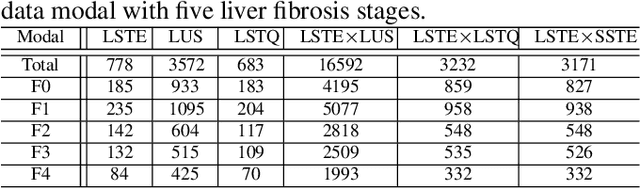
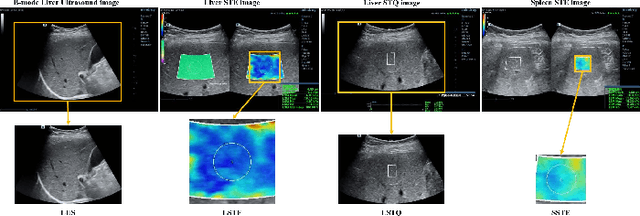
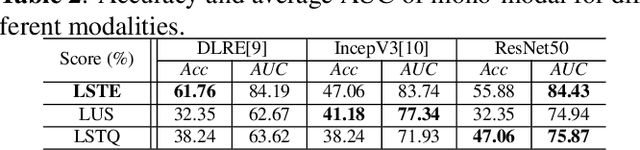
With the development of radiomics, noninvasive diagnosis like ultrasound (US) imaging plays a very important role in automatic liver fibrosis diagnosis (ALFD). Due to the noisy data, expensive annotations of US images, the application of Artificial Intelligence (AI) assisting approaches encounters a bottleneck. Besides, the use of mono-modal US data limits the further improve of the classification results. In this work, we innovatively propose a multi-modal fusion network with active learning (MMFN-AL) for ALFD to exploit the information of multiple modalities, eliminate the noisy data and reduce the annotation cost. Four image modalities including US and three types of shear wave elastography (SWEs) are exploited. A new dataset containing these modalities from 214 candidates is well-collected and pre-processed, with the labels obtained from the liver biopsy results. Experimental results show that our proposed method outperforms the state-of-the-art performance using less than 30% data, and by using only around 80% data, the proposed fusion network achieves high AUC 89.27% and accuracy 70.59%.
Conditional Random Field and Deep Feature Learning for Hyperspectral Image Segmentation
Dec 27, 2017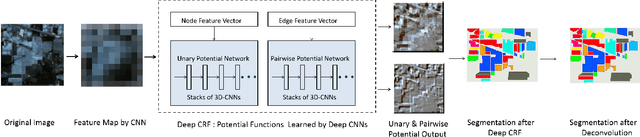
Image segmentation is considered to be one of the critical tasks in hyperspectral remote sensing image processing. Recently, convolutional neural network (CNN) has established itself as a powerful model in segmentation and classification by demonstrating excellent performances. The use of a graphical model such as a conditional random field (CRF) contributes further in capturing contextual information and thus improving the segmentation performance. In this paper, we propose a method to segment hyperspectral images by considering both spectral and spatial information via a combined framework consisting of CNN and CRF. We use multiple spectral cubes to learn deep features using CNN, and then formulate deep CRF with CNN-based unary and pairwise potential functions to effectively extract the semantic correlations between patches consisting of three-dimensional data cubes. Effective piecewise training is applied in order to avoid the computationally expensive iterative CRF inference. Furthermore, we introduce a deep deconvolution network that improves the segmentation masks. We also introduce a new dataset and experimented our proposed method on it along with several widely adopted benchmark datasets to evaluate the effectiveness of our method. By comparing our results with those from several state-of-the-art models, we show the promising potential of our method.
Feature based Sequential Classifier with Attention Mechanism
Jul 22, 2020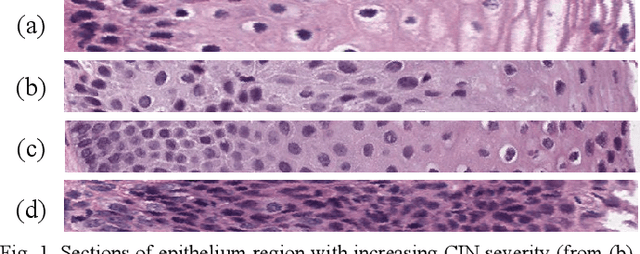
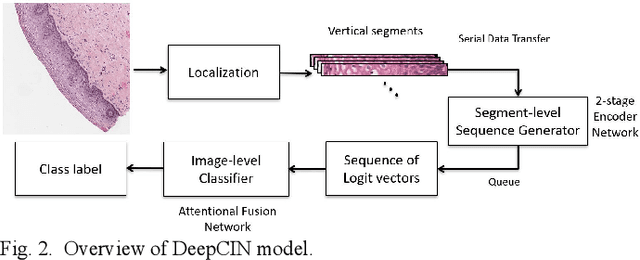
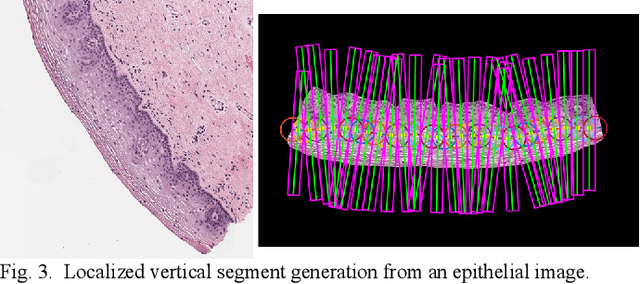
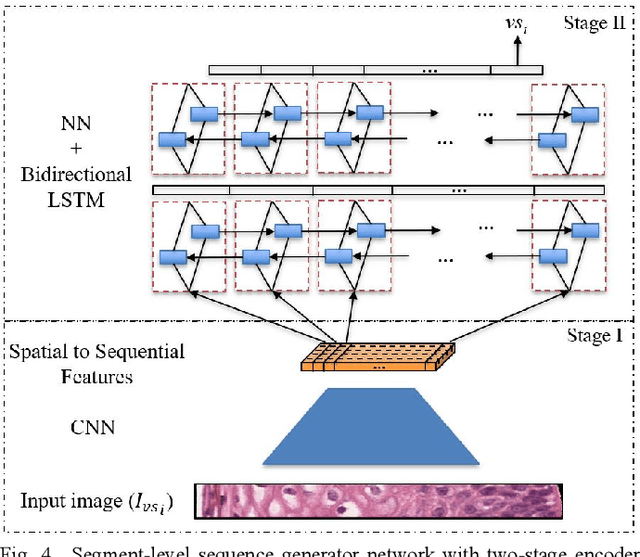
Cervical cancer is one of the deadliest cancers affecting women globally. Cervical intraepithelial neoplasia (CIN) assessment using histopathological examination of cervical biopsy slides is subject to interobserver variability. Automated processing of digitized histopathology slides has the potential for more accurate classification for CIN grades from normal to increasing grades of pre-malignancy: CIN1, CIN2 and CIN3. Cervix disease is generally understood to progress from the bottom (basement membrane) to the top of the epithelium. To model this relationship of disease severity to spatial distribution of abnormalities, we propose a network pipeline, DeepCIN, to analyze high-resolution epithelium images (manually extracted from whole-slide images) hierarchically by focusing on localized vertical regions and fusing this local information for determining Normal/CIN classification. The pipeline contains two classifier networks: 1) a cross-sectional, vertical segment-level sequence generator (two-stage encoder model) is trained using weak supervision to generate feature sequences from the vertical segments to preserve the bottom-to-top feature relationships in the epithelium image data; 2) an attention-based fusion network image-level classifier predicting the final CIN grade by merging vertical segment sequences. The model produces the CIN classification results and also determines the vertical segment contributions to CIN grade prediction. Experiments show that DeepCIN achieves pathologist-level CIN classification accuracy.
Robust Perceptual Night Vision in Thermal Colorization
Mar 04, 2020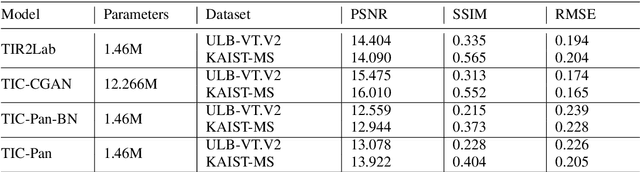
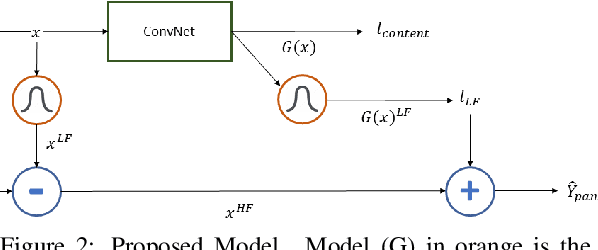
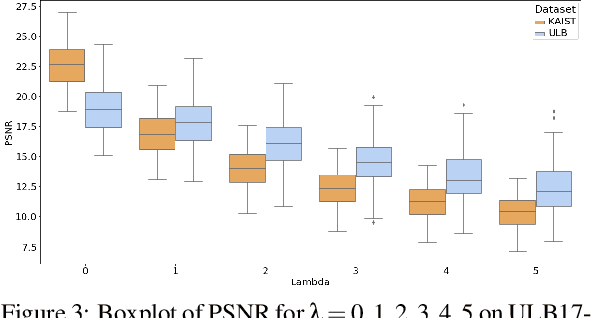

Transforming a thermal infrared image into a robust perceptual colour Visible image is an ill-posed problem due to the differences in their spectral domains and in the objects' representations. Objects appear in one spectrum but not necessarily in the other, and the thermal signature of a single object may have different colours in its Visible representation. This makes a direct mapping from thermal to Visible images impossible and necessitates a solution that preserves texture captured in the thermal spectrum while predicting the possible colour for certain objects. In this work, a deep learning method to map the thermal signature from the thermal image's spectrum to a Visible representation in their low-frequency space is proposed. A pan-sharpening method is then used to merge the predicted low-frequency representation with the high-frequency representation extracted from the thermal image. The proposed model generates colour values consistent with the Visible ground truth when the object does not vary much in its appearance and generates averaged grey values in other cases. The proposed method shows robust perceptual night vision images in preserving the object's appearance and image context compared with the existing state-of-the-art.
Sparse Separable Nonnegative Matrix Factorization
Jun 13, 2020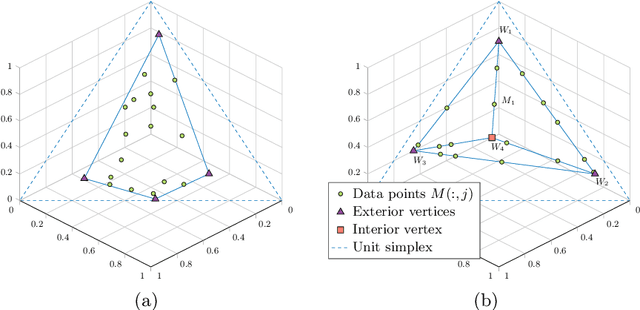


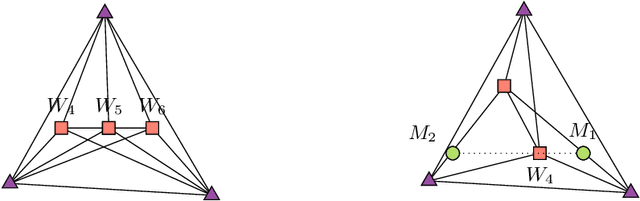
We propose a new variant of nonnegative matrix factorization (NMF), combining separability and sparsity assumptions. Separability requires that the columns of the first NMF factor are equal to columns of the input matrix, while sparsity requires that the columns of the second NMF factor are sparse. We call this variant sparse separable NMF (SSNMF), which we prove to be NP-complete, as opposed to separable NMF which can be solved in polynomial time. The main motivation to consider this new model is to handle underdetermined blind source separation problems, such as multispectral image unmixing. We introduce an algorithm to solve SSNMF, based on the successive nonnegative projection algorithm (SNPA, an effective algorithm for separable NMF), and an exact sparse nonnegative least squares solver. We prove that, in noiseless settings and under mild assumptions, our algorithm recovers the true underlying sources. This is illustrated by experiments on synthetic data sets and the unmixing of a multispectral image.
Evolution of active categorical image classification via saccadic eye movement
Jun 16, 2016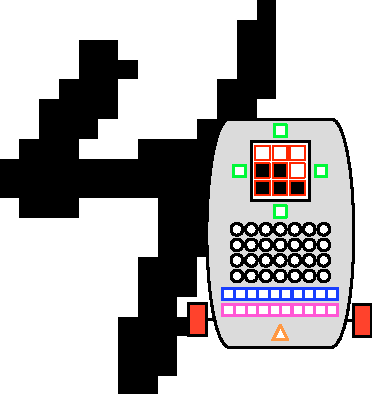
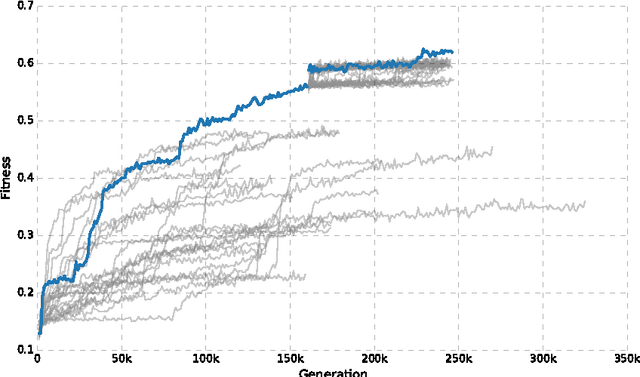
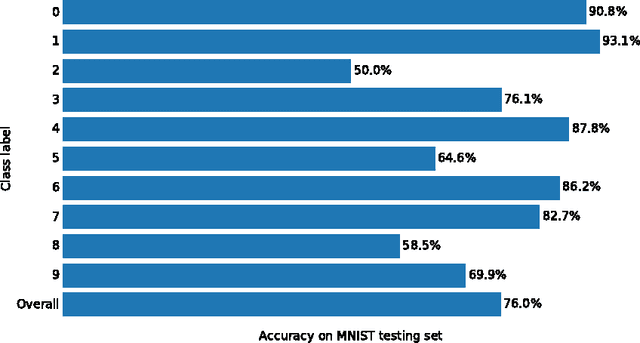
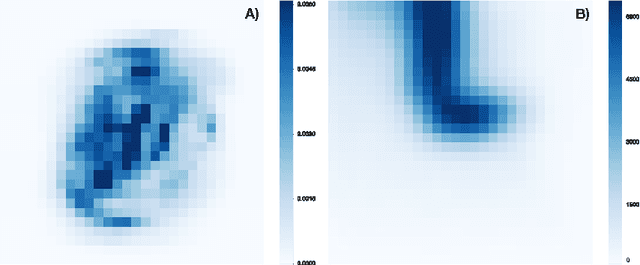
Pattern recognition and classification is a central concern for modern information processing systems. In particular, one key challenge to image and video classification has been that the computational cost of image processing scales linearly with the number of pixels in the image or video. Here we present an intelligent machine (the "active categorical classifier," or ACC) that is inspired by the saccadic movements of the eye, and is capable of classifying images by selectively scanning only a portion of the image. We harness evolutionary computation to optimize the ACC on the MNIST hand-written digit classification task, and provide a proof-of-concept that the ACC works on noisy multi-class data. We further analyze the ACC and demonstrate its ability to classify images after viewing only a fraction of the pixels, and provide insight on future research paths to further improve upon the ACC presented here.
* 10 pages, 5 figures, to appear in PPSN 2016 conference proceedings
Pairwise Decomposition of Image Sequences for Active Multi-View Recognition
May 26, 2016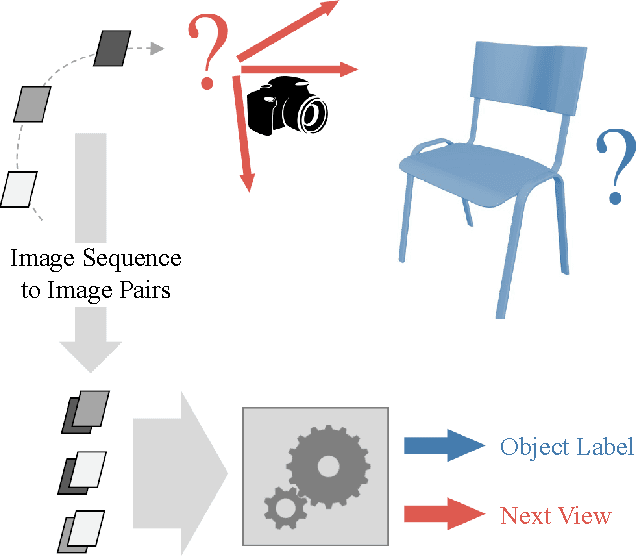
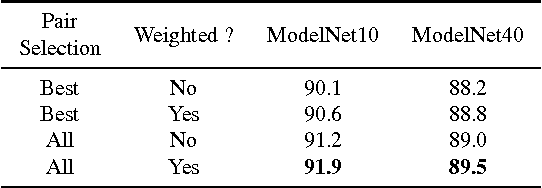
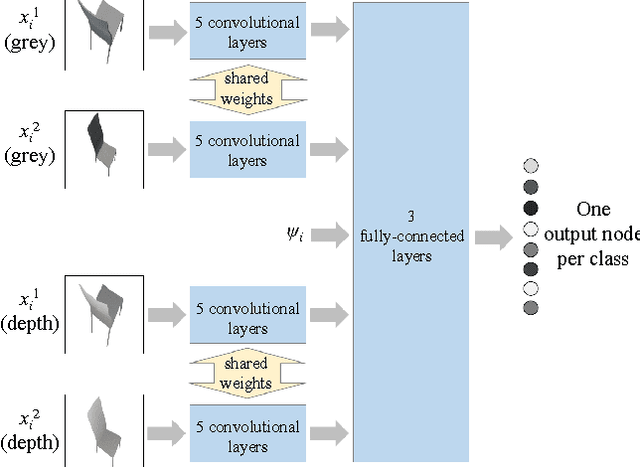
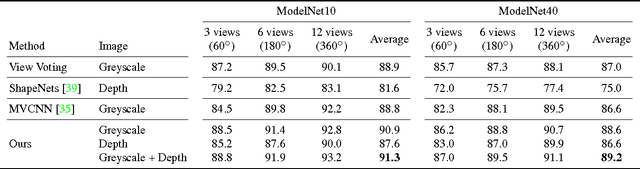
A multi-view image sequence provides a much richer capacity for object recognition than from a single image. However, most existing solutions to multi-view recognition typically adopt hand-crafted, model-based geometric methods, which do not readily embrace recent trends in deep learning. We propose to bring Convolutional Neural Networks to generic multi-view recognition, by decomposing an image sequence into a set of image pairs, classifying each pair independently, and then learning an object classifier by weighting the contribution of each pair. This allows for recognition over arbitrary camera trajectories, without requiring explicit training over the potentially infinite number of camera paths and lengths. Building these pairwise relationships then naturally extends to the next-best-view problem in an active recognition framework. To achieve this, we train a second Convolutional Neural Network to map directly from an observed image to next viewpoint. Finally, we incorporate this into a trajectory optimisation task, whereby the best recognition confidence is sought for a given trajectory length. We present state-of-the-art results in both guided and unguided multi-view recognition on the ModelNet dataset, and show how our method can be used with depth images, greyscale images, or both.
Image Retargeting by Content-Aware Synthesis
Aug 21, 2014

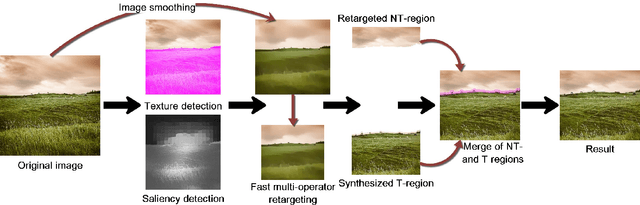

Real-world images usually contain vivid contents and rich textural details, which will complicate the manipulation on them. In this paper, we design a new framework based on content-aware synthesis to enhance content-aware image retargeting. By detecting the textural regions in an image, the textural image content can be synthesized rather than simply distorted or cropped. This method enables the manipulation of textural & non-textural regions with different strategy since they have different natures. We propose to retarget the textural regions by content-aware synthesis and non-textural regions by fast multi-operators. To achieve practical retargeting applications for general images, we develop an automatic and fast texture detection method that can detect multiple disjoint textural regions. We adjust the saliency of the image according to the features of the textural regions. To validate the proposed method, comparisons with state-of-the-art image targeting techniques and a user study were conducted. Convincing visual results are shown to demonstrate the effectiveness of the proposed method.