 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
3rd Place Solution to "Google Landmark Retrieval 2020"
Aug 25, 2020
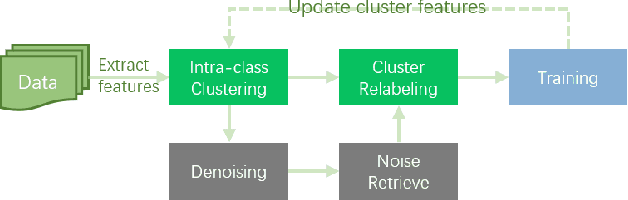
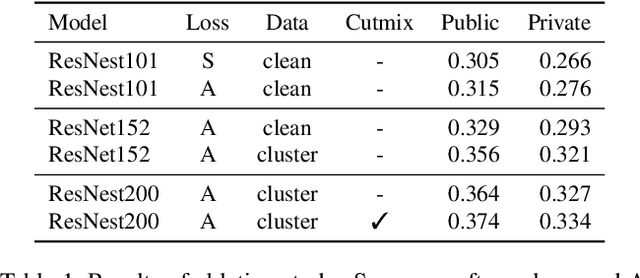

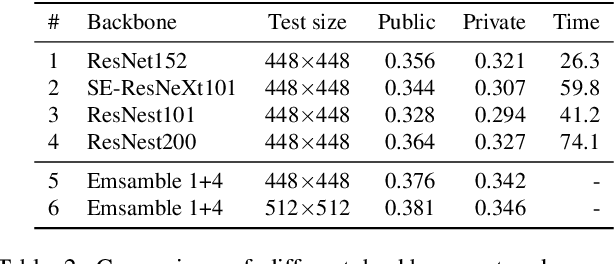
Image retrieval is a fundamental problem in computer vision. This paper presents our 3rd place detailed solution to the Google Landmark Retrieval 2020 challenge. We focus on the exploration of data cleaning and models with metric learning. We use a data cleaning strategy based on embedding clustering. Besides, we employ a data augmentation method called Corner-Cutmix, which improves the model's ability to recognize multi-scale and occluded landmark images. We show in detail the ablation experiments and results of our method.
Neural Group Testing to Accelerate Deep Learning
Nov 21, 2020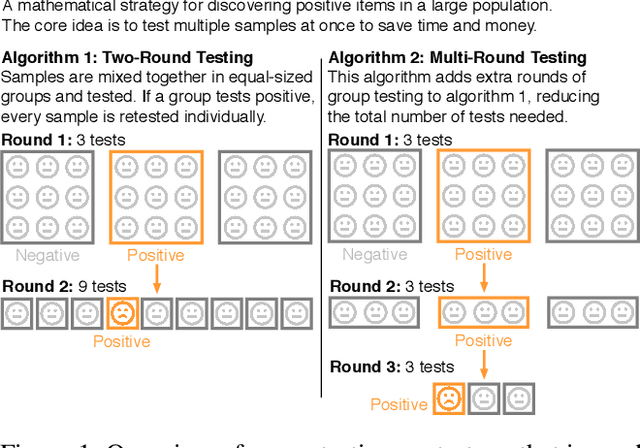
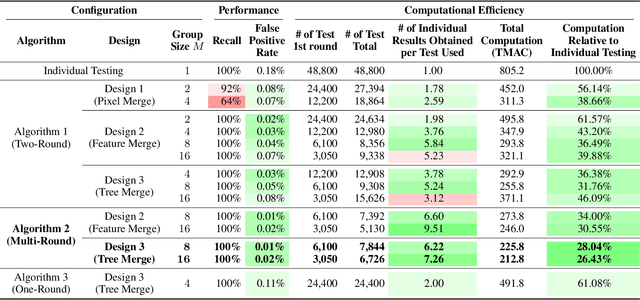
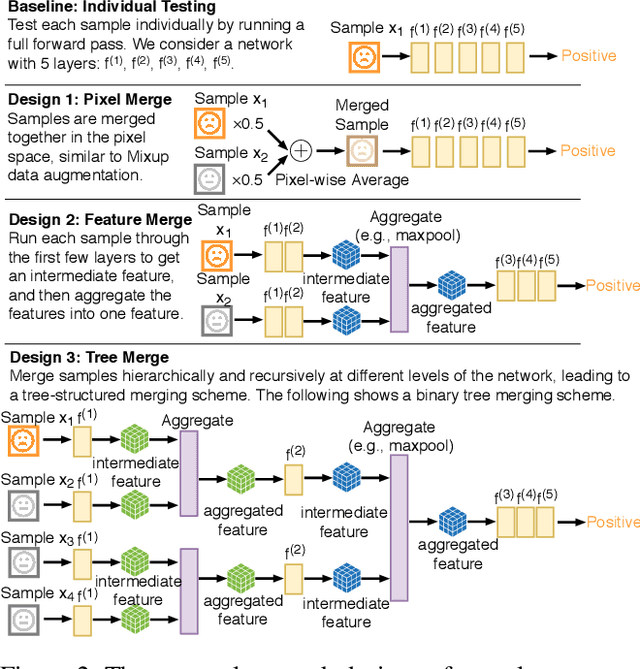
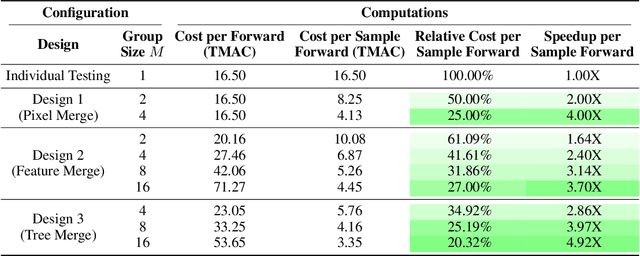
Recent advances in deep learning have made the use of large, deep neural networks with tens of millions of parameters. The sheer size of these networks imposes a challenging computational burden during inference. Existing work focuses primarily on accelerating each forward pass of a neural network. Inspired by the group testing strategy for efficient disease testing, we propose neural group testing, which accelerates by testing a group of samples in one forward pass. Groups of samples that test negative are ruled out. If a group tests positive, samples in that group are then retested adaptively. A key challenge of neural group testing is to modify a deep neural network so that it could test multiple samples in one forward pass. We propose three designs to achieve this without introducing any new parameters and evaluate their performances. We applied neural group testing in an image moderation task to detect rare but inappropriate images. We found that neural group testing can group up to 16 images in one forward pass and reduce the overall computation cost by over 73% while improving detection performance.
Webpage Segmentation for Extracting Images and Their Surrounding Contextual Information
May 18, 2020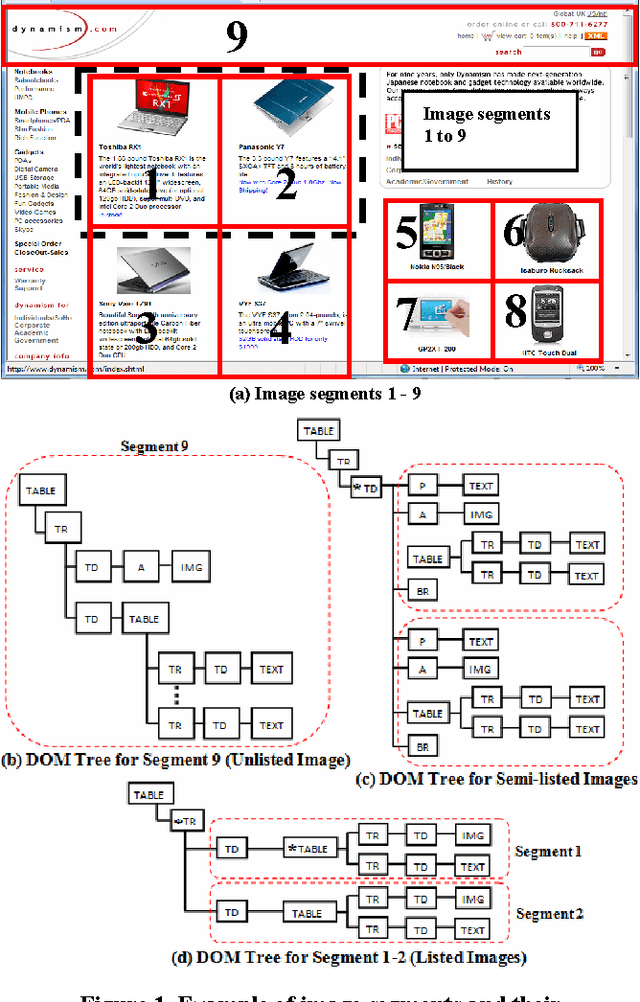
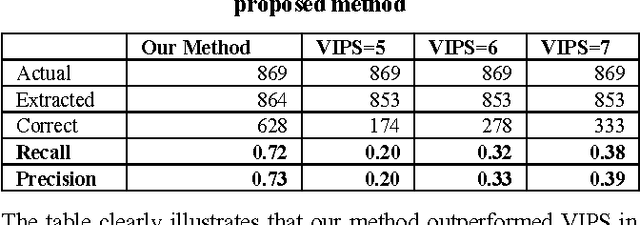
Web images come in hand with valuable contextual information. Although this information has long been mined for various uses such as image annotation, clustering of images, inference of image semantic content, etc., insufficient attention has been given to address issues in mining this contextual information. In this paper, we propose a webpage segmentation algorithm targeting the extraction of web images and their contextual information based on their characteristics as they appear on webpages. We conducted a user study to obtain a human-labeled dataset to validate the effectiveness of our method and experiments demonstrated that our method can achieve better results compared to an existing segmentation algorithm.
Point Cloud Quality Assessment: Large-scale Dataset Construction and Learning-based No-Reference Approach
Dec 22, 2020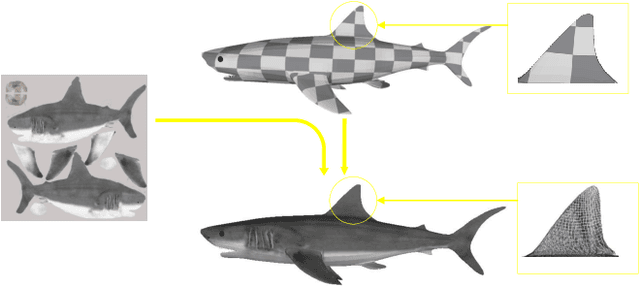
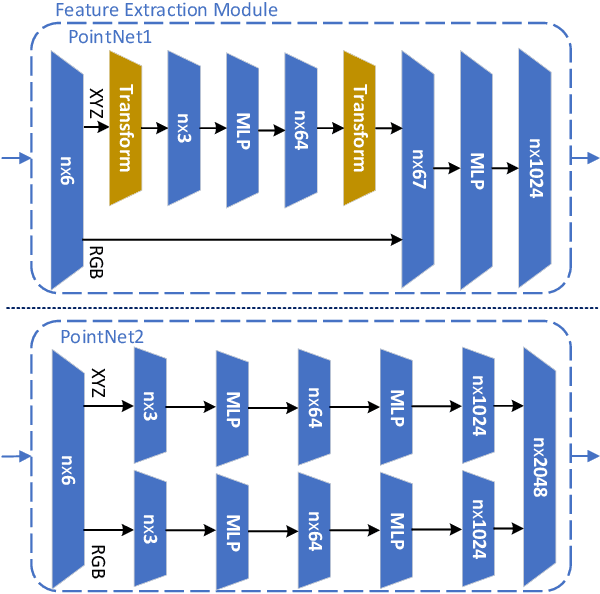
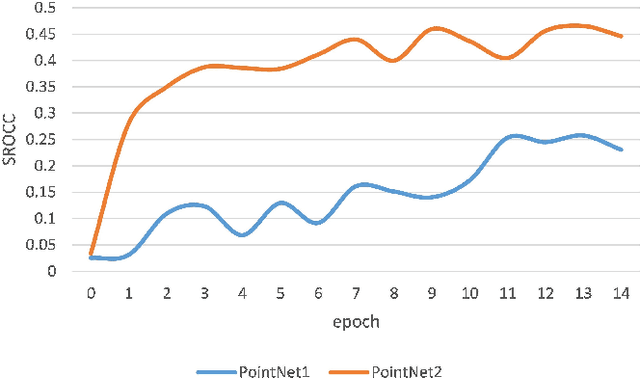
Full-reference (FR) point cloud quality assessment (PCQA) has achieved impressive progress in recent years. However, in many cases, obtaining the reference point cloud is difficult, so the no-reference (NR) methods have become a research hotspot. Since learning-based FR-PCQA methods should be driven by data, few researches about NR objective quality metrics are conducted due to lack of large-scale subjective point cloud dataset. The shortage of point cloud data restricts the development of NR-PCQA techniques. Besides, the distinctive property of point cloud format makes infeasible applying blind image quality assessment (IQA) methods directly to predict the quality scores of point clouds. In this paper, we establish a large-scale PCQA dataset, which includes 104 reference point clouds and more than 24,000 distorted point clouds. In the established dataset, each reference point cloud is augmented with 34 types of impairments (e.g., Gaussian noise, contrast distortion, geometry noise, local loss, and compression loss) at 7 different distortion levels. Besides, inspired by the hierarchical perception system and considering the intrinsic attribute of point clouds, an end-to-end sparse convolutional neural network (CNN) is designed to accurately estimate the subjective quality. We conduct experiments on the new dataset to evaluate the performance of the proposed network. The results demonstrate that the proposed network has reliable performance. The dataset presented in this work will be publicly accessible at http://smt.sjtu.edu.cn.
Interpretable Deep Models for Cardiac Resynchronisation Therapy Response Prediction
Jul 09, 2020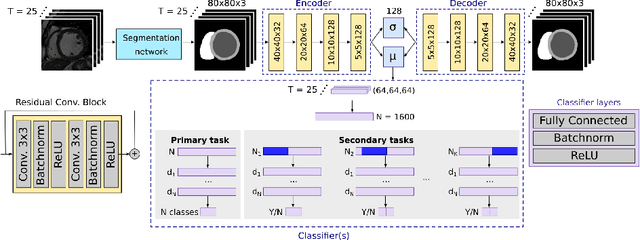

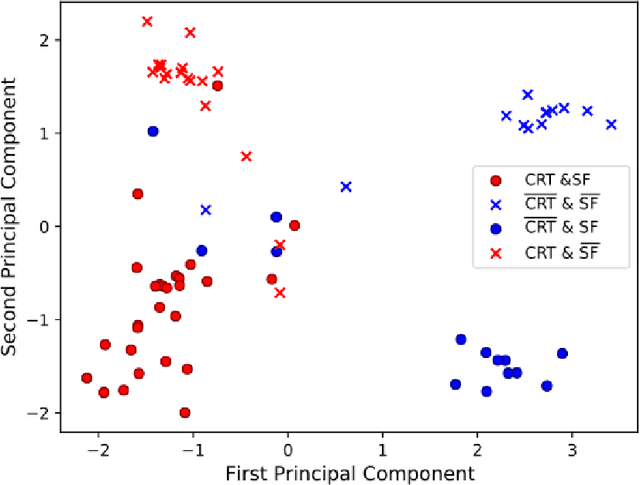

Advances in deep learning (DL) have resulted in impressive accuracy in some medical image classification tasks, but often deep models lack interpretability. The ability of these models to explain their decisions is important for fostering clinical trust and facilitating clinical translation. Furthermore, for many problems in medicine there is a wealth of existing clinical knowledge to draw upon, which may be useful in generating explanations, but it is not obvious how this knowledge can be encoded into DL models - most models are learnt either from scratch or using transfer learning from a different domain. In this paper we address both of these issues. We propose a novel DL framework for image-based classification based on a variational autoencoder (VAE). The framework allows prediction of the output of interest from the latent space of the autoencoder, as well as visualisation (in the image domain) of the effects of crossing the decision boundary, thus enhancing the interpretability of the classifier. Our key contribution is that the VAE disentangles the latent space based on `explanations' drawn from existing clinical knowledge. The framework can predict outputs as well as explanations for these outputs, and also raises the possibility of discovering new biomarkers that are separate (or disentangled) from the existing knowledge. We demonstrate our framework on the problem of predicting response of patients with cardiomyopathy to cardiac resynchronization therapy (CRT) from cine cardiac magnetic resonance images. The sensitivity and specificity of the proposed model on the task of CRT response prediction are 88.43% and 84.39% respectively, and we showcase the potential of our model in enhancing understanding of the factors contributing to CRT response.
Evolutionary Image Transition Based on Theoretical Insights of Random Processes
Apr 21, 2016
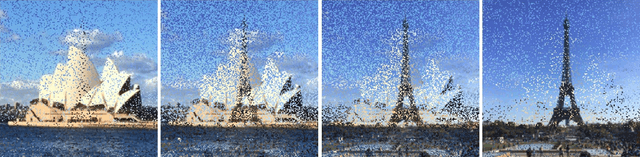


Evolutionary algorithms have been widely studied from a theoretical perspective. In particular, the area of runtime analysis has contributed significantly to a theoretical understanding and provided insights into the working behaviour of these algorithms. We study how these insights into evolutionary processes can be used for evolutionary art. We introduce the notion of evolutionary image transition which transfers a given starting image into a target image through an evolutionary process. Combining standard mutation effects known from the optimization of the classical benchmark function OneMax and different variants of random walks, we present ways of performing evolutionary image transition with different artistic effects.
Hierarchical Motion Consistency Constraint for Efficient Geometrical Verification in UAV Image Matching
Jan 12, 2018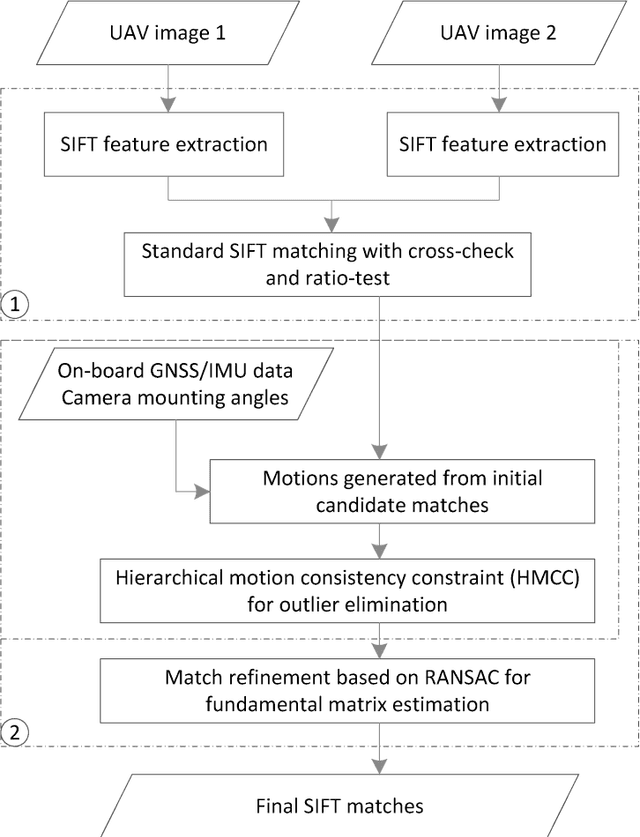
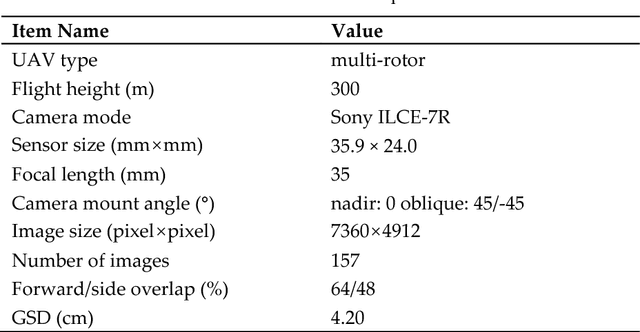
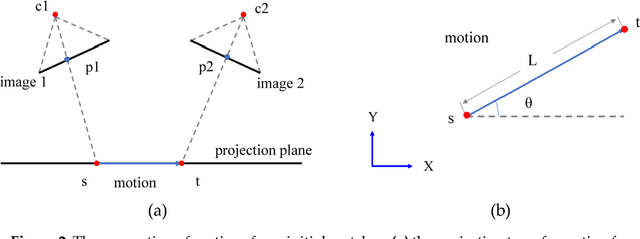

This paper proposes a strategy for efficient geometrical verification in unmanned aerial vehicle (UAV) image matching. First, considering the complex transformation model between correspondence set in the image-space, feature points of initial candidate matches are projected onto an elevation plane in the object-space, with assistant of UAV flight control data and camera mounting angles. Spatial relationships are simplified as a 2D-translation in which a motion establishes the relation of two correspondence points. Second, a hierarchical motion consistency constraint, termed HMCC, is designed to eliminate outliers from initial candidate matches, which includes three major steps, namely the global direction consistency constraint, the local direction-change consistency constraint and the global length consistency constraint. To cope with scenarios with high outlier ratios, the HMCC is achieved by using a voting scheme. Finally, an efficient geometrical verification strategy is proposed by using the HMCC as a pre-processing step to increase inlier ratios before the consequent application of the basic RANSAC algorithm. The performance of the proposed strategy is verified through comprehensive comparison and analysis by using real UAV datasets captured with different photogrammetric systems. Experimental results demonstrate that the generated motions have noticeable separation ability, and the HMCC-RANSAC algorithm can efficiently eliminate outliers based on the motion consistency constraint, with a speedup ratio reaching to 6 for oblique UAV images. Even though the completeness sacrifice of approximately 7 percent of points is observed from image orientation tests, competitive orientation accuracy is achieved from all used datasets. For geometrical verification of both nadir and oblique UAV images, the proposed method can be a more efficient solution.
Large Scale Neural Architecture Search with Polyharmonic Splines
Nov 20, 2020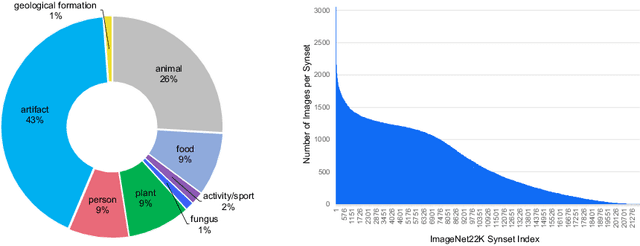
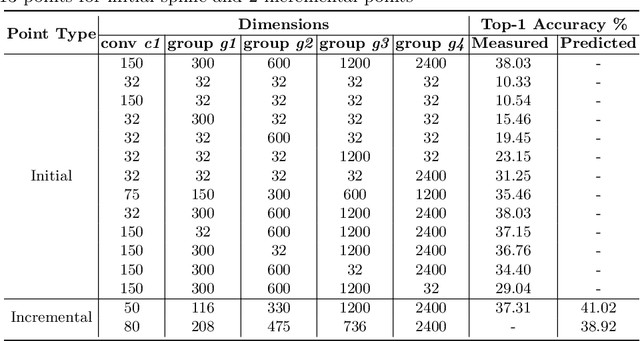
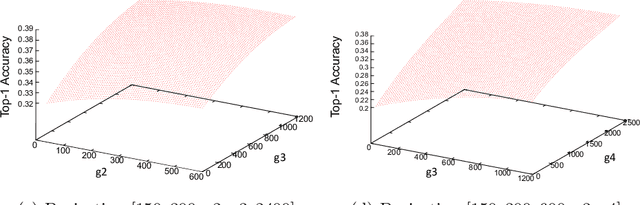
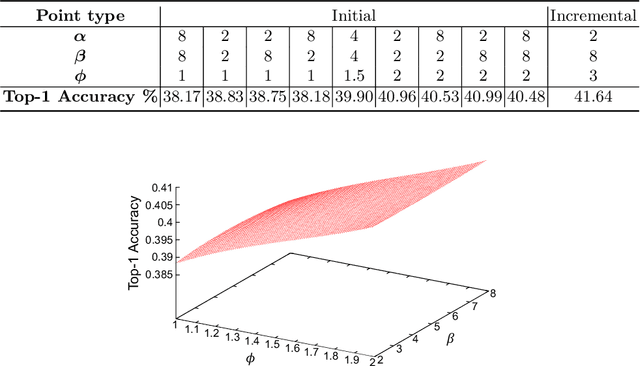
Neural Architecture Search (NAS) is a powerful tool to automatically design deep neural networks for many tasks, including image classification. Due to the significant computational burden of the search phase, most NAS methods have focused so far on small, balanced datasets. All attempts at conducting NAS at large scale have employed small proxy sets, and then transferred the learned architectures to larger datasets by replicating or stacking the searched cells. We propose a NAS method based on polyharmonic splines that can perform search directly on large scale, imbalanced target datasets. We demonstrate the effectiveness of our method on the ImageNet22K benchmark[16], which contains 14 million images distributed in a highly imbalanced manner over 21,841 categories. By exploring the search space of the ResNet [23] and Big-Little Net ResNext [11] architectures directly on ImageNet22K, our polyharmonic splines NAS method designed a model which achieved a top-1 accuracy of 40.03% on ImageNet22K, an absolute improvement of 3.13% over the state of the art with similar global batch size [15].
BiCANet: Bi-directional Contextual Aggregating Network for Image Semantic Segmentation
Mar 21, 2020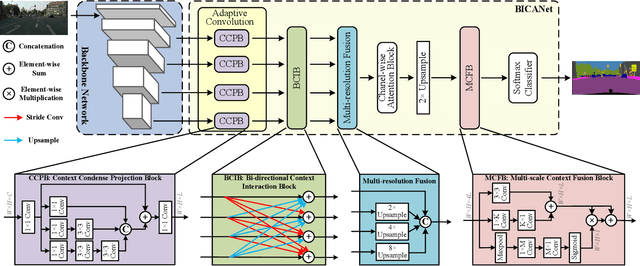
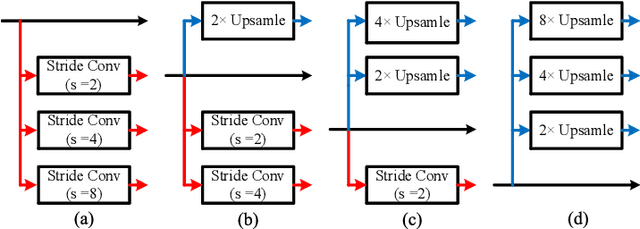
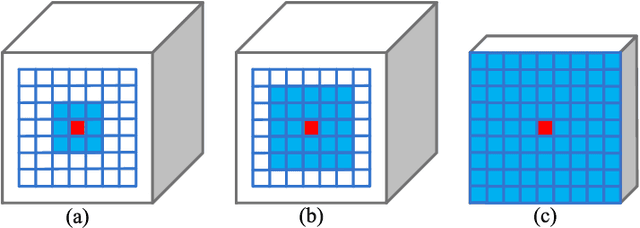

Exploring contextual information in convolution neural networks (CNNs) has gained substantial attention in recent years for semantic segmentation. This paper introduces a Bi-directional Contextual Aggregating Network, called BiCANet, for semantic segmentation. Unlike previous approaches that encode context in feature space, BiCANet aggregates contextual cues from a categorical perspective, which is mainly consist of three parts: contextual condensed projection block (CCPB), bi-directional context interaction block (BCIB), and muti-scale contextual fusion block (MCFB). More specifically, CCPB learns a category-based mapping through a split-transform-merge architecture, which condenses contextual cues with different receptive fields from intermediate layer. BCIB, on the other hand, employs dense skipped-connections to enhance the class-level context exchanging. Finally, MCFB integrates multi-scale contextual cues by investigating short- and long-ranged spatial dependencies. To evaluate BiCANet, we have conducted extensive experiments on three semantic segmentation datasets: PASCAL VOC 2012, Cityscapes, and ADE20K. The experimental results demonstrate that BiCANet outperforms recent state-of-the-art networks without any postprocess techniques. Particularly, BiCANet achieves the mIoU score of 86.7%, 82.4% and 38.66% on PASCAL VOC 2012, Cityscapes and ADE20K testset, respectively.
Robust Retinal Vessel Segmentation from a Data Augmentation Perspective
Jul 31, 2020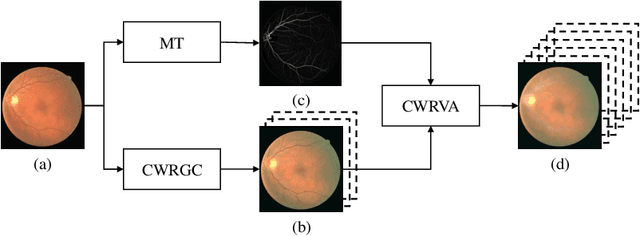
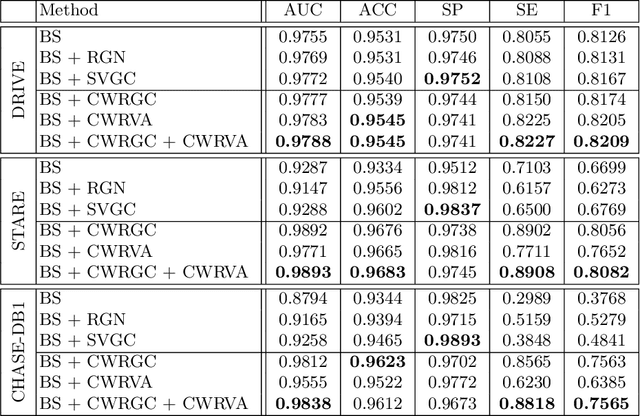

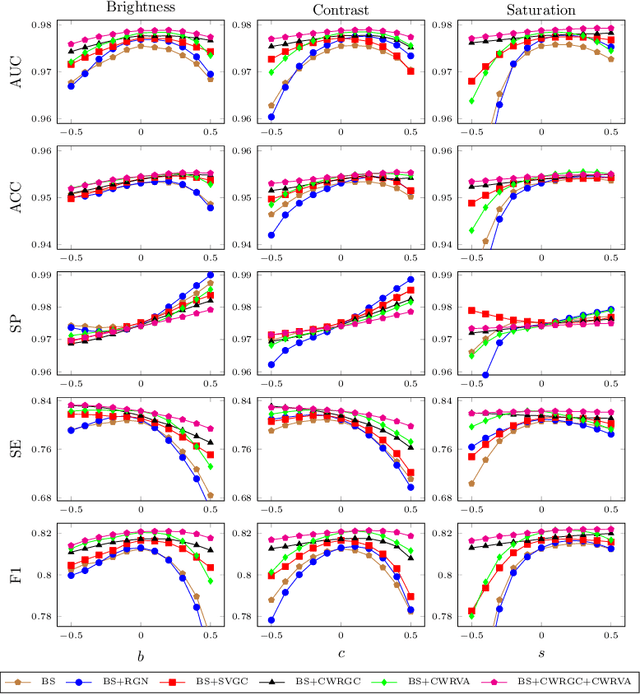
Retinal vessel segmentation is a fundamental step in screening, diagnosis, and treatment of various cardiovascular and ophthalmic diseases. Robustness is one of the most critical requirements for practical utilization, since the test images may be captured using different fundus cameras, or be affected by various pathological changes. We investigate this problem from a data augmentation perspective, with the merits of no additional training data or inference time. In this paper, we propose two new data augmentation modules, namely, channel-wise random Gamma correction and channel-wise random vessel augmentation. Given a training color fundus image, the former applies random gamma correction on each color channel of the entire image, while the latter intentionally enhances or decreases only the fine-grained blood vessel regions using morphological transformations. With the additional training samples generated by applying these two modules sequentially, a model could learn more invariant and discriminating features against both global and local disturbances. Experimental results on both real-world and synthetic datasets demonstrate that our method can improve the performance and robustness of a classic convolutional neural network architecture. Source codes are available https://github.com/PaddlePaddle/Research/tree/master/CV/robust_vessel_segmentation