 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SimUSR: A Simple but Strong Baseline for Unsupervised Image Super-resolution
Apr 23, 2020

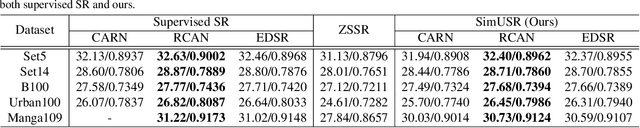
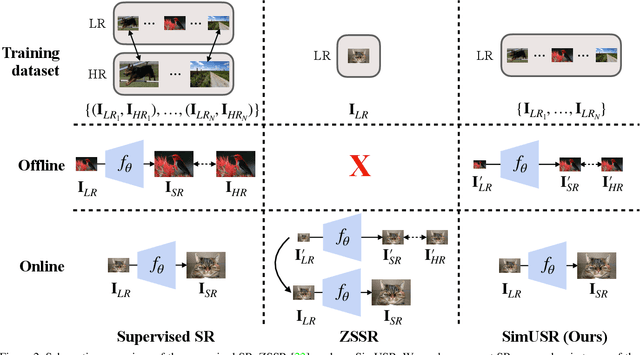
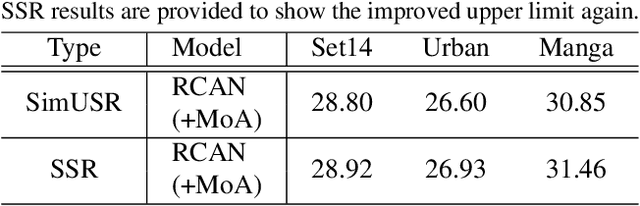
In this paper, we tackle a fully unsupervised super-resolution problem, i.e., neither paired images nor ground truth HR images. We assume that low resolution (LR) images are relatively easy to collect compared to high resolution (HR) images. By allowing multiple LR images, we build a set of pseudo pairs by denoising and downsampling LR images and cast the original unsupervised problem into a supervised learning problem but in one level lower. Though this line of study is easy to think of and thus should have been investigated prior to any complicated unsupervised methods, surprisingly, there are currently none. Even more, we show that this simple method outperforms the state-of-the-art unsupervised method with a dramatically shorter latency at runtime, and significantly reduces the gap to the HR supervised models. We submitted our method in NTIRE 2020 super-resolution challenge and won 1st in PSNR, 2nd in SSIM, and 13th in LPIPS. This simple method should be used as the baseline to beat in the future, especially when multiple LR images are allowed during the training phase. However, even in the zero-shot condition, we argue that this method can serve as a useful baseline to see the gap between supervised and unsupervised frameworks.
Ensemble Soft-Margin Softmax Loss for Image Classification
May 10, 2018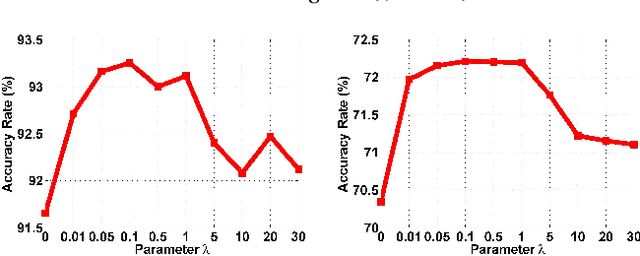
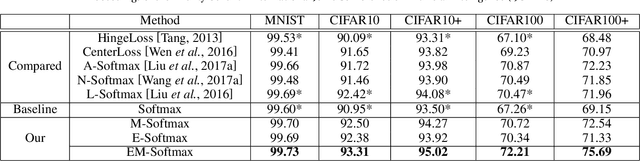
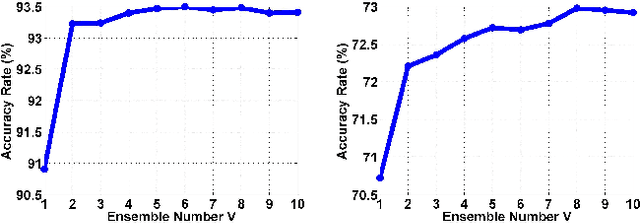

Softmax loss is arguably one of the most popular losses to train CNN models for image classification. However, recent works have exposed its limitation on feature discriminability. This paper casts a new viewpoint on the weakness of softmax loss. On the one hand, the CNN features learned using the softmax loss are often inadequately discriminative. We hence introduce a soft-margin softmax function to explicitly encourage the discrimination between different classes. On the other hand, the learned classifier of softmax loss is weak. We propose to assemble multiple these weak classifiers to a strong one, inspired by the recognition that the diversity among weak classifiers is critical to a good ensemble. To achieve the diversity, we adopt the Hilbert-Schmidt Independence Criterion (HSIC). Considering these two aspects in one framework, we design a novel loss, named as Ensemble soft-Margin Softmax (EM-Softmax). Extensive experiments on benchmark datasets are conducted to show the superiority of our design over the baseline softmax loss and several state-of-the-art alternatives.
Physical deep learning based on optimal control of dynamical systems
Dec 16, 2020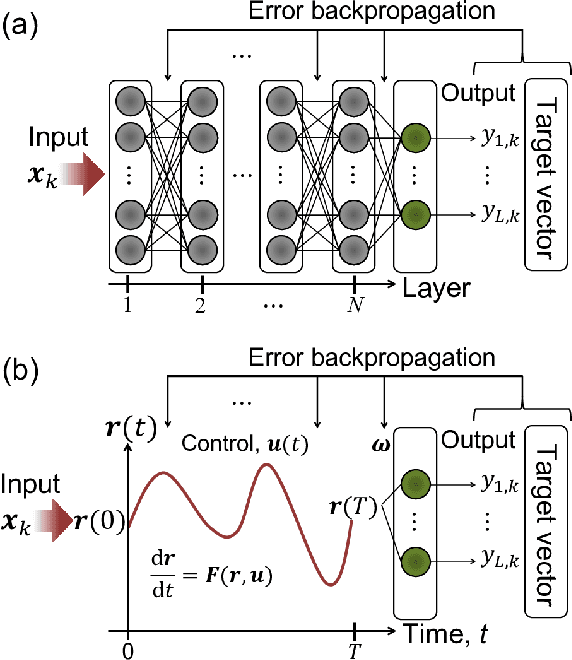
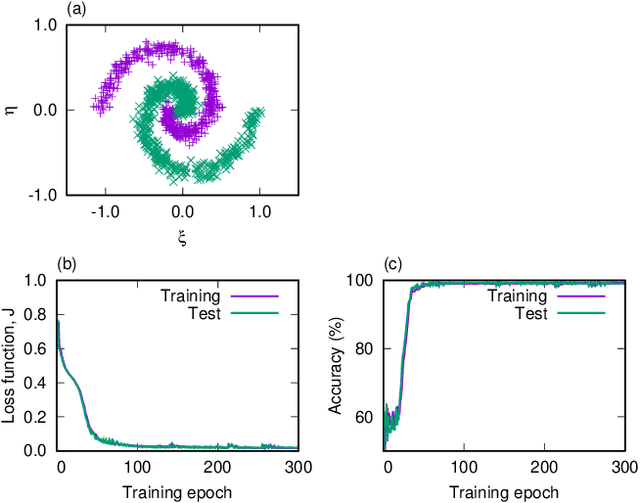
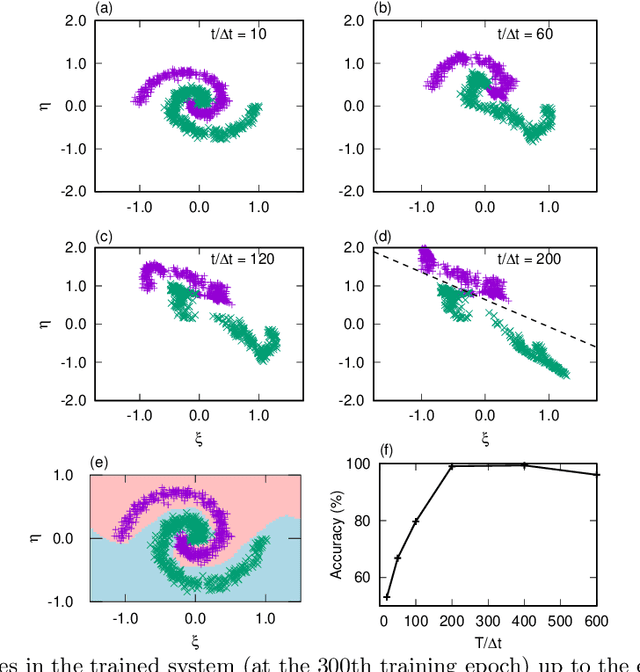
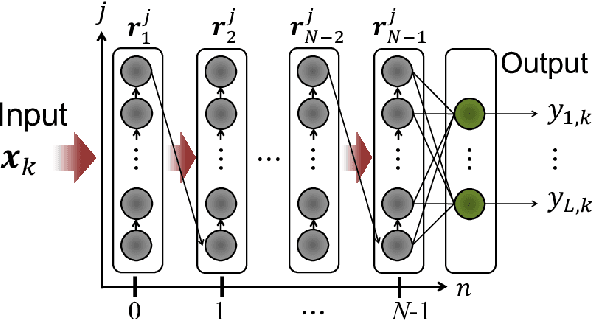
A central topic in recent artificial intelligence technologies is deep learning, which can be regarded as a multilayer feedforward neural network. An essence of deep learning is the information propagation through the layers, suggesting a connection between deep neural networks and dynamical systems, in the sense that the information propagation is explicitly modeled by the time-evolution of dynamical systems. Here, we present a pattern recognition based on optimal control of continuous-time dynamical systems, which is suitable for physical hardware implementation. The learning is based on the adjoint method to optimally control dynamical systems, and the deep (virtual) network structures based on the time evolution of the systems can be used for processing input information. As an example, we apply the dynamics-based recognition approach to an optoelectronic delay system and show that the use of the delay system enables image recognition and nonlinear classifications with only a few control signals, in contrast to conventional multilayer neural networks which require training of a large number of weight parameters. The proposed approach enables to gain insight into mechanisms of deep network processing in the framework of an optimal control problem and opens a novel pathway to realize physical computing hardware.
Achieving Sample-Efficient and Online-Training-Safe Deep Reinforcement Learning with Base Controllers
Nov 24, 2020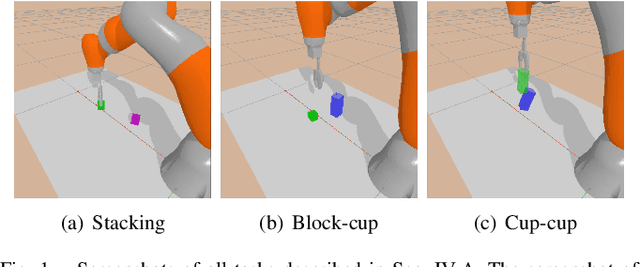
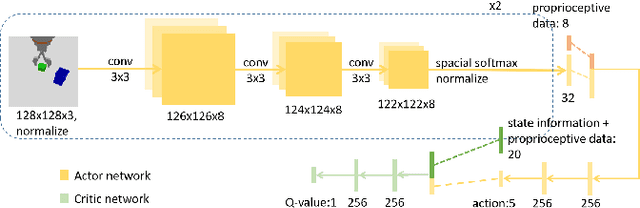
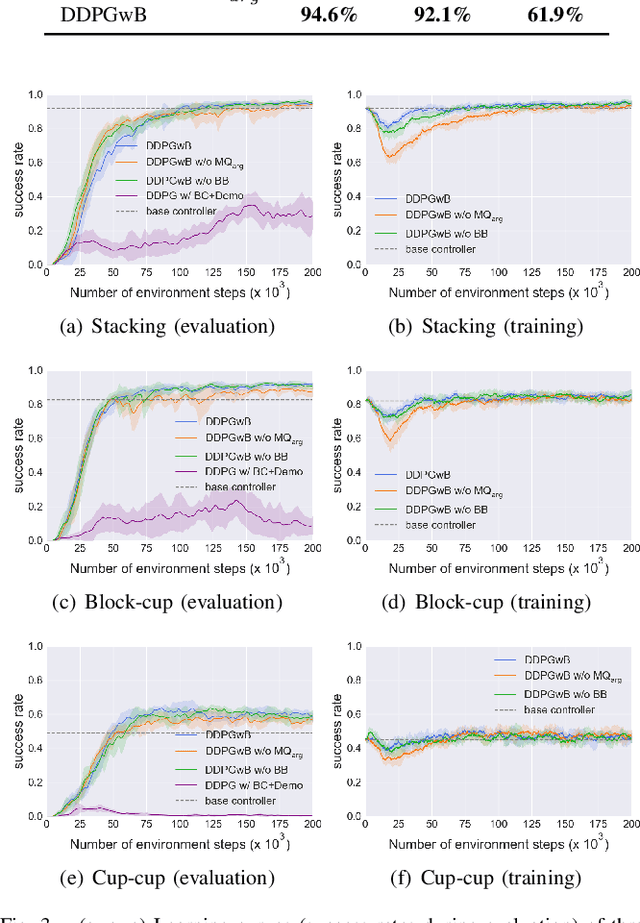
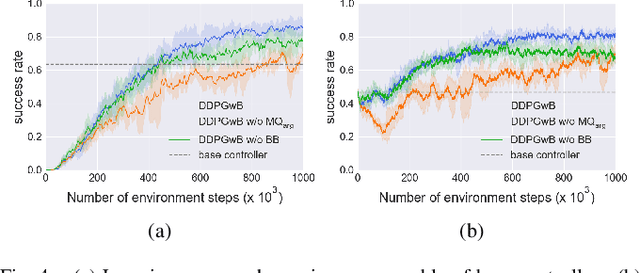
Application of Deep Reinforcement Learning (DRL) algorithms in real-world robotic tasks faces many challenges. On the one hand, reward-shaping for complex tasks is difficult and may result in sub-optimal performances. On the other hand, a sparse-reward setting renders exploration inefficient, and exploration using physical robots is of high-cost and unsafe. In this paper we propose a method of learning challenging sparse-reward tasks utilizing existing controllers. Built upon Deep Deterministic Policy Gradients (DDPG), our algorithm incorporates the controllers into stages of exploration, Q-value estimation as well as policy update. Through experiments ranging from stacking blocks to cups, we present a straightforward way of synthesizing these controllers, and show that the learned state-based or image-based policies steadily outperform them. Compared to previous works of learning from demonstrations, our method improves sample efficiency by orders of magnitude and can learn online in a safe manner. Overall, our method bears the potential of leveraging existing industrial robot manipulation systems to build more flexible and intelligent controllers.
Stabilizing Deep Tomographic Reconstruction Networks
Aug 04, 2020
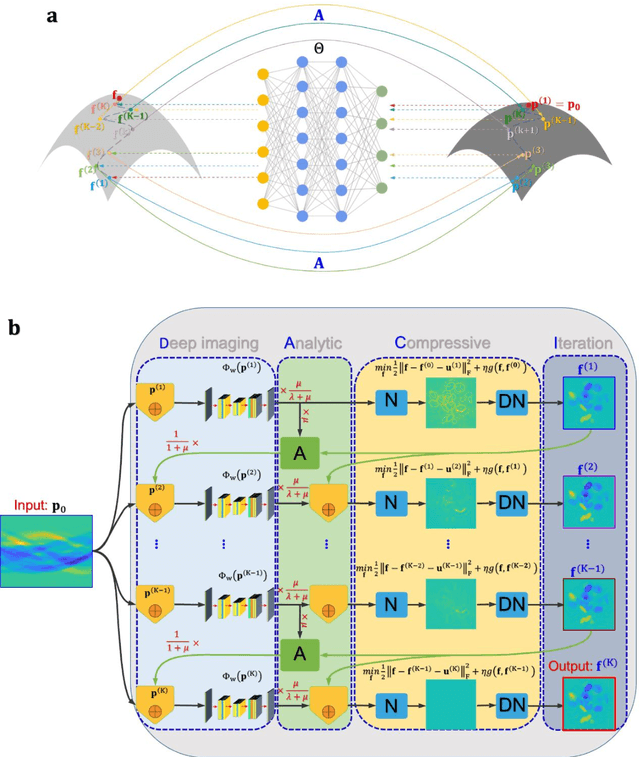
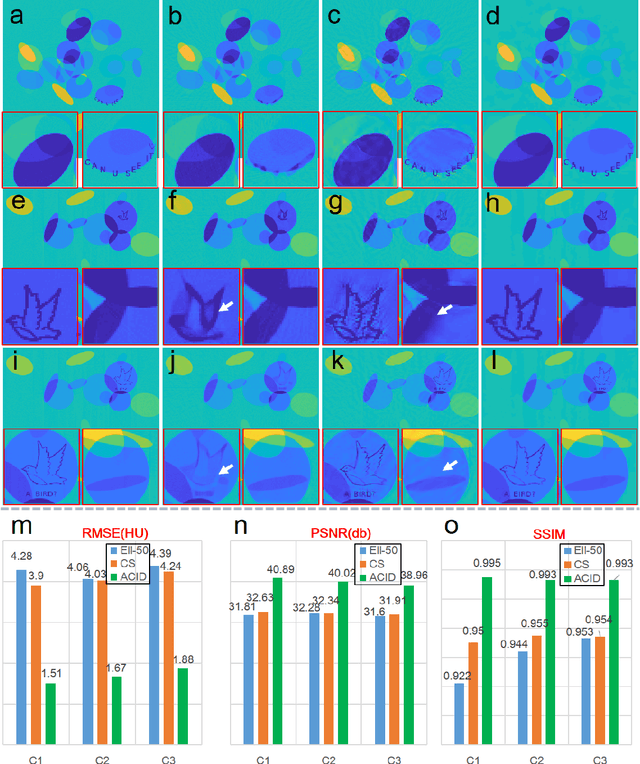
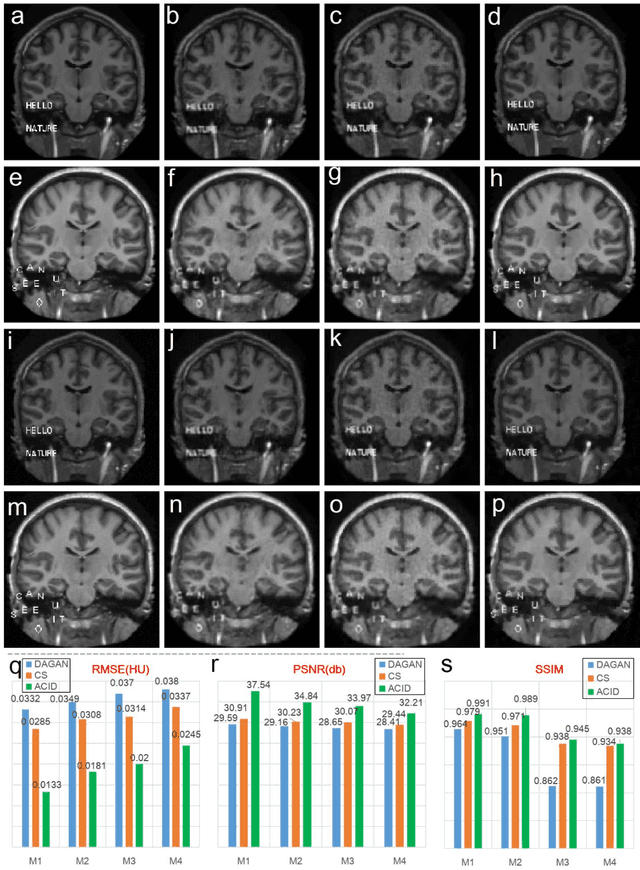
While the field of deep tomographic reconstruction has been advancing rapidly since 2016, there are constant debates and major challenges with the recently published PNAS paper on instabilities of deep learning in image reconstruction as a primary example, in which three kinds of unstable phenomena are demonstrated: (1) tiny perturbation on input generating strong output artifacts, (2) small structural features going undetected, and (3) increased input data leading to decreased performance. In this article, we show that key algorithmic ingredients of analytic inversion, compressed sensing, iterative reconstruction, and deep learning can be synergized to stabilize deep neural networks for optimal tomographic image reconstruction. With the same or similar datasets used in the PNAS paper and relative to the same state of the art compressed sensing algorithm, our proposed analytic, compressed, iterative deep (ACID) network produces superior imaging performance that are both accurate and robust with respect to noise, under adversarial attack, and as the number of input data is increased. We believe that deep tomographic reconstruction networks can be designed to produce accurate and robust results, improve clinical and other important applications, and eventually dominate the tomographic imaging field.
COVIDX: Computer-aided diagnosis of Covid-19 and its severity prediction with raw digital chest X-ray images
Dec 25, 2020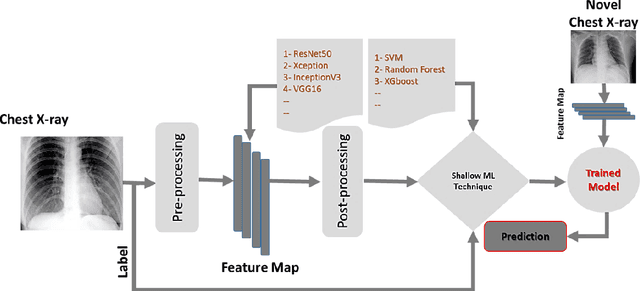
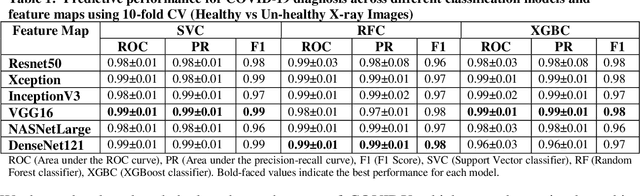
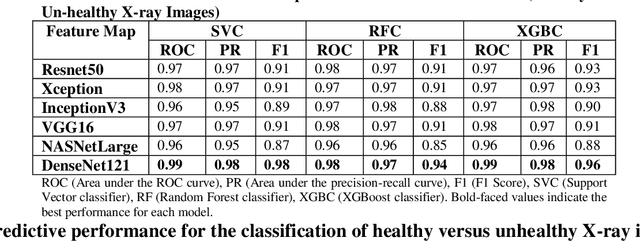
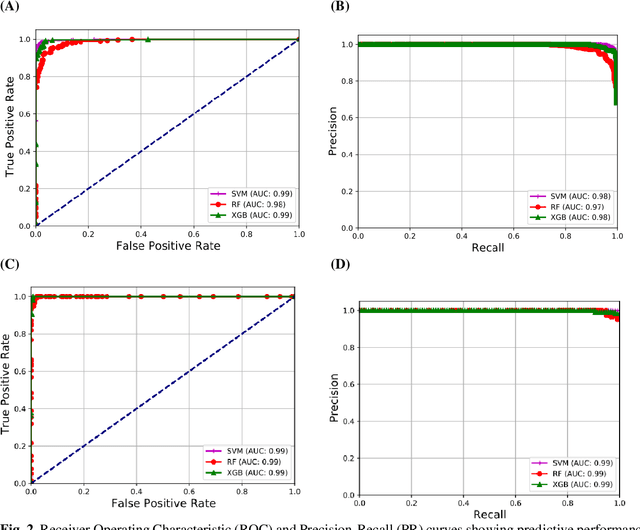
Coronavirus disease (COVID-19) is a contagious infection caused by severe acute respiratory syndrome coronavirus-2 (SARS-COV-2) and it has infected and killed millions of people across the globe. In the absence of specific drugs or vaccines for the treatment of COVID-19 and the limitation of prevailing diagnostic techniques, there is a requirement for some alternate automatic screening systems that can be used by the physicians to quickly identify and isolate the infected patients. A chest X-ray (CXR) image can be used as an alternative modality to detect and diagnose the COVID-19. In this study, we present an automatic COVID-19 diagnostic and severity prediction (COVIDX) system that uses deep feature maps from CXR images to diagnose COVID-19 and its severity prediction. The proposed system uses a three-phase classification approach (healthy vs unhealthy, COVID-19 vs Pneumonia, and COVID-19 severity) using different shallow supervised classification algorithms. We evaluated COVIDX not only through 10-fold cross2 validation and by using an external validation dataset but also in real settings by involving an experienced radiologist. In all the evaluation settings, COVIDX outperforms all the existing stateof-the-art methods designed for this purpose. We made COVIDX easily accessible through a cloud-based webserver and python code available at https://sites.google.com/view/wajidarshad/software and https://github.com/wajidarshad/covidx, respectively.
Person Re-identification Meets Image Search
Feb 07, 2015
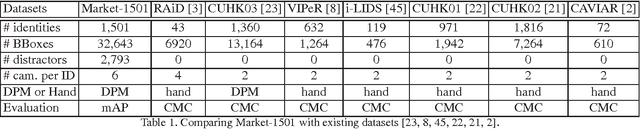
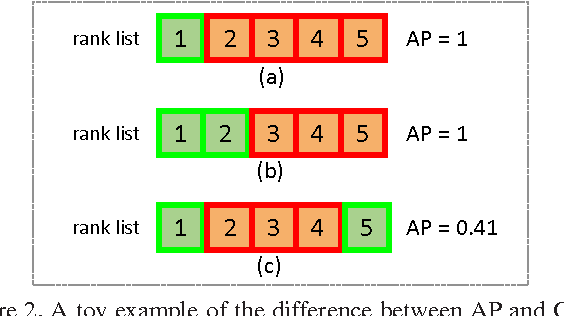
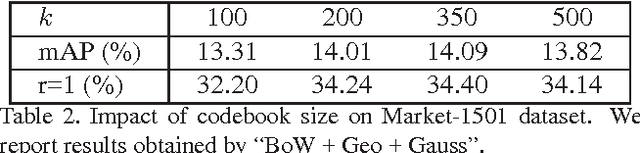
For long time, person re-identification and image search are two separately studied tasks. However, for person re-identification, the effectiveness of local features and the "query-search" mode make it well posed for image search techniques. In the light of recent advances in image search, this paper proposes to treat person re-identification as an image search problem. Specifically, this paper claims two major contributions. 1) By designing an unsupervised Bag-of-Words representation, we are devoted to bridging the gap between the two tasks by integrating techniques from image search in person re-identification. We show that our system sets up an effective yet efficient baseline that is amenable to further supervised/unsupervised improvements. 2) We contribute a new high quality dataset which uses DPM detector and includes a number of distractor images. Our dataset reaches closer to realistic settings, and new perspectives are provided. Compared with approaches that rely on feature-feature match, our method is faster by over two orders of magnitude. Moreover, on three datasets, we report competitive results compared with the state-of-the-art methods.
Adaptive binarization based on fuzzy integrals
Mar 04, 2020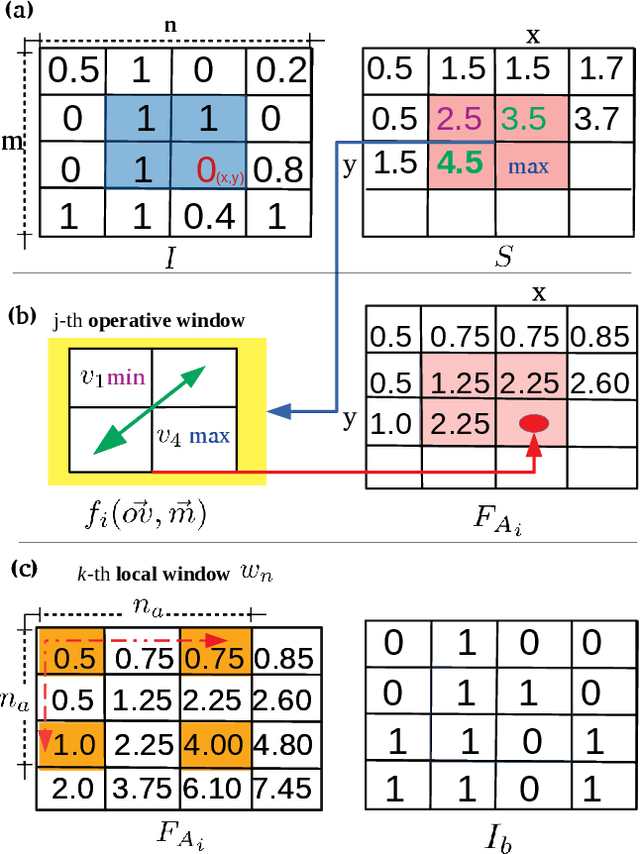

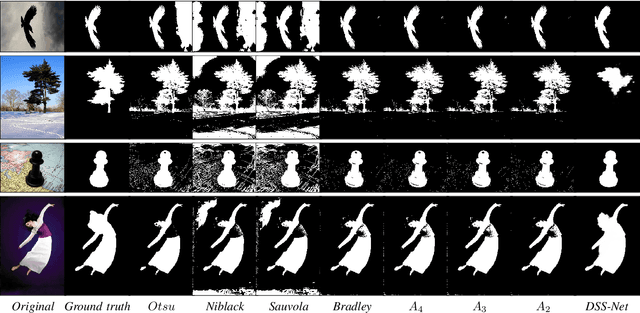
Adaptive binarization methodologies threshold the intensity of the pixels with respect to adjacent pixels exploiting the integral images. In turn, the integral images are generally computed optimally using the summed-area-table algorithm (SAT). This document presents a new adaptive binarization technique based on fuzzy integral images through an efficient design of a modified SAT for fuzzy integrals. We define this new methodology as FLAT (Fuzzy Local Adaptive Thresholding). The experimental results show that the proposed methodology have produced an image quality thresholding often better than traditional algorithms and saliency neural networks. We propose a new generalization of the Sugeno and CF 1,2 integrals to improve existing results with an efficient integral image computation. Therefore, these new generalized fuzzy integrals can be used as a tool for grayscale processing in real-time and deep-learning applications. Index Terms: Image Thresholding, Image Processing, Fuzzy Integrals, Aggregation Functions
Knowledge Distillation Methods for Efficient Unsupervised Adaptation Across Multiple Domains
Jan 18, 2021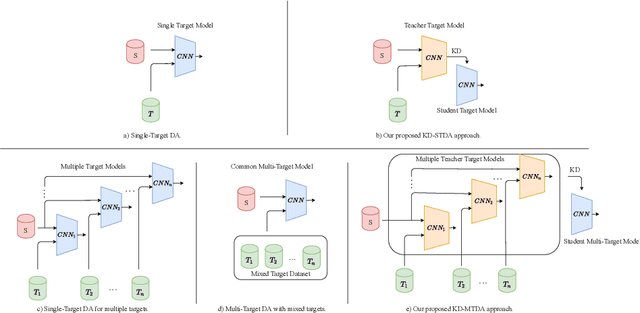
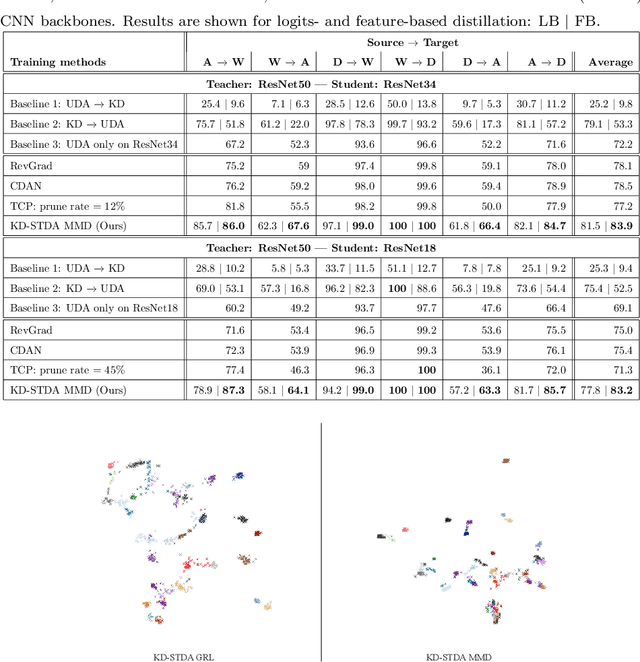
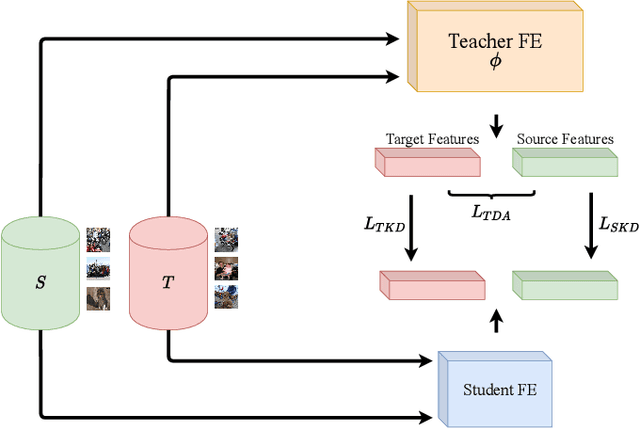
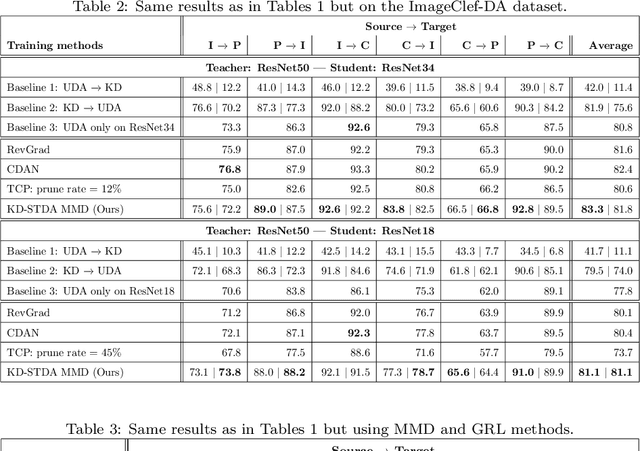
Beyond the complexity of CNNs that require training on large annotated datasets, the domain shift between design and operational data has limited the adoption of CNNs in many real-world applications. For instance, in person re-identification, videos are captured over a distributed set of cameras with non-overlapping viewpoints. The shift between the source (e.g. lab setting) and target (e.g. cameras) domains may lead to a significant decline in recognition accuracy. Additionally, state-of-the-art CNNs may not be suitable for such real-time applications given their computational requirements. Although several techniques have recently been proposed to address domain shift problems through unsupervised domain adaptation (UDA), or to accelerate/compress CNNs through knowledge distillation (KD), we seek to simultaneously adapt and compress CNNs to generalize well across multiple target domains. In this paper, we propose a progressive KD approach for unsupervised single-target DA (STDA) and multi-target DA (MTDA) of CNNs. Our method for KD-STDA adapts a CNN to a single target domain by distilling from a larger teacher CNN, trained on both target and source domain data in order to maintain its consistency with a common representation. Our proposed approach is compared against state-of-the-art methods for compression and STDA of CNNs on the Office31 and ImageClef-DA image classification datasets. It is also compared against state-of-the-art methods for MTDA on Digits, Office31, and OfficeHome. In both settings -- KD-STDA and KD-MTDA -- results indicate that our approach can achieve the highest level of accuracy across target domains, while requiring a comparable or lower CNN complexity.
PadChest: A large chest x-ray image dataset with multi-label annotated reports
Feb 07, 2019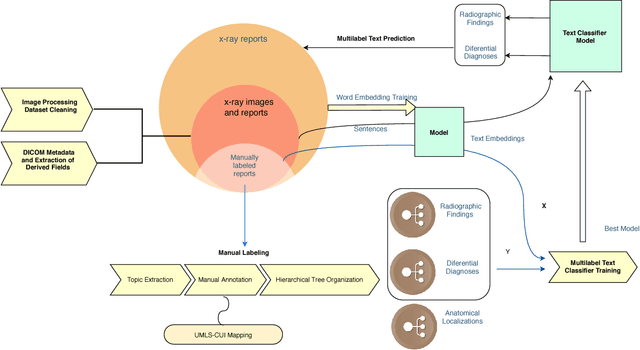

We present a labeled large-scale, high resolution chest x-ray dataset for the automated exploration of medical images along with their associated reports. This dataset includes more than 160,000 images obtained from 67,000 patients that were interpreted and reported by radiologists at Hospital San Juan Hospital (Spain) from 2009 to 2017, covering six different position views and additional information on image acquisition and patient demography. The reports were labeled with 174 different radiographic findings, 19 differential diagnoses and 104 anatomic locations organized as a hierarchical taxonomy and mapped onto standard Unified Medical Language System (UMLS) terminology. Of these reports, 27% were manually annotated by trained physicians and the remaining set was labeled using a supervised method based on a recurrent neural network with attention mechanisms. The labels generated were then validated in an independent test set achieving a 0.93 Micro-F1 score. To the best of our knowledge, this is one of the largest public chest x-ray database suitable for training supervised models concerning radiographs, and the first to contain radiographic reports in Spanish. The PadChest dataset can be downloaded from http://bimcv.cipf.es/bimcv-projects/padchest/.