 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Synergistic Learning of Lung Lobe Segmentation and Hierarchical Multi-Instance Classification for Automated Severity Assessment of COVID-19 in CT Images
May 24, 2020
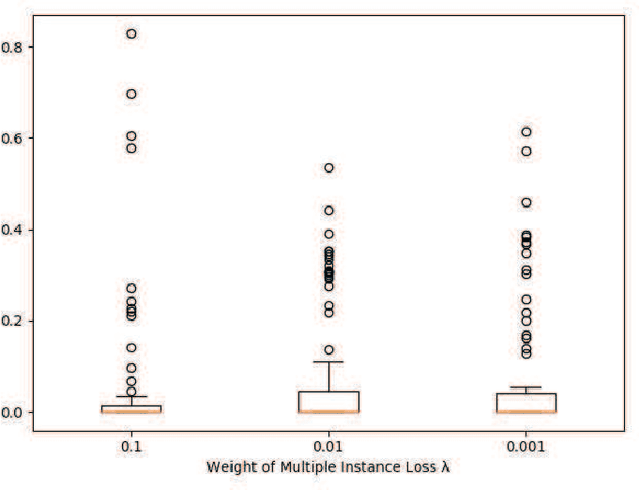
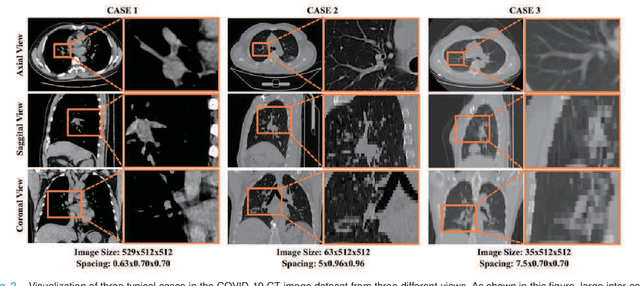
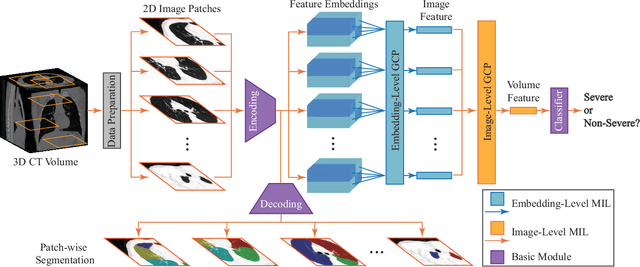
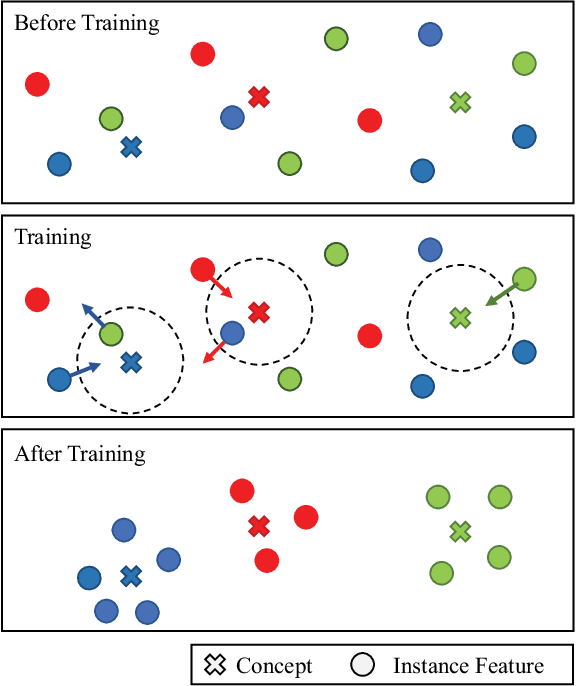
Understanding chest CT imaging of the coronavirus disease 2019 (COVID-19) will help detect infections early and assess the disease progression. Especially, automated severity assessment of COVID-19 in CT images plays an essential role in identifying cases that are in great need of intensive clinical care. However, it is often challenging to accurately assess the severity of this disease in CT images, due to variable infection regions in the lungs, similar imaging biomarkers, and large inter-case variations. To this end, we propose a synergistic learning framework for automated severity assessment of COVID-19 in 3D CT images, by jointly performing lung lobe segmentation and multi-instance classification. Considering that only a few infection regions in a CT image are related to the severity assessment, we first represent each input image by a bag that contains a set of 2D image patches (with each cropped from a specific slice). A multi-task multi-instance deep network (called M$^2$UNet) is then developed to assess the severity of COVID-19 patients and also segment the lung lobe simultaneously. Our M$^2$UNet consists of a patch-level encoder, a segmentation sub-network for lung lobe segmentation, and a classification sub-network for severity assessment (with a unique hierarchical multi-instance learning strategy). Here, the context information provided by segmentation can be implicitly employed to improve the performance of severity assessment. Extensive experiments were performed on a real COVID-19 CT image dataset consisting of 666 chest CT images, with results suggesting the effectiveness of our proposed method compared to several state-of-the-art methods.
Deep Generation of Face Images from Sketches
Jun 05, 2020
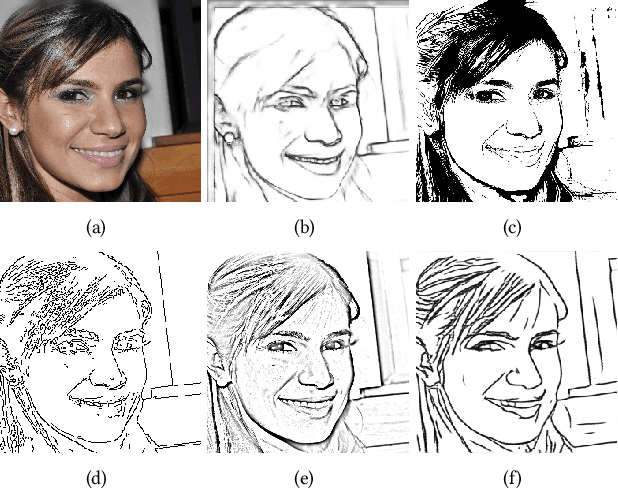
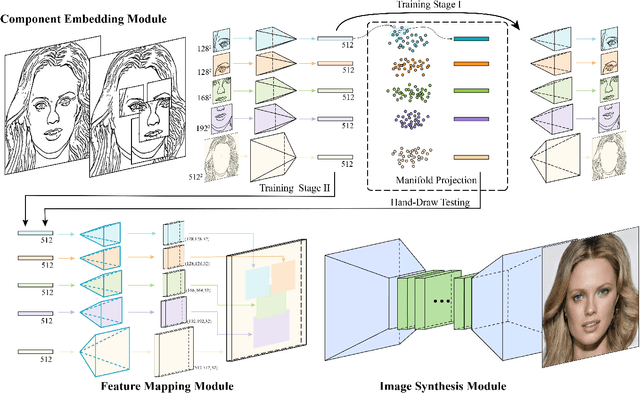

Recent deep image-to-image translation techniques allow fast generation of face images from freehand sketches. However, existing solutions tend to overfit to sketches, thus requiring professional sketches or even edge maps as input. To address this issue, our key idea is to implicitly model the shape space of plausible face images and synthesize a face image in this space to approximate an input sketch. We take a local-to-global approach. We first learn feature embeddings of key face components, and push corresponding parts of input sketches towards underlying component manifolds defined by the feature vectors of face component samples. We also propose another deep neural network to learn the mapping from the embedded component features to realistic images with multi-channel feature maps as intermediate results to improve the information flow. Our method essentially uses input sketches as soft constraints and is thus able to produce high-quality face images even from rough and/or incomplete sketches. Our tool is easy to use even for non-artists, while still supporting fine-grained control of shape details. Both qualitative and quantitative evaluations show the superior generation ability of our system to existing and alternative solutions. The usability and expressiveness of our system are confirmed by a user study.
A regularization-based approach for unsupervised image segmentation
Mar 08, 2016
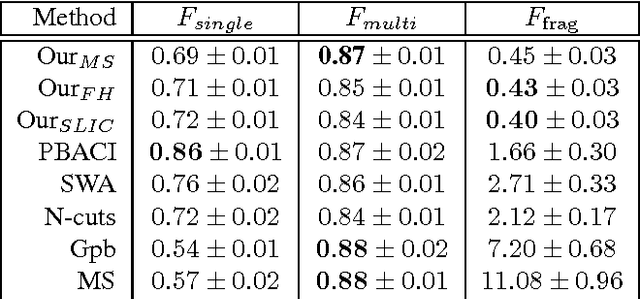

We propose a novel unsupervised image segmentation algorithm, which aims to segment an image into several coherent parts. It requires no user input, no supervised learning phase and assumes an unknown number of segments. It achieves this by first over-segmenting the image into several hundred superpixels. These are iteratively joined on the basis of a discriminative classifier trained on color and texture information obtained from each superpixel. The output of the classifier is regularized by a Markov random field that lends more influence to neighbouring superpixels that are more similar. In each iteration, similar superpixels fall under the same label, until only a few coherent regions remain in the image. The algorithm was tested on a standard evaluation data set, where it performs on par with state-of-the-art algorithms in term of precision and greatly outperforms the state of the art by reducing the oversegmentation of the object of interest.
Keep Your AI-es on the Road: Tackling Distracted Driver Detection with Convolutional Neural Networks and Targetted Data Augmentation
Jun 19, 2020

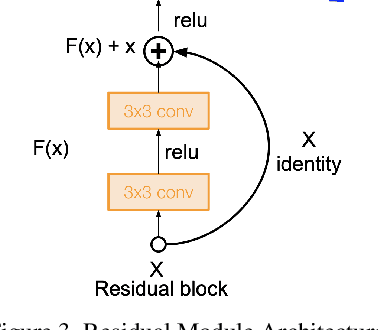

According to the World Health Organization, distracted driving is one of the leading cause of motor accidents and deaths in the world. In our study, we tackle the problem of distracted driving by aiming to build a robust multi-class classifier to detect and identify different forms of driver inattention using the State Farm Distracted Driving Dataset. We utilize combinations of pretrained image classification models, classical data augmentation, OpenCV based image preprocessing and skin segmentation augmentation approaches. Our best performing model combines several augmentation techniques, including skin segmentation, facial blurring, and classical augmentation techniques. This model achieves an approximately 15% increase in F1 score over the baseline, thus showing the promise in these techniques in enhancing the power of neural networks for the task of distracted driver detection.
APF-PF: Probabilistic Depth Perception for 3D Reactive Obstacle Avoidance
Oct 15, 2020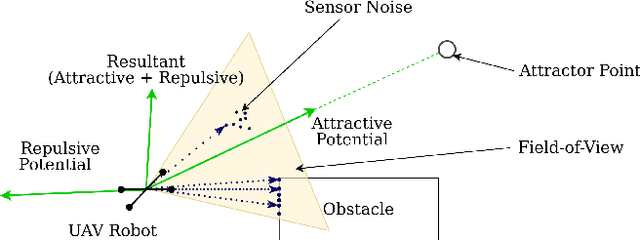
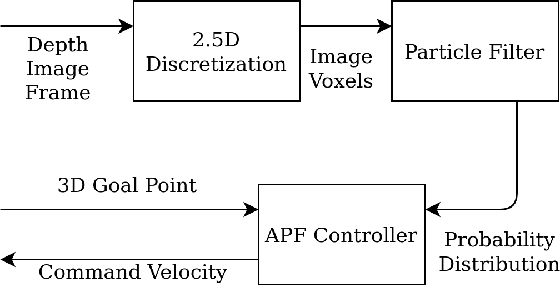
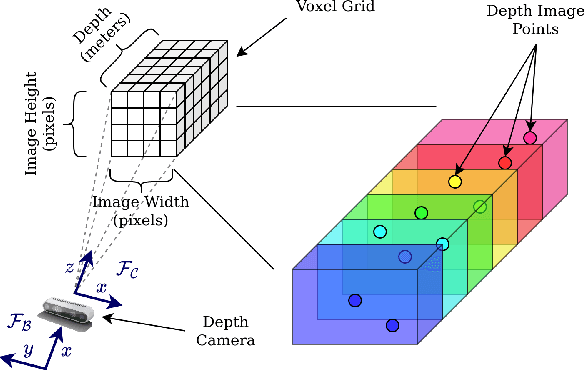
This paper proposes a framework for 3D obstacle avoidance in the presence of partial observability of environment obstacles. The method focuses on the utility of the Artificial Potential Field (APF) controller in a practical setting where noisy and incomplete information about the proximity is inevitable. We propose a Particle Filter (PF) approach to estimate potential obstacle locations in an input depth image stream. The probable candidates are then used to generate an action that maneuvers the robot towards the negative gradient of potential at each time instant. Rigorous experimental validation on a quadrotor UAV demonstrates the robustness and reliability of the method when robot's sensitivity to incorrect perception information can be concerning. The proposed method is highly compute efficient for real-time applications and agile robots.
Using Graph Neural Networks to Reconstruct Ancient Documents
Nov 13, 2020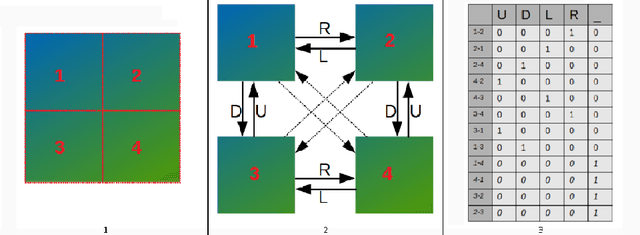
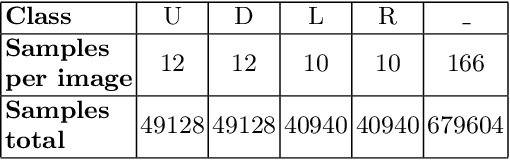
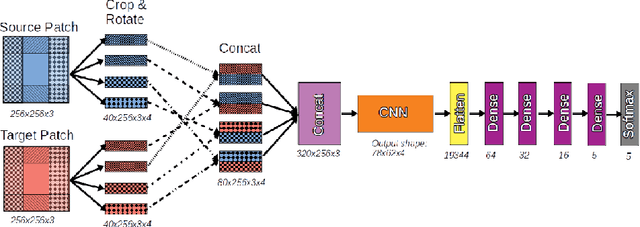
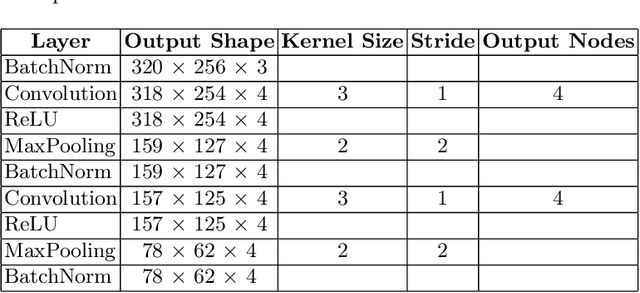
In recent years, machine learning and deep learning approaches such as artificial neural networks have gained in popularity for the resolution of automatic puzzle resolution problems. Indeed, these methods are able to extract high-level representations from images, and then can be trained to separate matching image pieces from non-matching ones. These applications have many similarities to the problem of ancient document reconstruction from partially recovered fragments. In this work we present a solution based on a Graph Neural Network, using pairwise patch information to assign labels to edges representing the spatial relationships between pairs. This network classifies the relationship between a source and a target patch as being one of Up, Down, Left, Right or None. By doing so for all edges, our model outputs a new graph representing a reconstruction proposal. Finally, we show that our model is not only able to provide correct classifications at the edge-level, but also to generate partial or full reconstruction graphs from a set of patches.
Polka Lines: Learning Structured Illumination and Reconstruction for Active Stereo
Nov 26, 2020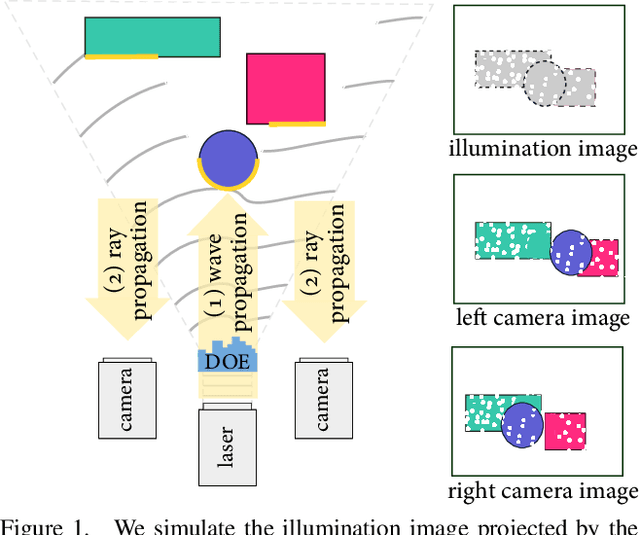
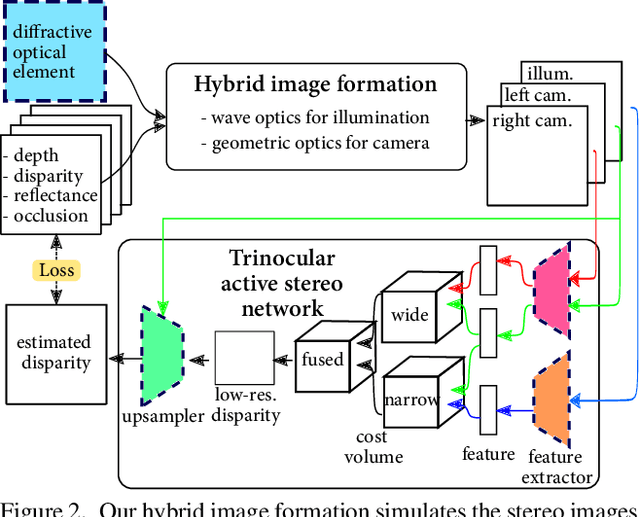
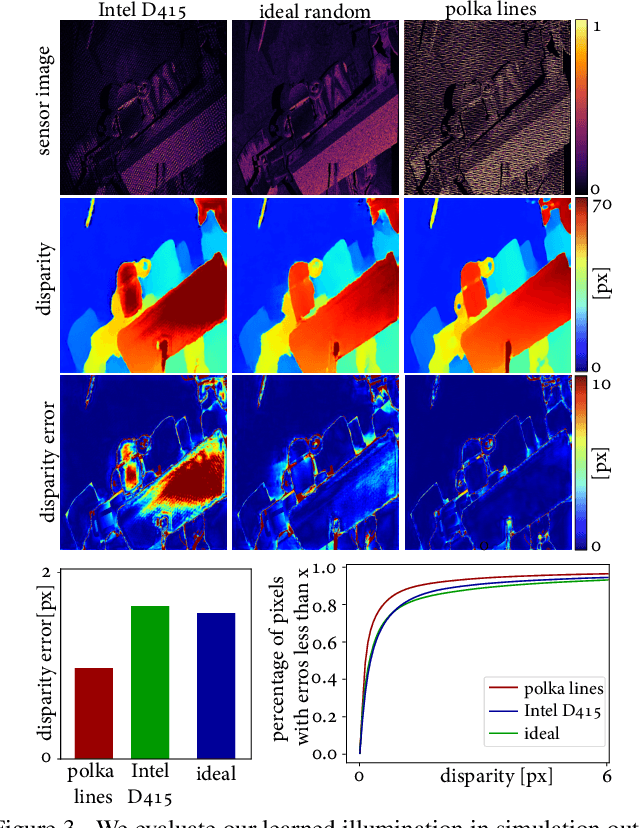
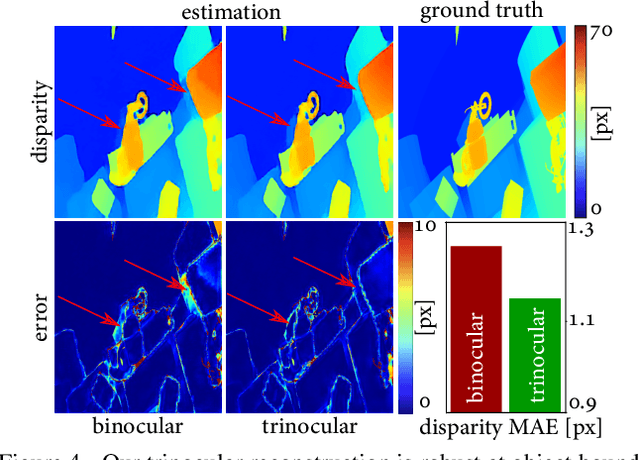
Active stereo cameras that recover depth from structured light captures have become a cornerstone sensor modality for 3D scene reconstruction and understanding tasks across application domains. Existing active stereo cameras project a pseudo-random dot pattern on object surfaces to extract disparity independently of object texture. Such hand-crafted patterns are designed in isolation from the scene statistics, ambient illumination conditions, and the reconstruction method. In this work, we propose the first method to jointly learn structured illumination and reconstruction, parameterized by a diffractive optical element and a neural network, in an end-to-end fashion. To this end, we introduce a novel differentiable image formation model for active stereo, relying on both wave and geometric optics, and a novel trinocular reconstruction network. The jointly optimized pattern, which we dub "Polka Lines," together with the reconstruction network, achieve state-of-the-art active-stereo depth estimates across imaging conditions. We validate the proposed method in simulation and on a hardware prototype, and show that our method outperforms existing active stereo systems.
Multi-View Attention Networks for Visual Dialog
Apr 29, 2020
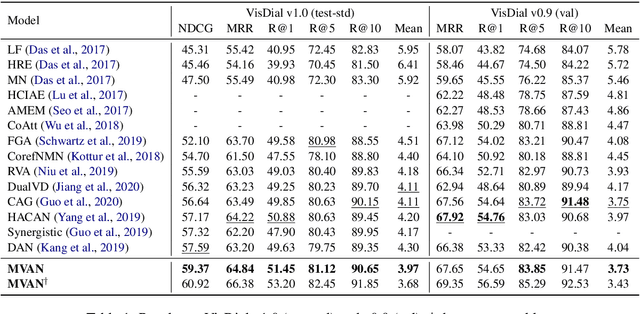
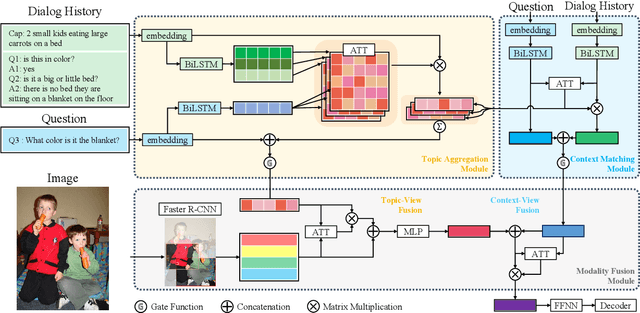
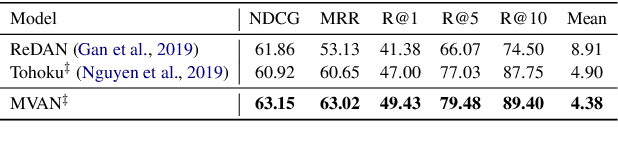
Visual dialog is a challenging vision-language task in which a series of questions visually grounded by a given image are answered. To resolve the visual dialog task, a high-level understanding of various multimodal inputs (e.g., question, dialog history, image, and answer) is required. Specifically, it is necessary for an agent to 1) understand question-relevant dialog history and 2) focus on question-relevant visual contents among the diverse visual contents in a given image. In this paper, we propose Multi-View Attention Network (MVAN), which considers complementary views of multimodal inputs based on attention mechanisms. MVAN effectively captures the question-relevant information from the dialog history with two different textual-views (i.e., Topic Aggregation and Context Matching), and integrates multimodal representations with two-step fusion process. Experimental results on VisDial v1.0 and v0.9 benchmarks show the effectiveness of our proposed model, which outperforms the previous state-of-the-art methods with respect to all evaluation metrics.
CARAFE++: Unified Content-Aware ReAssembly of FEatures
Dec 07, 2020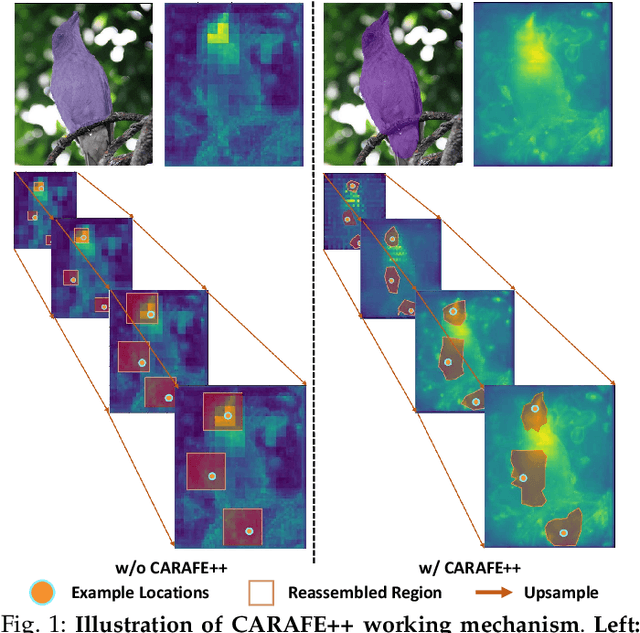
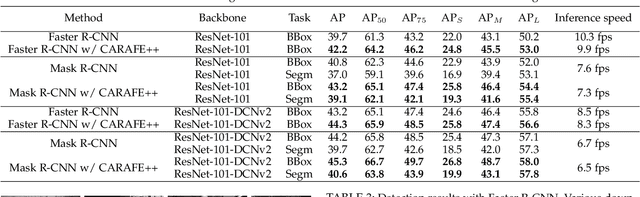
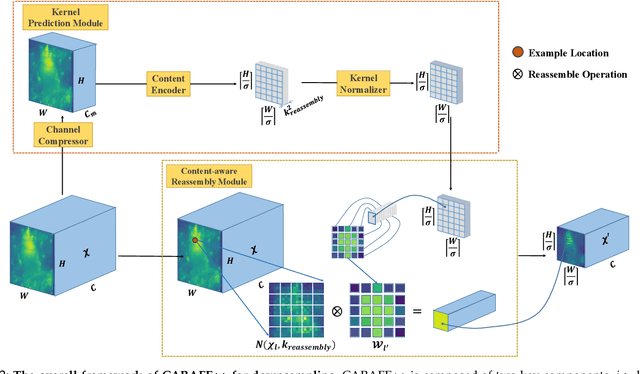
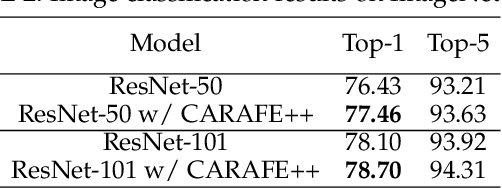
Feature reassembly, i.e. feature downsampling and upsampling, is a key operation in a number of modern convolutional network architectures, e.g., residual networks and feature pyramids. Its design is critical for dense prediction tasks such as object detection and semantic/instance segmentation. In this work, we propose unified Content-Aware ReAssembly of FEatures (CARAFE++), a universal, lightweight and highly effective operator to fulfill this goal. CARAFE++ has several appealing properties: (1) Unlike conventional methods such as pooling and interpolation that only exploit sub-pixel neighborhood, CARAFE++ aggregates contextual information within a large receptive field. (2) Instead of using a fixed kernel for all samples (e.g. convolution and deconvolution), CARAFE++ generates adaptive kernels on-the-fly to enable instance-specific content-aware handling. (3) CARAFE++ introduces little computational overhead and can be readily integrated into modern network architectures. We conduct comprehensive evaluations on standard benchmarks in object detection, instance/semantic segmentation and image inpainting. CARAFE++ shows consistent and substantial gains across all the tasks (2.5% APbox, 2.1% APmask, 1.94% mIoU, 1.35 dB respectively) with negligible computational overhead. It shows great potential to serve as a strong building block for modern deep networks.
Siamese Network of Deep Fisher-Vector Descriptors for Image Retrieval
Feb 01, 2017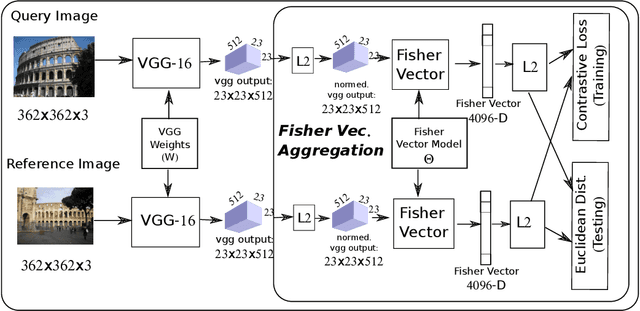
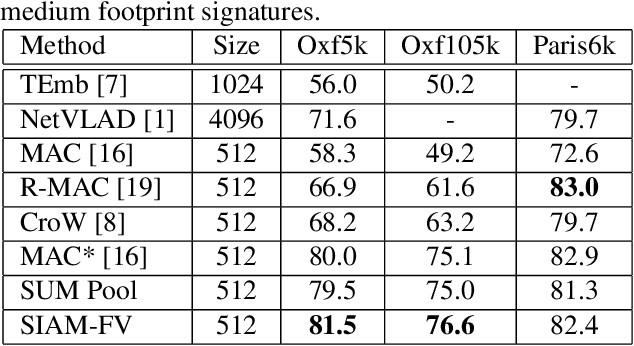
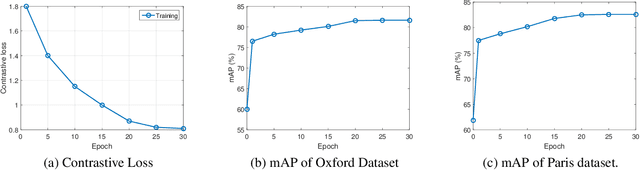
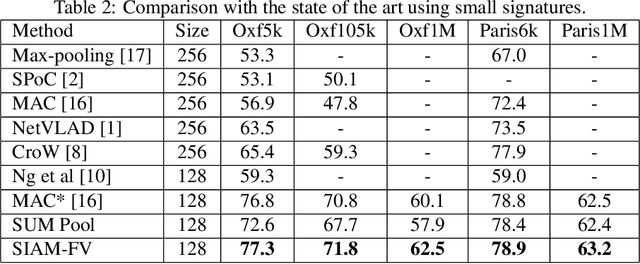
This paper addresses the problem of large scale image retrieval, with the aim of accurately ranking the similarity of a large number of images to a given query image. To achieve this, we propose a novel Siamese network. This network consists of two computational strands, each comprising of a CNN component followed by a Fisher vector component. The CNN component produces dense, deep convolutional descriptors that are then aggregated by the Fisher Vector method. Crucially, we propose to simultaneously learn both the CNN filter weights and Fisher Vector model parameters. This allows us to account for the evolving distribution of deep descriptors over the course of the learning process. We show that the proposed approach gives significant improvements over the state-of-the-art methods on the Oxford and Paris image retrieval datasets. Additionally, we provide a baseline performance measure for both these datasets with the inclusion of 1 million distractors.