 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Large Margin Image Set Representation and Classification
Apr 22, 2014
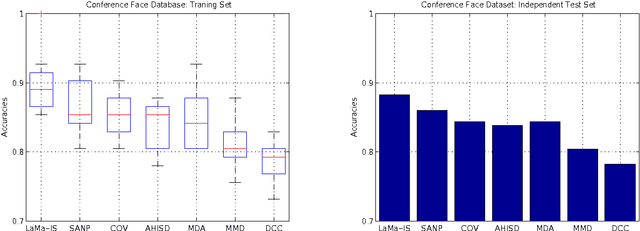
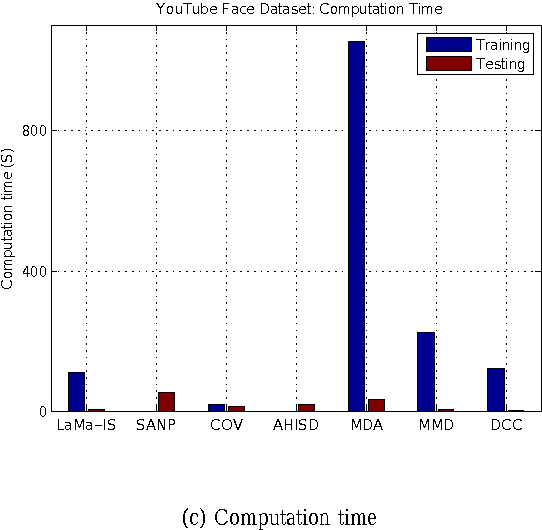
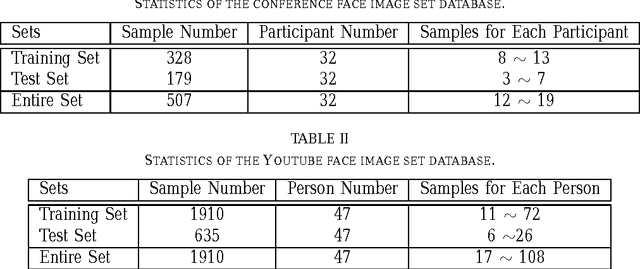
In this paper, we propose a novel image set representation and classification method by maximizing the margin of image sets. The margin of an image set is defined as the difference of the distance to its nearest image set from different classes and the distance to its nearest image set of the same class. By modeling the image sets by using both their image samples and their affine hull models, and maximizing the margins of the images sets, the image set representation parameter learning problem is formulated as an minimization problem, which is further optimized by an expectation -maximization (EM) strategy with accelerated proximal gradient (APG) optimization in an iterative algorithm. To classify a given test image set, we assign it to the class which could provide the largest margin. Experiments on two applications of video-sequence-based face recognition demonstrate that the proposed method significantly outperforms state-of-the-art image set classification methods in terms of both effectiveness and efficiency.
PRVNet: Variational Autoencoders for Massive MIMO CSI Feedback
Nov 09, 2020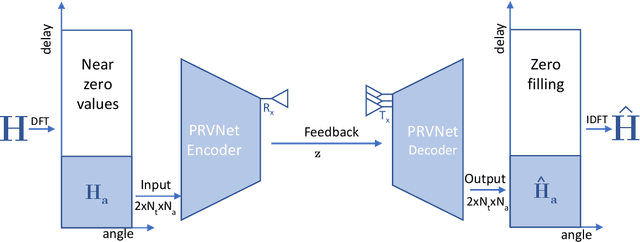
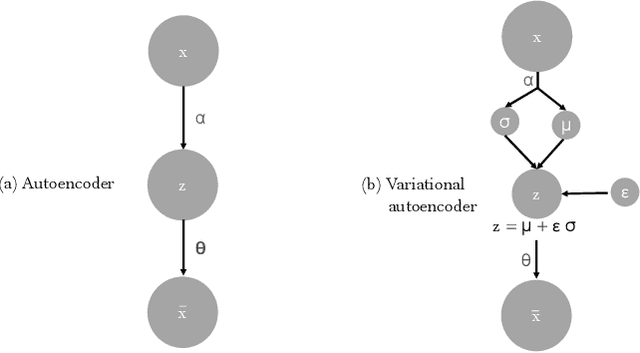
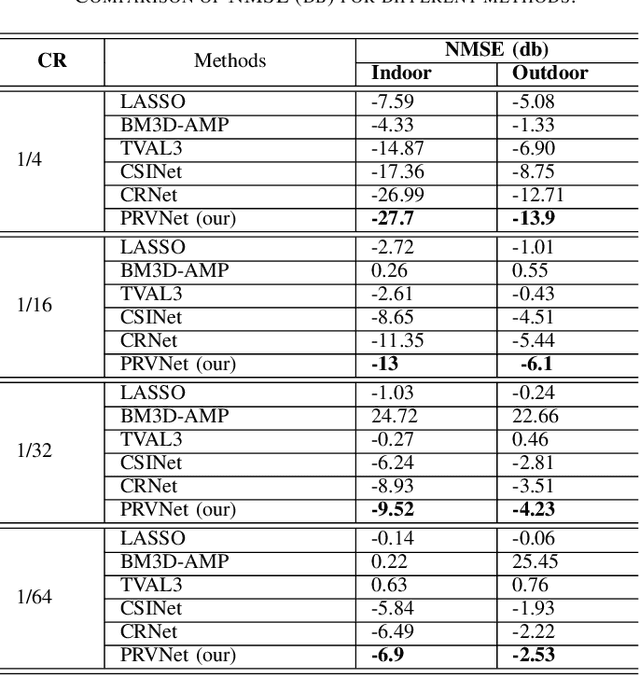

In a frequency division duplexing multiple-input multiple-output (FDD-MIMO) system, the user equipment (UE) send the downlink channel state information (CSI) to the base station for performance improvement. However, with the growing complexity of MIMO systems, this feedback becomes expensive and has a negative impact on the bandwidth. Although this problem has been largely studied in the literature, the noisy nature of the feedback channel is less considered. In this paper, we introduce PRVNet, a neural architecture based on variational autoencoders (VAE). VAE gained large attention in many fields (e.g., image processing, language models, or recommendation system). However, it received less attention in the communication domain generally and in CSI feedback problem specifically. We also introduce a different regularization parameter for the learning objective, which proved to be crucial for achieving competitive performance. In addition, we provide an efficient way to tune this parameter using KL-annealing. Empirically, we show that the proposed model significantly outperforms state-of-the-art, including two neural network approaches. The proposed model is also proved to be more robust against different levels of noise.
Crowdsourcing Airway Annotations in Chest Computed Tomography Images
Nov 20, 2020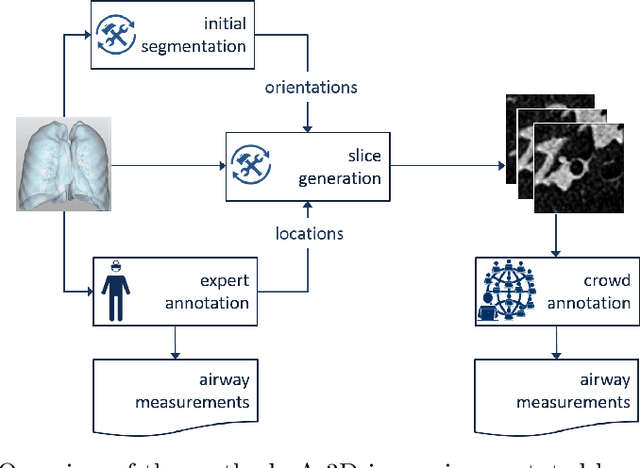
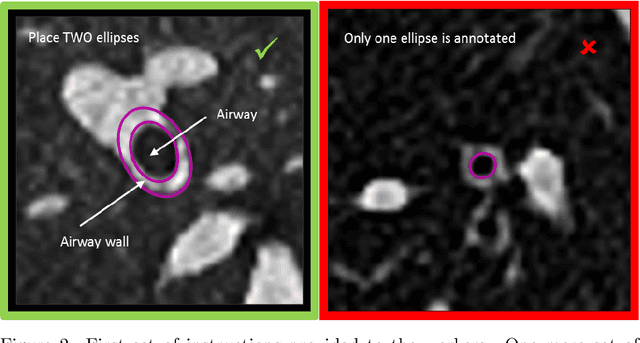
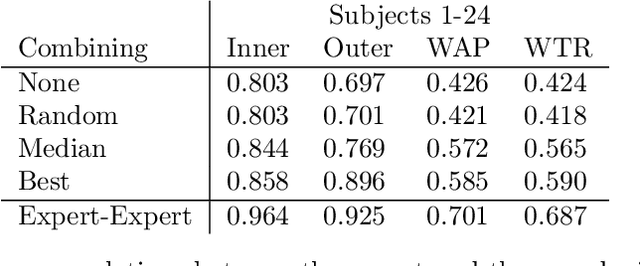

Measuring airways in chest computed tomography (CT) scans is important for characterizing diseases such as cystic fibrosis, yet very time-consuming to perform manually. Machine learning algorithms offer an alternative, but need large sets of annotated scans for good performance. We investigate whether crowdsourcing can be used to gather airway annotations. We generate image slices at known locations of airways in 24 subjects and request the crowd workers to outline the airway lumen and airway wall. After combining multiple crowd workers, we compare the measurements to those made by the experts in the original scans. Similar to our preliminary study, a large portion of the annotations were excluded, possibly due to workers misunderstanding the instructions. After excluding such annotations, moderate to strong correlations with the expert can be observed, although these correlations are slightly lower than inter-expert correlations. Furthermore, the results across subjects in this study are quite variable. Although the crowd has potential in annotating airways, further development is needed for it to be robust enough for gathering annotations in practice. For reproducibility, data and code are available online: \url{http://github.com/adriapr/crowdairway.git}.
Compressing Images by Encoding Their Latent Representations with Relative Entropy Coding
Oct 27, 2020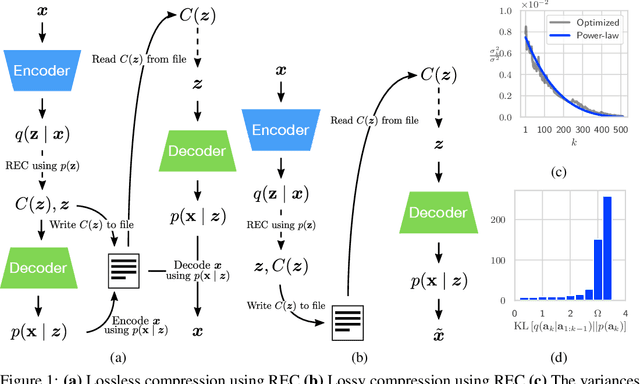
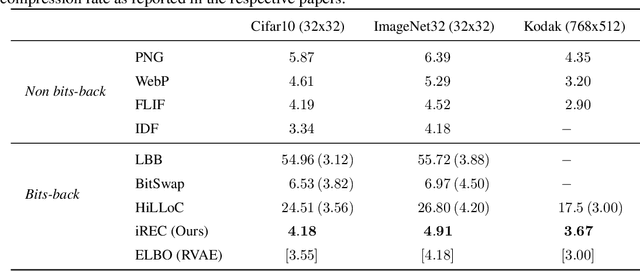
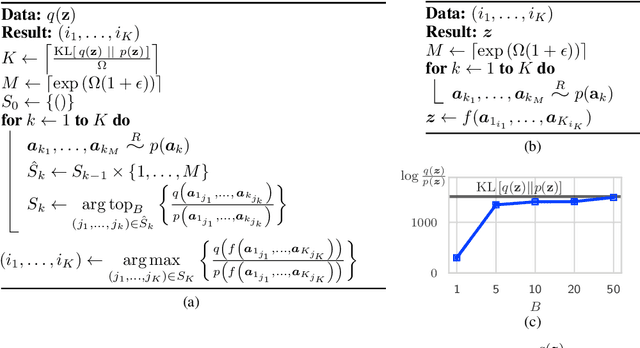
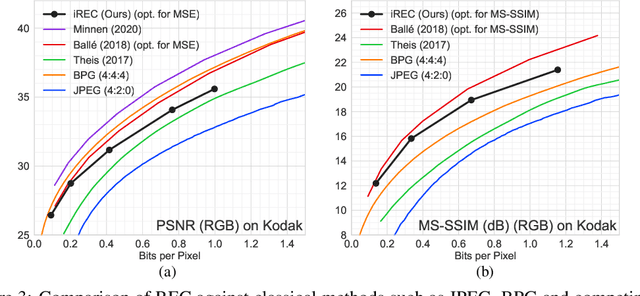
Variational Autoencoders (VAEs) have seen widespread use in learned image compression. They are used to learn expressive latent representations on which downstream compression methods can operate with high efficiency. Recently proposed 'bits-back' methods can indirectly encode the latent representation of images with codelength close to the relative entropy between the latent posterior and the prior. However, due to the underlying algorithm, these methods can only be used for lossless compression, and they only achieve their nominal efficiency when compressing multiple images simultaneously; they are inefficient for compressing single images. As an alternative, we propose a novel method, Relative Entropy Coding (REC), that can directly encode the latent representation with codelength close to the relative entropy for single images, supported by our empirical results obtained on the Cifar10, ImageNet32 and Kodak datasets. Moreover, unlike previous bits-back methods, REC is immediately applicable to lossy compression, where it is competitive with the state-of-the-art on the Kodak dataset.
Does V-NIR based Image Enhancement Come with Better Features?
Aug 24, 2016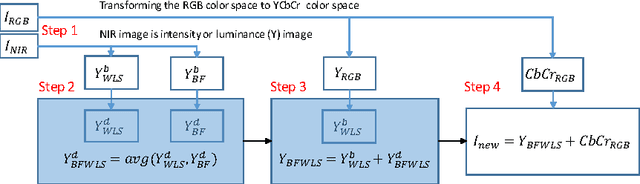


Image enhancement using the visible (V) and near-infrared (NIR) usually enhances useful image details. The enhanced images are evaluated by observers perception, instead of quantitative feature evaluation. Thus, can we say that these enhanced images using NIR information has better features in comparison to the computed features in the Red, Green, and Blue color channels directly? In this work, we present a new method to enhance the visible images using NIR information via edge-preserving filters, and also investigate which method performs best from a image features standpoint. We then show that our proposed enhancement method produces more stable features than the existing state-of-the-art methods.
OneNet: Towards End-to-End One-Stage Object Detection
Dec 10, 2020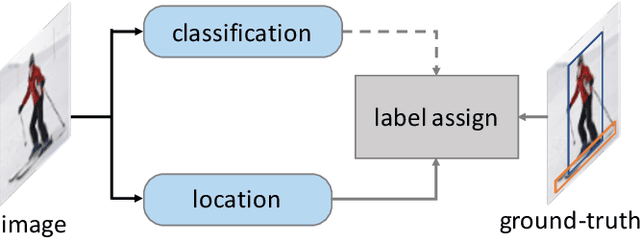

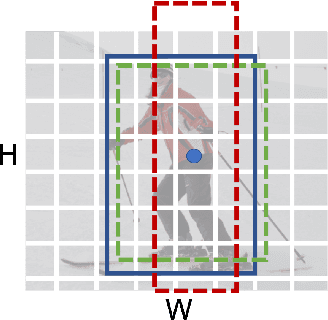

End-to-end one-stage object detection trailed thus far. This paper discovers that the lack of classification cost between sample and ground-truth in label assignment is the main obstacle for one-stage detectors to remove Non-maximum Suppression(NMS) and reach end-to-end. Existing one-stage object detectors assign labels by only location cost, e.g. box IoU or point distance. Without classification cost, sole location cost leads to redundant boxes of high confidence scores in inference, making NMS necessary post-processing. To design an end-to-end one-stage object detector, we propose Minimum Cost Assignment. The cost is the summation of classification cost and location cost between sample and ground-truth. For each object ground-truth, only one sample of minimum cost is assigned as the positive sample; others are all negative samples. To evaluate the effectiveness of our method, we design an extremely simple one-stage detector named OneNet. Our results show that when trained with Minimum Cost Assignment, OneNet avoids producing duplicated boxes and achieves to end-to-end detector. On COCO dataset, OneNet achieves 35.0 AP/80 FPS and 37.7 AP/50 FPS with image size of 512 pixels. We hope OneNet could serve as an effective baseline for end-to-end one-stage object detection. The code is available at: \url{https://github.com/PeizeSun/OneNet}.
Born Identity Network: Multi-way Counterfactual Map Generation to Explain a Classifier's Decision
Nov 20, 2020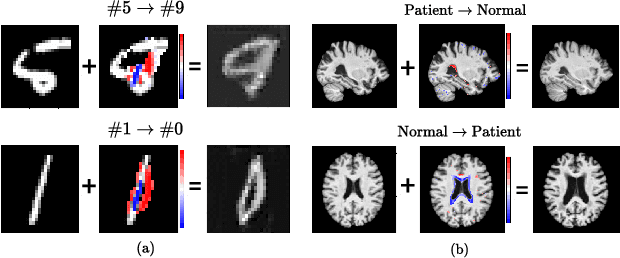
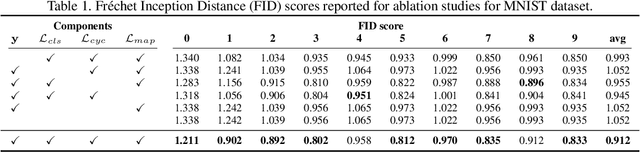
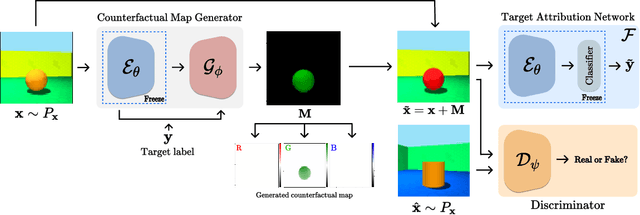
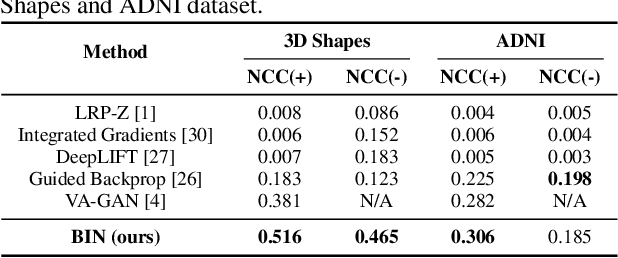
There exists an apparent negative correlation between performance and interpretability of deep learning models. In an effort to reduce this negative correlation, we propose Born Identity Network (BIN), which is a post-hoc approach for producing multi-way counterfactual maps. A counterfactual map transforms an input sample to be classified as a target label, which is similar to how humans process knowledge through counterfactual thinking. Thus, producing a better counterfactual map may be a step towards explanation at the level of human knowledge. For example, a counterfactual map can localize hypothetical abnormalities from a normal brain image that may cause it to be diagnosed with a disease. Specifically, our proposed BIN consists of two core components: Counterfactual Map Generator and Target Attribution Network. The Counterfactual Map Generator is a variation of conditional GAN which can synthesize a counterfactual map conditioned on an arbitrary target label. The Target Attribution Network works in a complementary manner to enforce target label attribution to the synthesized map. We have validated our proposed BIN in qualitative, quantitative analysis on MNIST, 3D Shapes, and ADNI datasets, and show the comprehensibility and fidelity of our method from various ablation studies.
Can Image Enhancement be Beneficial to Find Smoke Images in Laparoscopic Surgery?
Dec 27, 2018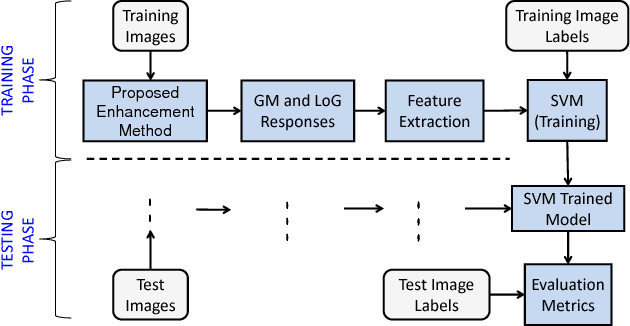
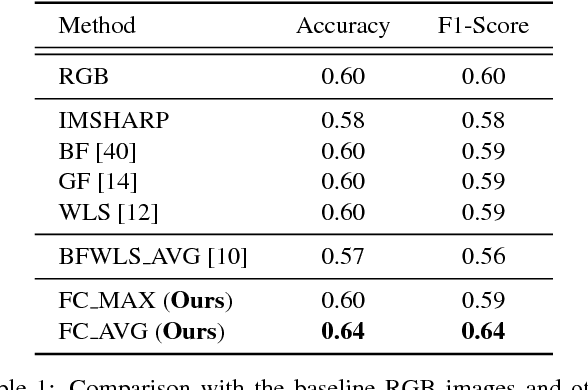
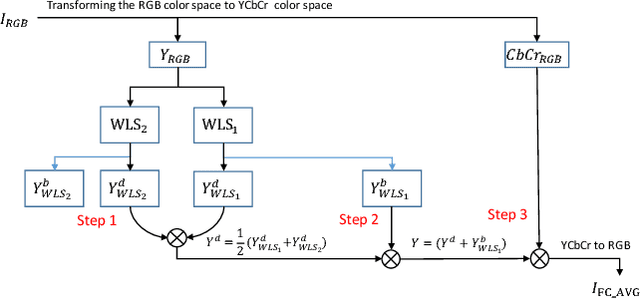

Laparoscopic surgery has a limited field of view. Laser ablation in a laproscopic surgery causes smoke, which inevitably influences the surgeon's visibility. Therefore, it is of vital importance to remove the smoke, such that a clear visualization is possible. In order to employ a desmoking technique, one needs to know beforehand if the image contains smoke or not, to this date, there exists no accurate method that could classify the smoke/non-smoke images completely. In this work, we propose a new enhancement method which enhances the informative details in the RGB images for discrimination of smoke/non-smoke images. Our proposed method utilizes weighted least squares optimization framework~(WLS). For feature extraction, we use statistical features based on bivariate histogram distribution of gradient magnitude~(GM) and Laplacian of Gaussian~(LoG). We then train a SVM classifier with binary smoke/non-smoke classification task. We demonstrate the effectiveness of our method on Cholec80 dataset. Experiments using our proposed enhancement method show promising results with improvements of 4\% in accuracy and 4\% in F1-Score over the baseline performance of RGB images. In addition, our approach improves over the saturation histogram based classification methodologies Saturation Analysis~(SAN) and Saturation Peak Analysis~(SPA) by 1/5\% and 1/6\% in accuracy/F1-Score metrics.
LooseCut: Interactive Image Segmentation with Loosely Bounded Boxes
Nov 22, 2015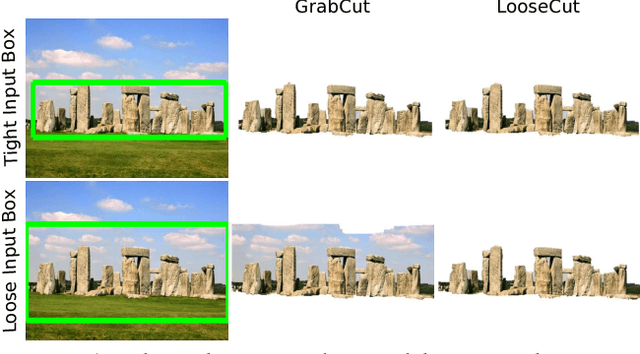


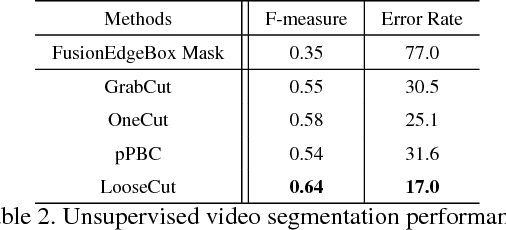
One popular approach to interactively segment the foreground object of interest from an image is to annotate a bounding box that covers the foreground object. Then, a binary labeling is performed to achieve a refined segmentation. One major issue of the existing algorithms for such interactive image segmentation is their preference of an input bounding box that tightly encloses the foreground object. This increases the annotation burden, and prevents these algorithms from utilizing automatically detected bounding boxes. In this paper, we develop a new LooseCut algorithm that can handle cases where the input bounding box only loosely covers the foreground object. We propose a new Markov Random Fields (MRF) model for segmentation with loosely bounded boxes, including a global similarity constraint to better distinguish the foreground and background, and an additional energy term to encourage consistent labeling of similar-appearance pixels. This MRF model is then solved by an iterated max-flow algorithm. In the experiments, we evaluate LooseCut in three publicly-available image datasets, and compare its performance against several state-of-the-art interactive image segmentation algorithms. We also show that LooseCut can be used for enhancing the performance of unsupervised video segmentation and image saliency detection.
LAGNet: Logic-Aware Graph Network for Human Interaction Understanding
Nov 20, 2020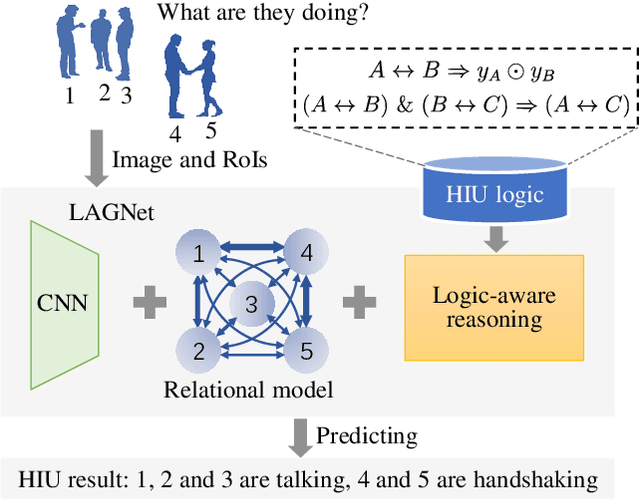
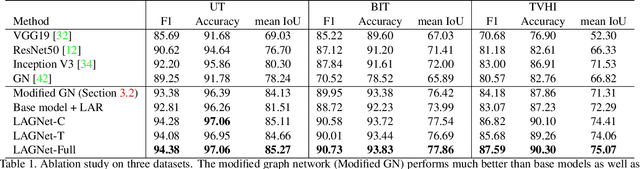
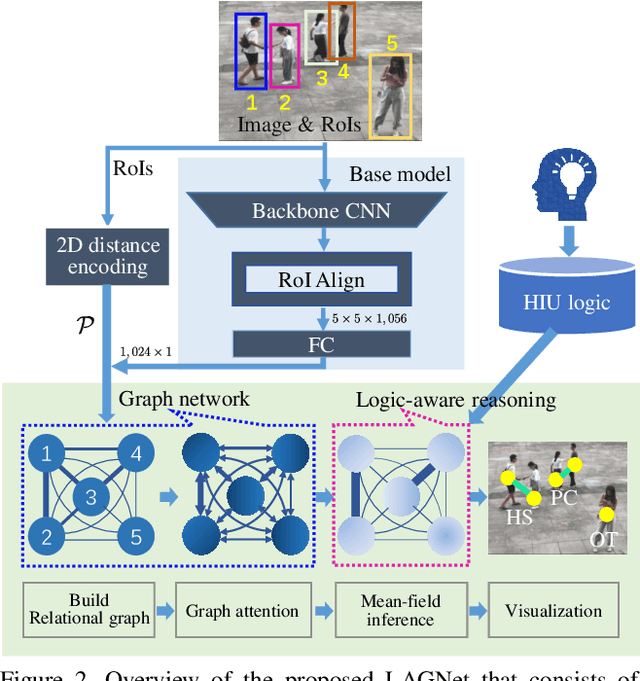

Compared with the progress made on human activity classification, much less success has been achieved on human interaction understanding (HIU). Apart from the latter task is much more challenging, the main cause is that recent approaches learn human interactive relations via shallow graphical representations, which is inadequate to model complicated human interactions. In this paper, we propose a deep logic-aware graph network, which combines the representative ability of graph attention and the rigorousness of logical reasoning to facilitate human interaction understanding. Our network consists of three components, a backbone CNN to extract image features, a graph network to learn interactive relations among participants, and a logic-aware reasoning module. Our key observation is that the first-order logic for HIU can be embedded into higher-order energy functions, minimizing which delivers logic-aware predictions. An efficient mean-field inference algorithm is proposed, such that all modules of our network could be trained jointly in an end-to-end way. Experimental results show that our approach achieves leading performance on three existing benchmarks and a new challenging dataset crafted by ourselves. Code will be publicly available.