 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Interleaved Text/Image Deep Mining on a Large-Scale Radiology Database for Automated Image Interpretation
May 04, 2015

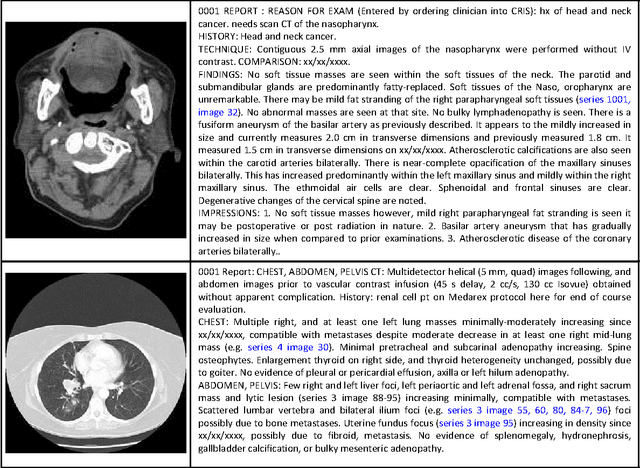
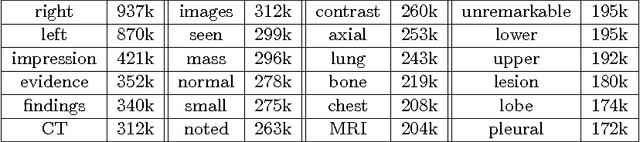
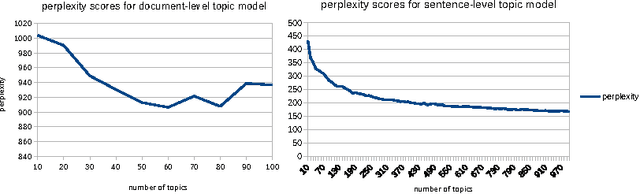
Despite tremendous progress in computer vision, there has not been an attempt for machine learning on very large-scale medical image databases. We present an interleaved text/image deep learning system to extract and mine the semantic interactions of radiology images and reports from a national research hospital's Picture Archiving and Communication System. With natural language processing, we mine a collection of representative ~216K two-dimensional key images selected by clinicians for diagnostic reference, and match the images with their descriptions in an automated manner. Our system interleaves between unsupervised learning and supervised learning on document- and sentence-level text collections, to generate semantic labels and to predict them given an image. Given an image of a patient scan, semantic topics in radiology levels are predicted, and associated key-words are generated. Also, a number of frequent disease types are detected as present or absent, to provide more specific interpretation of a patient scan. This shows the potential of large-scale learning and prediction in electronic patient records available in most modern clinical institutions.
Cross Domain Image Generation through Latent Space Exploration with Adversarial Loss
May 24, 2018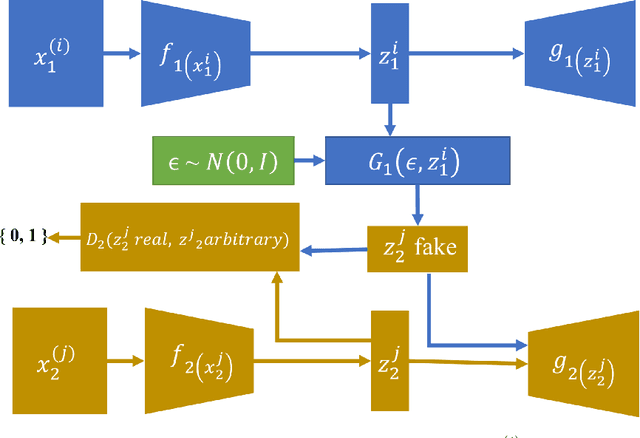
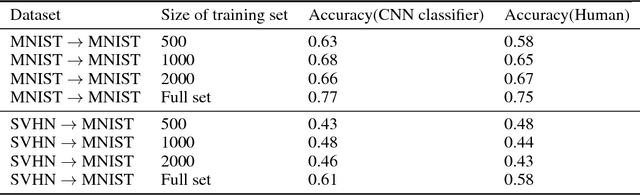
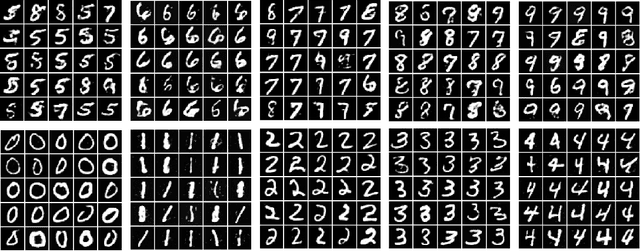

Conditional domain generation is a good way to interactively control sample generation process of deep generative models. However, once a conditional generative model has been created, it is often expensive to allow it to adapt to new conditional controls, especially the network structure is relatively deep. We propose a conditioned latent domain transfer framework across latent spaces of unconditional variational autoencoders(VAE). With this framework, we can allow unconditionally trained VAEs to generate images in its domain with conditionals provided by a latent representation of another domain. This framework does not assume commonalities between two domains. We demonstrate effectiveness and robustness of our model under widely used image datasets.
Dropout during inference as a model for neurological degeneration in an image captioning network
Aug 11, 2018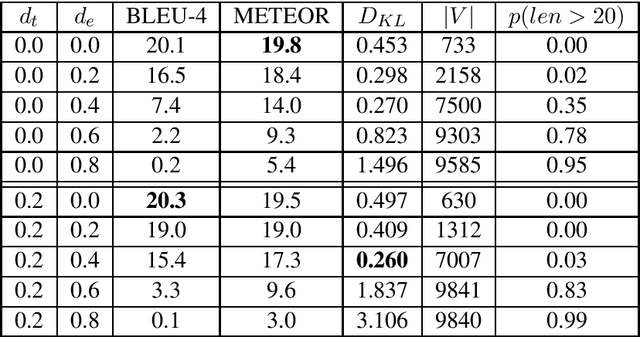
We replicate a variation of the image captioning architecture by Vinyals et al. (2015), then introduce dropout during inference mode to simulate the effects of neurodegenerative diseases like Alzheimer's disease (AD) and Wernicke's aphasia (WA). We evaluate the effects of dropout on language production by measuring the KL-divergence of word frequency distributions and other linguistic metrics as dropout is added. We find that the generated sentences most closely approximate the word frequency distribution of the training corpus when using a moderate dropout of 0.4 during inference.
CIDEr: Consensus-based Image Description Evaluation
Jun 03, 2015
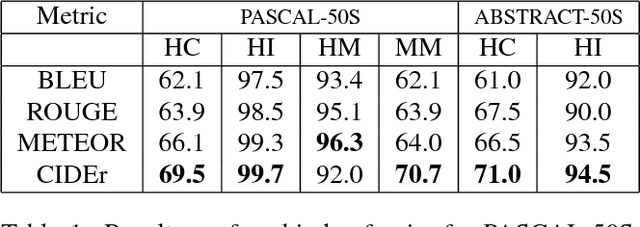

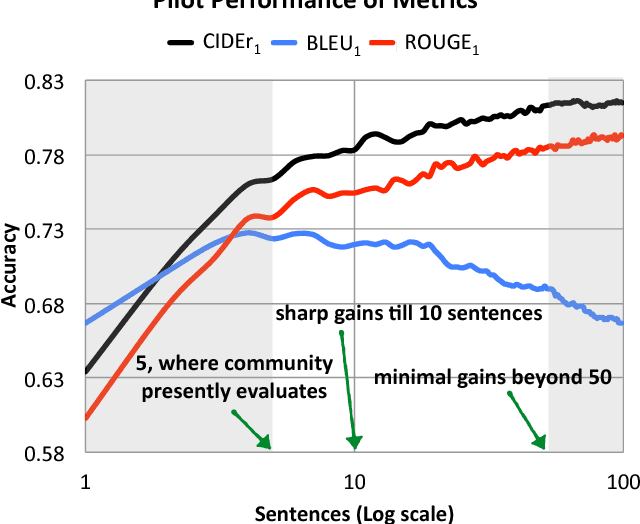
Automatically describing an image with a sentence is a long-standing challenge in computer vision and natural language processing. Due to recent progress in object detection, attribute classification, action recognition, etc., there is renewed interest in this area. However, evaluating the quality of descriptions has proven to be challenging. We propose a novel paradigm for evaluating image descriptions that uses human consensus. This paradigm consists of three main parts: a new triplet-based method of collecting human annotations to measure consensus, a new automated metric (CIDEr) that captures consensus, and two new datasets: PASCAL-50S and ABSTRACT-50S that contain 50 sentences describing each image. Our simple metric captures human judgment of consensus better than existing metrics across sentences generated by various sources. We also evaluate five state-of-the-art image description approaches using this new protocol and provide a benchmark for future comparisons. A version of CIDEr named CIDEr-D is available as a part of MS COCO evaluation server to enable systematic evaluation and benchmarking.
Pose-Normalized Image Generation for Person Re-identification
Apr 25, 2018
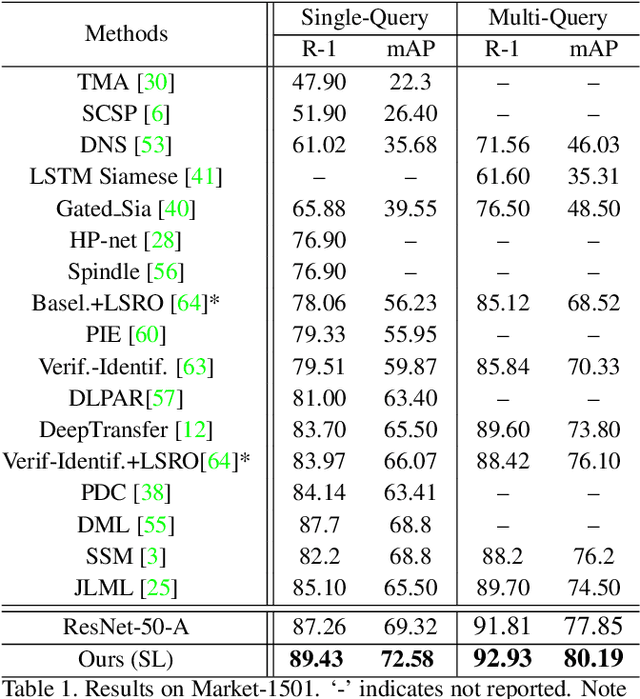
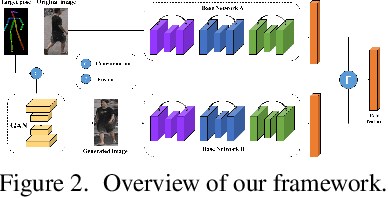
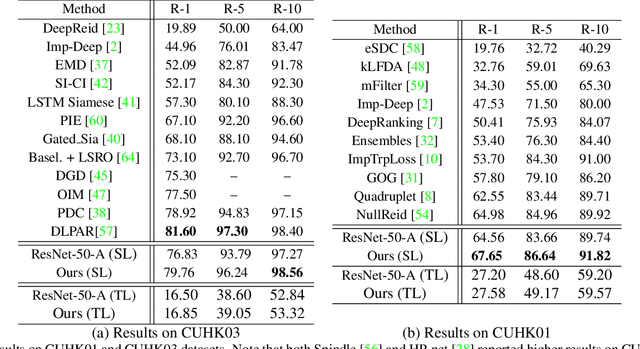
Person Re-identification (re-id) faces two major challenges: the lack of cross-view paired training data and learning discriminative identity-sensitive and view-invariant features in the presence of large pose variations. In this work, we address both problems by proposing a novel deep person image generation model for synthesizing realistic person images conditional on the pose. The model is based on a generative adversarial network (GAN) designed specifically for pose normalization in re-id, thus termed pose-normalization GAN (PN-GAN). With the synthesized images, we can learn a new type of deep re-id feature free of the influence of pose variations. We show that this feature is strong on its own and complementary to features learned with the original images. Importantly, under the transfer learning setting, we show that our model generalizes well to any new re-id dataset without the need for collecting any training data for model fine-tuning. The model thus has the potential to make re-id model truly scalable.
Fast, Accurate and Fully Parallelizable Digital Image Correlation
Oct 12, 2017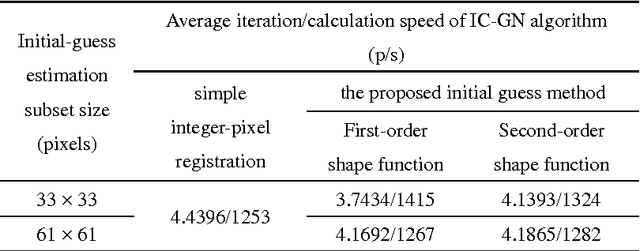

Digital image correlation (DIC) is a widely used optical metrology for surface deformation measurements. DIC relies on nonlinear optimization method. Thus an initial guess is quite important due to its influence on the converge characteristics of the algorithm. In order to obtain a reliable, accurate initial guess, a reliability-guided digital image correlation (RG-DIC) method, which is able to intelligently obtain a reliable initial guess without using time-consuming integer-pixel registration, was proposed. However, the RG-DIC and its improved methods are path-dependent and cannot be fully parallelized. Besides, it is highly possible that RG-DIC fails in the full-field analysis of deformation without manual intervention if the deformation fields contain large areas of discontinuous deformation. Feature-based initial guess is highly robust while it is relatively time-consuming. Recently, path-independent algorithm, fast Fourier transform-based cross correlation (FFT-CC) algorithm, was proposed to estimate the initial guess. Complete parallelizability is the major advantage of the FFT-CC algorithm, while it is sensitive to small deformation. Wu et al proposed an efficient integer-pixel search scheme, but the parameters of this algorithm are set by the users empirically. In this technical note, a fully parallelizable DIC method is proposed. Different from RG-DIC method, the proposed method divides DIC algorithm into two parts: full-field initial guess estimation and sub-pixel registration. The proposed method has the following benefits: 1) providing a pre-knowledge of deformation fields; 2) saving computational time; 3) reducing error propagation; 4) integratability with well-established DIC algorithms; 5) fully parallelizability.
FPCC-Net: Fast Point Cloud Clustering for Instance Segmentation
Dec 29, 2020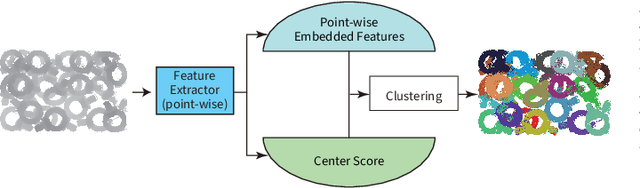

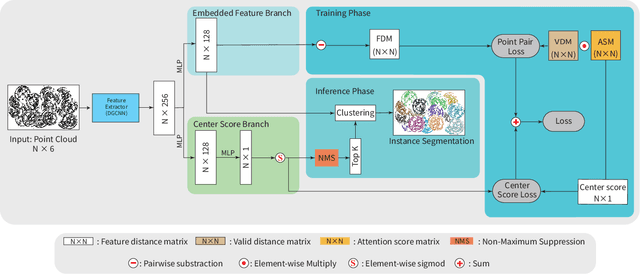
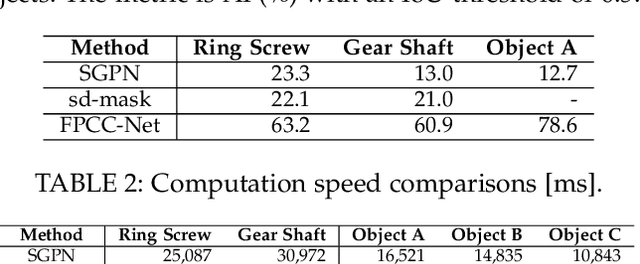
Instance segmentation is an important pre-processing task in numerous real-world applications, such as robotics, autonomous vehicles, and human-computer interaction. However, there has been little research on 3D point cloud instance segmentation of bin-picking scenes in which multiple objects of the same class are stacked together. Compared with the rapid development of deep learning for two-dimensional (2D) image tasks, deep learning-based 3D point cloud segmentation still has a lot of room for development. In such a situation, distinguishing a large number of occluded objects of the same class is a highly challenging problem. In a usual bin-picking scene, an object model is known and the number of object type is one. Thus, the semantic information can be ignored; instead, the focus is put on the segmentation of instances. Based on this task requirement, we propose a network (FPCC-Net) that infers feature centers of each instance and then clusters the remaining points to the closest feature center in feature embedding space. FPCC-Net includes two subnets, one for inferring the feature centers for clustering and the other for describing features of each point. The proposed method is compared with existing 3D point clouds and 2D segmentation methods in some bin-picking scenes. It is shown that FPCC-Net outperforms SGPN by about 40\% average precision (AP) and can process about 60,000 points in about 0.8[s]
An Efficient and Scalable Deep Learning Approach for Road Damage Detection
Nov 18, 2020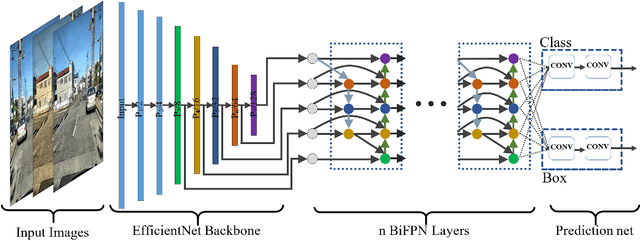

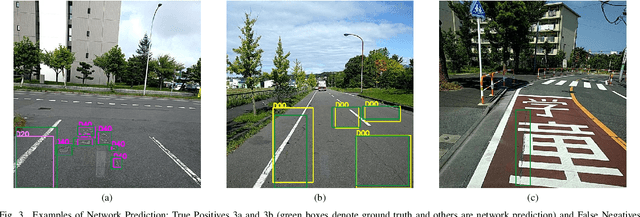

Pavement condition evaluation is essential to time the preventative or rehabilitative actions and control distress propagation. Failing to conduct timely evaluations can lead to severe structural and financial loss of the infrastructure and complete reconstructions. Automated computer-aided surveying measures can provide a database of road damage patterns and their locations. This database can be utilized for timely road repairs to gain the minimum cost of maintenance and the asphalt's maximum durability. This paper introduces a deep learning-based surveying scheme to analyze the image-based distress data in real-time. A database consisting of a diverse population of crack distress types such as longitudinal, transverse, and alligator cracks, photographed using mobile-device is used. Then, a family of efficient and scalable models that are tuned for pavement crack detection is trained. Proposed models, resulted in F1-scores, ranging from 52% to 56%, and average inference time from 178-10 images per second. Finally, the performance of the object detectors are examined, and error analysis is reported against various images. The source code is available at https://github.com/mahdi65/roadDamageDetection2020.
Stylized Adversarial Defense
Jul 29, 2020
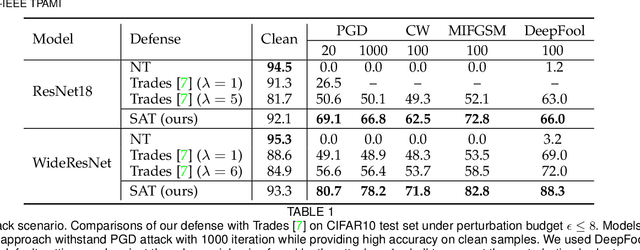
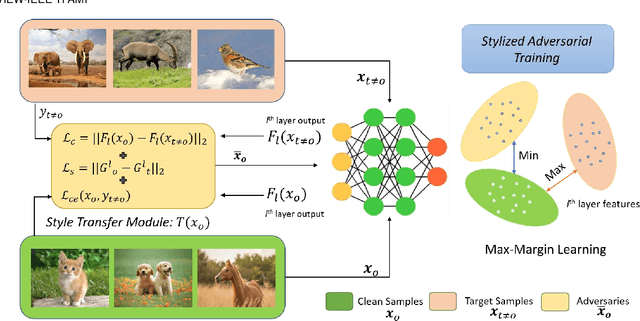
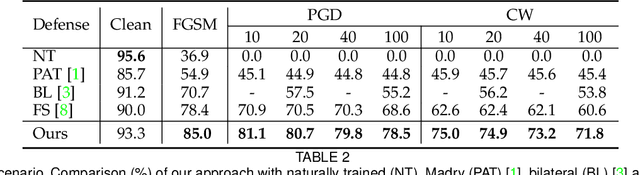
Deep Convolution Neural Networks (CNNs) can easily be fooled by subtle, imperceptible changes to the input images. To address this vulnerability, adversarial training creates perturbation patterns and includes them in the training set to robustify the model. In contrast to existing adversarial training methods that only use class-boundary information (e.g., using a cross entropy loss), we propose to exploit additional information from the feature space to craft stronger adversaries that are in turn used to learn a robust model. Specifically, we use the style and content information of the target sample from another class, alongside its class boundary information to create adversarial perturbations. We apply our proposed multi-task objective in a deeply supervised manner, extracting multi-scale feature knowledge to create maximally separating adversaries. Subsequently, we propose a max-margin adversarial training approach that minimizes the distance between source image and its adversary and maximizes the distance between the adversary and the target image. Our adversarial training approach demonstrates strong robustness compared to state of the art defenses, generalizes well to naturally occurring corruptions and data distributional shifts, and retains the model accuracy on clean examples.
Anchor-Based Spatial-Temporal Attention Convolutional Networks for Dynamic 3D Point Cloud Sequences
Dec 20, 2020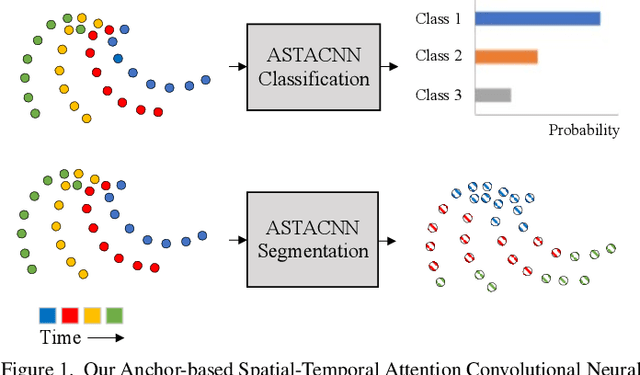
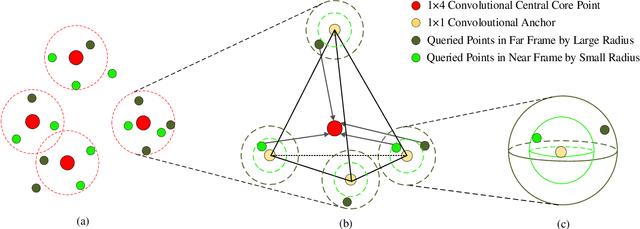
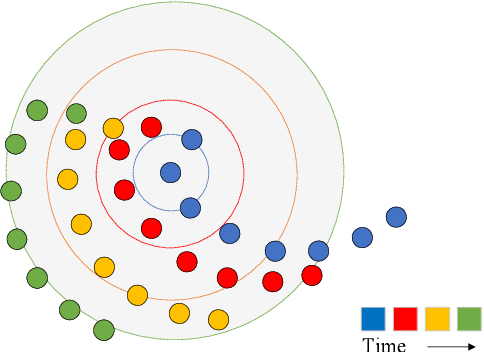
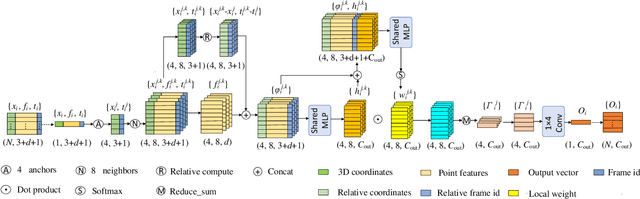
Recently, learning based methods for the robot perception from the image or video have much developed, but deep learning methods for dynamic 3D point cloud sequences are underexplored. With the widespread application of 3D sensors such as LiDAR and depth camera, efficient and accurate perception of the 3D environment from 3D sequence data is pivotal to autonomous driving and service robots. An Anchor-based Spatial-Temporal Attention Convolution operation (ASTAConv) is proposed in this paper to process dynamic 3D point cloud sequences. The proposed convolution operation builds a regular receptive field around each point by setting several virtual anchors around each point. The features of neighborhood points are firstly aggregated to each anchor based on spatial-temporal attention mechanism. Then, anchor-based sparse 3D convolution is adopted to aggregate the features of these anchors to the core points. The proposed method makes better use of the structured information within the local region, and learn spatial-temporal embedding features from dynamic 3D point cloud sequences. Then Anchor-based Spatial-Temporal Attention Convolutional Neural Networks (ASTACNNs) are proposed for classification and segmentation tasks and are evaluated on action recognition and semantic segmentation tasks. The experimental results on MSRAction3D and Synthia datasets demonstrate that the higher accuracy can be achieved than the previous state-of-the-art method by our novel strategy of multi-frame fusion.