 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Melanoma Detection using Adversarial Training and Deep Transfer Learning
Apr 14, 2020
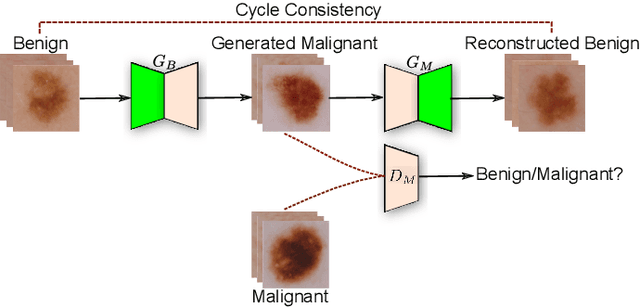
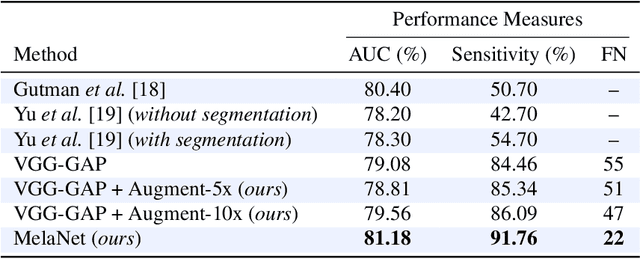

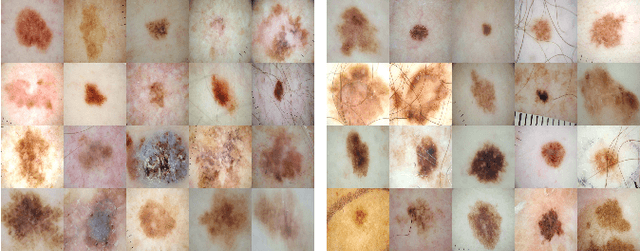
Skin lesion datasets consist predominantly of normal samples with only a small percentage of abnormal ones, giving rise to the class imbalance problem. Also, skin lesion images are largely similar in overall appearance owing to the low inter-class variability. In this paper, we propose a two-stage framework for automatic classification of skin lesion images using adversarial training and transfer learning toward melanoma detection. In the first stage, we leverage the inter-class variation of the data distribution for the task of conditional image synthesis by learning the inter-class mapping and synthesizing under-represented class samples from the over-represented ones using unpaired image-to-image translation. In the second stage, we train a deep convolutional neural network for skin lesion classification using the original training set combined with the newly synthesized under-represented class samples. The training of this classifier is carried out by minimizing the focal loss function, which assists the model in learning from hard examples, while down-weighting the easy ones. Experiments conducted on a dermatology image benchmark demonstrate the superiority of our proposed approach over several standard baseline methods, achieving significant performance improvements. Interestingly, we show through feature visualization and analysis that our method leads to context based lesion assessment that can reach an expert dermatologist level.
Siamese Network of Deep Fisher-Vector Descriptors for Image Retrieval
Feb 01, 2017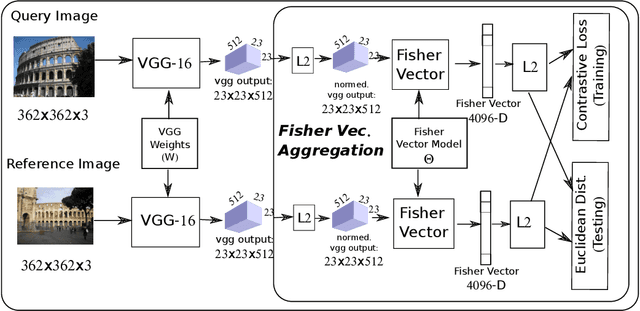
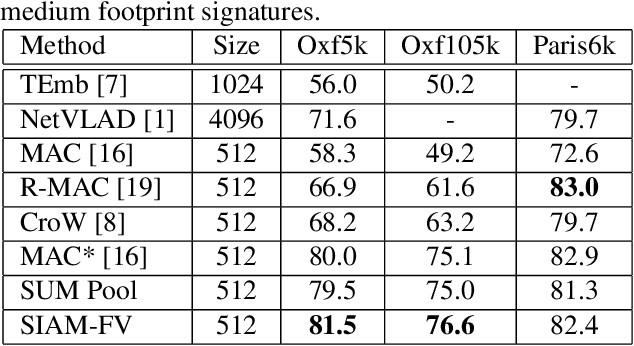
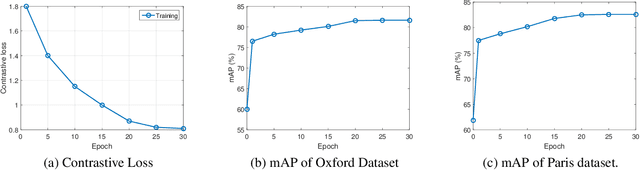
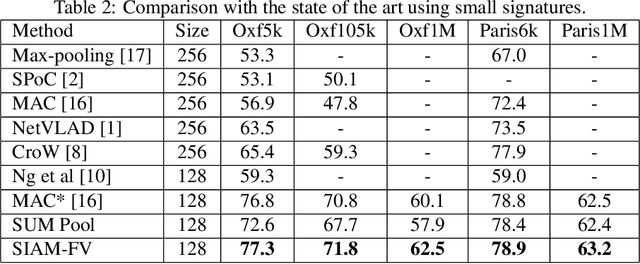
This paper addresses the problem of large scale image retrieval, with the aim of accurately ranking the similarity of a large number of images to a given query image. To achieve this, we propose a novel Siamese network. This network consists of two computational strands, each comprising of a CNN component followed by a Fisher vector component. The CNN component produces dense, deep convolutional descriptors that are then aggregated by the Fisher Vector method. Crucially, we propose to simultaneously learn both the CNN filter weights and Fisher Vector model parameters. This allows us to account for the evolving distribution of deep descriptors over the course of the learning process. We show that the proposed approach gives significant improvements over the state-of-the-art methods on the Oxford and Paris image retrieval datasets. Additionally, we provide a baseline performance measure for both these datasets with the inclusion of 1 million distractors.
Sparse Signal Models for Data Augmentation in Deep Learning ATR
Dec 16, 2020


Automatic Target Recognition (ATR) algorithms classify a given Synthetic Aperture Radar (SAR) image into one of the known target classes using a set of training images available for each class. Recently, learning methods have shown to achieve state-of-the-art classification accuracy if abundant training data is available, sampled uniformly over the classes, and their poses. In this paper, we consider the task of ATR with a limited set of training images. We propose a data augmentation approach to incorporate domain knowledge and improve the generalization power of a data-intensive learning algorithm, such as a Convolutional neural network (CNN). The proposed data augmentation method employs a limited persistence sparse modeling approach, capitalizing on commonly observed characteristics of wide-angle synthetic aperture radar (SAR) imagery. Specifically, we exploit the sparsity of the scattering centers in the spatial domain and the smoothly-varying structure of the scattering coefficients in the azimuthal domain to solve the ill-posed problem of over-parametrized model fitting. Using this estimated model, we synthesize new images at poses and sub-pixel translations not available in the given data to augment CNN's training data. The experimental results show that for the training data starved region, the proposed method provides a significant gain in the resulting ATR algorithm's generalization performance.
SqueezeSegV3: Spatially-Adaptive Convolution for Efficient Point-Cloud Segmentation
Apr 03, 2020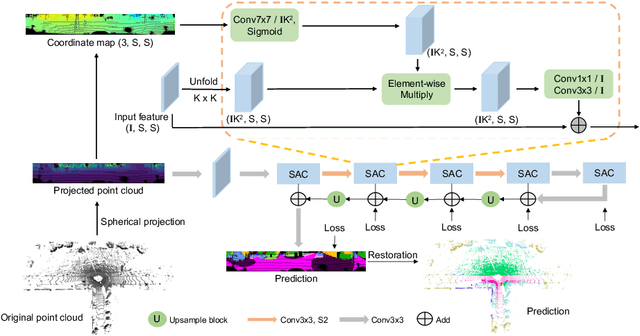
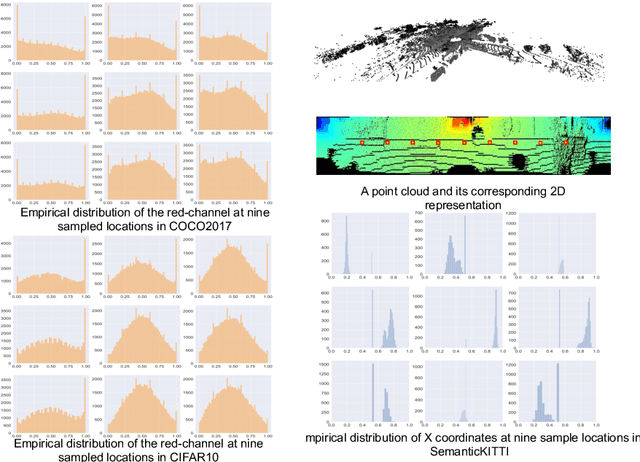
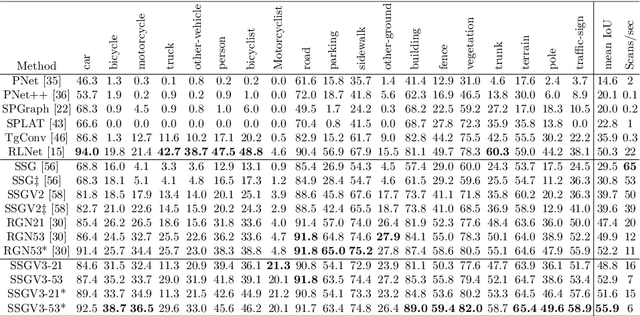
LiDAR point-cloud segmentation is an important problem for many applications. For large-scale point cloud segmentation, the \textit{de facto} method is to project a 3D point cloud to get a 2D LiDAR image and use convolutions to process it. Despite the similarity between regular RGB and LiDAR images, we discover that the feature distribution of LiDAR images changes drastically at different image locations. Using standard convolutions to process such LiDAR images is problematic, as convolution filters pick up local features that are only active in specific regions in the image. As a result, the capacity of the network is under-utilized and the segmentation performance decreases. To fix this, we propose Spatially-Adaptive Convolution (SAC) to adopt different filters for different locations according to the input image. SAC can be computed efficiently since it can be implemented as a series of element-wise multiplications, im2col, and standard convolution. It is a general framework such that several previous methods can be seen as special cases of SAC. Using SAC, we build SqueezeSegV3 for LiDAR point-cloud segmentation and outperform all previous published methods by at least 3.7% mIoU on the SemanticKITTI benchmark with comparable inference speed.
Detection of data drift and outliers affecting machine learning model performance over time
Dec 16, 2020

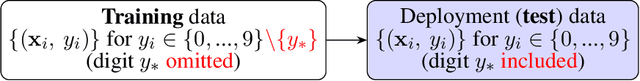
A trained ML model is deployed on another `test' dataset where target feature values (labels) are unknown. Drift is distribution change between the training and deployment data, which is concerning if model performance changes. For a cat/dog image classifier, for instance, drift during deployment could be rabbit images (new class) or cat/dog images with changed characteristics (change in distribution). We wish to detect these changes but can't measure accuracy without deployment data labels. We instead detect drift indirectly by nonparametrically testing the distribution of model prediction confidence for changes. This generalizes our method and sidesteps domain-specific feature representation. We address important statistical issues, particularly Type-1 error control in sequential testing, using Change Point Models (CPMs; see Adams and Ross 2012). We also use nonparametric outlier methods to show the user suspicious observations for model diagnosis, since the before/after change confidence distributions overlap significantly. In experiments to demonstrate robustness, we train on a subset of MNIST digit classes, then insert drift (e.g., unseen digit class) in deployment data in various settings (gradual/sudden changes in the drift proportion). A novel loss function is introduced to compare the performance (detection delay, Type-1 and 2 errors) of a drift detector under different levels of drift class contamination.
Humble Teacher and Eager Student: Dual Network Learning for Semi-supervised 2D Human Pose Estimation
Nov 25, 2020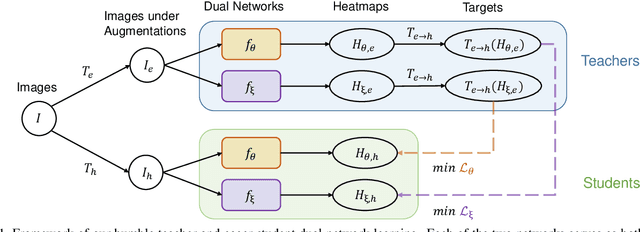
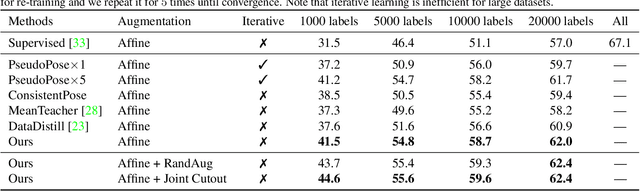

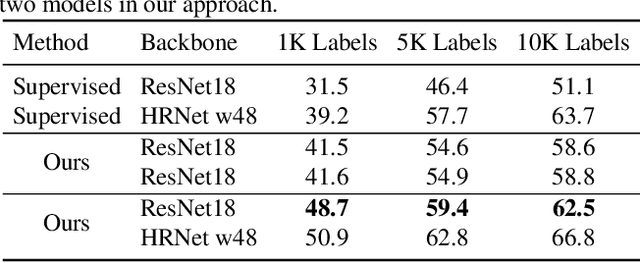
Semi-supervised learning aims to boost the accuracy of a model by exploring unlabeled images. The state-of-the-art methods are consistency-based which learn about unlabeled images by encouraging the model to give consistent predictions for images under different augmentations. However, when applied to pose estimation, the methods degenerate and predict every pixel in unlabeled images as background. This is because contradictory predictions are gradually pushed to the background class due to highly imbalanced class distribution. But this is not an issue in supervised learning because it has accurate labels. This inspires us to stabilize the training by obtaining reliable pseudo labels. Specifically, we learn two networks to mutually teach each other. In particular, for each image, we compose an easy-hard pair by applying different augmentations and feed them to both networks. The more reliable predictions on easy images in each network are used to teach the other network to learn about the corresponding hard images. The approach successfully avoids degeneration and achieves promising results on public datasets. The source code will be released.
GETNET: A General End-to-end Two-dimensional CNN Framework for Hyperspectral Image Change Detection
May 05, 2019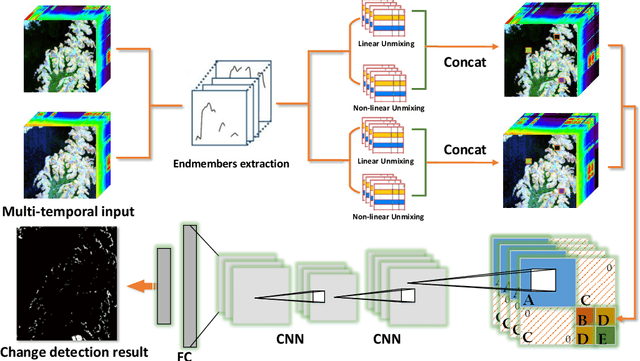

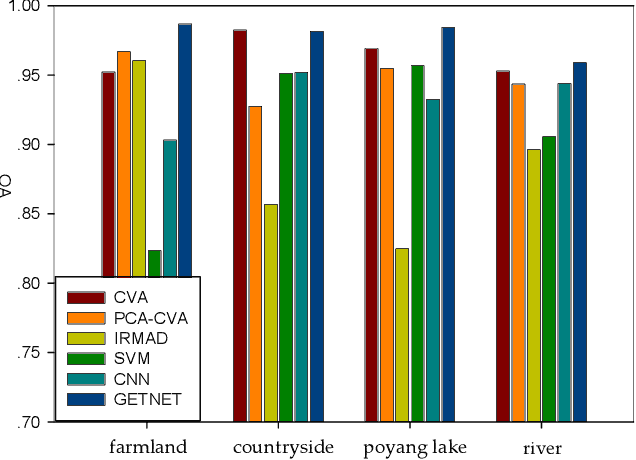
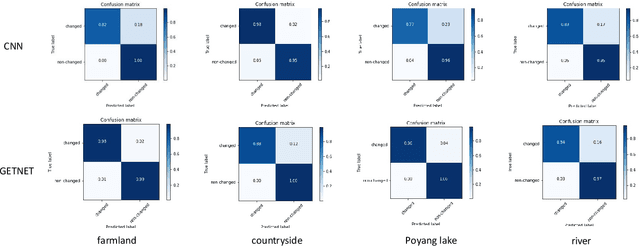
Change detection (CD) is an important application of remote sensing, which provides timely change information about large-scale Earth surface. With the emergence of hyperspectral imagery, CD technology has been greatly promoted, as hyperspectral data with the highspectral resolution are capable of detecting finer changes than using the traditional multispectral imagery. Nevertheless, the high dimension of hyperspectral data makes it difficult to implement traditional CD algorithms. Besides, endmember abundance information at subpixel level is often not fully utilized. In order to better handle high dimension problem and explore abundance information, this paper presents a General End-to-end Two-dimensional CNN (GETNET) framework for hyperspectral image change detection (HSI-CD). The main contributions of this work are threefold: 1) Mixed-affinity matrix that integrates subpixel representation is introduced to mine more cross-channel gradient features and fuse multi-source information; 2) 2-D CNN is designed to learn the discriminative features effectively from multi-source data at a higher level and enhance the generalization ability of the proposed CD algorithm; 3) A new HSI-CD data set is designed for the objective comparison of different methods. Experimental results on real hyperspectral data sets demonstrate the proposed method outperforms most of the state-of-the-arts.
Are Visual Explanations Useful? A Case Study in Model-in-the-Loop Prediction
Jul 23, 2020
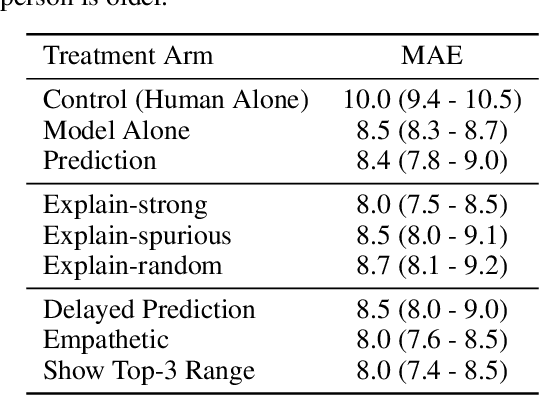

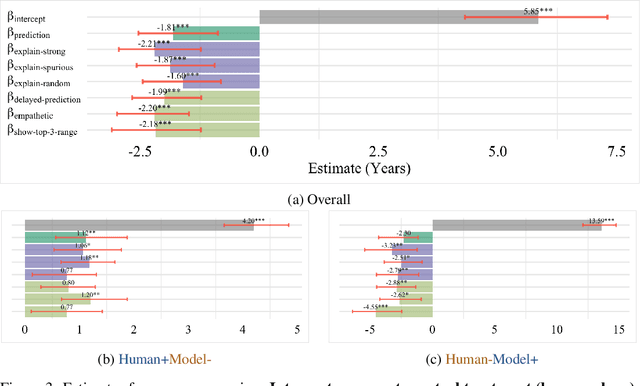
We present a randomized controlled trial for a model-in-the-loop regression task, with the goal of measuring the extent to which (1) good explanations of model predictions increase human accuracy, and (2) faulty explanations decrease human trust in the model. We study explanations based on visual saliency in an image-based age prediction task for which humans and learned models are individually capable but not highly proficient and frequently disagree. Our experimental design separates model quality from explanation quality, and makes it possible to compare treatments involving a variety of explanations of varying levels of quality. We find that presenting model predictions improves human accuracy. However, visual explanations of various kinds fail to significantly alter human accuracy or trust in the model - regardless of whether explanations characterize an accurate model, an inaccurate one, or are generated randomly and independently of the input image. These findings suggest the need for greater evaluation of explanations in downstream decision making tasks, better design-based tools for presenting explanations to users, and better approaches for generating explanations.
Building and Using Personal Knowledge Graph to Improve Suicidal Ideation Detection on Social Media
Dec 16, 2020
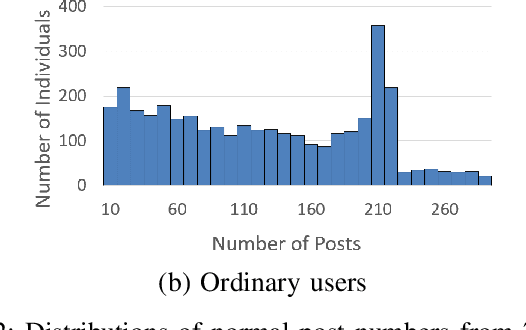
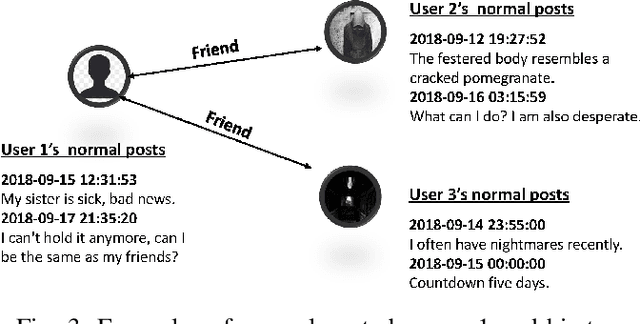
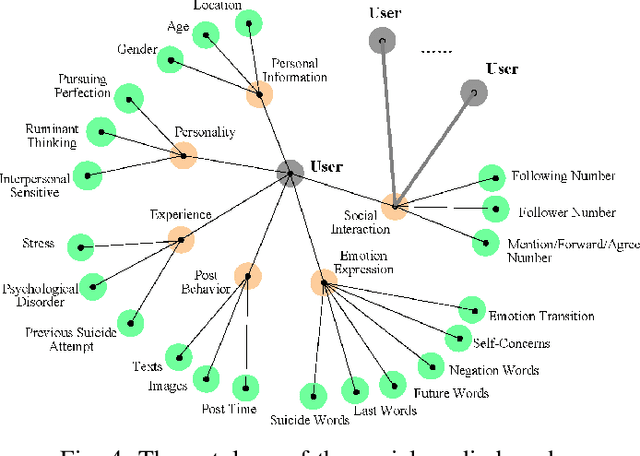
A large number of individuals are suffering from suicidal ideation in the world. There are a number of causes behind why an individual might suffer from suicidal ideation. As the most popular platform for self-expression, emotion release, and personal interaction, individuals may exhibit a number of symptoms of suicidal ideation on social media. Nevertheless, challenges from both data and knowledge aspects remain as obstacles, constraining the social media-based detection performance. Data implicitness and sparsity make it difficult to discover the inner true intentions of individuals based on their posts. Inspired by psychological studies, we build and unify a high-level suicide-oriented knowledge graph with deep neural networks for suicidal ideation detection on social media. We further design a two-layered attention mechanism to explicitly reason and establish key risk factors to individual's suicidal ideation. The performance study on microblog and Reddit shows that: 1) with the constructed personal knowledge graph, the social media-based suicidal ideation detection can achieve over 93% accuracy; and 2) among the six categories of personal factors, post, personality, and experience are the top-3 key indicators. Under these categories, posted text, stress level, stress duration, posted image, and ruminant thinking contribute to one's suicidal ideation detection.
An Analysis of Deep Object Detectors For Diver Detection
Nov 25, 2020
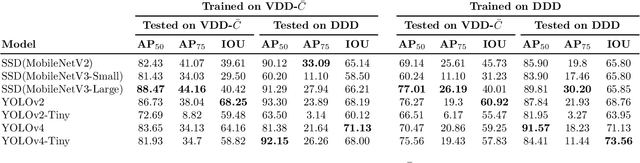

With the end goal of selecting and using diver detection models to support human-robot collaboration capabilities such as diver following, we thoroughly analyze a large set of deep neural networks for diver detection. We begin by producing a dataset of approximately 105,000 annotated images of divers sourced from videos -- one of the largest and most varied diver detection datasets ever created. Using this dataset, we train a variety of state-of-the-art deep neural networks for object detection, including SSD with Mobilenet, Faster R-CNN, and YOLO. Along with these single-frame detectors, we also train networks designed for detection of objects in a video stream, using temporal information as well as single-frame image information. We evaluate these networks on typical accuracy and efficiency metrics, as well as on the temporal stability of their detections. Finally, we analyze the failures of these detectors, pointing out the most common scenarios of failure. Based on our results, we recommend SSDs or Tiny-YOLOv4 for real-time applications on robots and recommend further investigation of video object detection methods.