 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Interpretable Deep Learning for Pattern Recognition in Brain Differences Between Men and Women
Jun 20, 2020
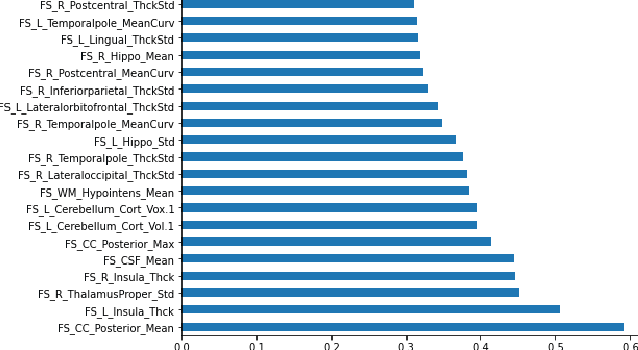

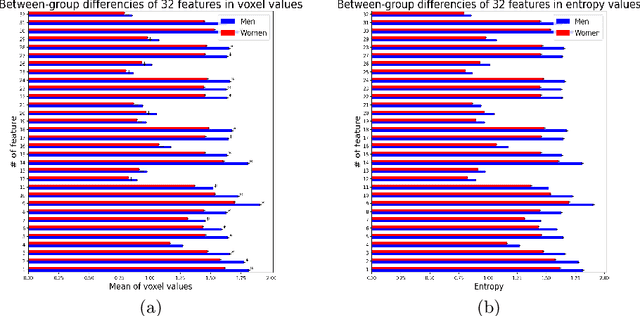
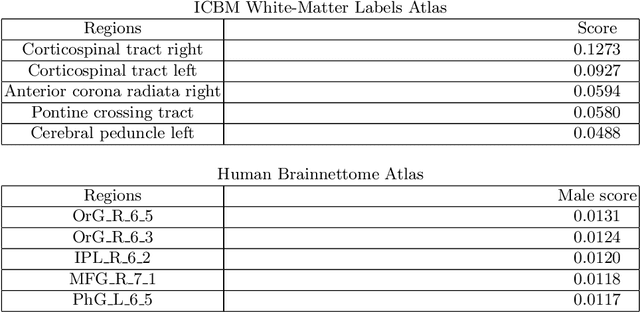
Deep learning shows high potential for many medical image analysis tasks. Neural networks work with full-size data without extensive preprocessing and feature generation and, thus, information loss. Recent work has shown that morphological difference between specific brain regions can be found on MRI with deep learning techniques. We consider the pattern recognition task based on a large open-access dataset of healthy subjects - an exploration of brain differences between men and women. However, interpretation of the lately proposed models is based on a region of interest and can not be extended to pixel or voxel-wise image interpretation, which is considered to be more informative. In this paper, we confirm the previous findings in sex differences from diffusion-tensor imaging on T1 weighted brain MRI scans. We compare the results of three voxel-based 3D CNN interpretation methods: Meaningful Perturbations, GradCam and Guided Backpropagation and provide the open-source code.
Nodule2vec: a 3D Deep Learning System for Pulmonary Nodule Retrieval Using Semantic Representation
Jul 11, 2020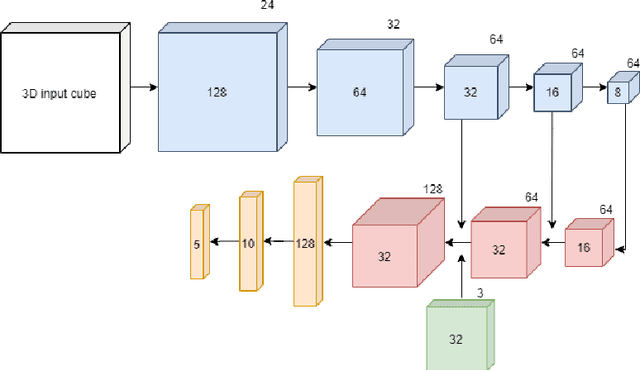
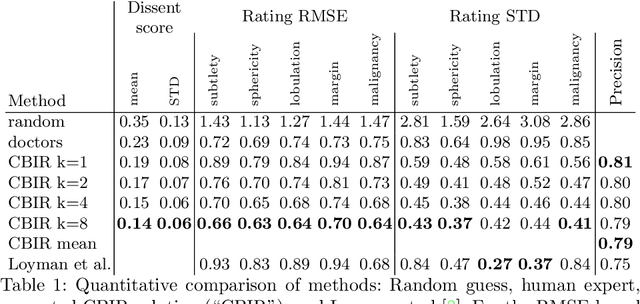
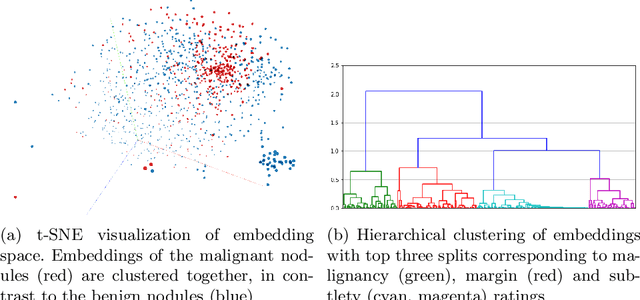
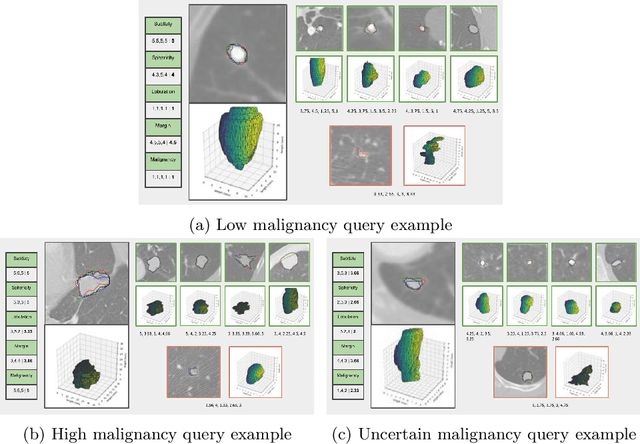
Content-based retrieval supports a radiologist decision making process by presenting the doctor the most similar cases from the database containing both historical diagnosis and further disease development history. We present a deep learning system that transforms a 3D image of a pulmonary nodule from a CT scan into a low-dimensional embedding vector. We demonstrate that such a vector representation preserves semantic information about the nodule and offers a viable approach for content-based image retrieval (CBIR). We discuss the theoretical limitations of the available datasets and overcome them by applying transfer learning of the state-of-the-art lung nodule detection model. We evaluate the system using the LIDC-IDRI dataset of thoracic CT scans. We devise a similarity score and show that it can be utilized to measure similarity 1) between annotations of the same nodule by different radiologists and 2) between the query nodule and the top four CBIR results. A comparison between doctors and algorithm scores suggests that the benefit provided by the system to the radiologist end-user is comparable to obtaining a second radiologist's opinion.
Adaptive Weighted Discriminator for Training Generative Adversarial Networks
Dec 05, 2020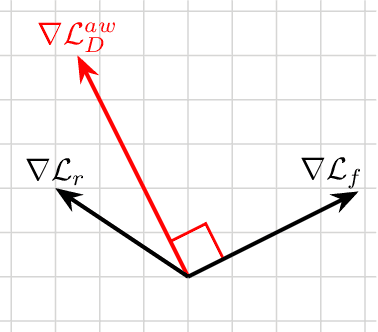
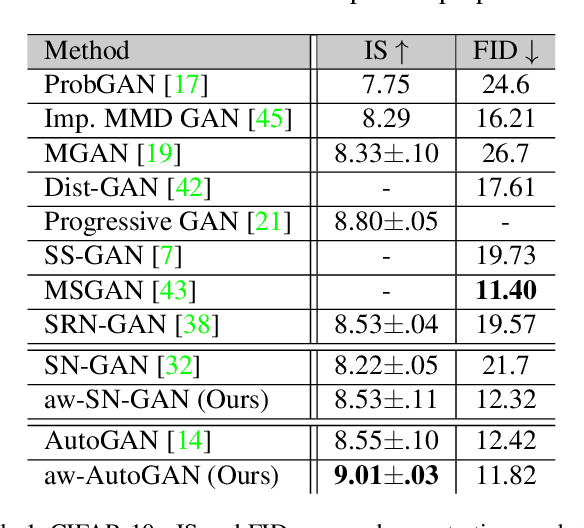

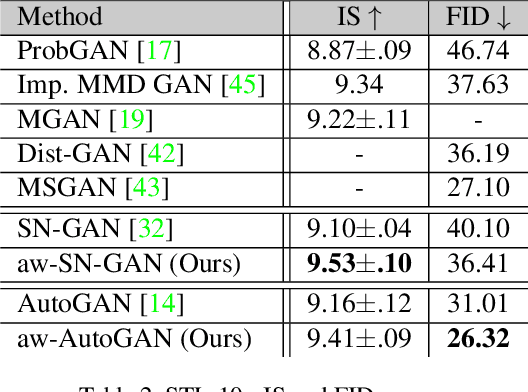
Generative adversarial network (GAN) has become one of the most important neural network models for classical unsupervised machine learning. A variety of discriminator loss functions have been developed to train GAN's discriminators and they all have a common structure: a sum of real and fake losses that only depends on the actual and generated data respectively. One challenge associated with an equally weighted sum of two losses is that the training may benefit one loss but harm the other, which we show causes instability and mode collapse. In this paper, we introduce a new family of discriminator loss functions that adopts a weighted sum of real and fake parts, which we call adaptive weighted loss functions or aw-loss functions. Using the gradients of the real and fake parts of the loss, we can adaptively choose weights to train a discriminator in the direction that benefits the GAN's stability. Our method can be potentially applied to any discriminator model with a loss that is a sum of the real and fake parts. Experiments validated the effectiveness of our loss functions on an unconditional image generation task, improving the baseline results by a significant margin on CIFAR-10, STL-10, and CIFAR-100 datasets in Inception Scores and FID.
Unveiling Real-Life Effects of Online Photo Sharing
Dec 24, 2020

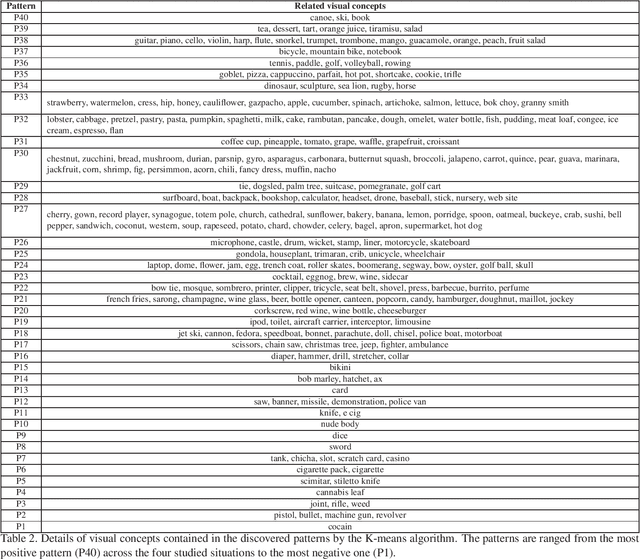
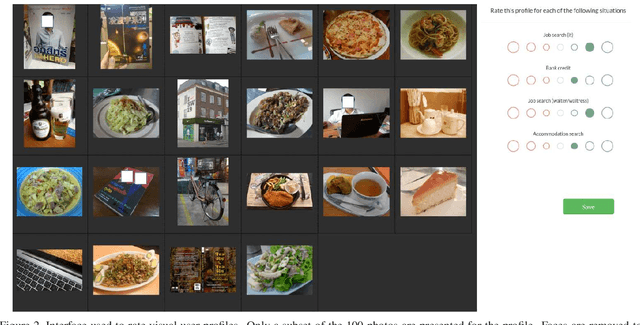
Social networks give free access to their services in exchange for the right to exploit their users' data. Data sharing is done in an initial context which is chosen by the users. However, data are used by social networks and third parties in different contexts which are often not transparent. We propose a new approach which unveils potential effects of data sharing in impactful real-life situations. Focus is put on visual content because of its strong influence in shaping online user profiles. The approach relies on three components: (1) a set of concepts with associated situation impact ratings obtained by crowdsourcing, (2) a corresponding set of object detectors used to analyze users' photos and (3) a ground truth dataset made of 500 visual user profiles which are manually rated for each situation. These components are combined in LERVUP, a method which learns to rate visual user profiles in each situation. LERVUP exploits a new image descriptor which aggregates concept ratings and object detections at user level. It also uses an attention mechanism to boost the detections of highly-rated concepts to prevent them from being overwhelmed by low-rated ones. Performance is evaluated per situation by measuring the correlation between the automatic ranking of profile ratings and a manual ground truth. Results indicate that LERVUP is effective since a strong correlation of the two rankings is obtained. This finding indicates that providing meaningful automatic situation-related feedback about the effects of data sharing is feasible.
360-Degree Gaze Estimation in the Wild Using Multiple Zoom Scales
Sep 15, 2020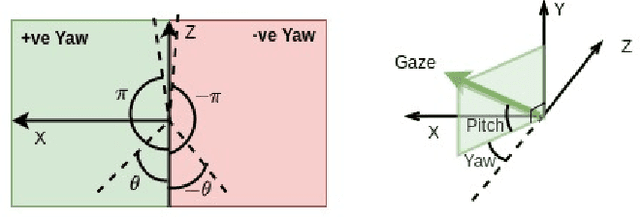
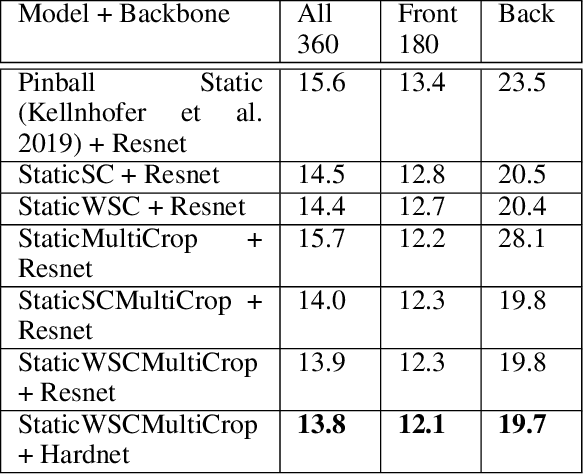
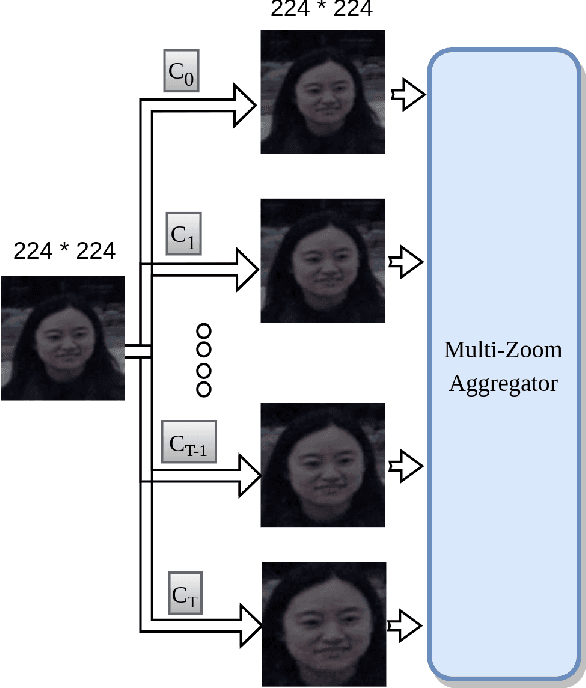
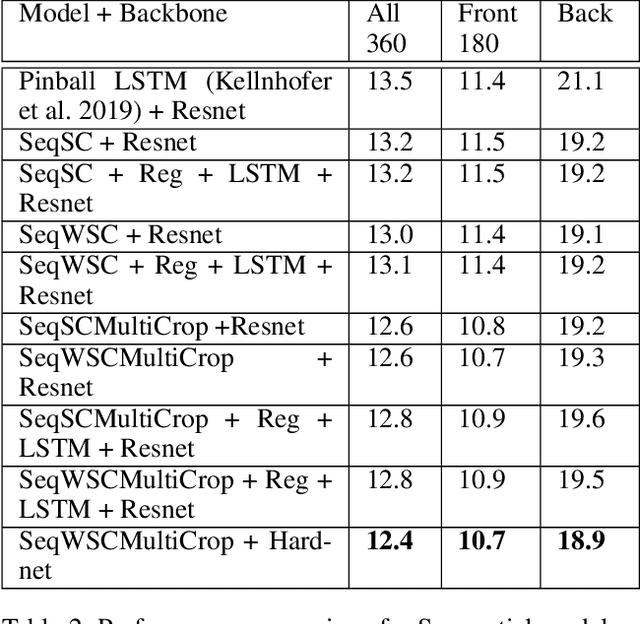
Gaze estimation involves predicting where the person is looking at, given either a single input image or a sequence of images. One challenging task, gaze estimation in the wild, concerns data collected in unconstrained environments with varying camera-person distances, like the Gaze360 dataset. The varying distances result in varying face sizes in the images, which makes it hard for current CNN backbones to estimate the gaze robustly. Inspired by our natural skill to identify the gaze by taking a focused look at the face area, we propose a novel architecture that similarly zooms in on the face area of the image at multiple scales to improve prediction accuracy. Another challenging task, 360-degree gaze estimation (also introduced by the Gaze360 dataset), consists of estimating not only the forward gazes, but also the backward ones. The backward gazes introduce discontinuity in the yaw angle values of the gaze, making the deep learning models affected by some huge loss around the discontinuous points. We propose to convert the angle values by sine-cosine transform to avoid the discontinuity and represent the physical meaning of the yaw angle better. We conduct ablation studies on both ideas, the novel architecture and the transform, to validate their effectiveness. The two ideas allow our proposed model to achieve state-of-the-art performance for both the Gaze360 dataset and the RT-Gene dataset when using single images. Furthermore, we extend the model to a sequential version that systematically zooms in on a given sequence of images. The sequential version again achieves state-of-the-art performance on the Gaze360 dataset, which further demonstrates the usefulness of our proposed ideas.
Image Annotation using Multi-Layer Sparse Coding
May 06, 2017


Automatic annotation of images with descriptive words is a challenging problem with vast applications in the areas of image search and retrieval. This problem can be viewed as a label-assignment problem by a classifier dealing with a very large set of labels, i.e., the vocabulary set. We propose a novel annotation method that employs two layers of sparse coding and performs coarse-to-fine labeling. Themes extracted from the training data are treated as coarse labels. Each theme is a set of training images that share a common subject in their visual and textual contents. Our system extracts coarse labels for training and test images without requiring any prior knowledge. Vocabulary words are the fine labels to be associated with images. Most of the annotation methods achieve low recall due to the large number of available fine labels, i.e., vocabulary words. These systems also tend to achieve high precision for highly frequent words only while relatively rare words are more important for search and retrieval purposes. Our system not only outperforms various previously proposed annotation systems, but also achieves symmetric response in terms of precision and recall. Our system scores and maintains high precision for words with a wide range of frequencies. Such behavior is achieved by intelligently reducing the number of available fine labels or words for each image based on coarse labels assigned to it.
L^2UWE: A Framework for the Efficient Enhancement of Low-Light Underwater Images Using Local Contrast and Multi-Scale Fusion
May 28, 2020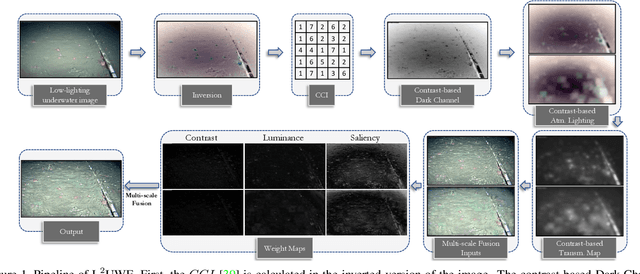
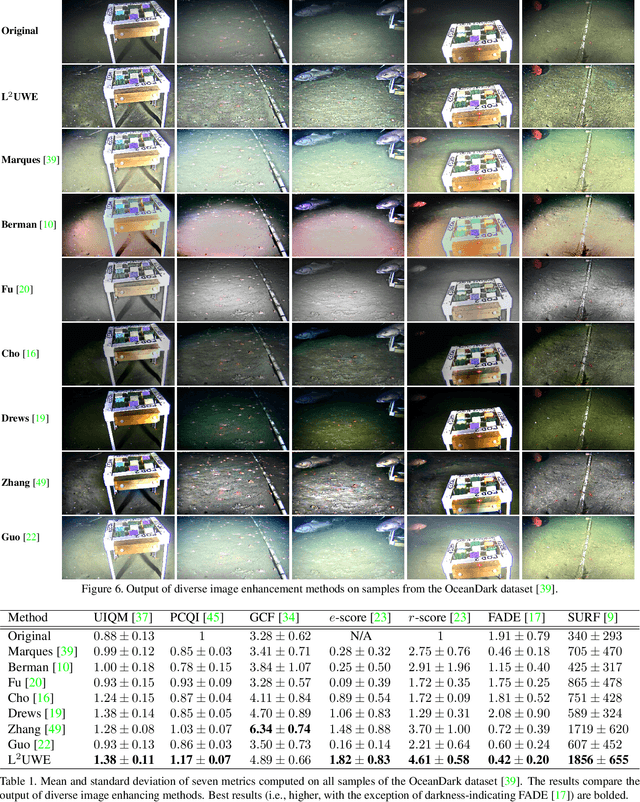
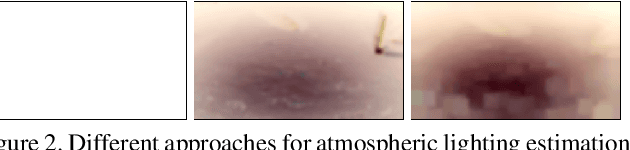

Images captured underwater often suffer from suboptimal illumination settings that can hide important visual features, reducing their quality. We present a novel single-image low-light underwater image enhancer, L^2UWE, that builds on our observation that an efficient model of atmospheric lighting can be derived from local contrast information. We create two distinct models and generate two enhanced images from them: one that highlights finer details, the other focused on darkness removal. A multi-scale fusion process is employed to combine these images while emphasizing regions of higher luminance, saliency and local contrast. We demonstrate the performance of L^2UWE by using seven metrics to test it against seven state-of-the-art enhancement methods specific to underwater and low-light scenes.
MyFood: A Food Segmentation and Classification System to Aid Nutritional Monitoring
Dec 05, 2020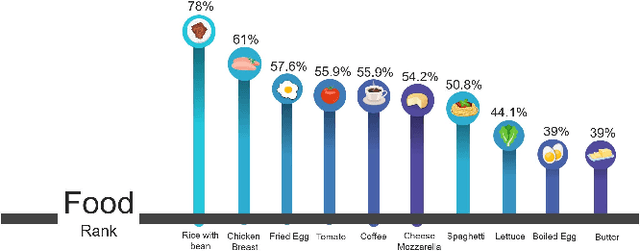


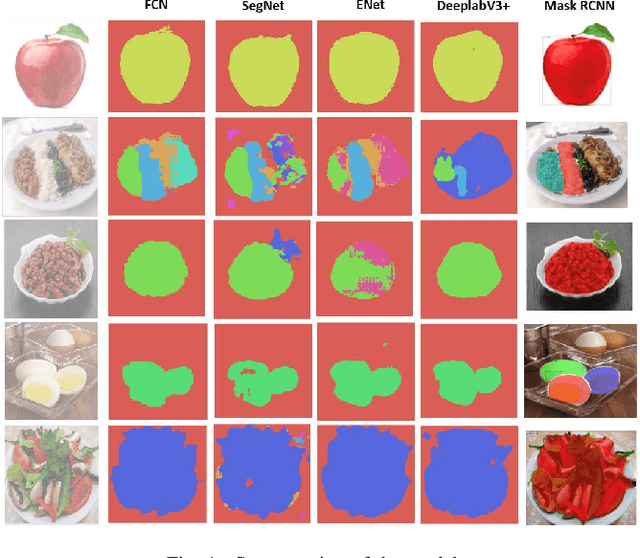
The absence of food monitoring has contributed significantly to the increase in the population's weight. Due to the lack of time and busy routines, most people do not control and record what is consumed in their diet. Some solutions have been proposed in computer vision to recognize food images, but few are specialized in nutritional monitoring. This work presents the development of an intelligent system that classifies and segments food presented in images to help the automatic monitoring of user diet and nutritional intake. This work shows a comparative study of state-of-the-art methods for image classification and segmentation, applied to food recognition. In our methodology, we compare the FCN, ENet, SegNet, DeepLabV3+, and Mask RCNN algorithms. We build a dataset composed of the most consumed Brazilian food types, containing nine classes and a total of 1250 images. The models were evaluated using the following metrics: Intersection over Union, Sensitivity, Specificity, Balanced Precision, and Positive Predefined Value. We also propose an system integrated into a mobile application that automatically recognizes and estimates the nutrients in a meal, assisting people with better nutritional monitoring. The proposed solution showed better results than the existing ones in the market. The dataset is publicly available at the following link http://doi.org/10.5281/zenodo.4041488
* Paper published at SIBRAPI 2020 (Camera ready version)
Lesion2Vec: Deep Metric Learning for Few-Shot Multiple Lesions Recognition in Wireless Capsule Endoscopy Video
Jan 15, 2021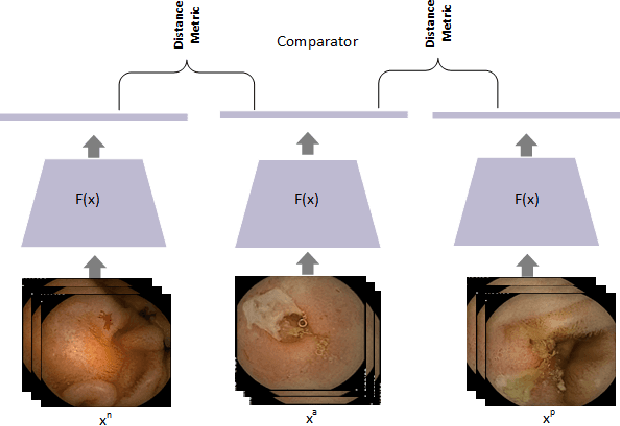
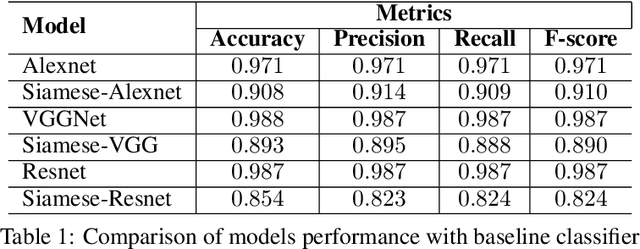
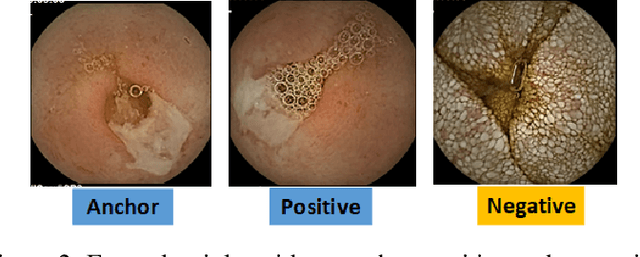
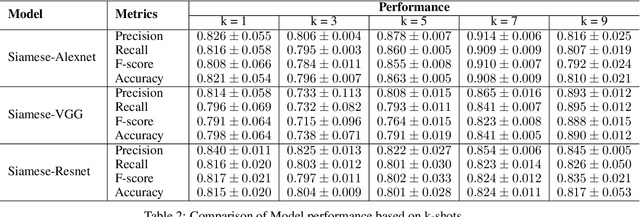
Effective and rapid detection of lesions in the Gastrointestinal tract is critical to gastroenterologist's response to some life-threatening diseases. Wireless Capsule Endoscopy (WCE) has revolutionized traditional endoscopy procedure by allowing gastroenterologists visualize the entire GI tract non-invasively. Once the tiny capsule is swallowed, it sequentially capture images of the GI tract at about 2 to 6 frames per second (fps). A single video can last up to 8 hours producing between 30,000 to 100,000 images. Automating the detection of frames containing specific lesion in WCE video would relieve gastroenterologists the arduous task of reviewing the entire video before making diagnosis. While the WCE produces large volume of images, only about 5\% of the frames contain lesions that aid the diagnosis process. Convolutional Neural Network (CNN) based models have been very successful in various image classification tasks. However, they suffer excessive parameters, are sample inefficient and rely on very large amount of training data. Deploying a CNN classifier for lesion detection task will require time-to-time fine-tuning to generalize to any unforeseen category. In this paper, we propose a metric-based learning framework followed by a few-shot lesion recognition in WCE data. Metric-based learning is a meta-learning framework designed to establish similarity or dissimilarity between concepts while few-shot learning (FSL) aims to identify new concepts from only a small number of examples. We train a feature extractor to learn a representation for different small bowel lesions using metric-based learning. At the testing stage, the category of an unseen sample is predicted from only a few support examples, thereby allowing the model to generalize to a new category that has never been seen before. We demonstrated the efficacy of this method on real patient capsule endoscopy data.
Learning Energy-Based Models by Diffusion Recovery Likelihood
Dec 15, 2020
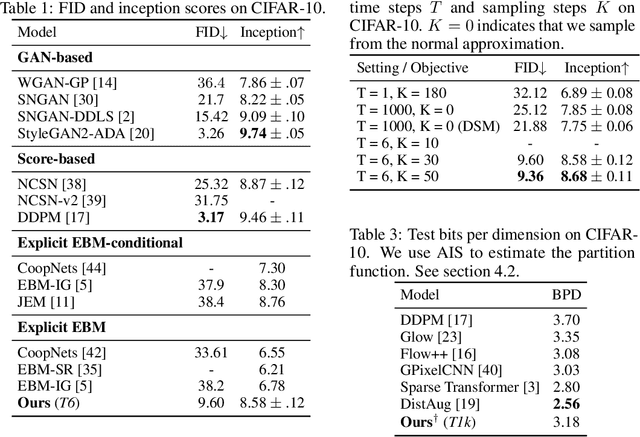
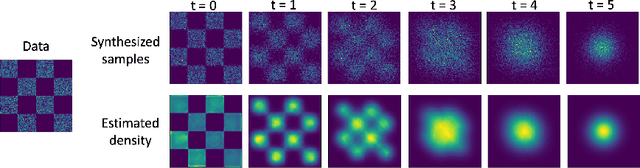

While energy-based models (EBMs) exhibit a number of desirable properties, training and sampling on high-dimensional datasets remains challenging. Inspired by recent progress on diffusion probabilistic models, we present a diffusion recovery likelihood method to tractably learn and sample from a sequence of EBMs trained on increasingly noisy versions of a dataset. Each EBM is trained by maximizing the recovery likelihood: the conditional probability of the data at a certain noise level given their noisy versions at a higher noise level. The recovery likelihood objective is more tractable than the marginal likelihood objective, since it only requires MCMC sampling from a relatively concentrated conditional distribution. Moreover, we show that this estimation method is theoretically consistent: it learns the correct conditional and marginal distributions at each noise level, given sufficient data. After training, synthesized images can be generated efficiently by a sampling process that initializes from a spherical Gaussian distribution and progressively samples the conditional distributions at decreasingly lower noise levels. Our method generates high fidelity samples on various image datasets. On unconditional CIFAR-10 our method achieves FID 9.60 and inception score 8.58, superior to the majority of GANs. Moreover, we demonstrate that unlike previous work on EBMs, our long-run MCMC samples from the conditional distributions do not diverge and still represent realistic images, allowing us to accurately estimate the normalized density of data even for high-dimensional datasets.