 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Localized Interactive Instance Segmentation
Oct 18, 2020
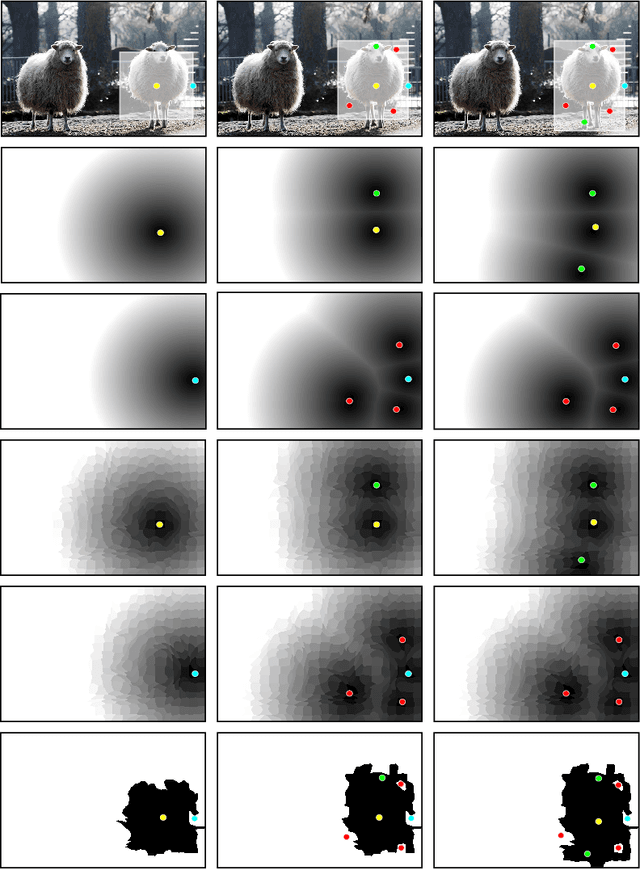
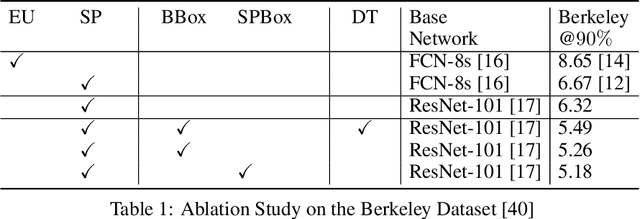
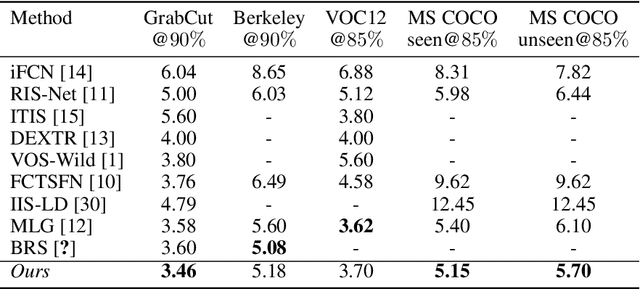

In current interactive instance segmentation works, the user is granted a free hand when providing clicks to segment an object; clicks are allowed on background pixels and other object instances far from the target object. This form of interaction is highly inconsistent with the end goal of efficiently isolating objects of interest. In our work, we propose a clicking scheme wherein user interactions are restricted to the proximity of the object. In addition, we propose a novel transformation of the user-provided clicks to generate a weak localization prior on the object which is consistent with image structures such as edges, textures etc. We demonstrate the effectiveness of our proposed clicking scheme and localization strategy through detailed experimentation in which we raise state-of-the-art on several standard interactive segmentation benchmarks.
Self-Challenging Improves Cross-Domain Generalization
Jul 05, 2020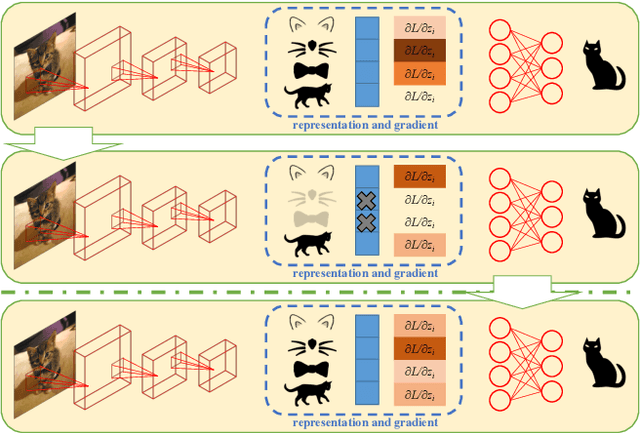
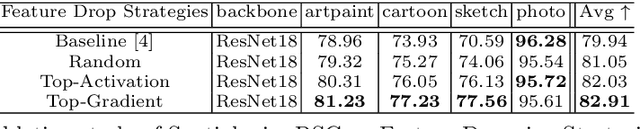
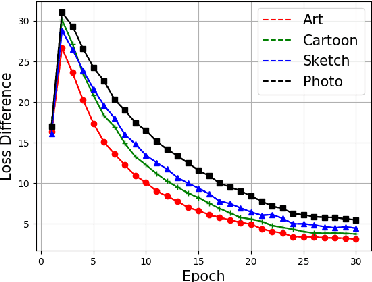
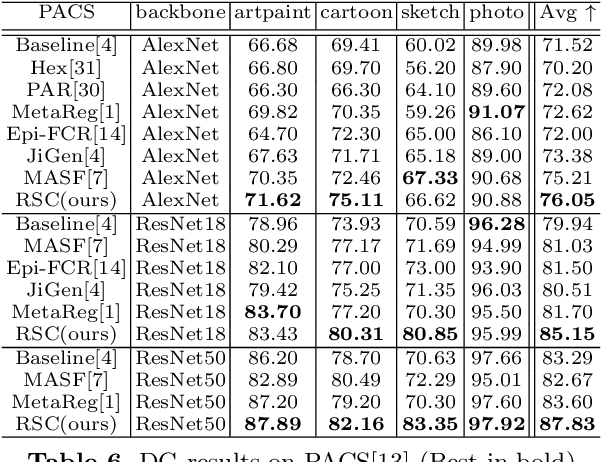
Convolutional Neural Networks (CNN) conduct image classification by activating dominant features that correlated with labels. When the training and testing data are under similar distributions, their dominant features are similar, which usually facilitates decent performance on the testing data. The performance is nonetheless unmet when tested on samples from different distributions, leading to the challenges in cross-domain image classification. We introduce a simple training heuristic, Representation Self-Challenging (RSC), that significantly improves the generalization of CNN to the out-of-domain data. RSC iteratively challenges (discards) the dominant features activated on the training data, and forces the network to activate remaining features that correlates with labels. This process appears to activate feature representations applicable to out-of-domain data without prior knowledge of new domain and without learning extra network parameters. We present theoretical properties and conditions of RSC for improving cross-domain generalization. The experiments endorse the simple, effective and architecture-agnostic nature of our RSC method.
Incremental Embedding Learning via Zero-Shot Translation
Dec 31, 2020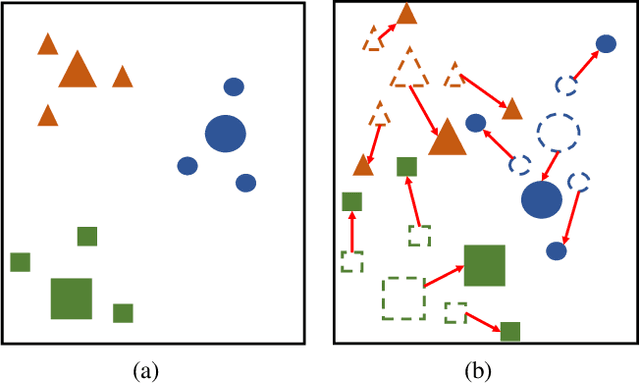
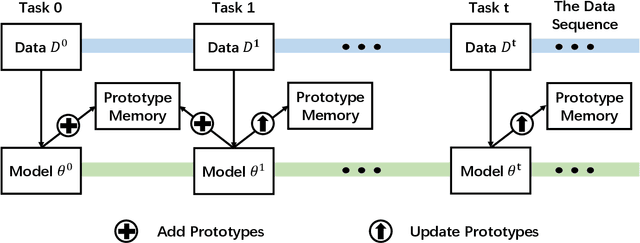
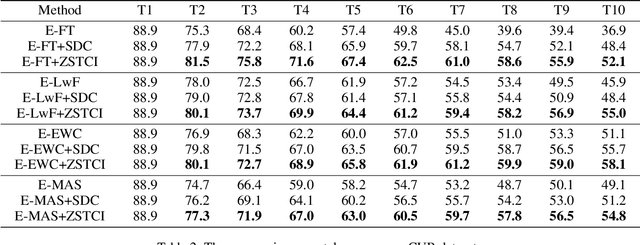
Modern deep learning methods have achieved great success in machine learning and computer vision fields by learning a set of pre-defined datasets. Howerver, these methods perform unsatisfactorily when applied into real-world situations. The reason of this phenomenon is that learning new tasks leads the trained model quickly forget the knowledge of old tasks, which is referred to as catastrophic forgetting. Current state-of-the-art incremental learning methods tackle catastrophic forgetting problem in traditional classification networks and ignore the problem existing in embedding networks, which are the basic networks for image retrieval, face recognition, zero-shot learning, etc. Different from traditional incremental classification networks, the semantic gap between the embedding spaces of two adjacent tasks is the main challenge for embedding networks under incremental learning setting. Thus, we propose a novel class-incremental method for embedding network, named as zero-shot translation class-incremental method (ZSTCI), which leverages zero-shot translation to estimate and compensate the semantic gap without any exemplars. Then, we try to learn a unified representation for two adjacent tasks in sequential learning process, which captures the relationships of previous classes and current classes precisely. In addition, ZSTCI can easily be combined with existing regularization-based incremental learning methods to further improve performance of embedding networks. We conduct extensive experiments on CUB-200-2011 and CIFAR100, and the experiment results prove the effectiveness of our method. The code of our method has been released.
Densely connected multidilated convolutional networks for dense prediction tasks
Nov 21, 2020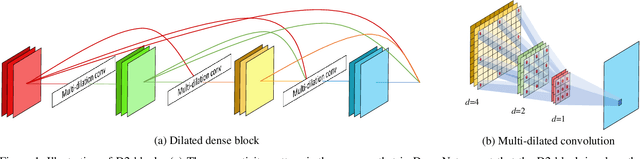
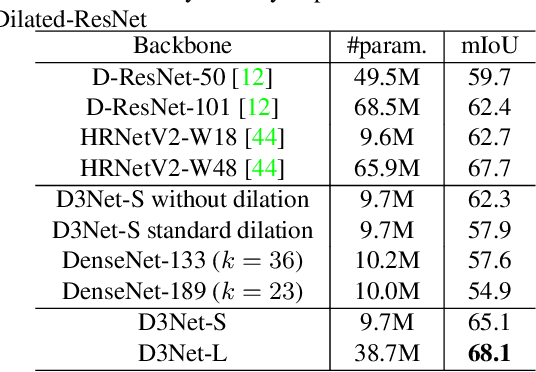

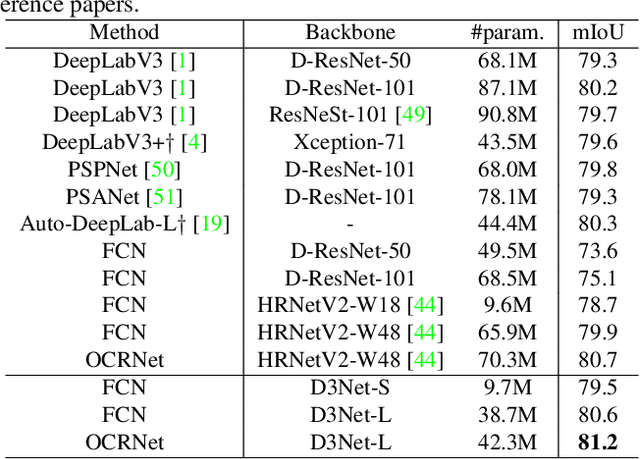
Tasks that involve high-resolution dense prediction require a modeling of both local and global patterns in a large input field. Although the local and global structures often depend on each other and their simultaneous modeling is important, many convolutional neural network (CNN)-based approaches interchange representations in different resolutions only a few times. In this paper, we claim the importance of a dense simultaneous modeling of multiresolution representation and propose a novel CNN architecture called densely connected multidilated DenseNet (D3Net). D3Net involves a novel multidilated convolution that has different dilation factors in a single layer to model different resolutions simultaneously. By combining the multidilated convolution with the DenseNet architecture, D3Net incorporates multiresolution learning with an exponentially growing receptive field in almost all layers, while avoiding the aliasing problem that occurs when we naively incorporate the dilated convolution in DenseNet. Experiments on the image semantic segmentation task using Cityscapes and the audio source separation task using MUSDB18 show that the proposed method has superior performance over state-of-the-art methods.
Self-Path: Self-supervision for Classification of Pathology Images with Limited Annotations
Aug 12, 2020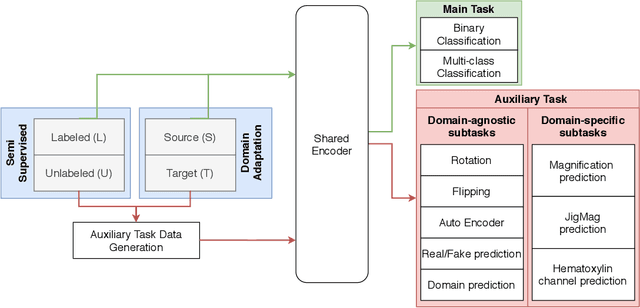
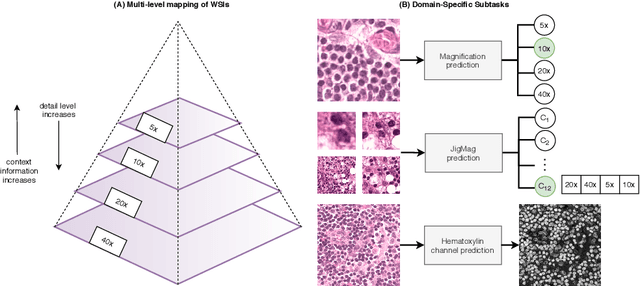
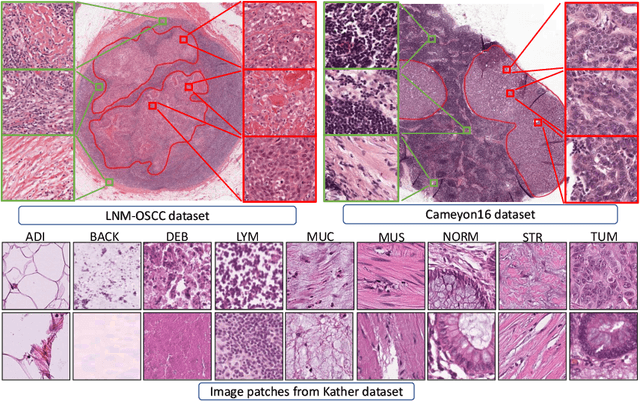
While high-resolution pathology images lend themselves well to `data hungry' deep learning algorithms, obtaining exhaustive annotations on these images is a major challenge. In this paper, we propose a self-supervised CNN approach to leverage unlabeled data for learning generalizable and domain invariant representations in pathology images. The proposed approach, which we term as Self-Path, is a multi-task learning approach where the main task is tissue classification and pretext tasks are a variety of self-supervised tasks with labels inherent to the input data. We introduce novel domain specific self-supervision tasks that leverage contextual, multi-resolution and semantic features in pathology images for semi-supervised learning and domain adaptation. We investigate the effectiveness of Self-Path on 3 different pathology datasets. Our results show that Self-Path with the domain-specific pretext tasks achieves state-of-the-art performance for semi-supervised learning when small amounts of labeled data are available. Further, we show that Self-Path improves domain adaptation for classification of histology image patches when there is no labeled data available for the target domain. This approach can potentially be employed for other applications in computational pathology, where annotation budget is often limited or large amount of unlabeled image data is available.
3D Point-to-Keypoint Voting Network for 6D Pose Estimation
Dec 22, 2020
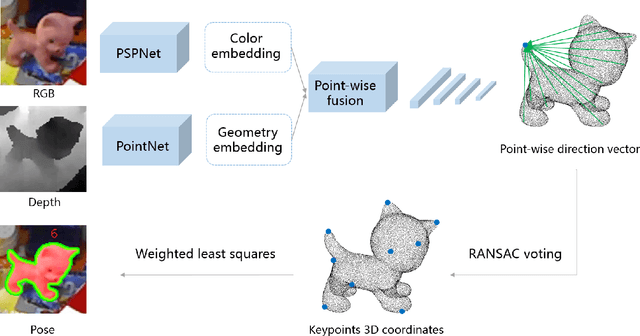


Object 6D pose estimation is an important research topic in the field of computer vision due to its wide application requirements and the challenges brought by complexity and changes in the real-world. We think fully exploring the characteristics of spatial relationship between points will help to improve the pose estimation performance, especially in the scenes of background clutter and partial occlusion. But this information was usually ignored in previous work using RGB image or RGB-D data. In this paper, we propose a framework for 6D pose estimation from RGB-D data based on spatial structure characteristics of 3D keypoints. We adopt point-wise dense feature embedding to vote for 3D keypoints, which makes full use of the structure information of the rigid body. After the direction vectors pointing to the keypoints are predicted by CNN, we use RANSAC voting to calculate the coordinate of the 3D keypoints, then the pose transformation can be easily obtained by the least square method. In addition, a spatial dimension sampling strategy for points is employed, which makes the method achieve excellent performance on small training sets. The proposed method is verified on two benchmark datasets, LINEMOD and OCCLUSION LINEMOD. The experimental results show that our method outperforms the state-of-the-art approaches, achieves ADD(-S) accuracy of 98.7\% on LINEMOD dataset and 52.6\% on OCCLUSION LINEMOD dataset in real-time.
Multi-channel Weighted Nuclear Norm Minimization for Real Color Image Denoising
May 28, 2017
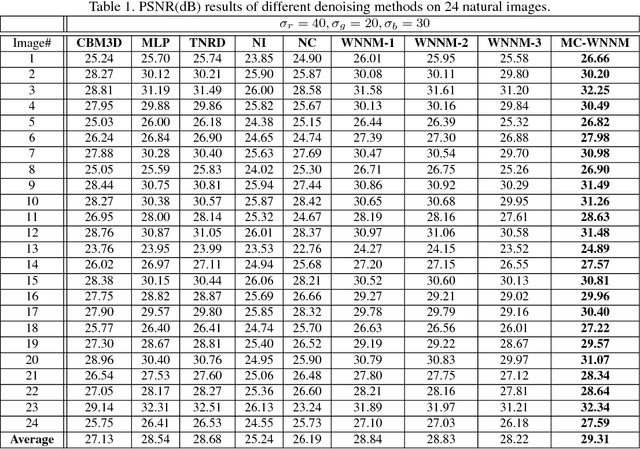

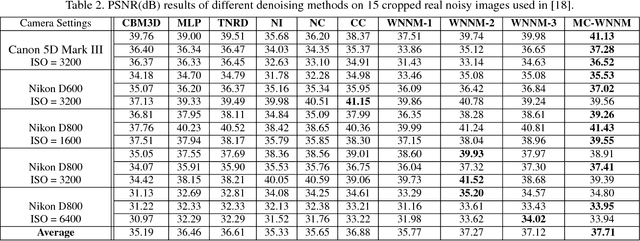
Most of the existing denoising algorithms are developed for grayscale images, while it is not a trivial work to extend them for color image denoising because the noise statistics in R, G, B channels can be very different for real noisy images. In this paper, we propose a multi-channel (MC) optimization model for real color image denoising under the weighted nuclear norm minimization (WNNM) framework. We concatenate the RGB patches to make use of the channel redundancy, and introduce a weight matrix to balance the data fidelity of the three channels in consideration of their different noise statistics. The proposed MC-WNNM model does not have an analytical solution. We reformulate it into a linear equality-constrained problem and solve it with the alternating direction method of multipliers. Each alternative updating step has closed-form solution and the convergence can be guaranteed. Extensive experiments on both synthetic and real noisy image datasets demonstrate the superiority of the proposed MC-WNNM over state-of-the-art denoising methods.
Neural Group Testing to Accelerate Deep Learning
Nov 21, 2020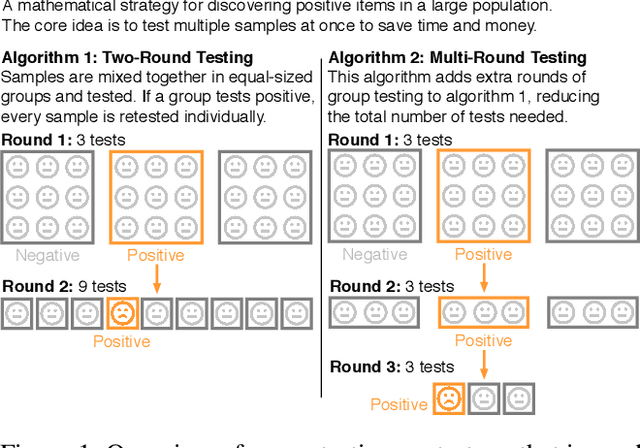
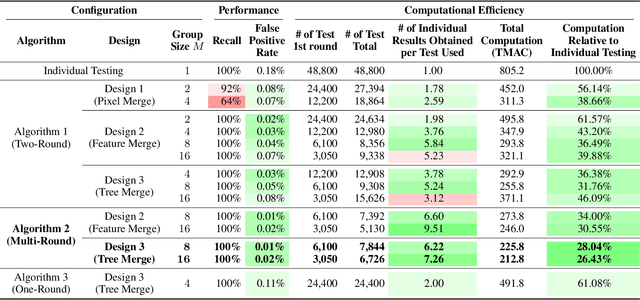
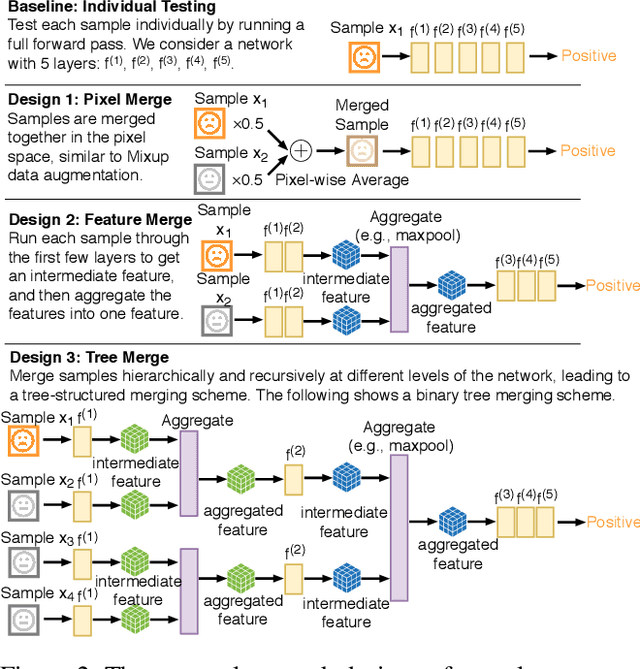
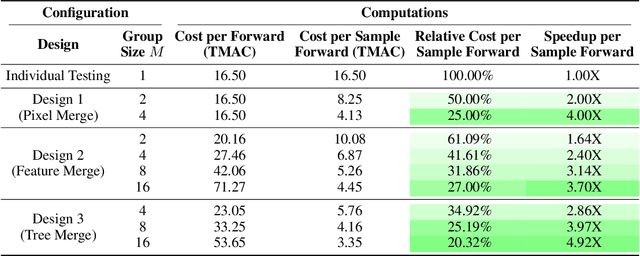
Recent advances in deep learning have made the use of large, deep neural networks with tens of millions of parameters. The sheer size of these networks imposes a challenging computational burden during inference. Existing work focuses primarily on accelerating each forward pass of a neural network. Inspired by the group testing strategy for efficient disease testing, we propose neural group testing, which accelerates by testing a group of samples in one forward pass. Groups of samples that test negative are ruled out. If a group tests positive, samples in that group are then retested adaptively. A key challenge of neural group testing is to modify a deep neural network so that it could test multiple samples in one forward pass. We propose three designs to achieve this without introducing any new parameters and evaluate their performances. We applied neural group testing in an image moderation task to detect rare but inappropriate images. We found that neural group testing can group up to 16 images in one forward pass and reduce the overall computation cost by over 73% while improving detection performance.
Point Cloud Quality Assessment: Large-scale Dataset Construction and Learning-based No-Reference Approach
Dec 22, 2020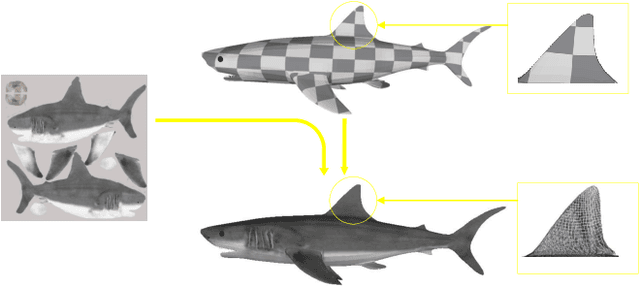
Full-reference (FR) point cloud quality assessment (PCQA) has achieved impressive progress in recent years. However, in many cases, obtaining the reference point cloud is difficult, so the no-reference (NR) methods have become a research hotspot. Since learning-based FR-PCQA methods should be driven by data, few researches about NR objective quality metrics are conducted due to lack of large-scale subjective point cloud dataset. The shortage of point cloud data restricts the development of NR-PCQA techniques. Besides, the distinctive property of point cloud format makes infeasible applying blind image quality assessment (IQA) methods directly to predict the quality scores of point clouds. In this paper, we establish a large-scale PCQA dataset, which includes 104 reference point clouds and more than 24,000 distorted point clouds. In the established dataset, each reference point cloud is augmented with 34 types of impairments (e.g., Gaussian noise, contrast distortion, geometry noise, local loss, and compression loss) at 7 different distortion levels. Besides, inspired by the hierarchical perception system and considering the intrinsic attribute of point clouds, an end-to-end sparse convolutional neural network (CNN) is designed to accurately estimate the subjective quality. We conduct experiments on the new dataset to evaluate the performance of the proposed network. The results demonstrate that the proposed network has reliable performance. The dataset presented in this work will be publicly accessible at http://smt.sjtu.edu.cn.
Size-to-depth: A New Perspective for Single Image Depth Estimation
Jan 13, 2018
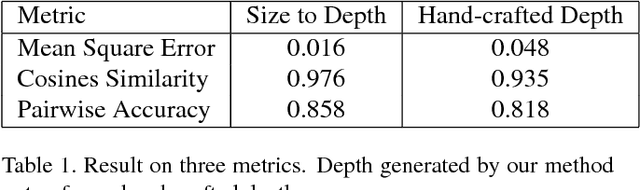


In this paper we consider the problem of single monocular image depth estimation. It is a challenging problem due to its ill-posedness nature and has found wide application in industry. Previous efforts belongs roughly to two families: learning-based method and interactive method. Learning-based method, in which deep convolutional neural network (CNN) is widely used, can achieve good result. But they suffer low generalization ability and typically perform poorly for unfamiliar scenes. Besides, data-hungry nature for such method makes data aquisition expensive and time-consuming. Interactive method requires human annotation of depth which, however, is errorneous and of large variance. To overcome these problems, we propose a new perspective for single monocular image depth estimation problem: size to depth. Our method require sparse label for real-world size of object rather than raw depth. A Coarse depth map is then inferred following geometric relationships according to size labels. Then we refine the depth map by doing energy function optimization on conditional random field(CRF). We experimentally demonstrate that our method outperforms traditional depth-labeling methods and can produce satisfactory depth maps.