 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Estimation, Confidence Intervals, and Large-Scale Hypotheses Testing for High-Dimensional Mixed Linear Regression
Nov 06, 2020
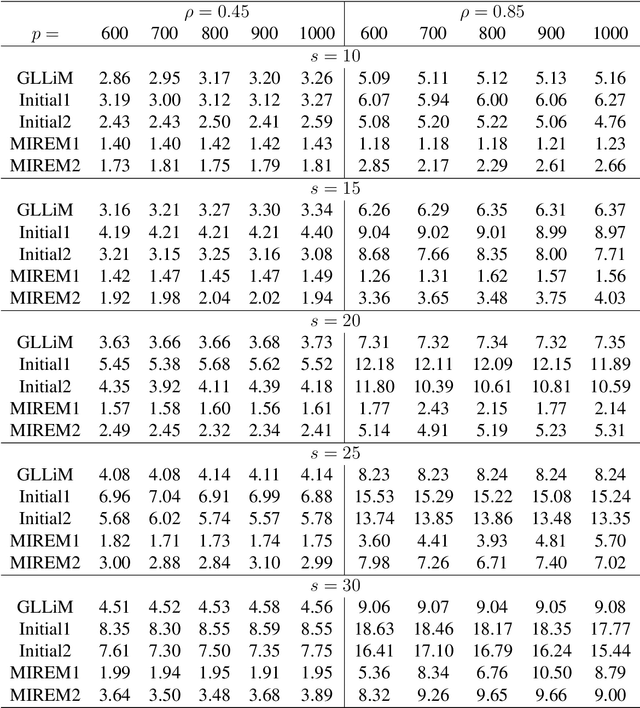
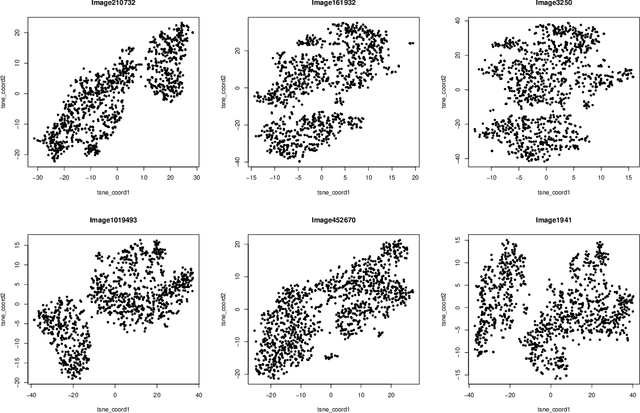
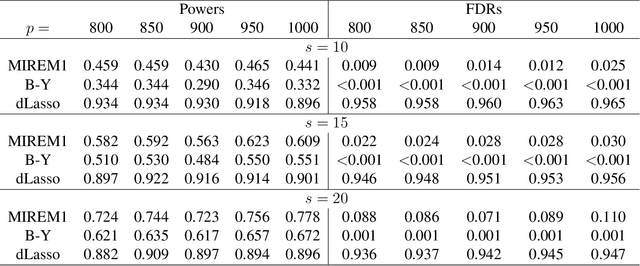
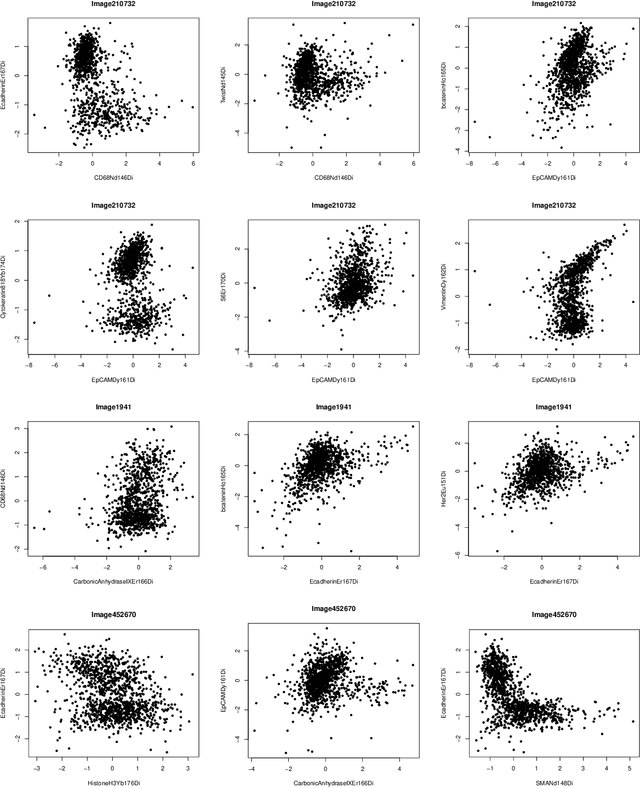
This paper studies the high-dimensional mixed linear regression (MLR) where the output variable comes from one of the two linear regression models with an unknown mixing proportion and an unknown covariance structure of the random covariates. Building upon a high-dimensional EM algorithm, we propose an iterative procedure for estimating the two regression vectors and establish their rates of convergence. Based on the iterative estimators, we further construct debiased estimators and establish their asymptotic normality. For individual coordinates, confidence intervals centered at the debiased estimators are constructed. Furthermore, a large-scale multiple testing procedure is proposed for testing the regression coefficients and is shown to control the false discovery rate (FDR) asymptotically. Simulation studies are carried out to examine the numerical performance of the proposed methods and their superiority over existing methods. The proposed methods are further illustrated through an analysis of a dataset of multiplex image cytometry, which investigates the interaction networks among the cellular phenotypes that include the expression levels of 20 epitopes or combinations of markers.
A Survey on Patch-based Synthesis: GPU Implementation and Optimization
May 11, 2020This thesis surveys the research in patch-based synthesis and algorithms for finding correspondences between small local regions of images. We additionally explore a large kind of applications of this new fast randomized matching technique. One of the algorithms we have studied in particular is PatchMatch, can find similar regions or "patches" of an image one to two orders of magnitude faster than previous techniques. The algorithmic program is driven by applying mathematical properties of nearest neighbors in natural images. It is observed that neighboring correspondences tend to be similar or "coherent" and use this observation in algorithm in order to quickly converge to an approximate solution. The algorithm is the most general form can find k-nearest neighbor matching, using patches that translate, rotate, or scale, using arbitrary descriptors, and between two or more images. Speed-ups are obtained over various techniques in an exceeding range of those areas. We have explored many applications of PatchMatch matching algorithm. In computer graphics, we have explored removing unwanted objects from images, seamlessly moving objects in images, changing image aspect ratios, and video summarization. In computer vision we have explored denoising images, object detection, detecting image forgeries, and detecting symmetries. We conclude by discussing the restrictions of our algorithmic program, GPU implementation and areas for future analysis.
Structured Landmark Detection via Topology-Adapting Deep Graph Learning
Apr 17, 2020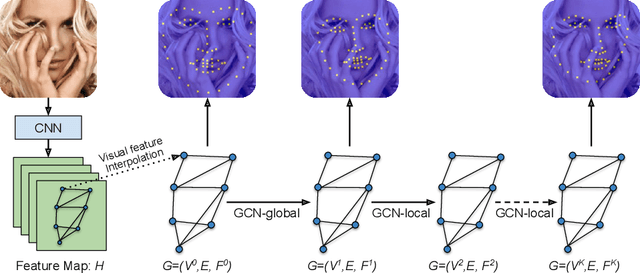
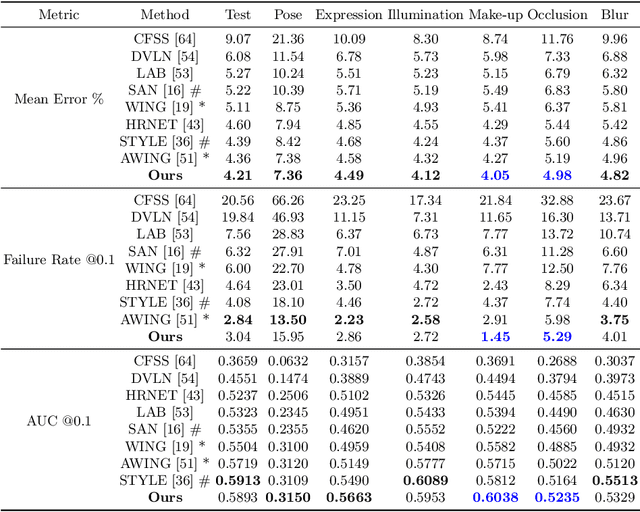

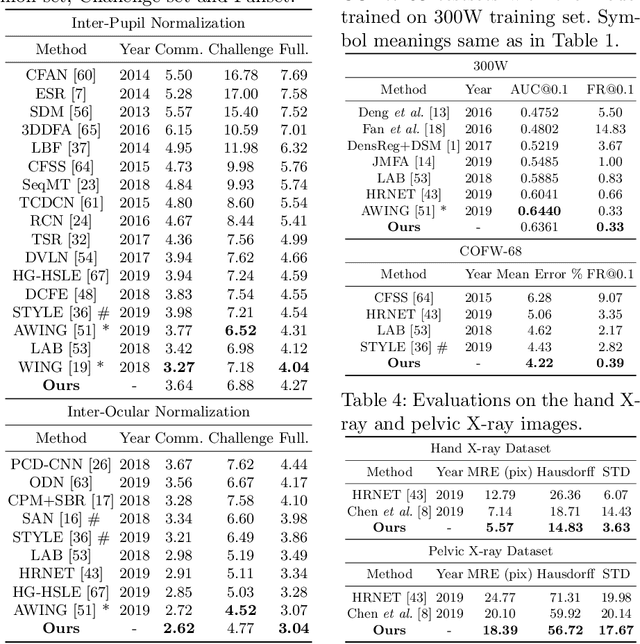
Image landmark detection aims to automatically identify the locations of predefined fiducial points. Despite recent success in this filed, higher-ordered structural modeling to capture implicit or explicit relationships among anatomical landmarks has not been adequately exploited. In this work, we present a new topology-adapting deep graph learning approach for accurate anatomical facial and medical (e.g., hand, pelvis) landmark detection. The proposed method constructs graph signals leveraging both local image features and global shape features. The adaptive graph topology naturally explores and lands on task-specific structures which is learned end-to-end with two Graph Convolutional Networks (GCNs). Extensive experiments are conducted on three public facial image datasets (WFLW, 300W and COFW-68) as well as three real-world X-ray medical datasets (Cephalometric (public), Hand and Pelvis). Quantitative results comparing with the previous state-of-the-art approaches across all studied datasets indicating the superior performance in both robustness and accuracy. Qualitative visualizations of the learned graph topologies demonstrate a physically plausible connectivity laying behind the landmarks.
Talking about the Moving Image: A Declarative Model for Image Schema Based Embodied Perception Grounding and Language Generation
Aug 13, 2015


We present a general theory and corresponding declarative model for the embodied grounding and natural language based analytical summarisation of dynamic visuo-spatial imagery. The declarative model ---ecompassing spatio-linguistic abstractions, image schemas, and a spatio-temporal feature based language generator--- is modularly implemented within Constraint Logic Programming (CLP). The implemented model is such that primitives of the theory, e.g., pertaining to space and motion, image schemata, are available as first-class objects with `deep semantics' suited for inference and query. We demonstrate the model with select examples broadly motivated by areas such as film, design, geography, smart environments where analytical natural language based externalisations of the moving image are central from the viewpoint of human interaction, evidence-based qualitative analysis, and sensemaking. Keywords: moving image, visual semantics and embodiment, visuo-spatial cognition and computation, cognitive vision, computational models of narrative, declarative spatial reasoning
DeepNAG: Deep Non-Adversarial Gesture Generation
Nov 18, 2020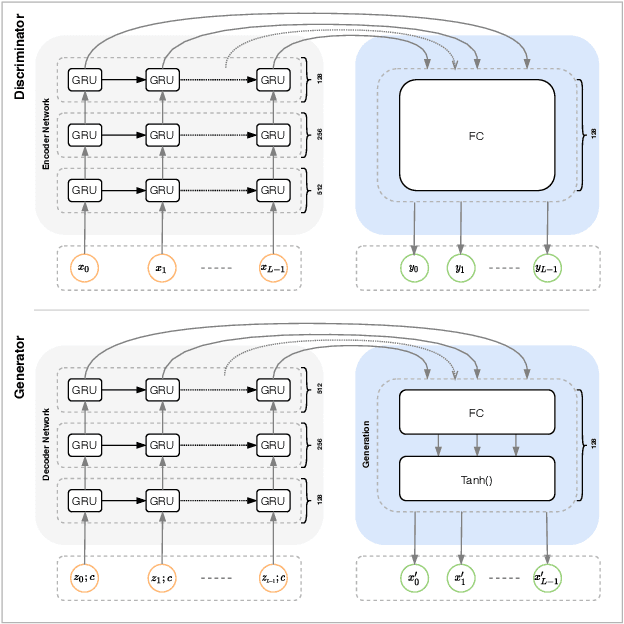
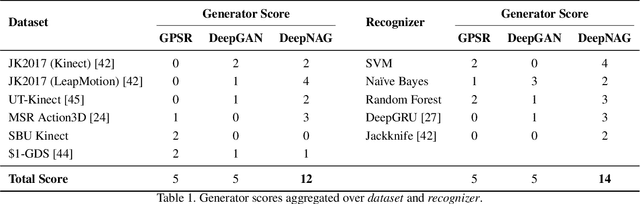
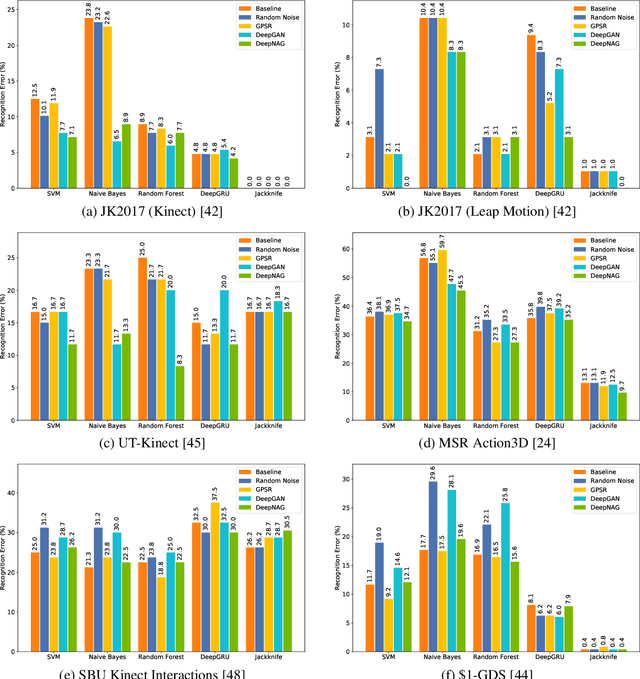

Synthetic data generation to improve classification performance (data augmentation) is a well-studied problem. Recently, generative adversarial networks (GAN) have shown superior image data augmentation performance, but their suitability in gesture synthesis has received inadequate attention. Further, GANs prohibitively require simultaneous generator and discriminator network training. We tackle both issues in this work. We first discuss a novel, device-agnostic GAN model for gesture synthesis called DeepGAN. Thereafter, we formulate DeepNAG by introducing a new differentiable loss function based on dynamic time warping and the average Hausdorff distance, which allows us to train DeepGAN's generator without requiring a discriminator. Through evaluations, we compare the utility of DeepGAN and DeepNAG against two alternative techniques for training five recognizers using data augmentation over six datasets. We further investigate the perceived quality of synthesized samples via an Amazon Mechanical Turk user study based on the HYPE benchmark. We find that DeepNAG outperforms DeepGAN in accuracy, training time (up to 17x faster), and realism, thereby opening the door to a new line of research in generator network design and training for gesture synthesis. Our source code is available at https://www.deepnag.com.
Polygonal Building Segmentation by Frame Field Learning
Apr 30, 2020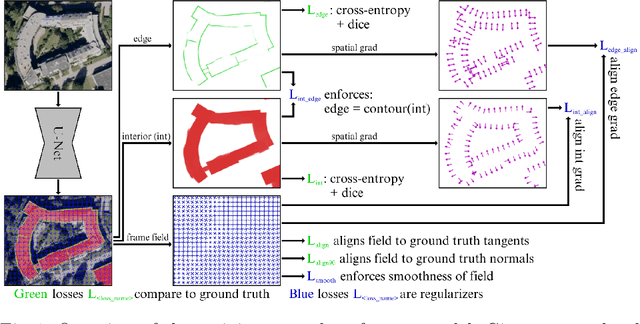
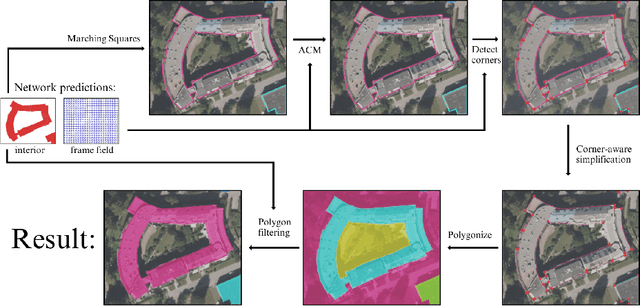

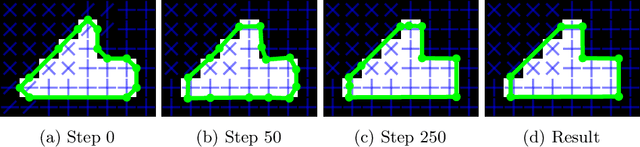
While state of the art image segmentation models typically output segmentations in raster format, applications in geographic information systems often require vector polygons. We propose adding a frame field output to a deep image segmentation model for extracting buildings from remote sensing images. This improves segmentation quality and provides structural information, facilitating more accurate polygonization. To this end, we train a deep neural network, which aligns a predicted frame field to ground truth contour data. In addition to increasing performance by leveraging multi-task learning, our method produces more regular segmentations. We also introduce a new polygonization algorithm, which is guided by the frame field corresponding to the raster segmentation.
Privacy Preserving Visual SLAM
Jul 27, 2020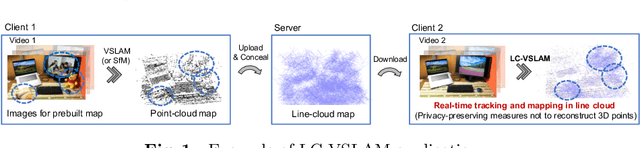

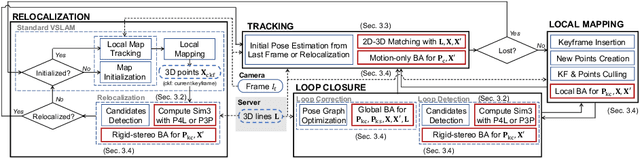

This study proposes a privacy-preserving Visual SLAM framework for estimating camera poses and performing bundle adjustment with mixed line and point clouds in real time. Previous studies have proposed localization methods to estimate a camera pose using a line-cloud map for a single image or a reconstructed point cloud. These methods offer a scene privacy protection against the inversion attacks by converting a point cloud to a line cloud, which reconstruct the scene images from the point cloud. However, they are not directly applicable to a video sequence because they do not address computational efficiency. This is a critical issue to solve for estimating camera poses and performing bundle adjustment with mixed line and point clouds in real time. Moreover, there has been no study on a method to optimize a line-cloud map of a server with a point cloud reconstructed from a client video because any observation points on the image coordinates are not available to prevent the inversion attacks, namely the reversibility of the 3D lines. The experimental results with synthetic and real data show that our Visual SLAM framework achieves the intended privacy-preserving formation and real-time performance using a line-cloud map.
A Deep Learning-Based Method for Automatic Segmentation of Proximal Femur from Quantitative Computed Tomography Images
Jul 01, 2020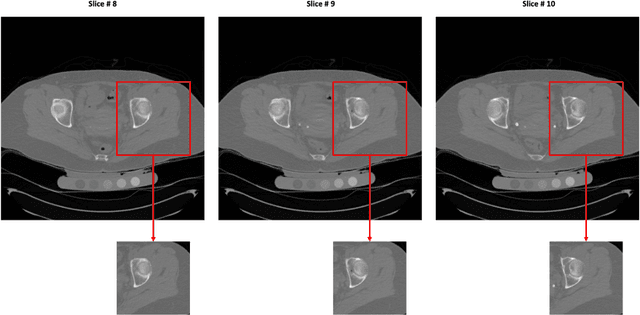
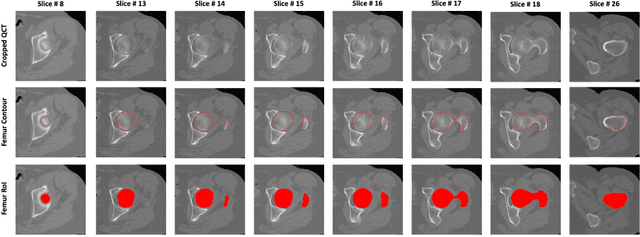

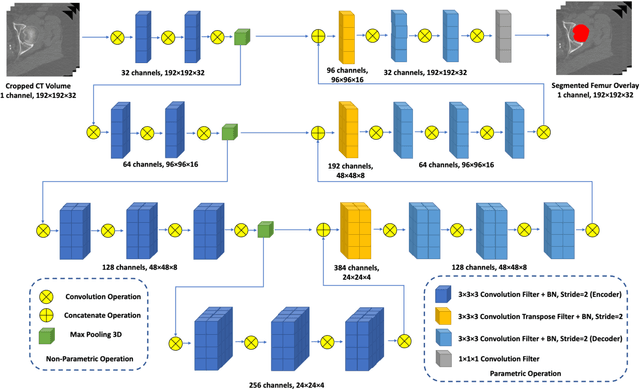
Purpose: Proximal femur image analyses based on quantitative computed tomography (QCT) provide a method to quantify the bone density and evaluate osteoporosis and risk of fracture. We aim to develop a deep-learning-based method for automatic proximal femur segmentation. Methods and Materials: We developed a 3D image segmentation method based on V-Net, an end-to-end fully convolutional neural network (CNN), to extract the proximal femur QCT images automatically. The proposed V-net methodology adopts a compound loss function, which includes a Dice loss and a L2 regularizer. We performed experiments to evaluate the effectiveness of the proposed segmentation method. In the experiments, a QCT dataset which included 397 QCT subjects was used. For the QCT image of each subject, the ground truth for the proximal femur was delineated by a well-trained scientist. During the experiments for the entire cohort then for male and female subjects separately, 90% of the subjects were used in 10-fold cross-validation for training and internal validation, and to select the optimal parameters of the proposed models; the rest of the subjects were used to evaluate the performance of models. Results: Visual comparison demonstrated high agreement between the model prediction and ground truth contours of the proximal femur portion of the QCT images. In the entire cohort, the proposed model achieved a Dice score of 0.9815, a sensitivity of 0.9852 and a specificity of 0.9992. In addition, an R2 score of 0.9956 (p<0.001) was obtained when comparing the volumes measured by our model prediction with the ground truth. Conclusion: This method shows a great promise for clinical application to QCT and QCT-based finite element analysis of the proximal femur for evaluating osteoporosis and hip fracture risk.
Class-agnostic Object Detection
Nov 28, 2020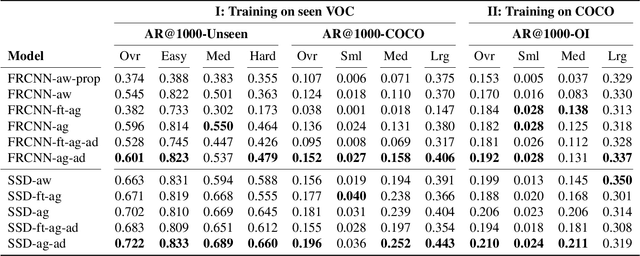
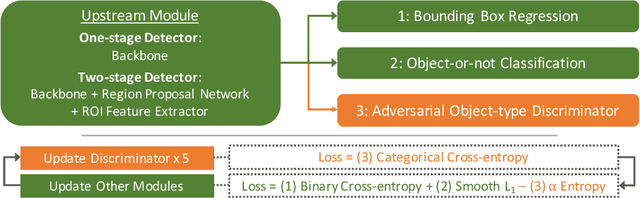
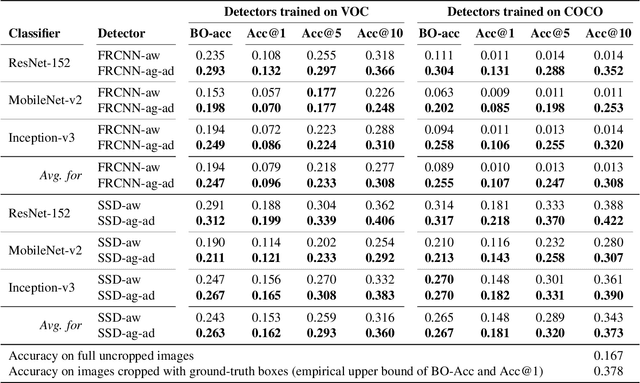
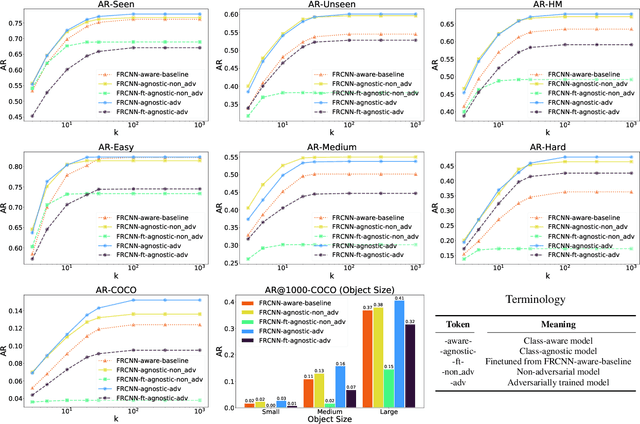
Object detection models perform well at localizing and classifying objects that they are shown during training. However, due to the difficulty and cost associated with creating and annotating detection datasets, trained models detect a limited number of object types with unknown objects treated as background content. This hinders the adoption of conventional detectors in real-world applications like large-scale object matching, visual grounding, visual relation prediction, obstacle detection (where it is more important to determine the presence and location of objects than to find specific types), etc. We propose class-agnostic object detection as a new problem that focuses on detecting objects irrespective of their object-classes. Specifically, the goal is to predict bounding boxes for all objects in an image but not their object-classes. The predicted boxes can then be consumed by another system to perform application-specific classification, retrieval, etc. We propose training and evaluation protocols for benchmarking class-agnostic detectors to advance future research in this domain. Finally, we propose (1) baseline methods and (2) a new adversarial learning framework for class-agnostic detection that forces the model to exclude class-specific information from features used for predictions. Experimental results show that adversarial learning improves class-agnostic detection efficacy.
A Hierarchical Feature Constraint to Camouflage Medical Adversarial Attacks
Dec 17, 2020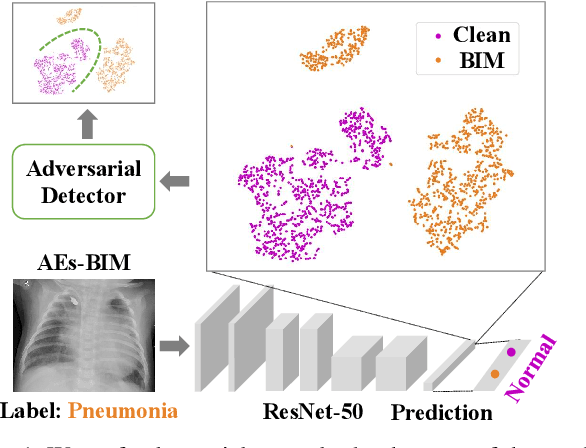
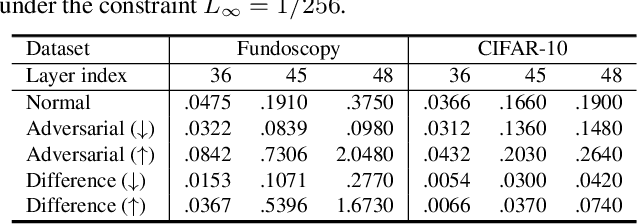
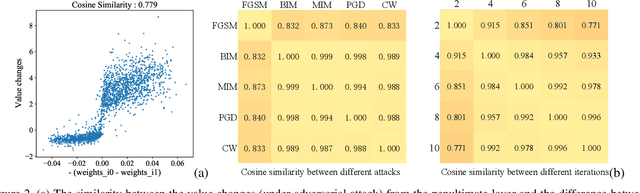
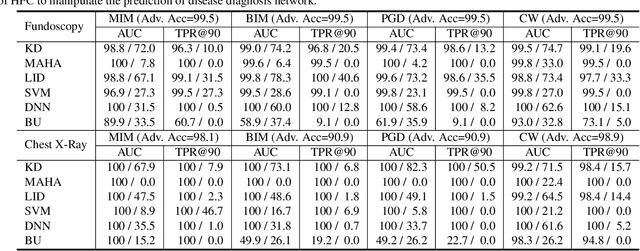
Deep neural networks (DNNs) for medical images are extremely vulnerable to adversarial examples (AEs), which poses security concerns on clinical decision making. Luckily, medical AEs are also easy to detect in hierarchical feature space per our study herein. To better understand this phenomenon, we thoroughly investigate the intrinsic characteristic of medical AEs in feature space, providing both empirical evidence and theoretical explanations for the question: why are medical adversarial attacks easy to detect? We first perform a stress test to reveal the vulnerability of deep representations of medical images, in contrast to natural images. We then theoretically prove that typical adversarial attacks to binary disease diagnosis network manipulate the prediction by continuously optimizing the vulnerable representations in a fixed direction, resulting in outlier features that make medical AEs easy to detect. However, this vulnerability can also be exploited to hide the AEs in the feature space. We propose a novel hierarchical feature constraint (HFC) as an add-on to existing adversarial attacks, which encourages the hiding of the adversarial representation within the normal feature distribution. We evaluate the proposed method on two public medical image datasets, namely {Fundoscopy} and {Chest X-Ray}. Experimental results demonstrate the superiority of our adversarial attack method as it bypasses an array of state-of-the-art adversarial detectors more easily than competing attack methods, supporting that the great vulnerability of medical features allows an attacker more room to manipulate the adversarial representations.