 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Select-ProtoNet: Learning to Select for Few-Shot Disease Subtype Prediction
Sep 03, 2020
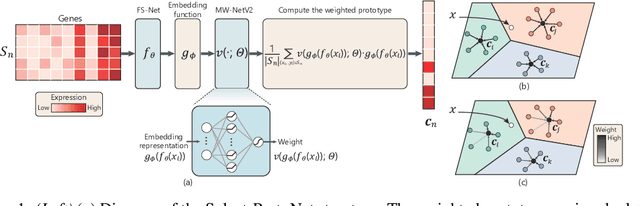
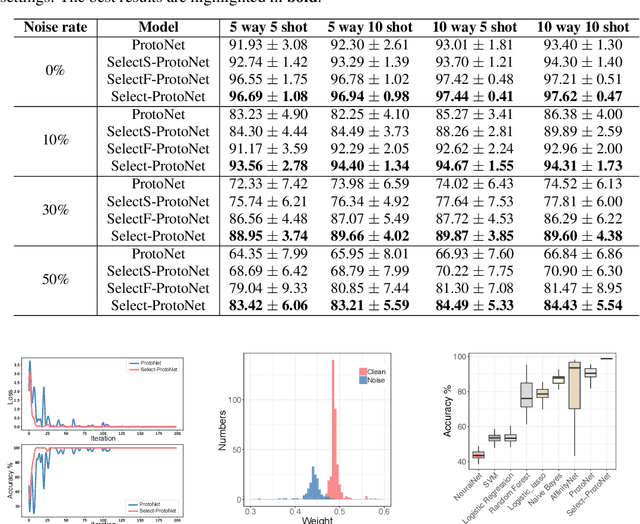
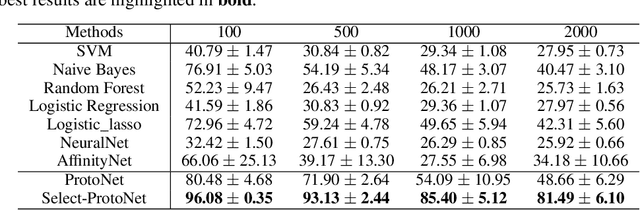
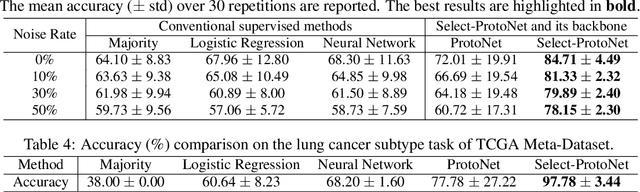
Current machine learning has made great progress on computer vision and many other fields attributed to the large amount of high-quality training samples, while it does not work very well on genomic data analysis, since they are notoriously known as small data. In our work, we focus on few-shot disease subtype prediction problem, identifying subgroups of similar patients that can guide treatment decisions for a specific individual through training on small data. In fact, doctors and clinicians always address this problem by studying several interrelated clinical variables simultaneously. We attempt to simulate such clinical perspective, and introduce meta learning techniques to develop a new model, which can extract the common experience or knowledge from interrelated clinical tasks and transfer it to help address new tasks. Our new model is built upon a carefully designed meta-learner, called Prototypical Network, that is a simple yet effective meta learning machine for few-shot image classification. Observing that gene expression data have specifically high dimensionality and high noise properties compared with image data, we proposed a new extension of it by appending two modules to address these issues. Concretely, we append a feature selection layer to automatically filter out the disease-irrelated genes and incorporate a sample reweighting strategy to adaptively remove noisy data, and meanwhile the extended model is capable of learning from a limited number of training examples and generalize well. Simulations and real gene expression data experiments substantiate the superiority of the proposed method for predicting the subtypes of disease and identifying potential disease-related genes.
From a Fourier-Domain Perspective on Adversarial Examples to a Wiener Filter Defense for Semantic Segmentation
Dec 02, 2020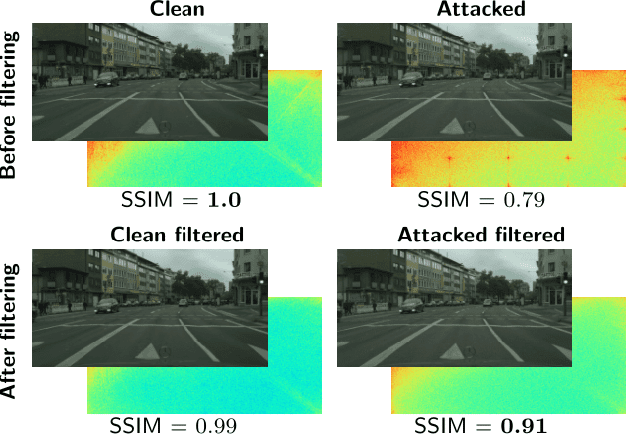
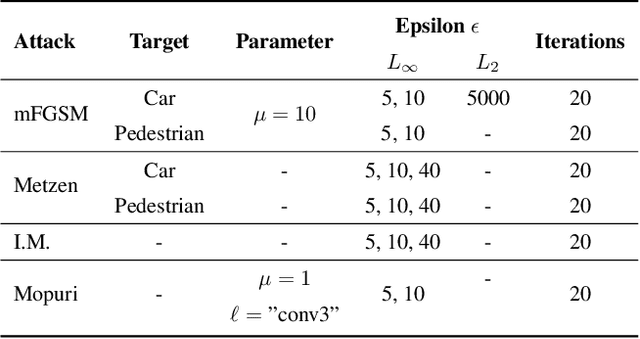
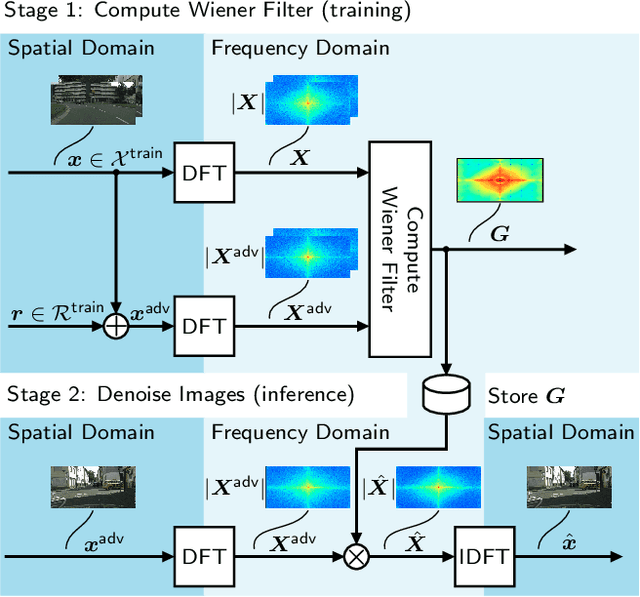
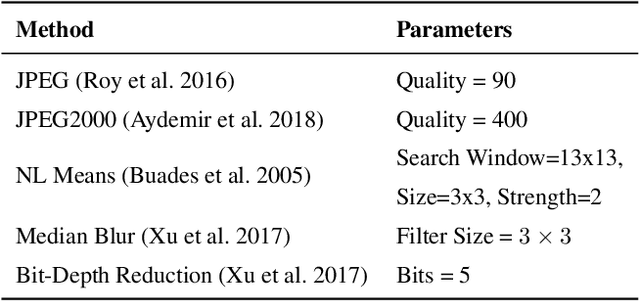
Despite recent advancements, deep neural networks are not robust against adversarial perturbations. Many of the proposed adversarial defense approaches use computationally expensive training mechanisms that do not scale to complex real-world tasks such as semantic segmentation, and offer only marginal improvements. In addition, fundamental questions on the nature of adversarial perturbations and their relation to the network architecture are largely understudied. In this work, we study the adversarial problem from a frequency domain perspective. More specifically, we analyze discrete Fourier transform (DFT) spectra of several adversarial images and report two major findings: First, there exists a strong connection between a model architecture and the nature of adversarial perturbations that can be observed and addressed in the frequency domain. Second, the observed frequency patterns are largely image- and attack-type independent, which is important for the practical impact of any defense making use of such patterns. Motivated by these findings, we additionally propose an adversarial defense method based on the well-known Wiener filters that captures and suppresses adversarial frequencies in a data-driven manner. Our proposed method not only generalizes across unseen attacks but also beats five existing state-of-the-art methods across two models in a variety of attack settings.
Polarization Human Shape and Pose Dataset
Apr 30, 2020


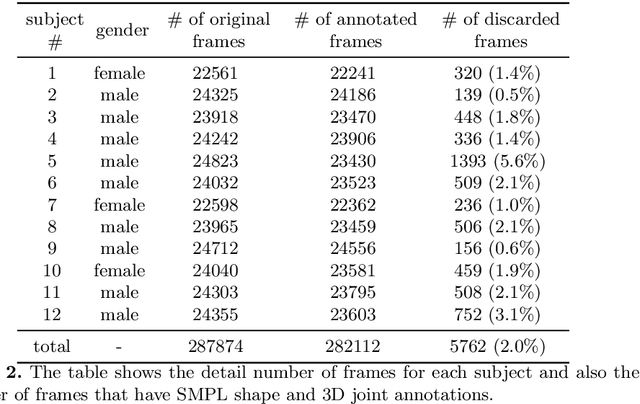
Polarization images are known to be able to capture polarized reflected lights that preserve rich geometric cues of an object, which has motivated its recent applications in reconstructing detailed surface normal of the objects of interest. Meanwhile, inspired by the recent breakthroughs in human shape estimation from a single color image, we attempt to investigate the new question of whether the geometric cues from polarization camera could be leveraged in estimating detailed human body shapes. This has led to the curation of Polarization Human Shape and Pose Dataset (PHSPD)5, our home-grown polarization image dataset of various human shapes and poses.
Improving Training on Noisy Stuctured Labels
Mar 08, 2020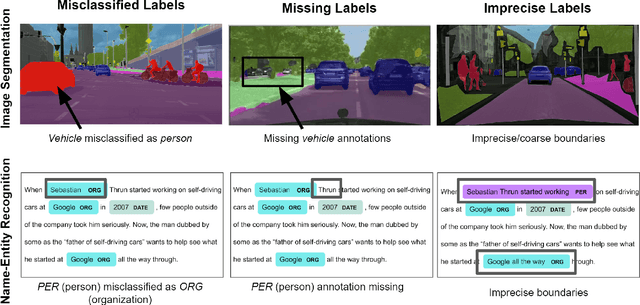
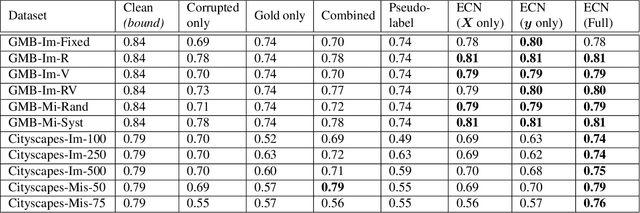
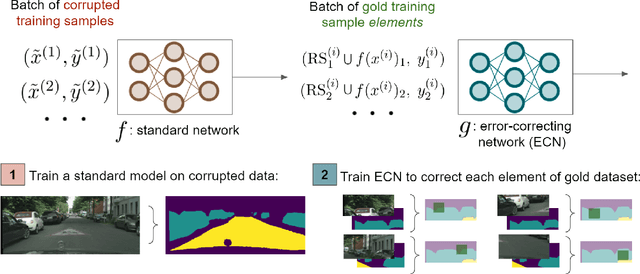
Fine-grained annotations---e.g. dense image labels, image segmentation and text tagging---are useful in many ML applications but they are labor-intensive to generate. Moreover there are often systematic, structured errors in these fine-grained annotations. For example, a car might be entirely unannotated in the image, or the boundary between a car and street might only be coarsely annotated. Standard ML training on data with such structured errors produces models with biases and poor performance. In this work, we propose a novel framework of Error-Correcting Networks (ECN) to address the challenge of learning in the presence structured error in fine-grained annotations. Given a large noisy dataset with commonly occurring structured errors, and a much smaller dataset with more accurate annotations, ECN is able to substantially improve the prediction of fine-grained annotations compared to standard approaches for training on noisy data. It does so by learning to leverage the structures in the annotations and in the noisy labels. Systematic experiments on image segmentation and text tagging demonstrate the strong performance of ECN in improving training on noisy structured labels.
Understanding the Failure Modes of Out-of-Distribution Generalization
Oct 29, 2020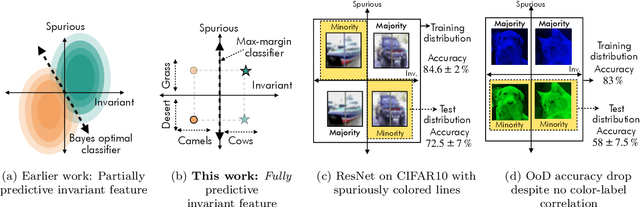
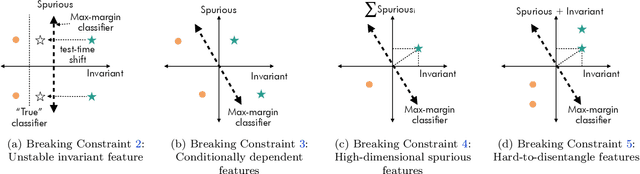
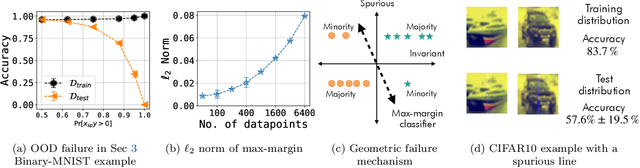
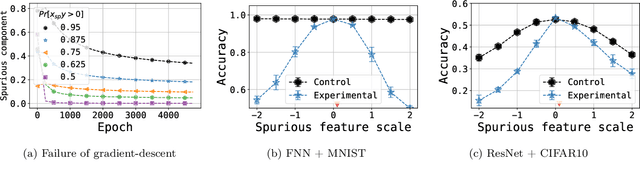
Empirical studies suggest that machine learning models often rely on features, such as the background, that may be spuriously correlated with the label only during training time, resulting in poor accuracy during test-time. In this work, we identify the fundamental factors that give rise to this behavior, by explaining why models fail this way {\em even} in easy-to-learn tasks where one would expect these models to succeed. In particular, through a theoretical study of gradient-descent-trained linear classifiers on some easy-to-learn tasks, we uncover two complementary failure modes. These modes arise from how spurious correlations induce two kinds of skews in the data: one geometric in nature, and another, statistical in nature. Finally, we construct natural modifications of image classification datasets to understand when these failure modes can arise in practice. We also design experiments to isolate the two failure modes when training modern neural networks on these datasets.
Image Annotation using Multi-Layer Sparse Coding
May 06, 2017

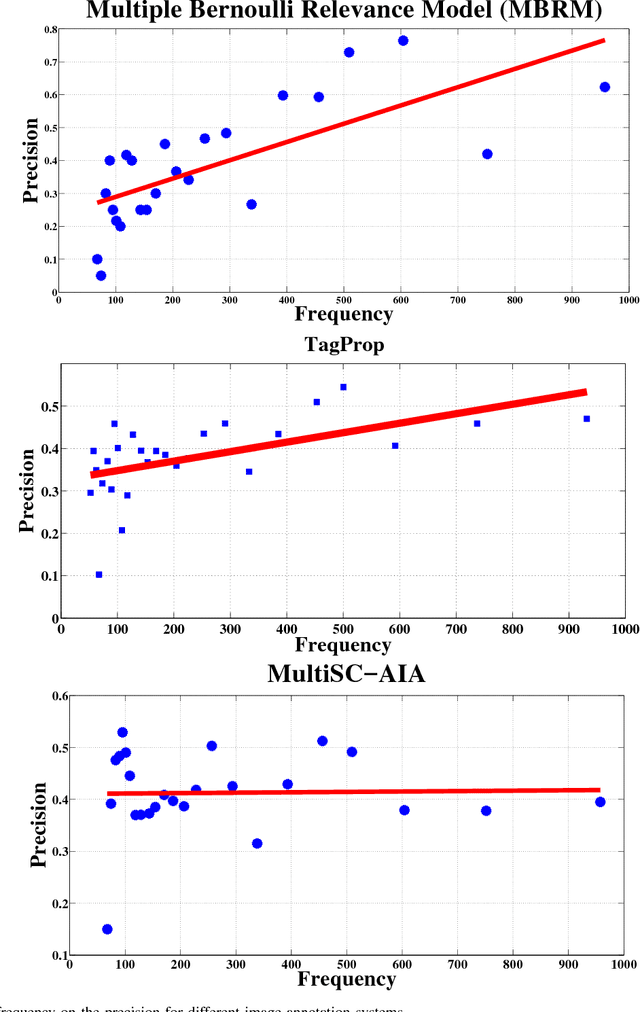

Automatic annotation of images with descriptive words is a challenging problem with vast applications in the areas of image search and retrieval. This problem can be viewed as a label-assignment problem by a classifier dealing with a very large set of labels, i.e., the vocabulary set. We propose a novel annotation method that employs two layers of sparse coding and performs coarse-to-fine labeling. Themes extracted from the training data are treated as coarse labels. Each theme is a set of training images that share a common subject in their visual and textual contents. Our system extracts coarse labels for training and test images without requiring any prior knowledge. Vocabulary words are the fine labels to be associated with images. Most of the annotation methods achieve low recall due to the large number of available fine labels, i.e., vocabulary words. These systems also tend to achieve high precision for highly frequent words only while relatively rare words are more important for search and retrieval purposes. Our system not only outperforms various previously proposed annotation systems, but also achieves symmetric response in terms of precision and recall. Our system scores and maintains high precision for words with a wide range of frequencies. Such behavior is achieved by intelligently reducing the number of available fine labels or words for each image based on coarse labels assigned to it.
SatImNet: Structured and Harmonised Training Data for Enhanced Satellite Imagery Classification
Jun 18, 2020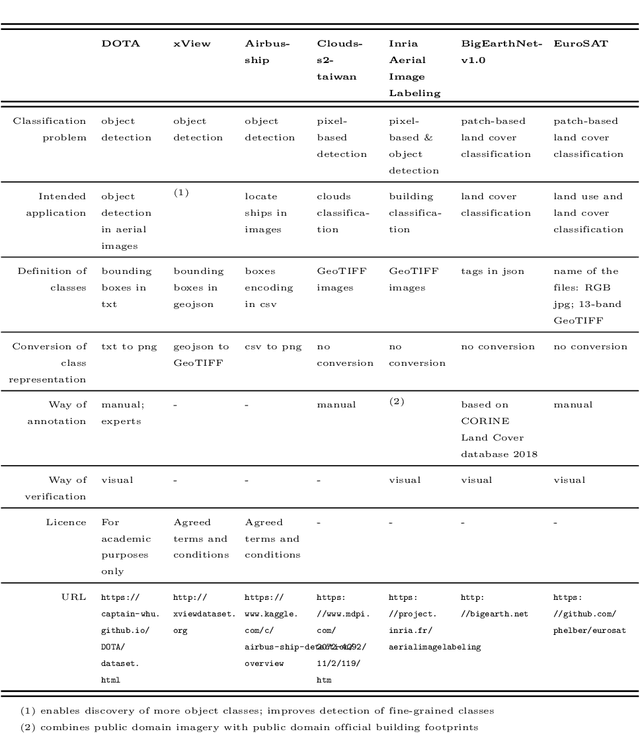
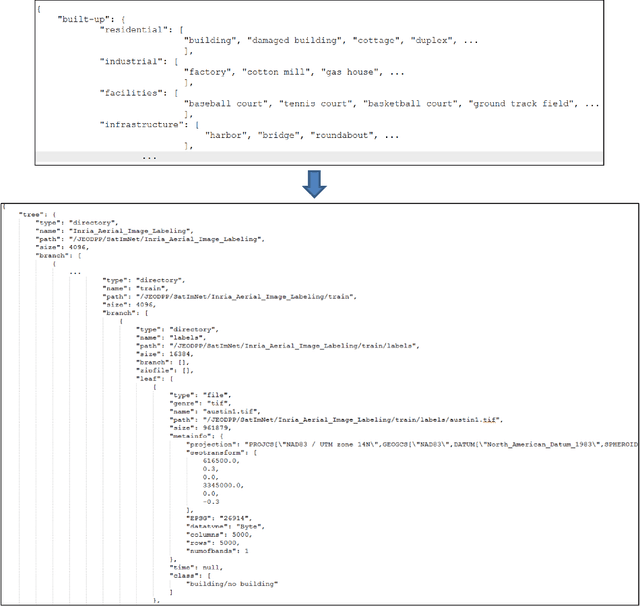
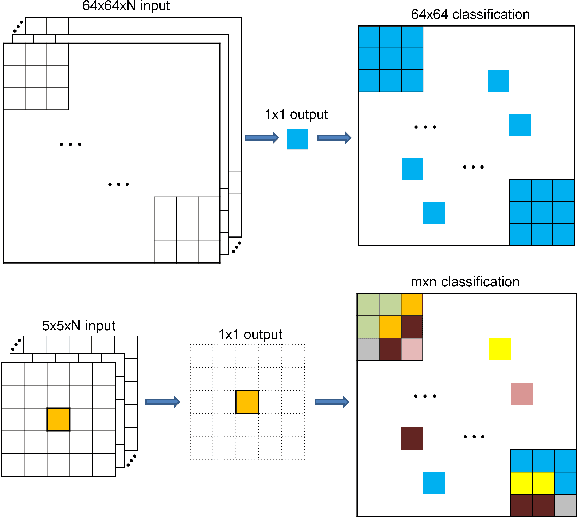
Automatic supervised classification of satellite images with complex modelling such as deep neural networks requires the availability of representative training datasets. While there exists a plethora of datasets that can be used for this purpose, they are usually very heterogeneous and not interoperable. This prevents the combination of two or more training datasets for improving image classification tasks based on machine learning. To alleviate these problems, we propose a methodology for structuring and harmonising open training datasets on the basis of a series of fundamental attributes we put forward for any such dataset. By applying this methodology to seven representative open training datasets, we generate a harmonised collection called SatImNet. Its usefulness is demonstrated for enhanced satellite image classification and segmentation based on convolutional neural networks. Data and open source code are provided to ensure the reproducibility of all obtained results and facilitate the ingestion of additional datasets in SatImNet.
A Self-Supervised Feature Map Augmentation (FMA) Loss and Combined Augmentations Finetuning to Efficiently Improve the Robustness of CNNs
Dec 02, 2020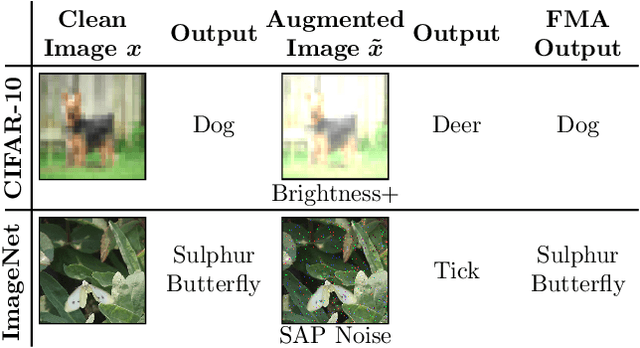
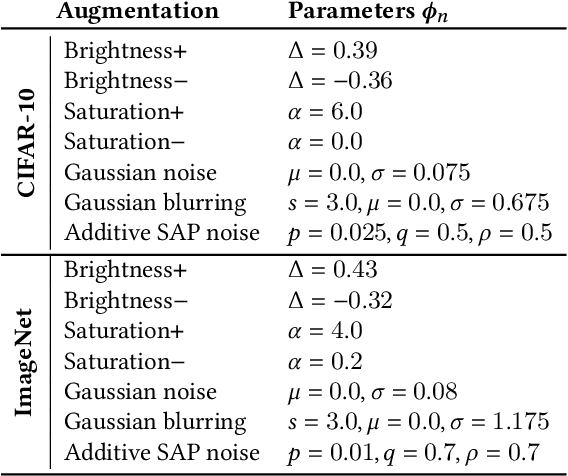
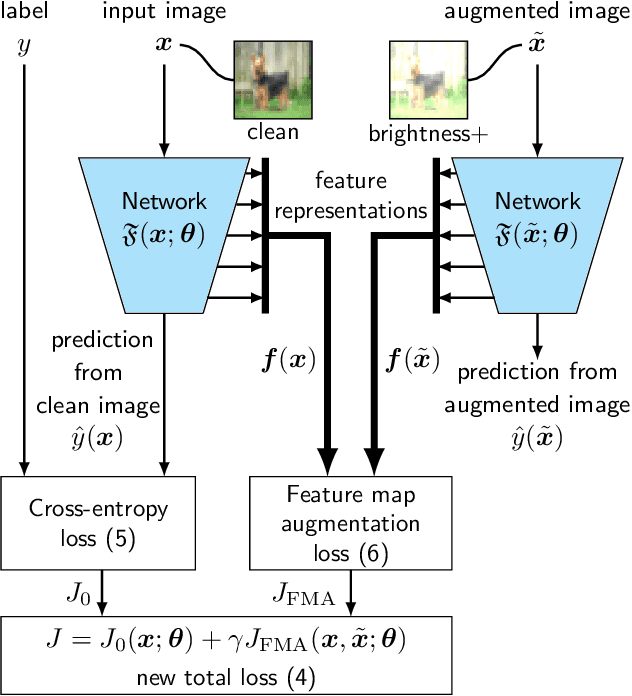
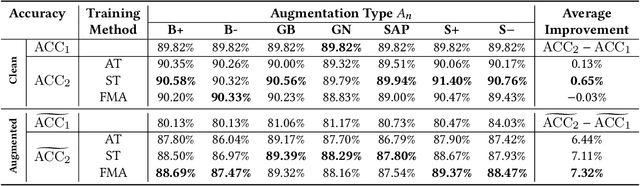
Deep neural networks are often not robust to semantically-irrelevant changes in the input. In this work we address the issue of robustness of state-of-the-art deep convolutional neural networks (CNNs) against commonly occurring distortions in the input such as photometric changes, or the addition of blur and noise. These changes in the input are often accounted for during training in the form of data augmentation. We have two major contributions: First, we propose a new regularization loss called feature-map augmentation (FMA) loss which can be used during finetuning to make a model robust to several distortions in the input. Second, we propose a new combined augmentations (CA) finetuning strategy, that results in a single model that is robust to several augmentation types at the same time in a data-efficient manner. We use the CA strategy to improve an existing state-of-the-art method called stability training (ST). Using CA, on an image classification task with distorted images, we achieve an accuracy improvement of on average 8.94% with FMA and 8.86% with ST absolute on CIFAR-10 and 8.04% with FMA and 8.27% with ST absolute on ImageNet, compared to 1.98% and 2.12%, respectively, with the well known data augmentation method, while keeping the clean baseline performance.
Cross-Descriptor Visual Localization and Mapping
Dec 02, 2020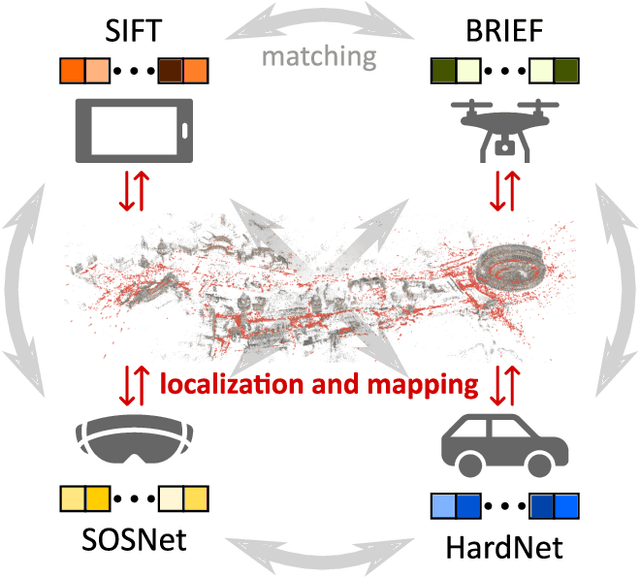
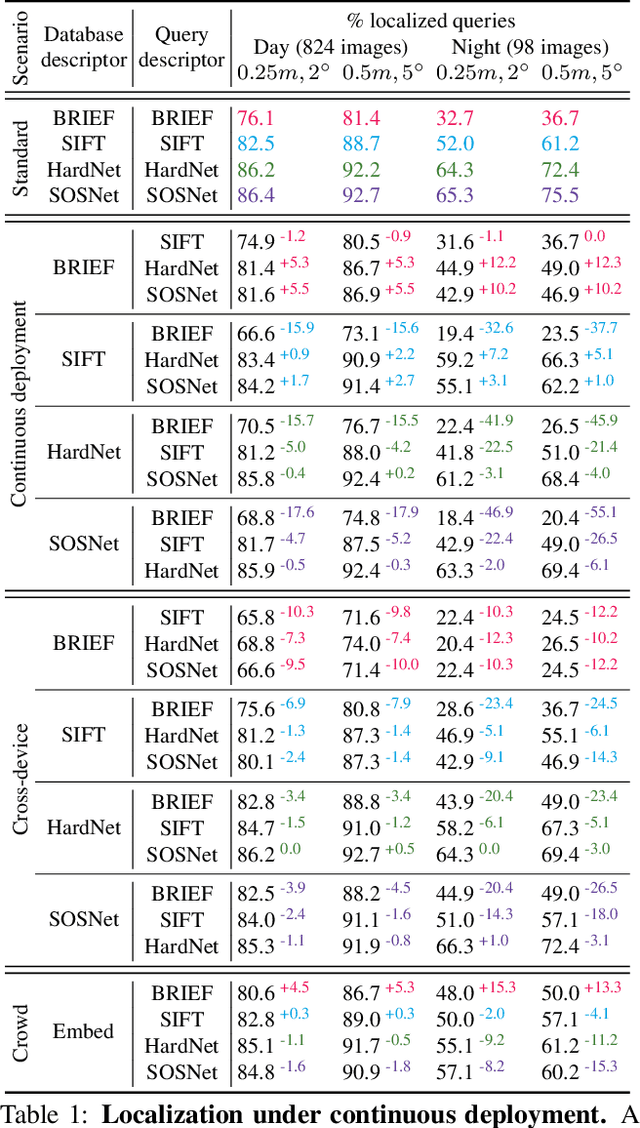
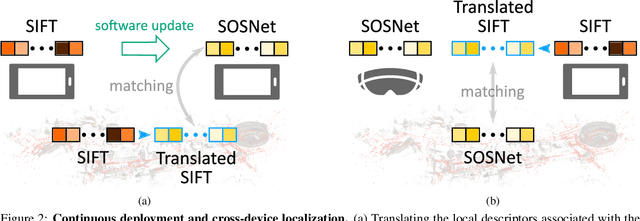
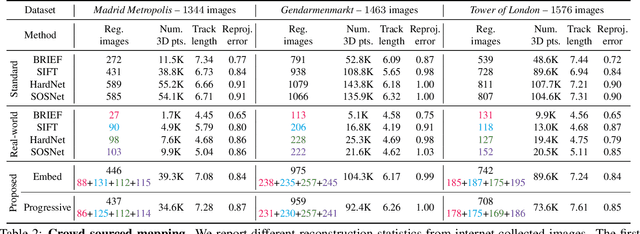
Visual localization and mapping is the key technology underlying the majority of Mixed Reality and robotics systems. Most state-of-the-art approaches rely on local features to establish correspondences between images. In this paper, we present three novel scenarios for localization and mapping which require the continuous update of feature representations and the ability to match across different feature types. While localization and mapping is a fundamental computer vision problem, the traditional setup treats it as a single-shot process using the same local image features throughout the evolution of a map. This assumes the whole process is repeated from scratch whenever the underlying features are changed. However, reiterating it is typically impossible in practice, because raw images are often not stored and re-building the maps could lead to loss of the attached digital content. To overcome the limitations of current approaches, we present the first principled solution to cross-descriptor localization and mapping. Our data-driven approach is agnostic to the feature descriptor type, has low computational requirements, and scales linearly with the number of description algorithms. Extensive experiments demonstrate the effectiveness of our approach on state-of-the-art benchmarks for a variety of handcrafted and learned features.
Sparse and Structured Visual Attention
Feb 13, 2020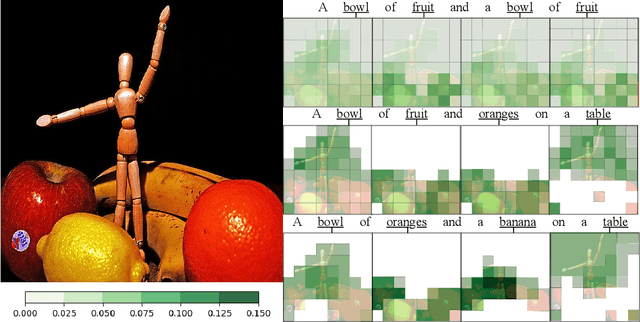

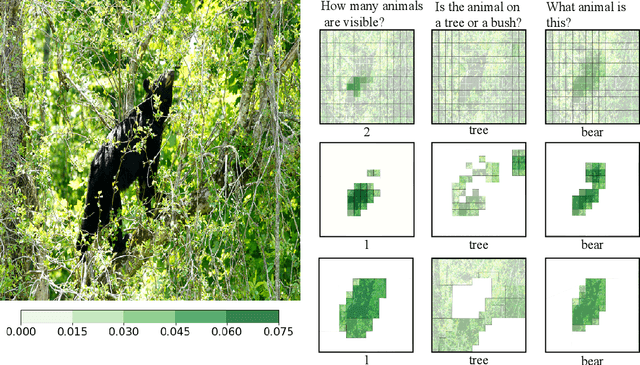

Visual attention mechanisms are widely used in multimodal tasks, such as image captioning and visual question answering (VQA). One drawback of softmax-based attention mechanisms is that they assign probability mass to all image regions, regardless of their adjacency structure and of their relevance to the text. In this paper, to better link the image structure with the text, we replace the traditional softmax attention mechanism with two alternative sparsity-promoting transformations: sparsemax, which is able to select the relevant regions only (assigning zero weight to the rest), and a newly proposed Total-Variation Sparse Attention (TVmax), which further encourages the joint selection of adjacent spatial locations. Experiments in image captioning and VQA, using both LSTM and Transformer architectures, show gains in terms of human-rated caption quality, attention relevance, and VQA accuracy, with improved interpretability.