 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
End-to-End Video Instance Segmentation with Transformers
Dec 04, 2020
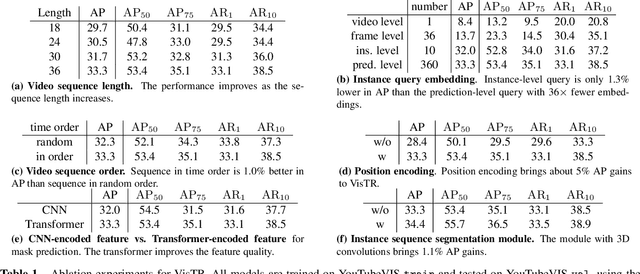
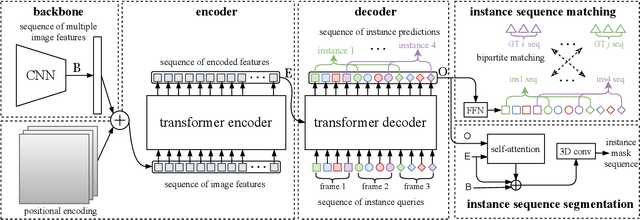
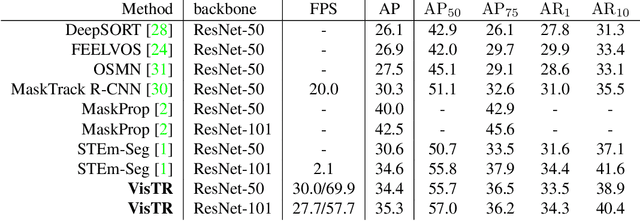

Video instance segmentation (VIS) is the task that requires simultaneously classifying, segmenting and tracking object instances of interest in video. Recent methods typically develop sophisticated pipelines to tackle this task. Here, we propose a new video instance segmentation framework built upon Transformers, termed VisTR, which views the VIS task as a direct end-to-end parallel sequence decoding/prediction problem. Given a video clip consisting of multiple image frames as input, VisTR outputs the sequence of masks for each instance in the video in order directly. At the core is a new, effective instance sequence matching and segmentation strategy, which supervises and segments instances at the sequence level as a whole. VisTR frames the instance segmentation and tracking in the same perspective of similarity learning, thus considerably simplifying the overall pipeline and is significantly different from existing approaches. Without bells and whistles, VisTR achieves the highest speed among all existing VIS models, and achieves the best result among methods using single model on the YouTube-VIS dataset. For the first time, we demonstrate a much simpler and faster video instance segmentation framework built upon Transformers, achieving competitive accuracy. We hope that VisTR can motivate future research for more video understanding tasks.
83% ImageNet Accuracy in One Hour
Oct 30, 2020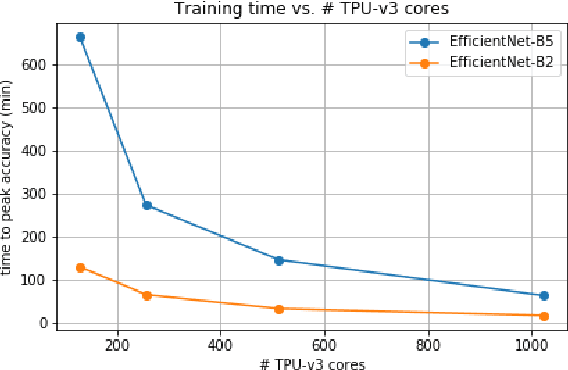
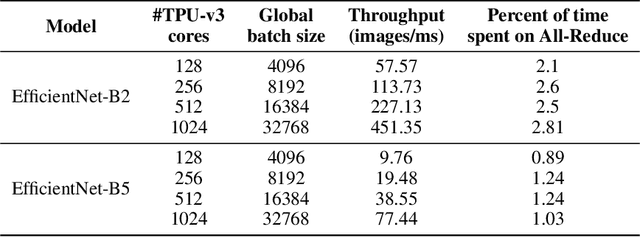
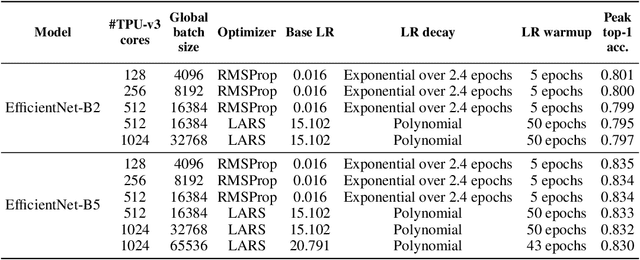
EfficientNets are a family of state-of-the-art image classification models based on efficiently scaled convolutional neural networks. Currently, EfficientNets can take on the order of days to train; for example, training an EfficientNet-B0 model takes 23 hours on a Cloud TPU v2-8 node. In this paper, we explore techniques to scale up the training of EfficientNets on TPU-v3 Pods with 2048 cores, motivated by speedups that can be achieved when training at such scales. We discuss optimizations required to scale training to a batch size of 65536 on 1024 TPU-v3 cores, such as selecting large batch optimizers and learning rate schedules as well as utilizing distributed evaluation and batch normalization techniques. Additionally, we present timing and performance benchmarks for EfficientNet models trained on the ImageNet dataset in order to analyze the behavior of EfficientNets at scale. With our optimizations, we are able to train EfficientNet on ImageNet to an accuracy of 83% in 1 hour and 4 minutes.
LooseCut: Interactive Image Segmentation with Loosely Bounded Boxes
Nov 22, 2015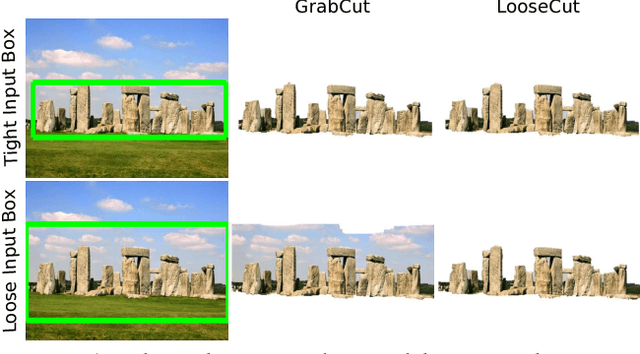


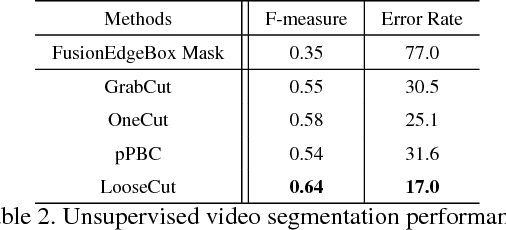
One popular approach to interactively segment the foreground object of interest from an image is to annotate a bounding box that covers the foreground object. Then, a binary labeling is performed to achieve a refined segmentation. One major issue of the existing algorithms for such interactive image segmentation is their preference of an input bounding box that tightly encloses the foreground object. This increases the annotation burden, and prevents these algorithms from utilizing automatically detected bounding boxes. In this paper, we develop a new LooseCut algorithm that can handle cases where the input bounding box only loosely covers the foreground object. We propose a new Markov Random Fields (MRF) model for segmentation with loosely bounded boxes, including a global similarity constraint to better distinguish the foreground and background, and an additional energy term to encourage consistent labeling of similar-appearance pixels. This MRF model is then solved by an iterated max-flow algorithm. In the experiments, we evaluate LooseCut in three publicly-available image datasets, and compare its performance against several state-of-the-art interactive image segmentation algorithms. We also show that LooseCut can be used for enhancing the performance of unsupervised video segmentation and image saliency detection.
Does V-NIR based Image Enhancement Come with Better Features?
Aug 24, 2016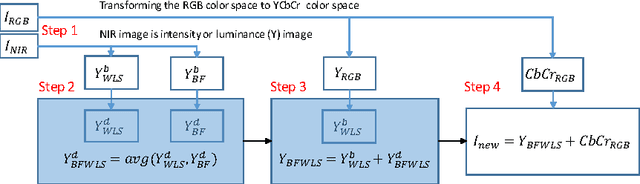


Image enhancement using the visible (V) and near-infrared (NIR) usually enhances useful image details. The enhanced images are evaluated by observers perception, instead of quantitative feature evaluation. Thus, can we say that these enhanced images using NIR information has better features in comparison to the computed features in the Red, Green, and Blue color channels directly? In this work, we present a new method to enhance the visible images using NIR information via edge-preserving filters, and also investigate which method performs best from a image features standpoint. We then show that our proposed enhancement method produces more stable features than the existing state-of-the-art methods.
Hierarchical Transfer Convolutional Neural Networks for Image Classification
May 09, 2018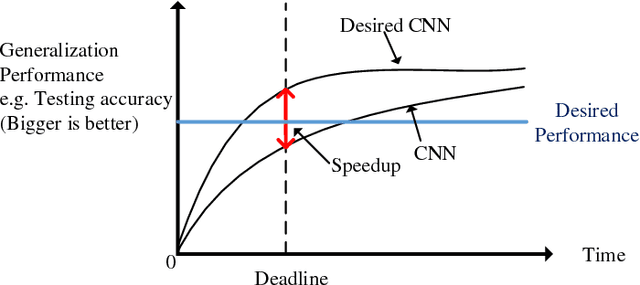
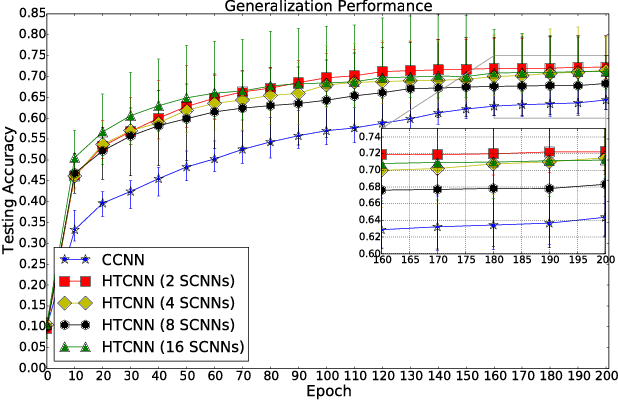
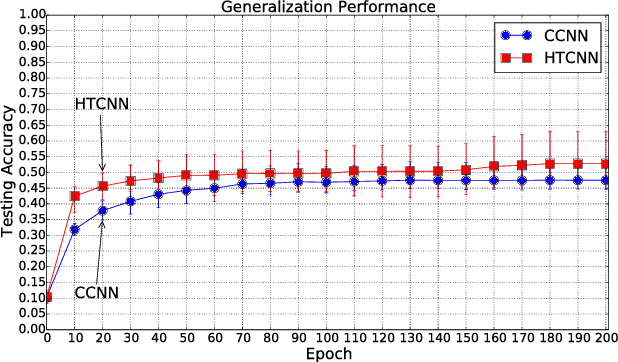
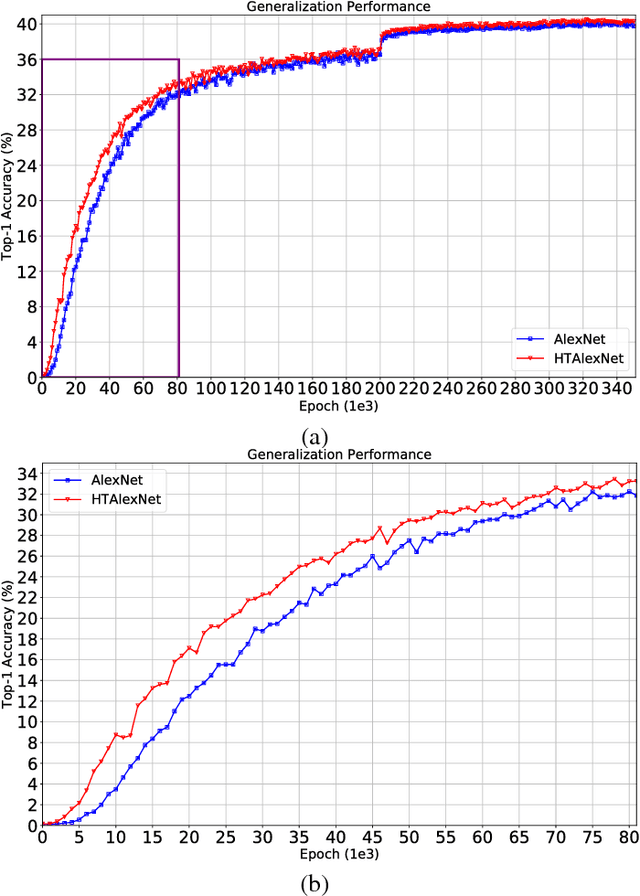
In this paper, we address the issue of how to enhance the generalization performance of convolutional neural networks (CNN) in the early learning stage for image classification. This is motivated by real-time applications that require the generalization performance of CNN to be satisfactory within limited training time. In order to achieve this, a novel hierarchical transfer CNN framework is proposed. It consists of a group of shallow CNNs and a cloud CNN, where the shallow CNNs are trained firstly and then the first layers of the trained shallow CNNs are used to initialize the first layer of the cloud CNN. This method will boost the generalization performance of the cloud CNN significantly, especially during the early stage of training. Experiments using CIFAR-10 and ImageNet datasets are performed to examine the proposed method. Results demonstrate the improvement of testing accuracy is 12% on average and as much as 20% for the CIFAR-10 case while 5% testing accuracy improvement for the ImageNet case during the early stage of learning. It is also shown that universal improvements of testing accuracy are obtained across different settings of dropout and number of shallow CNNs.
CPR-GCN: Conditional Partial-Residual Graph Convolutional Network in Automated Anatomical Labeling of Coronary Arteries
Apr 18, 2020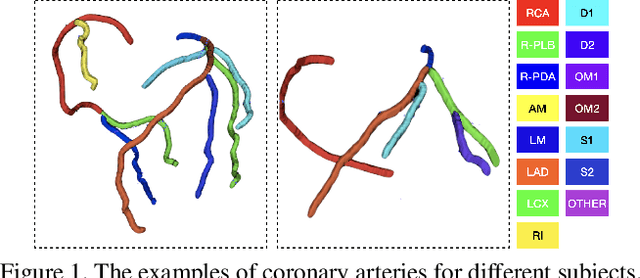
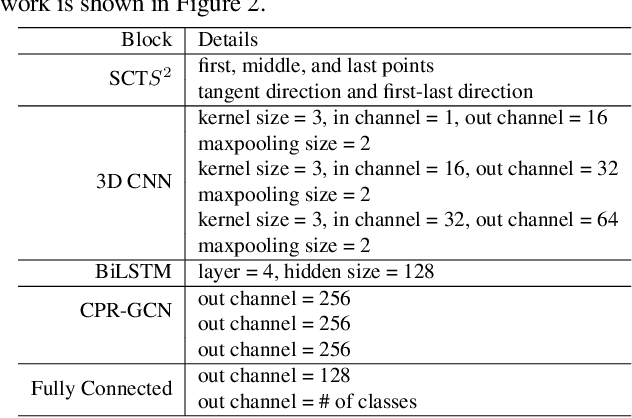
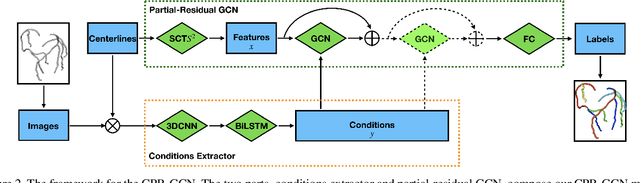
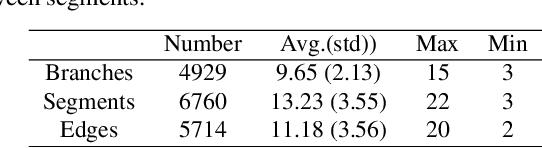
Automated anatomical labeling plays a vital role in coronary artery disease diagnosing procedure. The main challenge in this problem is the large individual variability inherited in human anatomy. Existing methods usually rely on the position information and the prior knowledge of the topology of the coronary artery tree, which may lead to unsatisfactory performance when the main branches are confusing. Motivated by the wide application of the graph neural network in structured data, in this paper, we propose a conditional partial-residual graph convolutional network (CPR-GCN), which takes both position and CT image into consideration, since CT image contains abundant information such as branch size and spanning direction. Two majority parts, a Partial-Residual GCN and a conditions extractor, are included in CPR-GCN. The conditions extractor is a hybrid model containing the 3D CNN and the LSTM, which can extract 3D spatial image features along the branches. On the technical side, the Partial-Residual GCN takes the position features of the branches, with the 3D spatial image features as conditions, to predict the label for each branches. While on the mathematical side, our approach twists the partial differential equation (PDE) into the graph modeling. A dataset with 511 subjects is collected from the clinic and annotated by two experts with a two-phase annotation process. According to the five-fold cross-validation, our CPR-GCN yields 95.8% meanRecall, 95.4% meanPrecision and 0.955 meanF1, which outperforms state-of-the-art approaches.
* This work is done by Xingjian Zhen during internship in Alibaba Damo Academy
Offset Curves Loss for Imbalanced Problem in Medical Segmentation
Dec 04, 2020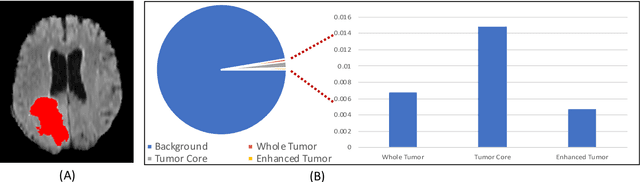
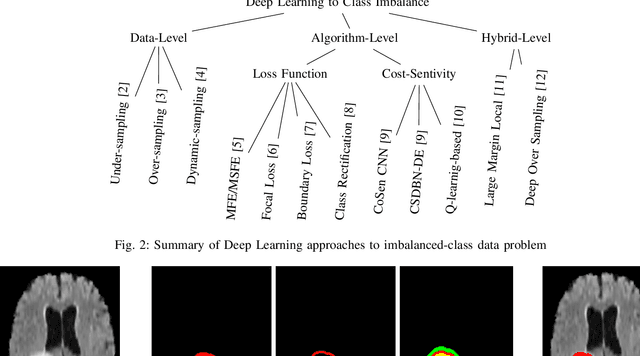

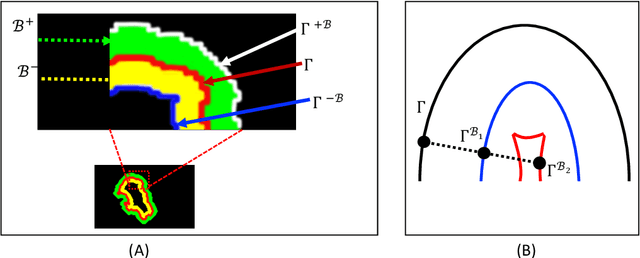
Medical image segmentation has played an important role in medical analysis and widely developed for many clinical applications. Deep learning-based approaches have achieved high performance in semantic segmentation but they are limited to pixel-wise setting and imbalanced classes data problem. In this paper, we tackle those limitations by developing a new deep learning-based model which takes into account both higher feature level i.e. region inside contour, intermediate feature level i.e. offset curves around the contour and lower feature level i.e. contour. Our proposed Offset Curves (OsC) loss consists of three main fitting terms. The first fitting term focuses on pixel-wise level segmentation whereas the second fitting term acts as attention model which pays attention to the area around the boundaries (offset curves). The third terms plays a role as regularization term which takes the length of boundaries into account. We evaluate our proposed OsC loss on both 2D network and 3D network. Two common medical datasets, i.e. retina DRIVE and brain tumor BRATS 2018 datasets are used to benchmark our proposed loss performance. The experiments have shown that our proposed OsC loss function outperforms other mainstream loss functions such as Cross-Entropy, Dice, Focal on the most common segmentation networks Unet, FCN.
VCE: Variational Convertor-Encoder for One-Shot Generalization
Nov 12, 2020Variational Convertor-Encoder (VCE) converts an image to various styles; we present this novel architecture for the problem of one-shot generalization and its transfer to new tasks not seen before without additional training. We also improve the performance of variational auto-encoder (VAE) to filter those blurred points using a novel algorithm proposed by us, namely large margin VAE (LMVAE). Two samples with the same property are input to the encoder, and then a convertor is required to processes one of them from the noisy outputs of the encoder; finally, the noise represents a variety of transformation rules and is used to convert new images. The algorithm that combines and improves the condition variational auto-encoder (CVAE) and introspective VAE, we propose this new framework aim to transform graphics instead of generating them; it is used for the one-shot generative process. No sequential inference algorithmic is needed in training. Compared to recent Omniglot datasets, the results show that our model produces more realistic and diverse images.
Algebraic Relations and Triangulation of Unlabeled Image Points
Jul 27, 2017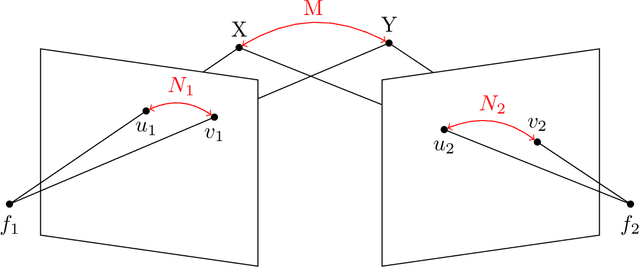

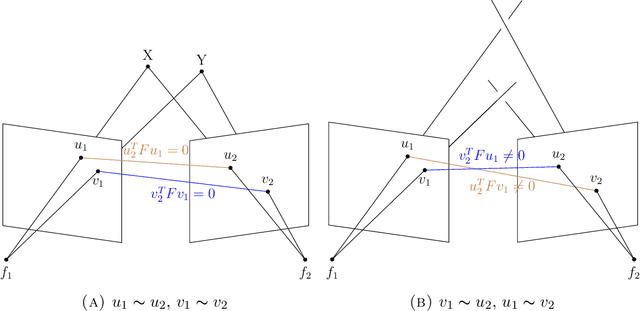

In multiview geometry when correspondences among multiple views are unknown the image points can be understood as being unlabeled. This is a common problem in computer vision. We give a novel approach to handle such a situation by regarding unlabeled point configurations as points on the Chow variety $\text{Sym}_m(\mathbb{P}^2)$. For two unlabeled points we design an algorithm that solves the triangulation problem with unknown correspondences. Further the unlabeled multiview variety $\text{Sym}_m(V_A)$ is studied.
Semantic Visual Navigation by Watching YouTube Videos
Jun 17, 2020
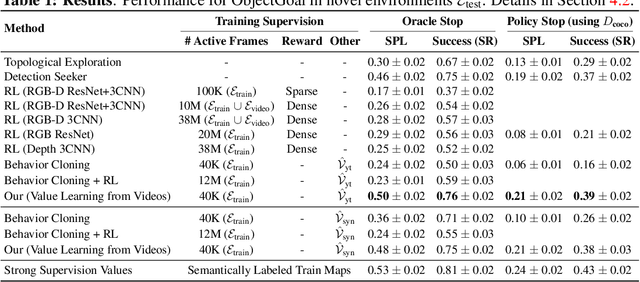
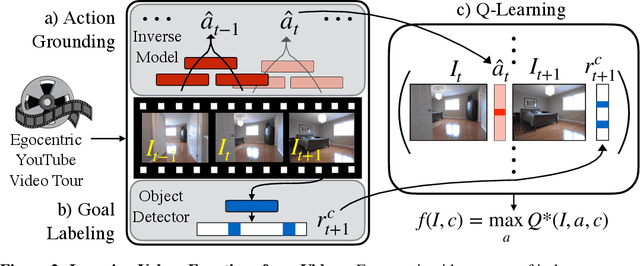
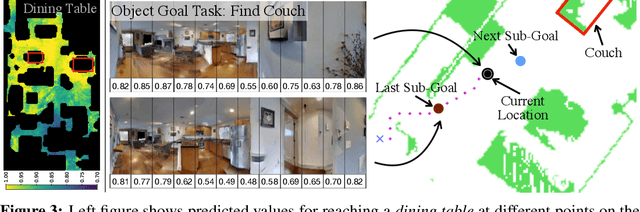
Semantic cues and statistical regularities in real-world environment layouts can improve efficiency for navigation in novel environments. This paper learns and leverages such semantic cues for navigating to objects of interest in novel environments, by simply watching YouTube videos. This is challenging because YouTube videos don't come with labels for actions or goals, and may not even showcase optimal behavior. Our proposed method tackles these challenges through the use of Q-learning on pseudo-labeled transition quadruples (image, action, next image, reward). We show that such off-policy Q-learning from passive data is able to learn meaningful semantic cues for navigation. These cues, when used in a hierarchical navigation policy, lead to improved efficiency at the ObjectGoal task in visually realistic simulations. We improve upon end-to-end RL methods by 66%, while using 250x fewer interactions. Code, data, and models will be made available.