 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Colorful Image Colorization
Oct 05, 2016

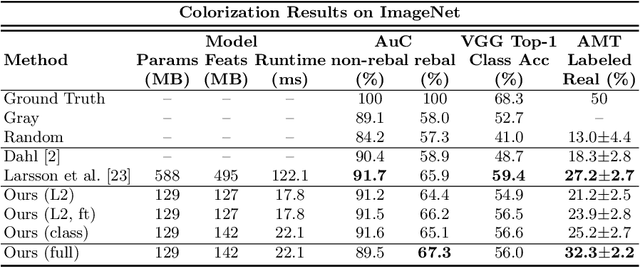
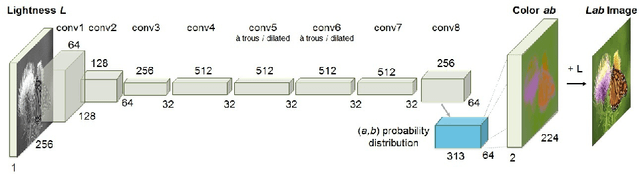
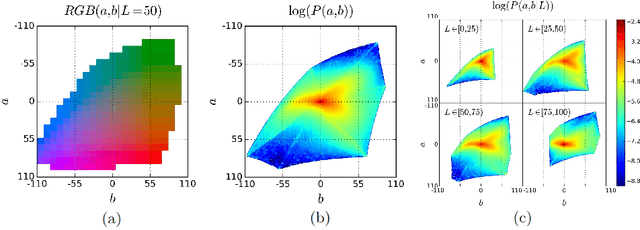
Given a grayscale photograph as input, this paper attacks the problem of hallucinating a plausible color version of the photograph. This problem is clearly underconstrained, so previous approaches have either relied on significant user interaction or resulted in desaturated colorizations. We propose a fully automatic approach that produces vibrant and realistic colorizations. We embrace the underlying uncertainty of the problem by posing it as a classification task and use class-rebalancing at training time to increase the diversity of colors in the result. The system is implemented as a feed-forward pass in a CNN at test time and is trained on over a million color images. We evaluate our algorithm using a "colorization Turing test," asking human participants to choose between a generated and ground truth color image. Our method successfully fools humans on 32% of the trials, significantly higher than previous methods. Moreover, we show that colorization can be a powerful pretext task for self-supervised feature learning, acting as a cross-channel encoder. This approach results in state-of-the-art performance on several feature learning benchmarks.
D2RL: Deep Dense Architectures in Reinforcement Learning
Oct 19, 2020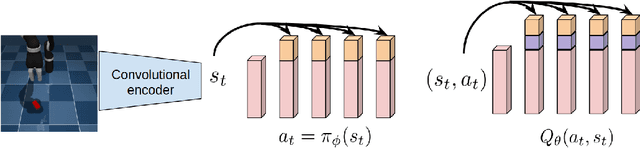
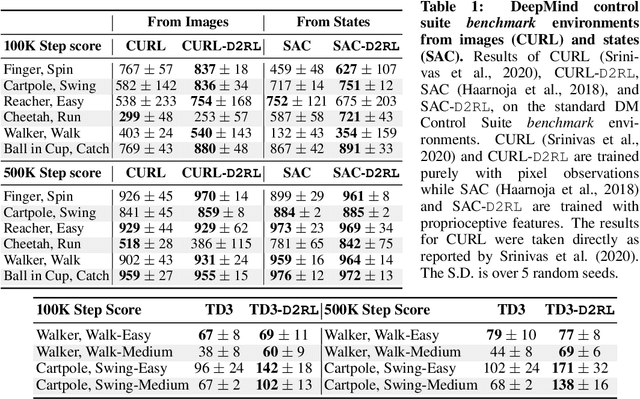
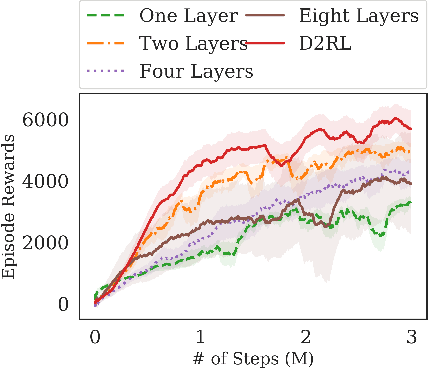
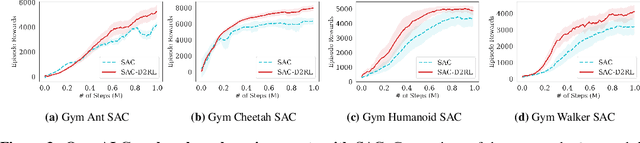
While improvements in deep learning architectures have played a crucial role in improving the state of supervised and unsupervised learning in computer vision and natural language processing, neural network architecture choices for reinforcement learning remain relatively under-explored. We take inspiration from successful architectural choices in computer vision and generative modelling, and investigate the use of deeper networks and dense connections for reinforcement learning on a variety of simulated robotic learning benchmark environments. Our findings reveal that current methods benefit significantly from dense connections and deeper networks, across a suite of manipulation and locomotion tasks, for both proprioceptive and image-based observations. We hope that our results can serve as a strong baseline and further motivate future research into neural network architectures for reinforcement learning. The project website with code is at this link https://sites.google.com/view/d2rl/home.
360-Degree Gaze Estimation in the Wild Using Multiple Zoom Scales
Sep 15, 2020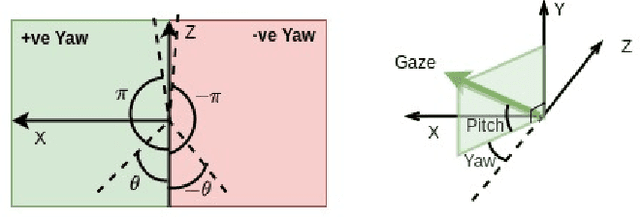
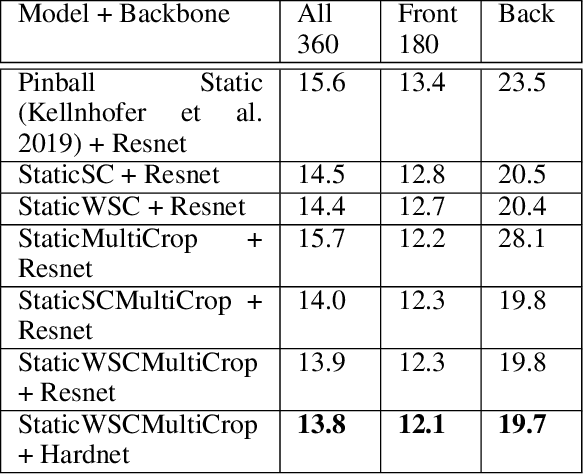
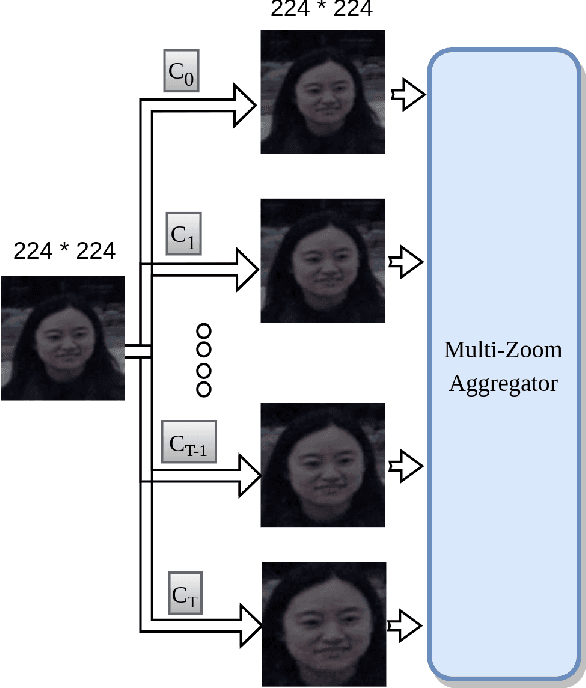
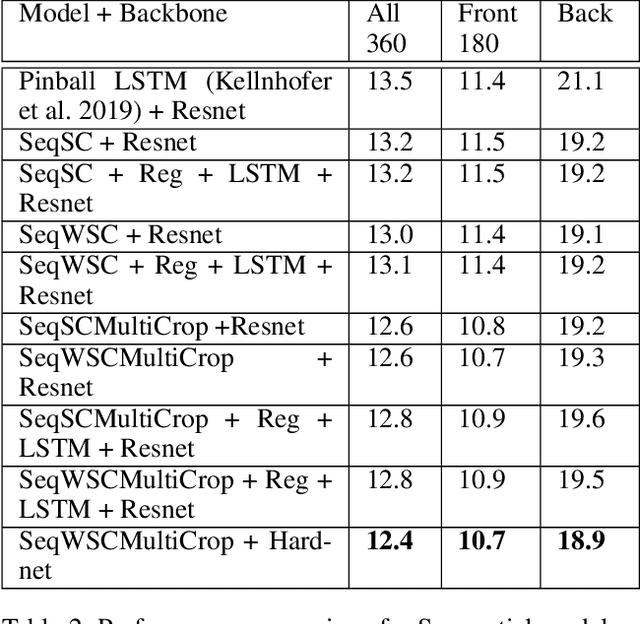
Gaze estimation involves predicting where the person is looking at, given either a single input image or a sequence of images. One challenging task, gaze estimation in the wild, concerns data collected in unconstrained environments with varying camera-person distances, like the Gaze360 dataset. The varying distances result in varying face sizes in the images, which makes it hard for current CNN backbones to estimate the gaze robustly. Inspired by our natural skill to identify the gaze by taking a focused look at the face area, we propose a novel architecture that similarly zooms in on the face area of the image at multiple scales to improve prediction accuracy. Another challenging task, 360-degree gaze estimation (also introduced by the Gaze360 dataset), consists of estimating not only the forward gazes, but also the backward ones. The backward gazes introduce discontinuity in the yaw angle values of the gaze, making the deep learning models affected by some huge loss around the discontinuous points. We propose to convert the angle values by sine-cosine transform to avoid the discontinuity and represent the physical meaning of the yaw angle better. We conduct ablation studies on both ideas, the novel architecture and the transform, to validate their effectiveness. The two ideas allow our proposed model to achieve state-of-the-art performance for both the Gaze360 dataset and the RT-Gene dataset when using single images. Furthermore, we extend the model to a sequential version that systematically zooms in on a given sequence of images. The sequential version again achieves state-of-the-art performance on the Gaze360 dataset, which further demonstrates the usefulness of our proposed ideas.
Image Segmentation for Fruit Detection and Yield Estimation in Apple Orchards
Oct 25, 2016
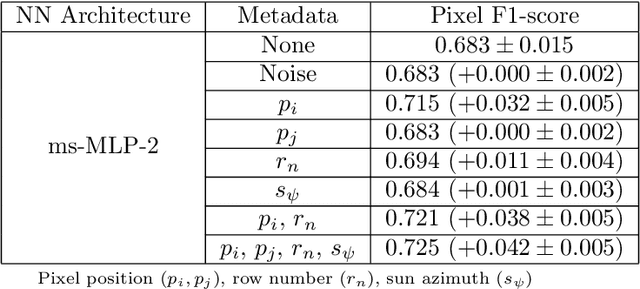


Ground vehicles equipped with monocular vision systems are a valuable source of high resolution image data for precision agriculture applications in orchards. This paper presents an image processing framework for fruit detection and counting using orchard image data. A general purpose image segmentation approach is used, including two feature learning algorithms; multi-scale Multi-Layered Perceptrons (MLP) and Convolutional Neural Networks (CNN). These networks were extended by including contextual information about how the image data was captured (metadata), which correlates with some of the appearance variations and/or class distributions observed in the data. The pixel-wise fruit segmentation output is processed using the Watershed Segmentation (WS) and Circular Hough Transform (CHT) algorithms to detect and count individual fruits. Experiments were conducted in a commercial apple orchard near Melbourne, Australia. The results show an improvement in fruit segmentation performance with the inclusion of metadata on the previously benchmarked MLP network. We extend this work with CNNs, bringing agrovision closer to the state-of-the-art in computer vision, where although metadata had negligible influence, the best pixel-wise F1-score of $0.791$ was achieved. The WS algorithm produced the best apple detection and counting results, with a detection F1-score of $0.858$. As a final step, image fruit counts were accumulated over multiple rows at the orchard and compared against the post-harvest fruit counts that were obtained from a grading and counting machine. The count estimates using CNN and WS resulted in the best performance for this dataset, with a squared correlation coefficient of $r^2=0.826$.
Removing Brightness Bias in Rectified Gradients
Nov 14, 2020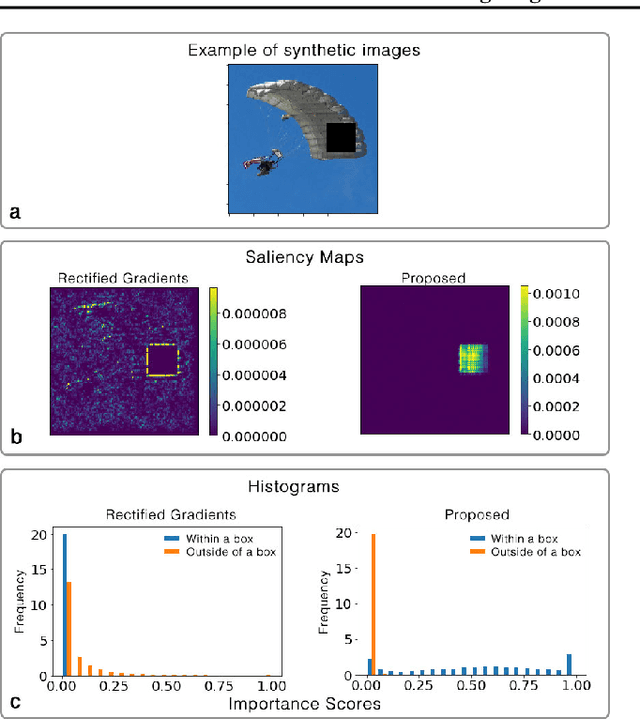
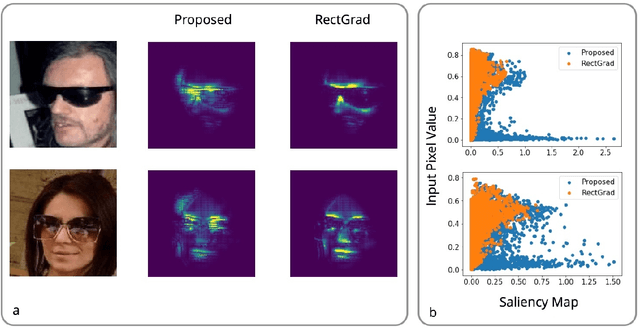
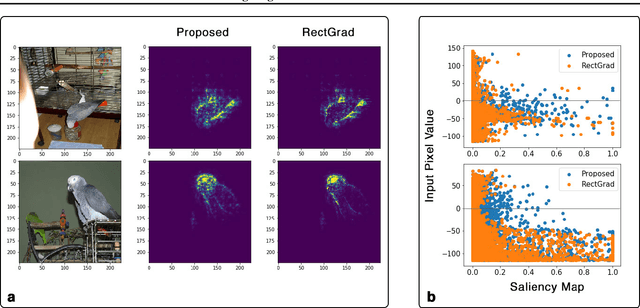
Interpretation and improvement of deep neural networks relies on better understanding of their underlying mechanisms. In particular, gradients of classes or concepts with respect to the input features (e.g., pixels in images) are often used as importance scores, which are visualized in saliency maps. Thus, a family of saliency methods provide an intuitive way to identify input features with substantial influences on classifications or latent concepts. Rectified Gradients \cite{Kim2019} is a new method which introduce layer-wise thresholding in order to denoise the saliency maps. While visually coherent in certain cases, we identify a brightness bias in Rectified Gradients. We demonstrate that dark areas of an input image are not highlighted by a saliency map using Rectified Gradients, even if it is relevant for the class or concept. Even in the scaled images, the bias exists around an artificial point in color spectrum. Our simple modification removes this bias and recovers input features that were removed due to their colors. "No Bias Rectified Gradient" is available at \url{https://github.com/lenbrocki/NoBias-Rectified-Gradient}
An Information-Geometric Distance on the Space of Tasks
Nov 01, 2020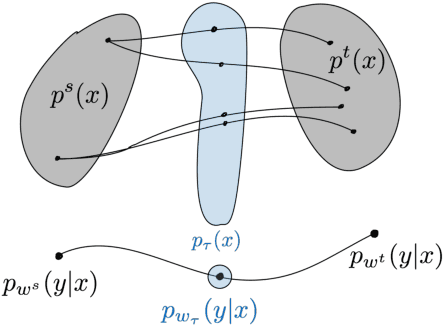
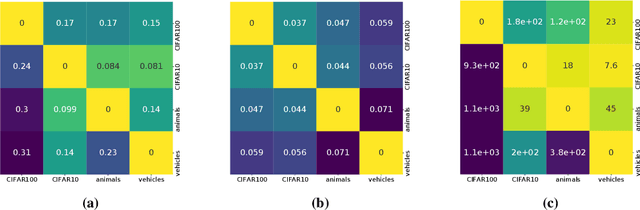
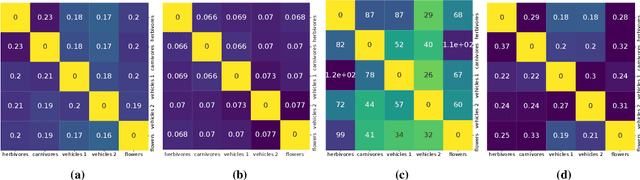
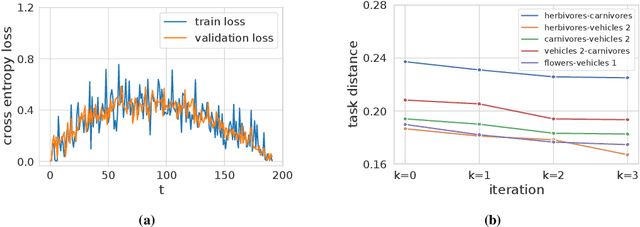
This paper computes a distance between tasks modeled as joint distributions on data and labels. We develop a stochastic process that transports the marginal on the data of the source task to that of the target task, and simultaneously updates the weights of a classifier initialized on the source task to track this evolving data distribution. The distance between two tasks is defined to be the shortest path on the Riemannian manifold of the conditional distribution of labels given data as the weights evolve. We derive connections of this distance with Rademacher complexity-based generalization bounds; distance between tasks computed using our method can be interpreted as the trajectory in weight space that keeps the generalization gap constant as the task distribution changes from the source to the target. Experiments on image classification datasets show that this task distance helps predict the performance of transfer learning: fine-tuning techniques have an easier time transferring to tasks that are close to each other under our distance.
Active Fire Detection in Landsat-8 Imagery: a Large-Scale Dataset and a Deep-Learning Study
Jan 09, 2021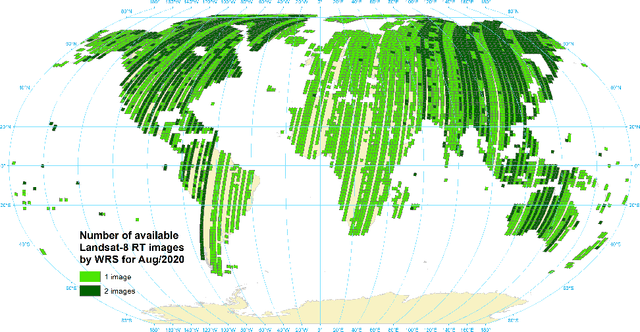
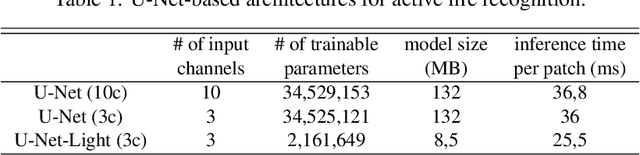
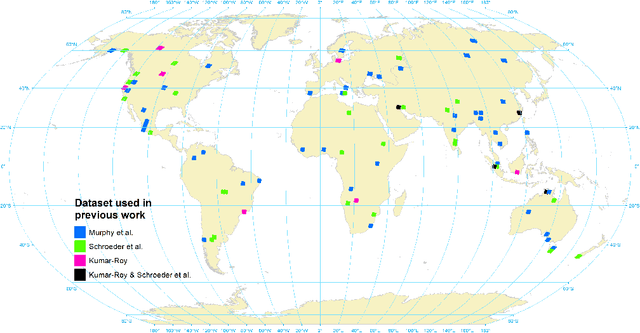
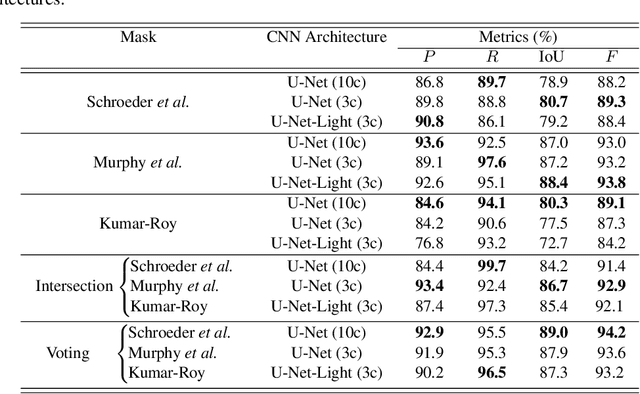
Active fire detection in satellite imagery is of critical importance to the management of environmental conservation policies, supporting decision-making and law enforcement. This is a well established field, with many techniques being proposed over the years, usually based on pixel or region-level comparisons involving sensor-specific thresholds and neighborhood statistics. In this paper, we address the problem of active fire detection using deep learning techniques. In recent years, deep learning techniques have been enjoying an enormous success in many fields, but their use for active fire detection is relatively new, with open questions and demand for datasets and architectures for evaluation. This paper addresses these issues by introducing a new large-scale dataset for active fire detection, with over 150,000 image patches (more than 200 GB of data) extracted from Landsat-8 images captured around the world in August and September 2020, containing wildfires in several locations. The dataset was split in two parts, and contains 10-band spectral images with associated outputs, produced by three well known handcrafted algorithms for active fire detection in the first part, and manually annotated masks in the second part. We also present a study on how different convolutional neural network architectures can be used to approximate these handcrafted algorithms, and how models trained on automatically segmented patches can be combined to achieve better performance than the original algorithms - with the best combination having 87.2% precision and 92.4% recall on our manually annotated dataset. The proposed dataset, source codes and trained models are available on Github (https://github.com/pereira-gha/activefire), creating opportunities for further advances in the field
Learning to Detect 3D Objects from Point Clouds in Real Time
May 09, 2020
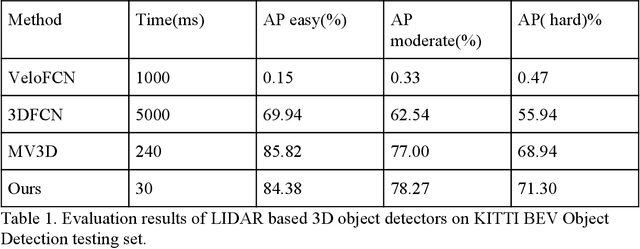
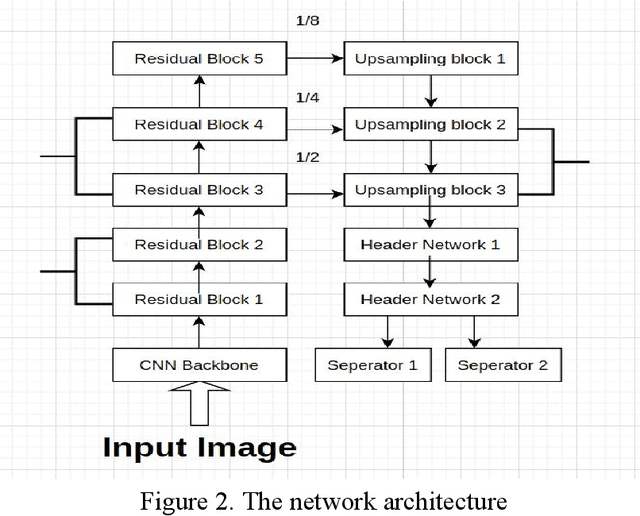
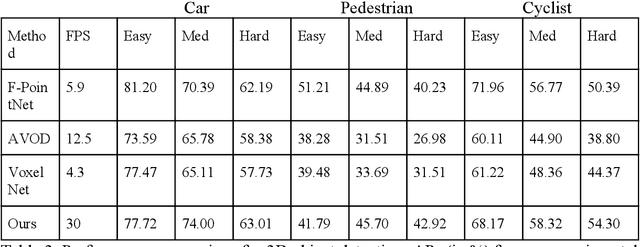
In this paper, we present a combined architecture using dilated and transposed convolutional neural networks for accurate and efficient semantic image segmentation. In contrast to previous fully convolutional neural networks such as FCN with almost all computation shared on the entire image, we propose an additional architecture which we have named as dilated - transposed fully convolutional neural networks. To achieve this goal, we used dilated convolutional layers in downsampling and transposed convolutional layers in upsampling layers. We have used skip connections in between the blocks formed by convolutions and max pooling layers. This type of architecture has been used successfully in the past for image classification using residual network. In addition we also found selu activation function instead of relu to give better results on the test set images. We reason this is the due to avoiding the model getting stuck in a local minimum, thus experiencing a famous vanishing gradient problem in case with relu activation function. Meanwhile, our result achieved pixel wise class accuracy of 88% on the test set and mean Intersection Over Union(IOU) value of 53.5 which is better than the state of the art using the previous fully convolutional neural networks.
Automated dataset generation for image recognition using the example of taxonomy
Jan 22, 2018
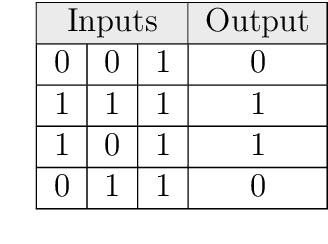
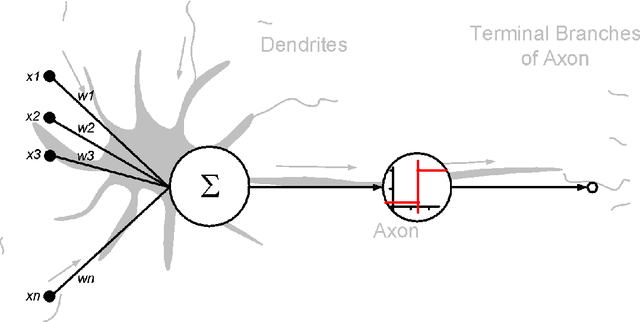
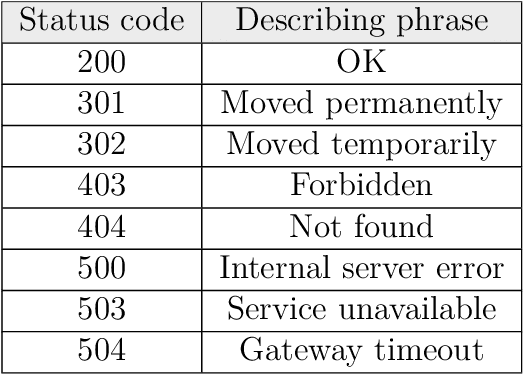
This master thesis addresses the subject of automatically generating a dataset for image recognition, which takes a lot of time when being done manually. As the thesis was written with motivation from the context of the biodiversity workgroup at the City University of Applied Sciences Bremen, the classification of taxonomic entries was chosen as an exemplary use case. In order to automate the dataset creation, a prototype was conceptualized and implemented after working out knowledge basics and analyzing requirements for it. It makes use of an pre-trained abstract artificial intelligence which is able to sort out images that do not contain the desired content. Subsequent to the implementation and the automated dataset creation resulting from it, an evaluation was performed. Other, manually collected datasets were compared to the one the prototype produced in means of specifications and accuracy. The results were more than satisfactory and showed that automatically generating a dataset for image recognition is not only possible, but also might be a decent alternative to spending time and money in doing this task manually. At the very end of this work, an idea of how to use the principle of employing abstract artificial intelligences for step-by-step classification of deeper taxonomic layers in a productive system is presented and discussed.
Self-Calibration of Cameras with Euclidean Image Plane in Case of Two Views and Known Relative Rotation Angle
Jul 30, 2018
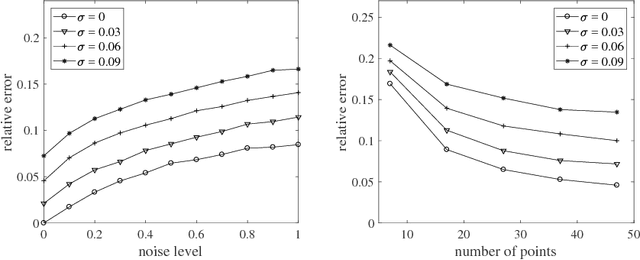
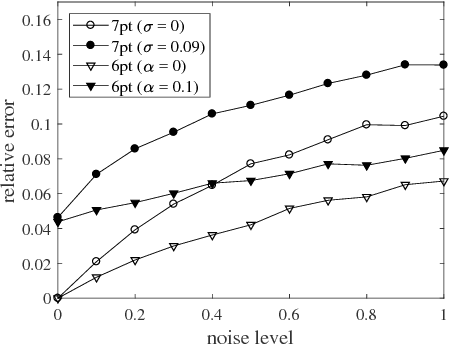
The internal calibration of a pinhole camera is given by five parameters that are combined into an upper-triangular $3\times 3$ calibration matrix. If the skew parameter is zero and the aspect ratio is equal to one, then the camera is said to have Euclidean image plane. In this paper, we propose a non-iterative self-calibration algorithm for a camera with Euclidean image plane in case the remaining three internal parameters --- the focal length and the principal point coordinates --- are fixed but unknown. The algorithm requires a set of $N \geq 7$ point correspondences in two views and also the measured relative rotation angle between the views. We show that the problem generically has six solutions (including complex ones). The algorithm has been implemented and tested both on synthetic data and on publicly available real dataset. The experiments demonstrate that the method is correct, numerically stable and robust.
* 13 pages, 7 eps-figures