 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Colorful Image Colorization
Oct 05, 2016

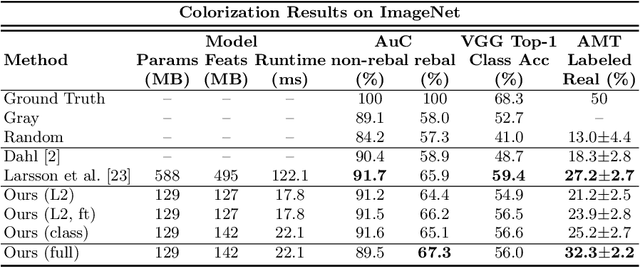
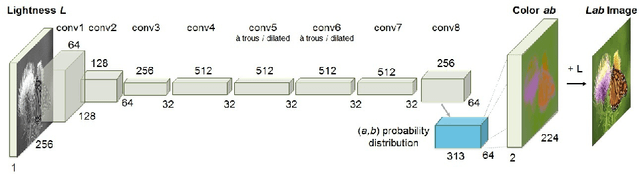
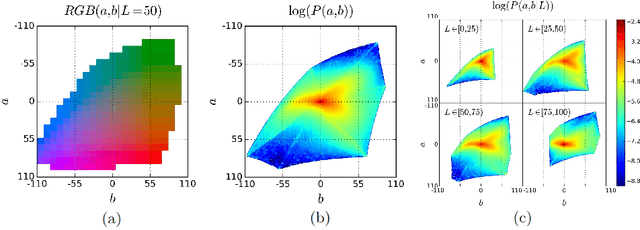
Given a grayscale photograph as input, this paper attacks the problem of hallucinating a plausible color version of the photograph. This problem is clearly underconstrained, so previous approaches have either relied on significant user interaction or resulted in desaturated colorizations. We propose a fully automatic approach that produces vibrant and realistic colorizations. We embrace the underlying uncertainty of the problem by posing it as a classification task and use class-rebalancing at training time to increase the diversity of colors in the result. The system is implemented as a feed-forward pass in a CNN at test time and is trained on over a million color images. We evaluate our algorithm using a "colorization Turing test," asking human participants to choose between a generated and ground truth color image. Our method successfully fools humans on 32% of the trials, significantly higher than previous methods. Moreover, we show that colorization can be a powerful pretext task for self-supervised feature learning, acting as a cross-channel encoder. This approach results in state-of-the-art performance on several feature learning benchmarks.
Phase Retrieval with Holography and Untrained Priors: Tackling the Challenges of Low-Photon Nanoscale Imaging
Dec 15, 2020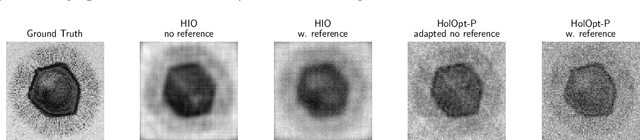
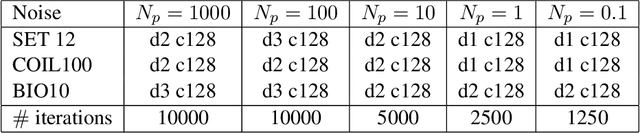


Phase retrieval is the inverse problem of recovering a signal from magnitude-only Fourier measurements, and underlies numerous imaging modalities, such as Coherent Diffraction Imaging (CDI). A variant of this setup, known as holography, includes a reference object that is placed adjacent to the specimen of interest before measurements are collected. The resulting inverse problem, known as holographic phase retrieval, is well-known to have improved problem conditioning relative to the original. This innovation, i.e. Holographic CDI, becomes crucial at the nanoscale, where imaging specimens such as viruses, proteins, and crystals require low-photon measurements. This data is highly corrupted by Poisson shot noise, and often lacks low-frequency content as well. In this work, we introduce a dataset-free deep learning framework for holographic phase retrieval adapted to these challenges. The key ingredients of our approach are the explicit and flexible incorporation of the physical forward model into an automatic differentiation procedure, the Poisson log-likelihood objective function, and an optional untrained deep image prior. We perform extensive evaluation under realistic conditions. Compared to competing classical methods, our method recovers signal from higher noise levels and is more resilient to suboptimal reference design, as well as to large missing regions of low frequencies in the observations. To the best of our knowledge, this is the first work to consider a dataset-free machine learning approach for holographic phase retrieval.
Seed Phenotyping on Neural Networks using Domain Randomization and Transfer Learning
Dec 24, 2020
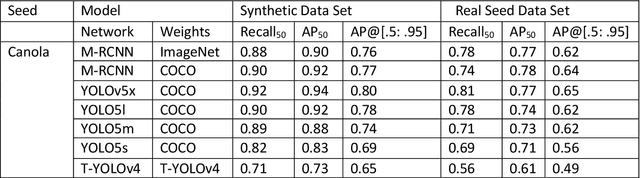
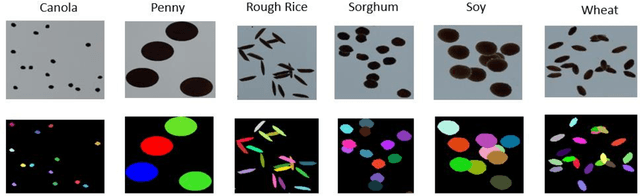
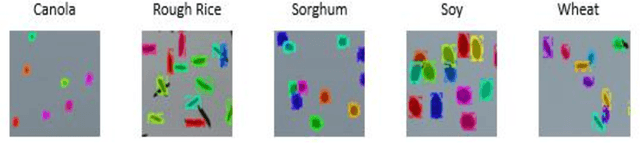
Seed phenotyping is the idea of analyzing the morphometric characteristics of a seed to predict the behavior of the seed in terms of development, tolerance and yield in various environmental conditions. The focus of the work is the application and feasibility analysis of the state-of-the-art object detection and localization neural networks, Mask R-CNN and YOLO (You Only Look Once), for seed phenotyping using Tensorflow. One of the major bottlenecks of such an endeavor is the need for large amounts of training data. While the capture of a multitude of seed images is taunting, the images are also required to be annotated to indicate the boundaries of the seeds on the image and converted to data formats that the neural networks are able to consume. Although tools to manually perform the task of annotation are available for free, the amount of time required is enormous. In order to tackle such a scenario, the idea of domain randomization i.e. the technique of applying models trained on images containing simulated objects to real-world objects, is considered. In addition, transfer learning i.e. the idea of applying the knowledge obtained while solving a problem to a different problem, is used. The networks are trained on pre-trained weights from the popular ImageNet and COCO data sets. As part of the work, experiments with different parameters are conducted on five different seed types namely, canola, rough rice, sorghum, soy, and wheat.
A General Approach for Using Deep Neural Network for Digital Watermarking
Mar 08, 2020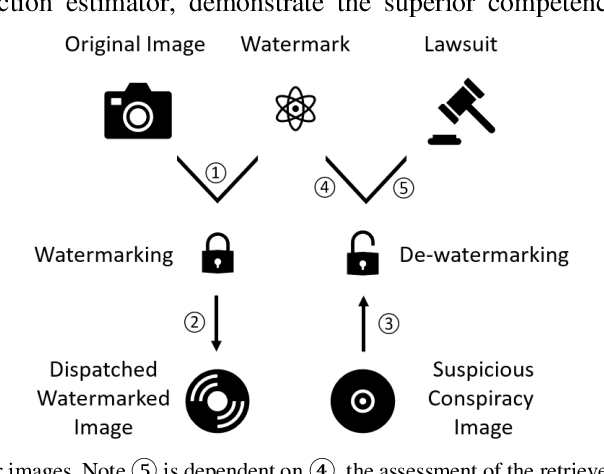

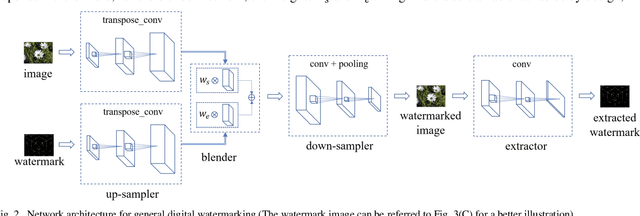
Technologies of the Internet of Things (IoT) facilitate digital contents such as images being acquired in a massive way. However, consideration from the privacy or legislation perspective still demands the need for intellectual content protection. In this paper, we propose a general deep neural network (DNN) based watermarking method to fulfill this goal. Instead of training a neural network for protecting a specific image, we train on an image set and use the trained model to protect a distinct test image set in a bulk manner. Respective evaluations both from the subjective and objective aspects confirm the supremacy and practicability of our proposed method. To demonstrate the robustness of this general neural watermarking mechanism, commonly used manipulations are applied to the watermarked image to examine the corresponding extracted watermark, which still retains sufficient recognizable traits. To the best of our knowledge, we are the first to propose a general way to perform watermarking using DNN. Considering its performance and economy, it is concluded that subsequent studies that generalize our work on utilizing DNN for intellectual content protection is a promising research trend.
DRST: Deep Residual Shearlet Transform for Densely Sampled Light Field Reconstruction
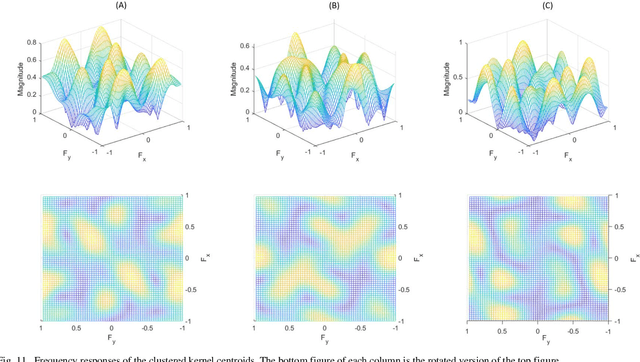
Mar 19, 2020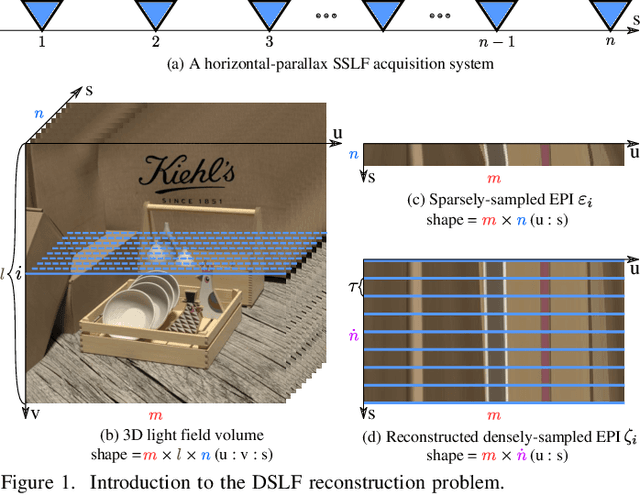

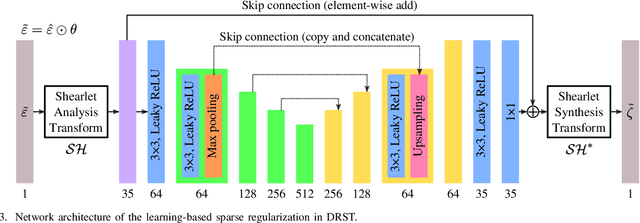
The Image-Based Rendering (IBR) approach using Shearlet Transform (ST) is one of the most effective methods for Densely-Sampled Light Field (DSLF) reconstruction. The ST-based DSLF reconstruction typically relies on an iterative thresholding algorithm for Epipolar-Plane Image (EPI) sparse regularization in shearlet domain, involving dozens of transformations between image domain and shearlet domain, which are in general time-consuming. To overcome this limitation, a novel learning-based ST approach, referred to as Deep Residual Shearlet Transform (DRST), is proposed in this paper. Specifically, for an input sparsely-sampled EPI, DRST employs a deep fully Convolutional Neural Network (CNN) to predict the residuals of the shearlet coefficients in shearlet domain in order to reconstruct a densely-sampled EPI in image domain. The DRST network is trained on synthetic Sparsely-Sampled Light Field (SSLF) data only by leveraging elaborately-designed masks. Experimental results on three challenging real-world light field evaluation datasets with varying moderate disparity ranges (8 - 16 pixels) demonstrate the superiority of the proposed learning-based DRST approach over the non-learning-based ST method for DSLF reconstruction. Moreover, DRST provides a 2.4x speedup over ST, at least.
Dynamic Group Convolution for Accelerating Convolutional Neural Networks
Jul 10, 2020
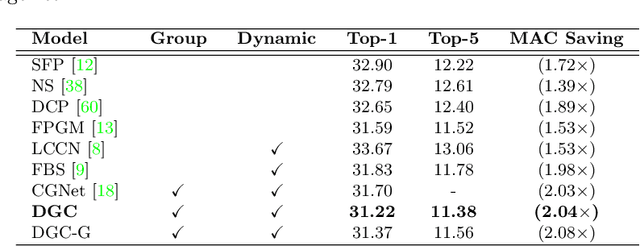
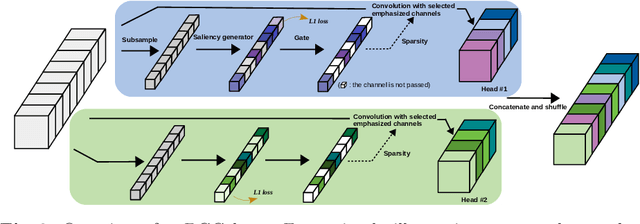
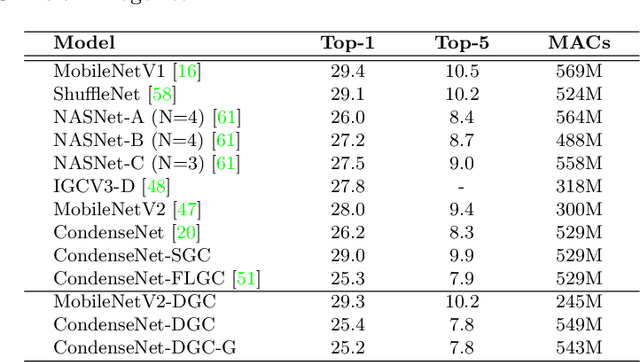
Replacing normal convolutions with group convolutions can significantly increase the computational efficiency of modern deep convolutional networks, which has been widely adopted in compact network architecture designs. However, existing group convolutions undermine the original network structures by cutting off some connections permanently resulting in significant accuracy degradation. In this paper, we propose dynamic group convolution (DGC) that adaptively selects which part of input channels to be connected within each group for individual samples on the fly. Specifically, we equip each group with a small feature selector to automatically select the most important input channels conditioned on the input images. Multiple groups can adaptively capture abundant and complementary visual/semantic features for each input image. The DGC preserves the original network structure and has similar computational efficiency as the conventional group convolution simultaneously. Extensive experiments on multiple image classification benchmarks including CIFAR-10, CIFAR-100 and ImageNet demonstrate its superiority over the existing group convolution techniques and dynamic execution methods. The code is available at https://github.com/zhuogege1943/dgc.
Polarization Human Shape and Pose Dataset
Apr 30, 2020


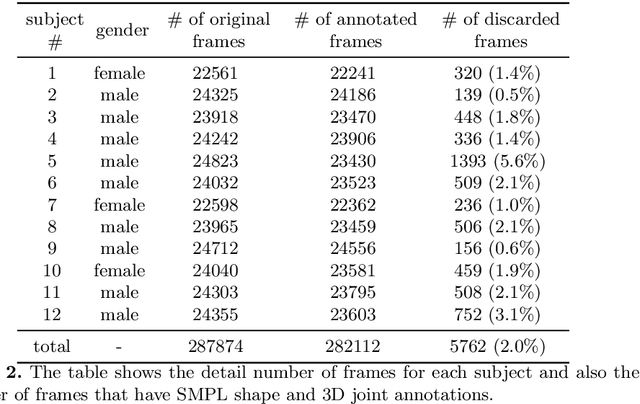
Polarization images are known to be able to capture polarized reflected lights that preserve rich geometric cues of an object, which has motivated its recent applications in reconstructing detailed surface normal of the objects of interest. Meanwhile, inspired by the recent breakthroughs in human shape estimation from a single color image, we attempt to investigate the new question of whether the geometric cues from polarization camera could be leveraged in estimating detailed human body shapes. This has led to the curation of Polarization Human Shape and Pose Dataset (PHSPD)5, our home-grown polarization image dataset of various human shapes and poses.
Adaptive Weighted Discriminator for Training Generative Adversarial Networks
Dec 05, 2020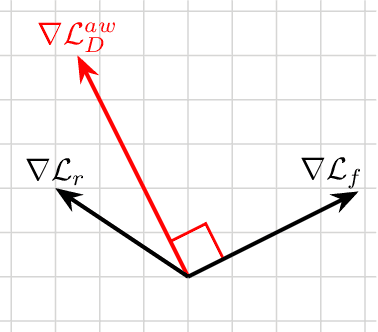
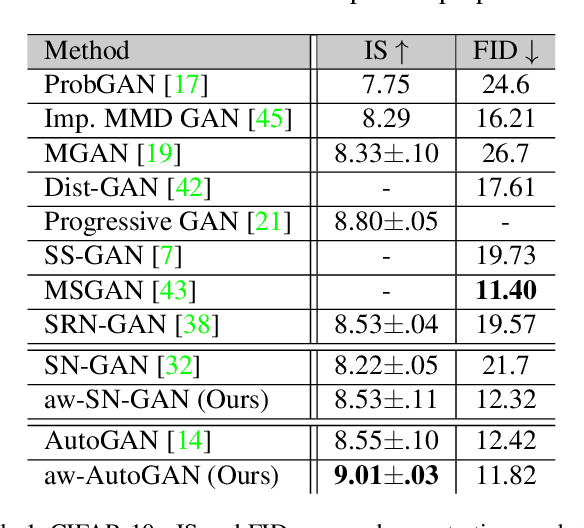

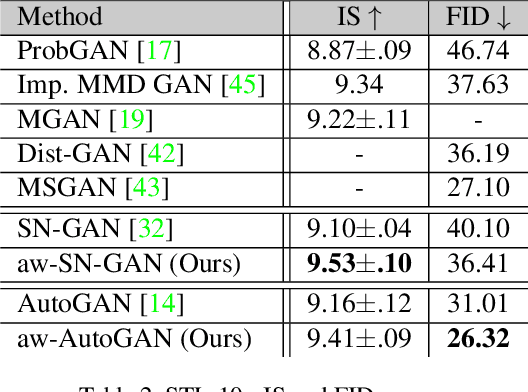
Generative adversarial network (GAN) has become one of the most important neural network models for classical unsupervised machine learning. A variety of discriminator loss functions have been developed to train GAN's discriminators and they all have a common structure: a sum of real and fake losses that only depends on the actual and generated data respectively. One challenge associated with an equally weighted sum of two losses is that the training may benefit one loss but harm the other, which we show causes instability and mode collapse. In this paper, we introduce a new family of discriminator loss functions that adopts a weighted sum of real and fake parts, which we call adaptive weighted loss functions or aw-loss functions. Using the gradients of the real and fake parts of the loss, we can adaptively choose weights to train a discriminator in the direction that benefits the GAN's stability. Our method can be potentially applied to any discriminator model with a loss that is a sum of the real and fake parts. Experiments validated the effectiveness of our loss functions on an unconditional image generation task, improving the baseline results by a significant margin on CIFAR-10, STL-10, and CIFAR-100 datasets in Inception Scores and FID.
Image Segmentation for Fruit Detection and Yield Estimation in Apple Orchards
Oct 25, 2016
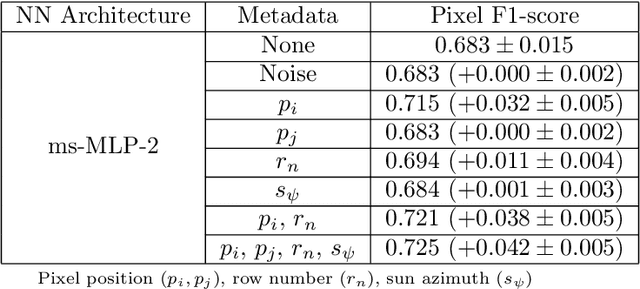


Ground vehicles equipped with monocular vision systems are a valuable source of high resolution image data for precision agriculture applications in orchards. This paper presents an image processing framework for fruit detection and counting using orchard image data. A general purpose image segmentation approach is used, including two feature learning algorithms; multi-scale Multi-Layered Perceptrons (MLP) and Convolutional Neural Networks (CNN). These networks were extended by including contextual information about how the image data was captured (metadata), which correlates with some of the appearance variations and/or class distributions observed in the data. The pixel-wise fruit segmentation output is processed using the Watershed Segmentation (WS) and Circular Hough Transform (CHT) algorithms to detect and count individual fruits. Experiments were conducted in a commercial apple orchard near Melbourne, Australia. The results show an improvement in fruit segmentation performance with the inclusion of metadata on the previously benchmarked MLP network. We extend this work with CNNs, bringing agrovision closer to the state-of-the-art in computer vision, where although metadata had negligible influence, the best pixel-wise F1-score of $0.791$ was achieved. The WS algorithm produced the best apple detection and counting results, with a detection F1-score of $0.858$. As a final step, image fruit counts were accumulated over multiple rows at the orchard and compared against the post-harvest fruit counts that were obtained from a grading and counting machine. The count estimates using CNN and WS resulted in the best performance for this dataset, with a squared correlation coefficient of $r^2=0.826$.
Self-Calibration of Cameras with Euclidean Image Plane in Case of Two Views and Known Relative Rotation Angle
Jul 30, 2018
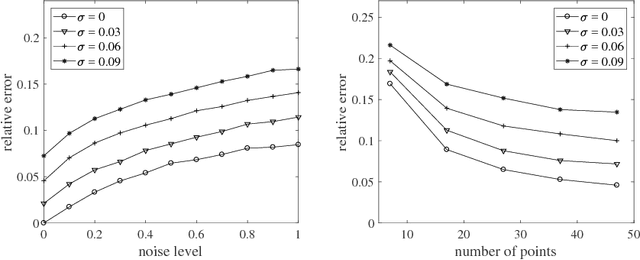
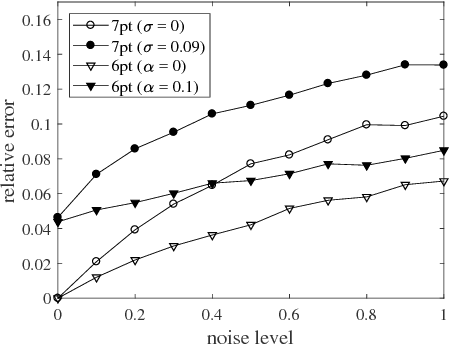
The internal calibration of a pinhole camera is given by five parameters that are combined into an upper-triangular $3\times 3$ calibration matrix. If the skew parameter is zero and the aspect ratio is equal to one, then the camera is said to have Euclidean image plane. In this paper, we propose a non-iterative self-calibration algorithm for a camera with Euclidean image plane in case the remaining three internal parameters --- the focal length and the principal point coordinates --- are fixed but unknown. The algorithm requires a set of $N \geq 7$ point correspondences in two views and also the measured relative rotation angle between the views. We show that the problem generically has six solutions (including complex ones). The algorithm has been implemented and tested both on synthetic data and on publicly available real dataset. The experiments demonstrate that the method is correct, numerically stable and robust.
* 13 pages, 7 eps-figures