 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Segmentation of Multi-Shaped Overlapping Objects
Nov 06, 2017

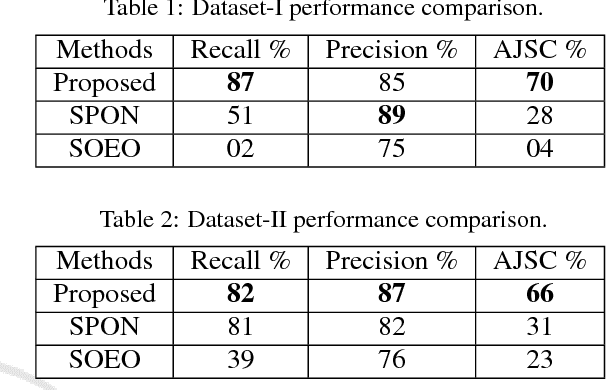

In this work, we propose a new segmentation algorithm for images containing convex objects present in multiple shapes with a high degree of overlap. The proposed algorithm is carried out in two steps, first we identify the visible contours, segment them using concave points and finally group the segments belonging to the same object. The next step is to assign a shape identity to these grouped contour segments. For images containing objects in multiple shapes we begin first by identifying shape classes of the contours followed by assigning a shape entity to these classes. We provide a comprehensive experimentation of our algorithm on two crystal image datasets. One dataset comprises of images containing objects in multiple shapes overlapping each other and the other dataset contains standard images with objects present in a single shape. We test our algorithm against two baselines, with our proposed algorithm outperforming both the baselines.
Learning an Animatable Detailed 3D Face Model from In-The-Wild Images
Dec 07, 2020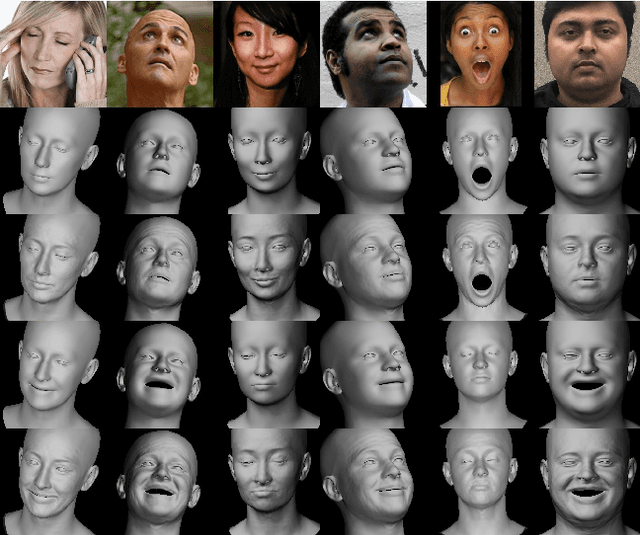
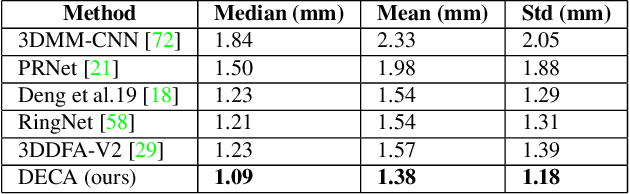
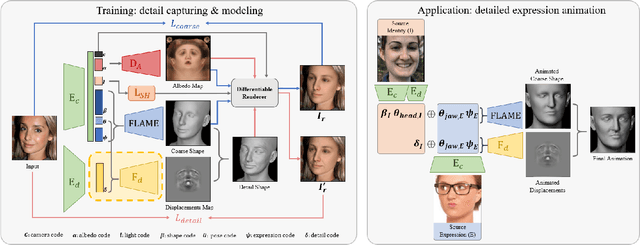
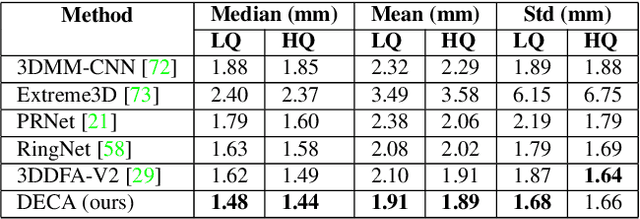
While current monocular 3D face reconstruction methods can recover fine geometric details, they suffer several limitations. Some methods produce faces that cannot be realistically animated because they do not model how wrinkles vary with expression. Other methods are trained on high-quality face scans and do not generalize well to in-the-wild images. We present the first approach to jointly learn a model with animatable detail and a detailed 3D face regressor from in-the-wild images that recovers shape details as well as their relationship to facial expressions. Our DECA (Detailed Expression Capture and Animation) model is trained to robustly produce a UV displacement map from a low-dimensional latent representation that consists of person-specific detail parameters and generic expression parameters, while a regressor is trained to predict detail, shape, albedo, expression, pose and illumination parameters from a single image. We introduce a novel detail-consistency loss to disentangle person-specific details and expression-dependent wrinkles. This disentanglement allows us to synthesize realistic person-specific wrinkles by controlling expression parameters while keeping person-specific details unchanged. DECA achieves state-of-the-art shape reconstruction accuracy on two benchmarks. Qualitative results on in-the-wild data demonstrate DECA's robustness and its ability to disentangle identity and expression dependent details enabling animation of reconstructed faces. The model and code are publicly available at https://github.com/YadiraF/DECA.
Progressively Diffused Networks for Semantic Image Segmentation
Feb 20, 2017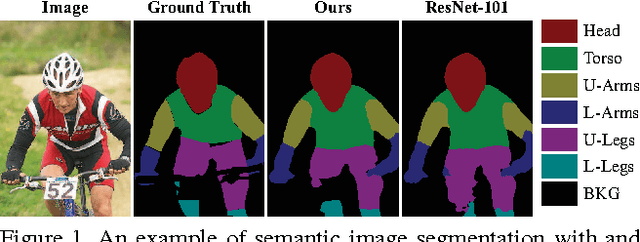
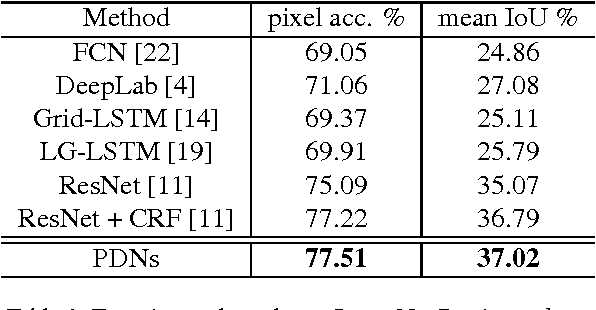
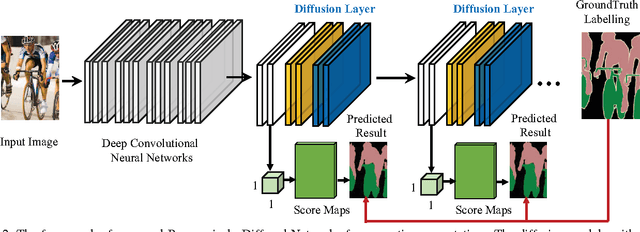
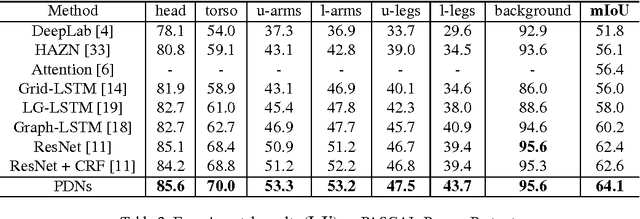
This paper introduces Progressively Diffused Networks (PDNs) for unifying multi-scale context modeling with deep feature learning, by taking semantic image segmentation as an exemplar application. Prior neural networks, such as ResNet, tend to enhance representational power by increasing the depth of architectures and driving the training objective across layers. However, we argue that spatial dependencies in different layers, which generally represent the rich contexts among data elements, are also critical to building deep and discriminative representations. To this end, our PDNs enables to progressively broadcast information over the learned feature maps by inserting a stack of information diffusion layers, each of which exploits multi-dimensional convolutional LSTMs (Long-Short-Term Memory Structures). In each LSTM unit, a special type of atrous filters are designed to capture the short range and long range dependencies from various neighbors to a certain site of the feature map and pass the accumulated information to the next layer. From the extensive experiments on semantic image segmentation benchmarks (e.g., ImageNet Parsing, PASCAL VOC2012 and PASCAL-Part), our framework demonstrates the effectiveness to substantially improve the performances over the popular existing neural network models, and achieves state-of-the-art on ImageNet Parsing for large scale semantic segmentation.
TRLG: Fragile blind quad watermarking for image tamper detection and recovery by providing compact digests with quality optimized using LWT and GA
Mar 07, 2018
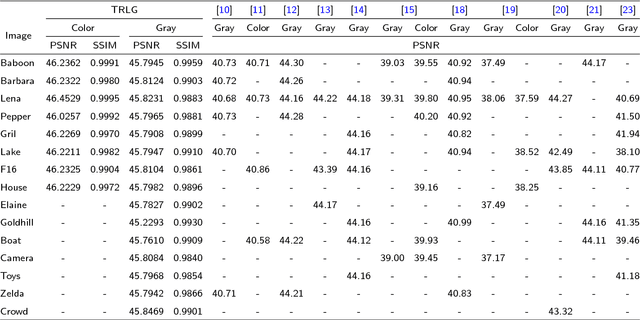
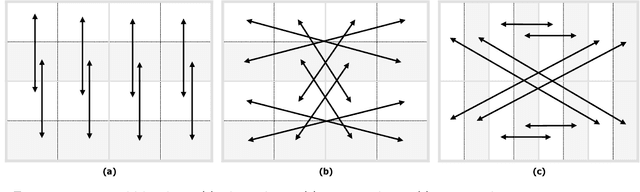
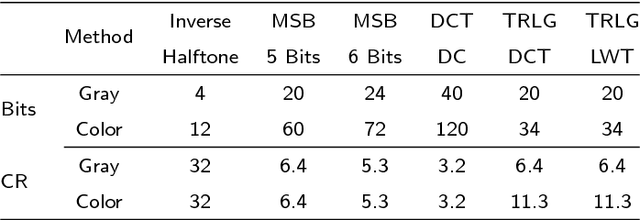
In this paper, an efficient fragile blind quad watermarking scheme for image tamper detection and recovery based on lifting wavelet transform and genetic algorithm is proposed. TRLG generates four compact digests with super quality based on lifting wavelet transform and halftoning technique by distinguishing the types of image blocks. In other words, for each 2*2 non-overlap blocks, four chances for recovering destroyed blocks are considered. A special parameter estimation technique based on genetic algorithm is performed to improve and optimize the quality of digests and watermarked image. Furthermore, CCS map is used to determine the mapping block for embedding information, encrypting and confusing the embedded information. In order to improve the recovery rate, Mirror-aside and Partner-block are proposed. The experiments that have been conducted to evaluate the performance of TRLG proved the superiority in terms of quality of the watermarked and recovered image, tamper localization and security compared with state-of-the-art methods. The results indicate that the PSNR and SSIM of the watermarked image are about 46 dB and approximately one, respectively. Also, the mean of PSNR and SSIM of several recovered images which has been destroyed about 90% is reached to 24 dB and 0.86, respectively.
Learning to Deblur and Generate High Frame Rate Video with an Event Camera
Mar 20, 2020
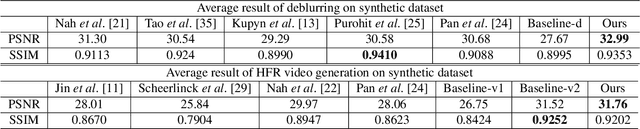
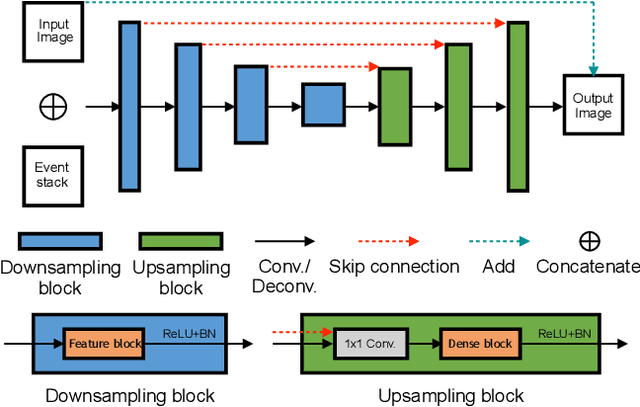
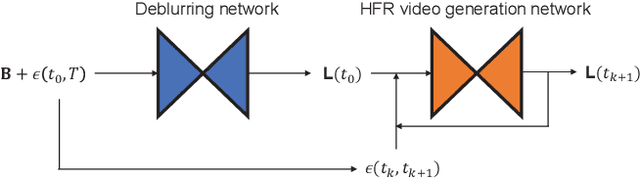
Event cameras are bio-inspired cameras which can measure the change of intensity asynchronously with high temporal resolution. One of the event cameras' advantages is that they do not suffer from motion blur when recording high-speed scenes. In this paper, we formulate the deblurring task on traditional cameras directed by events to be a residual learning one, and we propose corresponding network architectures for effective learning of deblurring and high frame rate video generation tasks. We first train a modified U-Net network to restore a sharp image from a blurry image using corresponding events. Then we train another similar network with different downsampling blocks to generate high frame rate video using the restored sharp image and events. Experiment results show that our method can restore sharper images and videos than state-of-the-art methods.
Rotated Ring, Radial and Depth Wise Separable Radial Convolutions
Oct 02, 2020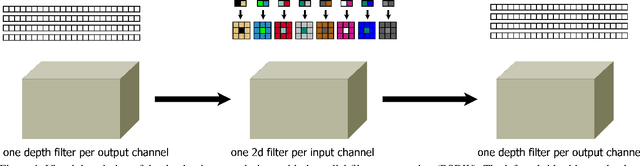

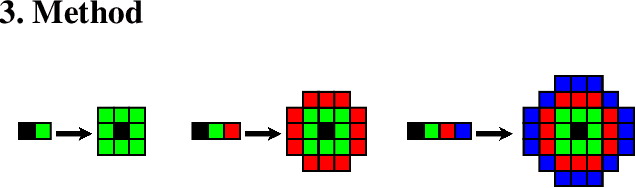

Simple image rotations significantly reduce the accuracy of deep neural networks. Moreover, training with all possible rotations increases the data set, which also increases the training duration. In this work, we address trainable rotation invariant convolutions as well as the construction of nets, since fully connected layers can only be rotation invariant with a one-dimensional input. On the one hand, we show that our approach is rotationally invariant for different models and on different public data sets. We also discuss the influence of purely rotational invariant features on accuracy. The rotationally adaptive convolution models presented in this work are more computationally intensive than normal convolution models. Therefore, we also present a depth wise separable approach with radial convolution. Link to CUDA code https://atreus.informatik.uni-tuebingen.de/seafile/d/8e2ab8c3fdd444e1a135/
Exploring Intermediate Representation for Monocular Vehicle Pose Estimation
Nov 17, 2020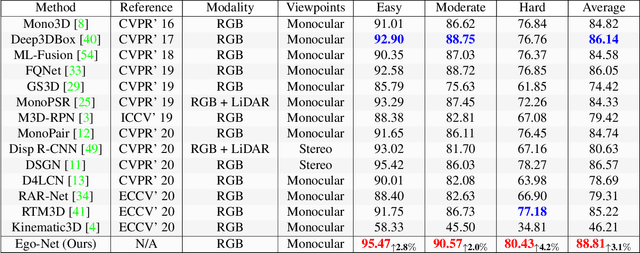

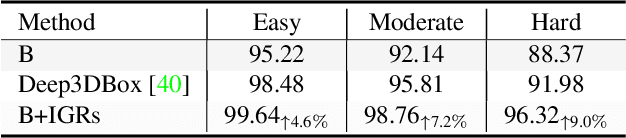
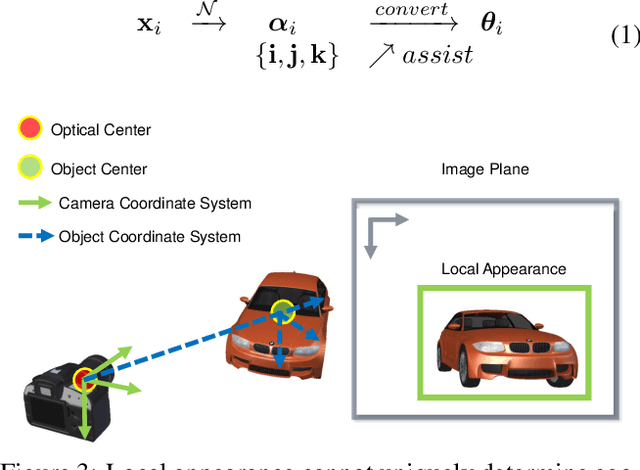
We present a new learning-based approach to recover egocentric 3D vehicle pose from a single RGB image. In contrast to previous works that directly map from local appearance to 3D angles, we explore a progressive approach by extracting meaningful Intermediate Geometrical Representations (IGRs) for 3D pose estimation. We design a deep model that transforms perceived intensities to IGRs, which are mapped to a 3D representation encoding object orientation in the camera coordinate system. To fulfill our goal, we need to specify what IGRs to use and how to learn them more effectively. We answer the former question by designing an interpolated cuboid representation that derives from primitive 3D annotation readily. The latter question motivates us to incorporate geometry knowledge by designing a new loss function based on a projective invariant. This loss function allows unlabeled data to be used in the training stage which is validated to improve representation learning. Our system outperforms previous monocular RGB-based methods for joint vehicle detection and pose estimation on the KITTI benchmark, achieving performance even comparable to stereo methods. Code and pre-trained models will be available at the project website.
Flickr30k Entities: Collecting Region-to-Phrase Correspondences for Richer Image-to-Sentence Models
Sep 19, 2016
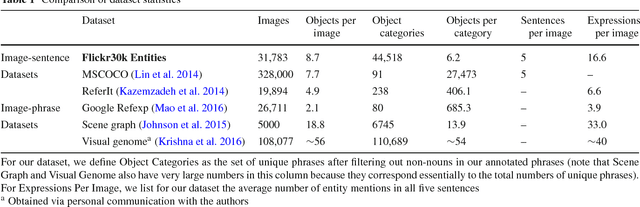
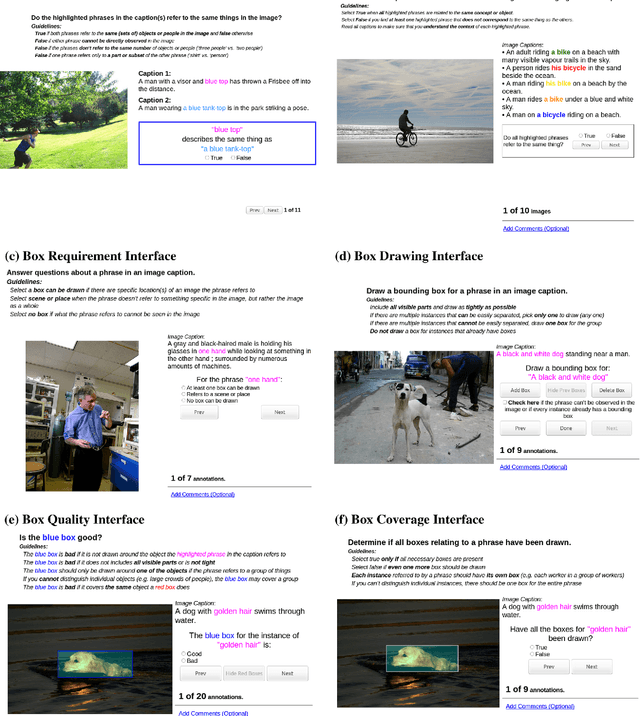

The Flickr30k dataset has become a standard benchmark for sentence-based image description. This paper presents Flickr30k Entities, which augments the 158k captions from Flickr30k with 244k coreference chains, linking mentions of the same entities across different captions for the same image, and associating them with 276k manually annotated bounding boxes. Such annotations are essential for continued progress in automatic image description and grounded language understanding. They enable us to define a new benchmark for localization of textual entity mentions in an image. We present a strong baseline for this task that combines an image-text embedding, detectors for common objects, a color classifier, and a bias towards selecting larger objects. While our baseline rivals in accuracy more complex state-of-the-art models, we show that its gains cannot be easily parlayed into improvements on such tasks as image-sentence retrieval, thus underlining the limitations of current methods and the need for further research.
Deep Affordance Foresight: Planning Through What Can Be Done in the Future
Nov 17, 2020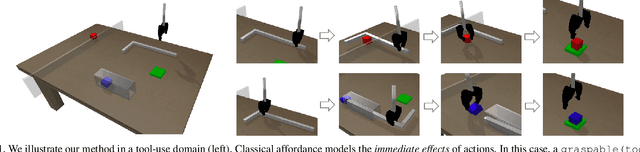
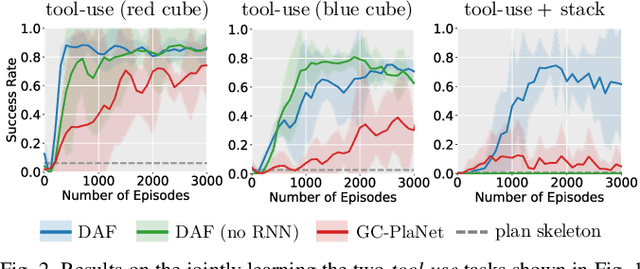
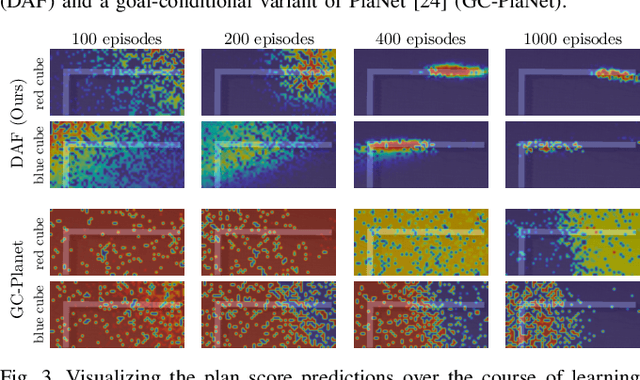
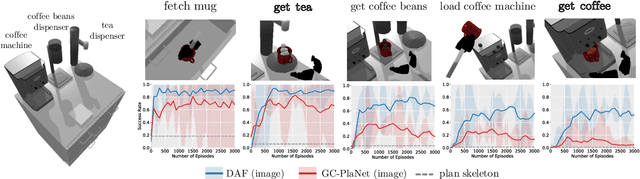
Planning in realistic environments requires searching in large planning spaces. Affordances are a powerful concept to simplify this search, because they model what actions can be successful in a given situation. However, the classical notion of affordance is not suitable for long horizon planning because it only informs the robot about the immediate outcome of actions instead of what actions are best for achieving a long-term goal. In this paper, we introduce a new affordance representation that enables the robot to reason about the long-term effects of actions through modeling what actions are afforded in the future, thereby informing the robot the best actions to take next to achieve a task goal. Based on the new representation, we develop a learning-to-plan method, Deep Affordance Foresight (DAF), that learns partial environment models of affordances of parameterized motor skills through trial-and-error. We evaluate DAF on two challenging manipulation domains and show that it can effectively learn to carry out multi-step tasks, share learned affordance representations among different tasks, and learn to plan with high-dimensional image inputs. Additional material is available at https://sites.google.com/stanford.edu/daf
Looking for the Devil in the Details: Learning Trilinear Attention Sampling Network for Fine-grained Image Recognition
Mar 14, 2019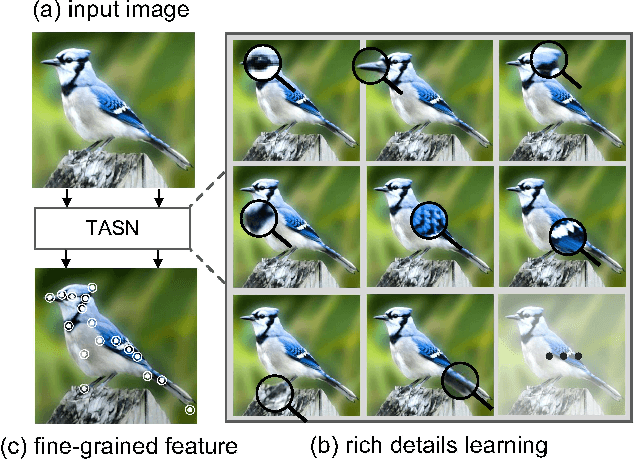
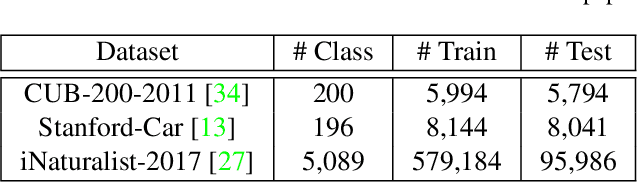
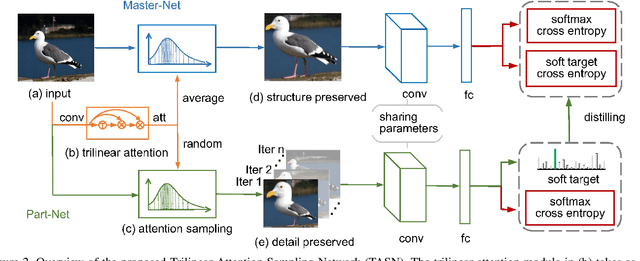
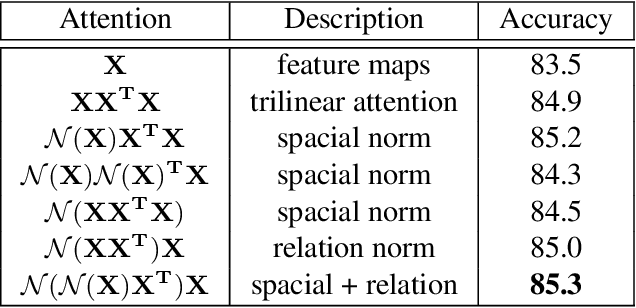
Learning subtle yet discriminative features (e.g., beak and eyes for a bird) plays a significant role in fine-grained image recognition. Existing attention-based approaches localize and amplify significant parts to learn fine-grained details, which often suffer from a limited number of parts and heavy computational cost. In this paper, we propose to learn such fine-grained features from hundreds of part proposals by Trilinear Attention Sampling Network (TASN) in an efficient teacher-student manner. Specifically, TASN consists of 1) a trilinear attention module, which generates attention maps by modeling the inter-channel relationships, 2) an attention-based sampler which highlights attended parts with high resolution, and 3) a feature distiller, which distills part features into a global one by weight sharing and feature preserving strategies. Extensive experiments verify that TASN yields the best performance under the same settings with the most competitive approaches, in iNaturalist-2017, CUB-Bird, and Stanford-Cars datasets.