 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Grouping Model for Unified Perceptual Parsing
Mar 25, 2020
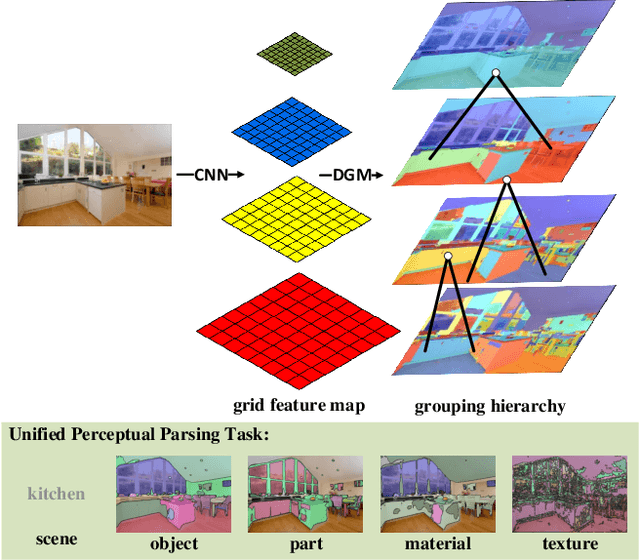
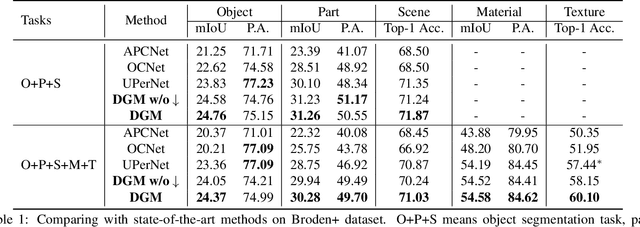
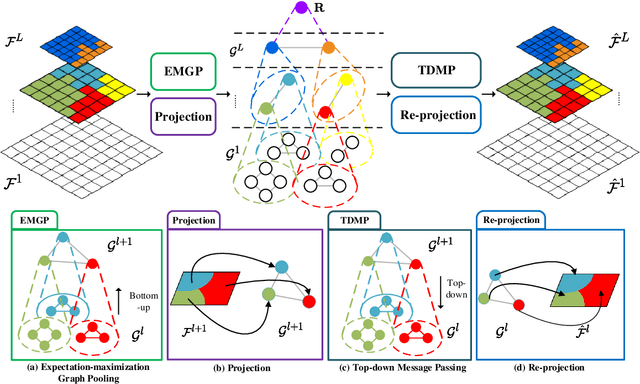
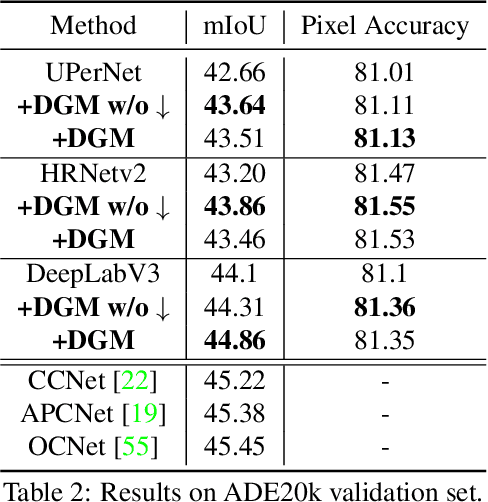
The perceptual-based grouping process produces a hierarchical and compositional image representation that helps both human and machine vision systems recognize heterogeneous visual concepts. Examples can be found in the classical hierarchical superpixel segmentation or image parsing works. However, the grouping process is largely overlooked in modern CNN-based image segmentation networks due to many challenges, including the inherent incompatibility between the grid-shaped CNN feature map and the irregular-shaped perceptual grouping hierarchy. Overcoming these challenges, we propose a deep grouping model (DGM) that tightly marries the two types of representations and defines a bottom-up and a top-down process for feature exchanging. When evaluating the model on the recent Broden+ dataset for the unified perceptual parsing task, it achieves state-of-the-art results while having a small computational overhead compared to other contextual-based segmentation models. Furthermore, the DGM has better interpretability compared with modern CNN methods.
* Accepted by CVPR 2020
Using a Bi-directional LSTM Model with Attention Mechanism trained on MIDI Data for Generating Unique Music
Nov 02, 2020


Generating music is an interesting and challenging problem in the field of machine learning. Mimicking human creativity has been popular in recent years, especially in the field of computer vision and image processing. With the advent of GANs, it is possible to generate new similar images, based on trained data. But this cannot be done for music similarly, as music has an extra temporal dimension. So it is necessary to understand how music is represented in digital form. When building models that perform this generative task, the learning and generation part is done in some high-level representation such as MIDI (Musical Instrument Digital Interface) or scores. This paper proposes a bi-directional LSTM (Long short-term memory) model with attention mechanism capable of generating similar type of music based on MIDI data. The music generated by the model follows the theme/style of the music the model is trained on. Also, due to the nature of MIDI, the tempo, instrument, and other parameters can be defined, and changed, post generation.
Multi-Modal Active Learning for Automatic Liver Fibrosis Diagnosis based on Ultrasound Shear Wave Elastography
Nov 02, 2020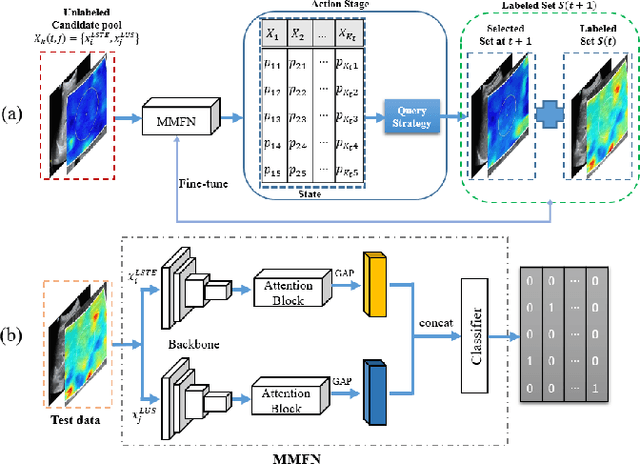
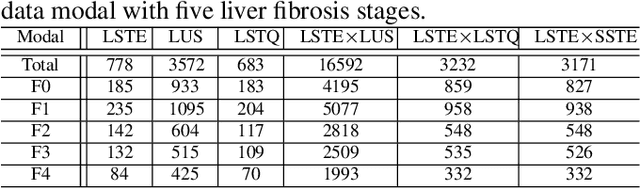
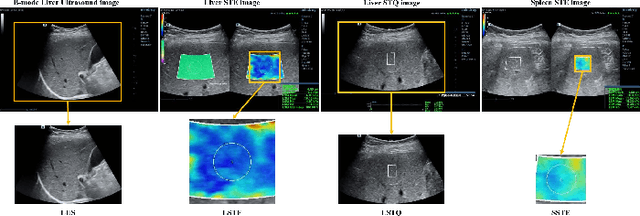
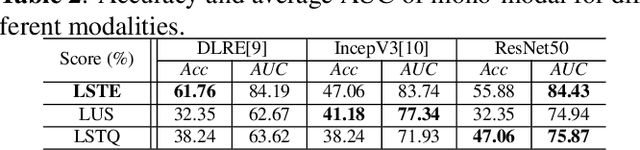
With the development of radiomics, noninvasive diagnosis like ultrasound (US) imaging plays a very important role in automatic liver fibrosis diagnosis (ALFD). Due to the noisy data, expensive annotations of US images, the application of Artificial Intelligence (AI) assisting approaches encounters a bottleneck. Besides, the use of mono-modal US data limits the further improve of the classification results. In this work, we innovatively propose a multi-modal fusion network with active learning (MMFN-AL) for ALFD to exploit the information of multiple modalities, eliminate the noisy data and reduce the annotation cost. Four image modalities including US and three types of shear wave elastography (SWEs) are exploited. A new dataset containing these modalities from 214 candidates is well-collected and pre-processed, with the labels obtained from the liver biopsy results. Experimental results show that our proposed method outperforms the state-of-the-art performance using less than 30% data, and by using only around 80% data, the proposed fusion network achieves high AUC 89.27% and accuracy 70.59%.
Progressively Diffused Networks for Semantic Image Segmentation
Feb 20, 2017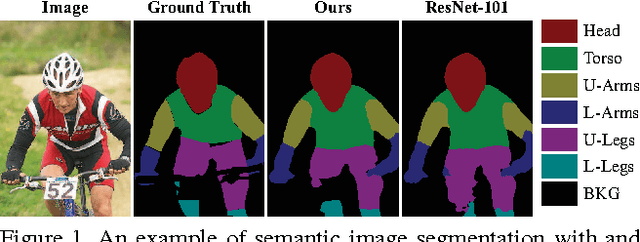
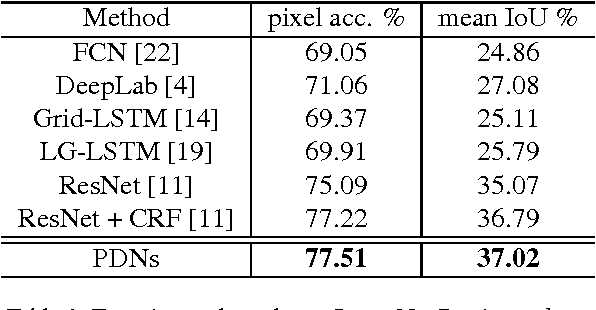
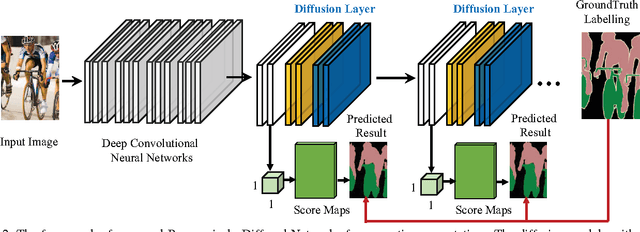
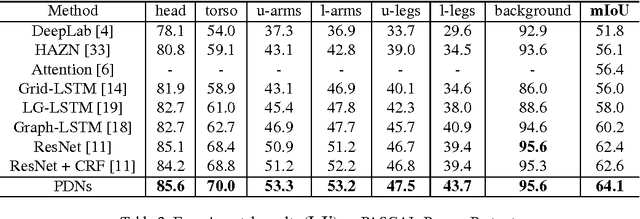
This paper introduces Progressively Diffused Networks (PDNs) for unifying multi-scale context modeling with deep feature learning, by taking semantic image segmentation as an exemplar application. Prior neural networks, such as ResNet, tend to enhance representational power by increasing the depth of architectures and driving the training objective across layers. However, we argue that spatial dependencies in different layers, which generally represent the rich contexts among data elements, are also critical to building deep and discriminative representations. To this end, our PDNs enables to progressively broadcast information over the learned feature maps by inserting a stack of information diffusion layers, each of which exploits multi-dimensional convolutional LSTMs (Long-Short-Term Memory Structures). In each LSTM unit, a special type of atrous filters are designed to capture the short range and long range dependencies from various neighbors to a certain site of the feature map and pass the accumulated information to the next layer. From the extensive experiments on semantic image segmentation benchmarks (e.g., ImageNet Parsing, PASCAL VOC2012 and PASCAL-Part), our framework demonstrates the effectiveness to substantially improve the performances over the popular existing neural network models, and achieves state-of-the-art on ImageNet Parsing for large scale semantic segmentation.
Finding the Evidence: Localization-aware Answer Prediction for Text Visual Question Answering
Oct 06, 2020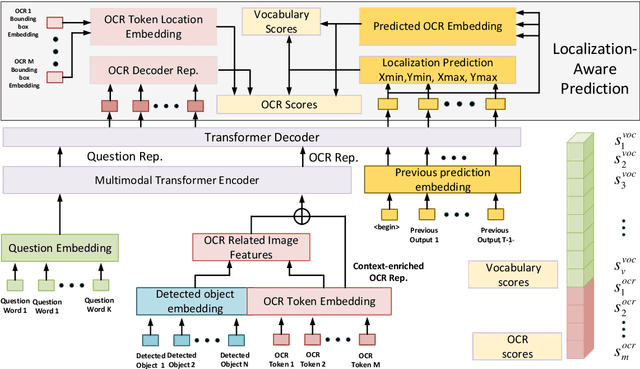
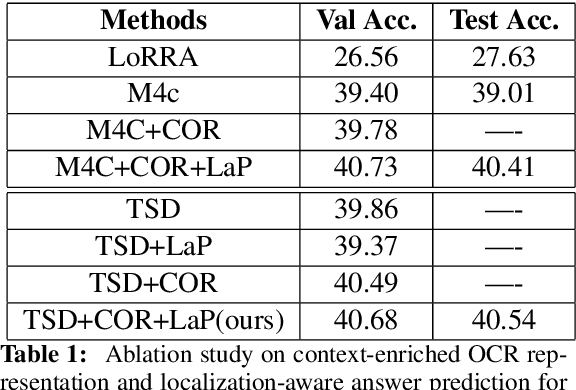

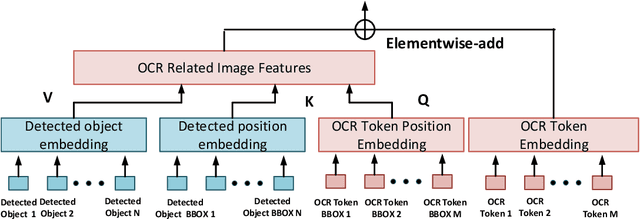
Image text carries essential information to understand the scene and perform reasoning. Text-based visual question answering (text VQA) task focuses on visual questions that require reading text in images. Existing text VQA systems generate an answer by selecting from optical character recognition (OCR) texts or a fixed vocabulary. Positional information of text is underused and there is a lack of evidence for the generated answer. As such, this paper proposes a localization-aware answer prediction network (LaAP-Net) to address this challenge. Our LaAP-Net not only generates the answer to the question but also predicts a bounding box as evidence of the generated answer. Moreover, a context-enriched OCR representation (COR) for multimodal fusion is proposed to facilitate the localization task. Our proposed LaAP-Net outperforms existing approaches on three benchmark datasets for the text VQA task by a noticeable margin.
TRLG: Fragile blind quad watermarking for image tamper detection and recovery by providing compact digests with quality optimized using LWT and GA
Mar 07, 2018
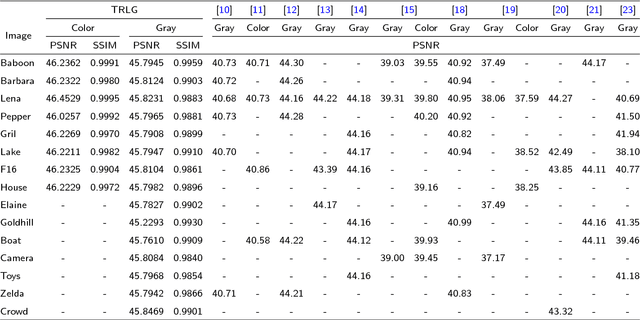
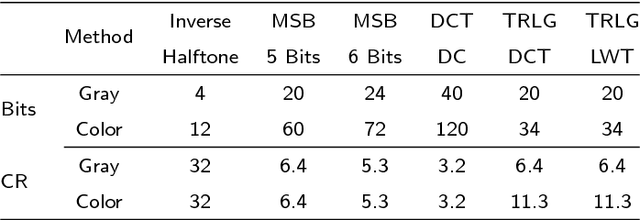
In this paper, an efficient fragile blind quad watermarking scheme for image tamper detection and recovery based on lifting wavelet transform and genetic algorithm is proposed. TRLG generates four compact digests with super quality based on lifting wavelet transform and halftoning technique by distinguishing the types of image blocks. In other words, for each 2*2 non-overlap blocks, four chances for recovering destroyed blocks are considered. A special parameter estimation technique based on genetic algorithm is performed to improve and optimize the quality of digests and watermarked image. Furthermore, CCS map is used to determine the mapping block for embedding information, encrypting and confusing the embedded information. In order to improve the recovery rate, Mirror-aside and Partner-block are proposed. The experiments that have been conducted to evaluate the performance of TRLG proved the superiority in terms of quality of the watermarked and recovered image, tamper localization and security compared with state-of-the-art methods. The results indicate that the PSNR and SSIM of the watermarked image are about 46 dB and approximately one, respectively. Also, the mean of PSNR and SSIM of several recovered images which has been destroyed about 90% is reached to 24 dB and 0.86, respectively.
A Simple Cache Model for Image Recognition
May 21, 2018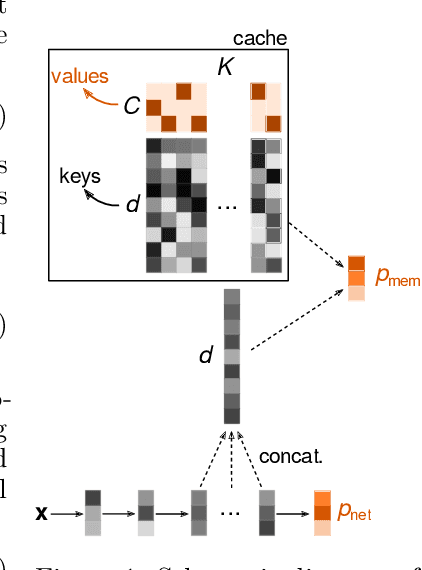
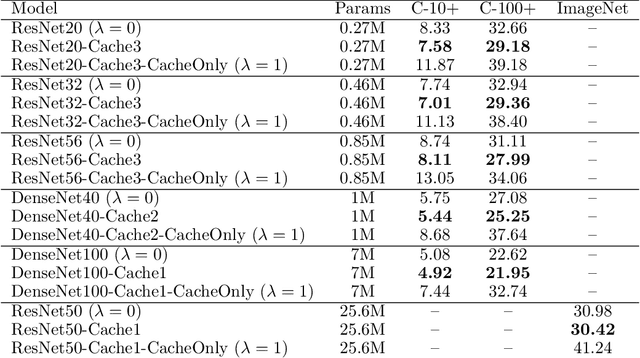
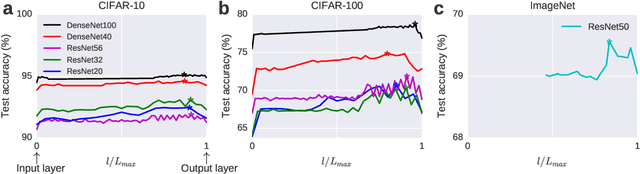

Training large-scale image recognition models is computationally expensive. This raises the question of whether there might be simple ways to improve the test performance of an already trained model without having to re-train or even fine-tune it with new data. Here, we show that, surprisingly, this is indeed possible. The key observation we make is that the layers of a deep network close to the output layer contain independent, easily extractable class-relevant information that is not contained in the output layer itself. We propose to extract this extra class-relevant information using a simple key-value cache memory to improve the classification performance of the model at test time. Our cache memory is directly inspired by a similar cache model previously proposed for language modeling (Grave et al., 2017). This cache component does not require any training or fine-tuning; it can be applied to any pre-trained model and, by properly setting only two hyper-parameters, leads to significant improvements in its classification performance. Improvements are observed across several architectures and datasets. In the cache component, using features extracted from layers close to the output (but not from the output layer itself) as keys leads to the largest improvements. Concatenating features from multiple layers to form keys can further improve performance over using single-layer features as keys. The cache component also has a regularizing effect, a simple consequence of which is that it substantially increases the robustness of models against adversarial attacks.
Fracking Deep Convolutional Image Descriptors
Feb 25, 2015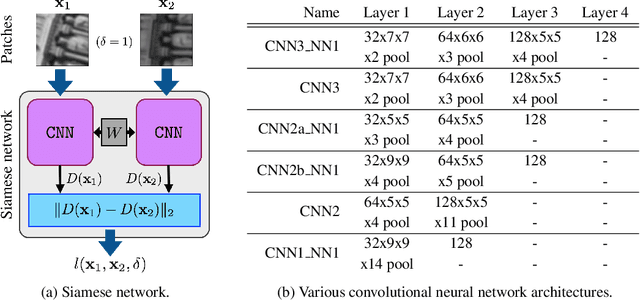
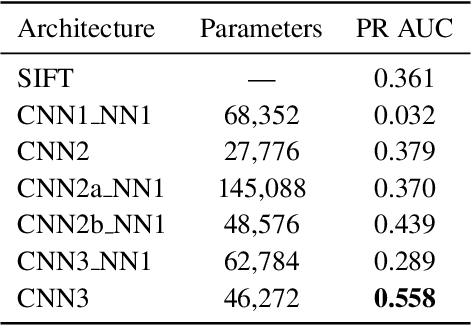

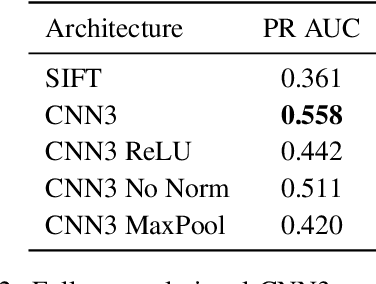
In this paper we propose a novel framework for learning local image descriptors in a discriminative manner. For this purpose we explore a siamese architecture of Deep Convolutional Neural Networks (CNN), with a Hinge embedding loss on the L2 distance between descriptors. Since a siamese architecture uses pairs rather than single image patches to train, there exist a large number of positive samples and an exponential number of negative samples. We propose to explore this space with a stochastic sampling of the training set, in combination with an aggressive mining strategy over both the positive and negative samples which we denote as "fracking". We perform a thorough evaluation of the architecture hyper-parameters, and demonstrate large performance gains compared to both standard CNN learning strategies, hand-crafted image descriptors like SIFT, and the state-of-the-art on learned descriptors: up to 2.5x vs SIFT and 1.5x vs the state-of-the-art in terms of the area under the curve (AUC) of the Precision-Recall curve.
Fast Constraint Propagation for Image Segmentation
Feb 05, 2015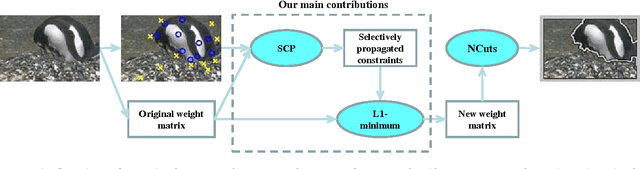



This paper presents a novel selective constraint propagation method for constrained image segmentation. In the literature, many pairwise constraint propagation methods have been developed to exploit pairwise constraints for cluster analysis. However, since most of these methods have a polynomial time complexity, they are not much suitable for segmentation of images even with a moderate size, which is actually equivalent to cluster analysis with a large data size. Considering the local homogeneousness of a natural image, we choose to perform pairwise constraint propagation only over a selected subset of pixels, but not over the whole image. Such a selective constraint propagation problem is then solved by an efficient graph-based learning algorithm. To further speed up our selective constraint propagation, we also discard those less important propagated constraints during graph-based learning. Finally, the selectively propagated constraints are exploited based on $L_1$-minimization for normalized cuts over the whole image. The experimental results demonstrate the promising performance of the proposed method for segmentation with selectively propagated constraints.
Detection of Double-Nuclei Galaxies in SDSS
Nov 23, 2020
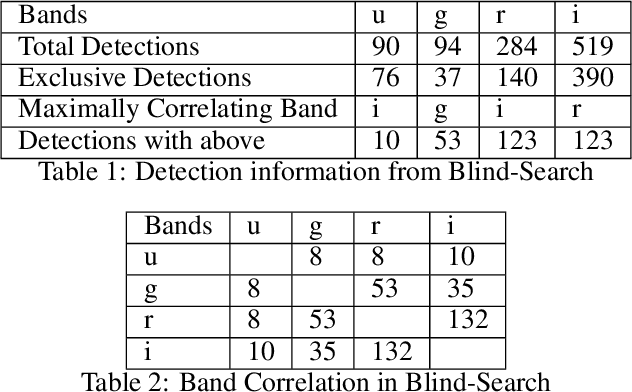
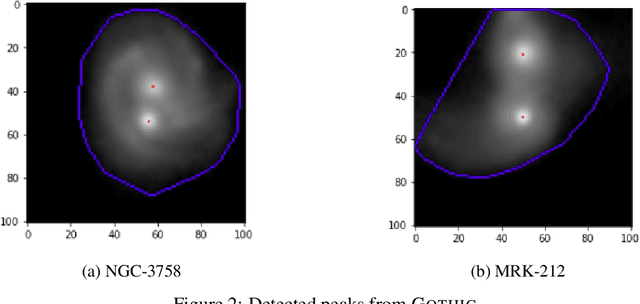
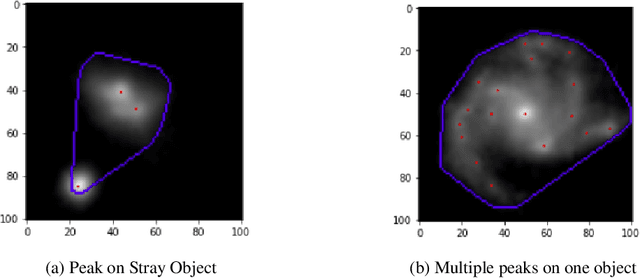
It is now well established that galaxy interactions and mergers play a crucial role in the hierarchical growth of structure in our universe. Galaxy mergers can lead to the formation of elliptical galaxies and larger disk galaxies, as well as drive galaxy evolution through star formation and nuclear activity. During mergers, the nuclei of the individual galaxies come closer and finally form a double nuclei galaxy. Although mergers are common, the detection of double-nuclei galaxies (DNGs) is rare and fairly serendipitous. Their detection is very important as their properties can help us understand the formation of supermassive black hole (SMBH) binaries, dual active galactic nuclei (DAGN), and the associated feedback effects. There is thus a need for an automatic/systematic survey of data for the discovery of double nuclei galaxies. Using the Sloan digital sky survey (SDSS) as the target catalog, we have introduced a novel algorithm "Gothic" (Graph-bOosTed iterated HIll Climbing) that detects whether a given image of a galaxy has characteristic features of a DNG (ASCL entry 2707). We have tested the algorithm on a random sample of 100,000 galaxies from the Stripe 82 region in SDSS and obtained a maximum detection rate of 4.2% with a careful choice of the input catalog.