 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Multi-class Approach -- Building a Visual Classifier based on Textual Descriptions using Zero-Shot Learning
Nov 18, 2020


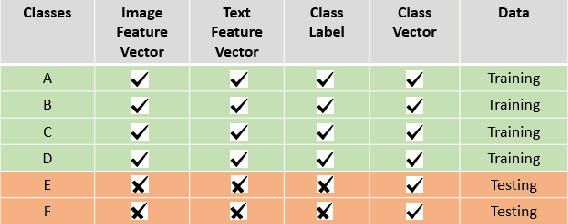
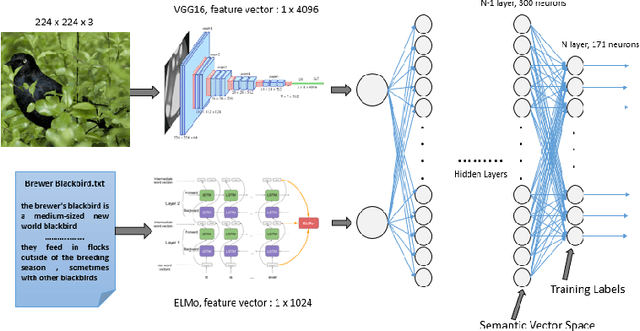
Machine Learning (ML) techniques for image classification routinely require many labelled images for training the model and while testing, we ought to use images belonging to the same domain as those used for training. In this paper, we overcome the two main hurdles of ML, i.e. scarcity of data and constrained prediction of the classification model. We do this by introducing a visual classifier which uses a concept of transfer learning, namely Zero-Shot Learning (ZSL), and standard Natural Language Processing techniques. We train a classifier by mapping labelled images to their textual description instead of training it for specific classes. Transfer learning involves transferring knowledge across domains that are similar. ZSL intelligently applies the knowledge learned while training for future recognition tasks. ZSL differentiates classes as two types: seen and unseen classes. Seen classes are the classes upon which we have trained our model and unseen classes are the classes upon which we test our model. The examples from unseen classes have not been encountered in the training phase. Earlier research in this domain focused on developing a binary classifier but, in this paper, we present a multi-class classifier with a Zero-Shot Learning approach.
Proposing method to Increase the detection accuracy of stomach cancer based on colour and lint features of tongue using CNN and SVM
Nov 18, 2020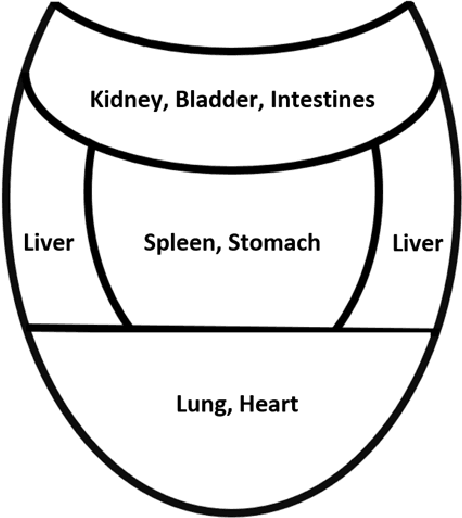
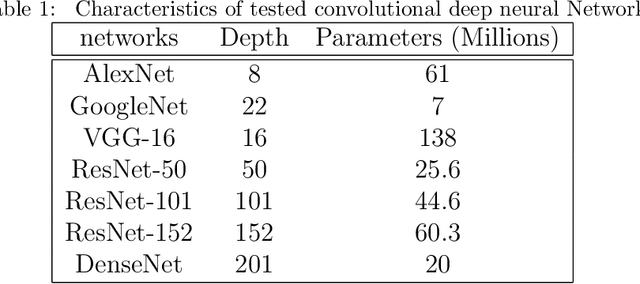
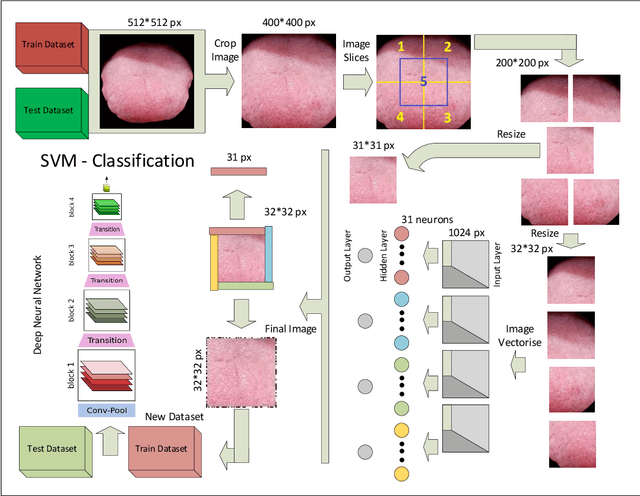
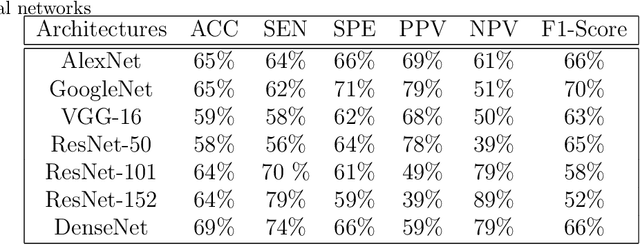
Today, gastric cancer is one of the diseases which affected many people's life. Early detection and accuracy are the main and crucial challenges in finding this kind of cancer. In this paper, a method to increase the accuracy of the diagnosis of detecting cancer using lint and colour features of tongue based on deep convolutional neural networks and support vector machine is proposed. In the proposed method, the region of tongue is first separated from the face image by {deep RCNN} \color{black} Recursive Convolutional Neural Network (R-CNN) \color{black}. After the necessary preprocessing, the images to the convolutional neural network are provided and the training and test operations are triggered. The results show that the proposed method is correctly able to identify the area of the tongue as well as the patient's person from the non-patient. Based on experiments, the DenseNet network has the highest accuracy compared to other deep architectures. The experimental results show that the accuracy of this network for gastric cancer detection reaches 91% which shows the superiority of method in comparison to the state-of-the-art methods.
Asymmetric Similarity Loss Function to Balance Precision and Recall in Highly Unbalanced Deep Medical Image Segmentation
Jun 29, 2018
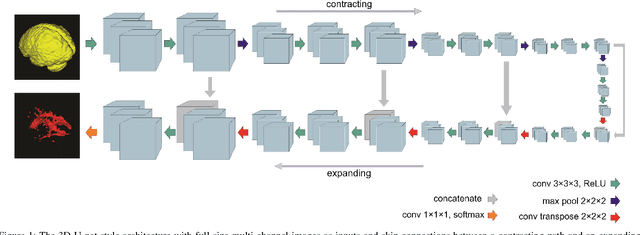
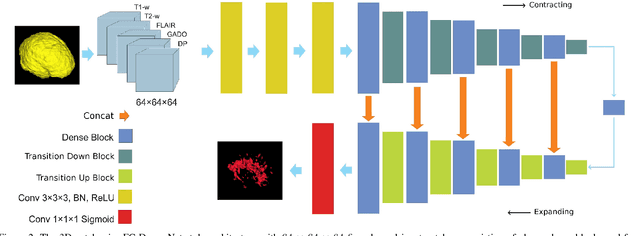

Fully convolutional deep neural networks have been asserted to be fast and precise frameworks with great potential in image segmentation. One of the major challenges in utilizing such networks raises when data is unbalanced, which is common in many medical imaging applications such as lesion segmentation where lesion class voxels are often much lower in numbers than non-lesion voxels. A trained network with unbalanced data may make predictions with high precision and low recall, being severely biased towards the non-lesion class which is particularly undesired in medical applications where false negatives are actually more important than false positives. Various methods have been proposed to address this problem including two step training, sample re-weighting, balanced sampling, and similarity loss functions. In this paper we developed a patch-wise 3D densely connected network with an asymmetric loss function, where we used large overlapping image patches for intrinsic and extrinsic data augmentation, a patch selection algorithm, and a patch prediction fusion strategy based on B-spline weighted soft voting to take into account the uncertainty of prediction in patch borders. We applied this method to lesion segmentation based on the MSSEG 2016 and ISBI 2015 challenges, where we achieved average Dice similarity coefficient of 69.9% and 65.74%, respectively. In addition to the proposed loss, we trained our network with focal and generalized Dice loss functions. Significant improvement in $F_1$ and $F_2$ scores and the APR curve was achieved in test using the asymmetric similarity loss layer and our 3D patch prediction fusion. The asymmetric similarity loss based on $F_\beta$ scores generalizes the Dice similarity coefficient and can be effectively used with the patch-wise strategy developed here to train fully convolutional deep neural networks for highly unbalanced image segmentation.
Self-Guiding Multimodal LSTM - when we do not have a perfect training dataset for image captioning
Sep 15, 2017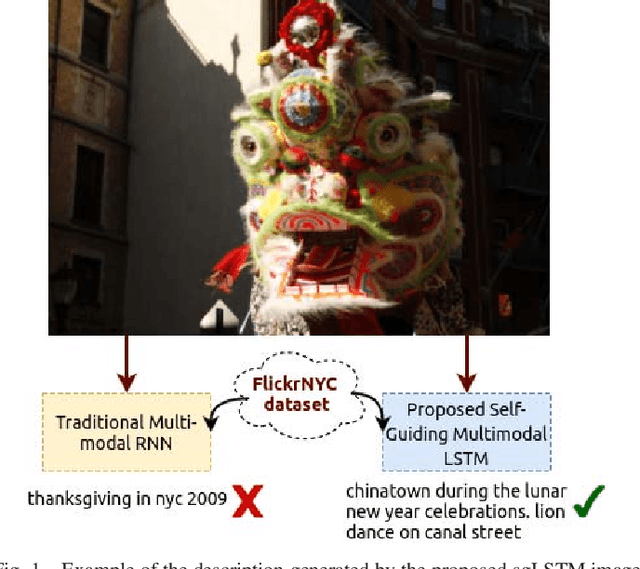

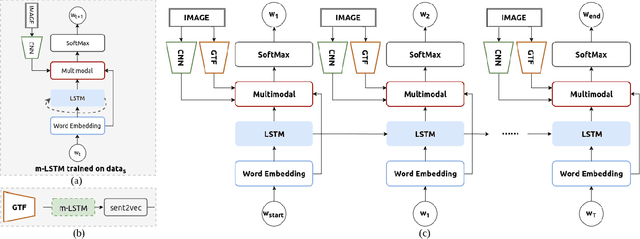

In this paper, a self-guiding multimodal LSTM (sg-LSTM) image captioning model is proposed to handle uncontrolled imbalanced real-world image-sentence dataset. We collect FlickrNYC dataset from Flickr as our testbed with 306,165 images and the original text descriptions uploaded by the users are utilized as the ground truth for training. Descriptions in FlickrNYC dataset vary dramatically ranging from short term-descriptions to long paragraph-descriptions and can describe any visual aspects, or even refer to objects that are not depicted. To deal with the imbalanced and noisy situation and to fully explore the dataset itself, we propose a novel guiding textual feature extracted utilizing a multimodal LSTM (m-LSTM) model. Training of m-LSTM is based on the portion of data in which the image content and the corresponding descriptions are strongly bonded. Afterwards, during the training of sg-LSTM on the rest training data, this guiding information serves as additional input to the network along with the image representations and the ground-truth descriptions. By integrating these input components into a multimodal block, we aim to form a training scheme with the textual information tightly coupled with the image content. The experimental results demonstrate that the proposed sg-LSTM model outperforms the traditional state-of-the-art multimodal RNN captioning framework in successfully describing the key components of the input images.
Reinforcement Based Learning on Classification Task Could Yield Better Generalization and Adversarial Accuracy
Dec 08, 2020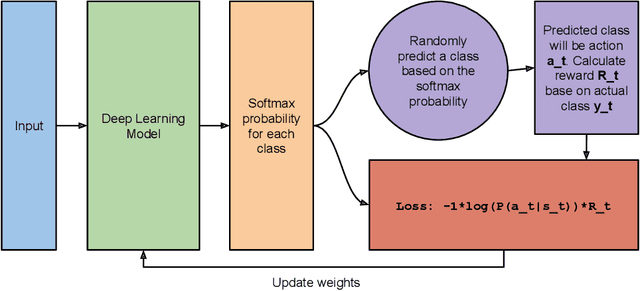
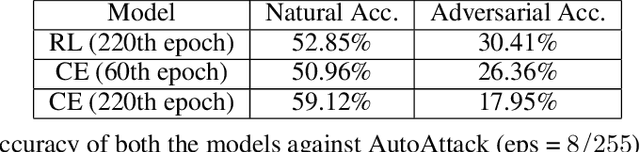
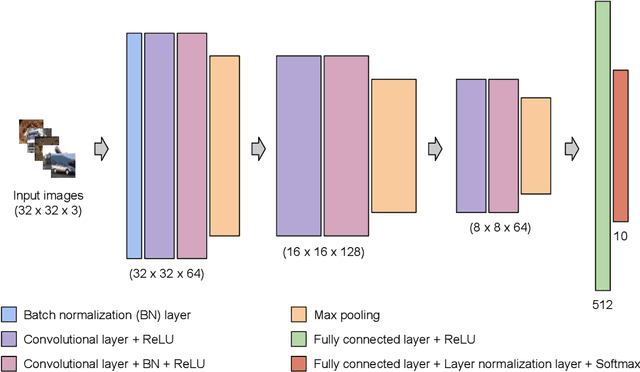
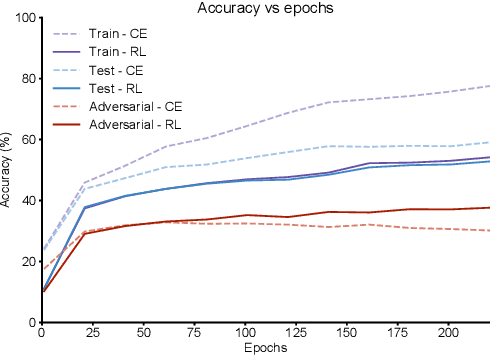
Deep Learning has become interestingly popular in computer vision, mostly attaining near or above human-level performance in various vision tasks. But recent work has also demonstrated that these deep neural networks are very vulnerable to adversarial examples (adversarial examples - inputs to a model which are naturally similar to original data but fools the model in classifying it into a wrong class). Humans are very robust against such perturbations; one possible reason could be that humans do not learn to classify based on an error between "target label" and "predicted label" but possibly due to reinforcements that they receive on their predictions. In this work, we proposed a novel method to train deep learning models on an image classification task. We used a reward-based optimization function, similar to the vanilla policy gradient method used in reinforcement learning, to train our model instead of conventional cross-entropy loss. An empirical evaluation on the cifar10 dataset showed that our method learns a more robust classifier than the same model architecture trained using cross-entropy loss function (on adversarial training). At the same time, our method shows a better generalization with the difference in test accuracy and train accuracy $< 2\%$ for most of the time compared to the cross-entropy one, whose difference most of the time remains $> 2\%$.
Fast and Accurate Light Field Saliency Detection through Feature Extraction
Oct 25, 2020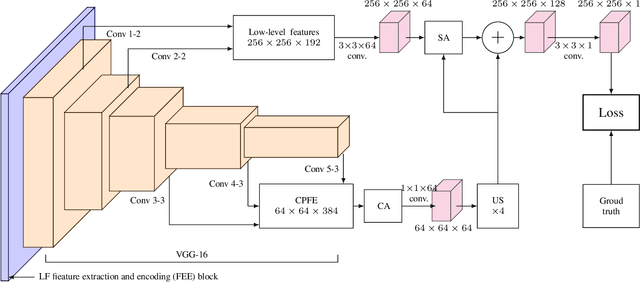
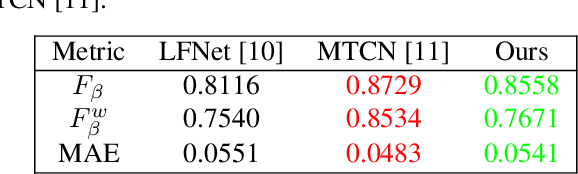

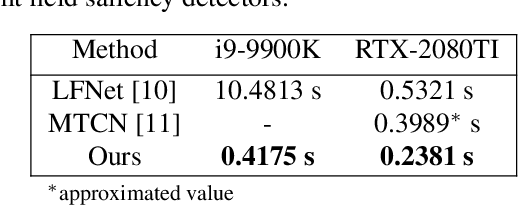
Light field saliency detection---important due to utility in many vision tasks---still lack speed and can improve in accuracy. Due to the formulation of the saliency detection problem in light fields as a segmentation task or a "memorizing" tasks, existing approaches consume unnecessarily large amounts of computational resources for (training and) testing leading to execution times is several seconds. We solve this by aggressively reducing the large light-field images to a much smaller three-channel feature map appropriate for saliency detection using an RGB image saliency detector. We achieve this by introducing a novel convolutional neural network based features extraction and encoding module. Our saliency detector takes $0.4$ s to process a light field of size $9\times9\times512\times375$ in a CPU and is significantly faster than existing systems, with better or comparable accuracy. Our work shows that extracting features from light fields through aggressive size reduction and the attention results in a faster and accurate light-field saliency detector.
Class-agnostic Object Detection
Nov 28, 2020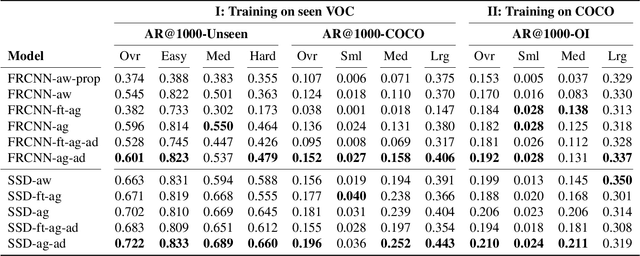
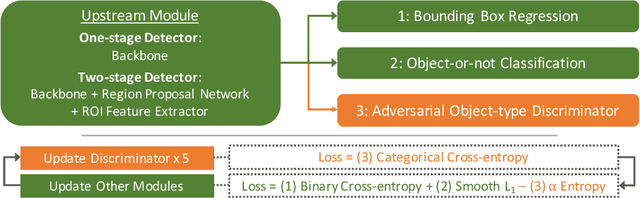
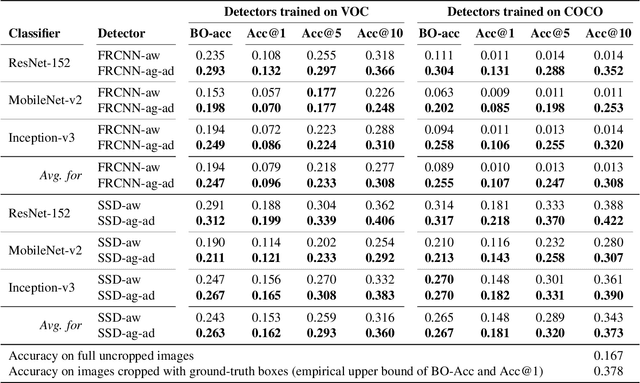
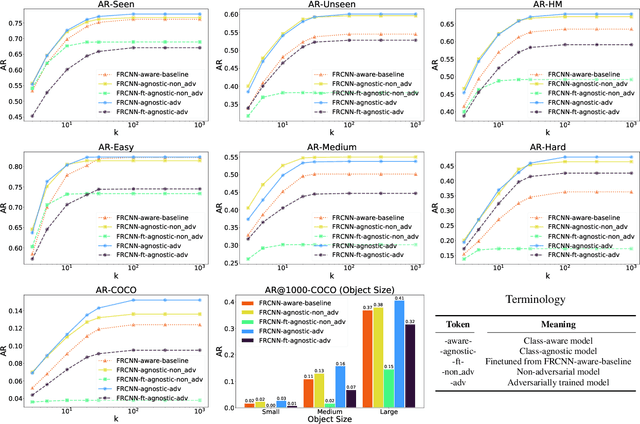
Object detection models perform well at localizing and classifying objects that they are shown during training. However, due to the difficulty and cost associated with creating and annotating detection datasets, trained models detect a limited number of object types with unknown objects treated as background content. This hinders the adoption of conventional detectors in real-world applications like large-scale object matching, visual grounding, visual relation prediction, obstacle detection (where it is more important to determine the presence and location of objects than to find specific types), etc. We propose class-agnostic object detection as a new problem that focuses on detecting objects irrespective of their object-classes. Specifically, the goal is to predict bounding boxes for all objects in an image but not their object-classes. The predicted boxes can then be consumed by another system to perform application-specific classification, retrieval, etc. We propose training and evaluation protocols for benchmarking class-agnostic detectors to advance future research in this domain. Finally, we propose (1) baseline methods and (2) a new adversarial learning framework for class-agnostic detection that forces the model to exclude class-specific information from features used for predictions. Experimental results show that adversarial learning improves class-agnostic detection efficacy.
DeepNAG: Deep Non-Adversarial Gesture Generation
Nov 18, 2020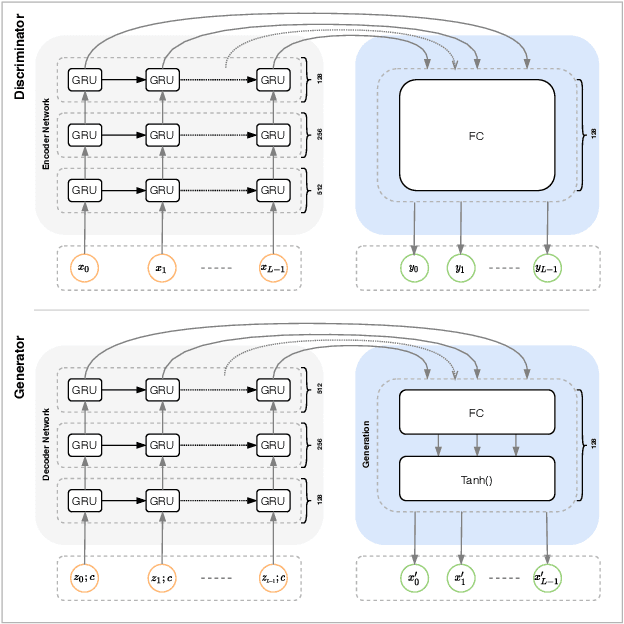
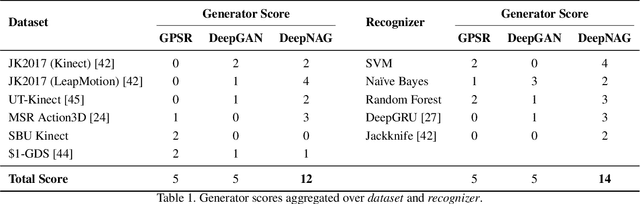
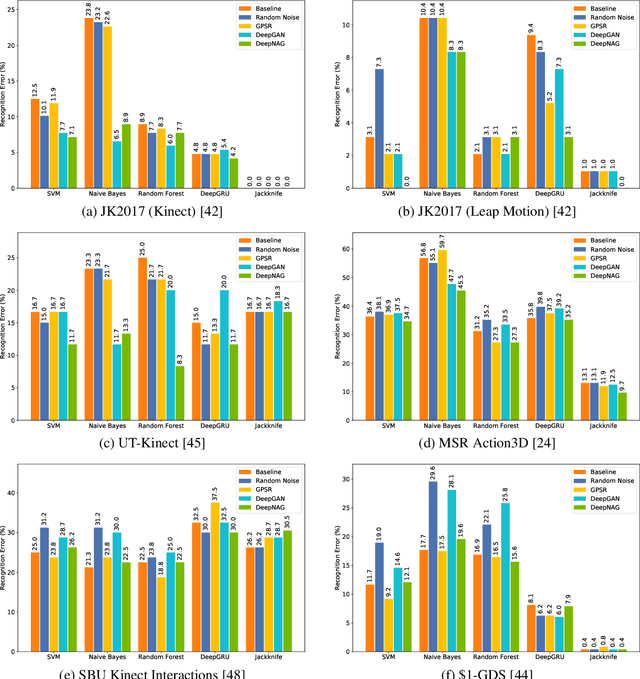

Synthetic data generation to improve classification performance (data augmentation) is a well-studied problem. Recently, generative adversarial networks (GAN) have shown superior image data augmentation performance, but their suitability in gesture synthesis has received inadequate attention. Further, GANs prohibitively require simultaneous generator and discriminator network training. We tackle both issues in this work. We first discuss a novel, device-agnostic GAN model for gesture synthesis called DeepGAN. Thereafter, we formulate DeepNAG by introducing a new differentiable loss function based on dynamic time warping and the average Hausdorff distance, which allows us to train DeepGAN's generator without requiring a discriminator. Through evaluations, we compare the utility of DeepGAN and DeepNAG against two alternative techniques for training five recognizers using data augmentation over six datasets. We further investigate the perceived quality of synthesized samples via an Amazon Mechanical Turk user study based on the HYPE benchmark. We find that DeepNAG outperforms DeepGAN in accuracy, training time (up to 17x faster), and realism, thereby opening the door to a new line of research in generator network design and training for gesture synthesis. Our source code is available at https://www.deepnag.com.
Estimation, Confidence Intervals, and Large-Scale Hypotheses Testing for High-Dimensional Mixed Linear Regression
Nov 06, 2020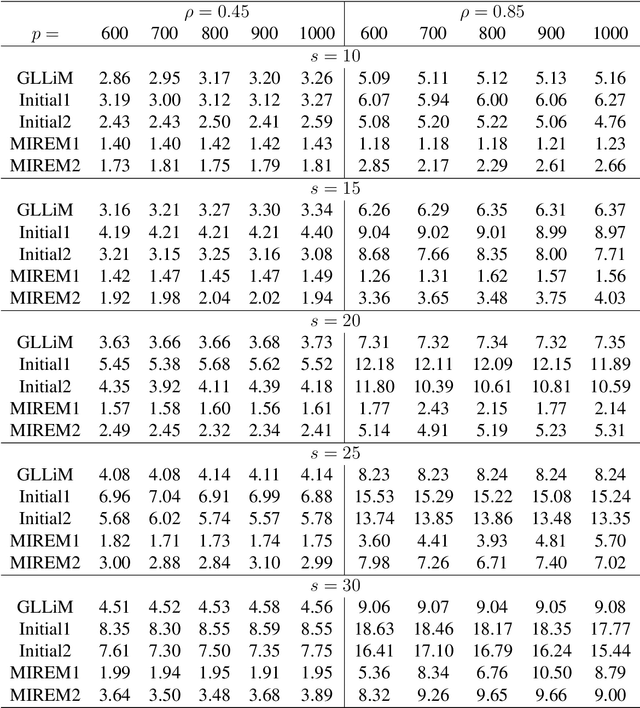
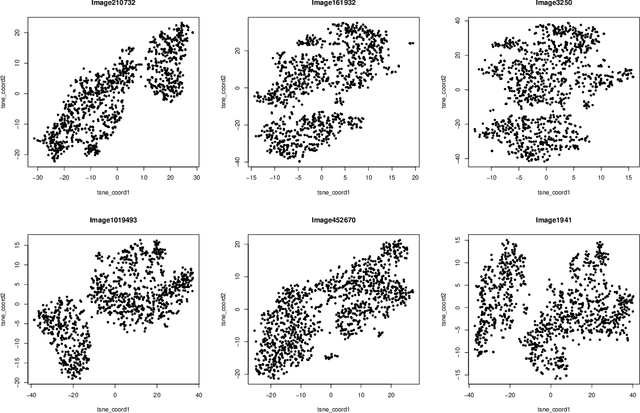
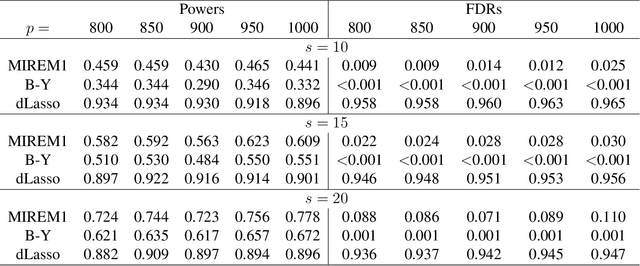
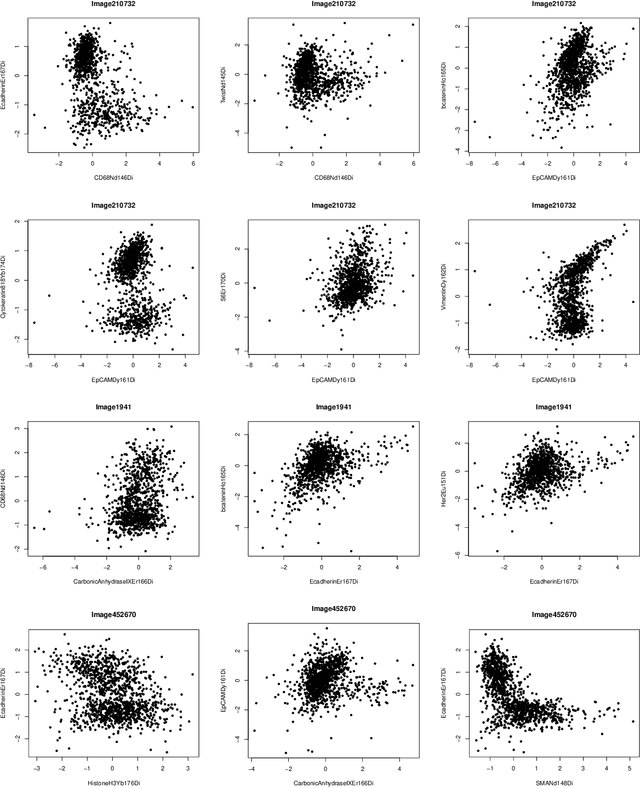
This paper studies the high-dimensional mixed linear regression (MLR) where the output variable comes from one of the two linear regression models with an unknown mixing proportion and an unknown covariance structure of the random covariates. Building upon a high-dimensional EM algorithm, we propose an iterative procedure for estimating the two regression vectors and establish their rates of convergence. Based on the iterative estimators, we further construct debiased estimators and establish their asymptotic normality. For individual coordinates, confidence intervals centered at the debiased estimators are constructed. Furthermore, a large-scale multiple testing procedure is proposed for testing the regression coefficients and is shown to control the false discovery rate (FDR) asymptotically. Simulation studies are carried out to examine the numerical performance of the proposed methods and their superiority over existing methods. The proposed methods are further illustrated through an analysis of a dataset of multiplex image cytometry, which investigates the interaction networks among the cellular phenotypes that include the expression levels of 20 epitopes or combinations of markers.
Date-Field Retrieval in Scene Image and Video Frames using Text Enhancement and Shape Coding
Jul 21, 2017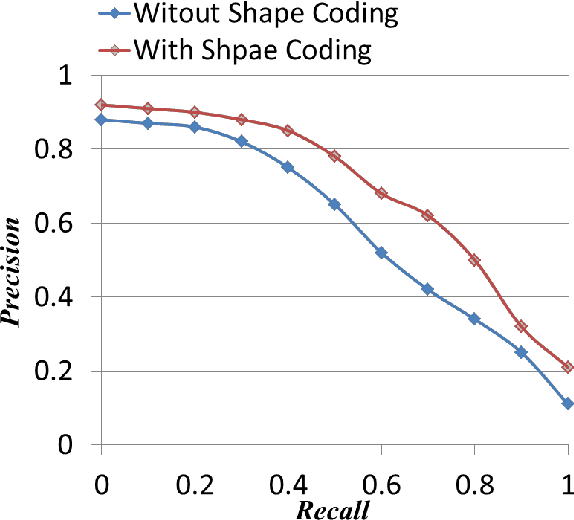

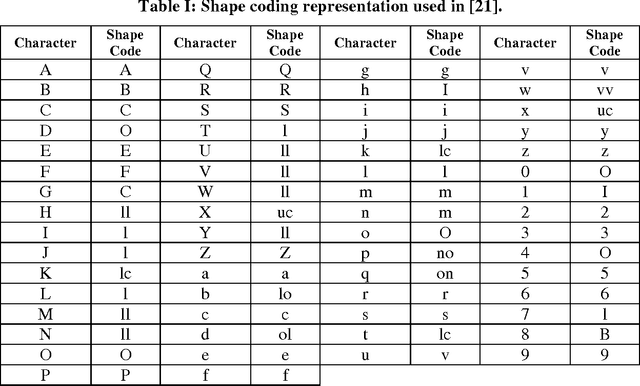

Text recognition in scene image and video frames is difficult because of low resolution, blur, background noise, etc. Since traditional OCRs do not perform well in such images, information retrieval using keywords could be an alternative way to index/retrieve such text information. Date is a useful piece of information which has various applications including date-wise videos/scene searching, indexing or retrieval. This paper presents a date spotting based information retrieval system for natural scene image and video frames where text appears with complex backgrounds. We propose a line based date spotting approach using Hidden Markov Model (HMM) which is used to detect the date information in a given text. Different date models are searched from a line without segmenting characters or words. Given a text line image in RGB, we apply an efficient gray image conversion to enhance the text information. Wavelet decomposition and gradient sub-bands are used to enhance text information in gray scale. Next, Pyramid Histogram of Oriented Gradient (PHOG) feature has been extracted from gray image and binary images for date-spotting framework. Binary and gray image features are combined by MLP based Tandem approach. Finally, to boost the performance further, a shape coding based scheme is used to combine the similar shape characters in same class during word spotting. For our experiment, three different date models have been constructed to search similar date information having numeric dates that contains numeral values and punctuations and semi-numeric that contains dates with numerals along with months in scene/video text. We have tested our system on 1648 text lines and the results show the effectiveness of our proposed date spotting approach.