 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Not 3D Re-ID: a Simple Single Stream 2D Convolution for Robust Video Re-identification
Aug 17, 2020
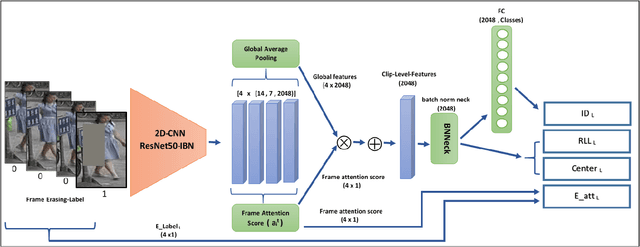

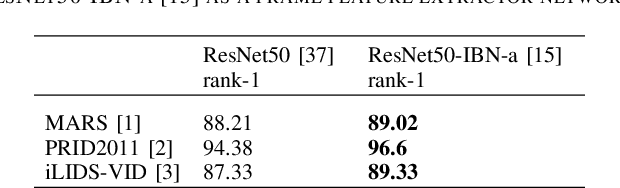
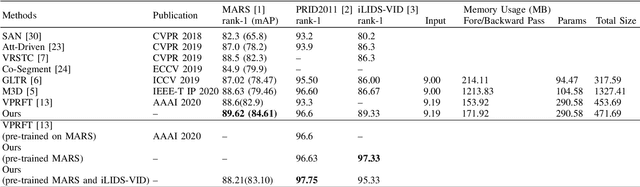
Video-based person re-identification has received increasing attention recently, as it plays an important role within surveillance video analysis. Video-based Re-ID is an expansion of earlier image-based re-identification methods by learning features from a video via multiple image frames for each person. Most contemporary video Re-ID methods utilise complex CNNbased network architectures using 3D convolution or multibranch networks to extract spatial-temporal video features. By contrast, in this paper, we illustrate superior performance from a simple single stream 2D convolution network leveraging the ResNet50-IBN architecture to extract frame-level features followed by temporal attention for clip level features. These clip level features can be generalised to extract video level features by averaging without any significant additional cost. Our approach uses best video Re-ID practice and transfer learning between datasets to outperform existing state-of-the-art approaches on the MARS, PRID2011 and iLIDS-VID datasets with 89:62%, 97:75%, 97:33% rank-1 accuracy respectively and with 84:61% mAP for MARS, without reliance on complex and memory intensive 3D convolutions or multi-stream networks architectures as found in other contemporary work. Conversely, our work shows that global features extracted by the 2D convolution network are a sufficient representation for robust state of the art video Re-ID.
SymmetryNet: Learning to Predict Reflectional and Rotational Symmetries of 3D Shapes from Single-View RGB-D Images
Aug 06, 2020
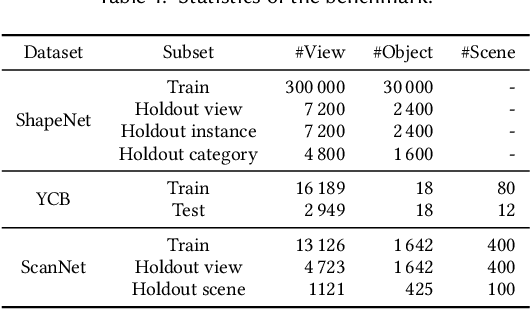
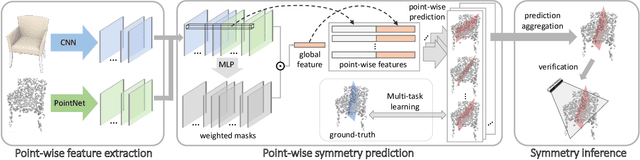
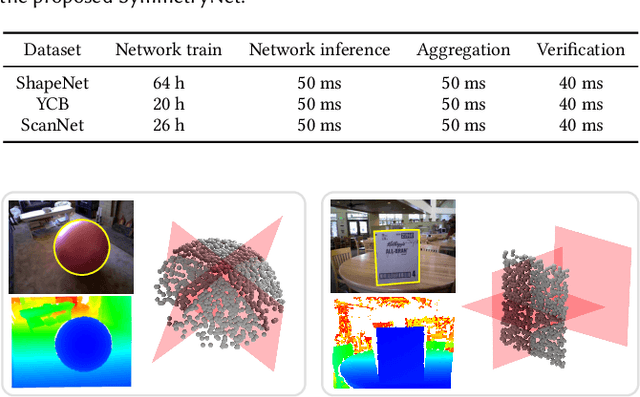
We study the problem of symmetry detection of 3D shapes from single-view RGB-D images, where severe missing data renders geometric detection approach infeasible. We propose an end-to-end deep neural network which is able to predict both reflectional and rotational symmetries of 3D objects present in the input RGB-D image. Directly training a deep model for symmetry prediction, however, can quickly run into the issue of overfitting. We adopt a multi-task learning approach. Aside from symmetry axis prediction, our network is also trained to predict symmetry correspondences. In particular, given the 3D points present in the RGB-D image, our network outputs for each 3D point its symmetric counterpart corresponding to a specific predicted symmetry. In addition, our network is able to detect for a given shape multiple symmetries of different types. We also contribute a benchmark of 3D symmetry detection based on single-view RGB-D images. Extensive evaluation on the benchmark demonstrates the strong generalization ability of our method, in terms of high accuracy of both symmetry axis prediction and counterpart estimation. In particular, our method is robust in handling unseen object instances with large variation in shape, multi-symmetry composition, as well as novel object categories.
* 14 pages
Interleaved Text/Image Deep Mining on a Large-Scale Radiology Database for Automated Image Interpretation
May 04, 2015
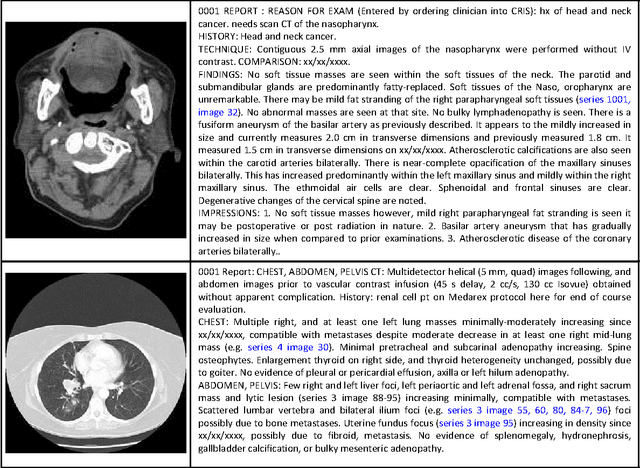
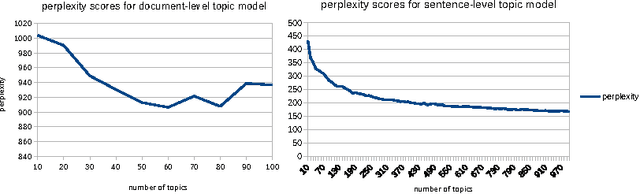
Despite tremendous progress in computer vision, there has not been an attempt for machine learning on very large-scale medical image databases. We present an interleaved text/image deep learning system to extract and mine the semantic interactions of radiology images and reports from a national research hospital's Picture Archiving and Communication System. With natural language processing, we mine a collection of representative ~216K two-dimensional key images selected by clinicians for diagnostic reference, and match the images with their descriptions in an automated manner. Our system interleaves between unsupervised learning and supervised learning on document- and sentence-level text collections, to generate semantic labels and to predict them given an image. Given an image of a patient scan, semantic topics in radiology levels are predicted, and associated key-words are generated. Also, a number of frequent disease types are detected as present or absent, to provide more specific interpretation of a patient scan. This shows the potential of large-scale learning and prediction in electronic patient records available in most modern clinical institutions.
Deep White-Balance Editing
Apr 03, 2020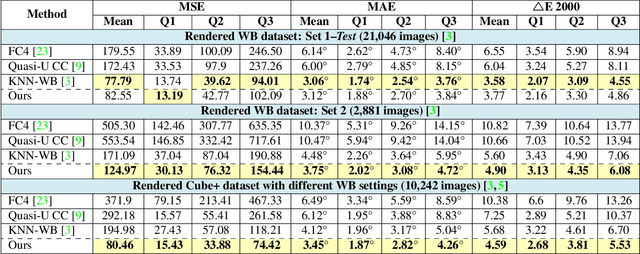
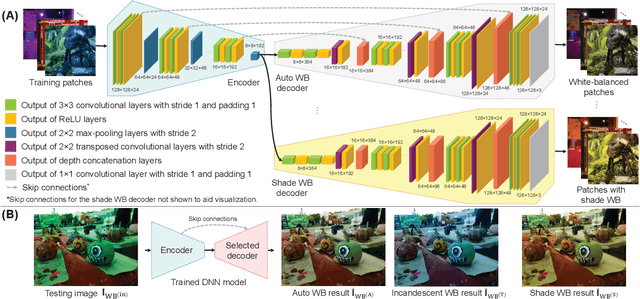

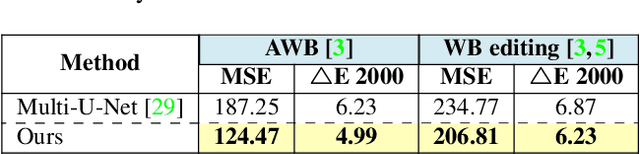
We introduce a deep learning approach to realistically edit an sRGB image's white balance. Cameras capture sensor images that are rendered by their integrated signal processor (ISP) to a standard RGB (sRGB) color space encoding. The ISP rendering begins with a white-balance procedure that is used to remove the color cast of the scene's illumination. The ISP then applies a series of nonlinear color manipulations to enhance the visual quality of the final sRGB image. Recent work by [3] showed that sRGB images that were rendered with the incorrect white balance cannot be easily corrected due to the ISP's nonlinear rendering. The work in [3] proposed a k-nearest neighbor (KNN) solution based on tens of thousands of image pairs. We propose to solve this problem with a deep neural network (DNN) architecture trained in an end-to-end manner to learn the correct white balance. Our DNN maps an input image to two additional white-balance settings corresponding to indoor and outdoor illuminations. Our solution not only is more accurate than the KNN approach in terms of correcting a wrong white-balance setting but also provides the user the freedom to edit the white balance in the sRGB image to other illumination settings.
Unveiling Real-Life Effects of Online Photo Sharing
Dec 24, 2020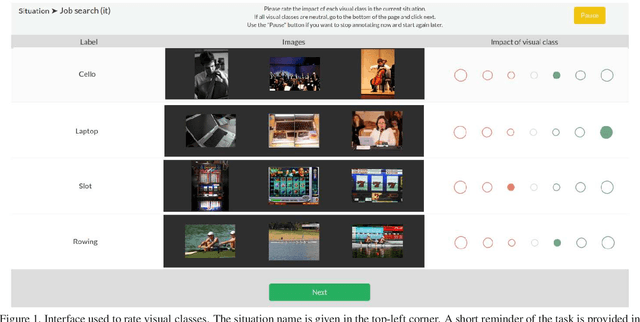

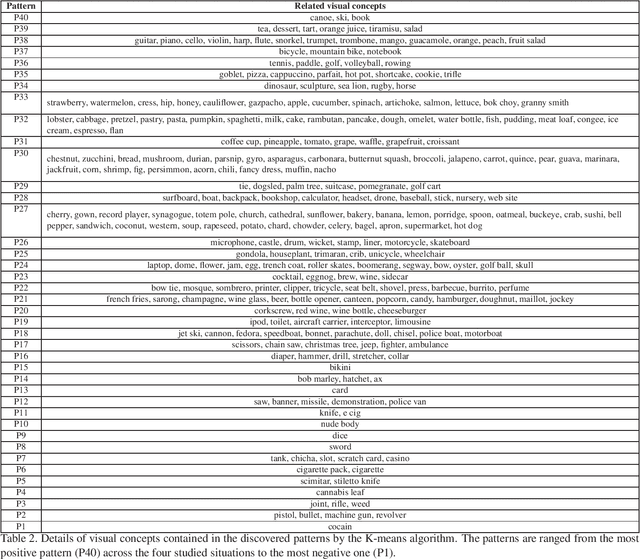
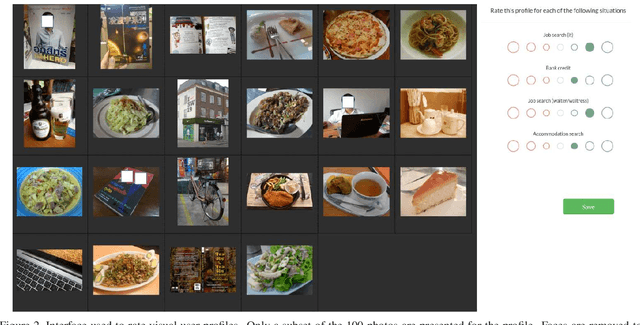
Social networks give free access to their services in exchange for the right to exploit their users' data. Data sharing is done in an initial context which is chosen by the users. However, data are used by social networks and third parties in different contexts which are often not transparent. We propose a new approach which unveils potential effects of data sharing in impactful real-life situations. Focus is put on visual content because of its strong influence in shaping online user profiles. The approach relies on three components: (1) a set of concepts with associated situation impact ratings obtained by crowdsourcing, (2) a corresponding set of object detectors used to analyze users' photos and (3) a ground truth dataset made of 500 visual user profiles which are manually rated for each situation. These components are combined in LERVUP, a method which learns to rate visual user profiles in each situation. LERVUP exploits a new image descriptor which aggregates concept ratings and object detections at user level. It also uses an attention mechanism to boost the detections of highly-rated concepts to prevent them from being overwhelmed by low-rated ones. Performance is evaluated per situation by measuring the correlation between the automatic ranking of profile ratings and a manual ground truth. Results indicate that LERVUP is effective since a strong correlation of the two rankings is obtained. This finding indicates that providing meaningful automatic situation-related feedback about the effects of data sharing is feasible.
comp-syn: Perceptually Grounded Word Embeddings with Color
Oct 19, 2020
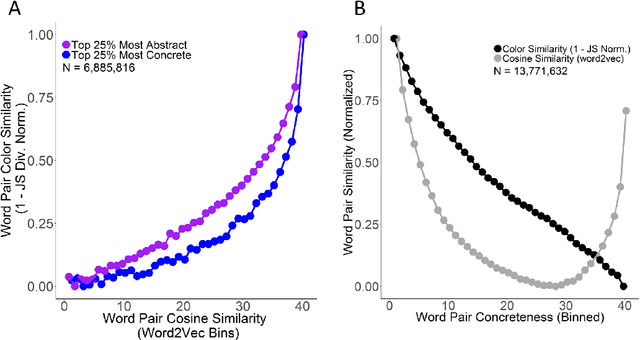
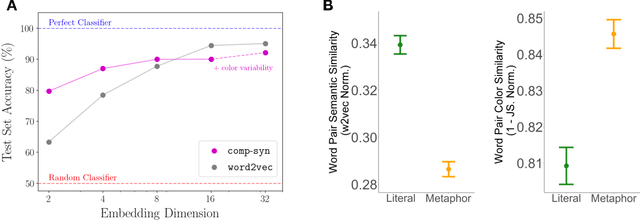

Popular approaches to natural language processing create word embeddings based on textual co-occurrence patterns, but often ignore embodied, sensory aspects of language. Here, we introduce the Python package comp-syn, which provides grounded word embeddings based on the perceptually uniform color distributions of Google Image search results. We demonstrate that comp-syn significantly enriches models of distributional semantics. In particular, we show that (1) comp-syn predicts human judgments of word concreteness with greater accuracy and in a more interpretable fashion than word2vec using low-dimensional word-color embeddings, and (2) comp-syn performs comparably to word2vec on a metaphorical vs. literal word-pair classification task. comp-syn is open-source on PyPi and is compatible with mainstream machine-learning Python packages. Our package release includes word-color embeddings for over 40,000 English words, each associated with crowd-sourced word concreteness judgments.
Adversarial Examples for Semantic Image Segmentation
Mar 03, 2017
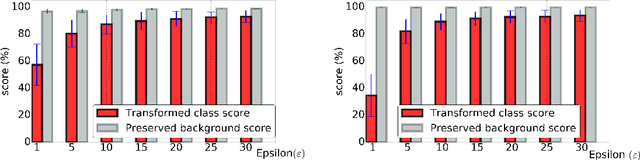
Machine learning methods in general and Deep Neural Networks in particular have shown to be vulnerable to adversarial perturbations. So far this phenomenon has mainly been studied in the context of whole-image classification. In this contribution, we analyse how adversarial perturbations can affect the task of semantic segmentation. We show how existing adversarial attackers can be transferred to this task and that it is possible to create imperceptible adversarial perturbations that lead a deep network to misclassify almost all pixels of a chosen class while leaving network prediction nearly unchanged outside this class.
Adaptive Weighted Discriminator for Training Generative Adversarial Networks
Dec 05, 2020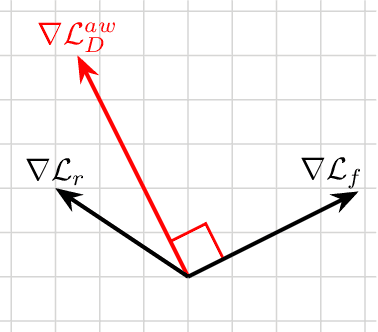
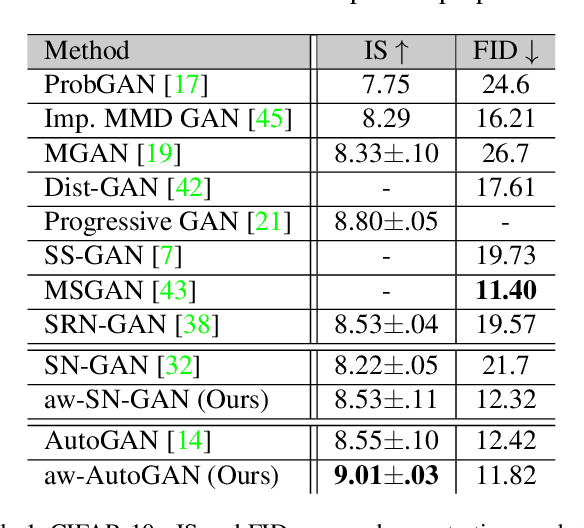

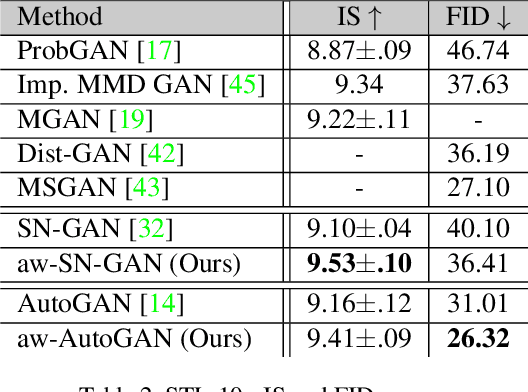
Generative adversarial network (GAN) has become one of the most important neural network models for classical unsupervised machine learning. A variety of discriminator loss functions have been developed to train GAN's discriminators and they all have a common structure: a sum of real and fake losses that only depends on the actual and generated data respectively. One challenge associated with an equally weighted sum of two losses is that the training may benefit one loss but harm the other, which we show causes instability and mode collapse. In this paper, we introduce a new family of discriminator loss functions that adopts a weighted sum of real and fake parts, which we call adaptive weighted loss functions or aw-loss functions. Using the gradients of the real and fake parts of the loss, we can adaptively choose weights to train a discriminator in the direction that benefits the GAN's stability. Our method can be potentially applied to any discriminator model with a loss that is a sum of the real and fake parts. Experiments validated the effectiveness of our loss functions on an unconditional image generation task, improving the baseline results by a significant margin on CIFAR-10, STL-10, and CIFAR-100 datasets in Inception Scores and FID.
Lesion2Vec: Deep Metric Learning for Few-Shot Multiple Lesions Recognition in Wireless Capsule Endoscopy Video
Jan 15, 2021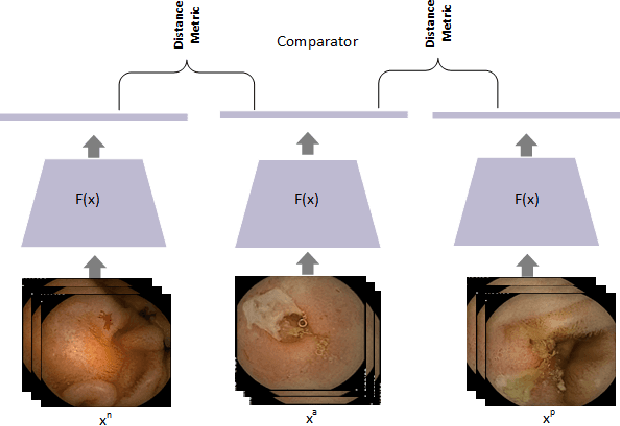
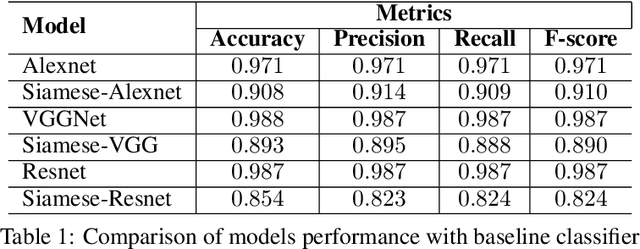
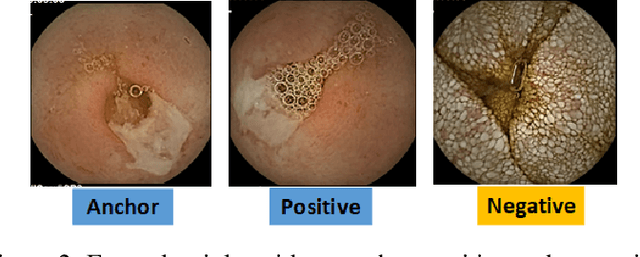
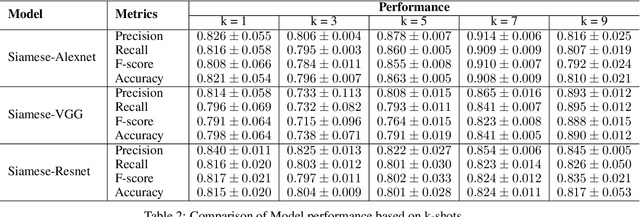
Effective and rapid detection of lesions in the Gastrointestinal tract is critical to gastroenterologist's response to some life-threatening diseases. Wireless Capsule Endoscopy (WCE) has revolutionized traditional endoscopy procedure by allowing gastroenterologists visualize the entire GI tract non-invasively. Once the tiny capsule is swallowed, it sequentially capture images of the GI tract at about 2 to 6 frames per second (fps). A single video can last up to 8 hours producing between 30,000 to 100,000 images. Automating the detection of frames containing specific lesion in WCE video would relieve gastroenterologists the arduous task of reviewing the entire video before making diagnosis. While the WCE produces large volume of images, only about 5\% of the frames contain lesions that aid the diagnosis process. Convolutional Neural Network (CNN) based models have been very successful in various image classification tasks. However, they suffer excessive parameters, are sample inefficient and rely on very large amount of training data. Deploying a CNN classifier for lesion detection task will require time-to-time fine-tuning to generalize to any unforeseen category. In this paper, we propose a metric-based learning framework followed by a few-shot lesion recognition in WCE data. Metric-based learning is a meta-learning framework designed to establish similarity or dissimilarity between concepts while few-shot learning (FSL) aims to identify new concepts from only a small number of examples. We train a feature extractor to learn a representation for different small bowel lesions using metric-based learning. At the testing stage, the category of an unseen sample is predicted from only a few support examples, thereby allowing the model to generalize to a new category that has never been seen before. We demonstrated the efficacy of this method on real patient capsule endoscopy data.
An Information-Geometric Distance on the Space of Tasks
Nov 01, 2020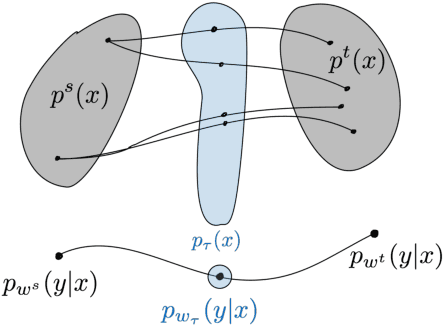
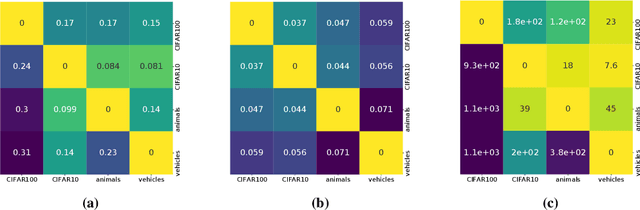
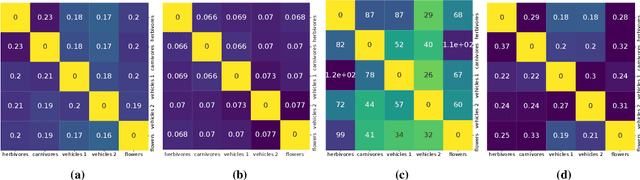
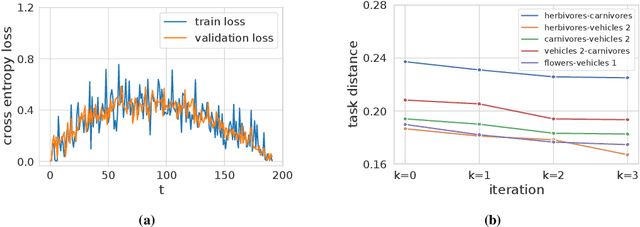
This paper computes a distance between tasks modeled as joint distributions on data and labels. We develop a stochastic process that transports the marginal on the data of the source task to that of the target task, and simultaneously updates the weights of a classifier initialized on the source task to track this evolving data distribution. The distance between two tasks is defined to be the shortest path on the Riemannian manifold of the conditional distribution of labels given data as the weights evolve. We derive connections of this distance with Rademacher complexity-based generalization bounds; distance between tasks computed using our method can be interpreted as the trajectory in weight space that keeps the generalization gap constant as the task distribution changes from the source to the target. Experiments on image classification datasets show that this task distance helps predict the performance of transfer learning: fine-tuning techniques have an easier time transferring to tasks that are close to each other under our distance.