 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning-based Image Reconstruction via Parallel Proximal Algorithm
Jan 29, 2018

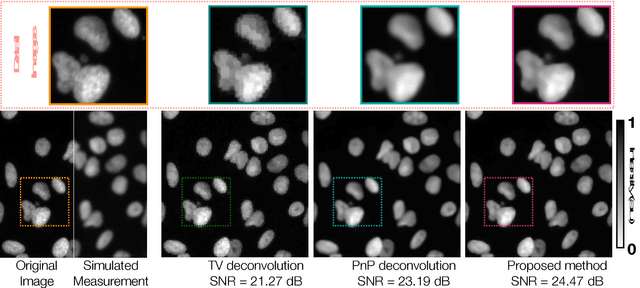
In the past decade, sparsity-driven regularization has led to advancement of image reconstruction algorithms. Traditionally, such regularizers rely on analytical models of sparsity (e.g. total variation (TV)). However, more recent methods are increasingly centered around data-driven arguments inspired by deep learning. In this letter, we propose to generalize TV regularization by replacing the l1-penalty with an alternative prior that is trainable. Specifically, our method learns the prior via extending the recently proposed fast parallel proximal algorithm (FPPA) to incorporate data-adaptive proximal operators. The proposed framework does not require additional inner iterations for evaluating the proximal mappings of the corresponding learned prior. Moreover, our formalism ensures that the training and reconstruction processes share the same algorithmic structure, making the end-to-end implementation intuitive. As an example, we demonstrate our algorithm on the problem of deconvolution in a fluorescence microscope.
Phase Retrieval with Holography and Untrained Priors: Tackling the Challenges of Low-Photon Nanoscale Imaging
Dec 15, 2020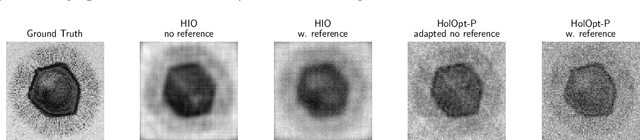


Phase retrieval is the inverse problem of recovering a signal from magnitude-only Fourier measurements, and underlies numerous imaging modalities, such as Coherent Diffraction Imaging (CDI). A variant of this setup, known as holography, includes a reference object that is placed adjacent to the specimen of interest before measurements are collected. The resulting inverse problem, known as holographic phase retrieval, is well-known to have improved problem conditioning relative to the original. This innovation, i.e. Holographic CDI, becomes crucial at the nanoscale, where imaging specimens such as viruses, proteins, and crystals require low-photon measurements. This data is highly corrupted by Poisson shot noise, and often lacks low-frequency content as well. In this work, we introduce a dataset-free deep learning framework for holographic phase retrieval adapted to these challenges. The key ingredients of our approach are the explicit and flexible incorporation of the physical forward model into an automatic differentiation procedure, the Poisson log-likelihood objective function, and an optional untrained deep image prior. We perform extensive evaluation under realistic conditions. Compared to competing classical methods, our method recovers signal from higher noise levels and is more resilient to suboptimal reference design, as well as to large missing regions of low frequencies in the observations. To the best of our knowledge, this is the first work to consider a dataset-free machine learning approach for holographic phase retrieval.
Adaptive Weighted Discriminator for Training Generative Adversarial Networks
Dec 05, 2020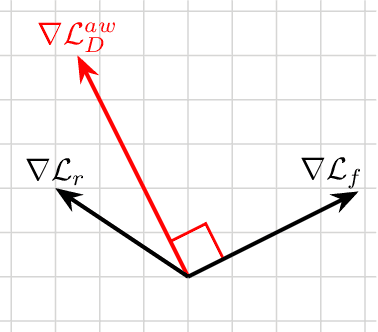
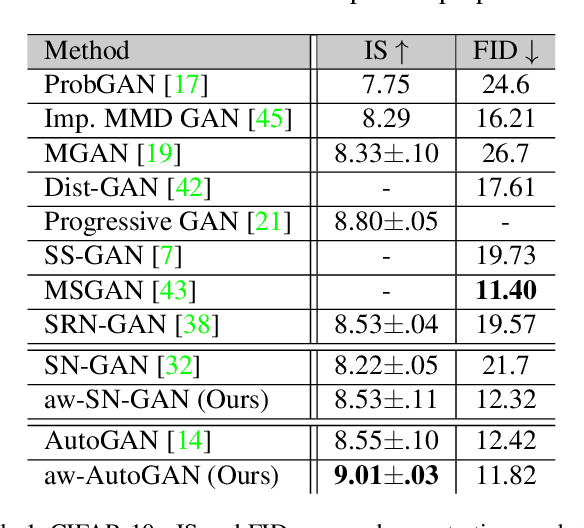

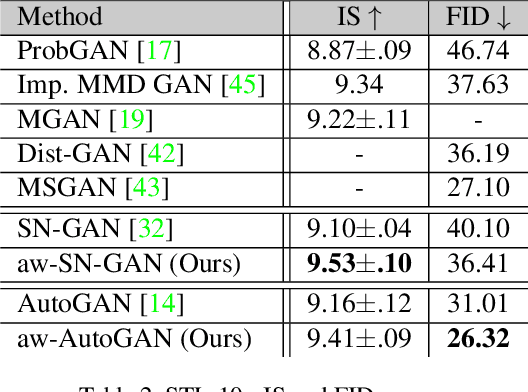
Generative adversarial network (GAN) has become one of the most important neural network models for classical unsupervised machine learning. A variety of discriminator loss functions have been developed to train GAN's discriminators and they all have a common structure: a sum of real and fake losses that only depends on the actual and generated data respectively. One challenge associated with an equally weighted sum of two losses is that the training may benefit one loss but harm the other, which we show causes instability and mode collapse. In this paper, we introduce a new family of discriminator loss functions that adopts a weighted sum of real and fake parts, which we call adaptive weighted loss functions or aw-loss functions. Using the gradients of the real and fake parts of the loss, we can adaptively choose weights to train a discriminator in the direction that benefits the GAN's stability. Our method can be potentially applied to any discriminator model with a loss that is a sum of the real and fake parts. Experiments validated the effectiveness of our loss functions on an unconditional image generation task, improving the baseline results by a significant margin on CIFAR-10, STL-10, and CIFAR-100 datasets in Inception Scores and FID.
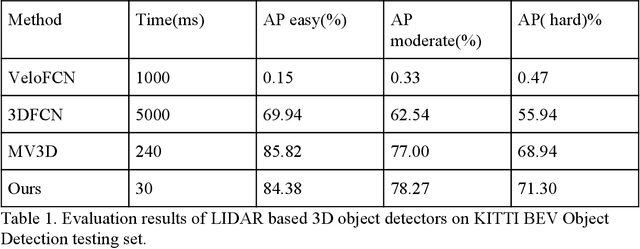
Learning to Detect 3D Objects from Point Clouds in Real Time
May 09, 2020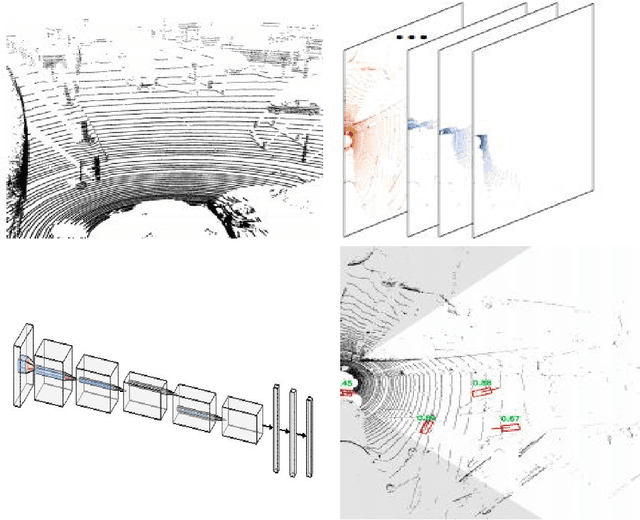
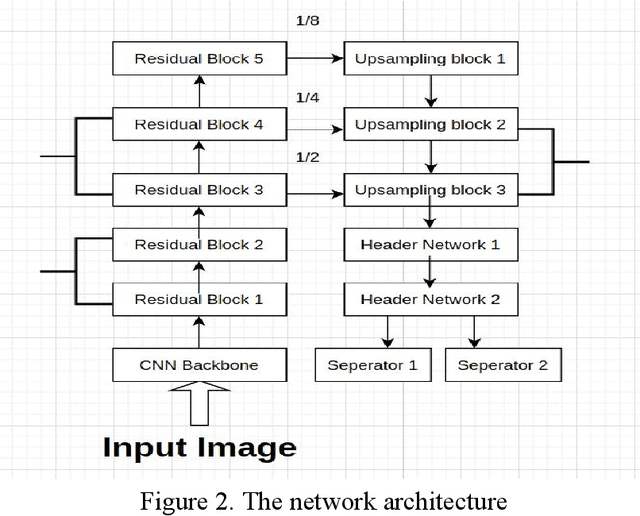
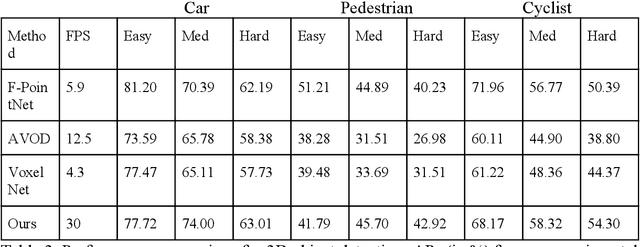
In this paper, we present a combined architecture using dilated and transposed convolutional neural networks for accurate and efficient semantic image segmentation. In contrast to previous fully convolutional neural networks such as FCN with almost all computation shared on the entire image, we propose an additional architecture which we have named as dilated - transposed fully convolutional neural networks. To achieve this goal, we used dilated convolutional layers in downsampling and transposed convolutional layers in upsampling layers. We have used skip connections in between the blocks formed by convolutions and max pooling layers. This type of architecture has been used successfully in the past for image classification using residual network. In addition we also found selu activation function instead of relu to give better results on the test set images. We reason this is the due to avoiding the model getting stuck in a local minimum, thus experiencing a famous vanishing gradient problem in case with relu activation function. Meanwhile, our result achieved pixel wise class accuracy of 88% on the test set and mean Intersection Over Union(IOU) value of 53.5 which is better than the state of the art using the previous fully convolutional neural networks.
Unveiling Real-Life Effects of Online Photo Sharing
Dec 24, 2020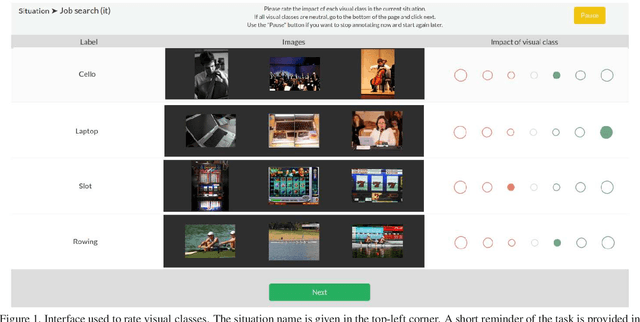

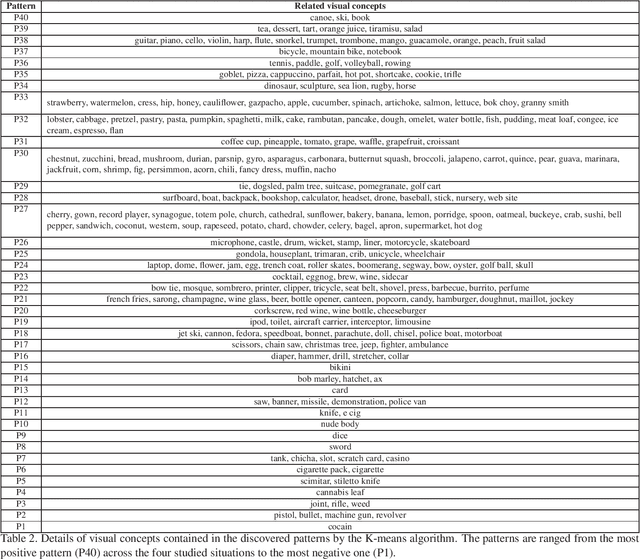
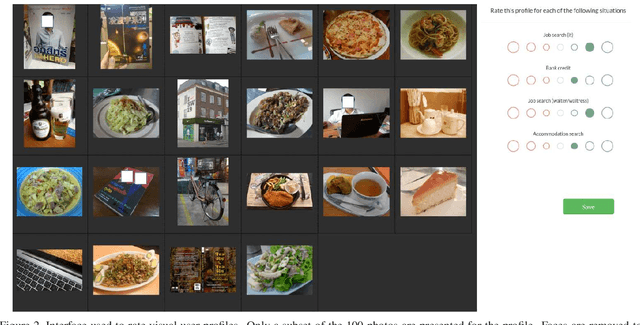
Social networks give free access to their services in exchange for the right to exploit their users' data. Data sharing is done in an initial context which is chosen by the users. However, data are used by social networks and third parties in different contexts which are often not transparent. We propose a new approach which unveils potential effects of data sharing in impactful real-life situations. Focus is put on visual content because of its strong influence in shaping online user profiles. The approach relies on three components: (1) a set of concepts with associated situation impact ratings obtained by crowdsourcing, (2) a corresponding set of object detectors used to analyze users' photos and (3) a ground truth dataset made of 500 visual user profiles which are manually rated for each situation. These components are combined in LERVUP, a method which learns to rate visual user profiles in each situation. LERVUP exploits a new image descriptor which aggregates concept ratings and object detections at user level. It also uses an attention mechanism to boost the detections of highly-rated concepts to prevent them from being overwhelmed by low-rated ones. Performance is evaluated per situation by measuring the correlation between the automatic ranking of profile ratings and a manual ground truth. Results indicate that LERVUP is effective since a strong correlation of the two rankings is obtained. This finding indicates that providing meaningful automatic situation-related feedback about the effects of data sharing is feasible.
Dynamic Group Convolution for Accelerating Convolutional Neural Networks
Jul 10, 2020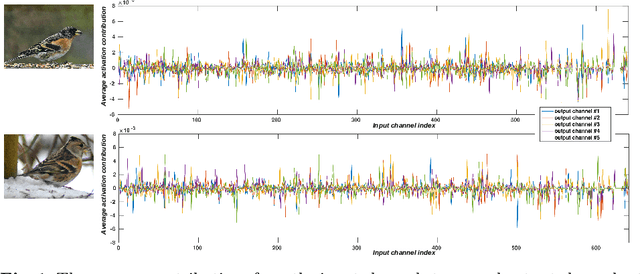
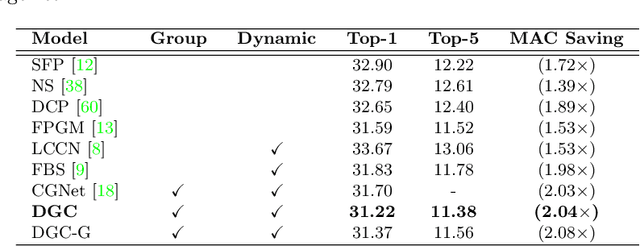
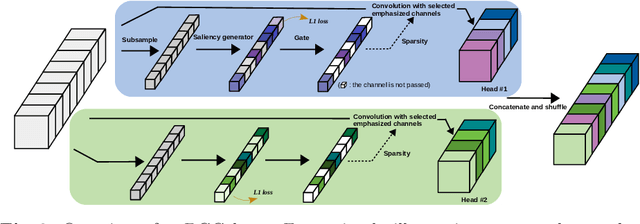
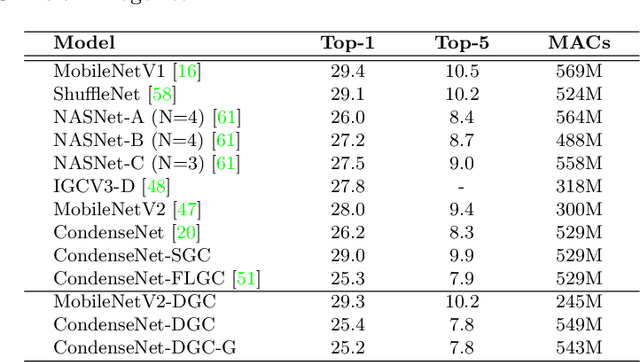
Replacing normal convolutions with group convolutions can significantly increase the computational efficiency of modern deep convolutional networks, which has been widely adopted in compact network architecture designs. However, existing group convolutions undermine the original network structures by cutting off some connections permanently resulting in significant accuracy degradation. In this paper, we propose dynamic group convolution (DGC) that adaptively selects which part of input channels to be connected within each group for individual samples on the fly. Specifically, we equip each group with a small feature selector to automatically select the most important input channels conditioned on the input images. Multiple groups can adaptively capture abundant and complementary visual/semantic features for each input image. The DGC preserves the original network structure and has similar computational efficiency as the conventional group convolution simultaneously. Extensive experiments on multiple image classification benchmarks including CIFAR-10, CIFAR-100 and ImageNet demonstrate its superiority over the existing group convolution techniques and dynamic execution methods. The code is available at https://github.com/zhuogege1943/dgc.
Utilizing Large Scale Vision and Text Datasets for Image Segmentation from Referring Expressions
Aug 30, 2016
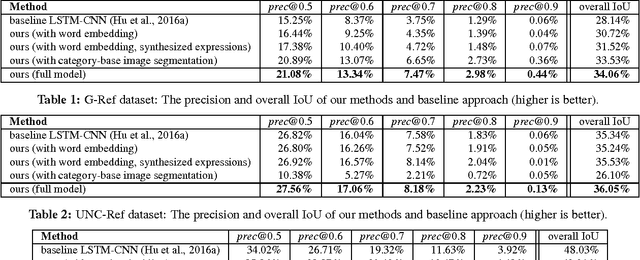
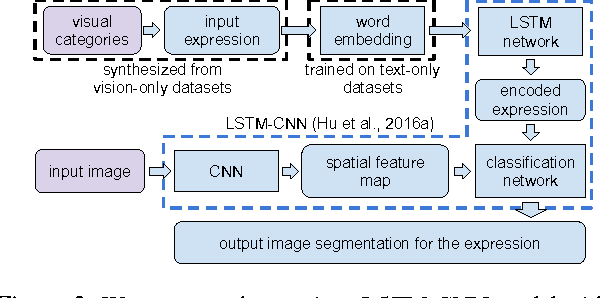
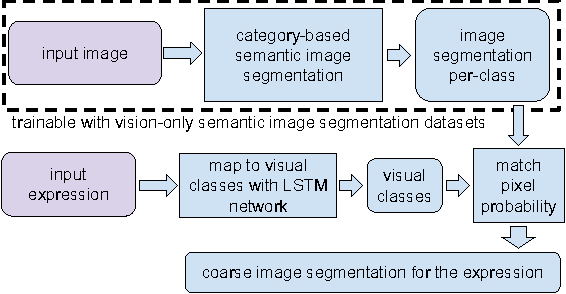
Image segmentation from referring expressions is a joint vision and language modeling task, where the input is an image and a textual expression describing a particular region in the image; and the goal is to localize and segment the specific image region based on the given expression. One major difficulty to train such language-based image segmentation systems is the lack of datasets with joint vision and text annotations. Although existing vision datasets such as MS COCO provide image captions, there are few datasets with region-level textual annotations for images, and these are often smaller in scale. In this paper, we explore how existing large scale vision-only and text-only datasets can be utilized to train models for image segmentation from referring expressions. We propose a method to address this problem, and show in experiments that our method can help this joint vision and language modeling task with vision-only and text-only data and outperforms previous results.
A Particle Swarm Optimization-based Flexible Convolutional Auto-Encoder for Image Classification
Dec 13, 2017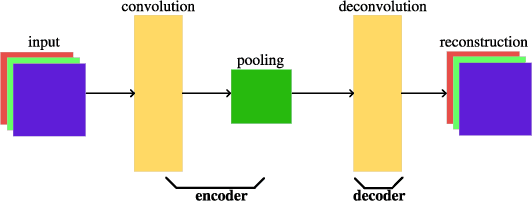
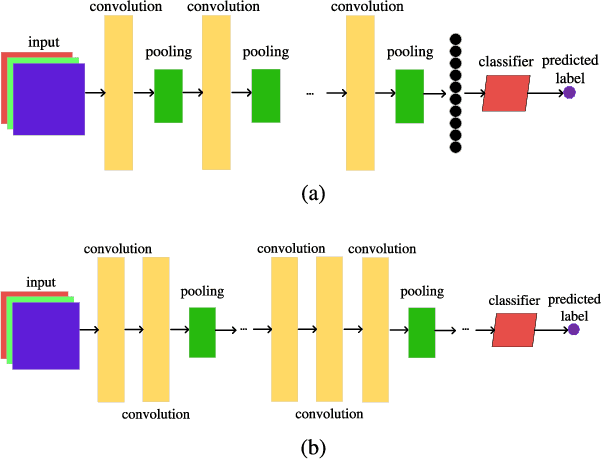
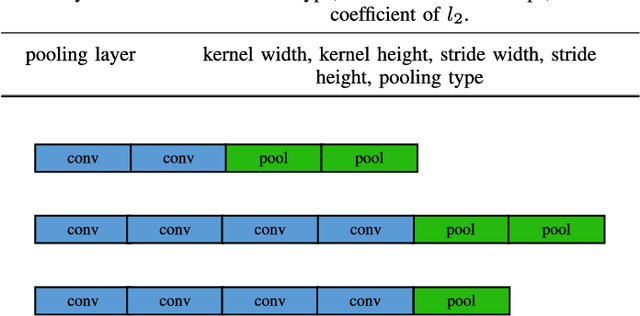
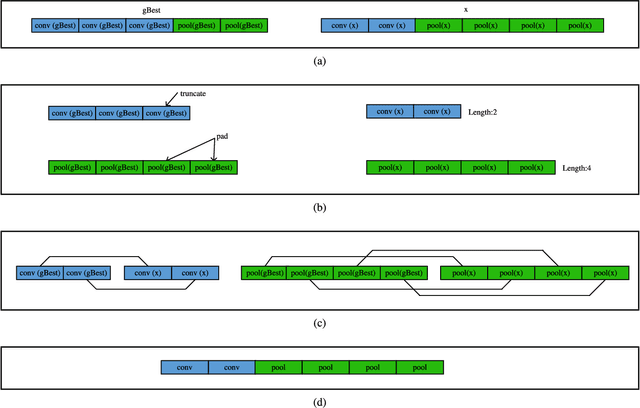
Convolutional auto-encoders have shown their remarkable performance in stacking to deep convolutional neural networks for classifying image data during past several years. However, they are unable to construct the state-of-the-art convolutional neural networks due to their intrinsic architectures. In this regard, we propose a flexible convolutional auto-encoder by eliminating the constraints on the numbers of convolutional layers and pooling layers from the traditional convolutional auto-encoder. We also design an architecture discovery method by using particle swarm optimization, which is capable of automatically searching for the optimal architectures of the proposed flexible convolutional auto-encoder with much less computational resource and without any manual intervention. We use the designed architecture optimization algorithm to test the proposed flexible convolutional auto-encoder through utilizing one graphic processing unit card on four extensively used image classification datasets. Experimental results show that our work in this paper significantly outperform the peer competitors including the state-of-the-art algorithm.
A General Approach for Using Deep Neural Network for Digital Watermarking
Mar 08, 2020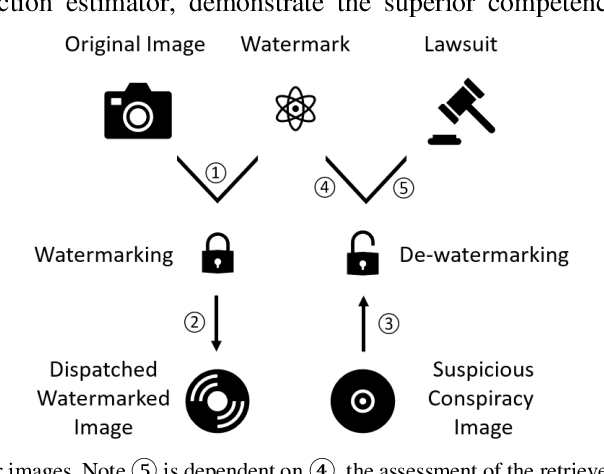

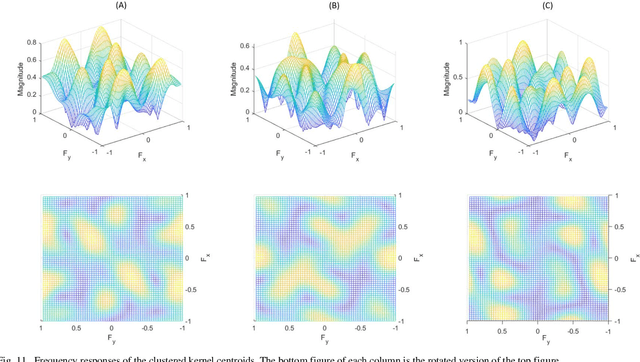
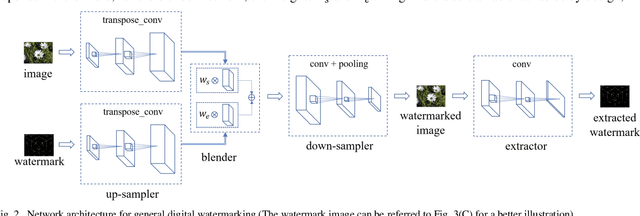
Technologies of the Internet of Things (IoT) facilitate digital contents such as images being acquired in a massive way. However, consideration from the privacy or legislation perspective still demands the need for intellectual content protection. In this paper, we propose a general deep neural network (DNN) based watermarking method to fulfill this goal. Instead of training a neural network for protecting a specific image, we train on an image set and use the trained model to protect a distinct test image set in a bulk manner. Respective evaluations both from the subjective and objective aspects confirm the supremacy and practicability of our proposed method. To demonstrate the robustness of this general neural watermarking mechanism, commonly used manipulations are applied to the watermarked image to examine the corresponding extracted watermark, which still retains sufficient recognizable traits. To the best of our knowledge, we are the first to propose a general way to perform watermarking using DNN. Considering its performance and economy, it is concluded that subsequent studies that generalize our work on utilizing DNN for intellectual content protection is a promising research trend.
Polarization Human Shape and Pose Dataset
Apr 30, 2020


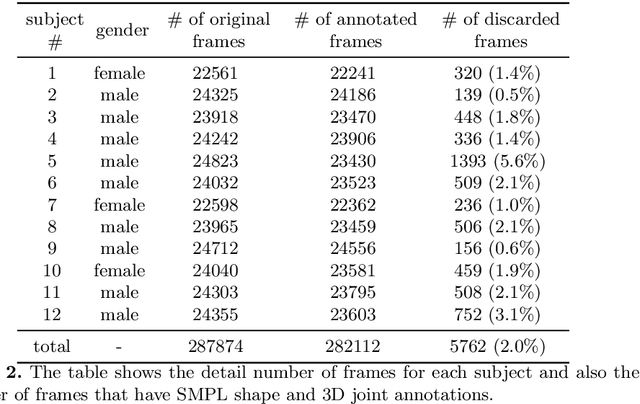
Polarization images are known to be able to capture polarized reflected lights that preserve rich geometric cues of an object, which has motivated its recent applications in reconstructing detailed surface normal of the objects of interest. Meanwhile, inspired by the recent breakthroughs in human shape estimation from a single color image, we attempt to investigate the new question of whether the geometric cues from polarization camera could be leveraged in estimating detailed human body shapes. This has led to the curation of Polarization Human Shape and Pose Dataset (PHSPD)5, our home-grown polarization image dataset of various human shapes and poses.